一种基于用户交互行为的微博社区发现方法
2016-11-07徐建民李腾飞吴树芳
徐建民,李腾飞,吴树芳
(1.河北大学 计算机科学与技术学院,河北 保定 071002;2.河北大学 管理学院,河北 保定 071002)
一种基于用户交互行为的微博社区发现方法
徐建民,李腾飞,吴树芳
(1.河北大学 计算机科学与技术学院,河北 保定071002;2.河北大学 管理学院,河北 保定071002)
通过研究微博社区的结构特征和用户交流模式,提出了一种基于微博用户交互行为的社区发现方法.该方法借鉴引文分析理论中的著者互引分析和著者耦合分析,分析微博社区内用户的交互行为,考虑到不同交互行为体现了对微博的不同兴趣度,给不同的交互行为赋予了不同权重,进行相似度计算,并利用用户相似度进行社区发现.实验结果显示,本文提出的方法可以有效地进行社区发现.
微博社区;社区发现;引文分析;交互行为;用户相似度
社区目前没有标准的定义,社会网络中的社区可以认为是网络中由一组具有相同结构或特性的节点组成的集合.社区发现是通过调用一定的社区发现算法,按照某种标准进行社区划分,其目的是将网络中的社区挖掘出来.随着互联网的发展、社交网络的兴盛,社区发现逐渐成为热门研究方向.微博是一种新兴的社交网络,现已成为中国重要的社交网络媒体之一.微博社区发现有助于研究社会网络演化过程、社会网络结构特征等课题,也可以为好友推荐、广告精准投放、话题推送等应用提供理论依据和具体方法,具有重要的学术和实用价值.
目前对微博社区的研究主要集中在用户关注关系和微博文本内容分析上.Golsefid等[1]提出利用模糊图聚类进行社区发现,以可能性C-聚类模型为基础,利用与聚类中心的相似度进行节点距离计算,最终完成社区发现.Tang等[2]利用数据场理论衡量用户间的联系程度,先确定初始聚类,然后采用粗糙集聚类算法进行社区发现.周小平等[3]以关注关系为网络节点,以关注之间的共同用户为关注关系潜在的边,以关注关系所关联用户的兴趣集的交集为关注关系的兴趣特征,构建微博网络R-C模型进行社区发现.于洪涛等[4]提出一种基于链接相似性的微博重叠社区发现算法,该算法通过用户相似度矩阵映射得到用户虚拟兴趣网并求得该网络的链接相似度,并综合用户的真实关注网络的链接相似度得到总的链接相似度,为了将链接相似度用于社区发现,该算法对传统的Ward层次聚类算法进行推广,使之适用于具有相似性度量的任意对象,并将其用于社区发现.
由于微博用户互粉、买粉、悄悄关注等行为,微博内容也不局限于文本形式,这些因素导致用户间的关注关系或微博内容并不能真实地反应用户的交际网络.文献[5]提出利用用户间交互行为提高社区划分质量,但并没有考虑不同的交互行为表示的联系的紧密程度不一样.1955年,Garfield提出引文分析理论,该理论通过数学方法分析文献间的引用和被引用关系,以发现其内在规律[6].2001年,Fang[7]将引文系统看成是网格,这些菱形网格对应的文献耦合与共引文献属于网格系统的基本结构.在微博社区中,不同微博用户可能关注同一条微博,一个微博用户可能同时关注多条微博,这些行为类似于引文分析中的互引和耦合.基于上述原因,本文通过分析用户交互行为,在引文分析理论的基础上,根据用户间的交互度得到用户间的相似度,并以此进行微博社区的发现.以新浪微博为数据采集平台,实验验证了文章给出的微博社区发现算法的有效性.
1 研究基础
1.1引文分析理论
一般来说,引文分析共包括3种关系,引用、共引和耦合.图1a表示文献引用关系,即如果文献B引用了文献A,则二者之间存在引用关系,互引关系是引用关系中的一个特例,一般发生在著者、期刊或者学科之间,如果著者A引用了著者B,而著者B又引用了著者A,则这2个著者之间为互引关系.将所有具有引用关系的论文连接起来,则形成了引文网络,图1d展示了引文网络的示例.
文献共引是Small在1973年提出,如果2个文献同时被一篇文献引用,则说明这2篇文献存在相似性[8].在图1c中,文献G和文献H同时被文献F引用,则认为文献G和文献H之间存在文献共引的关系.
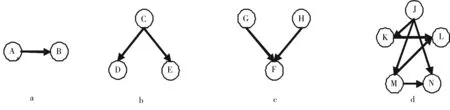
a.文献引用;b.文献耦合;c.文献共引;d.引文网络.图1 文献引用关系Fig.1 Relationships of literature citation
文献耦合的概念是Kessler[9]于1963年提出的,他发现学科或者内容相近的论文,参考文献中包含着较多的相同文献,他把同时引用了一篇文献的2篇文献称为耦合文献,把它们之间的关系称为文献耦合.在图1b中,文献D和文献E同时引用了文献C,则文献D和文献E之间存在文献耦合关系.耦合关系中除了文献耦合外,还有学科耦合、期刊耦合、著者耦合等,其中著者耦合认为引用了相同参考文献的著者之间存在相似性,可以根据共同引用的参考文献数量对著者间的相似性进行量化.
1.2微博社区
微博是一种新兴的社交网络,有低门槛、实时性、简易性、传播快的特点,这些特点造成微博信息数量巨大,结构复杂.在微博网络中,用户不可能浏览到所有用户发布的所有微博,而是会基于兴趣爱好、职业、地理等因素关注自己感兴趣的用户,并和这些用户组成社区,即微博社区,图2展示了微博社区交互示例.1个微博用户可能会有多个兴趣爱好,也就会分属于多个社区,这被称为“重叠社区”.例如图2中,用户A同时关注IT和美食2个社区,则在社区划分时用户A既在IT社区内,也在美食社区内;用户B同时关注了体育和金融2个社区,则在社区划分时,用户B既在体育社区内也在金融社区内.

图2 微博社区交互示例Fig.2 A sample of micro-blogging community interactions
1.3微博用户交互行为
微博社区内主要通过用户间的交互行为维持彼此之间的联系.微博用户对博文的交互行为主要有以下6种:
1)转发微博(retweet):用户可以将其他用户的博文或评论内容转发到自己微博中,转发时可以对微博内容进行评论,也可以只转发.转发后,会推送给粉丝,粉丝可以对微博进行再次转发、评论等交互行为.
2)评论微博(comment):用户可以对博文进行评论,也可以同其他评论者进行交流.
3)点赞微博(like):用户可以对博文点赞,表示对内容的赞同或喜欢.
4)@用户(at):用户在发表博文时可以@其他用户,表示这是对@用户说的话,此时,其他用户会收到通知.
5)私信(direct message):私信类似于电子邮件,只有互相通信的2人可以看到.
6)收藏(collect):用户可以收藏自己喜欢的微博,收藏后可以在收藏栏中看到.
对于1条微博,用户可以同时有多种交互方式,比如同时点赞和评论,图2中的用户C同时评论和点赞了用户A的1条微博.@用户一般用在发布微博或者转发微博时,图2中的用户B在发布微博时@到了用户D.每个微博用户偏好的社交习惯不尽相同,有的用户偏好转发,有的用户偏好点赞,有的用户倾向性不明显,每种交互行为都可能会被使用.共同交互的用户间存在相似性,用户间共同交互的微博数目越多,相似性越大.
2 基于用户交互行为的微博社区发现算法
微博用户通过交互行为产生联系,本文称为交互关系.微博用户间的交互关系分为直接和间接2种.直接交互指用户之间直接对彼此发布的微博进行交互,例如图2中用户C对用户A的微博进行了评论,则C对A有直接交互关系.间接交互指不同用户同时对其他用户发布的博文进行交互,例如图2中用户E和F均转发了用户A的某条博文,则认为这2个用户间存在间接交互关系.
直接交互关系类似于著者互引关系,间接交互类似于著者耦合关系.借鉴引文分析理论中著者关系的分析方法,通过量化微博用户间的直接交互关系和间接交互关系计算用户间的相似度.虽然微博处于时时动态更新中,微博用户也不断地和其他用户进行交互,但用户的兴趣爱好和社交网络可以认为大体上是稳定不变的.为此,可以通过用户的历史交互行为记录挖掘出用户兴趣爱好特征,以此发现用户的社区归属.
2.1基于用户交互行为的用户相似度计算
本文首先计算出用户对一条博文的兴趣度,然后分别计算出用户直接交互的交互度和间接交互的耦合度,最后加权求和得到用户间的相似度.由于私信和收藏的交互行为属于隐私,无法获取,所以研究中不考虑.
假设网络中所有用户集合为user,所有用户发布的微博集合为blog,用户A发布的博文为A1,A2,A3,…,Aj,用户B发布的博文为B1,B2,B3,…,Bk,其他用户发布的博文为O1,O2,O3,…,Om.在上述假设的基础上,用户对博文兴趣度、用户交互度、用户耦合度、用户相似度的具体计算方法如下文所述.
1)用户对博文兴趣度
微博用户对一条博文可以有多种的、重复的交互行为,用户对一条博文的兴趣度由各项交互行为权重累加得到,其计算方法为
(1)
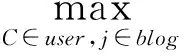
2)用户交互度
用户间的交互度指用户间的直接交互关系的紧密程度,由于用户间直接交互关系并非对等关系,所以用户间的交互度由用户对彼此微博的兴趣度加权得到,具体公式如下:

(2)
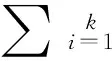
3)用户耦合度
用户耦合度指用户间的间接交互关系的紧密程度,其内涵类似于著者耦合分析中的耦合强度,文献[10]证明著者耦合分析中,最小值算法是一种比较理想的算法,因此采用最小值算法并通过归一化得到微博用户的间接耦合度,计算公式如下:
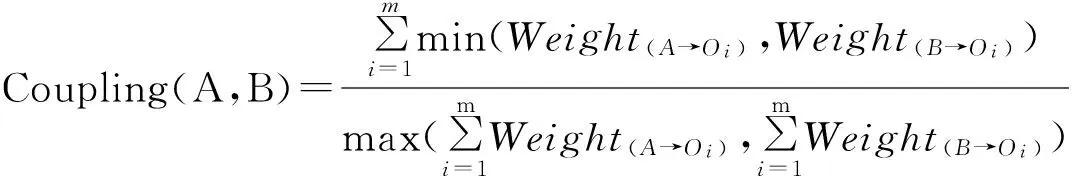
(3)

4)用户相似度
由用户的交互度和耦合度可以得到用户间的相似度.计算公式如下:
Sim(A,B)=ωInteraction(A,B)+(1-ω)Coupling(A,B),
(4)
公式(4)中,Sim(A,B)表示用户A和B之间的相似度.Interaction(A,B)表示用户A和B之间的直接交互度,Coupling(A,B)表示用户A和B之间的间接耦合度.ω为权重系数,其值根据经验设定为0.7.
观察公式(4)发现,不同微博用户间的相似度越高,则二者共同交互的微博越多,联系越紧密,属于同一社区的概率越大.
2.2基于用户交互相似度的社区发现算法
一般认为,一个良好的社区发现算法应该使得社区内部的成员联系紧密,同时与社区外部的成员联系尽可能的少.文章依据上述思想,借鉴Blondel等[11]提出的模块度增量函数和上节的相似度计算方法,不断将与社区相似度值最大、且模块度增量大于0的用户节点加入社区,最终完成社区发现的任务.
节点与社区的相似度体现了节点属于社区的可能性,相似度值越大,可能性越高.节点与社区相似度计算公式如公式(5)所示:
(5)
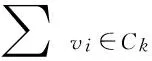
Blondel等在2008年提出一种基于模块度优化的社区发现算法,利用模块度增量判断节点是否可加入社区,如果模块度增量ΔQ大于0,则说明节点可加入社区,反之则说明节点不属于此社区,模块度增量计算公式如下:
(6)
公式(6)中∑in是社区Ck中所有节点之间的相似度总和,∑tot是Ck中所有节点与其他所有节点相似度总和,∑vj是节点j与其他所有节点相似度总和,∑vj,in是节点j与社区Ck中节点的相似度总和,m为网络中所有相似度的和.
具体社区发现算法步骤如下.
输入:微博用户节点集合V={v1,v2,v3,…,vn};
用户相似度集合E={Sim(v1,v2),Sim(v1,v3),Sim(v1,v4),…,Sim(vn-1,vn)},每个相似度值为社区网络中连接微博用户的边的权重.
输出:社区集合C={C1,C2,C3,…,Ck}.
算法步骤:
1)随机从用户节点集合V中选取1个节点,加入空的社区Ck内,并从用户节点集合V内删除这个节点.
2)根据公式(5)计算社区Ck外用户节点与社区Ck的相似度,选取与社区相似度值最大的节点vj,按公式(6)计算其模块度增量,如果ΔQ>0,则将节点加入社区内,更新社区集合,并从用户节点集合V中删除此节点.重复此步骤直到没有节点的模块度增量ΔQ>0,表示社区已发现所有属于此社区的用户节点.
3)对于用户节点集合V内剩余节点,重复步骤1)-2),直到用户节点集合V为空,表示社区发现已完成.
3 实验
3.1实验数据
由于目前没有统一的、权威的微博数据集供使用,因此本文通过爬虫工具,随机爬取新浪微博网络来采集数据.经过预处理后得到实验数据,共包括5 487名用户,165 859条微博,以及他们之间互相交互的数据.将获得的数据分为训练集和测试集,训练集包括50名用户,4 802条微博,用于获取交互行为权重.测试集合包括5 437名用户,161 057条微博,用于测试算法的有效性.
本文通过人工标注,对训练数据集进行分类,得到用户发布微博的兴趣分布和交互微博的兴趣分布,并通过设定不同的交互行为权重值比较这2个分布,进而获得结果较优的交互行为权重,结果如表1所示.

表1 用户交互行为权重
3.2评价标准
本文采用Newman和Girvan[12]提出的社区评价标准检测算法的有效性,Newman和Girvan认为一个好的社区应该是内部的边尽可能的多,而外部的边尽可能的少,基于这种思想,提出了社区评价标准Q函数,由于Q函数不适合加权网络,研究者对其进行了扩展,笔者采用的评测标准是扩展后的Qw函数.
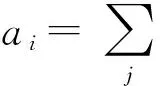
(7)
Newman和Girvan指出,如果Q函数值为0,表示所有的节点都属于同一个社区;Q函数的值越大,说明社区划分的结果越好.
Q函数不适用于带权网络,对于带权网络,扩展后的模块度函数Qw如下所示:
(8)
公式(8)中,W是网络中所有边的权值之和,Wc表示社区c内部所有边的权值之和,Tc为与社区c中的所有节点相邻的边的权值之和.
3.3结果分析
为验证社区发现算法的有效性,对新浪微博数据的测试部分进行实验,并运用3.2节的Qw函数对社区划分结果进行评价.
根据公式(1)得到用户对博文的兴趣度,结果如表2所示.其中,用户自己发布的微博的兴趣度为1.
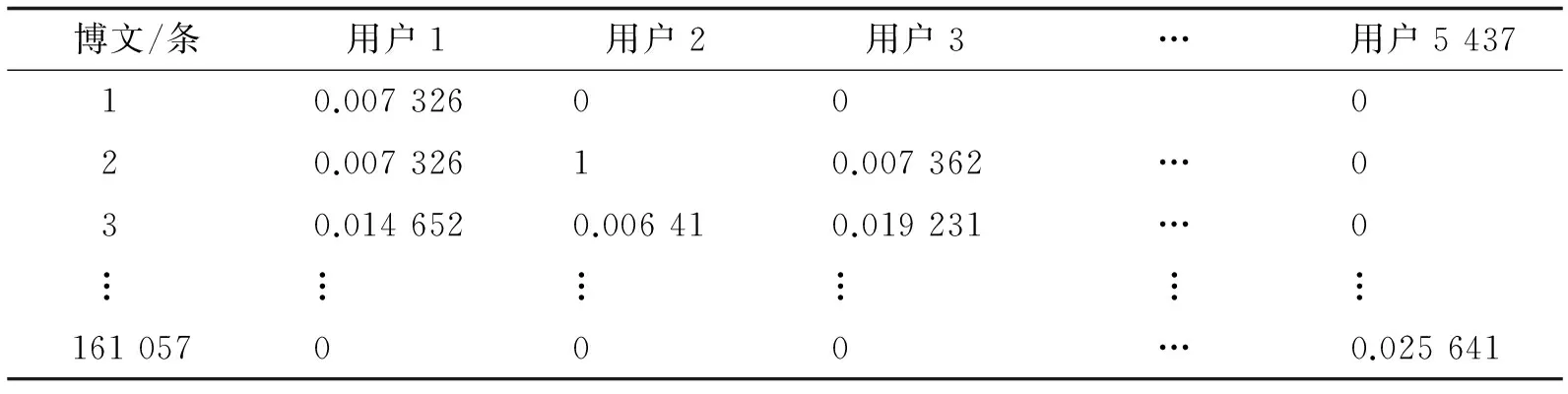
表2 用户对博文兴趣度
根据公式(2)和公式(3)分别得到用户交互度和用户耦合度,最后通过公式(4)得到用户相似度,结果如表3所示.用户自己对自己的相似度为1.

表3 微博用户相似度
在上述实验结果的基础上,运用文章提出的社区发现算法,对微博用户进行了社区划分,结果如图3所示.由于节点过多,图3中只选择了部分社区划分结果.

图3 部分社区划分结果示意Fig.3 Part of the result of community division
为了检验算法社区发现的有效性,运用3.2节介绍的评价标准计算了Qw函数值,如表4所示.一般认为Qw函数值越大证明算法的社区发现能力越好,但是在实际的社交网络中,由于各种因素的制约,Qw函数值通常为0.3~0.7,论文提出的社区发现算法的Qw函数值为0.667 9.所以实验结果显示论文提出的基于用户交互行为的社区发现算法能有效地进行社区发现.

表4 Q函数值
4 结束语
本文通过分析微博社区结构和交互行为特征,借鉴引文分析理论中著者互引关系和著者耦合关系,将用户交互行为分为直接交互关系和间接交互关系,通过对博文的兴趣度量化用户间的亲密程度,最终加权得到用户的相似度.在用户相似度的基础上,将模块度增量作为判断节点是否加入社区的标准,完成社区发现.论文从新浪微博采集数据,验证新算法的有效性.由于实验是在新浪微博上随机获取的部分数据,权威性不高,所以在未来的研究中寻找更加权威的数据进一步验证算法的有效性.
[1]GOLSEFID S M M,ZARANDI M H F,BASTANI S.Fuzzy community detection model in social networks[J].International Journal of Intelligent Systems,2015,30(12): 1227-1244.DOI:10.1002/int.21743.
[2]TANG L,NI Z.Applying overlapping community detection based on data field theory for twitt-er audiences classification[J].International Journal of u- and e- Service,Science and Technology, 2015,8(5): 23-26.DOI:10.14257/ijunesst.2015.8.5.03.
[3]周小平,梁循,张海燕.基于R-C模型的微博用户社区发现[J].软件学报,2014,25(12): 2808-2823.DOI:10.13328/j.cnki.jos.004720.
ZHOU Xiaoping,LIANG Xun,ZHANG Haiyan.User community detection on micro-blog using R-C model[J].Journal of Software,2014,25(12):2808-2823.DOI:10.13328/j.cnki.jos.004720.
[4]于洪涛, 崔瑞飞, 黄瑞阳.链接相似性的微博重叠社区发现算法[J].小型微型计算机系统, 2015, 36(5): 928-933.
YU Hongtao,CUI Ruifei,HUANG Ruiyang.Link-based similarity micro-blog overlapping community detecting algorithm[J].Journal of Chinese Computer Systems,2015,36(5):928-933.
[5]QI G J,AGGARWAL C C,HUANG T.Community detection with edge content in social media networks[C]//Data Engineering (ICDE),2012 IEEE 28th International Conference on IEEE,2012: 534-545.DOI:10.1109/ICDE.2012.77.
[6]苑彬成,方曙,刘清,等.国内外引文分析研究进展综述[J].情报科学,2010,28(1): 147-153.
YUAN Bincheng,FANG Shu,LIU Qing,et al.Overview on progress in citation analysis at home and abroad[J].Information Science,2010,28(1):147-153.
[7]FANG Y,ROUSSRAU R.Lattices in citation networks: An investigation into the structure of citation graph[J].Scientometrics,2001,50(2): 273-287.DOI:10.1023/A:1010573723540.
[8]SMALL H,GRIFFITH B C.The structure of scientific literatures I: Identifying and graphing specialties[J].Science Studies,1974:4(1) 17-40.DOI:10.1177/030631277400400102.
[9]KESSLER M M.Bibliographic coupling between scientific papers[J].American documentation,1963,14(1): 10-25.DOI:10.1002/asi.5090140103.
[10]马瑞敏,倪超群.作者耦合分析: 一种新学科知识结构发现方法的探索性研究[J].中国图书馆学报,2012,38(3):4-11.DOI:10.13530/j.cnki.jlis.2012.02.002.
MA Ruimin,NI Chaoqun.Author coupling analysis:an exploratory study on a new approach to discover intellectual structure of a discipline[J].Journal of Library Science in China,2012,38(3):4-11.DOI:10.13530/ j.cnki.jlis.2012.02.002.
[11]BLONDEL V D,GUILLAUME J L,LAMBIOTTE R, et al.Fast unfolding of communities in large networks[J].Journal of Statistical Mechanics: Theory and Experiment,2008:30(2):155-168.DOI:10.1088/1742-5468/2008/10/P10008.
[12]NEWMAN M E J,GIRVAN M.Finding and evaluating community structure in networks[J].Physical Review E,2004,69(2): 026113.DOI:10.1103/PhysRevE.69.026113.
(责任编辑:孟素兰)
A micro-blogging community discovery method based on user’s interactions
XU Jianmin1,LI Tengfei1,WU Shufang2
(1.College of Computer Science and Technology,Hebei University,Baoding 071002,China;2.College of Management,Hebei University,Baoding 071002,China)
By investigating the structure of micro-blogging and user’s communication mode,a micro-blogging community discovery method based on user’s interactions was presented.User’s interactions in micro-blogging are analyzed by referring to author cross citation and author coupling citation in citation analysis.Considering different interactions reflect different interests in micro-blogging articles,this paper sets different weights for different interactions and proposes a new calculation method of user’s similarity based on interactions that is used to divide micro-blogging community.Experimental results show that the proposed method can effectively perform community discovery.
micro-blogging community;community discovery;citation analysis;user’s interactions;user’s similarity
10.3969/j.issn.1000-1565.2016.02.014
2015-12-07
河北省自然科学基金资助项目(F2015201142);河北省教育厅青年基金资助项目(QN2015099);河北省社会科学基金资助项目(HB15TQ013);河北省社会科学基金课题(HB15SH064)
徐建民(1966-),男,河北邯郸人,河北大学教授,博士,主要从事信息检索、不确定信息处理方向研究.
E-mail:84887613@qq.com
吴树芳(1979-),女,河北邯郸人,河北大学副教授,博士,主要从事信息检索、不确定信息处理方向研究.
E-mail:598704274@qq.com
TP391
A
1000-1565(2016)02-0189-08
