汉语公式化序列长度和频数关系的协同理论研究
2016-11-06戴雪婷梁怡洲瞿云华
戴雪婷,梁怡洲,瞿云华
(浙江大学外国语言文化与国际交流学院,浙江杭州310058)
汉语公式化序列长度和频数关系的协同理论研究
戴雪婷,梁怡洲,瞿云华
(浙江大学外国语言文化与国际交流学院,浙江杭州310058)
本研究采取语料库驱动范式,探究汉语公式化序列长度和频数的关系规律,旨在验证协同理论构建于词汇层面的理论和模型在公式化语言上的适用性。研究结果表明,汉语公式化多词序列的长度对其使用频数产生负影响,二者之间的关系规律可以进一步通过幂函数F=aLbe⁃cL描述。从长度—频数关系出发,研究结果拓宽了原有理论和模型的适用范围,进一步探讨了语言的共性;通过跨语域的对比研究,发掘了公式化语言的特性。
汉语公式化序列;长度;频数;协同理论;语域
一、引言
Zipf于1935年首次提出“词汇的长度和其使用频数呈负相关”[1]25①的理论假设。这一设想开启了语言学界对词汇长度(词长)和使用频数(词频)关系的探讨研究。半个多世纪以来,国内外语言学家通过对不同语种的考察,并以多种类型的语言单位来度量词长,对Zipf的假设进行了广泛的验证和拓展。Zipf最早基于德语语料对词长和词频的关系进行了简单的阐释,其他研究者则相继基于英语(分别以字母和音素数量为词长单位)[2]、拉丁语(以音节数为词长单位)[3]、荷兰语(以字母数为词长单位)[3]、汉语(以汉字字数为词长单位)[4]等语料对这一假说进行了反复验证。
从建立假设到验证拓展,以往研究对“长度”和“频数”关系的探讨大多建立在词汇层面,也有研究者观察到在多词组合中同样存在长度和频数呈负相关的现象[5]②。然而到目前为止,多词组合的长度—频数关系研究仅仅停留在现象观察的(observational)层面,尚未进行系统、深入的探究和解释,也缺少充足的语料支撑。相关的汉语研究更是有待挖掘。
近三十年来,语言学界广泛关注的语言公式化问题为我们进一步考察长度和频数的关系提供了新的思路。本研究基于自建的浙江大学汉语语料库,对汉语公式化序列的长度和使用频数之间的关系进行计量分析,旨在验证协同理论的动态机制在公式化语言上的适用性,以进一步发掘公式化语言的特性,探讨语言共性。
二、研究背景
(一)公式化语言:基本特征和语料库提取
正如Bolinger所言,语言的建构并不要求我们全部从原始的“几块木材,几颗钉子和一张图纸”[6]1开始;相反,它为我们提供了大量的“预制件”。公式化语言(formulaic language)正是语言建构中的“预制件”,它在日常语言使用中占据了较高的比重。Wray将公式化语言定义为预制的序列 (prefab⁃ricated sequences of words),这类序列往往“作为整体储存在记忆中,并在使用时作为整体取出,不需要经过语法的生成和分析”[7]9(例如 the end of the,in terms of,by and large,goods and service)。 因此,处理优势是公式化语言的一个重要特征:通过使用这些预制的序列,可以压缩语言处理的时间,节约精力,符合语言使用的经济原则。从这一角度看,单个的公式化语言即公式化序列(formulaic sequences)与单个词汇具有高度的相似性。除此之外,Wray&Perkins指出,公式化语言还具有语篇标记(discourse marker)的功能,能够促进不同语境下的语言交际[8]。
根据公式化语言的定义和特征,语言学家建立了一套可操作的鉴别和提取标准,其中较常用、相对可靠的方法是根据其高频特征(recurrent),基于频数标准(raw frequency)进行语料库驱动式抽取。基于不同语料和不同研究目的,研究者[5,7,9]使用的抽取标准也不尽相同,在一定程度上不可避免地存在任意性。因此不少研究者在鉴别时还使用了其他标准,用以弥补频数抽取的不足。如Biber设立抽取lexical bundle的标准为每百万词出现十次及以上[9],他还提出:“为了消除语料中说话人/作者的个人语言特质影响,公式化语言必须在多个(≥5)文本中出现。”[9]282除了机器提取以外,不少研究者采用了母语使用者人工判断筛选的方法。例如Wray&Namba制定了包含十一项标准的语言公式化的人工判断量表 (checklists)[10]。
语料库驱动的公式化语言研究在获取语料时,不需要预设完整的语言单位和理论假设,通常只将长度和频数量级设定为条件,以充分发掘语料,尽可能地穷尽不同类别的公式化语言。这类研究往往将“长度”和“频数”视为鉴别和提取公式化语言的标准,而对于二者之间的关系则鲜有涉及。
(二)协同理论与长度—频数关系研究
Zipf对语言使用中词长和词频呈负相关的观察启发了大量后继研究。除了多语种、多种语言单位的横向验证和拓展以外,研究者们还对二者之间关系的统计规律进行了深入的描述。其中,以Köhler为代表的协同语言学家构建了较为完善的框架和模型,用以描述和解释词长—词频关系。
Köhler指出,协同方法(synergetic approach)以跨学科视阈,采用模型构建的方法描述和解释所有动态系统,关注结构的自发调整和发展变化过程。协同语言学主张,语言既是心理社会(psycho⁃social)现象,同时也是生物认知(biological⁃cognitive)现象。语言被视为一个庞大的动态系统,各个子系统之间相互协作、相互竞争,融合来自生物机体、心理社会等外部作用,共同构成了语言体系的运作机制[11]761。交际活动中呈现的各种语言现象、语言结构和语言各个属性之间的协作关系,都是语言体系运作机制的反映,也是协同语言学的主要关注对象。
“语言的运作机制并非杂乱无章,而是有规律可循的。”[4]30协同语言学的核心目的在于:以演绎的方式对语言运作机制提出普遍性的理论假设,运用数学计量方法对其运作规律进行宏观性的总结、建模和解释。通过验证理论假设和模型测试,揭示语言系统运作和发展的规律,并以数学定律的形式呈现,逐渐形成并完善语言理论的网络体系[11]761。
Köhler以德语为语料,构建了首个针对词汇的协同语言学模型,描述了四个词汇属性“词长(length)”“词频(frequency)”“多义性(polysemy)”以及“多文度(polytextuality)”之间的协同关系[11]768。图1为简化的Köhler词汇控制回路模型(lexical control circuit):箭头代表影响作用及作用方向;加减号分别代表正、负影响。如图1所示,词频对词长产生直接性负影响,受语言系统运作中生成负担最小化(Minimization of production effort,即MinP)要求的支配,与Zipf提出的省力原则(principle of least effort)相符。
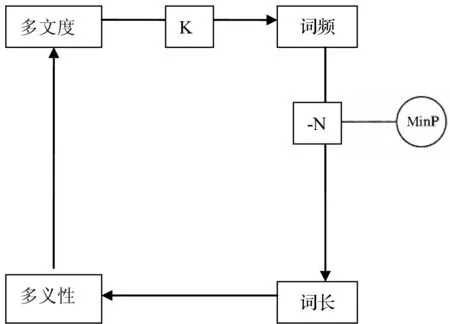
图1 Köhler词汇控制回路模型(简化)[11]768
Köhler进一步将词长和词频的关系表示为微分方程:变量x的相对变率与变量y成比例。
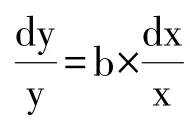
这一公式可以转化为幂函数F=aLb(b<0;a,b为参数)。 在该公式中,L(length)的取值为同一词长范围内所有频数量级F(frequency)的平均数值。
Köhler建立的词长和词频关系模型和幂函数公式为二者之间的关系规律研究提供了新的分析方向。其后,不少研究者就Köhler提出的模型进行了验证和补充:Strausset al.[3]基于10种语言和多种语篇类型,证实了词长和词频的协同规律在自然语言中的普遍性,并就函数模型中的参数变化规律进行了分析;邓&冯[4]将该模型引入汉语词汇中进行了验证,同样分析了函数模型中的参数变化规律;Altman 提出的 F=aLbe⁃cL(a,b,c 为参数,e 为自然常数) 函数被证实具有相当高的拟合效度[12]。
迄今为止,研究者对长度—频数的协同关系规律已经进行了多语种、多语篇、多维度的分析。但相关研究均停留在词汇层面,尚未拓展到其他语言单位。词汇的协同规律是否同样适用于多词序列?这是本研究所要探讨的重点:通过不同语言单位的验证,进一步揭示语言规律的共性。
为了探讨以上问题,本研究先对汉语公式化序列作出界定,界定标准基于Wray(2002,2003)[7,10]对英文序列特征的定义及公式化判断量表,结合汉语语法特征,内容包括:1)使用频数高;2)语义不透明,在感知上并不突出;3)语法结构特殊,甚至有不规则现象;4)在语音上具有连续性;5)包含虚词和实词;6)较短的序列可以并入较长的序列;7)呈现固化和半固化性。具体地说,主要为:
1)与英语公式化序列定义相似,汉语公式化序列是指在日常汉语使用中经常出现的,由多个词构成、具有整存整取预制特征的连续序列。汉语公式化序列同样包括搭配、惯用语、成语、习语等固定或半固定的词语序列。
2)但汉语公式化序列在构成单位上与英语有所区别:英语公式化序列由单个词汇构成,序列长度通常以单词为划分单位,例如“on the other hand”为四词序列。汉语公式化序列则以结合紧密、使用稳定的汉语词汇为最小单位,例如序列“我 不知道”和“你 告诉 我”由三个词汇构成,为三词序列;“我跟你说”“我想问一下”为四词序列。
另外,汉语公式化序列倾向于代指单个的、可数的序列,汉语公式化语言是将此类序列视为整体的总称。本文为语料库实证研究,侧重序列的长度和频数研究,因而采用汉语公式化序列这一名称。
基于以上观察,结合对公式化序列特征的考察,本研究提出假设:协同理论关于词长和词频的理论假设和数学模型可能同样适用于汉语公式化序列。为验证该假设,本研究基于大量汉语公式化序列数据,运用计量方法揭示其长度和频数之间的协同关系,并探讨公式化语言和协同规律在不同语体(书面语/口语)下的特征。
三、研究方法
(一)数据来源
本研究数据来自于自建的浙江大学汉语语料库(Zhejiang University Corpus of Spoken and Written Mandarin Chinese,简称ZCMC)。ZCMC共计100万词,均为汉语普通话,取自2000到2014年间的正式出版物或公开发表内容。口语、书面语各50万词,包括新闻、社论、学术文章、政府文件、小说、电视节目、法庭辩论等多种语体。语言取样时效性强,类型广泛,能够充分反映当代汉语口语和书面语使用的语言特征。
(二)数据收集及处理
本研究以3—6词的连续性汉语公式化序列为对象,研究数据包括:1)序列长度;2)相应长度等级序列的频数数据。序列长度以所包含的汉语词汇数目来衡量,例如词条“我不知道”,包含了“我”“不”“知道”三个语法上独立完整的词,因此被界定为三词序列。频数为该长度序列在语料库中出现的次数,以语料库中该长度等级下所有序列的平均频数为准。
序列的抽取采用Antconc3.2.4软件中的n⁃gram功能,基于频数(50万词语料库中出现5次及以上)和文本分布(跨越5个及以上文本)标准进行自动抽取。再根据界定标准请多位母语使用者对抽取结果进行人工筛选核对,主要删去不符合要求的人名、地名、专业术语等,以确保处理结果的准确性。
本研究以长度(L)为自变量,频数(F)为因变量,运用SPSS16.0对二者关系进行回归分析、幂函数F=aLb(b<0)及F=aLbe-cL拟合度检验,以验证公式化多词序列长度和频数关系的假设。
四、研究结果
(一)汉语公式化序列长度对使用频数的影响
口语和书面语料中,汉语公式化序列长度和频数数据以及公式拟合结果如表1所列:
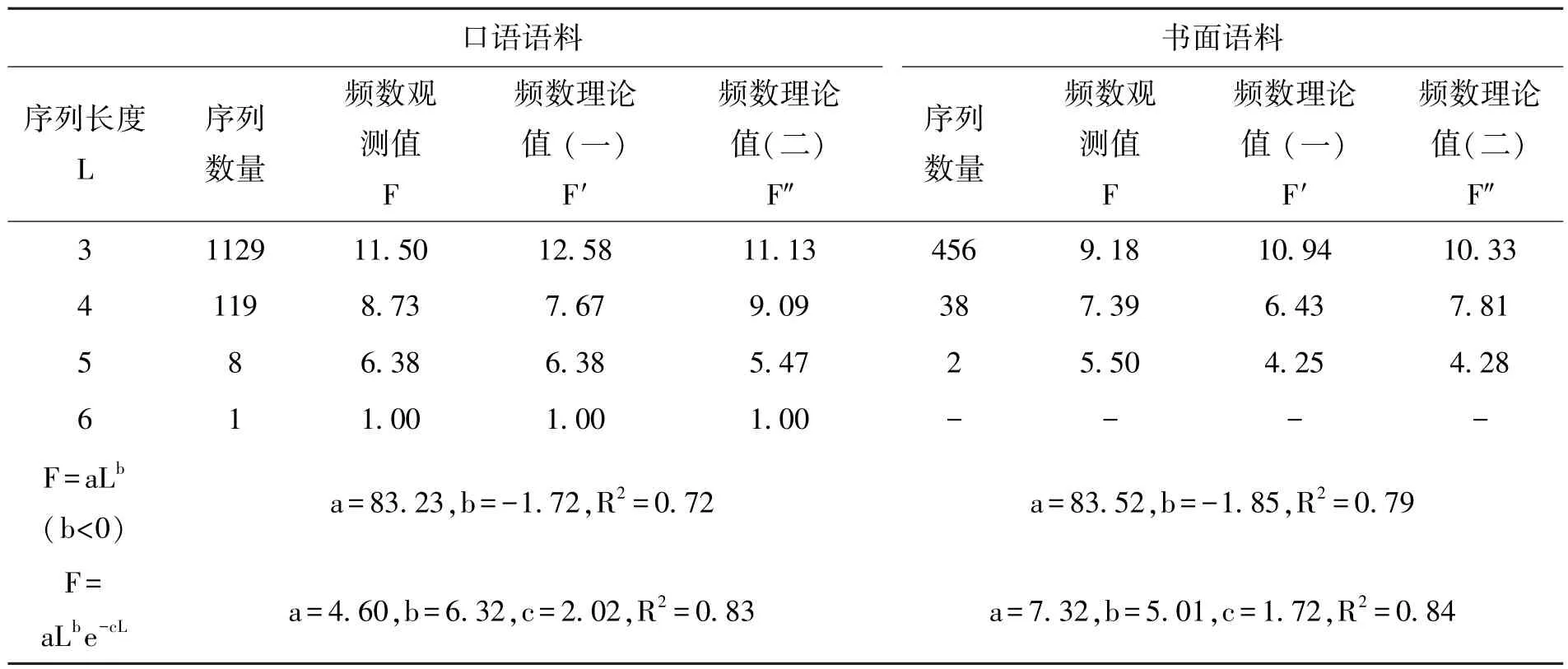
表1 序列长度和频数关系
表1中的数据统计结果显示,口语和书面语料中,长度较短的三、四词序列的总数量要远远高于五、六词的总数量。且随着序列长度增加,其使用频数呈现明显的下降趋势,在口语和书面语料中均有体现。书面语料库中,随着序列长度的增加,其平均使用频数从9.18下降到5.5;这一趋势在口语语料中则更加明显:从平均11.5次下降到仅出现1次。由此,研究假设得到证实,汉语公式化序列长度对其频数产生负影响,即长度越长,使用频数越低。
邓&冯[4]选取了1—4词的汉语词汇,对词长和词频关系进行了统计,同样发现了明显的负相关趋势(见图2中的词汇曲线)。将本研究所得的公式化序列曲线(见图2中的公式化序列曲线)与词汇曲线进行对比可以发现,随着长度的增加,序列使用频数变化的幅度要远远小于词汇。换言之,公式化序列的长度对其使用频数影响的显著性要小于词汇长度对词频的影响。其原因在于公式化语言不同于单个词汇的特征,具体留待讨论部分中再作详细解释。

图2 词汇/公式化序列长度—频数关系曲线对比(书面语/口语)
通过观察以上关系曲线发现,随着序列长度增加,其使用频数呈现非线性模式递减。因此,我们在序列频数统计的基础上,对长度和频数关系进行了回归分析,检验幂函数模型,与频数的观测值进行对比。
(二)长度和频数关系的数学模型拟合
图3和图4呈现了观测值(由点阵表示)和理论值曲线的拟合情况。总体来看,两个函数模型大致上符合观测值的变化趋势。其中,F=aLbe-cL函数提供的理论值更加接近观测数据。
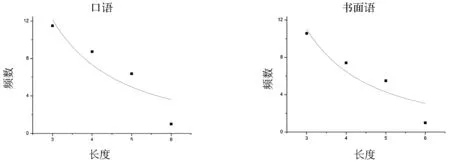
图3 频数观测值(一)和理论值(口语/书面语) F=aLb(b<0)

图4 频数观测值(二)和理论值(口语/书面语)F=aLbe-cL
由图3、图4和表1可知,幂函数F=aLb(b<0)和F=aLbe-cL在口语和书面语料库中的拟合效度相对都很高,且后者高于前者。这说明在口语和书面语中,幂函数F=aLbe-cL能更好地描述序列长度和频数的关系规律。其中,书面语中的拟合效度稍微高于口语语料。除此之外,就当前容量为100万词的汉语语料而言,幂函数 F= 4.6L6.32e-2.02L和 F= 7.32L5.01e-1.72L能够分别准确地预测口语和书面语中3—6词序列的使用频数。
(三)语域视角下的公式化序列
以跨语域的视角重新审视以上数据,我们能够发掘更多公式化语言的特征。公式化序列在汉语口语和书面语中均得到了高频率的使用,但在具体的数据统计上呈现了明显的差别。这些差别可以进一步追溯到不同语境特征和交际目的。
口语和书面语在语境上的区别使其对该语境下语言的使用产生不同的要求,主要体现在交际性(interactivity)以及交际模式(physical mode)两个方面[13]。书面语境中,语言使用者有相对充足的时间进行规划和修改;而口语语境则是即时和即兴的,说话人需要承受更大的语言处理压力,因而会倾向于诉诸更快、更为省力的途径。“整存整取、无需语法生产分析”的公式化语言便是这样一条节省语言处理精力的捷径。如表1数据所示,口语语料库中抽取的公式化序列数量远远多于书面语料库,并且前者各个长度等级下的序列使用频数均高于后者。通过大量使用公式化语言,可以使说话人在言语交际中节省消耗。这既是口语语境的要求,也是语言经济原则的体现。
就交际目的而言,在书面语境中,书写人的首要目的在于“传达新信息”,而说话人在口语语境中更倾向于以“交际”为目的,与听话人建立关系[13]109。Wray&Perkins指出,公式化语言除了语言加工优势以外,还可以起到凸显说话人目的、掌控对话的交际功能,以满足口语交际的要求[8]17⁃18。因此,公式化语言在口语语境中的使用频率更高。
五、讨论与总结
本文以协同理论为框架,采用数学计量方法,分析了汉语公式化多词序列长度对使用频数的影响规律。研究结果显示,汉语公式化多词序列的长度对其使用产生负影响,即序列越长,其使用频数越低。二者存在依存关系,并且可以进一步通过幂函数公式F=aLbe-cL准确描述。这一结果与Köhler等协同语言学家对于词长和词频关系的设想相同,也再次印证了语言机制运作中生成负担最小化(MinP)的系统要求。
这一结果不是对协同理论和模型的简单重复论证,研究表明长度和频数的协同关系不仅仅适用于词汇,还可以进一步拓展到多词序列的层面。这拓宽了原有理论模型的适用范围,揭示了语言规律的普遍性。
另外,本研究在探讨长度和频数关系规律的基础上,对汉语公式化语言自身的特征进行了考察。基于公式化序列“整存整取”,与单个词汇高度相似的特征,我们提出了研究设想:构建于词汇层面的词长—词频协同关系规律同样适用于公式化序列。研究结果显然证实了这一假设,从词长—词频关系的角度验证了公式化语言的“预制性”和“整体性”特征。
然而我们也发现,汉语公式化序列的长度—频数关系规律与汉语词汇有所不同。总体而言,序列的长度对其使用频数的影响显著性要低于词汇。邓&冯的研究结果揭示了语言经济原则在汉语词长和词频关系规律上的体现:词长一定程度代表了语言单位的复杂性,人类的惰性和大脑信息处理能力的有限性导致语言使用者在满足交际目的的前提下,倾向于选择短小简单的词汇来表达特定意义[4]37。然而,就公式化序列而言,首先,其本身就具有节省语言加工处理的优势。随着长度的累加,公式化序列并未产生明显的复杂性,因而长度对使用频数的影响也较小。其次,与意义完整的单个词汇不同,大部分公式化序列在结构和意义上具有不完整性,加之汉语在拆分组合上的高度灵活性,长度较短的序列可以任意地延伸拓展为长序列(如:就是说—也就是说,多的是—更多的是),序列长度增加的同时也是信息的叠加和补充。因此在语言交际和信息传递的要求下,语言使用者对序列长度的敏感性有所降低。
书面语和口语两个维度的对比分析揭示了口语语境下语言使用者对公式化语言的偏好。这一现象是由语境特征和公式化语言的特性共同决定的。另外,我们发现幂函数公式F=aLbe-cL对书面语料的拟合效度要稍高于口语语料。参数估计结果显示,参数a、b在不同的语体中有所区别。针对模型参数,有待于引入更多语体类别进一步研究其变化规律。
本研究充分体现和证实了协同语言学的核心思想:语言运作于一个“自调节、自组织”的动态系统。我们所观察到的语言现象和语言特征均可以通过数学模型来描述、解释甚至预测,以提取语言共性,形成严密的语言理论系统。本研究沿用了协同理论的词汇模型,得出其在汉语公式化序列上良好的拟合效度。为进一步精确描述公式化序列的长度—频数关系规律,后续研究可以基于更多的语料和语种数据进行拓展和补充,也可考虑结合开放性测试,构建更符合公式化语言的数学模型。
注释:
①“That the magnitude of words tends,on the whole,to stand in an inverse (not necessarily proportionate) relationship to the number of occurrences.” Zipf[1]25.
②DeCock等(1998)从英语语料库中抽取高频词组时发现:词组越长,使用频率越低。Hyland(2008)观察到了类似的现象:当学术写作中的序列扩展到五词及以上时,其使用频数大幅下降。
[1]Zipf G K.The Psycho⁃Biology of Language:An Introduction to Dynamic Philology[M].New York:Houghton Mifflin,1935.
[2]Miller G A,Newman E B,Friedman E A.Length⁃frequency statistics for written English[J].Information and Control,1958,1:370⁃389.
[3]Strauss U,Grzybek P,Altmann G.Word length and word frequency[C] //Grzybek (ed.).Contributions to the Science of Text and Language:Word Length Studies and Related Issues.Dordrecht:Springer,2007:277⁃294.
[4]邓耀臣,冯志伟.词汇长度与词汇频数关系的计量语言学研究[J].外国语,2013,36(3):29⁃39.
[5]DeCock S,Granger S,Leech G,et al.An automated approach to the phrasicon of EFL learners[C] //Granger S(ed.).Learner English on Computer.London & New York:Addison Wesley Longman,1998:67⁃69.
[6]Bolinger D.Meaning and memory[J].Forum Linguisticum,1979,11:1⁃14.
[7]Wray A.Formulaic Language and the Lexicon[M].Cambridge:Camberige University Press,2002.
[8]Wray A,Perkins M R.The functions of formulaic language:an integrated model[J].Language & Communication,2000,20:1⁃28.
[9]Biber D.A corpus⁃driven approach to formulaic language in English:Multi⁃word patterns in speech and writing[J].Interna⁃tional Journal of Corpus Linguistics,2009,14(3):275⁃311.
[10]Wray A,Namba K.Use of formulaic language by a Japanese⁃English bilingual child:A practical approach to data analysis[J].Japan Journal of Multilingualism & Multiculturalism,2003,9:29⁃32.
[11]Köhler R.Synergetic linguisrics[C] //Köhler R,Altmann G,Piotrowski G (eds.).Quantitative Linguistics.Berlin/New York:Walter de Gruyter,2005:760⁃774.
[12]Altmann G.Prolegomena to Menzerath’s law[J].Glottometrika,1980,2:1⁃10.
[13]Biber D,Conrad S.Register,Genre and Style[M].Cambridge:Cambridge University Press,2009.
A Synergetic Approach to the Relationship between the Length and Frequency of Chinese Formulaic Sequences
DAI Xueting,LIANG Yizhou,QU Yunhua
(School of International Studies,Zhejiang University,Hangzhou 310058,China)
The present paper adopts a corpus⁃driven approach to explore the relationship between length and frequency among Chinese lexical bundles,in an attempt to test whether the synergetic model/formula constructed at the lexical level can extend its applicability to multi⁃word formulaic sequences.The results in⁃dicate that the length of Chinese lexical bundles exerts a negative influence on its frequency of occurrence.Power function F=aLbe-cLcan adequately describe this regularity.Based on the length⁃frequency relationship,this research shall prove universal language rules by testing and extending the scope of synergetic theory.It will also identify the characteristics of formulaic language through register analysis.
Chinese lexical bundles;length;frequency;synergetic linguistics;register
H030
A
2095-2074(2016)06-0024-08
2016-05-12
戴雪婷(1993-),女,浙江台州人,浙江大学外国语言文化与国际交流学院硕士研究生;梁怡洲(1992-),女,浙江台州人,浙江大学外国语言文化与国际交流学院本科生;瞿云华(1961-),女,浙江杭州人,浙江大学外国语言文化与国际交流学院教授,博士生导师。
