一种基于复合稀疏表示的阿尔茨海默病的诊断方法*
2016-10-18滕升华商胜楠王芳赵增顺
滕升华,商胜楠△,王芳,赵增顺,2
(1.山东科技大学电子通信与物理学院,青岛 266590;2.山东大学控制科学与工程学院,济南 250061)
1 引 言
对阿尔茨海默病(Alzheimer′s disease,AD)及其前期阶段——轻度认知障碍(mild cognitive impairment,MCI)的计算机辅助诊断一直是神经影像分析领域的研究热点,目的是利用计算机分析方法处理脑影像数据实现对患者的精确诊断。迄今为止,许多模式识别和机器学习方法被开发并应用于辨别AD、MCI和正常群体(normal control,NC)[1-3]。
在此类神经组织退化疾病的诊断中,常用到结构性脑影像数据如磁共振图像[4]。由于脑影像数据通常维数非常高,因此,不宜直接在原始图像域进行类别分析,而是通过特征提取和特征选择,最终在低维空间实现分类。在众多分类方法中,支持向量机因分类精度高且应用简便而被广为采用[5-6]。然而对于脑影像等高维、含噪数据支持向量机的分类性能则会显著下降[7]。
近年来,基于稀疏表示的分类方法逐渐受到重视[8-10]:将各类别的训练样本混合起来组成字典,根据字典以稀疏表示的形式重建待识别样本;在对待识别样本的稀疏表示中,各类别的训练样本贡献不同,识别结果判定为在稀疏表示中贡献最大的类别。
基于稀疏表示的分类机理是寻找能够最好地表示待识别样本的类别,默认前提是样本能且仅能被同类样本精确地表示。但是如果训练样本构建的字典是非完备的,某些待识别样本不能被训练字典精确地表示,相应地可能会得到错误的分类结果。因此,稀疏表示分类器的识别能力受限于字典表示未知样本的能力,对于特征维数高而训练样本数量相对较少的情形更是如此。
增强字典的表示能力是优化稀疏表示分类器的有效方法,由此产生了一些改进的稀疏表示分类器。有研究者提出引入类内差异构造增强型的字典[11],或者采用字典学习得到可分性更强的字典[12-13]。这些改进方法是计算机视觉领域中专为人脸识别而设计的,并不适用于数据维数相对更高而训练样本数量更少的AD诊断。
构造增强字典用到的类内差异[11]是指同类样本之间的差别,被认为包含了一定成分的样本细节信息。本研究首先对各类样本进行聚类,得到若干子类中心,以这些子类中心而非原始样本构建第一层字典;计算每个样本与最近子类中心的差作为类内差异,构建补充性的第二层字典。两层字典联合起来对待识别样本进行稀疏表示,实现一种基于复合稀疏表示的分类器,并通过实验验证该分类器用于诊断阿尔茨海默病的有效性。
2 方法
常规的稀疏表示分类器首先将待识别样本表示成包含所有类别训练样本的线性组合,通过计算在此联合表示中每类训练样本对待识别样本的表示结果,最终将待识别样本判定为表示误差最小的类别。改变字典结构或者利用不同的稀疏表示形式会产生不同的稀疏表示分类器。
类似于图像分解,将图像表示成主体结构和纹理信息之和,本研究利用混合稀疏表示将待识别样本分解为两层内容:与类别相关的主体结构和与类别无关的通用细节,根据各类别主体结构在联合稀疏表示中的贡献量实现分类。
2.1 常规稀疏表示分类器[9]
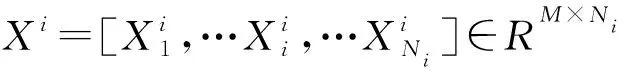
(1)
依据上式的表示系数,分别计算独立利用每类样本表示待识别样本y的误差。
(2)
将y判定为表示误差最小的类别。
Label(y)=arg miniri(y)
(3)
2.2 构建双层字典
常规的稀疏表示分类器利用原始形式的训练样本构造字典,该方法在人脸识别中的应用表明:精心选择训练样本而且每类的样本数量都足够多,稀疏表示分类器能够实现较好的识别效果。然而对于实际的AD分类问题,相对于脑影像数据的高维度,训练样本数量明显不足。因此,在常规的稀疏表示框架下,现有的训练数据不足以精确地表示待识别样本。
也正如人脸识别中同一个人的不同图像之间可能存在明显的表情、光照、妆扮等差异,而这些细节因素并非决定类别的关键,直接堆砌训练样本会降低稀疏表示的分类精度。在AD分类中即使同类的脑影像数据之间通常也会表现出显著的个体差异,为对样本进行筛选,本研究利用聚类方法得到各类的若干子类,进而挑选出每类的若干典型样本构成基础字典。
另一方面,挑选样本会减小字典规模,进一步降低字典对未知样本的表示能力。为此,利用样本间的差异构成补充性字典,对基础字典在表示待识别样本时的误差进行编码,最终实现对待识别样本的精确表示。文中采用基础字典加补充性字典的双层字典模式。
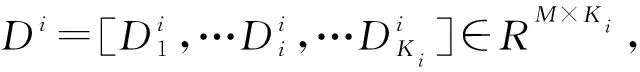
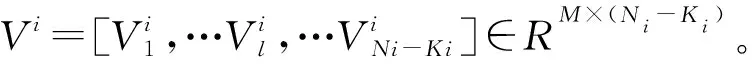
2.3 基于复合稀疏表示的分类方法:
利用双层字典D+V,待识别样本y可以表示为
y=Dα+Vβ+e
(4)
其中α和β是系数向量,e是表示误差。利用L1范数最小化计算稀疏表示系数(λ1、λ2是调节稀疏程度的参数):
(5)
采用增广拉格朗日乘子法(Augmented Lagrange multiplier,简称ALM)[15]进行求解,得:
(6)

求解公式 (6)的ALM算法:输入:D、V、y、λ1、λ2初始化:α=0,β=0,ϕ=0, ξ=1,ξmax=104,ρ=1.5,ε=10(-4)While ‖y-Dα-Vβ‖22>εdo1.固定其他参数更新αα=arg minαξ2‖(y-Vβ+1ξϕ)-Dα‖22+λ1‖α‖12.固定其他参数更新ββ=arg minβξ2‖(y-Dα+1ξϕ)-Vβ‖22+λ2‖β‖13.更新拉格朗日乘子ϕ=ϕ+ξ(y-Dα-Vβ)4.更新参数 ξ=min(ξmax,ρξ)end输出:α,β
在基于双层字典的复合稀疏表示中,第一层字典存储区分类别的主体结构信息,第二层字典提供补充性细节,以弥补仅用第一层字典表示待识别样本的信息缺失。稀疏表示分类器根据各类别的表示误差决定类别归属,因此计算表示误差除利用对应类别的第一层字典元素之外、还可共用所有类别提供的类内差异。
表示误差定义为:
(7)
同样依据公式(3),类别标签取最小的ri(y)对应的类别。
3 实验内容与结果
利用本研究提出的复合稀疏表示分类器(hybrid sparse representation based classifier,HSRC)针对取自ADNI(Alzheimer’s Disease Neuroimaging Initiative,ADNI)数据库的磁共振影像进行分类实验,并与支持向量机[5](support vector machine,SVM)、稀疏表示分类器[9](sparse representation based classifier,SRC)及基于多分类器集成的稀疏表示分类器[7](ensemble sparse representation based classifier,ESRC)进行比较。采用文献中常用两类别分类实验,具体包括AD-NC分类、MCI-NC分类。
实验中共采用了652个样本,包括198个AD、225个MCI和229个NC。在大脑的磁共振影像中,相对于白质和脑脊液,灰质部分与AD的诊断相关性更强[7],因此,以验证算法的有效性为目的,本研究仅使用灰质密度作为样本特征。
灰质密度图的维数是256×256×256,为减少数据量将其下采样变为64×64×64。利用t-检验对全脑体素进行筛选以去除与分类任务相关性弱的体素,取P值大于0.005的体素构成最终的特征向量。公式(6)中调节两层字典稀疏度的参数分别取λ1=0.1,λ2=0.001。这两个参数的选择借鉴了文献[13]的处理思路,本研究中采用稀疏与稠密相结合的表示方式;本研究中λ1取值较大强化与类别相关的第一次字典在联合表示中的稀疏性以利于分类,同时认为第二层字典不包含类别信息而使λ2取较小值以更精确地表示待识别样本。实验中发现只需遵循λ1取值相对较大、λ2取值小的设置,实验结果对二者数值的变化并不敏感(比如λ2取0.001还是0.002几乎不影响识别结果,这也体现了算法对参数选择的鲁棒性)。
3.1 AD/NC分类实验
实验数据是198个AD样本和229个NC样本,利用10交叉验证评估最终的识别结果。复合稀疏表示分类器HSRC与SVM、SRC、ESRC的识别结果见表1。与其他三种方法相比,HSRC表现出了更好的分类性能,准确率、灵敏度、ROC曲线下面积等指标数值最高;为了达到最佳的综合性能,特异度指标稍低。图1为几种方法ROC曲线的对比,可以看出HSRC综合性能最优。
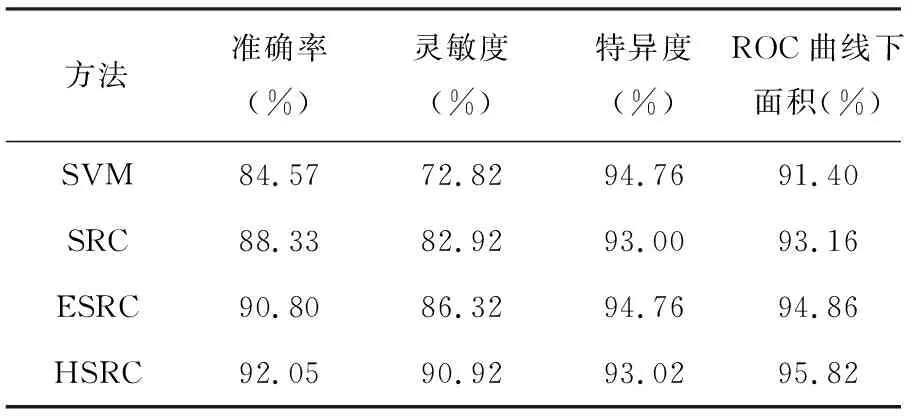
表1 AD/NC分类的性能比较

图1 AD/NC分类中四种方法的ROC曲线
3.2 MCI/NC分类实验
该实验比较不同方法对225个MCI样本和229个NC样本的分类性能,结果见表2。同AD-NC分类结果一致,本研究提出的方法对应的准确率、灵敏度、ROC曲线下面积等三个指标数值最高,综合性能最优,ROC曲线见图2。

表2 MCI/NC分类的性能比较
4 结论
对于高维小样本的识别问题,原始形式的训练样本不足以精确地表示待识样本,从而造成常规稀疏表示分类器性能下降。将稀疏表示中的字典分解为功能不同的两个层次:第一层由各类经聚类筛选出的典型样本组成,以期在字典中排除离群样本又保留类别间的可分性特征;第二层字典的元素是各类中普通样本与典型样本的差,这种类内差异体现了同类样本内部的个体多样性、而不携带显著的类别区分性信息。
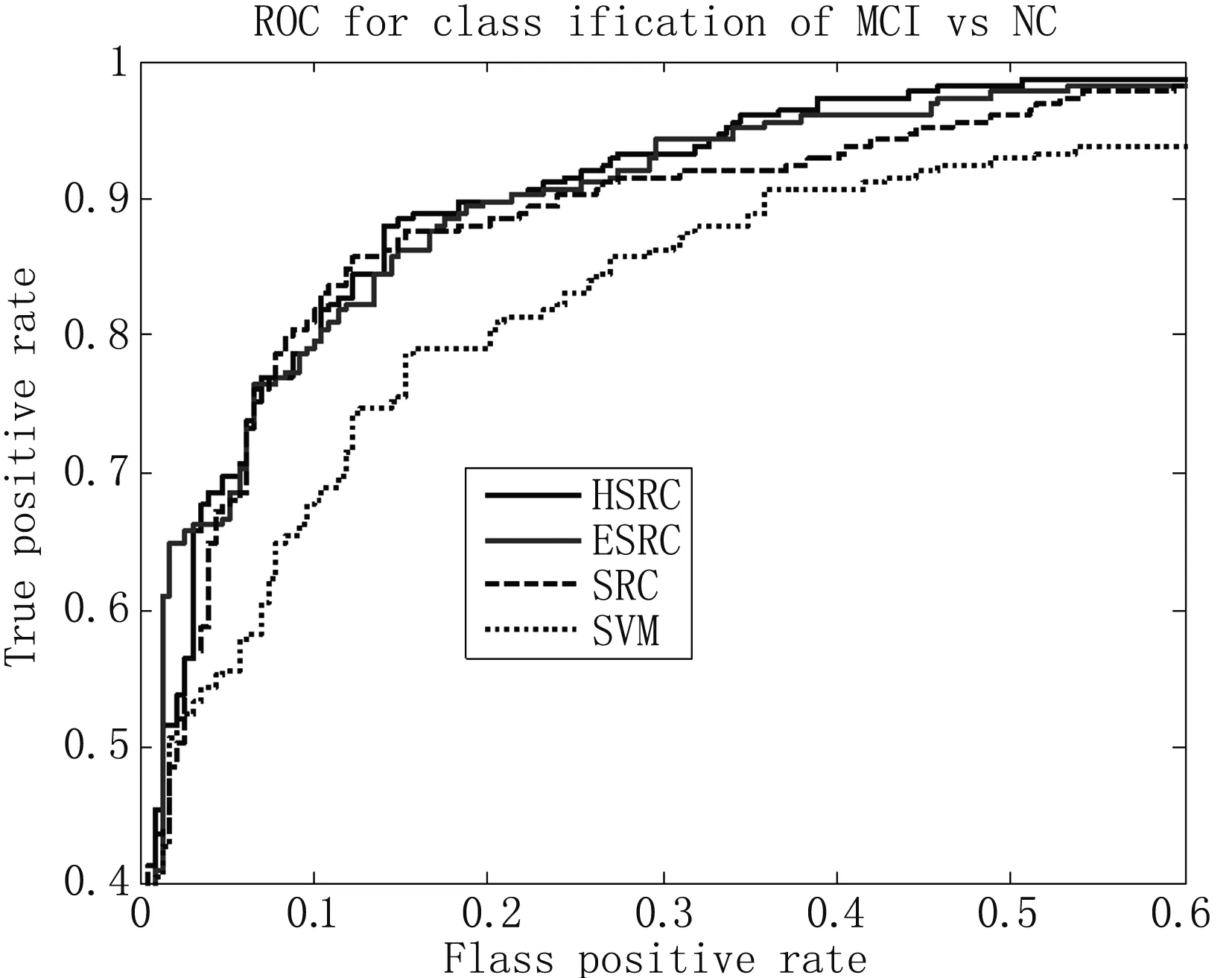
图2 MCI/NC分类中四种方法的ROC曲线
基于两层字典的协同工作,设计了一种复合稀疏表达形式,并构建分类器用于阿尔茨海默病的计算机辅助诊断。在ADNI数据库上的分类实验结果表明,与常规稀疏表示分类器及支持向量机相比,这种复合稀疏表示分类器的识别能力更强。
最后需要特别指出,本研究的主要贡献是设计了适用于阿尔茨海默病诊断的复合稀疏表示分类器,为与其他分类器进行比较仅利用灰质密度作为样本特征。后续工作中将该分类器推广到多模态及纵向脑影像数据,并融合特征选择、多分类器集成等策略能进一步提高相关疾病计算机辅助诊断的准确率和可靠性。
