大数据时代基于DBSCAN聚类方法的审计抽样
2016-09-23程平陈珊
程平 陈珊
大数据时代基于DBSCAN聚类方法的审计抽样
程平陈珊
高度信息化的大数据时代,导致企业的生产经营产生大量、分散、复杂的会计数据,在审计全覆盖无法实现的情况下,审计抽样的质量至关重要。针对现有审计抽样问题,本文提出了在已有的审计领域知识库的基础上,建立审计样本与审计目标的关联规则,并利用DBSCAN聚类算法对审计抽样关联规则进行聚类,接着对聚类结果进行新颖度评价,筛选出高价值聚类结果存入审计领域知识库,实现审计领域知识的积累和再利用。最后,运用审计实例对实验进行分析。
大数据审计抽样聚类关联规则
21世纪是一个高度信息化的大数据时代,信息经济和知识经济占据了主导地位。企业为了提高管理水平,信息化应用越来越深入已经成为企业管理与业务运行的神经系统。云会计(程平,2011)等AIS系统虽然能够帮助企业获取与其经营活动相关的各种结构化、半结构化和非机构化的数据,但是如此大规模、大数量、大范围的数据信息,给大数据时代下的审计抽样带来了不小的挑战。如何在此环境下实现审计目标、提高审计抽样的质量本文就此展开探讨。
一、大数据时代的审计抽样
2015年,国务院印发《关于加强审计工作的意见》,第19条明确提出:探索在审计实践中运用大数据技术的途径,加大数据综合利用力度,提高运用信息化技术查核问题、评价判断、宏观分析的能力。随着大数据时代的来临,许多被审计单位的数据越来越呈现出海量化的趋势,不少单位已建立起TB甚至PB级的数据库。云会计AIS软件功能和规模的不断壮大,以及基于云计算的软件开发环境和大数据环境发生的深刻变化,使得企业的财务数据不仅数量愈加庞大,复杂程度也呈现前所未有的高度。其实,大数据审计的最终目标是实现数据全覆盖,但是就目前的技术水平以及审计数据的复杂程度来看,短时间内难以实现。审计抽样作为计算机审计的一个至关重要的模块,在国内刚刚起步。
近几年来,针对大数据时代的审计做了不少研究。秦荣生(2014)分析了大数据、云计算技术对审计的影响,并且针对相关问题给出了应用的建议。顾洪菲(2015)根据大数据的特点,从数据量、数据结构、数据处理方式三个方面分析大数据环境下进行审计数据分析所需的技术要求,从分析学和使用者的角度阐述了大数据环境下进行审计的数据分析方法和分析结果的显示需求。陈新华(2010)对时间抽样法这种非概率抽样方法进行了介绍,具体分析了样本选择和样本量两个基本内容。王海霞(2014)分析了聚类技术及其对电子政务审计的意义,结合电子政务抽样审计中对多维数据进行分层的需要,提出将基于主次属性划分的聚类方法用于分层算法之中,以适应多维数据分层抽样的需要。
纵观现有研究发现,面对当今企业面临的数量庞大、种类繁多的数据,要通过审计抽样方法实现审计目标,最优的方案莫过于利用数据挖掘技术。基于概率和数理统计理论的审计抽样在计算机软件的辅助下,则可以在保证科学性的前提下,有效地提高审计效率并降低审计成本。然而,现有的研究虽然也有这方面的考量,却忽视了领域知识和审计样本与审计目标间的关联规则对审计抽样结果的影响。基于此,本文主要研究在获取审计领域知识之后,针对审计目标对审计业务进行聚类、抽样算法的研究,并带入实际业务数据进行应用研究和检验其可行性。
二、基于DBSCAN聚类方法的审计抽样方法
(一)基于聚类算法的审计抽样流程
基于领域知识的审计样本聚类过程是对挖掘出的审计样本与审计目标间的关联规则进行聚类分析,而后对聚类后的审计关联规则进行审计抽样并且利用审计结果进行新颖度分析筛选出审计规则中高价值、高可信的规则,其过程如图1所示。
基于领域知识的审计样本聚类过程,是在建立基于云会计AIS审计领域知识库的基础上,建立审计样本与审计目标之间的关联规则,并最终形成基于云会计AIS审计知识关联规则库。然后,采用基于密度的聚类算法DBSCAN对审计规则进行聚类。针对聚类之后的结果,又有如下两个方面的处理:一是完成对聚类后的结果进行随机抽样,完成审计抽样的流程;二是对聚类后的结果进行新颖度的评价,根据实际应用情况设计阈值选取有价值的规则存储于审计领域知识库中,用以引导下次的审计规则挖掘过程,这就使得新的审计规则能够实现审计领域知识的积累和再利用。
(二)基于DBSCAN的审计关联规则聚类算法
总体上,规则聚类对聚类算法并没有特殊的要求。现有的大部分聚类算法,如K-means,BIRCH,CHAMELEON,OPTICS等算法均可实现规则的聚类。在传统的聚类算法中,没有一种聚类算法可以保证应用于各类样本空间分析中并保证较好的性能,每一种算法都有自己的特点和应用范围,只有根据具体实际应用去选择合适的聚类算法。鉴于存在于网络虚拟环境审计数据数量巨大、复杂,本文选择基于密度的聚类算法DBSCAN(Density-Based Spatial Clustering of Applications with Noise)用于基于云会计AIS审计抽样聚类。
DBSCAN算法由Ester等人最早提出。它是利用类的高密度连通性,快速发现任意形状的簇。其基本思想是:对于簇中的每个数据点,在给定的半径(用Eps表示)的邻域(neighbor-hood)内包含的数据点数目必须不小于某一给定值(用minPts表示)。如图2为基于DBSCAN聚类方法的关联规则聚类过程图。
基于DBSCAN聚类方法的审计关联规则聚类过程是:首先输入审计关联规则库,半径e和阈值MinPts,检查审计规则R是否为小于阈值MinPts的核心规则。如果审计规则R是核心规则,那么就开始创建初始的类S,S中包含审计规则R及其R直接密度可达的所有审计规则,也就是包含审计规则R及其e-领域内的所有审计规则。然后,判定该领域中的每一条审计规则是否为核心规则。如果都是核心规则,那么将其e-领域内尚未包含在类中的所有审计规则追加到S中,并继续判定这些新加进到类S中的审计规则是否为核心规则。如果是核心规则,则继续进行以上的追加过程,直到没有新的审计规则可以追加到S中。
三、审计规则的积累与再利用
为了实现对每次审计抽样过程中新挖掘的审计规则的积累与利用,需要对审计关联规则进行新颖性的评价。
关联规则的新颖性是针对与原有的知识而言,这些知识包括两部分:一部分是以往得到的准确性很高的关联规则,与这些知识相悖的关联规则可能说明以下几种情况:一是形成这条关联规则的数据有问题,这条规则是错误的;二是这条规则是对原有规则的一个修正,可以与原有的知识结合形成一条具有更多约束的新的规则;三是否定了原有的规则,说明使原有知识成立的前提条件已经不存在了,以后的证据已不足以支持原有规则的成立,从而相悖的新发现的规则取代了它。也就是对这种发现的规则是不同的情况进行不同的处理。另一部分是与用户的期望相悖,这样有利于帮助用户找到影响期望情况出现的因素,从而可以采取一定的措施阻止这些因素的出现。衡量主要是从形式上,即分别与关联规则的前件和后件的相悖程度来衡量。可用与原有知识相悖的项数来衡量。
由此,新颖性程度分别表现在发现的规则与基础知识库(主要存放专家输入的领域知识和用户已知的一些规则)中的规则的各项差异程度上,分别表现在前件各项的差异和后件各项的差异上(分别从语言变量和同一语言变量的不同语言值的角度)。此外前件和后件也分别看待。
设审计知识库里的审计规则组成的集合为R,审计知识库中的规则集合为A。A中的审计规则个数为|A|,R中的审计规则数为|R|。
设Wi为R中的审计规则Ri与A的新颖度,W(i,j)是规则Ri与原始审计知识库中的规则Aj之间的新颖度即差别程度。W(i,j)包含两部分,前件的新颖度L(i,j)和后件的新颖度Z(i,j)。
1.计算L(i,j)
设原始审计知识库中的审计规则Aj中所有前件的语言变量组成的集合为J。并且R中审计规则Rj的所有前件的所属的语言变量组成的集合为I。
对I中的任一项Ik,记V(i,j)k为这一项与审计规则Rj的差异程度,则有
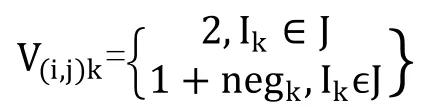
negk为I中的第k项的语言值与J中同一语言变量对应的语言值之间的差异程度。前面加1是为了避免当所有项都在J中出现并且对应语言均值相同时,会出现0的情况。
这样前件的新颖度等于:
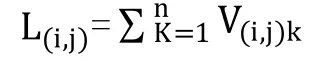
2.计算Z(i,j)
经过规则简约后,原始审计知识库中所有规则后件的项数均为1,同时通过数据挖掘算法得到的规则后件的项数也为1。所以新发现的审计规则Ri与审计知识库中的任一条规则Aj在后件上只有下面两种可能关系:
一是两条规则的后件属于同一个语言变量,这时首先计算两者的语言值对应的矛盾度,则Z(i,j)=1+neg;加1的目的是为了避免当后件是同一个语言变量的相同语言值时出现0的现象。
二是两条规则的后件不属于同一个语言变量,这时令度量后件差异的数值记为2,即Z(i,j)=2。
3.计算W(i,j)
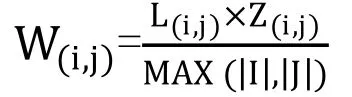
4.计算Wi

通过以上模型的筛选,衡量了新规则与审计领域知识库中的规则的各项差异程度,根据实际应用情况设计阈值选取有价值的规则存储于审计领域知识库中,用以引导下次的审计规则挖掘过程,这就使得新的审计规则能够实现审计领域知识的积累和再利用。
四、基于领域知识和聚类的审计抽样实例分析与结果
下面选取某在美国上市生产太阳能多晶硅片为主营业务的集团企业合同审计项目为例。合同审计是指内部审计机构和人员对合同的签订、履行、变更、终止过程及合同管理进行独立客观的监督和评价活动。该集团企业的不同的部门、业务类型、合同金额和授权级别都是会影响该合同是否有效的重要因素,表1为截取的部分合同审批权限。
如表2所示,为通过本体论的方法获取的初始审计领域规则知识库,并结合该集团公司的合同审计制度建立的部分审计规则。其中,M代表金额,P代表管理职位,D代表部门,B代表业务类型,R代表风险程度,C代表控制点。在建立规则的基础上,运用DBSCAN聚类的方法,对本审计规则库进行聚类。但是值得注意的是,从表中可以看出,规则后件为No的审计规则,在实验中应该不参加聚类,因为如果筛选出的审计样本属于此种规则,那么说明这项业务就有问题。在审计过程中,如果遇到有问题的样本,必须全部抽取出来详细清查,所以就不参与后面的聚类。这样不仅提高了审计的质量,也可以减轻后期参与聚类的审计规则的数量。根据对规则的聚类,R3和 R16聚为一类C1,R4、R11和R15聚为一类C2,R9和R19聚为一类C3,R5和R18聚为一类C4。
针对本次合同审计的具体内容,通过决策树4.5挖掘算法,得到了如表3所示的新审计规则。由于已对审计领域知识库和新规则集分别聚类并对应,因而在计算新规则新颖性时不必将新规则与领域知识库中的规则逐条比较。而只要比较同一类中的领域知识,对于成熟的大规模领域知识库来说,聚类后的规则比较将大大提高算法效率。
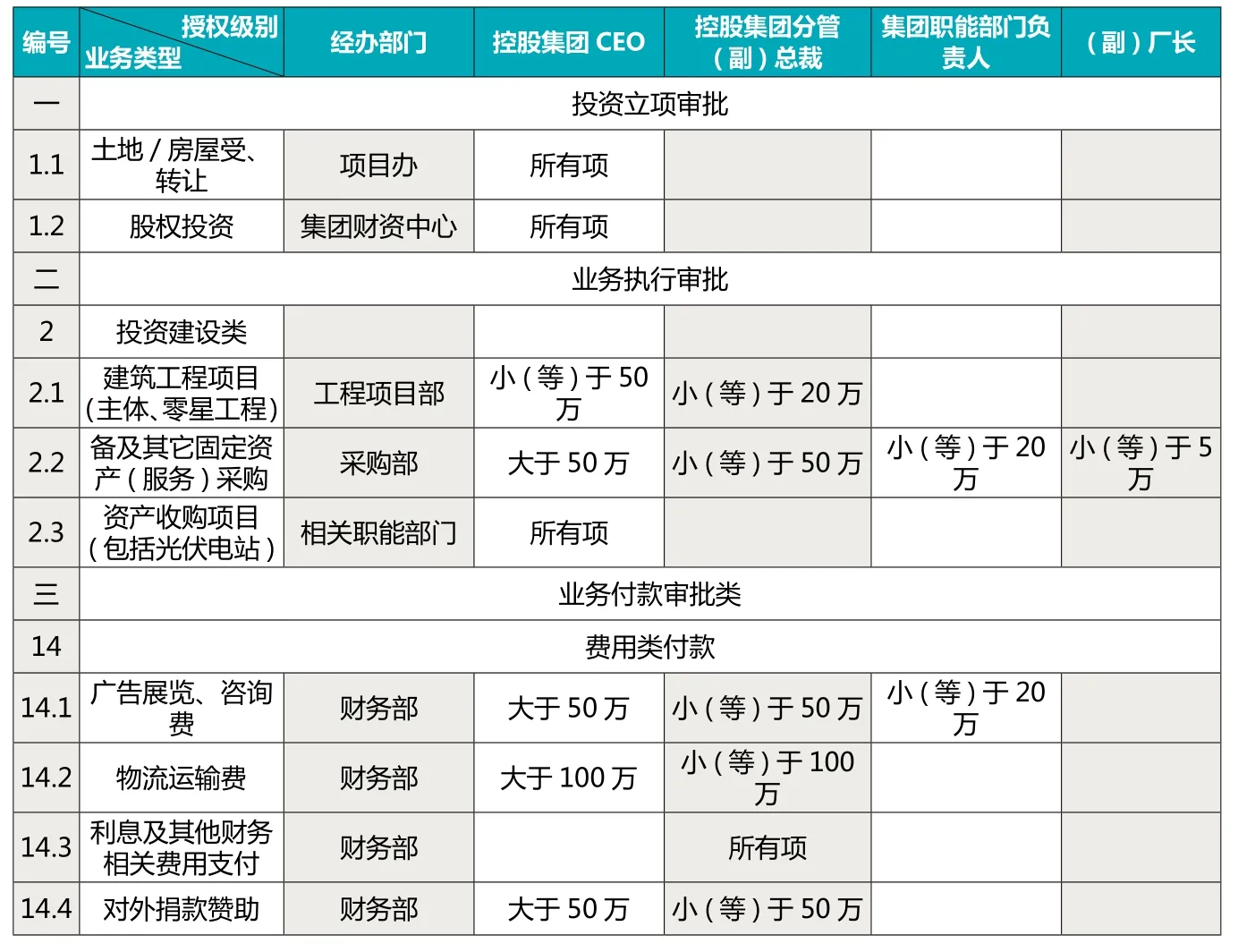
表1 审批权限表
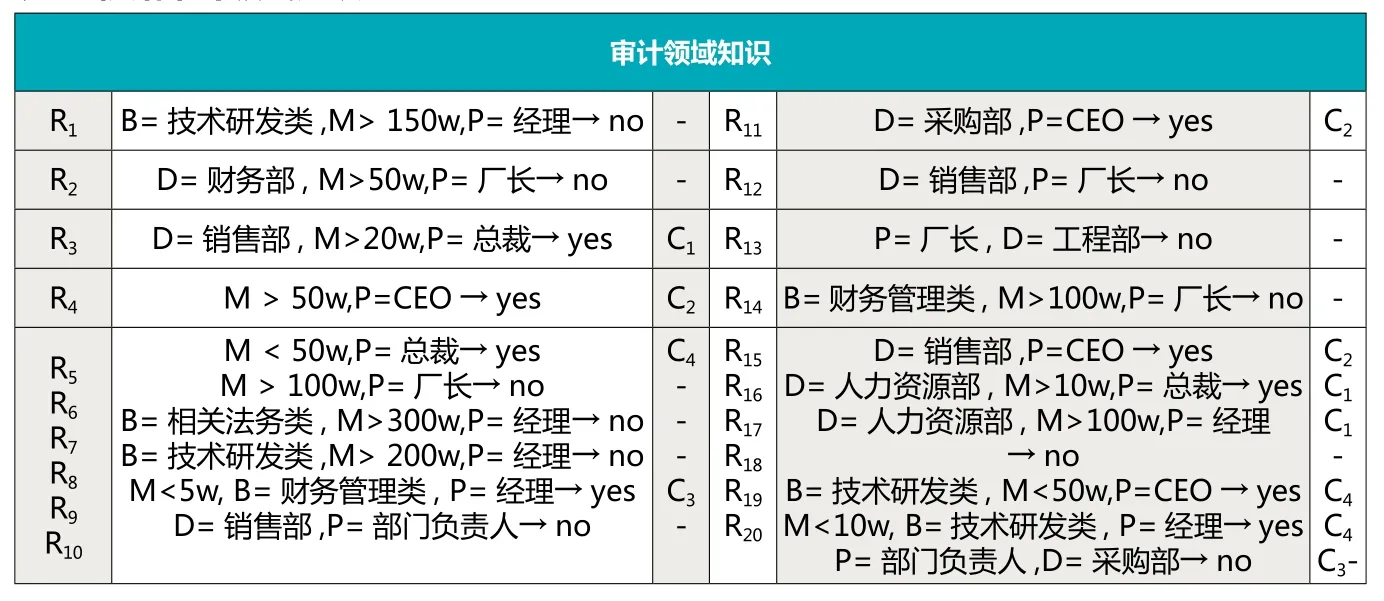
表2 初始审计领域知识
如表4所示为新审计关联规则的新颖度评价,每一大类中的新规则都计算出了规则新颖度,而如何确定选取规则新颖度的阈值则需要依据实际情况而定。在本例中,可以看出新颖度小于0.5的规则与原审计领域知识重复性较大或者说是原审计领域知识的子集,应当予以删除,而将剩余的有价值规则按大类存入领域知识库中。

表3 新审计关联规则集
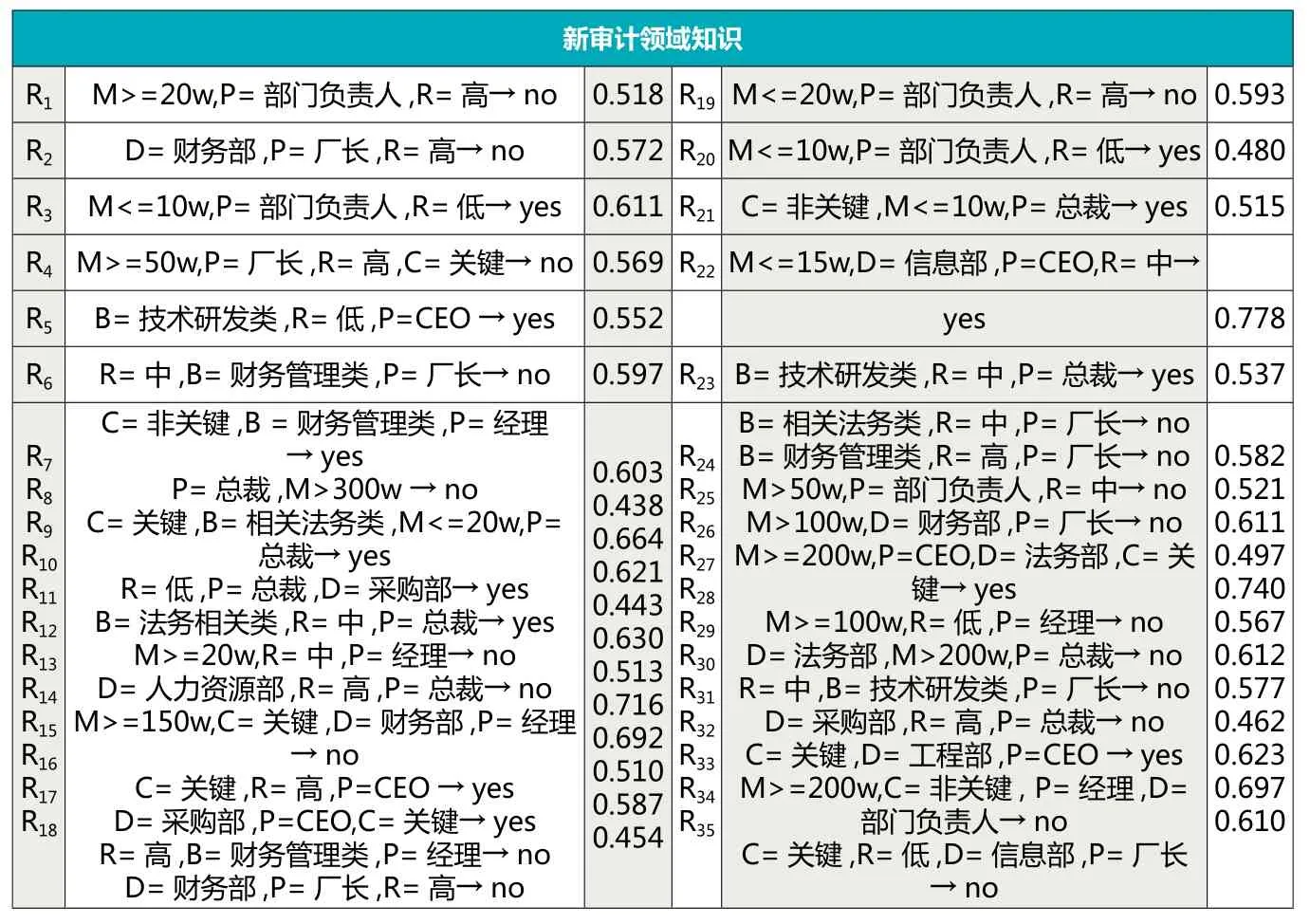
表4 新审计关联规则新颖度
本例中,在利用本体论建立企业的原始审计领域知识库的基础上,通过DBSCAN聚类的方法,将原始审计领域知识规则分为C1、C2、C3、C4这4类。接着,利用决策树4.5挖掘算法,针对当前审计要求,挖掘出了新的审计规则,并依照原始的分类进行聚类。在得到以上聚类之后,对属于本项规则的合同项进行随机抽样,完成审计抽样的流程。同时,对新挖掘出的审计规则进行新颖度的评价,将新颖度高的审计规则存入到审计领域知识库。
通过本次实例可以看出,基于领域知识和聚类的审计抽样对大数据时代下基于云会计的审计业务意义重大。通过计算机软件的辅助, 基于领域知识和聚类的审计抽样可以在保证科学性的前提下,不仅可以有效地提高审计质量与审计效率,同时还可以降低审计成本。
五、结语
本文在获得审计领域知识的基础上,建立审计样本与审计目标之间的关联规则,并形成审计知识关联规则库。然后,采用DBSCAN聚类的方法,对审计关联规则库进行聚类,在利用挖掘算法挖掘针对本次审计项目的新审计规则,对比原始审计知识库,筛选出新颖度较高的储存于审计知识库,以便以后审计项目的实施再利用。最后,以某在美国上市的生产太阳能多晶硅片企业的合同审计项目为例,验证了大数据时代基于领域知识和聚类的云会计AIS审计抽样的有效性。
作者单位:重庆理工大学
主要参考文献
1.程平,何雪峰.“云会计” 在中小企业会计信息化中的应用.重庆理工大学学报(社会科学版).2011(1)
2.秦荣生.大数据、云计算技术对审计的影响研究.审计研究.2015(06)
3.顾菲洪.大数据环境下审计数据分析技术方法初探.中国管理信息化.2015(03)
4.陈新华,胡桂华.一种非概率审计抽样方法:时间抽样法.财会月刊.2010(7)
5.王海霞,多维数据聚类技术在电子政务审计分层抽样中的应用研究.商业会计.2014(01)
6.夏锋,基于聚类方法的审计分层抽样算法研究.计算机应用与软件.2008(01)
国家自然科学基金青年项目(批准号:71201179);教育部人文社会科学基金青年项目(批准号:12YJC630025);重庆市教委科学技术研究项目资助(批准号:KJ1400905);重庆理工大学财会研究与开发中心科研创新重大项目(批准号:14ARC101);重庆理工大学研究生创新基金项目(批准号:YCX2015105)
