基于属性加权核密度估计的朴素贝叶斯分类算法
2016-09-08谢小军陈光喜丁伯伦
谢小军,陈光喜,丁伯伦
(1.桂林电子科技大学 数学与计算科学学院,广西 桂林 541004;2.安徽工程大学机电学院,安徽 芜湖 241000)
基于属性加权核密度估计的朴素贝叶斯分类算法
谢小军1,陈光喜1,丁伯伦2
(1.桂林电子科技大学 数学与计算科学学院,广西 桂林541004;2.安徽工程大学机电学院,安徽 芜湖241000)
为了削弱朴素贝叶斯分类算法的属性条件独立性假设,提出了一种属性加权核密度估计的朴素贝叶斯分类算法。该算法结合条件属性与决策属性的相关系数以及互信息得到新的属性加权值,并将该加权值嵌入核密度估计的朴素贝叶斯分类算法。实验结果表明,该算法提高了分类准确率。
属性加权;核密度估计;朴素贝叶斯;分类
分类是数据挖掘的核心之一。分类算法的目的是构造分类模型,该模型通过分析训练样本数据建立分类模型,并对未知类别的数据进行分类预测。朴素贝叶斯算法由于计算高效、精度高,被广泛应用于模式识别、垃圾邮件处理、故障检测、自然语言处理、机器人导航等领域[1-4]。朴素贝叶斯算法的前提是在给定分类特征的条件下属性之间相互独立,而现实中常常不能满足属性独立性假设。针对此问题,研究人员做了大量的研究工作。文献[5-8]分别使用粗糙集属性重要度、属性之间互信息、属性之间相关系数、分类概率建立了加权朴素贝叶斯分类模型。文献[9]提出了一种基于加权核密度估计的半朴素贝叶斯分类模型,采用最小二乘交叉验证方法选择最优加权值。文献[10]提出了一种新的加权核密度估计的朴素贝叶斯算法,该算法利用属性之间互信息,对分类属性进行属性加权,并结合核密度估计方法,减弱了朴素贝叶斯算法的属性独立性假设。
鉴于此,基于属性加权[11],提出了一种新的加权核密度估计的朴素贝叶斯分类算法。该算法通过计算条件属性与决策属性的相关系数,并结合互信息作为新的属性加权值,然后将属性加权值嵌入到核密度估计方法,以提高朴素贝叶斯算法的分类性能。
1 朴素贝叶斯分类算法
(1)
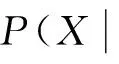
(2)
假设测试实例t=〈a1,a2,…,an〉,朴素贝叶斯分类算法得到实例t的类别预测为:
(3)
2 加权的朴素贝叶斯分类模型
朴素贝叶斯算法在实际中难以满足属性独立性假设,不同的属性根据其分类重要性赋予不同的加权值,则加权朴素贝叶斯分类模型为:
(4)
其中Wci为属性Ai的加权值。若属性Ai在数据集D中能提供更多的信息以减少类别的熵,则属性Ai应该分配更大的加权值。
3 属性加权核密度估计的朴素贝叶斯分类模型
3.1核密度估计
给定样本X=〈x1,x2,…,xn〉,其中xi为样本X的属性Ai的值,其核函数为:
(5)
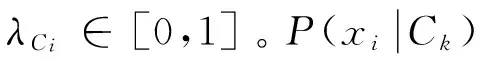
(6)
对所有的属性构造一组参数值,并定义损失函数为:
(7)
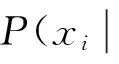
(8)
属性加权核密度估计的朴素贝叶斯分类模型为:
(10)
3.2属性加权
属性加权通过求条件属性与决策属性的相关系数,并结合互信息得到新的加权值[11]。条件属性与决策属性的相关度越高,则该条件属性对分类的影响就越大;反之条件属性与决策属性之间的相关度越小,则该条件属性对分类的影响就越小。条件属性X与决策属性Y之间的相关系数为:
(11)
设加权值为:
(12)
相关系数侧重于属性间的偏离程度,它对属性的变化不敏感,故结合互信息获得更好的加权值。条件属性Ai与决策属性的互信息定义为:
(13)
I(Ai,C)越大,则属性Ai对决策C越重要,故属性Ai的加权值为:
(14)
综合相关系数与互信息的加权值,则新的加权值为:
(15)
属性加权核密度估计的朴素贝叶斯分类模型构造步骤为:
1)利用数据预处理技术将原始数据补齐和离散化。
2)构造分类器:
b)通过式(12)计算条件属性对应的加权值Wc,然后通过式(13)计算每个条件属性和决策属性对应的互信息I(Ai,C)、加权值Wi,综合Wc和Wi得Wci;
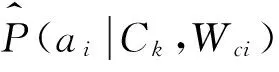
3)分类评估,根据分类模型(10)得到分类结果。
4 仿真实验
实验采用UCI(university of California in Irvine)机器学习数据库的8个数据集进行测试,其中训练集为70%,测试集为30%。预处理后的实验数据集及算法分类结果如表1所示。其中:NBA表示朴素贝叶斯分类算法;NBAWKDE表示以互信息作为权值的加权核密度估计的朴素贝叶斯分类算法;NBA-AWI表示结合互信息与相关系数的加权朴素贝叶斯分类算法;NBAWKDE-AWI表示结合互信息与相关系数的属性加权核密度估计的朴素贝叶斯分类算法。
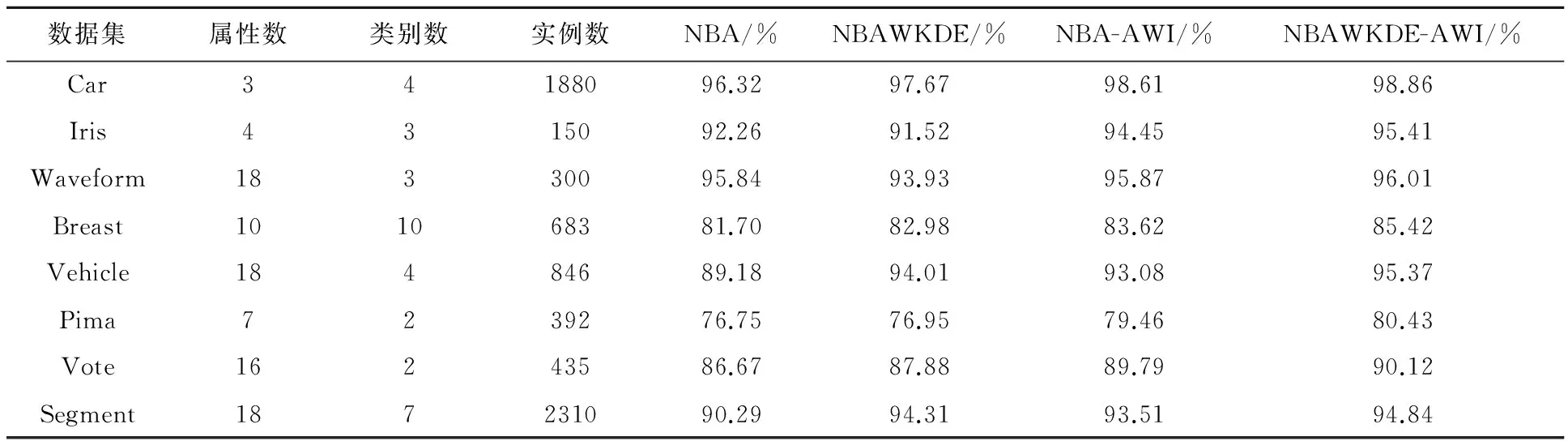
表1 预处理后的实验数据集及分类结果
由表1可知,除了在实例数较小的数据集Iris和Waveform,NBAWKDE分类准确率小于NBA外,在其他数据集NBAWKDE的分类准确率大于NBA,NBAWKDE更适合实例数大的数据集进行分类。在8个数据集中,NBAWKDE-AWI分类准确率大于NBA、NBAWKDE,说明结合互信息与相关系数的属性加权核密度估计的朴素贝叶斯算法分类更加准确,可以提高分类器的性能。
5 结束语
通过计算条件属性与决策属性的相关系数,结合互信息作为属性权值,提出了一种新的属性加权核密度估计的朴素贝叶斯算法。仿真实验表明,该算法是有效和可行的。
[1]马小龙.一种改进的贝叶斯算法在垃圾邮件过滤中的研究[J].计算机应用研究,2012,29(3):1091-1094.
[2]张轮,杨文臣,刘拓,等.基于朴素贝叶斯分类的高速公路交通事件检测[J].同济大学学报(自然科学版),2014,42(4):558-563.
[3]朱克楠,尹宝林,冒亚明,等.基于有效窗口和朴素贝叶斯的恶意代码分类[J].计算机研究与发展,2014(2):373-381.
[4]苏中,张宏江,马少平.基于贝叶斯分类器的图像检索相关反馈算法[J].软件学报,2002,13(10):2001-2006.
[5]邓维斌,王国胤,王燕.基于Rough Set的加权朴素贝叶斯分类算法[J].计算机科学, 2007,34(2):204-206.
[6]张明卫,王波,张斌,等.基于相关系数的加权朴素贝叶斯分类算法[J].东北大学学报(自然科学版),2008,29(7):952-955.
[7]郑默,刘琼荪.一种属性相关性的加权贝叶斯分类算法研究[J].微型机与应用,2011,30(7):96-98.
[8]张步良.基于分类概率加权的朴素贝叶斯分类方法[J].重庆理工大学学报(自然科学版),2012,26(7):81-83.
[9]CHEN L,WANG S.Semi-naive Bayesian classification by weighted kernel density estimation[C]//8th International Conference on Advanced Data Mining and Applications,2012:260-270.
[10]XIANG Z L,YU X R,HUI A W M,et al. Novel naive Bayes based on attribute weighting in kernel density estimation[C]//2014 Joint 7th International Conference on Soft Computing and Intelligent Systems and 15th International Symposium on Advanced Intelligent Systems,2014:1439-1442.
[11]刘牛.基于属性加权的朴素贝叶斯分类算法改进[J].网络安全技术与应用,2011(6):72-74.
编辑:曹寿平
A naive Bayes classification algorithm based on attribute weighting and kernel density estimation
XIE Xiaojun1, CHEN Guangxi1, DING Bolun2
(1.School of mathematics and computational science, Guilin University of Electronic Technology, Guilin 541004, China;2.College of Mechanical and Electrical Engineering, Anhui Polytechnic University, Wuhu 241000, China)
In order to weaken the attribute conditional independence assumption in the naive Bayes classification algorithm, a naive Bayes classification algorithm based on attribute weighting and kernel density estimation is presented. Combining the correlation coefficients of conditional attributes and decision attributes with mutual information, a new attribute weighting is obtained. Then the weighting is embedded into the naive Bayes classification algorithm based on kernel density estimation. Experimental results show that the classification accuracy is improved by the proposed algorithm.
attribute weighting; kernel density estimation; naive Bayes; classification
2015-12-14
广西自然科学基金(2013GXNSFC019330);广西教育厅科研项目(2013YB086)
陈光喜(1971-),男,四川金堂人,教授,博士,研究方向为可信计算、图像处理。E-mail:chgx@guet.edu.cn
TP181
A
1673-808X(2016)03-0231-03
引文格式: 谢小军,陈光喜,丁伯伦.基于属性加权核密度估计的朴素贝叶斯分类算法[J].桂林电子科技大学学报,2016,36(3):231-233.
