一种基于二叉树的RFID防碰撞改进算法
2016-09-03姚幼敏
江 岸,姚幼敏
(广东农工商职业技术学院计算机系,广东广州510507)
[应用研究]
一种基于二叉树的RFID防碰撞改进算法
江岸,姚幼敏
(广东农工商职业技术学院计算机系,广东广州510507)
电子标签防碰撞是RFID系统中的一个关键问题,该文提出一种基于标签识别码分组的防碰撞算法。该算法根据标签识别码按位异或的结果,将待识别标签分为两个集合,通过分散阅读器识别的标签数目、简化识别码数据的传输、动态调整冲突检测过程,有效的降低了标签冲突概率和系统通信量。再利用并行处理策略,使阅读器同时识别两个标签子集。理论分析和仿真结果显示,该算法较其他二叉树算法性能有明显提升,具有良好的应用前景。
RFID;防碰撞算法;并行处理;二进制搜索
一、引言
射 频 识 别(Radio frequency identification,RFID)是一种利用无线电讯号识别目标的通信技术,[1]它无需识别系统与被识别目标建立物理接触,整个识别过程快捷方便,且无需人工干预。射频识别技术及其应用正处于迅速发展上升阶段,目前其在自动收费、防伪防盗、交通管理等诸多领域得到了越来越广泛的应用。
一个基本的RFID系统由标签、阅读器和天线三部分组成。[1]标签之间共享同一无线通信信道,当同一时刻有多个标签发送数据时,阅读器端必然因为信号干扰而无法正确接收数据,即会产生标签碰撞问题。防碰撞算法是RFID系统中的一个核心问题,它对提升RFID系统性能至关重要。而一个优秀的防碰撞算法必须具备识别精度高、识别延时低、功率消耗小等三个重要特点。目前按照标签的响应方式,将防碰撞算法分为随机算法和树分叉算法两种。
随机算法基本思路是将通信信道划分为若干个时隙,标签只要有数据就会随机选择时隙发送,因此标签之间会出现通信信道的竞争,若竞争成功,那么标签被成功识别,若竞争失败,标签则会等待一段时间后再次随机选择时隙发送数据。该类算法比较简单,易于实现,且标签数较少时具有良好性能。但是由于随机性大,当待识别标签规模较大时,帧冲突现象严重,系统的性能将急剧下降,可能存在一个标签在很长时间内都不能被识别的状况,即“标签饥饿问题(Tag Starvation)”现象。典型的随机算法有纯时隙ALOHA算法、帧时隙ALOHA算法等。[2-3]树结构算法的识别精度较高,可以识别完所有待识别标签,主要包括有查询树算法(Query Tree QT)[4]、ABS算法[5]、跳跃式动态树形反碰撞算法(Jumping Dynamic Search JDS)[6]等。但现有树分叉算法的主要问题是识别延时较大、通信复杂度较高,功率消耗也随之增大,因此仍然有进一步提高的空间。
为此,笔者提出一种基于标签识别码分组的防碰撞算法,该算法根据标签识别码按位异或的结果,将待识别标签分为两个集合,降低了同一时间响应阅读器的标签数,从而减少了碰撞概率。并通过简化识别码数据的传输、动态调整冲突检测过程,降低了系统的整体通信量。此外,该算法引入了并行处理策略,使得阅读器同时识别两个标签子集,极大地提高了识别效率。
二、改进的算法
笔者提出的改进算法与文献中的二叉树搜索算法相比较,采取了较明显的优化措施,主要从以下一些方面进行改进:
降低标签碰撞概率:改进算法将标签ID比特位数据按位异或的结果存入计数器R当中,R值有0和1两种情况,分别表示标签识别码中比特位“1”的个数是偶数和奇数的情况。根据R值,算法将标签划分为两个子集,阅读器分别识别每个子集,这样缩小了阅读器的识别范围,降低了多个标签同时发送数据而产生碰撞的概率。[7]
提高阅读器识别效率:改进算法采取并行处理技术,阅读器使用相同算法同时处理两个标签子集的冲突检测过程。
降低系统传输的通信量:标签中的flag和count是两个预设的计数器,其中flag是表示标签是否被激活的标识位,当flag=0时表示没有被识别,收到阅读器指令后,根据count标识的比特位为起始点传输自己的数据信息,这种动态传输标签数据的措施有效减少了冗余数据的传输,当flag大于零时则表示标签处于静默状态,此时不会响应阅读器的命令。阅读器为了减少指令传输的长度,会利用上一次轮询周期的信息,即把上次标签比特碰撞的最高位作为Request指令。[8]
优化碰撞处理技巧:每一轮阅读器轮询周期中,响应阅读器的标签都具有相同的R值,意味着所有响应的标签,它们的ID中比特位“1”的个数具有相同的奇偶性。根据此特性,如果一次标签碰撞只有两次比特位产生冲突,那么可以直接识别出发生冲突的两个标签。例如标签C:10101001、D:11001001都属于按位异或结果为0的子集成员。阅读器识别这两个标签时接收到的解码为1××01001,根据曼彻斯特编码规则能够判断只有两个冲突位发生,阅读器对成功接收到的标签比特位1××01001进行按位异或的运算,此时结果为1,因此可知冲突位部分的按位异或结果也必须为1,即说明当中只有一个比特位值等于1,也就是说××部分应该是01和10,那么对应的标签ID为10101001和11001001。
降低识别延时:当阅读器在一次识别过程中检测到有三次比特位冲突时,即终止本次搜索,进入下一次搜索周期,因为后续标签比特位数据即使正确被接收也无法被利用,即无效数据,这样有效地减少了识别过程中的识别延时。
(一)算法的相关指令
为了更好地描述算法,下面详细介绍算法中使用的指令,算法中每个电子标签拥有唯一的识别码。[9]具体指令如下:
1.Request(m,n)-----请求命令:m表示上一次轮询周期中比特位冲突的最高位置,n表示子集划分的标志位。根据算法规定,只有标签计数器R=n时,该标签才能响应阅读器。如果m+1> count,则令count=m+1。然后根据标签的第m个比特位作出下一步判断,当该位等于0时,标签选择从计数器count指向的比特位为起始数据传输点发送ID数据,若该位等于1时,那么对应的flag++,该标签被屏蔽。此外,算法规定阅读器进行第一次轮询时发送Request(m-1,n)指令,m等于标签的长度,搜索范围内对应子集标识位n的所有标签都会响应。[9]
2.Select(ID)-----选择命令:当阅读器确定读取或者写入某个标签数据,则发送ID数据给标签,只有与该ID数据匹配的标签响应,并令flag--。
3.Read-Data-----读出数据:被Select(ID)命令确定后的标签,发送自己的数据信息给阅读器。
4.Unselect-----去选择:当标签被成功识别后,阅读器发送该命令,让标签变成“无声状态”,不再响应阅读器命令。[10]
(二)算法的工作流程
由图1可以看出,阅读器同时对两个标签子集进行搜索,每个子集的具体搜索流程按照同一识别规则进行。假设阅读器作用区域内有5个标签,各个标签的编码及其识别过程如图2所示。
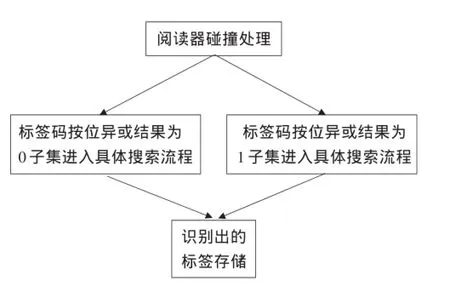
图1 算法整体框架
步骤1:阅读器同时对两个子集进行搜索识别,发出Request(7,0)和Request(7,1)。分别要求R=0和R=1的标签响应阅读器的指令,标签在传送子集识别码时会附上子集的模块标记,即R值,阅读器会根据模块标记值分类处理。
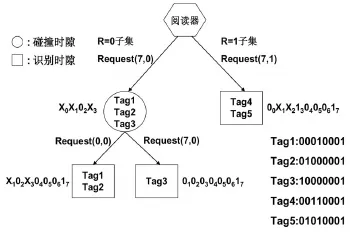
图2 算法的搜索识别过程
步骤2:阅读器处理R=0子集时,检测出标签码冲突位是X0X102X3,有标签1、2、3响应,在检测到3个冲突位后即停止接收标签数据。同时在处理R=1子集中,检测出标签冲突位是00X1X21304050617,有标签4、5响应,则直接识别出标签4:00110001和标签5:01010001。因此R=1的子集即全部识别完。
步骤3:阅读器处理R=0子集,发出Request(0,0),即要求第0位上比特位为“0”的所有标签响应,标签1、2响应,阅读器解码得到X102X304050617,只有2位冲突位,因此标签1、2得到识别。
步骤4:阅读器继续处理R=0子集,发出Re⁃quest(7,0),要求所有未被识别的标签响应,此时只有标签3响应,直接识别。
由图2可知识别按位异或为0的子集使用了3次搜索过程,识别按位异或为1的子集用了1次搜索过程。由于阅读器是同时对两个子集进行识别搜索,那么整个系统的搜索开销等于两个子集中较大一个子集的搜索开销。因在此使用本算法识别5个标签等同于只用了3次搜索过程,标签与阅读器之间的通信量为47。相比于传统的二叉树搜索算法,搜索次数和通信量都有了较大的优化。
三、算法的性能分析
(一)阅读器的搜索次数
命题:本算法中,为了成功识别阅读器轮询范围内的N个标签,假设需要S(N)次搜索,那么,
S(N)=MAX(2×(N1-K1)-1,2×(N2-K2)-1)(1)
其中R值等于1的标签数量为N1,R值等于0的标签数量为N2,标签根据自己的R值被划分为奇偶两个子集,阅读器分别对奇偶两个子集进行识别,设在识别过程中只发生2次碰撞位的次数分别为K1、和K2。
证明:在跳跃式动态树形反碰撞算法[6]中,当发生比特位冲突时,对应的冲突位分裂成0和1两个子节点,将冲突范围不断缩小,节点分裂的过程也是二叉树构建的过程,最后的叶子节点即待识别标签ID。在跳跃式动态树形反碰撞算法中,识别P个标签的搜索次数是S(P)=2×P-1[6],本算法继承了该算法的识别优点,在本算法中当只检测出二次比特位发生冲突时可以直接识别两个标签,那么说明当只发生二次碰撞位时不需要分裂节点,这样二叉树的叶子节数得到修剪。假设阅读器轮询过程中出现了T次只有2次碰撞位的情况,那么本算法在跳跃式动态树形反碰撞算法的基础上减少了T个叶子节点,即二叉树只有P-T个叶子节点。由此可知阅读器的搜索次数变为:
S(P)=2×(P-T)-1(2)
根据公式(2),可得识别子集N1个、N2个标签的搜索次数为
S(N1)=2×(N1-K1)-1(3)
S(N2)=2×(N2-K2)-1(4)
由于本算法采用了并行策略,能同时对两个子集进行标签识别,所以整个系统的搜索次数等于两个子集中较大的一个搜索次数。则识别完N个标签的搜索次数:
S(N)=MAX(S(N1),S(N2))
=MAX(2×(N1-K1)-1,2×(N2-K2)-1)(5)
(二)算法的传输延时
假设待识别标签数为n,标签的ID长度为kbit,标签数据传输速率为vbit/s,阅读器在识别完所有标签的过程中,标签的k位ID中有m位发生了碰撞,由于碰撞位置是随机的,则k位比特位中某一位发生碰撞的概率为

因此在本算法中,标签每次发送数据的平均长度是
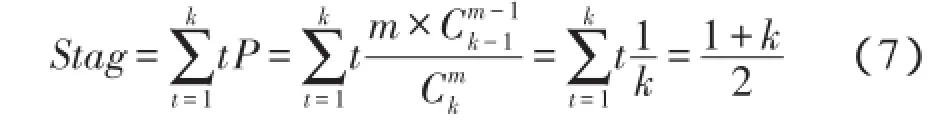
再加上标识标签所属模块的1个比特位和阅读器指令的长度2位,那么本算法中一次搜索的有效通信量是
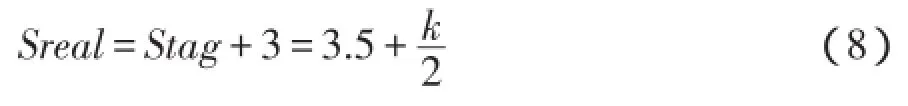
因为数据传输的时延是由阅读器的搜索次数和有效通信量决定的,因此本文算法中的识别延时为
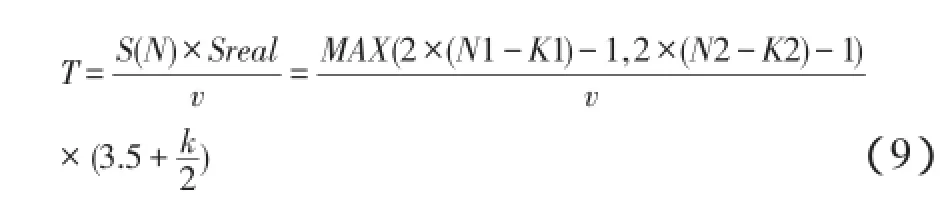
从(9)式可知本算法的识别延时主要是由识别完标签的搜索次数决定。
(三)与其它算法的性能比较
通过MATLAB对改进算法和其它二进制搜索算法进行了性能的仿真对比。设标签ID长度为64,标签数据随机分配,阅读器和标签的数据传输速率均为128 Kbps,搜索过程中的响应延迟为40 μs,空闲时隙为80 μs。
根据图3的数据,我们可以看出,当待识别标签数量增加时,改进算法的搜索次数要明显优于其他算法,这是因为当标签样本数较多时,按位异或结果分离的两个子集标签数趋于一致。即公式(5)中N1的值约等于N2,那么识别完N个标签所需的搜索次数为:
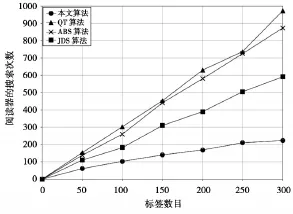
图3 算法搜索次数比较
S(N)≈2×(N/2-K1)-1=N-2XK1-1 由于识别标签的搜索次数减少,再加上改进算法采取了简化阅读器指令,动态传输标签识别码的策略,因此较大程度降低了阅读器与标签之间的通信量,如图4所示。通过公式(9)得知标签的识别延时取决于搜索次数,而改进算法中阅读器的搜索次数得到了有效地降低,所以标签的识别延时也会随之减少,如图5所示。这说明算法的仿真结果与理论分析一致。 图4 算法通信量比较 图5 算法识别延时比较结论 笔者提出了一个改进的二进制搜索算法,根据标签按位异或结果分为两个子集,再通过并行策略的引入,有效地减少了标签的碰撞概率和识别延时。理论分析和仿真比较均显示本算法优于文献中的二进制搜索算法,且当标签数量较多时,本算法优势越明显。虽然算法增加了一定的硬件复杂度,但是由于在标签中设置计数器的成本较低,且硬件增加的代价是远小于整个识别系统的性能提升产生的价值,因此该算法具有良好的应用前景。 [1] Ali K,Hassanein H,and Taha A E M.RFID anti-colli⁃sion protocol for dense passive tag environments[C]. IEEE Conference on Local Computer Networks,Dublin,Ireland,2007:819-824. [2] 吴海锋,曾玉,丰继华.无标签数估计的被动RFID标签防冲突二进制树时隙协议[J].计算机研究与发展,2012,49(9):1959-1971. [3] Eom D F and Lee T J.Accurate tag estimation for dynam⁃ic framed-slotted ALOHA in RFID systems[J].IEEE Communications Letters,2010,14(1):60-62. [4] 王雪,钱志鸿,胡正超,等.基于二叉树的RFID防碰撞算法的研究[J].通信学报,2010,31(6):49-57. [5] Jihoon Myung,Wonjun Lee,Jaideep Srivastava,Timo⁃thy K.Shih.“Tag-Splitting:Adaptive Collision Arbitra⁃tion Protocols for RFID Tag Identification”[J].IEEE transactions on parallel and distributed systems,2007,18(6):763-775. [6] 谢振华,赖声礼,陈鹏.RFID技术和防冲撞算法[J].计算机工程与应用,2007,43(6):223-225. [7] FINKENZELLER K.RFID Handbook:Fundamentals and Applications in Contactless Smart Cards and Identifi⁃cation[M].John Wiley&Sons Ltd,2003:187-193. [8] 伍继雄,江岸,黄生叶,等.RFID系统中二叉树防碰撞算法性能的提升[J].湖南大学学报,2010,37(12):82-96. [9] 江岸.无线射频识别系统中防碰撞问题的研究[D].长沙:湖南大学,2009:31-36. [10]Auto-ID Center.Draft Protocol Specification for a 900MHz Class 0 Radio Frequency Identification tag[Z]. Auto-ID Center,2003. (责任编辑:肖胜中) An Improved RFID Anti-collision Algorithm Based on Binary Tree JIANG An,YAO You-min Tag anti-collision is a key technology in RFID.This paper presents an anti-collision algorithm based on grouping mechanism of tag identification data.According to the result of bitwise XOR of tag identification data,we divide the unidentified tags into two groups,it greatly reduced the transmit data of system and tags collision probability by disperse the unidentified tags,simplify the transmit data of tag and adjust the process of conflict detection dynamically.In addition,the reader can identify two subsets according to parallel processing strategy. Theoretical analysis and simulation results show that the proposed algorithm has made a distinct progress in perfor⁃mance and has a well application prospect compared with other binary search Anti-collision algorithms. RFID;anti-collision algorithm;parallel processing;binary search TP273 A 1009-931X(2016)02—00063-05 2015-11-13 广东农工商职业技术学院2014年度科研课题(xyzd1403) 江岸(1982-),男,湖南常德人,讲师,硕士。研究方向:RFID防冲突算法。四、结束语


(Department of Computer Science,Guangdong Agriculture Industry Business Polytechnic,Guangzhou 510507,China)
