基于Probit回归的小企业债信评级模型及实证①
2016-09-02迟国泰张亚京石宝峰
迟国泰, 张亚京, 石宝峰
(大连理工大学管理与经济学部, 大连 116024)
基于Probit回归的小企业债信评级模型及实证①
迟国泰, 张亚京, 石宝峰
(大连理工大学管理与经济学部, 大连 116024)
小企业债信评级系指评价一笔小企业的债务信用资质的高低和债务违约损失率的大小.它事关银行贷款的风险管理以及合格的小企业能否得到融资.因此、债信评级的指标必须能直接鉴别小企业的违约状态.以等级评分和排序为目的的现有的信用评级体系并不评价一笔债务违约损失率大小,现有的信用评级体系也没有任何证据表明其评级指标体系与企业违约状态的鉴别能力有关.本研究根据指标对违约状态鉴别能力的大小遴选指标体系,建立了小企业债信评级体系.本文的创新与特色一是在偏相关系数大于0.7、反映信息重复的一对高度相关的指标中,删除F值小、对小企业违约状态判别能力弱的指标,既避免了第一次筛选后评级指标体系的信息冗余、又避免了误删对违约状态影响大的指标.改变了现有研究评级体系指标的遴选与指标违约状态的鉴别能力无关的状况.二是通过求解违约状态变量与评价指标之间Probit回归方程的回归系数β和回归系数的标准误差SEβ,构建Wald统计量对回归系数β的显著水平进行检验,剔除对小企业违约状态影响小的、回归系数β不显著的指标,保证了第二次筛选出的指标能显著区分企业的违约状态.三是研究表明本文构造的指标体系的感受型曲线ROC的面积AUC大于0.9,不仅保证单个指标能有效区分违约状态,同时确保了整体构建的指标体系对违约状态具有极强的鉴别能力.四是研究结果表明,满足信用等级越高、违约损失率越低的小企业债信评级指标体系的非财务指标权重为56%.五是通过对1 231笔小企业贷款数据进行实证,结果表明:速动比率、总资产增长率、行业景气指数等23个指标能够显著区分小企业的违约状态.
小企业; 债信评级体系; 指标筛选; Probit回归
0 引 言
债信评级是指对客户或一笔贷款的信用资质、违约损失率进行评估.银行参照客户信用等级的高低决策贷款的发放.因此,债信评级事关客户能否从银行获得贷款,及银行对一笔贷款所承担的风险.
据国家工商总局统计,小企业已达1 169.87万家,占企业总数的76.57%,且提供了70%的新增就业和再就业岗位[1].我国小企业数量庞大,已成为国民经济的重要支柱;也是安置新增就业人员的主要渠道.因小企业的发展需要,其贷款需求也高出大型和中型企业分别17.2个和8.2个百分点[2].但是,小企业由于自身财务信息不完备、缺乏抵质押品等特点,导致其贷款融资难的问题长期存在,抑制了小企业发展.如何构建一套合理的小企业信用评级模型,帮助解决小企业融资难的问题,成为亟待解决的难题.
1)企业信用评级指标体系的研究现状
“5C”原则是国际经典信用评级方法,主要指品德(character)、资本(capital)、能力(capacity)、担保(collateral)、经营环境(condition of business)五个方面[3],从这五个方面对企业信用状况进行评估.美国穆迪(Moody’s)评级公司从企业规模、销售增长、资本结构等方面对企业信用评价[4].标普(S&P)评级机构主要从企业经营状况、财务因素两大方面对企业进行评价[5].惠誉(Fitch)评级机构主要从企业结构、企业盈利、企业战略等方面对贷款企业的信用水平评价[6].大公国际主要从宏观经济环境、行业特性、企业经营管理、企业财务状况、特殊事项风险及外部支持等要素,对工商企业信用质量做出的判断[7].中国银行对企业的信用评级指标主要是现金比率、债务覆盖率、存货周准率等财务指标[8].中国建设银行综合考虑宏观经济数据、客户信用记录、客户财务数据、客户基本面信息四个方面对公司类客户信用评级[9].Li等利用贷款目的、资产负债率等17个指标,对农户贷款的信用风险进行评价[10].Psillaki等从息税前利润、员工数、固定资产、营业收入等16个指标,对企业是否违约进行甄别[11].
现有研究[4-11]企业信用评级指标体系是针对大中型企业,并不适合财务信息不完备的中国小企业信用评级研究.
2)企业信用评级指标筛选方法的研究现状
指标筛选是指从大量指标中遴选出用于企业信用评级的指标.Li等采用投影寻踪模型,遴选了适用于农户信用风险指标体系[10].Shi等通过显著性判别方法,构建了商户小额贷款信用评价指标体系[12].马晓青等采用逻辑回归模型与因子分析相结合的方法,建立了用于企业信用评级的指标体系[13].
现有研究[10,12-13]筛选指标的方法在剔除反映信息冗余的指标时,往往都是人为主观删除一个指标,并没有考虑哪个指标对企业的违约状态影响显著.
3)企业信用评分方法的研究现状
一是基于数理统计的信用评价方法.早期,Altman通过线性多元判别法建立了Z分数判别函数对33家企业进行信用评价[14].Maria等使用了Logistic回归构建了适用于塞尔维亚公司的信用评分模型[15].高丽君以928个企业为样本,通过贝叶斯平均生存模型、传统生存模型等三种模型对企业信用违约情况进行估计;并对三种模型的预测结果进行对比,实证表明贝叶斯模型平均生存模型对违约判别的准确性更高[16].
二是基于人工智能方法信用评价方法研究.Hong等以韩国科技型中小企业为样本,通过支持向量机方法进行信用评价,并将信用评价结果与反向传播人工神经网络方法所得结果进行对比,结果表明支持向量机的判别准确率更高[17].Niccolò以3 100个意大利制造业的中小企业为样本,通过遗传算法预测企业的违约状况[18].BLANCO等采用神经网络法,为秘鲁构建了小额信贷机构信用评分模型[19].肖进等采用动态分类器集成选择模型DCESM对客户信用状况进行评价[20].余高峰等将粗糙集与改进后的局部变权方法相结合,建立了企业质量信用评价模型[21].
现有研究[16-19]的信用评价方法没有专门针对中国小企业的情况,提出适用于我国小企业的信用评价方法.
针对上述问题,本文基于Probit回归方法构建了小企业债信评级模型,并以中国某区域性商业银行1 231笔小企业贷款数据为基础进行实证.本文选用Probit回归模型的主要依据在于:一是现有研究已经证明Probit回归模型在债务预警、个人信用评价、农户信用评价等领域都有良好的评估能力,且对二元离散因变量有较强的判别能力[22-23];二是较少学者以中国商业银行小企业为实证对象,利用Probit回归模型构建小企业债信评级体系,本文旨在利用我国商业银行小企业信贷数据、校验Probit回归模型的适用性;三是正如下文3.6所述,采用Probit回归模型构建的小企业信用评级指标体系,其ROC曲线对应的AUC值高达0.987 6,表明该方法在小企业债信评级中,具有极高的违约判别能力.
1 小企业债信评级的构建原理
1.1小企业的贷款特点
1)信息不健全且不易获取[24].小企业因企业规模小,管理不规范,很多财务信息与非财务信息的经典指标数据都不易获取,给评价小企业信用状况带来困难.
2)小企业贷款单笔的额度小,还款的不确定性大.但同一企业贷款频次高、不同企业组合后的贷款业务量大,组合风险小.
3)地区的宏观经济社会环境影响着小企业的还款能力[24-25].各省份在国家政策、经济发展水平、自然环境等方面都存在较大差异,故不同地区的宏观经济社会环境影响着小企业的偿债能力.
1.2问题的难点
难点1在剔除反映信息重复的指标时,如何避免误删对企业违约状态鉴别能力强的指标.
难点2如何确保遴选的指标能有效判别小企业违约状态.
1.3突破难点的思路
1)在偏相关系数大于0.7、反映信息重复的一对高度相关的指标中,删除F值小的、对小企业违约状态判别能力弱的指标(F值的含义将在下文2.3“式(8)的经济学含义”中详细解释),既避免了评级指标体系的信息冗余、又避免了误删对违约状态影响大的指标.改变了现有研究评级体系指标的遴选与指标违约状态的鉴别能力无关的状况.解决难点1.
2)通过求解违约状态变量与评价指标之间Probit回归方程的回归系数β和回归系数的标准误差SEβ,构建Wald统计量对回归系数β的显著水平进行检验,剔除对小企业违约状态影响小的、回归系数β不显著的指标,保证了筛选出的指标能显著区分企业的违约状态.解决难点2.
小企业债信评级的原理如图1所示.

图1小企业债信评级的原理
Fig. 1 The principle of indicator system of debt rating for small enterprises
2 小企业债信评级模型的构建方法
2.1债信评级指标的海选
参考国际穆迪、标普等评级机构、及国内建设银行、工商银行等金融机构的经典信用评级指标,同时梳理与信用评价相关的经典文献[4-19],海选小企业的信用评价指标,确保高频经典指标不遗漏.根据数据可观测性原则,将没有数据来源的海选指标删除,保证初步筛选后的指标体系可以量化.
2.2指标的标准化
在nf=0.5和传感器节点数为50的情况下,首先采用ADM算法进行了初始定位,结果如图2所示,可见存在较显著的定位误差(ERA=6.923 7)。而后以ADM定位作为初值,分别采用CGA算法和PSO算法进行了精确定位。图3和图4分别为CGA算法和PSO算法定位结果,其相对定位误差分别为0.577 1和0.587 1,与图2对比可见定位精度获得显著提升。
1)正向指标的标准化
正向指标:数值越大表明信用状况越好的指标.设xij为第i个指标第j个企业标准化后的值;vij为第i个指标第j个企业的值;n为企业的总数.根据正向指标的打分公式,xij为[26]
(1)
2)负向指标的标准化
负向指标:数值越小信用状况越差的指标.负向指标的标准化公式为[26]
(2)
式(2)中各符号含义与式(1)相同.
3)区间型指标的标准化
最佳区间型指标:数值距离某一特定区间越近、表明小企业信用状况越好的指标.例如,“年龄”的最佳区间为[31,45][26],表明企业负责人的年龄越偏离这个区间,这个指标的得分应该越小.
(3)
式(3)中其他符号含义与式(1)相同.
4)定性指标的标准化
由于同一个定性指标存在不同的状态,因此可以针对不同的状态进行打分,从而把定性指标定量化.对于可观测的指标,例如下文的23个可观测定性指标进行评分,如表1所示.
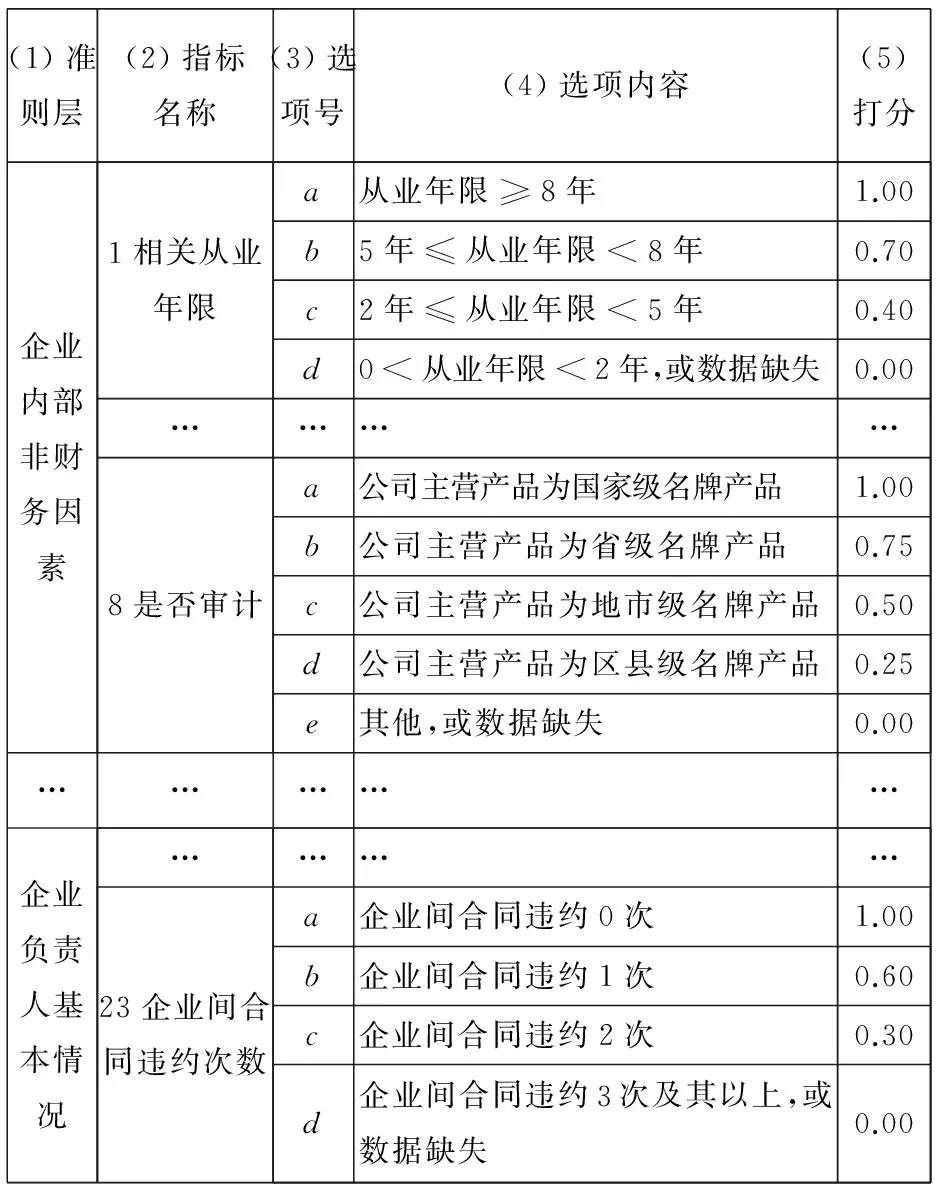
表1 定性指标打分标准
2.3基于偏相关分析的第一次筛选
目的单独一个指标看似很好,但整个评价指标体系中可能会有其他指标与它反映的信息重复,就会造成评价指标体系因含有无用指标而过于庞杂.通过偏相关分析删除反映信息重复的指标.
在准则层内偏相关分析,而不对全部指标偏相关分析的原因:避免指标在数值上相关,而实际经济含义上不相关;因此选择在准则层内相关分析,保证指标若在数据上相关,在经济含义上也一定相关.
1)准则层内指标之间偏相关系数的计算
设xij为第i个指标第j个企业的值,xkj为第k个指标第j个企业的值,rik为第i个指标与第k个指标之间的相关系数,则rik[27]为
(4)
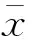
设R为第i个指标和第k个指标的简单相关系数rik组成的相关系数矩阵,m为此准则层指标的个数.相关系数矩阵R如式(5)所示[27].
(5)
相关系数矩阵R的逆矩阵为C[27]
(6)
根据偏相关系数的计算公式,可得第i个指标和第k个指标的偏相关系数[27]
(7)
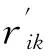
2)F值的计算
计算F值的目的:在高相关指标中,为避免主观误删对违约状态影响显著的指标,分别计算高相关指标的F值.

Fi=
式(8)的经济学含义:式(8)等号右边的分子是第i个指标违约、非违约样本均值与总体样本均值的距离之和,反映了违约样本与非违约样本的差异,差异越大表明该指标越能区分企业的违约状态.分母是第i个评价指标违约样本内的方差与非违约样本内的方差之和,反映了违约和非违约样本各自的离散程度,离散程度越小表明违约、非违约样本内部的指标特征越集中.式(8)中Fi反映了第i个指标对企业违约状态的鉴别能力,Fi越大表明鉴别能力越强,指标对违约状态的影响越显著;反之,该指标对违约状态的影响越小.
偏相关分析好处:多元相关分析时,简单相关分析不能真实地反映出两个变量之间的相关程度,因为它们可能受到不止一个变量的影响,而偏相关分析的相关系数排除了其他指标的影响.
3)偏相关分析删除指标的标准
两个评价指标的偏相关系数绝对值|rik|>0.7,认为这两个评价指标高度相关[27],反映的信息重复,因此仅保留一个指标,将另一指标删除.为避免人为主观误删对违约状态影响显著的指标,本文采用F值鉴别指标对违约状态的判别能力,在偏相关系数绝对值大于0.7的指标集中保留F值大的指标.
4)第一次指标筛选的特点
在偏相关系数大于0.7、反映信息重复的一对高度相关的指标中,删除F值小的、对小企业违约状态判别能力弱的指标,既避免了评级指标体系的信息冗余、又避免了误删对违约状态影响大的指标.改变了现有研究的评级体系指标的遴选与指标违约状态的鉴别能力无关的状况.
2.4基于Probit回归的第二次筛选
目的通过在每个准则层内Probit回归,逐步剔除对小企业违约状态影响小的、回归系数β不显著的指标,筛选出能显著区分小企业违约状态的指标.
2.4.1Probit回归模型
Probit模型是针对二分类因变量的回归模型,本文用Probit模型筛选对因变量yj(违约状态)影响显著的指标.因变量yj只有两种选择,指贷款小企业只有违约(yj=1)、非违约(yj=0)两种状态.
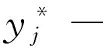
(9)
其中β=(β0,β1,…,βm)T为回归系数组成的列向量,Xj=(x1j, x2j, …,xmj)为第j个企业各个指标数值组成的行向量.
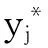
2)测算企业的违约概率P(yj=1|Xj).
(10)
其中Φ(·)表示正态累计分布函数,式中Φ(α+Xjβ)函数中的α、β由下文式(12)中求出.
相应可得到企业的非违约概率,如式(11)所示
P(yj=0|Xj)=1-P(yj=1|Xj)=
1-Φ(α+Xjβ)
(11)
3)通过极大似然估计求解待估计参数α, βi.
式(9)中的待估计参数α, βi可以通过极大似然估计法求解,其对数似然函数为[28]
(1-yj)ln(1-Φ(α+Xjβ))]
(12)
式(12)的含义对数似然函数lnL最大,表明对违约状态的估计最准确,此时α, β的估计值即为所求.
4)求解思路.
步骤1求解α, β.在式(12)中yj是真实的违约状态,是已知的;Xj是第j个企业的各指标值组成的向量也是已知的;只有α、 β是未知的、待求解的;所以每给定一个α、 β值,都能对应计算出一个似然值lnL.给定α、βi参数一个初值,将给定的α、βi、代入式(12),得到对数似然函数值lnL,若此时lnL是最大值,则α,βi即为所求.否则,给定新的α,βi值,重复上述过程,直至式(12)的似然函数lnL最大.一般上述思路通过拟牛顿法[28]迭代求解,由计算机软件实现.
步骤2求解企业的违约概率P(yj=1|Xj).将求解出的α,βi、及每个企业的指标值向量Xj代入式(10),确定各个企业的违约概率.
步骤3求解企业非违约概率P(yj=0|Xj).将求解出的α,βi、及每个企业的指标值向量Xj代入式(11),可求解出各个企业的违约概率.
2.4.2指标第二次筛选步骤
在每个准则层内进行Probit回归,计算指标的Wald统计量,进行χ2检验,在对应双尾显著性概率Sig>0.01的指标中,删除Sig值最大的指标,保留能有效区分违约状态的指标.
1)基于Probit回归第二次筛选指标的具体步骤
步骤1求解Probit回归系数.将所有的m个评价指标与违约状态yj的观测值,按照式(9)-式(12)构建Probit回归模型,并求解参数α,β1,β2,…,βm的估计值,及βk的标准误差SEβk.此计算过程由Stata软件实现.
步骤2求解每个指标的双尾显著性概率值Sig.构建Wald统计量,对每个指标系数的显著性进行假设检验,查表得到对应的Sig值.
假设H0βk=0.若H0成立,则第k个指标对违约状态影响不显著.
假设H1βk≠0.若H1成立,则第k个指标对违约状态影响显著.
设Wk-第k个评价指标Wald统计量值,βk-第k个指标的参数估计值,SEβk-βk的标准误差(standard error);则[28]
Wk=(βk/SEβk)2
(13)
式(13)的作用 通过构造Wald统计量Wk,检验βk是否显著为0.在H0假设成立的条件下,Wk服从自由度为1的χ2分布,查卡方分布表得到对应的双尾显著性概率Sig值.
①若Sig<0.01,则拒绝原假设H0,说明该指标对违约状态影响显著.
②若Sig>0.01,则接受原假设H0,说明第k个指标的系数βk=0,即该指标对因变量没有影响.
步骤3在显著性概率Sig>0.01的指标中,剔除Sig值最大的一个指标.
Sig>0.01的指标说明接受H0假设,对违约状态影响不显著,在所有不显著的指标中,剔除Sig值最大、也就是删除对违约状态影响最小的一个指标.这一个步骤不能一次全部剔除Sig>0.01的指标,只能逐步一个一个剔除,因为一个变量受到多个变量的影响,因而去掉一个变量后再做Probit回归,其中有些变量就会变得显著.
步骤4将剩余的m-1个指标与因变量违约状态y返回步骤1-步骤3,直至模型中所有剩余变量的系数都确保Sig<0.01,则停止.
2)指标第二次筛选的特点
通过求解违约状态变量与评价指标之间Probit回归方程的回归系数β和回归系数的标准误差SEβ,构建Wald统计量对回归系数β的显著性概率进行检验,剔除对小企业违约状态影响小的、回归系数β不显著的指标,保证了筛选出的指标能显著区分企业的违约状态.
2.5基于ROC曲线检验指标体系的有效性
2.5.1ROC曲线检验指标体系有效性的方法
目的是通过ROC曲线的AUC值,检验Probit模型筛选出的指标判断样本违约与否的正确率.
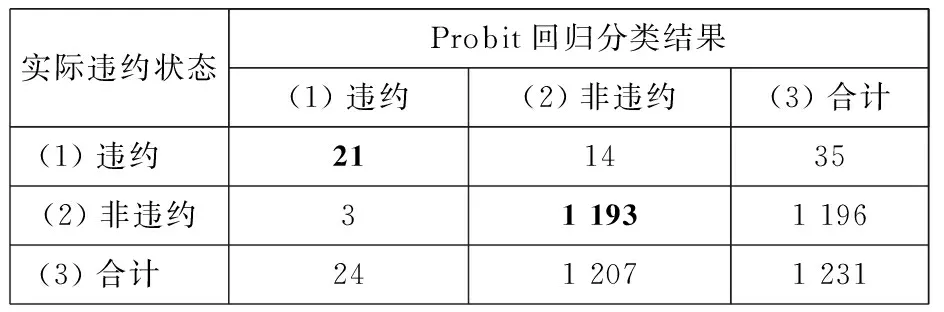
将违约样本(yj=1)正确判定为违约的个数,记为TP(true positive);将违约样本误判为非违约的个数,记为FN(false negative);将非违约样本(yj=0)正确判定为非违约的个数,记为TN(true negative);将非违约样本误判为违约的个数,记为FP(false positive),如表2所示.
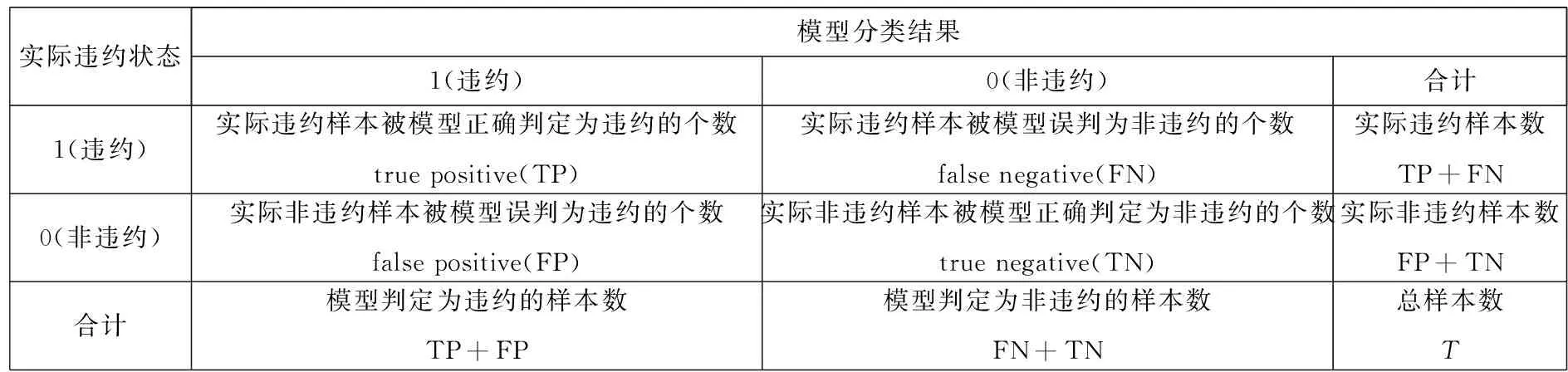
表2 Probit模型分类结果
ROC(Receiver Operating Characteristic Curve)曲线,也称为感受型曲线.ROC曲线作图时需要用到两个指标:灵敏度(sensitivity)、特异度(specificity),如式(14)、式(15)[29]所示.
sensitivity=TP/(TP+FN)
(14)
specificity=TN/(FP+TN)
(15)
式(14)sensitivity灵敏度,是用正确判定为违约的个数TP除以实际所有的违约数TP+FN,指实际违约的样本被式(10)的Probit模型准确判定为违约样本的比率,它为一种违约状态判别的正确率.
式(15)特异度specificity,是用正确判定为非违约的个数TN除以所有的非违约数FP+TN,指实际非违约的样本被准确判定为非违约的比率,它是一种非违约状态判别的正确率.
1-式(15)、即1-特异度,是将实际违约的样本误判为非违约的错误率,它为一种非违约状态判别的错误率.
ROC曲线是以1-式(15)、即1-特异度为横坐标,以式(14)灵敏度为纵坐标绘制而成的[29].
当横坐标不变时,纵坐标越大、实际非违约的样本被准确判定为非违约的比率TP/(TP+FN)越大,这个指标体系区分违约状态的能力越强.此时、ROC下边包围的面积AUC也就越大.因此、AUC面积越大、则遴选的指标体系鉴别违约状态的能力越强.
ROC图中的对角线代表判断违约状态的正确率等于判断非违约错误率.当将样本判断为违约的正确率远大于将样本判断为非违约的错误率、即ROC曲线在对角线之上如图2所示时,表明对违约与否的区分效果较好.
ROC曲线以下的面积大小,如图2阴影部分所示,记为AUC(Area Under Curve),其判别效果分为五档[29]:(1)当AUC=1时为理想值,其判别效果最好.(2)AUC=0.9以上时,违约判别效果较好.(3)当AUC在0.7~0.9之间违约判别效果中等.(4)AUC在0.5~0.7之间违约判别效果较差.(5)当AUC在0~0.5之间违约判别效果极差.
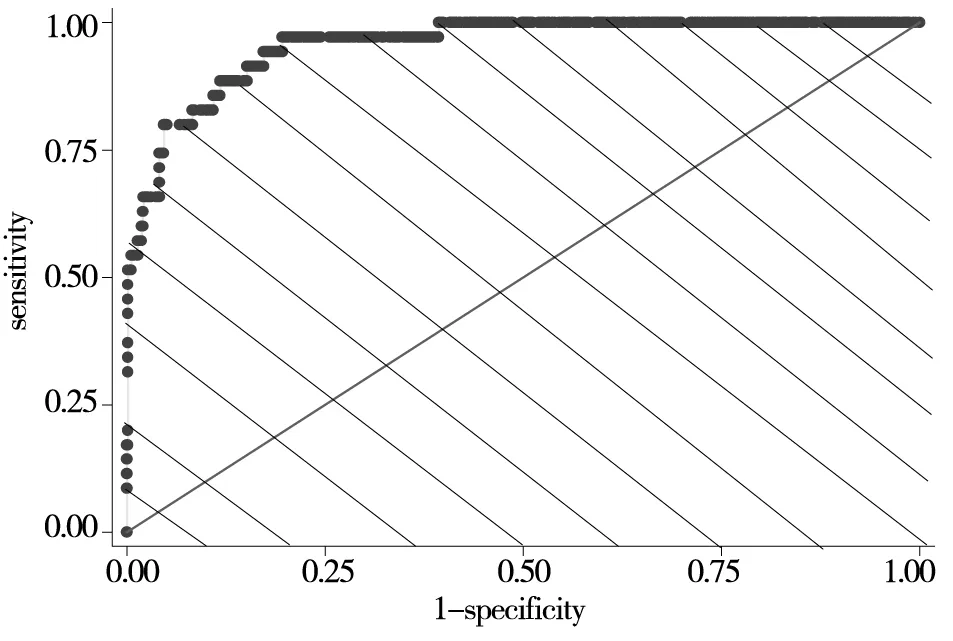
图2 ROC曲线
若上文2.4中经过Probit模型筛选出的指标体系,其违约状态判别的AUC值能够达到0.9以上,则该指标体系对违约状态有较好的区分效果[29].
研究表明下文构造的感受型曲线ROC的面积AUC大于0.9的指标体系,确保了整体构建的指标体系对违约状态具有极强的鉴别能力.通过违约样本被正确判定为违约的个数TP占全部实际违约样本的个数(TP+FN)的比率、与非违约样本正确地判定为非违约的个数占实际全部非违约样本的个数(FN+TN)的对比关系,构造感受型曲线ROC的面积AUC大于0.9的指标体系,确保整体构建的指标体系对违约状态具有极强的鉴别能力.
指标体系的整体鉴别能力、而不是单个指标的鉴别能力及其重要程度.因为单个鉴别能力强的指标并不一定能组合成鉴别能力也强的指标体系.
流行的指标不一定组成一个好的指标体系,因为这个指标的组合、或这个指标体系的AUC值不一定大.并不流行的指标组成的体系或许反而好,因为这个指标组合、或这个指标体系的AUC值可能会很大.
2.5.2几点说明
1)检验整体指标体系有效性的原因.第一次偏相关分析筛选指标、第二次Probit回归筛选指标都是针对单个指标,只能检验单个指标对违约状态的鉴别能力,并不能保证最终筛选出的整个指标体系对违约状态.而实际中为企业进行信用评级使用的整个指标体系,而非单个指标,所以进行整个指标体系的检验是必要的.
2)指标体系的调整.当债信评级指标体系的AUC值较小时,变换筛选指标的方法重新建立指标体系,直至最终构建的指标体系的AUC值达到大于0.9的标准.本文中使用的指标筛选方法是偏相关分析和Probit回归分析,也可使用其他指标筛选方法,如聚类分析、主成分分析、Logit回归分析等方法去构建债信评级指标体系.直至最终构建的指标体系的AUC值达到大于0.9的标准.
2.6债信评级指标权重的确定与评价方程的
建立
2.6.1指标权重的确定
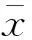
(16)
式(16)的含义第i个指标的变异系数,反映该指标信息含量的大小,变异系数越大表明信息含量越大,权重也应越大.
设wi-第i个评价指标的变异系数权重,对式(16)中的qi作归一化处理,则[26]
(17)
2.6.2评价方程的建立
设zj-第j个企业的加权得分,则[26]
(18)
式(18)计算所得加权得分zj在[0,1]区间内,为了符合人们的习惯,将zj化为0-100分之间的得分,如式(19)所示.
设Sj-第j个企业的信用得分,则[26]
Sj=100×(zj-min(zj))/(max(zj)-min(zj))
(19)
2.7信用等级的划分
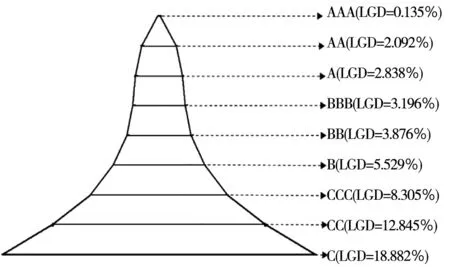
本文将客户划分为AAA、AA、A、BBB、BB、B、CCC、CC、C九个信用等级,从AAA到C信用等级依次降低,代表客户信用依次变差.
应该指出,因现实中几乎每个信用等级都会有违约的客户出现,所以本文在划分信用等级时,为了使划分结果更接近实际,要求每个等级至少有一笔违约的贷款,以保证每个等级的违约损失率LGD大于0.
1)信用等级的初步划分.
将客户按信用得分由高到低排列,将客户划分为9个等级,每个等级都要有违约的客户,并根据客户的应收本息和应收未收本息,计算每个等级违约损失率.
2)信用等级的调整.
不断调整每个等级的界限、即调整每个等级的企业数,使等级划分的结果满足信用等级越高违约损失率越低的原则.
等级界限调整过程中,一旦一个等级的上下限改变,就会引起相邻等级的违约损失率的变化,使相邻等级的界限也会被迫进行调整.实际调整的过程比较复杂,且不属于本文的研究范围与创新点,本文不再赘述,具体参见课题组研究成果[26].
3 小企业债信评级的实证分析
3.1指标的海选
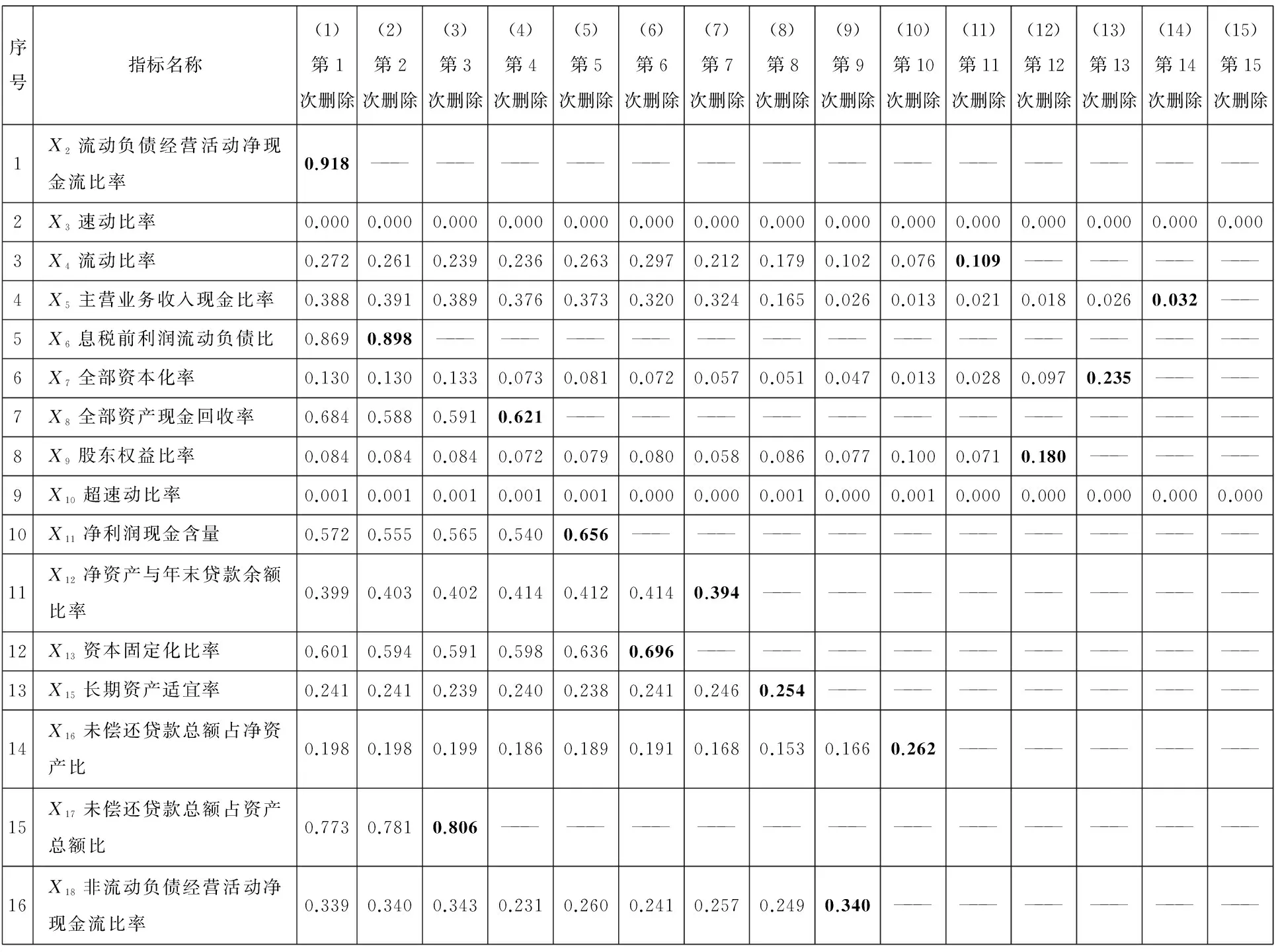
以穆迪公司、标普公司等国外权威机构,及中国建设银行等国内金融机构的经典高频指标为基础[4-13],结合权威研究文献[14-19],海选出用于小企业债信评价的107个指标,如表3第5列所示.指标主要涵盖了还款能力、还款意愿两个一级准则层,企业内部财务因素、企业外部宏观条件、抵质押担保因素等7个二级准则层,其中,企业内部财务因素又细分为偿债能力、盈利能力等4个三级准则层,如表3第2列~第4列所示.每个指标的类型如表3第6列所示,指标对应的文献来源如表3第7列所示.
根据数据可观测性原则,剔除“还款来源”、“每股现金流”、“工资、福利增长率”等26个数据不可获得的指标,剔除的指标在表3第8列用“数据不可获得删除”标注.删除26个指标后,剩余81个债信评级指标,如表5第e列所示.

表3 小企业债信评级海选指标集
3.2样本选取和数据来源
1)样本选取
根据中华人民共和国工业和信息化部发布的《中小企业划型标准规定》[30],批发业中从业人员5人及以上,且营业收入1 000万元及以上的为小型企业.零售业、建筑业等其他行业也按照《中小企业划型标准规定》中要求的从业人数和营业收入选出小企业样本.
按照工信部行业划分标准[30],将所有小企业样本划分为批发业、零售业等12个行业,行业分布如表4第2列所示;每个行业的违约样本数及总样本数如表4第3列、第4列所示.

表4 按工信部标准分类的各行业小企业样本数
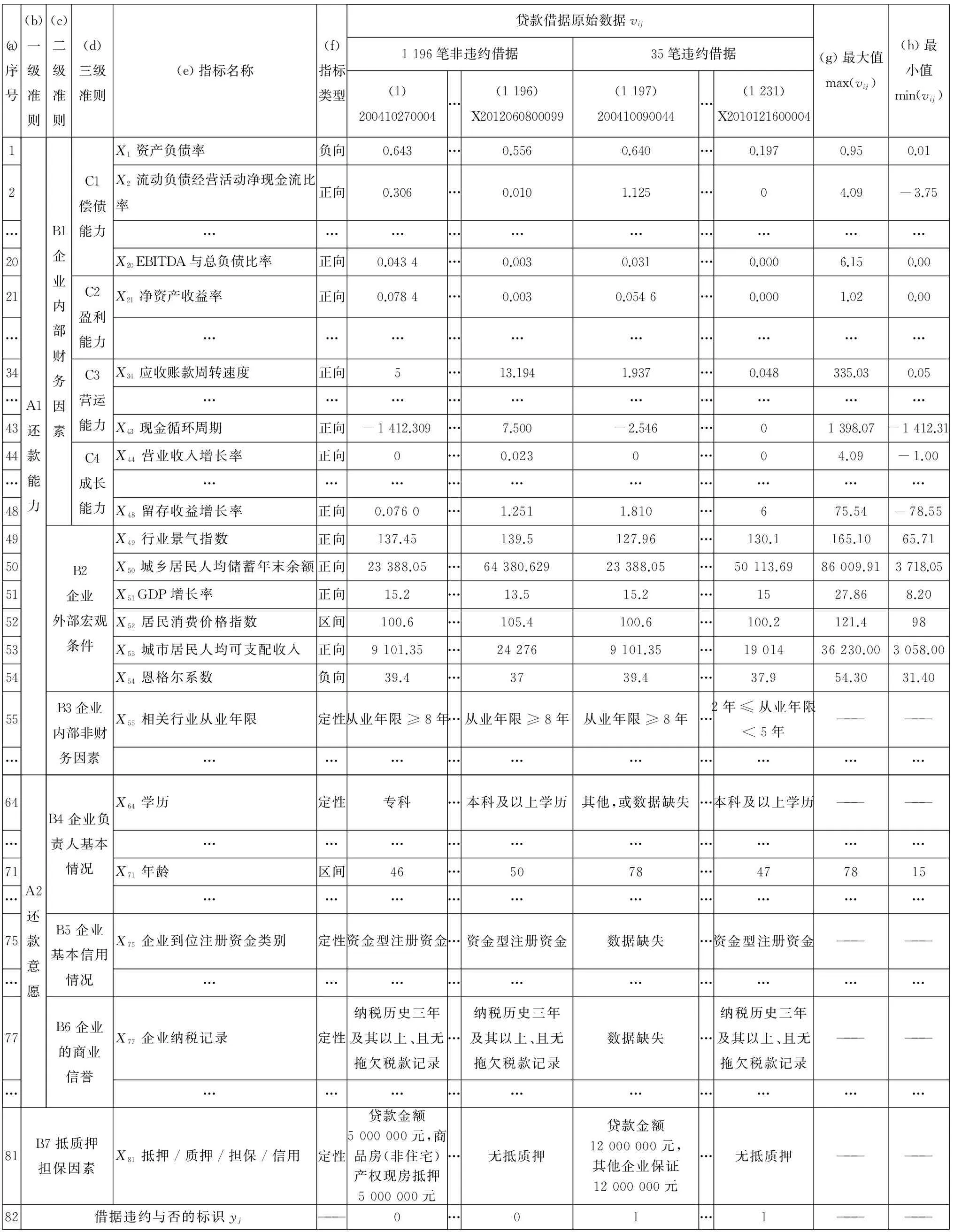
表5 小企业债信评级指标筛选原始数据
多个非工业行业样本合并一起评级的原因:上文2.7节信用等级划分中,要求每个信用等级至少有一个违约样本,本文划分9个信用等级,则样本中必须有9个以上的违约样本.从表4第12行可知,工业行业的违约样本数及样本总数都较大,适合单独债信评级,能够更有针对性地分析工业行业的债信评级特性,另有专文详述.从表4前11行可知,批发业等许多行业的违约样本小于9个,零售业等行业甚至没有违约样本,为了有足够的违约样本,本文将批发业、零售业等11个非工业行业的样本数据合并,共有1 231个小企业样本,在这些数据的基础上为小企业债信评级.
2)数据来源
选取中国某区域性商业银行分布在京、津、沪、渝等分支行的1 231笔小企业贷款借据做为实证样本.
1 231个小企业的原始数据,如表5第1-1 231列所示.其中,包含1 196个非违约借据,如表5第1-1 196列所示;35个违约借据,如表5第1 197-1 231列所示.每个企业对应的违约状态yj如表5第82行所示,0代表非违约借据,1代表违约借据.
3.3指标数据标准化
1)定量指标数据的标准化
通用指标数据的确定:定量指标包含正向、负向、区间型指标.对表5的前81行的58个定量数据,每一行的数据都确定出最大值和最小值,列入其对应行的最后两列.
根据表5中第f列指标类型的标注,将正向型指标数据代入式(1)、负向型指标数据代入式(2)、区间型指标数据代入式(3),得到标准化处理后0-1间的数值,结果列入表6对应行.
2)定性指标打分
经过3.3(1)定量指标标准化后,在表5第f列的剩余的“定性”的指标,按照表1的定性指标打分标准进行打分,打分后的值已在0-1之间,不需要再通过正向、负向等打分公式转化到0-1之间,将结果列入表6对应的行.
3.4基于偏相关性分析的第一次指标筛选
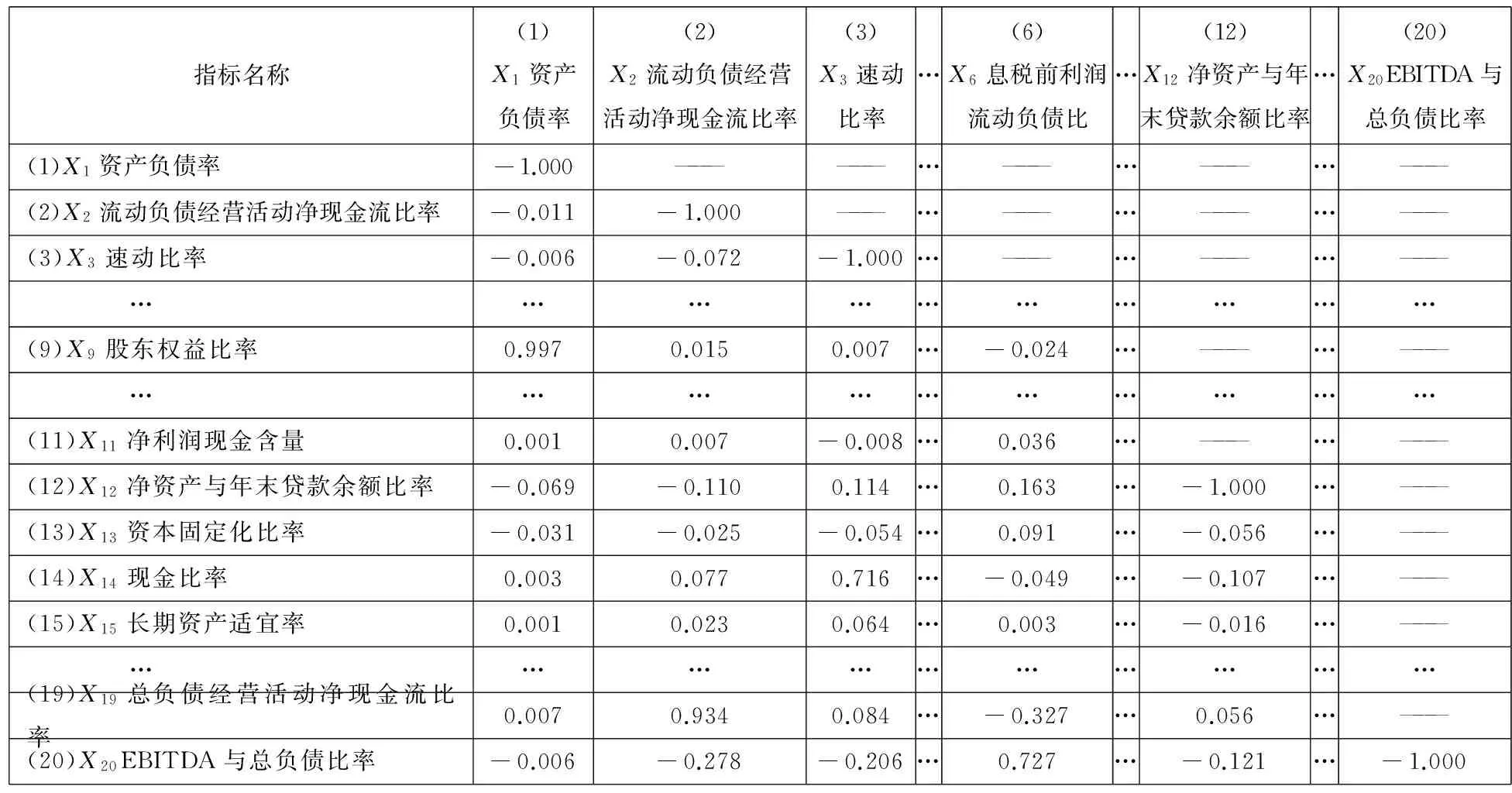
在准则层内进行偏相关分析,避免指标只在数据上相关,在经济意义上不相关.
以“C1偿债能力”准则层为例,说明偏相关分析筛选指标的过程.
将表6前20行20个指标数据代入式(4)-式(7),计算偏相关系数,结果如表7所示.
由表7可知,共有4对指标的偏相关系数绝对值大于0.7,说明这4对指标高度相关,反映信息冗余.将这4对指标名称及对应偏相关系数列入表8第2、4、6列.
每对冗余指标中需要删除一个,计算其F值.以“X1资产负债率”、“X9股东权益比率”为例:由表8第1行第6列知这两个指标的偏相关系数绝对值为0.997>0.7,二者反映信息重复,需计算两指标的F值.
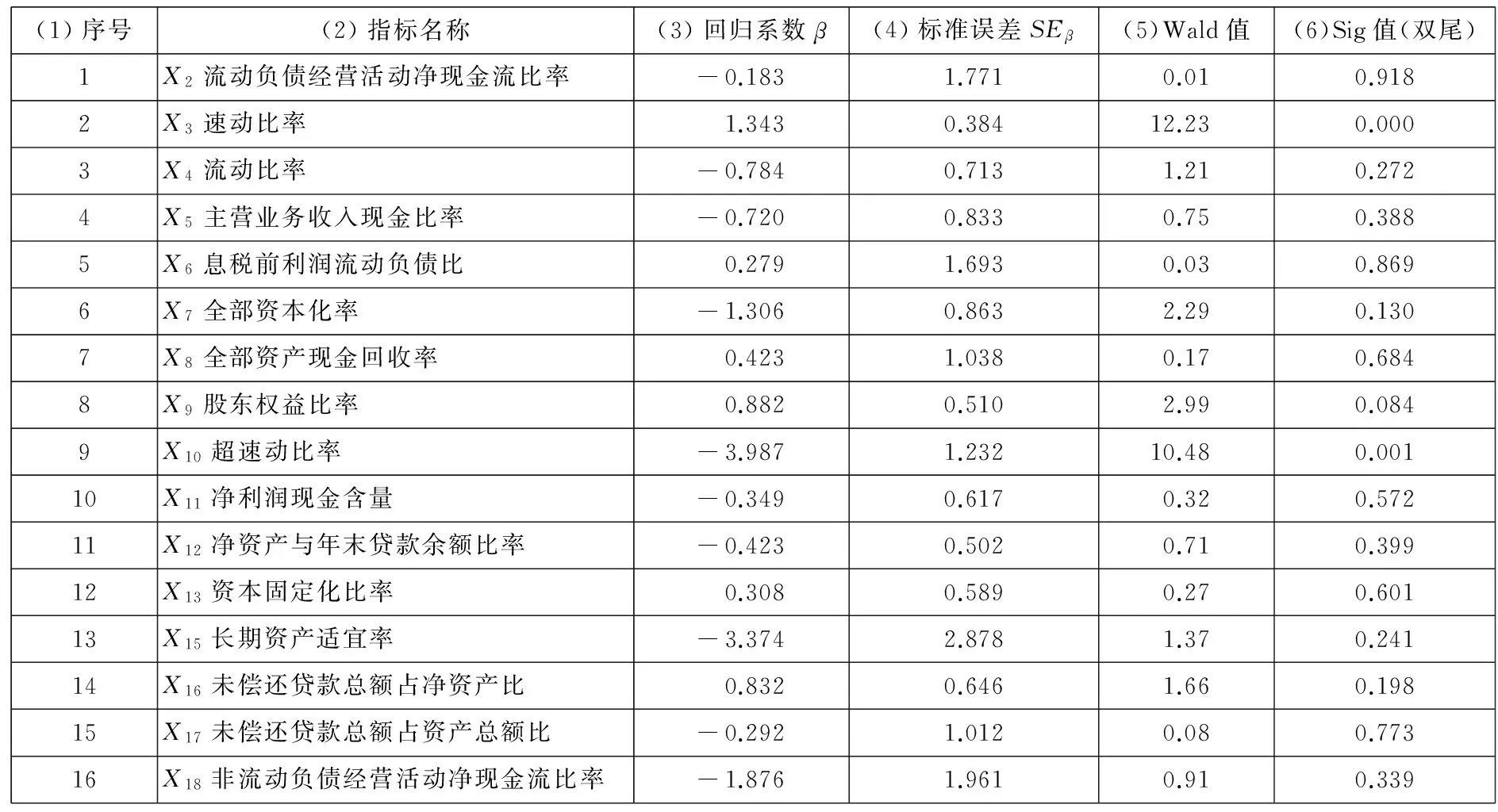
将表6中第1行、第9行数据代入式(8),可以得到指标X1、X9的F值,列入表8第1行第3列与第5列,因F1=0.029 7 同理删除其他三对重复指标中F值较小的那一个指标,亦如第7列所示. 表8中的“C1偿债能力”准则层前后共删除了4个反映信息重复的指标,剩余16个指标. 其他准则层同理,通过偏相关分析-F值判别,共剔除了“X1资产负债率”、“X54恩格尔系数”等12个反映信息冗余的指标.所有剔除的指标在表3第8列用“偏相关分析删除”标注. 经过第一次偏相关分析筛选,81个指标中剔除12个指标,共剩余69个指标. 经过第一次偏相关分析筛选,找到反映信息重复的指标,并通过F值进行判别,剔除F值较小的、即对违约状态影响小的指标,避免人为误删对违约状态影响大的指标. 表6 小企业信用指标筛选标准化数据 3.5基于Probit回归的第二次指标筛选 在偏相关分析的基础上,通过Probit回归筛选各准则层中剩余的指标,遴选对违约状态有显著鉴别能力的指标. 以“C1偿债能力”准则层为例,说明Probit回归删除指标的过程. 1)第1个指标的剔除过程.将”C1偿债能力”准则层经第一次偏相关分析后、剩余的16个指标在表6对应行中的数据,及表6最后一行的违约状态代入式(9)~式(13),Stata软件可以自动完成Probit回归过程,得到Probit回归参数,如表9第3列~第6列所示. 表7 “偿债能力”准则层内指标的偏相关系数 表8 偏相关分析删除的指标 根据上文2.4.2(1)中“在显著性概率Sig>0.01的指标中,剔除Sig值最大的一个指标”的标准,在表9第6列所有Sig>0.01的指标中,“X2流动负债经营活动净现金流比率”的显著性概率Sig值最大,表明该指标对违约状态影响最不显著.第一轮将其剔除,则“C1偿债能力”准则层16个指标中还剩余15个指标. 2)其余指标的删除过程 剔除“X2流动负债经营活动净现金流比率”后,“C1偿债能力”准则层中剩余15个指标按照上述方法进行筛选,直至剩余所有指标的显著性概率Sig均小于0.01,即可停止,指标筛选过程结果如表10第1列~第16列所示. “C1偿债能力”准则层最终剩下“速动比率”、“超速动比率”两个指标的Sig值均小于0.01,如表10第15列所示. 其余准则层同理,采用Probit回归筛选对违约状态影响显著的指标. 第一次偏相关筛选后剩余的69个指标,通过Probit回归分析进行第二次筛选,剔除了“X2流动负债经营活动净现金流比率”、“X21净资产收益率”等46个对违约状态影响不显著的指标,剔除的指标在表3第8列用“Probit删除”标注.最终保留了“速动比率”、“应收账款周转速度”等23个指标,在表3第8列标注“保留”.由这23个指标构建的小企业债信评级指标体系,如表12第b列~第e列所示. 第二次指标筛选通过求解违约状态变量与评价指标之间Probit回归方程的回归系数β和回归系数的标准误差SEβ,构建Wald统计量对回归系数β的显著性进行检验,剔除对小企业违约状态影响小的、回归系数β不显著的指标,保证了筛选出的指标能显著区分企业的违约状态. 表9 Probit回归的指标参数 表10 Probit回归剔除指标的过程 3.6基于ROC曲线检验指标体系的有效性 将上文3.5节中筛选出的23个信用评级指标在表6对应行中的数据,代入式(9)~式(12),通过Probit回归模型,求解出式(10)中每个企业的违约概率P(yj=1|Xj).当P(yj=1|Xj)≥0.5时,判为违约;当P(yj=1|Xj)<0.5,判为非违约.相应得到违约分类结果如表11所示.该过程可由Stata软件得到结果. 表11中:Probit回归模型将实际违约的样本判定为违约的个数为21,如表11第1行第1列所示.将实际非违约的样本判定为非违约的个数为1 193,如表11第2行第2列所示.则判断准确率=(21+1 193) /1 231=98.62%.从分类结果可知,筛选出的23个指标对违约状态的鉴定准确性较高. 表11 23个指标通过Probit回归对违约状态的分类结果 ROC曲线是由多个临界值C0对应的灵敏度与特异度构成的.当样本的违约概率大于临界值C0时,即P(yj=1|Xj)≥C0时,Probit模型判定该样本为违约,反之则判为非违约. 表11是以临界值为0.5时的分类结果,将表11第1行数据代入式(14),可得,灵敏度=21/35=0.600;将第2行数据代入式(15),可得,特异度=1 193/1 196 =0.997;对应得到ROC曲线上的一个点(1-特异度,灵敏度)=(1-0.997, 0.600),即(0.003, 0.600). 取不同的临界值,可得到多组灵敏度、特异度,对应可得到多个ROC曲线上的点.以1-特异度为横轴、以灵敏度为纵轴画出ROC曲线,如图3的粗实线所示.可由Stata软件得到ROC曲线图. 图3中,粗实线ROC曲线下方的面积、即反映指标体系鉴别能力的AUC=0.987 6>0.9.所以,由筛选出的23个指标组成的债信评级指标体系对违约状态有较好的区分效果. 图3 ROC曲线图 3.7小企业债信评级指标权重的确定与评价方 程的建立 1)债信评级指标权重的确定 将最终筛选出的23个指标在表6对应数据xij列入表12第1列-第1 231列中,并将数据代入式(16)- 式(17),得到变异系数为指标赋权结果wi,如表12第f列所示.将每个准则层的指标权重加和,为该准则层的权重,如表12第b列~第d列所示. 其中,表12第1行-第8行财务指标的权重之和为0.056+…+0.027=0.44,表12第9行-第23行非财务指标的权重之和为0.008+…+0.024=0.56,即财务指标的重要程度为44%,非财务指标的重要程度为56%. 可见在小企业债信评级指标体系中,非财务指标的重要程度大于财务指标,这与传统信用评级指标体系中常常注重财务指标有所不同.原因是小企业财务指标更加难获取,而且小企业的发展受外界环境的影响与冲击更大,所以非财务指标相对于财务指标更加重要. 2)评价方程的建立 将最终筛出的23个指标在表12第1行~第23行第f列的指标权重代入式(18),得到小企业的信用评价方程 zj=0.065x1,j+…+0.027x46,j+ …+0.024x81,j (20) 将表12第1列~第1 231列数据,代入评价方程(20),得到0至1之间的评价得分zj,结果如表13第3列所示.再将表13第3列评价得分zj代入式(19),化为0到100之间的信用得分Sj,并按照信用得分降序排列,结果如表13第4列所示. 表12 小企业信用评价指标指标权重及标准化后数据 注:第1列~第1 231列数据来自表6. 3.8小企业的信用等级划分 图4 1 231个小企业违约损失率分布 根据上文2.7中的信用等级划分的思路,通过课题组的研究成果[26],对1 231个小企业划分信用等级,结果如表13第5列~第8列所示. 信用得分区间的确定过程,以AAA级为例说明.由表13第5列可知,AAA级共202个样本,表13前202行为AAA等级;AAA级第1个样本得分为100分,最后一个样本为55.66分,则AAA等级的信用得分区间为55.66≤S≤100.同理,可以得到AA、A、…、C其余8个等级的信用得分区间,结果如表13第8列所示. 为了更直接的检验各等级的违约损失率LGD是否呈现金字塔的形状,对表13中第5列、第7列数据做如下处理: 以表13第7列违约损失率LGD大小为底边,以表13第5列等级为高度作图,结果如图4所示. 图4显示:越高的信用等级,其违约损失率越低.表明该信用评价指标体系满足“信用等级越高、违约损失率越低”的原则. 表13 1 231个小企业信用等级划分结果 3.9小企业债信评级指标体系合理性分析 1)小企业债信评级指标体系与5C原则的对应 从表12第g列~第k列的对应关系可知,该指标体系的23个指标涵盖了“5C评价原则”的五个方面,每个方面都有指标与之对应. 一是通过法人代表信用卡记录、企业间合同违约次数等4个指标,反映了5C原则的品德(character)属性,如表12第g列所示. 二是通过总资产报酬率、营业利润率等12个指标,反映了5C原则的能力(capacity)属性,如表12第h列所示. 三是通过速动比率、超速动比率等3个指标,反映了5C原则的资本(capital)属性,如表12第i列所示. 四是通过指标抵质押担保因素,反映了5C原则的担保(collateral)属性,如表12第j列所示. 五是通过行业景气指数、居民消费价格指数等3个指标,反映了5C原则的经营环境(condition)属性,如表12第k列所示. 2)债信评级指标体系反映小企业的贷款特点 一是反映小企业贷款容易受到外部环境的影响.最终构建的债信评级指标体系的23个指标中,“行业景气指数”、“居民消费价格指数”、“城市居民人均可支配收入”三个指标反映了外部宏观条件对小企业的还款的影响,如表12第9行~第11行所示.因为小企业规模小,容易受到市场波动的影响,当行业不景气时,小企业的还款风险也会增大. 二是反映小企业贷款受到非财务因素的影响较大.由上文3.7(1)中可知,对小企业债信评级时,非财务因素的权重为56%,可见非财务因素更能反映小企业的信用资质.小企业财务信息不完善,且财务信息中容易有虚假信息,所以小企业进行债信评级时,非财务指标所占权重比例更高. 4.1主要结论 1)通过对中国某区域性商业银行分布在京、津、沪、渝等分支行的1 231笔小企业贷款借据进行实证,结果表明:速动比率、净资产收益率、行业景气指数、年龄、抵质押担保等23个指标能够显著区分小企业的违约状态. 2)实证结果表明,本文构建的小企业的债信评级指标体系符合“信用等级越高、违约损失率越低”的原则,且满足5C原则. 4.2主要创新与特色 1)通过偏相关分析,在高度相关的指标中,删除F值小、对小企业违约状态判别能力弱的指标,既保证了筛选的指标反映信息不重复,也避免了现有删除重复指标时、对违约状态影响大的指标可能被误删的弊端.且采用偏相关分析弥补了简单相关分析仅仅考虑两个变量间的相关程度,忽略了其余变量影响的不足. 2)通过求解违约状态变量与评价指标之间Probit回归方程的回归系数β和回归系数的标准误差SEβ,构建Wald统计量对回归系数β的显著性进行检验,剔除对小企业违约状态影响小的、β不显著的指标,保证了筛选出的指标能显著区分企业的违约状态. 3)通过构造小企业债信评级指标体系的感受型曲线ROC,测算出ROC曲线下方的面积AUC值,用于检测整个指标体系区分违约状态的有效性.弥补了单个指标对违约状态影响显著,而构建的整个指标体系可能对违约状态鉴别能力不强的弊端. [1]中华人民共和国工商行政管理总局. 国家工商总局发布小微企业发展情况报告[EB/OL]. 中华人民共和国工商行政管理总局网站. http://www.saic.gov.cn/ywdt/gsyw/zjyw/xxb/201403/t20140331_143496.html. 2014-03-31. State Administration for Industry & Commerce of the People’s Republic of China. The small enterprises development report[EB/OL]. State Administration for Industry & Commerce of the People’s Republic of China Website. http://www.saic.gov.cn/ywdt/gsyw/zjyw/xxb/201403/t20140331_143496.html. 2014-03-31.(in Chinese) [2]中国人民银行调查统计司. 2014年第1季度银行家调查问卷[EB/OL]. 中国人民银行网站. http://www.pbc.gov.cn/publish/diaochatongjisi/193/2014/20140321155104356260357/20140321155104356260357_.html. 2014-04-25.Satistics and analysis department of the Pepple’s Bank of China. The questionnaire report from bankers in the first quarter of 2014[EB/OL]. http://www.pbc.gov.cn/publish/diaochatongjisi/193/2014/20140321155104356260357/20140321155104356260357_.html.2014-04-25. (in Chinese) [3]Ileana Nicula. Some aspects concerning the measurement of credit risk[J]. Procedia Economics and Finance, 2013, 6: 668-674. [4]吴青. 《巴塞尔协议II》、内部信用评级及小企业贷款[J]. 国际金融研究, 2007, (5): 44-53. Wu Qing. The Basel II, Internal credit rating and small-business loans[J]. Studies of International Finance, 2007, (5): 44-53.(in Chinese) [5]Standard & Poor’s. Standard & Poor’s Guide to Credit Rating Essentials[R]. New York: Standard &Poor’s, 2011. [6]Fitch Ratings. Fitch Ratings Global Corporate Finance 2012 Transition and Default Study[R]. New York: Credit Market Research-Fitch Ratings, 2013. [7]大公资信评估有限公司. 大公信用评级方法及流程[EB/OL]. 大公资信评估有限公司网站, http://www.dagongcredit.com/ratingSystem/contents1.html. 2012-09-24. Dagong Global Credit Rationg Co. Credit rationg method and process[EB/OL]. Dagong Global Credit Rationg Co. website.http://www.dagongcredit.com/ratingSystem/contents1.html.2012-09-24.(in Chinese) [8]中国银行. 中国银行股份有限公司客户信用评级指标体系与评分标准说明[R]. 中国银行有限公司, 2010. Bank of China. Credit Rating Index System and the Definition of Scoring Standard for Custom in Bank of China[R]. Bank of China Ltd. 2010. (in Chinese) [9]中国建设银行. 中国建设银行小企业客户评价办法[R]. 北京: 中国建设银行, 2007. China Construction Bank. Enterprise Customer’s Credit Rating Rules of CCB[R]. Beijing: China Construction Bank, 2007. (in Chinese) [10]Li Z, Chi G. Factors Study of Credit Risks of Farmer Loans Based on Projection Pursuit[C]//Dongguan: Service Operations and Logistics, and Informatics (SOLI) 2013 Ieee International Conference on, 2013: 274-277. [11]Psillaki M, Tsolas I E, Margaritis D. Evaluation of credit risk based on firm performance[J]. European Journal of Operational Research, 2010, 201(3): 873-881. [12]Shi B F, Chi G T. A credit risk evaluation index screening model of petty loans for small private business and its application[J]. Advances in Information Sciences and Service Sciences, 2013, 5(7): 1116-1124. [13]马晓青, 刘莉亚, 胡乃红, 等. 小企业信用评估的模型构建与实证分析[J]. 财经研究, 2012, 38(5): 28-37. Ma Xiaoqing, Liu Liya, Hu Naihong, et al. The credit rating model for small enterprise and empirical study[J]. Journal of Finance and Economics, 2012, 38(5): 28-37.(in Chinese) [14]Altman E I. Predicting Financial Distress of Companies: Revisiting the Z-score and ZETA Models[R]. New York: Stern School of Business, New York University, 2000. [15]Maria D C, Antonio B O, Rafael P M, et al. Improving the management of microfinance institutions by using credit scoring models based on statistical learning techniques[J]. Expert Systems with Applications, 2013, 40(17): 6910-6917. [16]高丽君. 基于贝叶斯模型平均生存模型的中小企业信用风险估计[J]. 中国管理科学, 2012, S1: 327-331. Gao Lijun. The estimation of credit risk of SMEs based on Bayesian model averaging survival model[J]. Chinese Journal of Management Science, 2012, S1: 327-331.(in Chinese) [17]Hong Sik Kim, So Young Sohn. Support vector machines for default prediction SMEs based on technology credit[J]. European Journal of Operational Research, 2010, 201(3): 838-846. [18]Niccolò Gordoni. Agenetic algorithm approach for SMEs bankruptcy prediction: Empirical evidence from Italy[J]. Expert Systems with Applications, 2014, 41(14): 6433-6445. [19]Blanco A, Pino-mejías R, Lara J, et al. Credit scoring models for the microfinance industry using neural networks: Evidence from Peru[J]. Expert Systems with Applications, 2013, 40(1): 356-364. [20]肖进, 刘敦虎, 顾新, 等. 银行客户信用评估动态分类器集成选择模型[J]. 管理科学学报, 2015, 18(3): 114-126. Xiao Jin, Liu Dunhu, Gu Xin, et al. Dynamic classifier ensemble selection model for bank customer’s credit scoring[J]. Journal of Management Sciences in China, 2015, 18(3): 114-126.(in Chinese) [21]余高锋, 刘文奇, 石梦婷. 基于局部变权模型的企业质量信用评估[J]. 管理科学学报, 2015, 18(2): 85-94. Yu Gaofeng, Liu Wenqi, Shi Mengting. Credit evaluation of enterprise quality based on local variable weight model[J]. Journal of Management Sciences in China, 2015, 18(2): 85-94.(in Chinese) [22]朱钧钧, 谢识予, 许祥云. 基于空间Probit面板模型的债务危机预警方法[J]. 数量经济技术经济研究, 2012, 10: 100-114. Zhu Junjun, Xie Shiyu, Xu Xiangyun. Debt crisis eearly warning method: Application of a spatial probit panel model[J]. The Journal of Quantitative & Technical Economics, 2012, 10: 100-114.(in Chinese) [23]Abdou H A, Pointon J. Credit scoring, statistical techniques and evaluation criteria: A review of the literature[J]. Intelligent Systems in Accounting, Finance and Management, 2011, 18(2-3): 59-88. [24]刘新华, 线文. 我国中小企业融资理论述评[J]. 经济学家, 2005, (2): 105-111.Liu Xinhua, Xian Wen. The reviews on Chinese SME financing theory[J]. Economist, 2005, (2): 105-111.(in Chinese) [25]徐广军, 倪晓华, 肖运香. 标普、穆迪、邓白氏企业信用评价指标体系比较研究[J]. 浙江金融, 2007, (3): 51-52. Xu Guangjun, Ni Xiaohua, Xiao Yunxiang. The comparative study among S&P, Moody’s, Dun &Brad street enterprise credit evaluation index system[J]. Zhejiang Finance, 2007, (3): 51-52.(in Chinese) [26]大连理工大学迟国泰课题组. 中国邮政储蓄银行农户小额贷款信用风险决策评价研究[R]. 大连: 大连理工大学, 2011. Chi Guotai research group in DLUT. Credit Risks Evaluation and Decision System of Microcredit for Farmers for Postal Savings Bank of China[R]. Dalian: Dalian University of Technology, 2011.(in Chinese) [27]程砚秋. 基于支持向量机的农户小额贷款决策评价研究[D]. 大连: 大连理工大学, 2011. Cheng Yanqiu. Research on Evaluation and Decision System of Small Amount Loans for Farmers Based on Support Vector Machines[D]. Dalian: Dalian University of Technology, 2011.(in Chinese) [28]威廉.H.格林. 计量经济分析[M]. 第六版. 北京: 中国人民大学出版社, 2011: 759-781. Greene W H. Econometric Analysis[M]. 6th Edition. Beijing: China Renmin University, 2011: 759-781.(in Chinese) [29]张建国. ROC曲线分析的基本原理以及在体质与健康促进研究中的应用[J]. 体育科学, 2008, (6): 62-66. Zhang Jianguo. The basic principle of ROC curve analysis and application in physical fitness and health promotion studies[J]. China Sport Science, 2008, (6): 62-66.(in Chinese) [30]工业和信息化部, 国家统计局, 国家发展和改革委员会, 财政部. 中小企业划型标准规定[R]. 北京: 工业和信息化部, 国家统计局, 国家发展和改革委员会, 财政部, 2011. Minstry of Industry and Information Technology, National Bureau of Statistics, National Development and Reform Commission. Standard type division formiddle and small-sized enterprises[R]. Beijing: Minstry of Industry and Information Technology, 2011.(in Chinese) The debt rating for small enterprises based on Probit regression CHIGuo-tai,ZHANGYa-jing,SHIBao-feng Faculty of Management and Economics, Dalian University of Technology, Dalian 116024, China Debt rating of small enterprises means a system that evaluates the size of a small enterprise’s credit level and LGD (Loss Given Default). It concerns the risk management of bank loans and whether small enterprises can get financing. Therefore, the indicators of credit rating must be able to identify the status of non-compliance of small enterprises. Existing credit rating system, aiming to rate scale and sort, does not evaluate the size of a debt LGD, and does not give evidence that its rating system is relevant to identify non-compliance. This article selects a index system according to the ability to identify the default status of enterprises, and establishes a credit rating system of small enterprises. This article has some innovations and features. Firstly, the paper deletesan index whose F-value is small and whose ability to distinguish the status of non-compliance of small enterprises is weak between one pair of highly related indicators which have partial correlation coefficients greater than 0.7 and reflect the duplication of information. This avoids information redundancy of the rating system after first section and at the same time avoids mistakenly deleting the index that has a big influence on the status of non-compliance. This paper improves the situation that existing credit rating system’s selection is unrelated to the ability to identify non-compliance. Secondly, the paperbuilds the Wald statistic to test for the significant of the Probit regression coefficient,β, through solving the regression coefficient,β, and the standard error,SEβ,of the regression coefficient between the default state variables and evaluation, and deletes the index that has a small influence on the status of non-compliance and whose regression coefficient,β, is not significant. The index can distinguish significantly the status of non-compliance of enterprises after the second selection. Thirdly, the AUC area of the indicator system’s experience curve built by this paper is greater than 0.9, and this guarantees the index system has a strong identification ability for the status of non-compliance. Fourthly, the results show the weight of the non-financial indicators, for small enterprises having a higher the credit rating and lower LGD, in the credit rating system is 56%. Finally, the empirical analysis for 1 231 small enterprises shows there are 23 indicators, involving the quick ratio, total asset growth, industry sentiment index, which can be used to distinguish the status of non-compliance of small enterprises. small businesses; debt rating; data mining; Probit regression ① 2015-03-26; 2015-12-25. 国家自然科学基金资助项目(71171031; 71471027); 国家自然科学基金青年科学基金资助项目(71201018; 71503199); 教育部人文社会科学研究青年基金资助项目(11YJC790157); 辽宁经济社会发展重点课题资助项目(2015lslktzdian05); 辽宁省博士启动基金资助项目(20131017); 河北省自然科学基金青年科学基金资助项目(G2012501013); 教育部科学技术研究项目(2011-10); 中国银监会银行业信息科技风险管理项目(2012-4-005); 大连银行小企业信用风险评级系统与贷款定价项目(2012-01); 中国邮政储蓄银行总行小额贷款信用风险评价与贷款定价资助项目(2009-07).本文入选“第十二届金融系统工程与风险管理年会”优秀论文(山西大学, 2014年8月). 迟国泰(1955—), 男, 黑龙江海伦人, 博士, 教授, 博士生导师. Email: chigt@dlut.edu.cn F830.56 A 1007-9807(2016)06-0136-21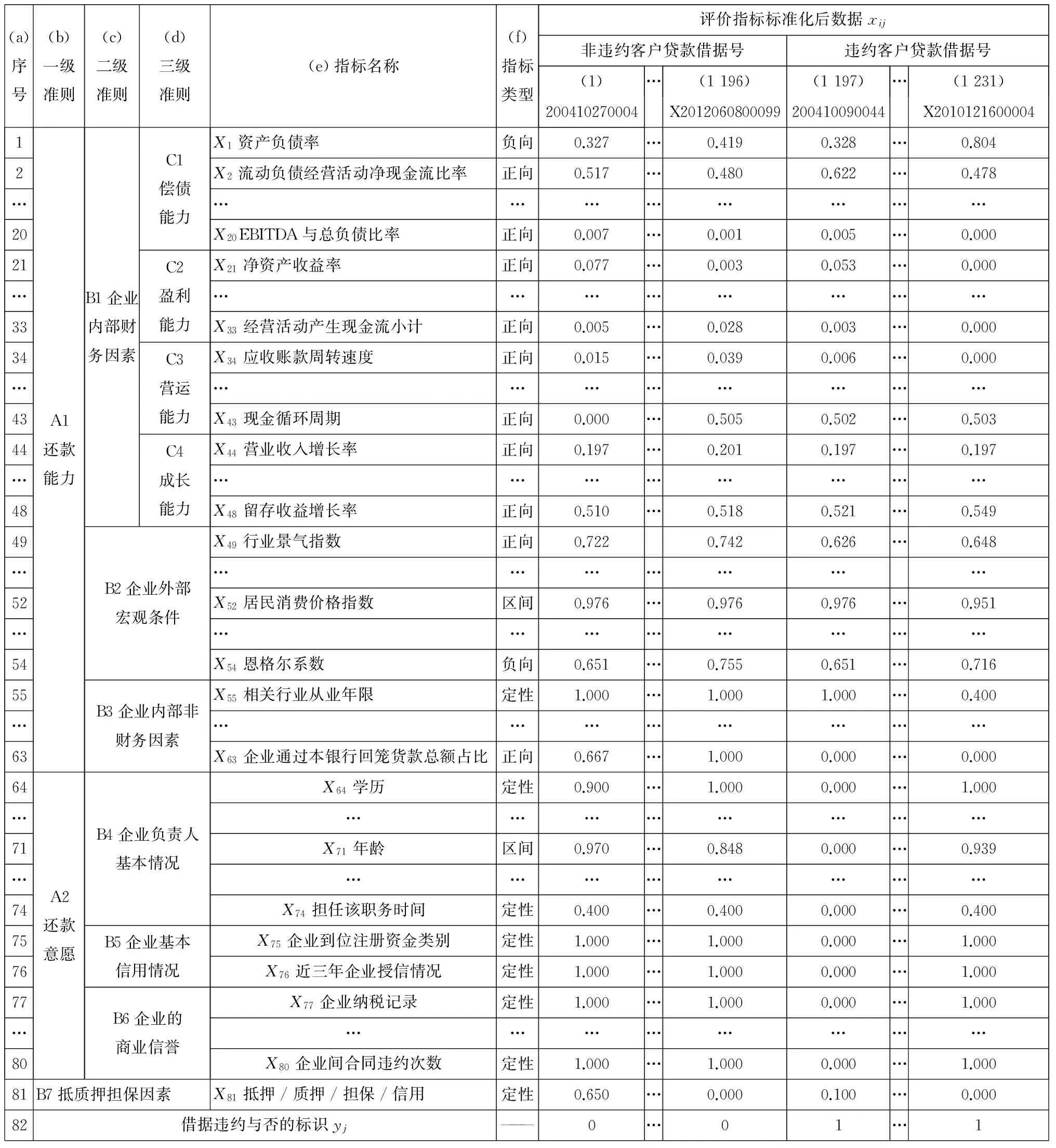




4 结束语
