基于Kullback-Leiber距离的迁移仿射聚类算法
2016-08-30毕安琪王士同江南大学数字媒体学院无锡214122
毕安琪 王士同(江南大学数字媒体学院无锡214122)
基于Kullback-Leiber距离的迁移仿射聚类算法
毕安琪*王士同
(江南大学数字媒体学院无锡214122)
针对迁移聚类问题,该文提出一种新的基于Kullback-Leiber距离的迁移仿射聚类算法(TAP_KL)。该算法从概率角度重新解释AP算法的目标函数,并借助于信息论中最常见的一种距离度量,即Kullback-Leiber距离,测量源域与目标域代表点的相似性。另外,通过详细分析TAP_KL算法与AP算法的目标函数,得出一个重要结论,即可以将源域与目标域的相似性嵌入到目标域数据集相似性矩阵的计算中,从而直接利用AP算法的优化算法优化TAP_KL算法的目标函数,解决基于代表点的迁移聚类问题。最后,通过基于4个数据集的仿真实验,进一步验证了TAP_KL算法在解决迁移聚类问题时的有效性。
仿射聚类算法;迁移学习;人脸数据集;概率框架;KL距离
1 引言
近年来,国内外研究学者从不同角度对迁移学习的研究已经取得了众多重要研究成果[18]-,包括迁移SVM(Support Vector Machine)算法[12],、迁移Adaboost算法[34]-,以及基于流形结构的MMDE(M axim um M ean D iscrepancy Em bedd ing)算法[56]-。然而聚类算法作为机器学习和模式识别领域的一个重要研究方向,现阶段对于迁移聚类算法的研究并不充分,取得的成果也不多[8]。聚类算法的目标是将相似的数据聚集为一个数据簇,并使差异较大的数据分别属于不同的数据簇。目前广泛使用的聚类算法,包括K-均值算法[9,10]、谱聚类算法[11,12]、仿射聚类(A ffinity,Propagation,AP)[1319]-以及模糊聚类方法[20]都是在数据量足够充分的前提下,才能保证算法得到可靠的、有效的聚类结果。因此,这些算法都不适用于迁移学习的场景中,本文就是针对迁移聚类问题进行研究探讨。
聚类算法的一个重要研究方向就是从已经存在的样本点中选择算法所得的数据簇类中心,这类算法统称为基于代表点的聚类算法,其中最具代表性的算法包括AP算法[13],EEM算法(Enhanced α-Expansion Move)[18,19]等。研究指出,基于代表点的聚类算法的目标函数均可以看作是马尔科夫随机场(M arkov Random Field,MRF)的能量函数,相应地,AP算法与EEM算法本质上是在优化相同的目标函数,其中AP算法使用的优化算法是基于样本点之间的信息传递,而EEM算法则基于Graph-Cuts。另一方面,基于代表点的聚类算法的一个重要优势在于算法可以根据数据集自动完成聚类,而不要求预设数据簇的总数。对于现有的迁移学习算法,一个重要的问题是如何基于源域与目标域数据的相似性,更好地借助于源域数据的研究成果完成对目标域数据的研究。在基于代表点的聚类算法中,进一步可以认为源域与目标域的相似性表现为源域与目标域代表点集合的相似性。具体地,本文首先从概率角度重新解释AP算法的目标函数,通过定义样本点和代表点的概率关系,以及代表点集合的先验概率,为度量源域与目标域代表点集合的相似性提供前提条件;其次,借助于信息论中最常见的一种距离度量,即Kullback-Leiber距离(KL距离),在概率框架下测量源域与目标域代表点的相似性,提出了TAP_KL算法的目标函数;最后,通过详细分析TAP_KL算法与AP算法的目标函数,得出一个重要结论,即可以将源域与目标域的相似性嵌入到目标域数据集相似性矩阵的计算中,从而直接借助AP算法的优化策略解决新的目标函数。
2 AP算法
2007年,文献[13]中指出,在聚类算法中,若取得的类中心点是从已存在的样本点中选择的,则称这类聚类算法为基于代表点聚类算法,并称这些类中心点为代表点。同时,文献[13]提出一种典型的基于代表点聚类算法,即AP聚类算法,其目标函数可以表示为
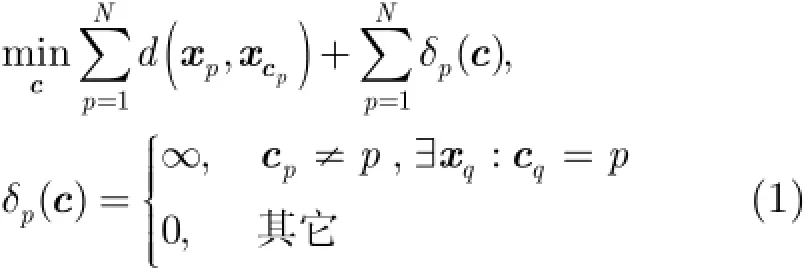
将上述目标函数的优化过程可以看作MRF的能量函数最小化过程,事实上,所有的基于代表点聚类算法的目标函数优化问题都可以看作是MRF的能量函数寻优问题。AP算法使用基于信息传递的LBP(Loopy Belief Propagation)优化算法来优化式(1)。在具体优化过程中,算法首先定义2个矩阵分别存储样本点传递给代表点的信息和代表点传递给样本点的信息,具体定义为
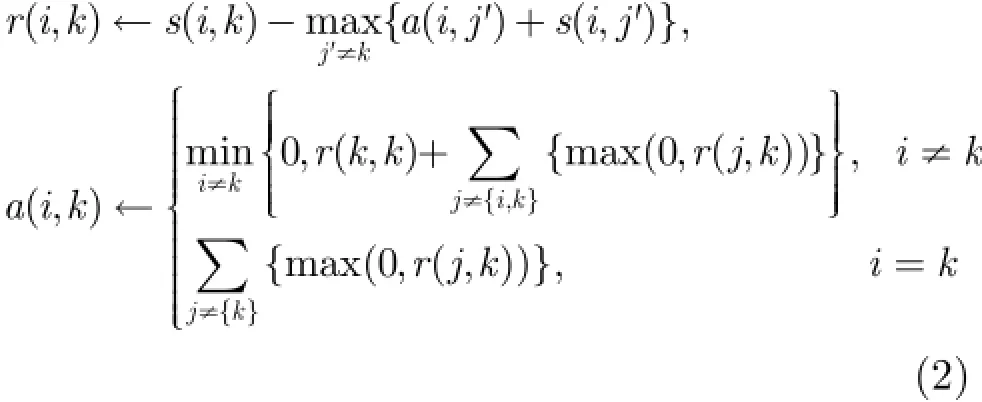
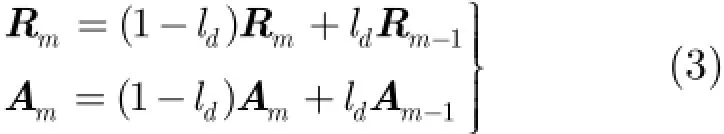
AP算法不需要提前预设聚类总数,算法能够根据数据集的相似性矩阵,自动计算出合适的聚类总数,从而获取有效的聚类结果;另一方面,实验证明AP算法所得到的聚类性能相当有效与稳定。基于这两个优势,近年来AP算法得到了国内外研究者的广泛关注,并已经取得了若干重要研究成果,其中包括半监督AP算法[14],递增式AP算法[16,17]等。为了解决迁移聚类问题,本文在保留原始AP算法以上两个优势的基础上,提出了一种改进的AP算法,即基于Kullback-Leiber距离的迁移仿射聚类算法。
3 基于Kullback-Leiber距离的迁移仿射聚类算法
迁移聚类问题涉及到两个数据集,即源域数据集与目标域数据集。因此,如何准确地度量目标域与源域数据集之间的相似性,以及目标域数据集样本间的相似性,是亟待解决的问题。另一方面,概率框架能够准确地体现数据的分布特征,而在信息论中已知若干种距离可用来度量两个概率分布的相似性。
因此,本文首先利用概率的信息表征特征,引入概率框架重新解释AP算法目标函数的合理性及有效性,其次,在新的目标函数的基础上,利用Kullback-Leiber距离度量源域数据集与目标域数据集的相似性,进而发现可以将源域与目标域的相似性嵌入到目标域数据集的相似性矩阵的计算中,并借助AP算法的优化算法解决迁移仿射聚类问题。
3.1 AP算法的概率框架下解释
在信息论中,概率能够更好地体现数据的分布特征。而在迁移学习中,较准确的表示源域和目标域的数据分布是解决其他问题的基础和前提。因此,本节首先引入相关的概率定义,然后表明在高斯概率假设下,可诱导出等价的AP算法的目标函数。换句话说,通过引入概率框架,我们可以重新解释AP聚类算法的目标函数,进而给出AP算法基于概率框架的目标函数。该概率框架为之后解决迁移学习中的聚类问题提供了可靠的基础。
令E表示代表点的下标集合,基于样本点与代表点间的相似度,定义样本点选择作为代表点的概率为
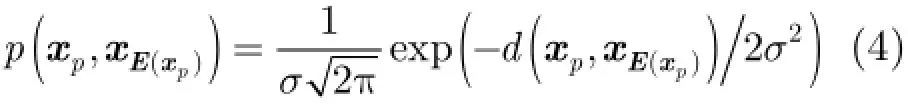
其次,若当前代表点集合中存在某代表点选择除自己以外的其他代表点,则当前代表点集合无效,即与AP算法的目标函数类似,在概率框架下也可以通过定义来避免这类无效的代表点集合的产生。因此,代表点集合的先验概率为
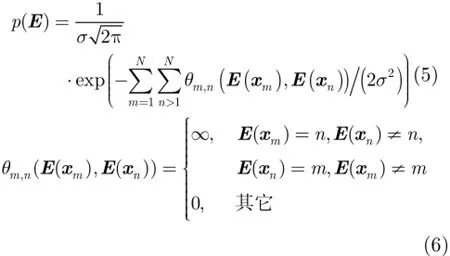
由于聚类过程要求算法找到一个有效的代表点集合,并使以上两项概率值最大。因此,从概率角度重新解释AP算法,得到的新的目标函数为
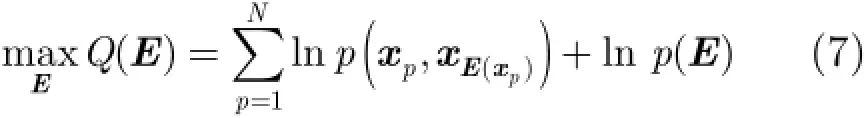
其中,N表示数据集中样本点的个数,E表示每个样本点所选择的代表点下标集合。进一步简化目标函数式(7),并忽略常数项的影响,可以认为式(7)与AP算法的目标函数式(1)是等价的。
因此,本节通过从概率角度重新考虑基于代表点的AP聚类算法,推导出了同样的AP算法的目标函数,这将为有效利用AP算法解决迁移聚类问题提供了前提条件;也就是在解决迁移聚类问题的时候,可以进一步利用概率来度量源域与目标域样本的关系。
3.2基于Kullback-Leiber距离的迁移仿射聚类算法TAP_KL
在试图利用AP聚类框架解决迁移聚类问题的时候,选择一种可以测量源域与目标域数据分布的距离公式具有重要作用。尽管我们可以采用其他的方法(如卡方检验(Chi-Square),Hausdorff距离)来研究迁移聚类。但这里我们选择KL距离,其原因是:(1)KL距离是信息论中最常见的一种距离度量方法。(2)基于KL距离,我们发现所得到的目标函数可以直接使用AP算法的优化算法,而不需要重新构建新的优化算法。这也是本文的贡献之一。KL距离是信息论中最常见的一种距离度量,这种距离从统计学角度测量两个概率分布之间的相似性。假设存在两个概率分别为P和Q,则概率分布P到概率分布Q的KL距离定义为
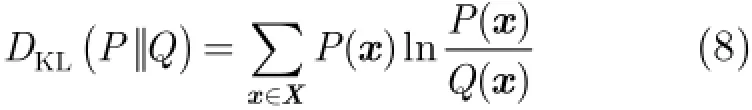
基于代表点的迁移聚类算法要求目标域产生的代表点集合与源域的代表点集合尽可能相似。具体地,首先目标域中的样本点px从源域代表点集合中选择最合适的代表点
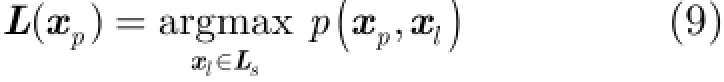
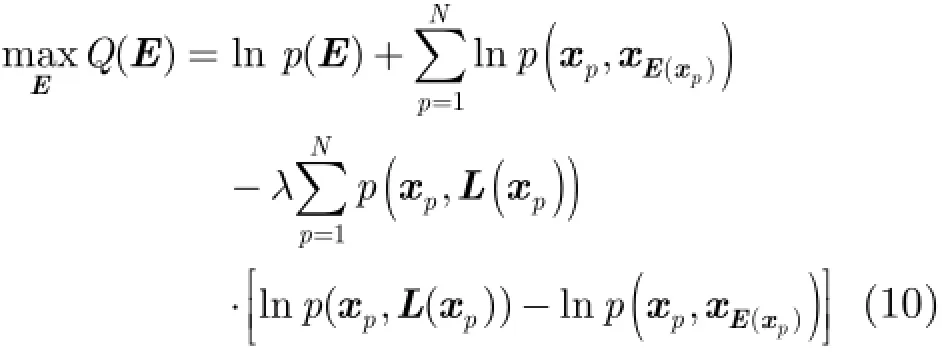
进一步简化式(10),并忽略对优化过程无影响的常数项,得到目标函数为
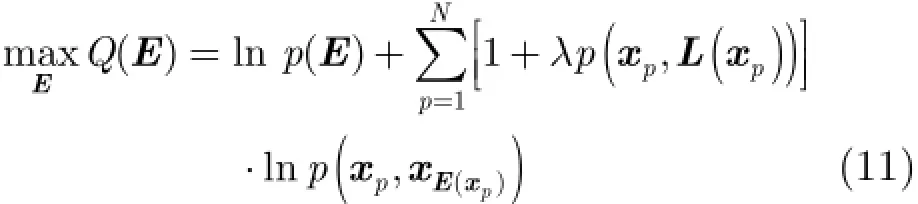
上述目标函数式(11)与AP算法的目标函数具有高度的相似性,因此可以借鉴AP算法的优化算法来优化式(11)。
3.3 TAP_KL与AP算法
3)开关量接点丰富,继电保护测试仪7路接点输入和2对空接点输出,输入接点为空接点和0~250V接点兼容;同时其自我保护结构设计具备一定散热性,本身具有可靠完善的多种保护措施和电源软启动,因此,微机继电保护装置整体性价比较高。
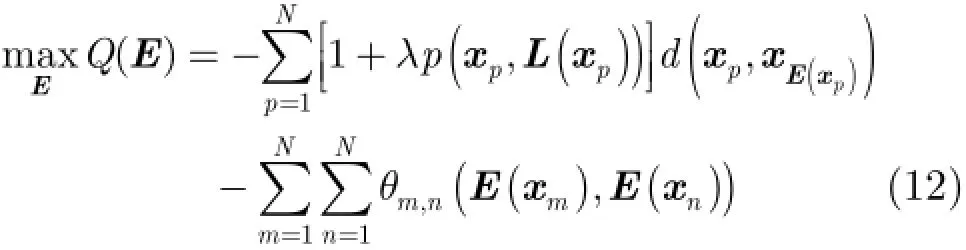
另一方面,从样本间相似性角度来说,AP算法的目标函数可以表示为
式(13)则等价于TAP_KL的目标函数式(12)。
综上所述,通过使用不同的相似性度量手段,式(13)分别扩展为AP算法的目标函数式(1)和式(12)。在AP的优化过程中,通过定义2个矩阵传递样本间的信息,2个矩阵A和R的定义如式(2)所示,其迭代公式如(4),A和R均与数据集的相似性矩阵S有关。因此,在优化TAP_KL算法的目标函数式(14)时,只需将新的相似性矩阵S代入矩阵A和R的计算中,而其他设置不变。由于新的相似性矩阵定义中嵌入了度量源域与目标域相似性的一项此时优化算法得到的结果既考虑了目标域样本间的相似性,也考虑了源域与目标域之间的相似性。TAP_KL算法的具体聚类步骤如表1所示。

表1 TAP_KL算法
TAP_KL算法在解决迁移聚类问题的时候,(1)继承了AP算法的优势,即不需要预设所得数据簇总数;(2)由于将源域与目标域的相似性嵌入到目标域相似性矩阵的计算中,TAP_KL算法不需要重新构建新的优化算法,而是直接利用AP算法的优化算法解决迁移聚类问题,算法的时间和空间复杂度均不会增加。因此,TAP_KL算法在保持了与AP算法一致的时间与空间复杂度时,有效地解决迁移聚类问题。
4 仿真实验
本文通过若干仿真实验,进一步验证TAP_KL算法的有效性,为构建合理的迁移数据集,实验中选取了4个真实数据集,并将其与AP算法、TSC(Transfer Spectral Clustering)算法[8]比较。
4.1数据集与评价标准
本文主要使用两个评价指标来测试TAP_KL算法的聚类性能,即芮氏指标(Rand Index,RI)[21]与归一化互信息(Normalized Mutual Inform ation,NM I)[19]。RI和NM I的值均在[0,1]区间内,且其值越接近1,算法所得的聚类性能越好。由于人脸数据集呈现出明显的非线性流形结果,且同一个类别的人脸图像,在不同的光照条件以及面部表情时,能够拥有很高的相似性。因此,本文采用如表2所示的Extend Yale B,Yale和O livetti 3个人脸数据集作为实验数据集[22,23]。另一方面,为了从不同类型数据集验证算法的有效性,本文还采用了MNIST手写体数据[24]。对于Extend Yale B和MNIST数据集,随机选取部分样本作为源域,剩余的少部分样本构成目标域;对于样本量不充分的Yale与O livetti数据集,实验中通过图片顺时针旋转5°、逆时针旋转5°、缩放0.9倍、缩放1.1倍,人为构造源域与目标域数据集[7,25]。为了更准确的分析比较各类聚类算法的聚类性能,本节中的实验结果均是随机进行30次所得。
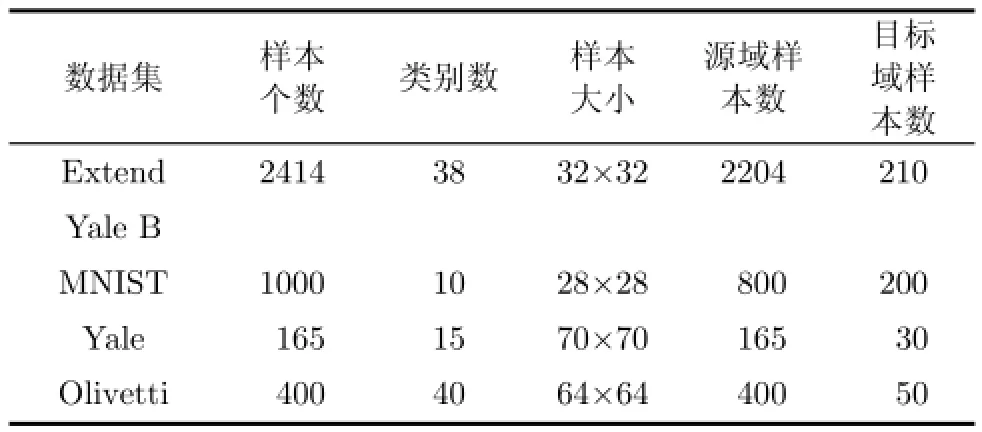
表2 各数据集描述

表3 参数设置
4.2实验结果分析
需要说明的是,与文献[19]中的实验部分一致,针对Yale和O livetti数据集,首先对图像进行高斯核滤波处理,高斯核参数为0.5,其次对图像进行均值为0,方差为0.1的归一化处理。TAP_KL算法和AP算法中的偏向参数α的设置将会影响算法所得的簇总数,α越大,算法所得的簇总数越少,反之,越小的α将导致越多的簇总数。综合数据集的真实类标以及文献[13]中偏向参数α的设置办法,本节中实验参数如表3所示。另外,TSC算法要求预先设定算法所得的簇总数,以及其他若干参数,由于篇幅原因,表3并没有标识出TSC算法的所有参数,涉及的有关参数的设置均遵循文献[8]。
针对正则化参数λ对TAP_KL算法聚类性能的影响,目标函数式(17)中第1,第2项拥有同样的量纲,因此λ的取值不必太大,λ可以在{1,2,3,4,5,6,7,8,9,10}范围内进行网格寻优。表4中列出了λ∈{1,3,5,7,10}时,基于各数据集的TAP_KL算法的聚类结果,并从平均值及标准差的角度进行说明。分析表中数据可知,λ从{1,2,3,4,5,6,7,8,9,10}范围内进行网格寻优是可靠的。
为了公正、准确地分析比较各类聚类算法,实验中的各类算法都在数据集中运行多次,借助多个聚类评价指标,并通过t检验(t-test)统计分析各类算法在不同数据集上的实验结果。基于4个数据集的各类算法的聚类结果具体如表5-表7所示,以TAP_KL算法为基准,采用t检验统计分析各算法的聚类性能,所得结果如表8所示,其中所有参数设置均如表3所示。值得指出的是,当表8中的p值小于0.05时,统计学中认为成对比较的两类实验结果具有显著性不同。由于O livetti数据集的高维度以及高类别数,基于O livetti数据集的TSC算法运行时间过长,因此本文未将其与TAP_KL算法比较。分析各算法的聚类性能,所得实验结论如下:
(1)分析表5-表7,考虑到TAP_KL算法在聚类性能RI与NM I的表现,在源域样本数充分而目标域样本数不足的情况下,TAP_KL算法能够借助源域的聚类结果完成目标域的聚类任务,并得到可靠的聚类结果。
(2)由于目标域的数据集不充分,原始AP算法所得的聚类性能低于迁移聚类算法的性能,尤其是基于人脸数据集的实验中,当λ取值合理时,根据表8中TAP_KL算法与AP算法的t检验统计分析结果,TAP_KL算法的性能完全优于原始的AP算法;
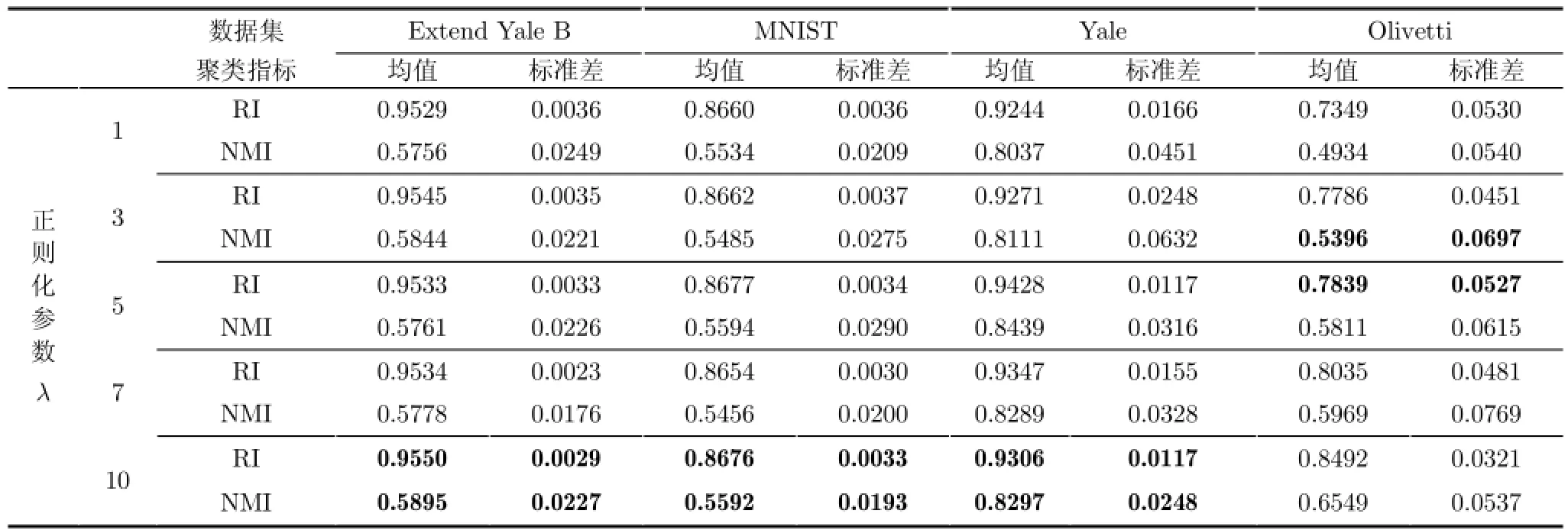
表4 TAP_KL算法在不同λ时的聚类结果
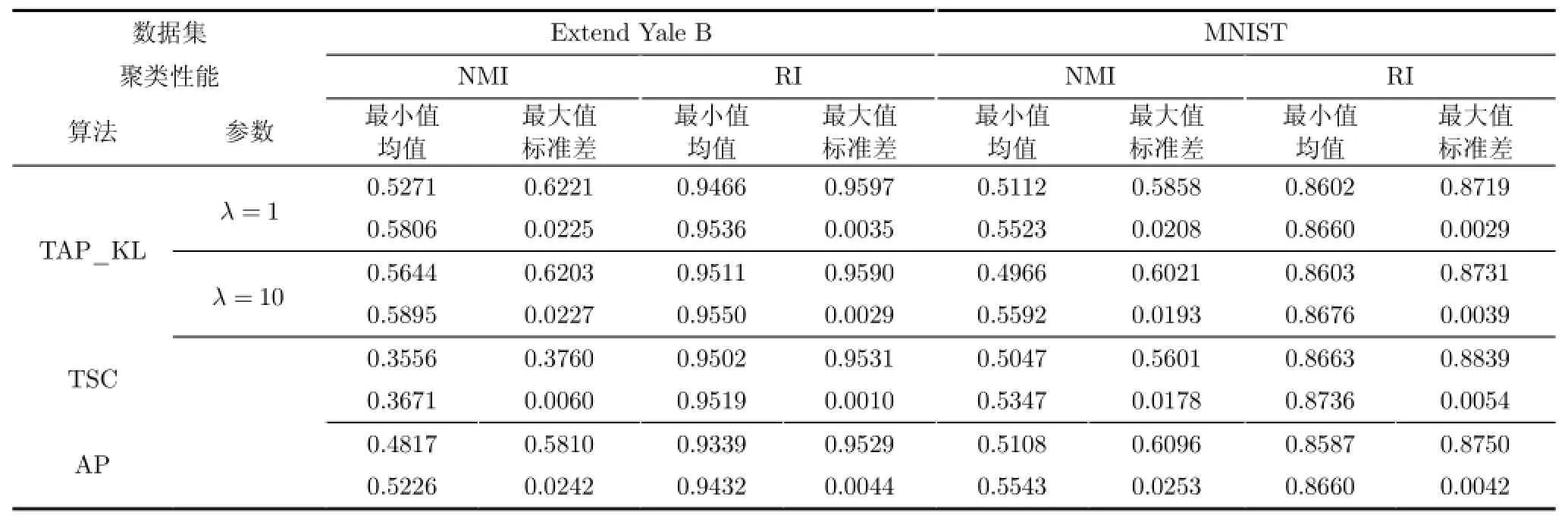
表5 各算法基于数据集聚类性能比较
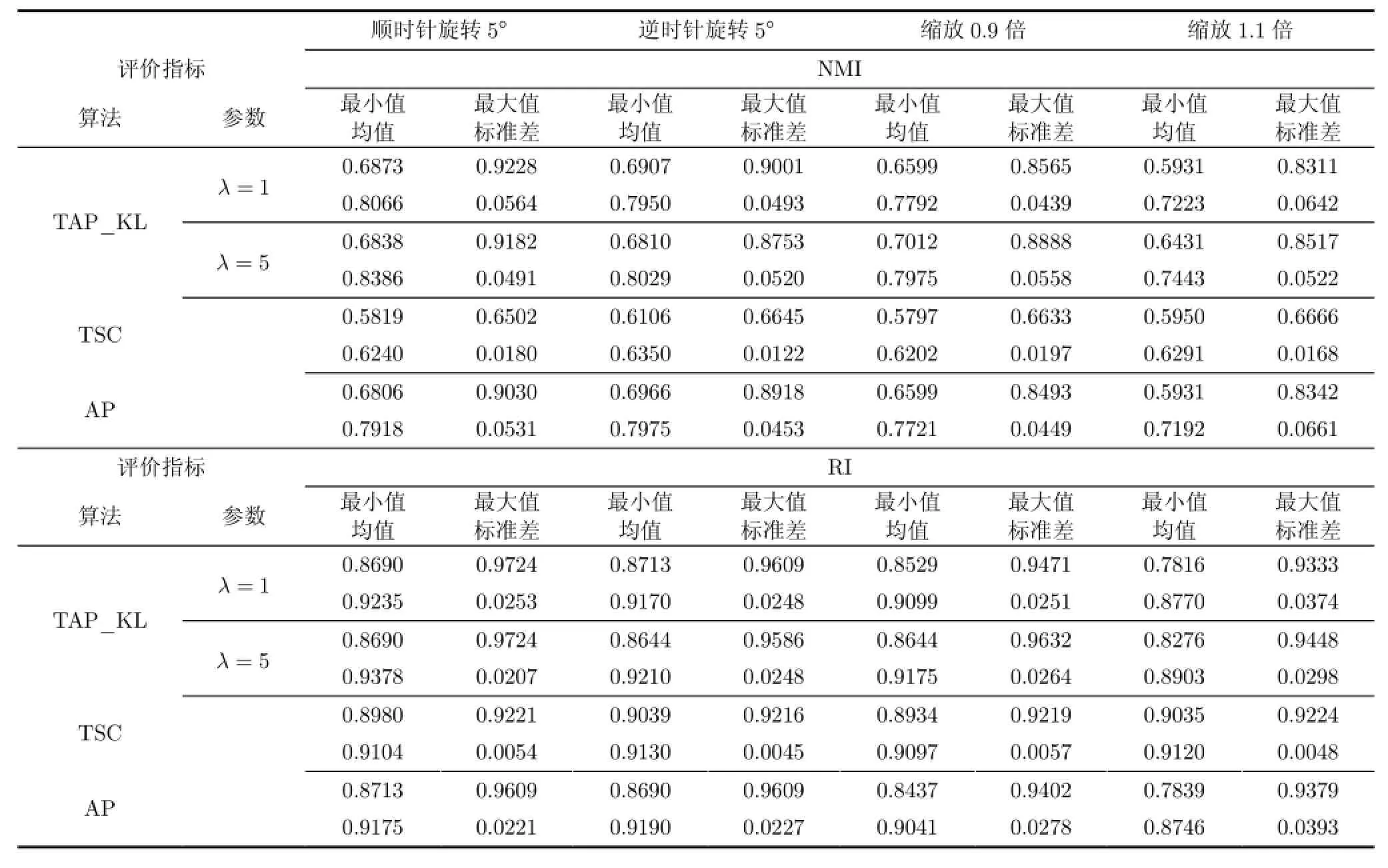
表6 各算法基于Yale数据集聚类性能
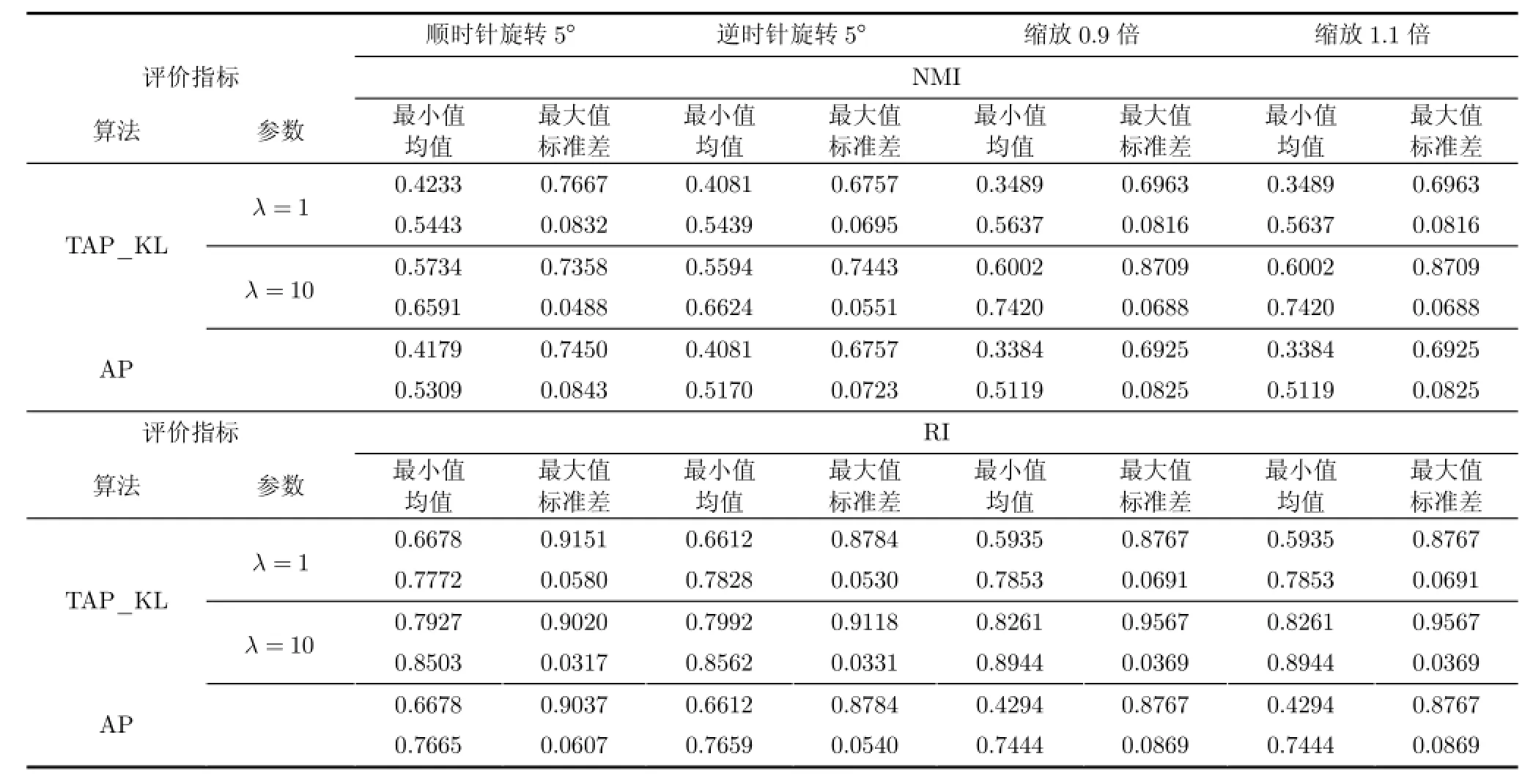
表7 各算法基于Olivetti数据集的聚类性能
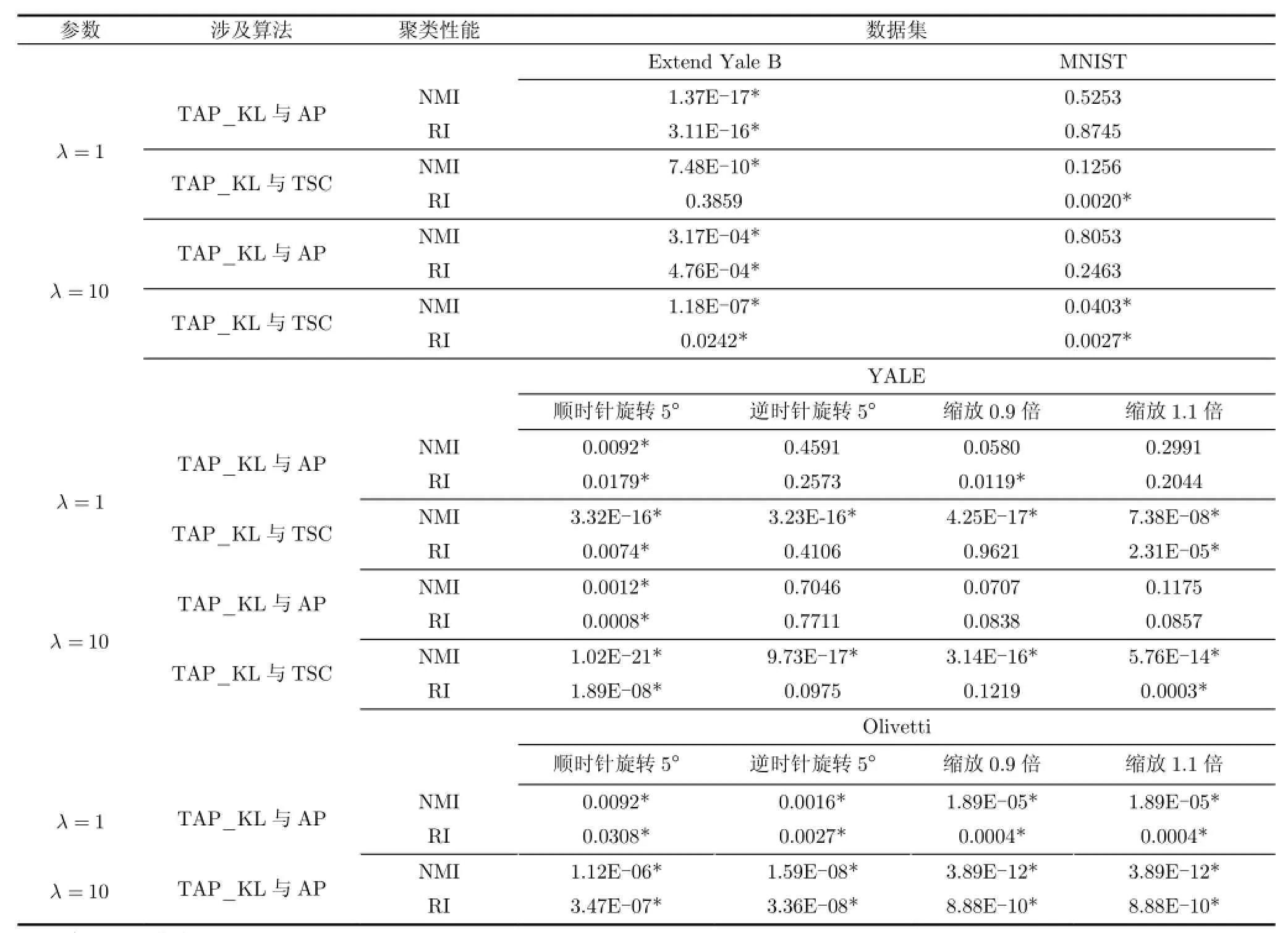
表8 各数据集t检验结果
(3)在与TSC算法的比较中,值得指出的是,TSC算法需要预设数据集的簇总数。在这个前提下,表8中TAP_KL算法与TSC算法的t检验统计分析结果显示,在解决本节中涉及到的4个数据集的迁移聚类问题时,TAP_KL算法的性能优于TSC算法。
5 结束语
本文针对迁移聚类问题,提出了一种新的基于Kullback-Leiber距离的迁移仿射聚类算法,即TAP_KL算法。相对于其他聚类算法,本文研究了基础的AP算法,并进行改进以解决迁移聚类问题。TAP_KL算法首先从概率角度重新解释AP算法的目标函数。其次借助于信息论中的KL距离,测量源域与目标域代表点集合的相似性。最后,通过详细分析TAP_KL算法与AP算法的目标函数,得出一个重要结论,即可以将源域与目标域的相似性嵌入到目标域数据集相似性矩阵的计算中,从而直接利用AP算法的优化算法解决新的迁移聚类问题。仿真实验分析进一步验证了TAP_KL算法在解决迁移聚类问题时的有效性。虽然本文所提算法在解决迁移聚类问题时体现了较高的可靠性,算法仍然存在一些需要解决的问题。例如,算法的聚类性能并不十分稳定,在多次重复的随机实验中出现了一定的差别及较高的标准差,如何提高算法的稳定性是一个非常重要的工作,我们将在未来的工作中做更深入的研究。另外,信息论中存在多种距离度量方法,其他距离是否可以度量源域与目标域的相似性,并进而发展出一种新的迁移聚类算法也是我们在以后的工作中会关注的方向。
[1]LONG M,WANG J,DING G,et al.Adaptation regularization:A general framework for transfer learning[J]. IEEE Transactions on Know ledge and Data Engineering,2014,26(5):1076-1089.doi:10.1109/TKDE.2013.111.
[2]毕安琪,王士同.基于SVC和SVR约束组合的迁移学习分类算法[J].控制与决策,2014,29(6):1021-1026.doi:10.13195 /j.kzyjc.2013.0520.
BIAnqiand WANG Shitong.Transfer classification learning based on com bination of both SVC and SVR’s constraints[J]. Con tro land Decision,2014,29(6):1021-1026.doi:10.13195/j. kzyjc.2013.0520.
[3]PATRICIA N and CAPUTO B.Learning to learn,from transfer learning to domain adap tation:A unifying perspective[C].Proceedings of the IEEE Conference on Com puter Vision and Pattern Recognition,Columbus,OH,USA,2014:1442-1449.doi:10.1109/CVPR.2014.187.
[4]XU Z J and SUN S L.M ulti-sou rce transfer learning w ith m ulti-view adaboost[J].Neural Inform ation Processing,2012,7665:332-339.doi:10.1007/978-3-642-34487-9_41.
[5]PAN S J L,KWOK JT,and YANG Q.Transfer learning via dimensionality reduction[C].Proceedings of the 23rd International Conference on A rtificial Intelligence,CA,USA: 2008:677-682.
[6]PAN S J L,NIX C,SUN J T,et al.Cross dom ain sentim ent classification via spectral feature alignment[C].Proceedings of the 19th International Con ference on World W ide W eb(WWW-10).New York,USA,2010,751-760.doi:10. 1145/1772690.1772767.
[7]蒋亦樟,邓赵红,王士同.M L型迁移学习模糊系统[J].自动化学报,2012,38(9):1393-1409.doi:10.3724/SP.J.1004.2012. 01393.
JIANG Yizhang,DENG Zhaohong,and WANG Shitong. Mam dani-Larsen type transfer learning fuzzy system[J].Acta Automatica Sinica,2012,38(9):1393-1409.doi:10. 3724/SP.J.1004.2012.01393.
[8]JIANG W H and CHUNG F L.Transfer spectral clustering[C].Proceedings of the 2012 European Conference on M achine Learn ing and Princip les and Practice of Know ledge Discovery in Databases,Berlin,Heidelberg,2012:789-803. doi:10.1007/978-3-642-33486-3_50.
[9]LIM J,NG M K,CHEUNG Y M,et al.Agglom erative fuzzy K-means clustering algorithm w ith selection of number of clusters[J].IEEE Transactions on Know ledge and Data Engineering,2008,20(11):1519-1534.doi:10.1109/TKDE. 2008.88.
[10]KRISHMA K and MURTY M N.Genetic K-m eans algorithm[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B,1999,29(3):433-439.doi:10.1109/3477. 764879.
[11]ERSAHIN K,CUMM ING I G,and WARD R K. Segmentation and classification of Polarimetric SAR data using spectral graph partitioning[J].IEEE Transactions on Geoscience and Rem ote Sensing,2010,48(1):164-167.doi: 10.1109/TGRS.2009.2024303.
[12]LAUER F and SCHNORR C.Spectral clustering of linear subspaces for motion segmentation[C].Proceedings of the 12th IEEE International Conference of Com puter V ision,Kyoto,Japan,2009:678-685.doi:10.1109/ICCV.2009. 5459173.
[13]FREY B J and DUECK D.Clustering by passing messages between data points[J].Science,2007,315(5814):972-976.
[14]肖宇,于剑.基于近邻传播算法的半监督聚类[J].软件学报,2008,19(11):2803-2813.doi:10.3724/SP.J.1001.2008.02803.
XIAO Yu and YU Jian.Sem i-supervised clustering based on affinity propagation algorithm[J].Journal of Software,2008,19(11):2803-2813.doi:10.3724/SP.J.1001.2008.02803.
[15]储岳中,徐波,高有涛.基于近邻传播聚类与核匹配追踪的遥感图像目标识别方法[J].电子与信息学报,2014,36(12): 2923-2928.doi:10.3724/SP.J.1146.2014.00422.
CHU Yuezhong,XU Bo,and GAO Youtao.Technique of remote sensing image target recognition based on affinity propagation and kernel m atching pursuit[J].Journal of Electronics&Inform ation Techno logy,2014,36(12): 2923-2928.doi:10.3724/SP.J.1146.2014.00422.
[16]SUN L and GUO C H.Incremental affinity propagation clustering based on message passing[J].IEEE Transactions on Know ledge and Data Engineering,2014,26(11):2731-2744. doi:10.1109/TKDE.2014.2310215.
[17]SHI X H,GUAN R C,WANG L P,et al.An increm ental affinity p ropagation algorithm and its applications for text clustering[C].Proceedings International Joint Con ference on Neural Networks,Atlanta,GA,USA,2009:2914-2919.doi: 10.1109/IJCNN.2009.5178973.
[18]ZHENG Yun and CHEN Pei.Clustering based on enhanced α-expansion move[J].IEEE Transactions on Know ledge and Data Engineering,2013,25(10):2206-2216.doi:10.1109/ TKDE.2012.202.
[19]毕安琪,董爱美,王士同.基于概率和代表点的数据流动态聚类算法[J].计算机研究与发展,2016,53(5):1029-1042.
BIAnqi,DONG Aimei,and WANG Shitong.A dynam ic data stream clustering algorithm based on probability and exem p lar[J].Journal ofCom puter Research and Developm en t,2016,53(5):1029-1042.
[20]孙力娟,陈小东,韩崇,等.一种新的数据流模糊聚类方法[J].电子与信息学报,2015,37(7):1620-1625.doi:10.11999/ JEIT 141415.
SUN Lijuan,CHEN Xiaodong,HAN Chong,etal.New fuzzyclustering algorithm for data stream[J].Journal of Electronics&Information Techno logy,2015,37(7): 1620-1625.doi:10.11999/JEIT 141415.
[21]JIANG Y Z,CHUNG F L,WANG S T,et al.Collaborative fuzzy clustering from mu ltip le weighted views[J].IEEE Transactions on Cybernetics,2015,45(4):688-701.doi:10. 1109/TCYB.2014.2334595.
[22]CAID,HE X F,HAN JW,et al.O rthogonal Lap lacian faces for face recognition[J].IEEE Transactions on Image Processing,2006,15(11):3608-3614.doi:10.1109/TIP.2006. 881945.
[23]张景祥,王士同,邓赵红,等.融合异构特征的子空间迁移学习算法[J].自动化学报,2014,40(2):236-246.doi: 10.3724/SP.J.1004.2014.00236.
ZHANG Jingxiang,WANG Shitong,DENG Zhaohong,et al. A subspace transfer learning algorithm integrating heterogeneous features[J].Acta Automatica Sinica,2014,40(2):236-246.doi:10.3724/SP.J.1004.2014.00236.
[24]LE C Y,BOTTOU L,BENGIO Y,et al.Gradient-based learn ing app lied to docum ent recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.doi:10.1109/5.726791.
[25]REN J,SHIX,FANW,et al.Type independent correction of sam p le selection bias via structural discovery and rebalancing[C].Proceedings of the 8th SIAM International Conference on Data M ining,A tlanta,GA,USA,2008: 565-576.doi:10.1137/1.9781611972788.52.
毕安琪:女,1989年生,博士生,研究方向为模式识别、人工智能、迁移学习等.
王士同:男,1964年生,教授,研究方向为模式识别、人工智能、模糊系统等.
Transfer Affinity Propagation Clustering Algorithm Based on Kullback-Leiber Distance
BIAnqi WANG Shitong
(Schoo l of Digital M edia,Jiangnan University,W uxi 214122,China)
For solving the clustering p rob lem of transfer learning,a new algorithm called Transfer A ffinity Propagation clustering algorithm is proposed based on Ku llback-Leiber distance(TAP_KL).Based on the probabilistic framework,a new interpretation of the ob jective function of A ffinity Propagation(AP)clustering algorithm is proposed.By leveraging Kullback-Leiber distance which is usually used in information theory,TAP_KL measures the sim ilarity relationship between source data and target data.Moreover,TAP_KL algorithm can embed the sim ilarity relationship to the calculation of sim ilarity matrix of target data.Thus,the op tim ization framework of AP can be directly used to optim ize the new target function of TAP_KL.In this case,TAP_KL builds a sim ple algorithm framework to solve the transfer clustering p roblem,in which the algorithm just needs tomodify the sim ilarity matrix to solve the transfer clustering prob lem.The experimental results based on both 4 datasets show the effectiveness of the p roposed algorithm TAP_KL.
A ffinity Propagation(AP)clustering algorithm;Transfer learning;Face datasets;Probabilistic framework;Kullback-Leiber distance(KL)
s:The National Natural Science Foundation of China(61170122,71272210),Jiangsu G raduate Student Innovation Projects(KYLX_1124),The Science and Technology P rogram Shandong Provinceial H igher Education(J14LN 05)
TP391.4
A
1009-5896(2016)08-2076-09
10.11999/JEIT 151132
2015-10-10;改回日期:2016-04-17;网络出版:2016-06-03
毕安琪angela.sue.bi@gm ail.com
国家自然科学基金(61170122,61272210),江苏省2014年度普通高校研究生科研创新计划项目(KYLX_1124),山东省高等学校科技计划项目(J14LN05)
