基于熵估计的安全协议密文域识别方法
2016-08-30朱玉娜韩继红范钰丹
朱玉娜 韩继红 袁 霖 谷 文 范钰丹
(解放军信息工程大学郑州450001)
基于熵估计的安全协议密文域识别方法
朱玉娜*韩继红袁霖谷文范钰丹
(解放军信息工程大学郑州450001)
现有基于网络报文流量信息的协议分析方法仅考虑报文载荷中的明文信息,不适用于包含大量密文信息的安全协议。为充分发掘利用未知规范安全协议的密文数据特征,针对安全协议报文明密文混合、密文位置可变的特点,该文提出一种基于熵估计的安全协议密文域识别方法CFIA(Ciphertext Field Identification Approach)。在挖掘关键词序列的基础上,利用字节样本熵描述网络流中字节的分布特性,并依据密文的随机性特征,基于熵估计预定位密文域分布区间,进而查找密文长度域,定位密文域边界,识别密文域。实验结果表明,该方法仅依靠网络数据流量信息即可有效识别协议密文域,并具有较高的准确率。
未知安全协议;协议格式;密文域;熵估计
1 引言
随着密码技术的广泛应用,安全协议被大量应用在互联网各种核心、关键应用中,与安全协议相关的各种数据在网络流量中比重日益增加。基于网络报文载荷数据,分析协议用户交互行为信息是安全协议流量分析的关键内容,有助于对各种网络应用实施监控和管理,有效降低系统面临的安全风险。目前存在很多私有协议,协议细节未公开,语法、语义、交互步骤缺少公开的描述文档,无法基于已有的协议分析工具(例如著名的W ireshark)进行分析。为此,如何提供一种方法,使其能够有效支持未知安全协议格式信息的解析,是进一步提升网络空间安全防护技术的关键问题。
安全协议运行过程中,频繁使用数据加密、数字签名、公钥证书、校验和验证等各种密码技术对关键信息进行加密和保护。一方面,可用明文信息较少,仅依靠有限的明文信息难以满足安全应用的需求。另一方面,攻击者在无法解密密文的情况下,常常通过重放、转发密文进行攻击。因此对未知安全协议进行格式解析时,不仅需要解析可用明文格式特征,还需要充分发掘和利用协议报文中包含的密文数据特征。
目前,网络协议格式解析技术包括两类方法:基于目标主机程序执行轨迹的方法[15]-和基于网络报文流量信息的方法[612]-。(1)前者借助特定二进制分析平台,基于目标主机上协议相关的应用程序运行状态特征,分析网络协议。该类方法可实现对安全协议的逆向。ReFormat[3]可以识别密码算法,并解析明文格式,但不适用于解密过程与解析过程交替进行的安全协议。为解决该问题,Dispatcher[4,5]允许多个加密过程与解析过程交替,识别力度细化到编码函数级(加/解密函数、哈希函数等),但通用性和准确性需进一步验证。上述方法可以处理加密报文,但需要在目标主机上获取执行协议的应用程序信息,并部署特定监测工具,实现复杂,局限性较大,无法真正满足网络环境中对数据报文监测需求。(2)基于网络报文流量信息的方法以捕获的网络流量数据为分析对象,依据协议字段的取值变化频率和特征推断得到协议格式,是使用范围更广的方法。文献[6]基于序列比对算法解析协议的结构信息。文献[7]以循环聚类为核心思想,采用基于类型的序列比对算法,实现了针对性更强的报文格式逆向。文献[8]基于隐半马尔科夫模型对报文格式进行分段。文献[9]基于数据挖掘提取协议关键词并构建状态机。文献[10]基于无监督分段方法提取协议格式特征。文献[11,12]利用语义信息推断协议格式。上述方法局限性较小,应用范围较广,但仅解析报文中的明文信息格式,不考虑协议的密文数据特征,不适用包含大量密文的安全协议。
为有效利用安全协议密文数据特征,本文面向未知安全协议,针对其报文明密文混合、密文位置可变的特点,提出了一种基于熵估计的密文域识别方法CFIA(Ciphertex t Field Identification Approach),仅依靠网络数据流量信息即可有效识别协议密文域。本文主要贡献有:(1)提出字节样本熵,用于描述网络流中字节的分布特性;(2)依据密文的随机性特征,基于熵估计给出密文域分布区间的预定位方法;(3)启发式查找密文长度域,进而定位密文域边界,识别密文域,从而为密文数据信息的有效利用提供了新的解决思路。
2 密文域识别问题描述
安全协议报文序列长、结构复杂、变长域多,其载荷可能为全明文、全密文或者明密文混合,并且密文位置、长度通常为可变值。本文分析对象为未知规范安全协议,目的是识别协议密文域,定位密文域边界,为入侵检测、流量监控、协议安全性在线分析等网络安全关键应用提供支撑。
协议格式由若干个域(具有特定语义且最小不可分割的连续字节序列)组成[4],域具有域类型、域边界、语义和取值约束等属性,域之间存在顺序、并列和层次关系。根据域在网络流中的取值变化情况,可将协议格式划分为不变域和可变域。
定义1协议关键词:报文格式中用于标识协议报文类型和传递相关控制信息的协议字段。文献[1]指出,绝大多数的网络协议都会在报文格式中定义一个或多个关键词,基于关键词可以有效区分报文中协议的控制信息和用户数据。
协议的关键词可以是协议名称和版本号,也可以是协议的各种命令和响应码。按照关键词出现的位置,可将其分为固定偏移关键词和非固定偏移关键词。前者在协议报文中位置固定;后者位置可变。
关键词在协议报文中频繁出现,为协议的不变域。前后两个关键词之间是协议的用户数据,取值可变,为协议的可变域。根据域是否加密,将可变域划分为明文域和密文域。安全协议为防止攻击,常采用具有新鲜性的随机数。普通网络协议则一般不包含随机数。本文将随机数区域看作广义上的密文域。
为识别密文域,需分析密文数据区别于明文数据的特征。从密码学角度,密文数据消除了统计特征,近似为随机数据。已有研究[1316]-基于密文数据的随机性分析加密流量,但其处理对象与本文不同,文献[13,14]针对全密文情况,文献[15]针对已知协议,文献[16]仅考虑报文前N个字节,均无法解决协议密文域识别问题。
由于密文是随机的,在密文域中不存在频繁项,也不可能存在关键词,密文域一定位于前后两个关键词之间,或者最后一个位置的关键词之后,因此可在提取关键词序列的基础上,对前后两个关键词之间的可变域进一步解析,识别密文域。
3 CFIA方法
本节给出CFIA总体框架,并详细阐述框架的密文域识别阶段,给出字节样本熵计算方法、密文域预定位算法以及密文域边界定位算法。
3.1 CFIA总体框架
CFIA总体框架如图1所示。
(1)数据预处理:利用数据包大小、方向、偏移位置等特征对同一类协议流量进行聚类,获取相同类型的报文组,并对每一个报文组中的报文提取载荷字节序列,用于后续密文域识别。
(2)密文域识别:根据密文的随机性,密文字节在网络流中随机取值。因此密文域中不存在频繁出现的协议关键词,密文域位于前后两个关键词之间。首先基于序列模式挖掘方法提取协议中具有时序关系的关键词序列;在此基础上,对前后两个关键词之间的可变域进一步进行解析,计算字节样本熵,描述两个关键词之间各个对齐字节的取值变化特性;并依据密文数据的随机性特征,基于熵估计预定位密文分布区间,进而启发式查找密文长度域,定位密文域边界,识别密文域。
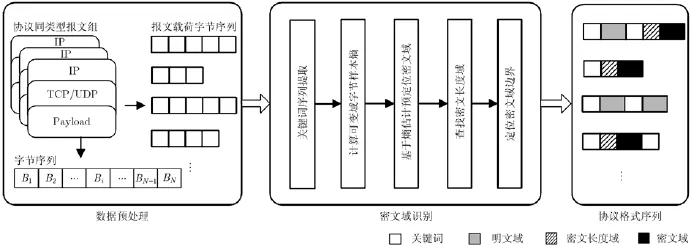
图1 CFIA总体框架
3.2字节样本熵
协议域通常以字节为小单位进行组织[7],本文将相同偏移位置的字节作为随机变量,利用信息熵来描述网络流中字节的分布特性。
定义2字节偏移:字节在所属载荷数据中的序号位置。
通过W ireshark在广域网中捕获SSL协议流量,并计算ClientHello报文前64 Byte的字节样本熵(报文数目N=300),如图2(c)所示。当字节位于关键词区域,其样本熵值为0;当字节位于明文区域,其样本熵值大都在3.1886~3.3671之间。当字节位于随机数区域时,偏移11~14的字节表示时间,不完全随机,其样本熵值小于7;偏移15~42的字节为随机值,样本熵值位于7.1552~7.3770之间。
在实验室局域网中运行NS公钥协议应用程序(采用Spi2java工具生成),并计算协议第1条报文前500 Byte的字节样本熵(报文数目N=300),如图2(d)所示。关键词区域的字节样本熵值为0;密文长度域区域的字节样本熵值位于0~1之间。密文区域的字节样本熵值在7.1317~7.4401之间。
依据文献[16],密文字节变量近似满足均匀分布。若字节属于协议密文域,则在网络流中随机取值,其熵值最大。若字节属于协议明文域,由于协议规范具有特定语义,字节取值在一定范围,其熵值明显小于密文域字节熵,与图2结果一致。因此可基于字节样本熵值区分密文域和明文域。
3.3密文域预定位算法
密文域预定位算法如表1所示。
(1)关键词提取:同种协议包含一个或多个关键词,组成具有时序关系的关键词集合。为处理关键词位置变化问题,本文基于序列模式挖掘方法PrefixSpan算法提取包含任意长度间隔的有序关键词序列。
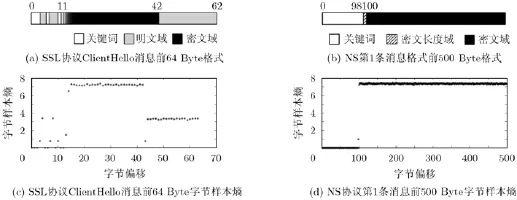
图2 协议字节样本熵(N=300)
(2)字节样本熵计算:获取关键字序列后,提取相邻的两个关键词之间的载荷数据,并将关键词之间相同偏移(偏移从关键词位置开始计数)的字节作为随机变量,计算字节样本熵,如图3所示。

表1 密文域预定位算法
(3)基于熵估计预定位密文分布区间:由熵的定义可知,均匀分布的熵值最大,为但字节样本熵与所选择的样本相关。在NS协议流量第1条报文中,随机选择某一密文字节变量,计算其字节样本熵,样本数目N为1~2048,如图4所示。当N为有限值时,特别在N~256或者N<256的情况下,字节样本熵值与8之间存在误差。只有N→∞时,密文字节样本熵值才近似为8[15]。为此,不能将样本熵值与8相比较。

图3 字节样本熵计算
为检测是否为密文字节变量,采用熵估计方法,计算样本数目为N时均匀分布的熵大小(根据文献并与字节样本熵相比较。文献[15]等给出N-截断熵(N-truncated entroy),估计分布依据分布p产生所有可能的长度为N的样本,并通过最大似然估计对这些样本进行熵估计,将估计的平均值作为N-截断熵值,随后证明了当p满足均匀分布时,为无偏估计值。

图4 样本数目熵

其中,N为样本数量,in为i值出现的次数,
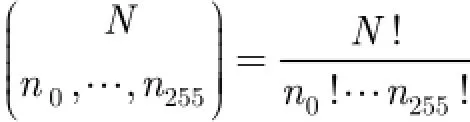
依据文献[15],采用蒙特卡罗方法计算均匀分布的N-截断熵及其置信区间6时,置信水平近似为99.9%[15],即满足均匀分布的变量以99.9%的概率位于区间为的标准偏移。随后,将字节熵与均匀分布的N-截断熵值相比较,若字节熵值落在置信区间中,则认为该字节变量满足均匀分布,为密文字节。最后,将连续的密文字节变量合并在一起,作为密文域分布区间,如图5所示。

图5 密文域分布区间预定位
3.4密文域边界定位算法
由于密文相对关键词偏移可变,密文长度可变,因此密文域分布区间不一定为密文域边界。
在协议报文中,依据长度是否可变,密文数据分布存在如下两种情况:(1)长度域||可变长度密文数据:密文长度与所采用的密码算法、明文长度、密钥长度相关。密文长度通常可变,而变长字段必须使用长度域,以便接收方进行解析。(2)固定长度密文数据:密文为固定长度,前面可能无长度域。
根据密文和关键词的相对位置,存在以下两种情况:
(1)密文相对关键词的偏移固定:(a)关键词||固定长度密文…||关键词;(b)关键词||固定长度明文||固定长度密文…||关键词;(c)关键词||长度域||可变长度密文…||关键词;(d)关键词||固定长度明文||长度域||可变长度密文…||关键词。若密文长度固定((a),(b)),则预定位的密文分布区间即为密文域边界。若密文长度可变((c),(d)),预定位的密文分布区间起始位置即为密文域起始位置,但密文域结束位置不确定。
(2)密文相对关键词的偏移可变:(a)关键词||可变长度明文||固定长度密文…||关键词;(b)关键词||可变长度明文||长度域||可变长度密文…||关键词。预定位的密文分布区间为密文域的一部分,不能确定密文域起止边界。
为此,在预定位密文分布区间后,查找密文长度域,进而定位密文域边界。本文主要考虑16进制值表示的长度域。
密文长度域的识别策略基于以下启发式规则。(1)密文长度域一般采用1~2 Byte长度的16进制数值表示。协议密文具有明确的规范,其长度在一定的范围内。通常情况下协议密文长度为128~4096 bit。密文长度为8 bit的倍数,相应的长度域10进制取值范围为16~512。(2)密文长度域与密文长度相关联。长度域值随着密文长度变化而改变。(3)密文长度域不可能出现在它所标记的密文区间之后。
记3.3节预定位的密文分布区间Ii长度为1l(单位为Byte),起始关键词和Ii起始位置之间的字节序列记为BS,BS中某一字节至下一关键词之间的长度记为2l(单位为Byte),如图6所示。
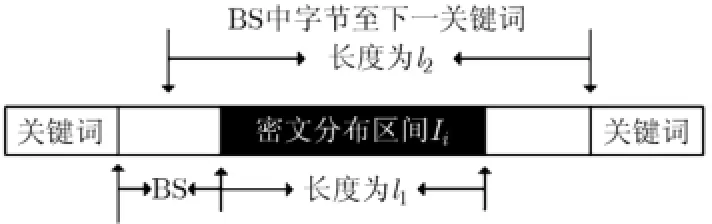
图6 报文格式
密文域边界定位算法描述如表2所示。

表2 密文域边界定位算法
(1)对每个BS序列查找可能的密文长度域。若116l≥,关键词之间可能存在密文域。对密文分布区间Ii之前的字节序列BS进行处理,分别计算BS各个字节值n,和连续2Byte(字节以及相邻的前一字节)对应的值512),记录长度向量(字节所在起始关键词K、字节所在终止关键词K'、字节相对起始关键词的偏移O、字节值,对应的字节序列);(b)若m=n(例如“00 C0”和“C0”都作为长度域标识密文域),长度域本身重叠,优先选取m作为长度域。
(2)进一步判定所记录的n值和m值是否为长度域。根据(字节所在起始关键词K、字节所在终止关键词K'、字节相对起始关键词的偏移O),对长度向量取交集。若存在,则密文相对关键词偏移固定,交集即为正确的长度向量。若不存在,则密文相对关键词偏移可变,查找明文长度域,确定明文字段长度,并从左至右层次化解析报文,确定密文长度域,定位密文域边界。
(3)若不存在密文长度域,则为固定长度密文,进一步查找明文长度域。若不存在,则明文为固定长度,密文相对关键词偏移固定,预定位的密文分布区间即为密文域;若存在,根据明文长度域确定明文,进而从左至右解析报文,定位密文域边界。
4 实验测试
SSL协议和SSH协议是网络中广泛应用的安全通信协议;NS(Needham-Schroeder)公钥协议和sof协议则属于经典基础安全协议。本文选取这4个经典的安全协议进行实验,结果表明本文方法可以准确识别密文域。
4.1实验数据
协议流量数据集由3部分组成,如表3所示。第1部分来源于广域网和MACCDC数据集[18],为包含SSL协议的网络流量。第2部分来源于In foV is Contest数据集[19],为包含SSH协议的网络流量。第3部分由实验室局域网环境产生,为包含NS公钥协议和sof协议[20]的网络流量。其中NS公钥协议、sof协议的应用程序采用Spi2Java[20]工具生成,并在各个主机上运行。

表3 协议数据集
4.2实验结果
现有基于网络报文流量信息的方法使用不公开的数据集,且主要解析协议的明文格式,难以和CFIA方法进行比较。CFIA对密文域识别主要依据密文的随机性,目前存在其它随机性评估方法,例如NIST测试、卡方测试等。文献[15]指出:(1)相比较样本平均值、方差,熵是最抗噪的随机性测试方法。(2)叠加使用多种随机性测试方法,不能提升测试效果,无意义。因此本文不再采用其他方法,仅基于熵识别密文域。
为检验CFIA方法的有效性,针对每个协议随机选取完整的K个会话(取K=16,32,64,128和 256),统计不同样本数K情况下密文域识别的正确率。绝大多数识别特征包含于流中第1条报文内[21],对第1条报文包含密文域的SSL协议,NS协议和sof协议分别进行1000次测试,统计报文密文域识别的正确率,如图7所示,当32K≥时,密文识别率在95%以上,与熵估计要求K>16一致。
为进一步验证CFIA方法的有效性,针对每个协议,随机选取完整的M个会话作为训练集,用于解析协议格式;其余部分作为测试集,用于评估所解析的格式。采用如下性能指标:记测试集中某协议A的样本数目为N。N1表示被正确识别为A的样本数,N2表示非A被错误识别为A的样本数,识别率=N1/N,误识别率=N2/(N1+N3)。识别率越高,误识别率越低,相应的识别效果越好。
不同训练样本数的识别率如图8所示。在小样本情况下,协议会话类型偏少,所解析的格式只能代表协议部分类型的会话,识别率偏低。随着M增加,选取的会话类型增多,解析的格式特征更为精确,识别率也随之增加。当M=128时,识别率基本在94%以上。另一方面,不同训练样本数目下,都可以提取有效的协议格式特征,与其他协议可以相区分,误识别率都为0。由上可知,本文方法可以较好地识别协议。

图7 协议第1条报文密文域识别正确率
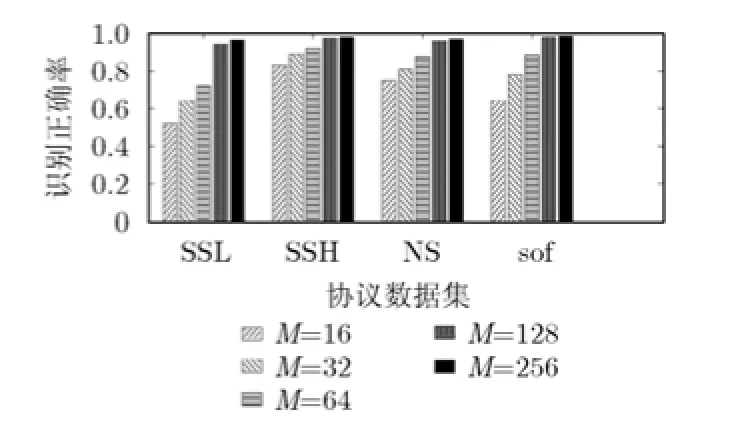
图8 训练集M不同大小时的识别率
5 结束语
本文提出CFIA方法,依据密文的随机性特征,利用字节样本熵和熵估计预定位密文域区间,进而通过密文长度域定位密文边界,识别密文域。最后对4个经典安全协议进行实验,结果表明,该方法仅依靠网络数据流量信息即可有效识别协议密文域。但CFIA未考虑协议的时序行为,存在一定的局限性。下一步需进一步构建未知安全协议状态机,给出协议的状态转换过程,刻画协议的行为关系,为信息系统各种网络安全应用提供支撑。
[1]CABALLERO J,YIN H,LIANG Zhenkai,et al.Polyglot:York:2007:317-329.doi:10.1145/1315245.1315286.
[2]CUIWeidong,PEINADO M,CHEN K,et al.Automatic reverse engineering of input format[P].USA,8935677 B 2,2015-1-13.
[3]WANG Zhi,JIANG Xuxian,CUIWeidong,et al.ReFormat: Automatic reverse engineering of encrypted messages[C]. European Symposium on Research in Com puter Security,Berlin,2009:200-215.doi:10.1007/978-3-642-04444-1_13.
[4]CABALLERO J,POOSANKAM P,KREIBICH C,et al. Dispatcher:enab ling active botnet in filtration using automatic protocol reverse-engineering[C].Proceedings of the 16th ACM Con ference on Com puter and Communications Security,New York,2009:621-634.doi:10.1145/1653662. 1653737.
[5]CABALLERO J and SONG D.Au tom atic protocol reverseengineering:m essage form at extraction and field sem antics in ference[J].Computer Network,2013,57(2):451-474.doi: 10.1016/j.comnet.2012.08.003.
[6]BEDDOE M.The protocol information pro ject[EB/OL]. http://www.4tphi.net/~awalters/PI/PI.htm l,2004.
[7]CUI W eidong,KANNAN J,and WANG H J.D iscoverer: Au tom atic protocol reverse engineering from network traces[C].Proceedings of the 16th USENIX Security Sym posium,Berkeley,2007:199-212.
[8]黎敏,余顺争.抗噪的未知应用层协议报文格式最佳分段方法[J].软件学报,2013,24(3):604-617.doi:10.3724/SP.J. 1001.2013.04243.
LI M in and YU Shunzheng.Noise-tolerant and op timal segmentation of message formats for unknown applicationlayer p rotocols[J].Journal of Software,2013,24(3):604-617. doi:10.3724/SP.J.1001.2013.04243.
[9]LUO Jianzhen and YU Shunzheng.Position-based automatic reverse engineering of network protocols[J].Journal of Network and Com puter Applications,2013,36(3):1070-1077. doi:10.1016/j.jnca.2013.01.013.
[10]ZHANG Zhuo,ZHANG Zhibin,Lee P P C,et al.Toward unsupervised protocol feature Word extraction[J].IEEE Journal on Selected Areas in Commun ications,2014,32(10): 1894-1906.doi:10.1109/JSAC.2014.2358857.
[11]TÉTARD O.Netzob[OL].http://www.netzob.org/,2013.
[12]BOSSERT G,GUIHÉRY F,and HIET G.Towards autom ated protocol reverse engineering using semantic in formation[C].Proceedings of the 9th ACM Sym posium on Information,Com puter and Communications Security,Kyoto,2014:51-62.doi:10.1145/2590296.2590346.
[13]KUMANO Y,ATA S,NAKAMURA N,et al.Towards realtime processing for app lication identification of encrypted traffic[C].International Conference on Com puting,Networking and Comm unications,Honolulu,H I,2014: 136-140.doi:10.1109/ICCNC.2014.6785319.
[14]赵博,郭虹,刘勤让,等.基于加权累积和检验的加密流量盲识别算法[J].软件学报,2013,24(6):1334-1345.doi:10. 3724/SP.J.1001.2013.04279.
ZHAO Bo,GUO Hong,LIU Qinrang,et al.Protocol independent identification of encrypted traffic based on weighted cumulative sum test[J].Journal of Software,2013,24(6):1334-1345.doi:10.3724/SP.J.1001.2013.04279.
[15]OLIVAIN J and GOUBAULT-LARRECQ J.Detecting subverted cryptographic protocols by entropy checking[R]. LSV-06-13,2006.
[16]BONFIGLIO D,MELLIA M,MEO M,et al.Revealing skype traffic:when randomness plays w ith you[C].Proceedings of the ACM SIGCOMM Conference on App lications,Technologies,Architectures,and Protocols for Com puter Communications,Kyoto,2007:37-48.doi:10.1145/1282380. 1282386.
[17]PAN INSKI L.A coincidence-based test for un iform ity given very sparsely samp led discrete data[J].IEEE Transactions on Information Theory,2008,54(10):4750-4755.doi:10.1109/ TIT.2008.928987.
[18]MACCDC traces[OL].http://www.netresec.com/?page= MACCDC,2012.
[19]InfoVisContest traces[DB/OL].http://2009.hack.lu/index. php/InfoVisContest,2009.
[20]PIRONTI A,POZZA D,and SISTO R.Spi2Java User Manual-Version 3.1[R].Turin:Piedmont:Italy,Polytechnic University of Turin,2008.
[21]ACETO G,DAINOTT I A,DONATO W,et al.PortLoad: taking the best of two worlds in traffic classification[C]. Proceedings of IEEE International Conference on Com puter Communications,San Diego,CA,2010:1-5.doi:10.1109/ INFCOMW.2010.5466645.
朱玉娜:女,1985年生,博士生,研究方向为安全协议逆向与识别.
韩继红:女,1966年生,教授,博士生导师,研究方向为网络与信息安全、安全协议形式化分析与自动化验证.
袁霖:男,副教授,研究方向为安全协议形式化分析与自动化验证、软件可信性分析.
Protocol Ciphertext Field Identification by Entropy Estimating
ZHU Yuna HAN Jihong YUAN Lin GU Wen FAN Yudan
(PLA Information Engineering University,Zhengzhou 450001,China)
Previous network-trace-based m ethods only consider the p laintext format of pay load data,and are not suitable for security p rotocolswhich include a large number of ciphertext data;therefore,a novel approach named CFIA(Ciphertext Field Identification Approach)is p roposed based on entropy estimation for unknown security protocols.On the basis of keywords sequences extraction,CFIA utilizes byte sam ple entropy and entropy estimation to pre-locate ciphertext filed,and further searches ciphertext length field to identify ciphertext field. The experimental resu lts show that w ithout using dynam ic binary analysis,the proposed method can effectively identify ciphertext fields pu rely from network traces,and the inferred formats are high ly accurate in identifying the protocols.
Unknown security protocol;Protocol format;Ciphertext field;Entropy estimation
The National Natural Science Foundation of China(61309018)
TP393.08
A
1009-5896(2016)08-1865-07
10.11999/JEIT 151205
2015-10-29;改回日期:2016-02-25;网络出版:2016-05-09
朱玉娜zyn_qingdao@126.com
国家自然科学基金(61309018)
