基于客户动态需求属性的物流配送线路聚类优化
2016-08-18韩世莲
韩世莲
(南京财经大学 营销与物流管理学院,南京 210042)
随着网络经济特别是各种新型电子商务模式如B2C、C2C、O2O 的蓬勃发展,物流配送环节的地位和作用愈加重要(2013“双十一”节阿里销售额350多亿元,仅天猫1天就产生逾1.5亿件包裹,平均每分钟10万件。实际递送6 000万件),并在很多情况下成为电子商务发展的制约因素和瓶颈环节[1-2]。物流配送路径选择问题是通过制定合理的配送路径,快速而经济地将货物送达用户手中。配送路径的选择是否合理,对加快配送速度、提高服务质量、降低配送成本、增加经济效益都有较大影响[1-2]。
物流配送路径选择问题是一个NP-难题,其求解计算量随着问题规模的增大呈指数增长[1-2]。该问题属组合优化问题,很难获得对一般问题的解决方案,尤其是带时间窗的多目标配送路径选择问题[3]。近年来,学者们用精确算法和启发式算法求解组合优化难题,取得了一定的进展[4-24]。
精确算法基于严格的数学手段,在可以求解的情况下,其解通常要优于启发式算法。但由于引入严格的数学方法,因而无法避开指数爆炸问题,从而使该类算法只能有效求解中小规模的单目标配送线路问题[4-5]。在求解大规模配送线路问题或多目标配送线路问题时,启发式算法总可以在有限时间内,找到满意的次优解/可行解。目前的启发式算法主要有以下几种:
(1)路径构造启发式算法[4-5]。路线改进启发式算法[5-6]复合启发式算法包含路线构造和路线改进2个阶段[8-10]。
(2)元启发式算法。包括禁忌搜索法[11-15]、模拟退火法[16-19]、遗传算法[20-23]以及蚁群算法[23]等。
(3)基于数学规划的启发式算法[25-28]。把问题直接描述为一个数学规划问题,根据其模型的特殊结构,应用一定的技术(如分解)进行划分,进而求解已被广泛研究的子问题。
以上方法基本都以运输费用最小为目标,事实上,对于配送而言,运输费用、快速和准时性都很重要,目前,将这几个目标综合研究的文献较少,而且,很多的配送线路选择模型均未考虑产品的生命周期、产品价值及产品特性等客户的需求属性,而这些因素都会直接影响客户的满意度,即服务质量。在电子商务背景下,这些因素的地位更大,影响也更加突出[29-30]。合理的配送线路应当在全面考虑客户需求属性的基础上达到预定的目标(时间最短、费用最小等)。因此,在综合考虑多种因素的前提下,为配送线路选择问题(包括单向、双向及单双向混合)提出一个通用的反应需求属性的客户聚类方法具有十分重要的理论和实际意义,尤其在客户有多样性需求的复杂物流配送网络中实施带时间窗的配送策略时,在配送线路确定前按照客户的需求属性对客户进行分类,不仅可以降低和减少问题求解的复杂性,而且可以提高供需双方的经济效益。
目前只有少量文献[29-30]在解决物流配送线路选择问题时涉及了客户分组方法,但文献[29]中仅考虑了静态的地理性能和需求量,而没有全面考虑客户的需求属性。文献[30]中提出的行前客户分类方法虽然对客户的需求属性进行了全面考虑,但对所有决策变量采用了同样的处理方法。由于定量决策变量的数值是确定的,转化为模糊数表示显然是多余和不必要的,而且该文所提方法无法保证每组客户仅需1辆车进行配送。
本文提出一种考虑客户全面需求属性的行前客户聚类方法。就是根据客户的需求属性,利用模糊聚类技术事先对客户分组,由于每组客户数目并不大,只需要1辆汽车进行配送,这样问题规模就相对很小,运用精确算法可以快速得到客户组的最优配送线路。
1 反应客户需求属性的模糊系统聚类方法
本文提出的混合模糊系统聚类方法可以看成一种无人监督的混合模糊聚类技术,该技术在模糊数据分析中运用了模糊和系统聚类2个概念。对照应用广泛的模糊c-均值算法[31],混合模糊系统聚类方法具有明显的优越性,这是因为模糊c-均值算法虽然在处理海量数据方面很有效,但计算复杂,且必须事先输入聚类块数。而模糊系统聚类法不但计算简单,而且不必事先输入聚类块数。由于多点物流配送线路选择前需要根据大量的客户属性将客户分配为未知的类型,正好符合系统聚类法不必事先输入聚类块数的特点,故在物流配送领域中,将模糊系统聚类技术运用于客户分类更为合适。
1.1 决策变量的确定
本文所提方法的第1步是确定决策变量以研究配送服务中的客户满意度。安全性、可靠性、经济性、便利性和对服务质量的满意度是客户主要关心的指标。为便于计算,本文选取能够全面反映5个指标的8个最重要的决策变量:
1.2 算法
模糊聚类算法的结构如图1所示,由数据处理、模糊相似矩阵的产生和客户分组三部分组成。
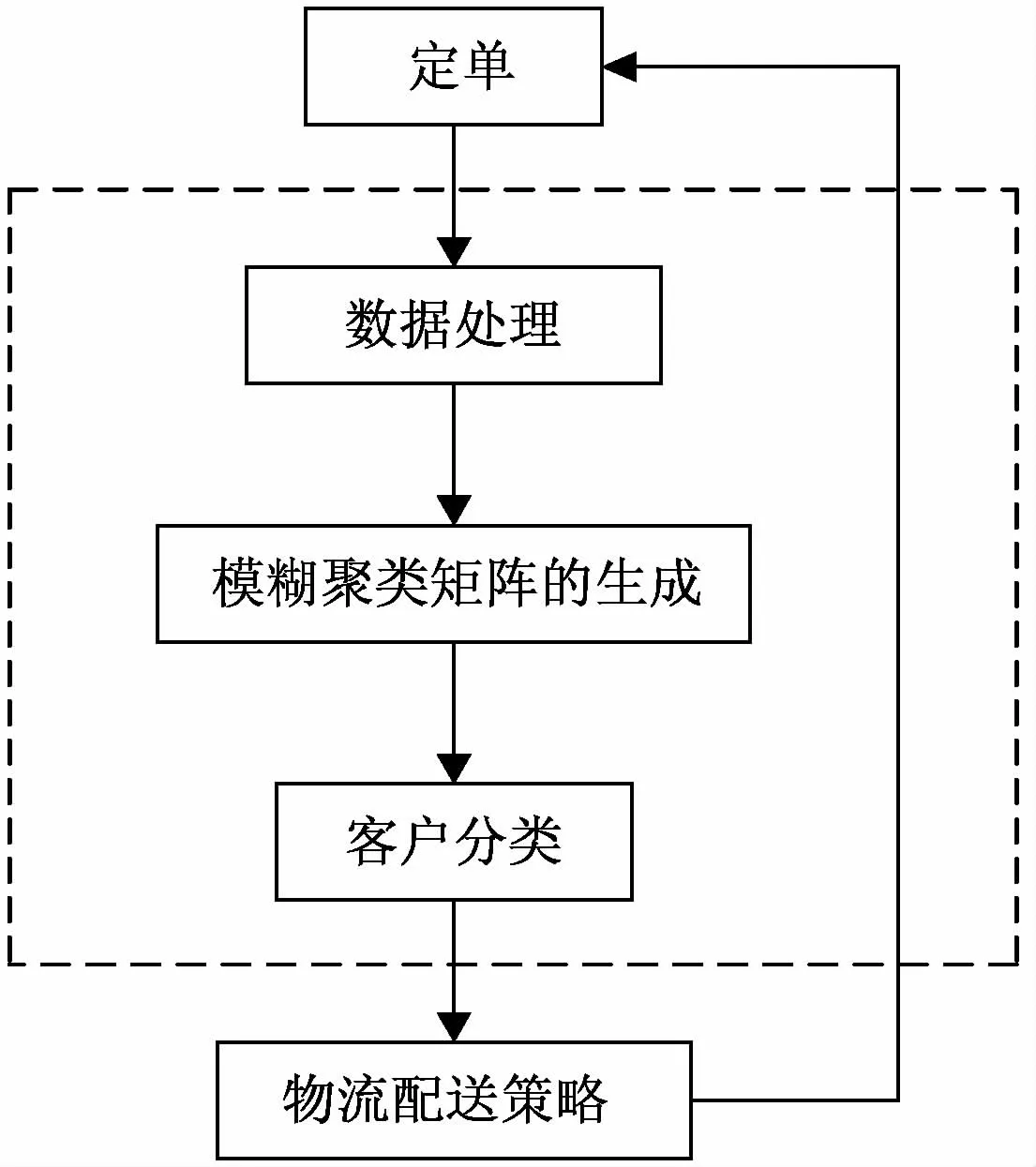
图1 模糊聚类算法的框架
①定性决策变量的处理。定性变量的处理主要由三角模糊数[32]评价客户订单中收集的客户决策变量。包含4个有序步骤:
(a)规定5 个语言术语,包括“很高”、“高”、“中”、“低”、“很低”,分别表示与客户需求模式相对应的5种服务水平,如表1所示。

表1 5个语言术语的模糊数表示
(b)根据反映客户需求的真实数据,采用5个语言术语评价与每个客户有关的变量决策。事实上,这些评价可以从最新时间段的订单中收集。
(c)根据表1提出的映射关联,每个语言术语由适当的三角模糊数表示,如(0,0,0.25)表示“很低”,(0.75,1,1)表示“很高”,因此,对于客户i的每个给定的语言决策变量k可由3 个数字表示为

(d)对用模糊数表示的第k个决策变量,分别计算不同客户属性之间的相似度。模糊数相似度的计算方法有很多[33-35],并被广泛应用于决策和数据分析的各个方面。任意2个客户对于第k个决策变量的相似度可采用文献[33-35]中的方法来确定。假定客户i、j的第k个决策变量的语言评价分别为:
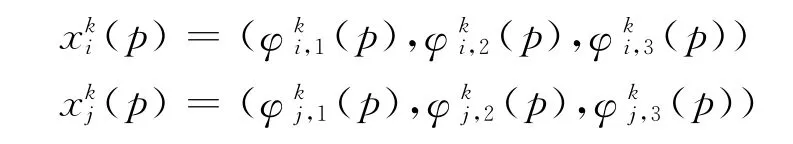
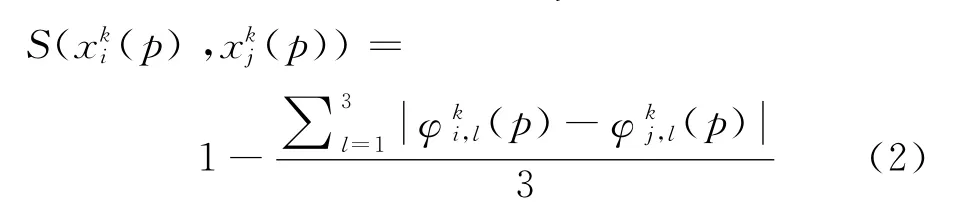
式中,
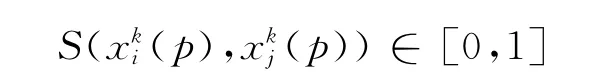
②定量决策变量的处理。本文采用下述方法求解任意2 个客户对于第k个决策变量的相似程度。为了使定量决策变量的相似度在[0,1]之间,首先对实际的决策变量数据进行归一化,然后将定量化的决策变量视为一种特殊的模糊数,采用和上面类似的方法计算任2个客户属性之间的相似度。对定量决策变量r,假定客户i、j的值分别为、,则它们之间的相似度
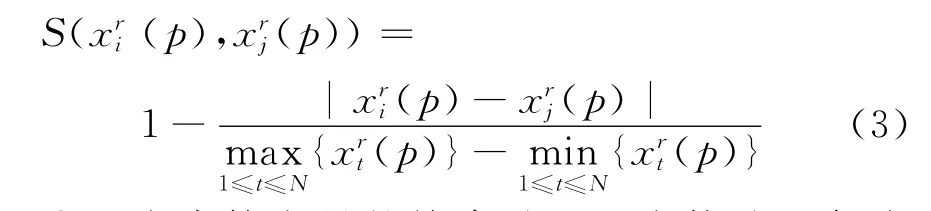
③7个决策变量的综合处理。在构造了每个决策变量的相似性后,就可以对任意2个客户之间的相似度进行计算,即

式中,w k表示决策变量k的重要性且满足
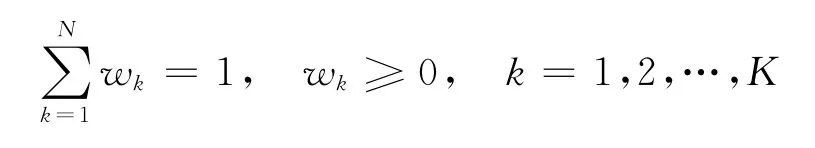
1.2.2 模糊相似矩阵的产生 在得到每2个客户之间的相似性后,就可以构造一个随时间变化的N×N模糊相似矩阵Ω(p)=[cij(p)]N×N,其中元素cij(p)表示客户i、j之间的相似性。Ω(p)可由下式表示:
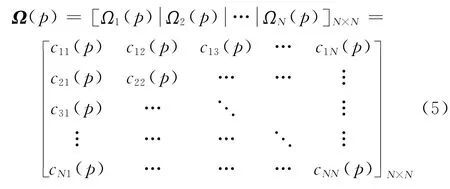
1.2.3 客户聚类程序 根据客户的属性,与其他组的客户相比,分配在同组的客户将具有相对较高的类似处。图2提出了客户分组的程序。

图2 客户分组程序图
(1)计算步骤。
步骤1初始化客户聚类数。令初始聚类数k=1,输入步骤评估的模糊聚类矩阵式(5)。
步骤2初始化计算循环。令初始循环数n=1。
步骤3从模糊聚类矩阵Ω(p)中选定第j列开始循环,从Ω(p)中删除与客户j对应的行(Ωj(p))T。
步骤4设m为Ωj(p)中与客户j分配在一起的客户数量,令m=0,sn m=j。
①找到Ωj(p)中的最大值cij(p),然后依次进行下面的聚类步骤;
②令m=m+1,sn m=i;
③如果条件
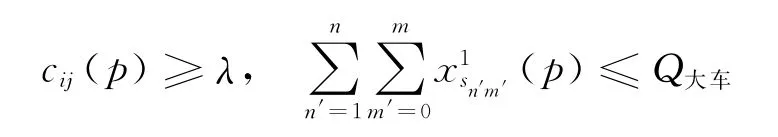
双向配送,即既送货又取货
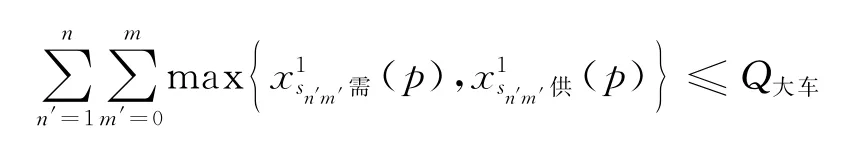
成立,则将客户i、j分配在一组,并在矩阵Ω(p)中删除与客户i对应的行(Ωi(p))T;
④返回①,继续检查Ωj(p)中的其他元素,直到没有元素满足上述聚类条件;
⑤从矩阵Ω(p)中删除Ωj(p);
⑥如果该阶段分配了一些客户,则分别令sn l(l=1,2,…,m)为目标客户,即j:=sn l,并令n=n+1。返回步骤3,处理Ω(p)中与目标客户相联系的元素。
步骤5终止程序,结束聚类分组。
①如果矩阵中不存在列,则停止聚类程序;
②否则,令k=k+1,返回步骤2,进入下一个循环。
(2)决定某一客户组k终止的2个判定准则。
①客户组中任一元素cij(p)小于预定的客户相关类似的极限λ,即

λ是决定循环次数n和聚类数目k的一个因素,取决于服务的有效性和物流配送业务中的运输工具。由于λ受制于实际应用问题中可得到的服务和运输车辆,最好通过试验测试,如果缺乏试验数据,建议λ>0.5[29]。
②配送车辆容量限制。
(a)单向(送货或取货)物流配送问题。客户组的需求(供应)量之和大于大车容量,即

(b)双向(既送又取)物流配送问题。客户组的需求量与供应量中的较大者之和大于大车容量,即

由式(4)可知,不同的权重向量(w1,w2,…,w8)可以产生不同的相似矩阵,从而得到不同的客户聚类结果。如果某一权重为1.0,就成为考虑单一因素的客户分类方法。特别是当的权重为1.0时,就成为通常的“范围配送”和“时间配送”。
需要说明的是,如果客户i要求将货物送达时间与将货物取走时间不同,应事先将该客户拆分为2个单独的客户参加相似度的计算和聚类。一个客户表示需求客户,其需求量为原客户的需求量,供应量为0,要求服务时间为原客户的需求时间;另一客户表示供应客户,其供应量为原客户的供应量,需求量为0,要求服务时间为原客户的供应时间;2个客户的位置均与原客户相同。
2 算 例
下面通过一个单、双向混合配送线路选择问题来说明本文所提模糊系统聚类方法的有效性和实用性。
设某一物流中心的配送网络中有24个客户,从客户的订单中收集了5个需求属性,分别为订单的到达时间和客户要求的最晚服务时间、客户与物流中心的相对距离、客户的需求(供应)量、客户期望的服务质量以及产品的外部相似性,如表2所示。图3形象直观地反映了物流中心和客户位置。物流中心拥有两种车型,容量分别为2.0 t和3.5 t.运用本文提出的模糊聚类方法为客户分组,要求每组客户只需1辆车进行配送。
计算步骤:
步骤1确定每个需求属性的权重w k(k=1,2,3,4);w1、w2、w3、w4分别为客户要求的最晚服务时间、客户与物流中心的相对距离、客户期望服务质量以及产品外部相似性的重要性。
步骤2计算2个客户之间的期望服务质量和产品外部相似性的相似度。
(1)分别用三角模糊数评价每个客户的期望服务质量和产品外部相似性,如表3所示。
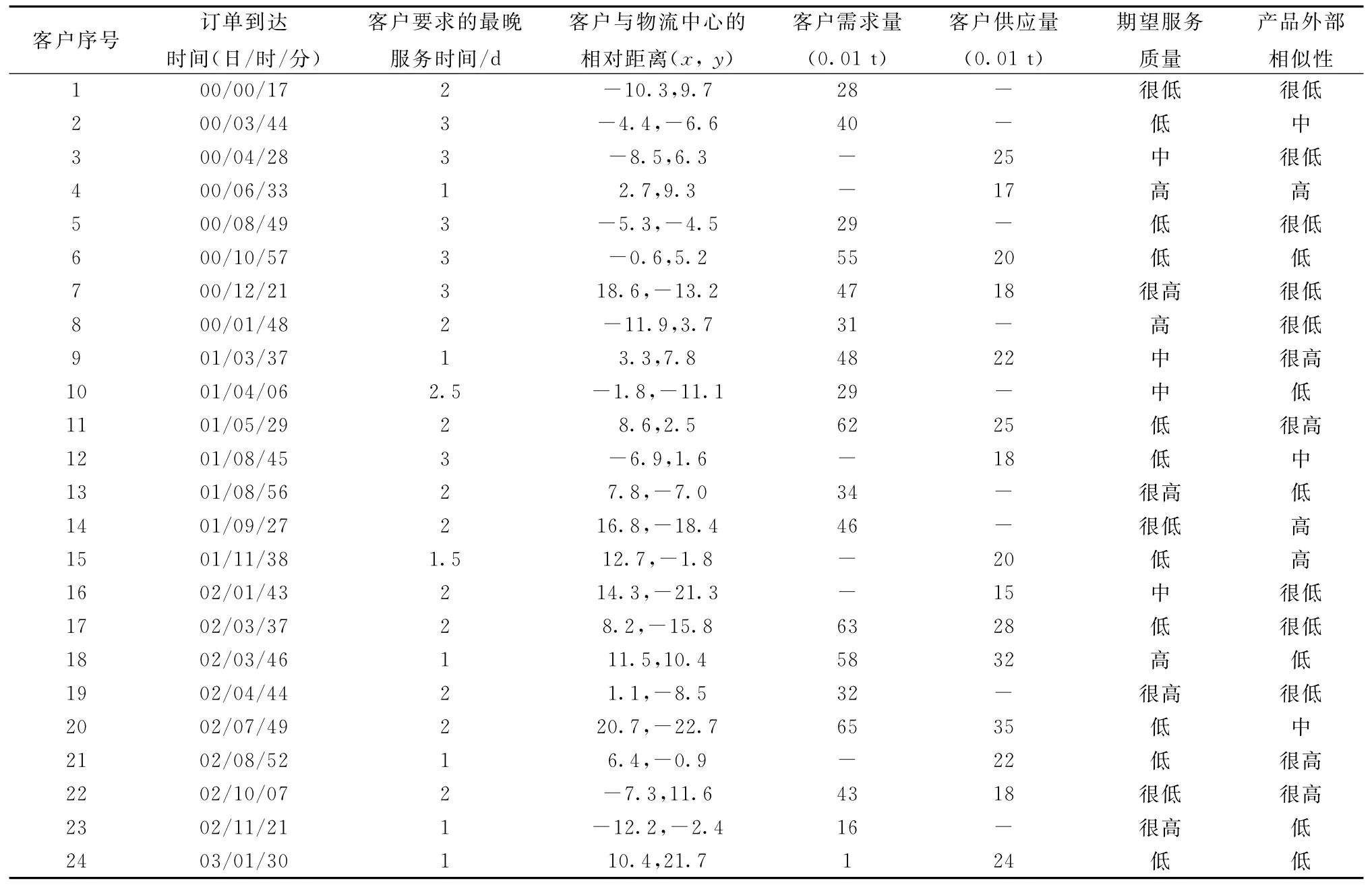
表2 客户的需求属性

图3 客户的地理位置分布
(2)根据式(1)计算2个客户之间的相似度。
步骤3根据式(3)计算2个客户之间的距离和要求最晚服务时间的相似度。
步骤4根据式(4)计算确定权重下的2个客户之间的相似度。
步骤5根据步骤4计算的相似度构造模糊相似矩阵。
步骤6客户聚类。
(1)规定客户相关类似的极限λ=0.7;
(2)客户组的载货量范围:
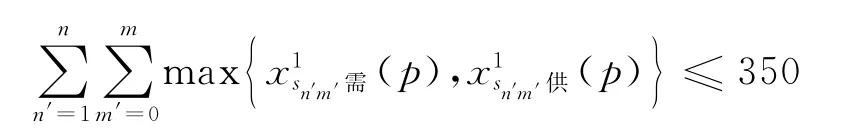
(3)根据1.2节客户分组步骤对24个客户进行聚类,聚类结果如表4所示。表中列出了各种分配权重下的客户分组结果,包括每个客户组的需求量、供应量及其载货量(确定车型的依据)。由表4可见,通过改变4 个需求属性的权重,运用编制的Matlab程序,可以产生不同的分组结果。
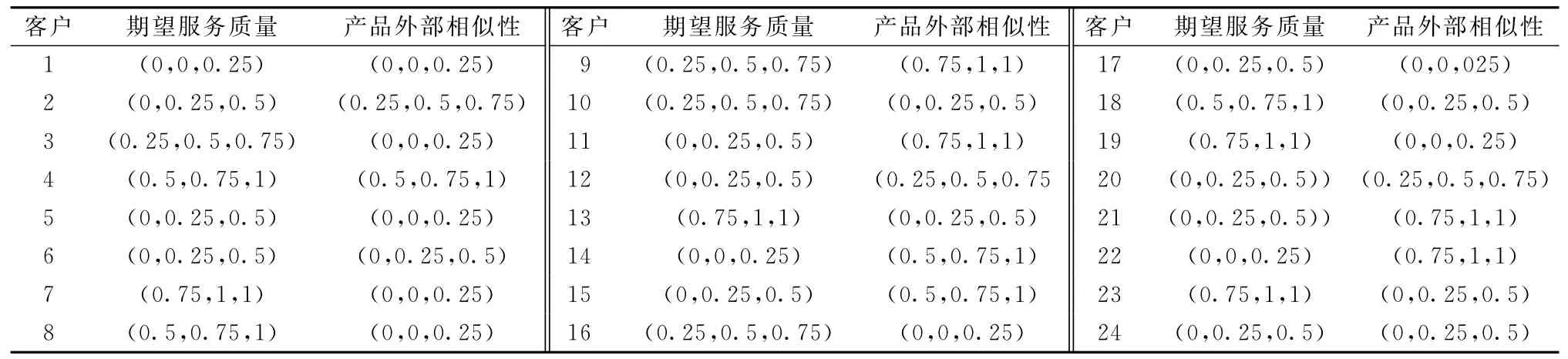
表3 客户期望服务质量和产品外部相似性的三角模糊数评价
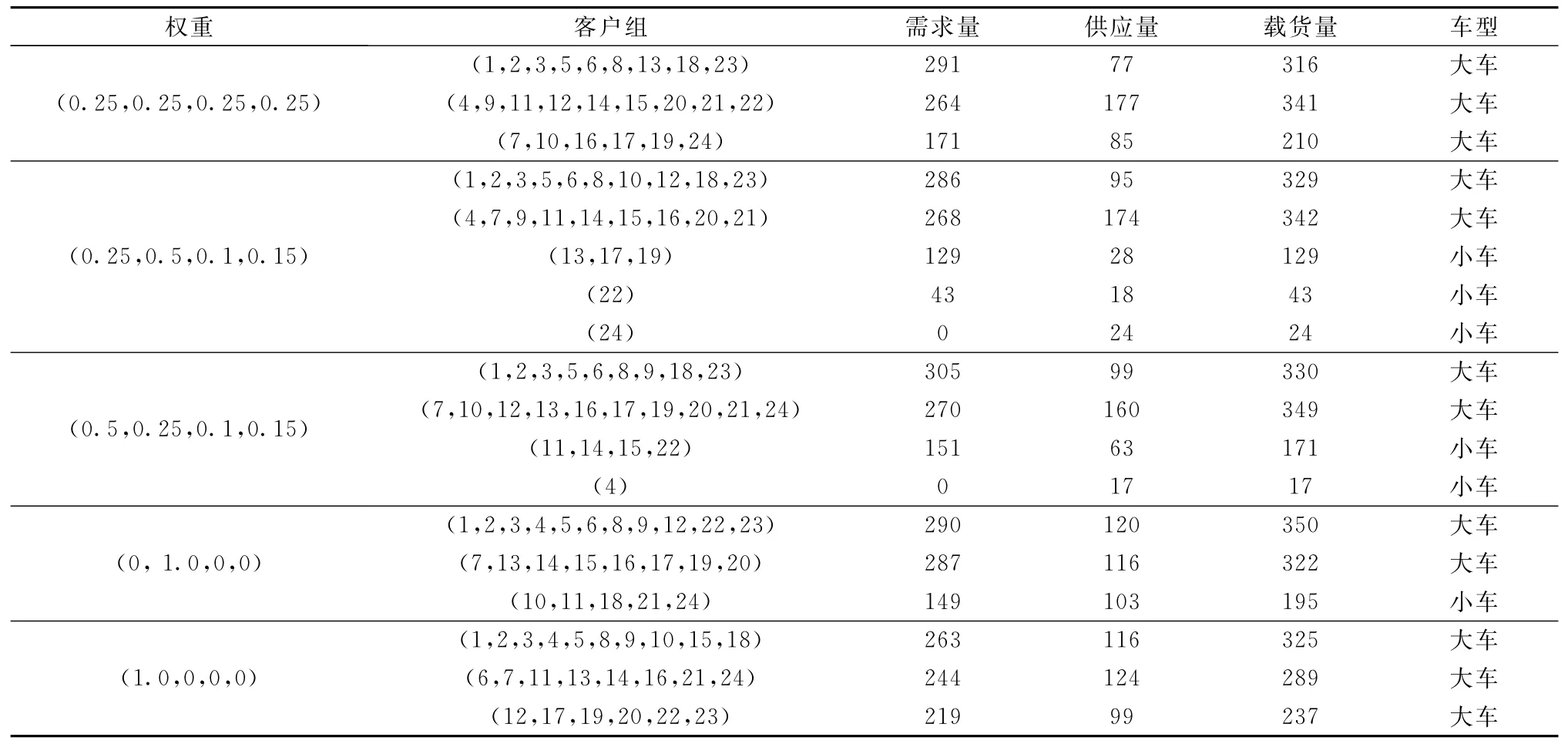
表4 各种分配权重下的客户分组结果
3 结语
本文根据模糊聚类技术提出了一种反应客户定性、定量需求属性的新的行前聚类方法,不仅有益于供给方的有效动态车辆管理,而且可以对客户需求的多样性快速做出反应。首先,通过分析客户的需求属性和较广范围的问卷调查,确定决策变量。然后利用从客户处收集的标准决策变量,对客户进行聚类。该方法共进行3个连续步骤,包括数据处理、相似度计算和模糊相关矩阵的生成以及客户分类。最后,运用前面所提模糊系统聚类方法求解单、双向混合配送线路选择问题,计算结果表明,通过改变决策者对客户需求属性的权重可以得到不同的聚类结果。因此,本文提出的行前客户聚类方法既有效又实用,适用于任何类型(包括单向、双向或单、双向混合)的物流配送线路选择问题,为物流配送线路优化提供了新的思路。
