基于霍克斯过程的社交网络用户关系强度模型
2016-08-12陈鸿昶于洪涛
于 岩,陈鸿昶,于洪涛
(国家数字交换系统工程技术研究中心,河南郑州 450002)
基于霍克斯过程的社交网络用户关系强度模型
于岩,陈鸿昶,于洪涛
(国家数字交换系统工程技术研究中心,河南郑州 450002)
社交网络节点之间的关系强度建模是研究信息传播、实现推荐服务等社交网络服务的关键.传统关系强度模型主要研究简单二元关系与静态关系,未考虑用户交互影响及其动态衰减.本文提出一种基于霍克斯过程的社交网络用户关系强度模型,将用户关系强度视为潜在因子,用户相似性与历史交互行为分别视为潜在因子诱因与表象,并使用霍克斯过程刻画历史交互行为与用户关系强度之间的关系,解决了已有模型未考虑用户历史交互影响及其动态衰减的问题.采用微博社交网络数据对模型进行的评估表明,本模型可以提高用户关系强度预测精度以及基于关系强度排序Top-N邻居节点的覆盖率.
社交网络;霍克斯过程;关系强度预测;微博
1 引言
人际关系将人们现实生活连成一个真实的社交网络,同时也限定着我们每天信息交互范围.而在线社交网络中的朋友关系、关注关系等也限定着我们信息交互对象.现有研究表明利用用户关系强度可以提高对用户社交结构和用户行为预测效果.文献[1,2]研究用户属性相似度与交互相似度,对用户之间的关系进行建模,并在真实网络中进行推荐服务实践,获得了较高的推荐效率与用户满意度.文献[3]提出一种潜在变量模型,将用户之间的关系强度视为引起交互行为的潜在变量,利用概率生成模型与判别式模型得出交互行为与用户关系强度之间的数学关系,并在Facebook与LinkedIn数据集进行算法评估,取得了较高的分类准确率与自相关系数.文献[4]提出一种隐含变量混合模型,检测用户之间的弱关系强度,并分析关系强度对网络结构以及信息传播的影响.
但是,现有的研究主要集中二元关系[5,6](如:是否是朋友关系,关系强弱等等)和静态交互[2,7](未考虑历史交互事件影响).简单的二元关系模型已不能较好满足针对社交网络的应用:商品与服务的推荐、诈骗的防范与追踪、谣言的预防与管控等.这些社交网络应用都需要准确、动态地量化用户之间关系强度,以便保证信息传播效果的准确性与时效性.
在社交网络中,用户的一些属性信息与交互信息是公开的,为研究用户之间的关系强度提供了便利.本文提出一种基于霍克斯过程社交网络用户关系强度模型,以便更为准确地预测用户关系强度.首先,模型将用户之间的关系强度视为潜在因子,用户之间的相似性与历史交互事件是潜在因子的决定因素,而用户之间发生的交互事件是潜在因子的表象;其次,利用判别式模型与生成模型定量分析三者之间的数学关系;最后,在利用腾讯微博公开API接口爬取的数据进行了模型的评估.
2 霍克斯模型分析
该部分主要介绍霍克斯模型应用范围,阐述其物理含义以及解释其对用户关系强度的适应性,并分析用户关系强度的影响因素,提出计算用户关系强度公式.
2.1霍克斯模型

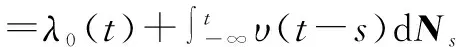
(1)

(2)
霍克斯过程可以表示为如图1所示.
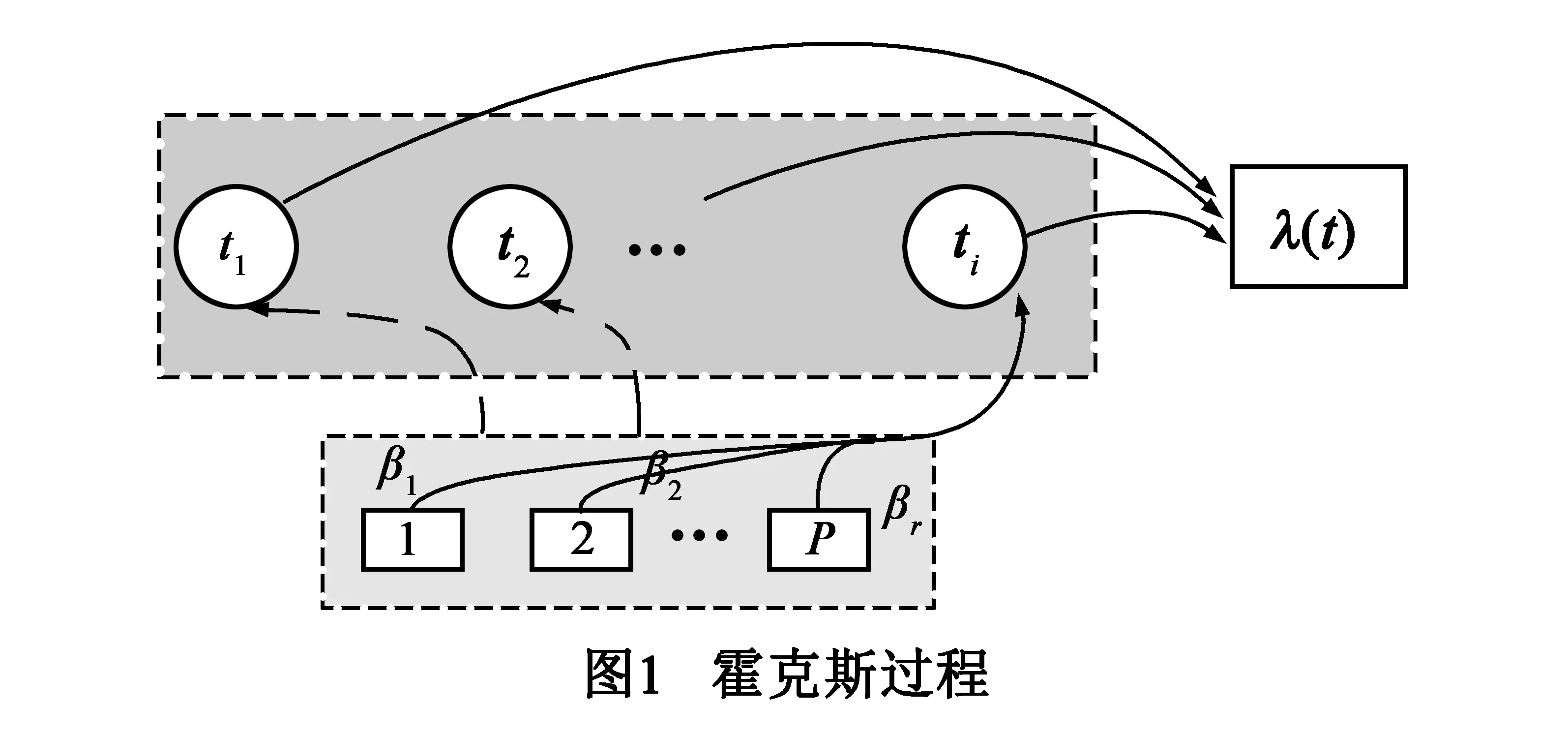
其中序列{ti}为顺序事件集合,序列中每一项是一个事件集合,由P个事件组成.
2.2霍克斯模型的适应性分析
由式(2)可知,霍克斯过程是I维点过程经过线性叠加构成的一种特殊的线性自激过程,其物理含义可以理解为:考察当前事件(点过程)的发生概率(强度),认为当前事件发生概率受历史该类事件的影响,因而可以通过建立历史事件与当前事件的某种关系,进而预测当前事件发生的概率(强度).
对于本文研究的用户关系强度,可理解为用户之间历史交互强度与属性信息相似度的加权和,概率形式表示为式(3),其中a,b分别为用户i与j的交互强度和其属性相似度的权重.
p(z(i,j))=abp(y(i,j))p(s(i,j))
∝p(y(i,j))p(s(i,j))
(3)
用户之间的发生交互行为可以理解成点过程,交互强度即为点过程发生强度,故使用霍克斯过程刻画用户关系强度模型,进行关系强度的预测以及后续的应用.
3 基于霍克斯模型的用户关系强度模型
在社会学中,存在同质相似性原理,在社交网络中该原理同样适用,本模型正是基于这样的假设.该模型包括三部分:属性相似度、用户交互行为与用户关系强度.
3.1用户相似度
用户之间的相似度可以分成文本相似度与背景相似度.
基于同质相似性的假设,得出以下两个结论:
(1)如果两个用户具有相似的属性信息,那么他们具有较强的关系强度,且属性信息越相似,属于同一“圈子”的概率越大,关系强度越强;
(2)如果两个用户发布相似的微博内容,那么他们具有较强的关系强度,且内容越相似,关系强度越强;
基于以上两条结论,本文使用文本相似与属性相似作为影响用户关系强度的两个因素.其中用户的属性信息相对稳定,而微博内容主题变化较大.
3.2用户交互行为
用户之间的交互行为可分为转发、回复与提及.
用户之间的交互行为是用户关系强度的表象,用户之间的关系强度越大,用户之间的交互行为越频繁.同时,用户的历史交互行为也增强了用户之间的关系强度.故用户之间的交互行为即是用户关系强度的表象,也是影响用户关系强度的重要因素.
用户之间交互行为不同于相对静态的属性信息,与文本相似同属于动态影响因素,故本文将微博内容的相似也归为用户交互行为的一种,同样使用霍克斯过程刻画其与用户关系强度之间的关系.
3.3用户关系强度模型构建
文献[3]中提出的一种潜在因子关系强度模型(Latent Factor Relationship Strength Model,LRS)(图2右半部分),预测结果具有较高的自相关性与分类准确性,但是其未考虑用户历史交互行为对用户关系强度的影响,针对这一问题本文提出一种基于霍克斯过程的社交网络用户关系强度模型(A Social Networks User Relationship Strength Model Based on Hawkes Process,HP-URS),将影响用户之间关系强度的因素增加为两类:历史交互事件与属性相似度;模型使用霍克斯过程刻画历史交互事件对当前研究用户之间的关系强度的影响,高斯过程刻画属性相似度对用户之间关系强度的影响,并将历史事件与用户相似度看成相互独立影响用户关系强度的两个因素;将历史事件按时间段提取,而不是按传统方式,不区分历史时间内的事件,以此将时间处理粒度变小,增强模型的实时评估效果.
根据3.1节、3.2节的分析,将影响用户关系强度的因素分成两类,即用户之间的属性相似度与历史交互事件.故模型结构表示为图2所示.
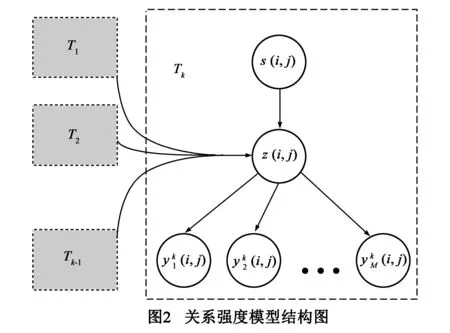
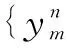
关系强度与交互行为之间表示为生成模型p(z(i,j),y(i,j)).故联合概率密度可写成
(4)
其中,假设当前用户之间的属性相似性与历史交互事件无关,事实上,用户的属性一般是固定的,并不随着用户之间的交互行为而改变,例如用户住址、教育背景、标签等等.因此可以认为用户之间的属性相似性与历史交互事件无关,故式(4)可以写成
(5)
在式(5)中,对于用户属性相似度与用户关系强度之间的概率模型采用普遍的条件概率模型:高斯分布,即
p(z1(i,j)|s(i,j))=N(ωTs(i,j),v)
(6)
其中,为了方便计算令v=0.5,ω为用户属性中各属性对相似度贡献的比重.
对于用户历交互行为与用户关系强度之间的概率模型则使用霍克斯过程模型表示,即
(7)
其中,M表示用户交互行为种类总数,参数αm表示第m项交互行为的权重,βm表示第m项交互行为的时间调节因子(αm>0,βm>0).
(8)

(9)
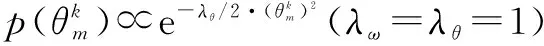
在阶段Tk的取样空间为S={(i1,j1),(i2,j2),…,(iN,jN)},Z={z(i,j)|(i,j)∈S},首先得出联合分布为
(10)
其次,将z(i,j)视为参数,对式(10)求对数得
(z(i,j),ω,θk)
(11)
式(11)的立方项与对数项皆为凹函数,故函数有极值,使用最大似然函数方法,得出如下式
(12)
(13)
(14)
(15)
(16)
对于z(i,j),ω,θk直接采用最大似然估计方法,令式(12)~(14)为0,由式(15)、(16)可以看出,其无法直接为0,故考虑整个研究区间[0,Tk]的最大似然估计.发生强度为λ的点过程的N(t)的最大似然估计可以写成
ln
(17)
故与此相对应的霍克斯过程的似然函数可以写成
=tk-Λ(0,tk)
(18)
其中
(19)
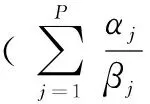
(20)

(21)

4 仿真实验
4.1实验环境及数据
4.1.1实验平台
实验硬件环境:Core(TM) i7双核处理器,主频3.4GHz,内存16GB;实验仿真软件:Matlab2008b,eclipse4.4.
4.1.2实验数据获取及预处理
2013年中国社交网络排名中,QQ空间与腾讯微博用户分列2、3位,总量超过第一的新浪微博.用户通过该平台发表状态、联系好友、获取信息等等,是目前活跃度较大的社交网络平台.
本文数据是利用腾讯微博提供的公开API接口,通过网络爬虫获取,主要步骤是:
(1)选取种子节点,并获取种子节点微博信息;
(2)采用广度优先策略获取种子节点队列中节点的微博信息,并将种子节点的关注列表中的用户作为待获取信息节点,加入种子节点队列;
(3)待获取的节点数达到设定的阈值或者种子节点中无节点.
4.2实验内容及结果分析
采用腾讯微博作为数据源,使用P@N以折扣累计利润 (Discounted Cumulative Gain,DCG)[15]评价指标评价通过HP-URS模型得出的基于用户关系强度排序的用户Top-N邻居节点序列,实验表明该序列相比其他方法得到的序列,具有较高的覆盖率及排序准确率.
4.2.1实验数据处理
实验数据来源2014年06月28日至2014年10月28日腾讯微博公开数据.
考虑降低实验的复杂度,本文将分段时间长度定为5天,并且最多考虑10段时间内的历史交互事件.
通过对微博网络进行分析,确定用户之间的属性相似项为所在地、学校、简介、性别、教育信息与标签信息;用户之间的交互行为包括转发、回复、提及以及微博文本相似性.将这两种影响用户之间关系强度的因素及计算方法分别表示为表1与表2.

表1 用户属性相似度以及度量方法
本文选取50个种子用户节点,考察其一跳范围内的邻居用户节点,由于用户关系强度的直接体现为用户之间的交互行为,故以用户之间的交互频次作为标准,得出用户邻居节点的有序序列S(u),作为基准序列,将HP-URS模型、属性相似度、微博文本相似度以及LRS模型[3]得出的邻居节点序列作为对比序列,其中,属性相似度只考虑用户之间的属性相似性;微博文本相似度只考虑用户之间的文本相似度,LRS模型考虑了用户之间的微博文本相似度与属性相似度,但未考虑用户之间的历史交互行为;HP-URS考虑以上所述三种因素.

表2 用户交互行为以及度量方法
为了进一步验证该模型的有效性,采用[2]中相似性度量模型(Similarity Measure between microblog Users,SMU)作为对比算法,该篇文献将用户关系强度定义为用户之间的相似度,通过分析用户的各种信息,最后得出能反映其社交信息的关注信息与粉丝信息作为度量用户关系强度指标效果最好.本文采用SMU作为对比模型,检验HP-URS模型的有效性.
4.2.2实验结果评价
按照表1与表2的方法计算用户在各阶段的交互向量以及在所考察阶段的用户与其邻居节点之间的用户相似性,利用3.3节中的最大似然公式计算各参数,预测用户与邻居节点之间的关系强度,并使用两种评价指标P@N、DCG对实验结果评价.
(1)P@N评价方法
该评价方法是覆盖率评价指标,评价对比序列表中包含的基准序列中用户数量占基准序列中总用户数量的比重,采用五种序列作为对比序列,分别属性相似度序列、微博文本相似度序列、通过LRS得到的序列、通过SMU模型得到序列以及通过HP-URS得到的序列,结果如图3所示(N=10,20,30,40,50)

由图3可以看出,基于属性相似度得出的用户关系强度Top-N列表的P@N值最小,而基于文本相似度、LRS与 SMU模型得出P@N值相差不大,HP-URS的P@N值最大.由除SMU曲线外,四条曲线之间的关系可以得出影响用户关系强度的因素主要是用户之间的交互行为以及用户微博文本之间的相似度;由SMU模型与HP-URS模型之间的对比证明与SMU模型相比,本模型在覆盖率上具有一定的优势,但稳定性略逊与SMU模型.该模型相比于实验表明HP-URS模型可以提高基于用户关系强度排序的Top-N序列的预测覆盖率.
(2)DCG评价方法
针对P@N评价方法未能考虑对比序列元素之间的排序缺点,引入推荐系统中排序准确率评价方法:DCG,其主要思想是与关系强度用户喜欢的商品被排在推荐列表前面比排在后面会更大程度上增加用户体验,定义为:
(22)
式中,ri表示排在对比序列第i位的邻居节点是否在基准序列中;ri=1表示在;ri=0表示不在;b是自由参数多设为2;L为推荐列表长度.结果如图4所示(N=10,20,30,40,50)
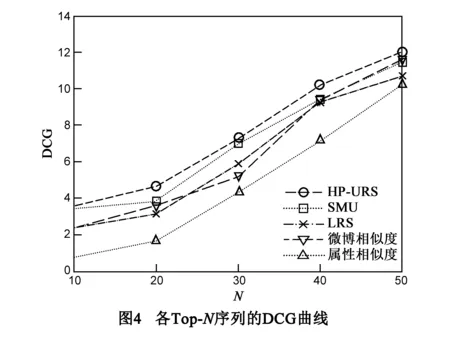
由图4可以看出,五种预测序列的DCG值排序与P@N值排序大体一致,HP-URS模型与SMU模型在预测排序准确性效果最好,原因是在本质上,SMU模型考虑的核心是用户之间的社交信息,是用户交互行为的一种体现,但是由于其未考虑随着时间社交关系的变化,无论从覆盖率还是排序准确率上都略逊HP-URS模型.进一步证实影响用户关系强度的因素主要是用户之间交互行为与微博文本的相似度,而微博文本的本质即为用户的兴趣.
5 总结
本文利用腾讯微博的数据,提出基于一种基于霍克斯过程社交网络用户关系强度模型,考虑用户之间的历史交互行为、微博文本相似度与属性相似度对用户之间的关系强度进行建模,实验结果表明影响用户之间的关系强度的因素主要是用户的交互行为与微博文本相似度,属性相似度只能在一定程度上表征用户之间的关系强度.实验结果还表明,HP-URS模型在预测用户关系强度上能提高预测Top-N序列覆盖率与排序准确性.
本文中关于高斯分布的参数选择了经典的、具有代表性的值,取得了显著的实验效果,但并不是最优解;模型对数据的完整性与有效性要求较高,鲁棒性与健壮性有待进一步加强.下一步的工作针对以上不足,对模型进一步优化.
[1]荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.
Rong Hui-gui,Huo Sheng-xu,Hu Chun-hua,et al,User similarity based collaborating filtering recommendation algorithm[J].Journal on Communications,2014,35(2):16-24.(in Chinese)
[2]徐志明,李栋,刘挺,等.微博用户的相似性度量及其应用[J].计算机学报,2014,37(1):207-218.
Xu Zhi-ming,Li Dong,Liu Ting,et al,Measuring similarity between microblog users and its application[J].Chinese Journal of Computers,2014,37(1):207-218.(in Chinese)
[3]Xiang R,Neville J,Rogati M.Modeling relationship strength in online social networks[A].Proceedings of the 19th International Conference on World Wide Web[C].Raleigh,North Carolina,USA:ACM,2010.981-990.
[4]Zhang S.Influence of relationship strengths to network structures in social network[A].2014 14th International Symposium on Communications and Information Technologies[C].Incheon,South Korea:IEEE,2014.279-283.
[5]Gilbert E,Karahalios K.Predicting tie strength with social media[A].Proceedings of the SIGCHI Conference on Human Factors in Computing Systems[C].Monterey,California,USA:ACM,2009.211-220.
[6]Panovich K,Miller R,Karger D.Tie strength in question & answer on social network sites[A].Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work[C].Seattle,Washington,USA:ACM,2012.1057-1066.
[7]He Y,Zhang C,Ji Y.Principle features for tie strength estimation in micro-blog social network[A].2012 IEEE 12th International Conference on Computer and Information Technology[C].Chengdu,Sichuan,China:IEEE,2012.359-367.
[8]Liniger TJ.Multivariate Hawkes Processes[D].Zurich:Swiss Federal Institute of Technology Zurich,2009.
[9]Filimonov V,Bicchetti D,Maystre N,et al.Quantification of the high level of endogeneity and of structural regime shifts in commodity markets[J].Journal of International Money and Finance,2014,42:174-192.
[10]Bowsher C G.Modelling security market events in continuous time:Intensity based,multivariate point process models[J].Journal of Econometrics,2007,141(2):876-912.
[11]Hawkes A G,Adamopoulos L.Cluster models for earthquakes:Regional comparisons[J].Journal of the International Association for Mathematical Geology,1976,8(4):463-475.
[12]Juncen L,Sheng G,Yu Z,et al.Inferring links in cascade through Hawkes process based diffusion model[A].2014 4th IEEE International Conference on Network Infrastructure and Digital Content[C].Beijing,China:IEEE,2014.471-475.
[13]Ozaki T.Maximum likelihood estimation of Hawkes′ self-exciting point processes[J].Annals of the Institute of Statistical Mathematics,1979,31(1):145-155.
[14]Guo C,Luk W.Accelerating maximum likelihood estimation for Hawkes point processes[A].2013 23rd International Conference on Field Programmable Logic and Applications[C].Porto,Portugal:IEEE,2013.1-6.
[15]朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):163-175.
Zhu Yu-xiao,Lv Lin-yuan.Evaluation metrics for recommender systems[J].Journal of Electronic Science and Technology.2012,41(2):163-175.(in Chinese)

于岩男,1989年6月生于吉林白城.现为国家数字交换系统工程技术研究中心硕士研究生.主要研究方向为数据挖掘与电信网信息关防.
E-mail:yuyneil@gmail.com

陈鸿昶男,1964年4月生于河南新密.现为国家数字交换系统工程技术研究中心教授、博士生导师.主要研究方向为电信网信息关防与信息通信安全.
E-mail:chenhongchang@ndsc.com.cn
A Social Networks User Relationship Strength Model Based on Hawkes Process
YU Yan,CHEN Hong-chang,YU Hong-tao
(ChinaNationalDigitalSwitchingSystemEngineering&TechnologicalR&DCenter,Zhengzhou,Henan450002,China)
The relationship strength model between social network nodes is the key of social networks service such as information dissemination researches and recommendation system.The traditional researches focus on modeling simple binary relations and static relations,without considering dynamic attenuation of user interaction effects.Aiming at this problem,this paper proposes a social networks user relationship strength model based on Hawkes process(HP-URS),which takes the relationship strength,similarity and history interaction behavior between users as a latent factor,latent factor incentive and presentation respectively.This model uses Hawkes process to characterize relationship between history interaction behavior and user relationship strength.This model provides a solution of the disadvantages of the original model without considering user history interaction effects and their attenuation.This paper uses the data from microblog social networks evaluating HP-URS model,and the experimental results show that this model can improve relationship strength prediction accuracy and coverage rate of the Top-Nneighbor nodes based on relationship strength.
social networks;Hawkes process;relationship strength prediction;microblog
2014-11-15;修回日期:2015-03-30;责任编辑:覃怀银
2014年国家科技支撑计划(No.2014BAH30B01)
TP393
A
0372-2112 (2016)06-1362-07
