空间近似关键字反远邻查询
2016-08-12邰伟鹏岳建华陈业斌
邰伟鹏,岳建华,邓 育,陈业斌,秦 锋
(1.中国矿业大学资源与地球科学学院,江苏徐州 221116; 2安徽工业大学计算机与技术学院,安徽马鞍山 243032)
邰伟鹏1,2,岳建华1,邓育2,陈业斌2,秦锋2
(1.中国矿业大学资源与地球科学学院,江苏徐州 221116; 2安徽工业大学计算机与技术学院,安徽马鞍山 243032)
空间数据集中的点普遍由空间信息及描述文本信息组成.空间近似
反远邻查询(Approximate String Reverse Furthest Neighbors Search,ASRFNS)问题是在一个空间数据集中搜索所有以给定查询点为最远邻,且满足文本相似度条件的目标.基于现有的空间反远邻查询算法以及近似
查询算法,我们提出了两个基本的解决算法:凸包最远单元交集(CHFCsJoin) 算法和凸包最远单元近似字符串串行查询(CHFCASSS) 算法;我们又设计了一种包含空间和
信息的外存索引结构Filter-Rtree,并给出了相应的凸包最远单元过滤R树(CHFilterRtree)高效算法.通过真实数据集的实验测试,验证这三种算法的有效性,并分析比较了其性能与效率.
近似
查询;反远邻查询;空间数据库;外存索引
1 引言
RFN作为空间数据库查询的一部分,近年来逐渐被许多学者深入研究.Bin Yao等人对于单色反远邻问题提出的改进的高效算法凸包最远单元算法(CHFC,the Convex Hull Furthest Cell algorithm),证明了只有在查询点位于凸包上或者凸包外侧时,查询点才会有最远voronoi单元,以凸包求出最远voronoi单元,进而在R-tree上执行一个范围查询,可以高效的得到查询点的反远邻[4].而近似字符串查询算法一直以来都是广大学者的研究热点[10~12],大多数算法采用q-gram技术,依靠倒排列表来产生候选字符串,相似的字符串之间必然有足够多相同的gram.基于这个原理, Heap算法和MergeOpt算法,ScanCount算法,MergeSkip算法和DivideSkip算法等高效的近似关键字查询算法被提出,还可以加入长度(length filter)、位置(position filter)、前缀(prefix filter)等字符串过滤器快速排除不符合条件的字符串,进一步提高查询效率[10,11].
2 问题的定义
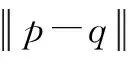
空间反远邻分为单色反远邻(MRFN)和双色反远邻(BRFN)问题,但因其解决方法相似,本文仅以MRFN分析空间近似关键字反远邻问题.
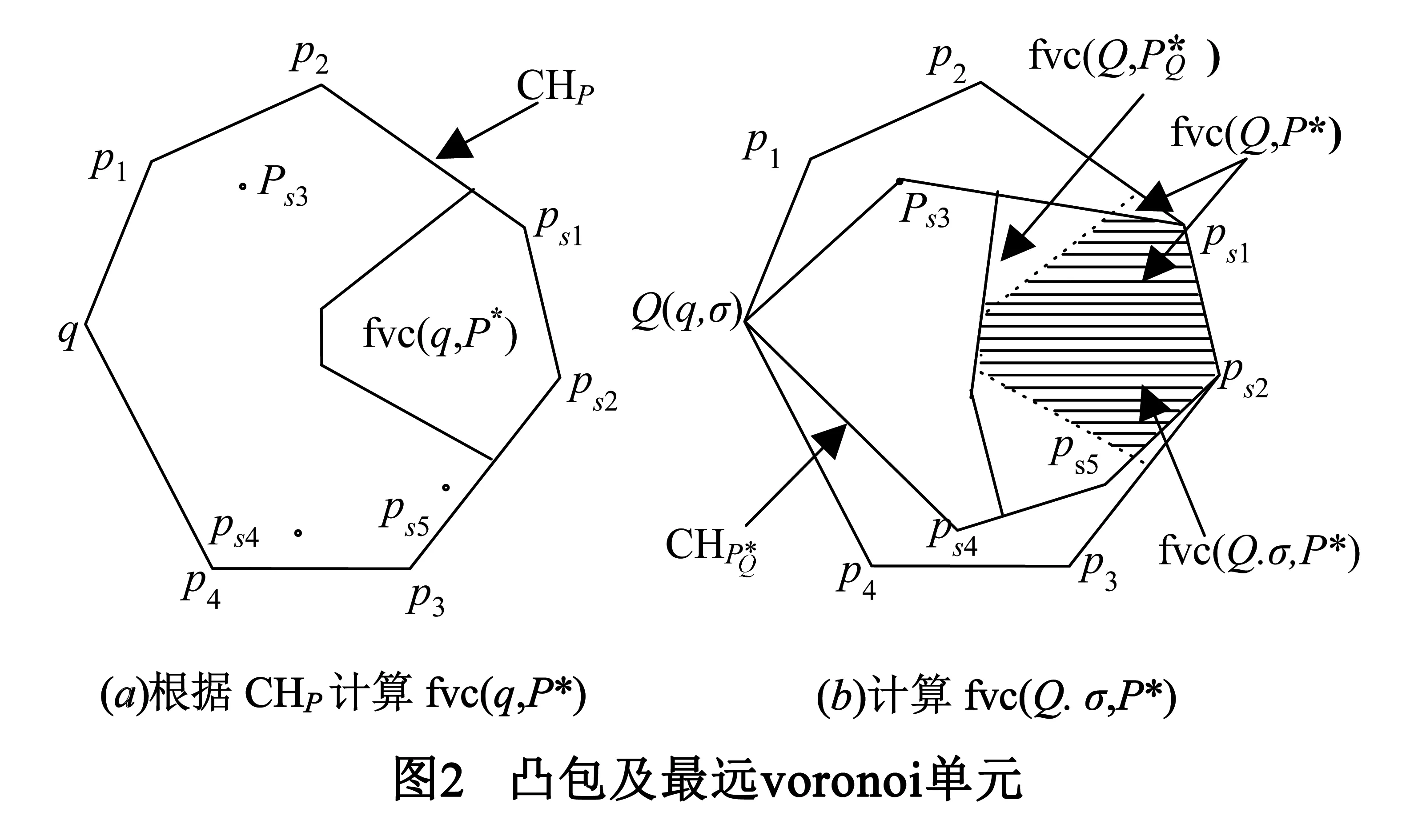
定义2单色反远邻查询的是指给定一个查询q,在P中找到所有以q点为最远邻的点集,即MRFN(q,P)={p|p∈P,fn(p,P{q})=q}.
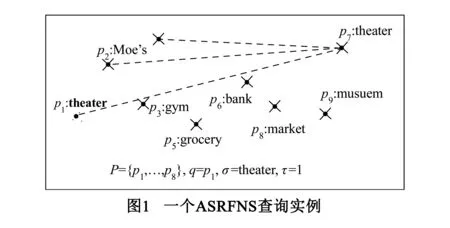
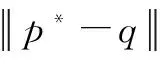
定义3给定一个带字符串的查询点Q(q,σ),其中q代表点的坐标信息,σ表示一个字符串,Ε(σ1,σ2)为字符串σ1与σ2之间的编辑距离.则近似字符串反远邻查询是指在P中找出所有以Q点为最远邻且字符串与Q.σ满足给定字符串相似度条件的点集.设编辑距离的阈值为τ,近似字符串反远邻查询可表示为ASRFNS(Q,τ,P)={p|p∈P,fn(p,P{Q})=Q,E(p.σ,Q.σ)≤τ}.
3 ASRFNS问题的基本解决方法
对于空间近似字符串反远邻查询,目前还没有针对的解决算法.空间查询的对象是空间数据集,而文本查询对象是文本数据集,此二者有独立的查询处理方法.针对ASRFNS问题可以通过分别处理空间数据与文本数据,再结合二者查询结果的方法来解决.基于上述思路,提出了如下两种算法.
3.1凸包最远单元交集算法
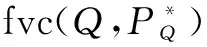
3.2凸包最远单元近似字符串串行查询算法
凸包最远单元近似字符串串行查询(CHFCASSS)算法首先得到查询点在给定数据集上的反远邻集合作为候选集,对此,利用现有的CHFC算法,再针对候选的反远邻集合执行近似字符串查询算法.
4 ASRFNS问题的高效算法——凸包最远单元过滤R树算法
4.1索引结构Filter-Rtree
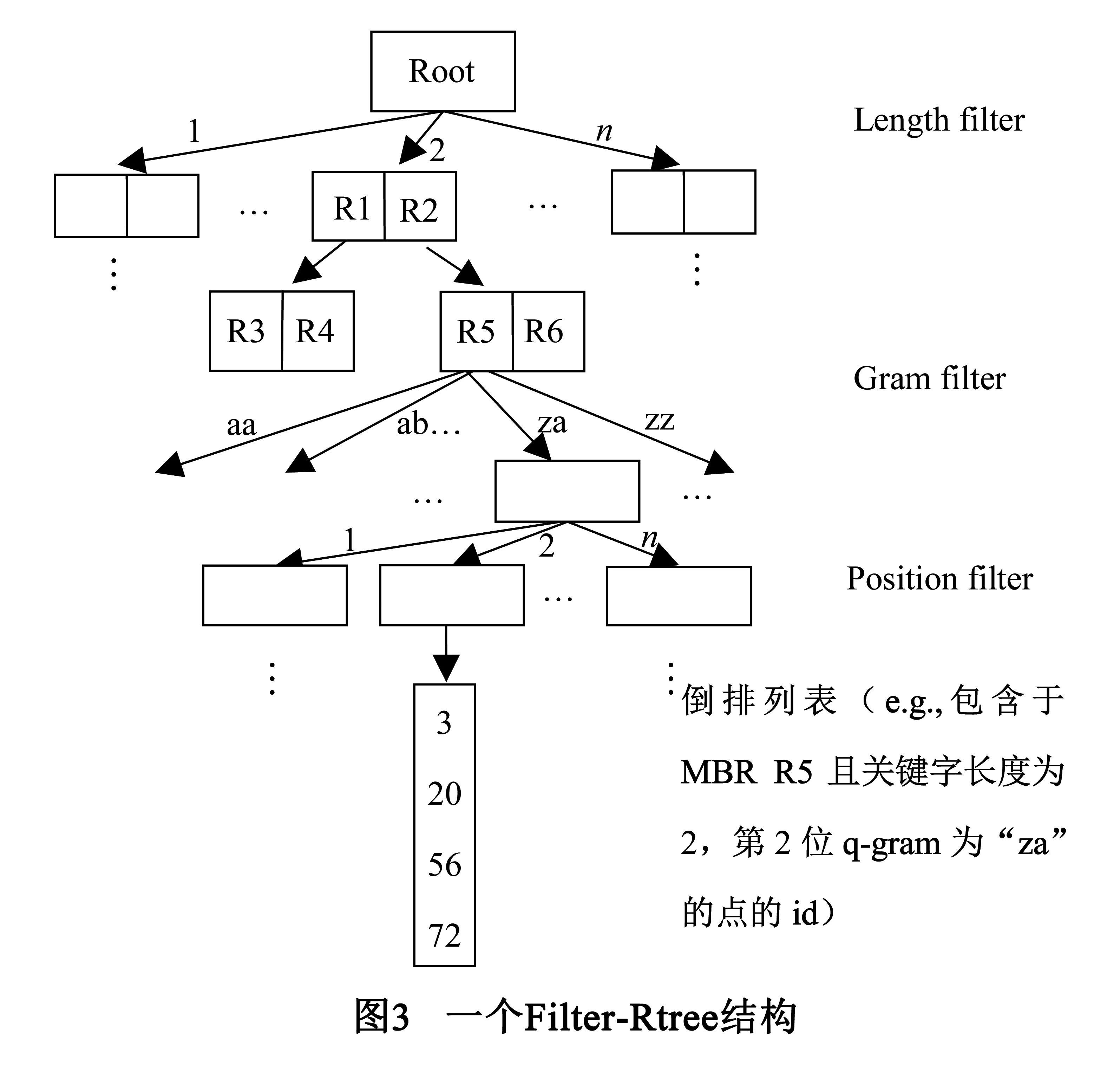
过滤器的不同使用方法将直接影响到算法的性能优劣.首先使用单签名过滤器,再加入多签名过滤器.
4.2查询算法
由于查询算法同样是基于凸包,求出查询点的最远voronoi单元,所以将此算法命名为凸包最远单元过滤R树算法(CHFilterRtree).同前两种算法一样,首先需要通过给定的查询点位置信息和数据集得到查询点的最远voronoi单元.再以这个voronoi单元为一个查询范围配合所要求的查询关键字及阈值在Filter-Rtree上执行近似关键字范围查询.
算法1CHFilterRtree(Query Q(q,σ),int τ)
1.LetLbe a FIFO queue initialized to ∅;
2.Set FvcSet=∅,ResultSet=∅;
3./*第1步:先执行空间部分的查询,得到Q在数据集P中所有的反远邻集合FvcSet */
4.Compute convex hullCPof datasetP;
5.ifQ⊂CPthen return ∅;
6.else
7.ComputeCP*usingCP∪{Q};
8.Set fvc (Q,P*) equal to fvc(Q,CP*);
9./*第2步:为数据集P构建Filter-Rtree FRT*/
10.Create Filter-Rtree FRT of datasetP;
12.Letube the root node of FRT;
for every child entryciofudo
13.LetLbe a FIFO queue initialized to ∅;
14.LetLbe a FIFO queue initialized to ∅;
15.Set FvcSet=∅,ResultSet=∅;
16./*第1步:先执行空间部分的查询,得到Q在数据集P中所有的反远邻集合FvcSet */
17.Compute convex hullCPof datasetP;
18.ifQ⊂CPthen return ∅;
19.else
20.ComputeCP*usingCP∪{Q};
21.Setfvc(Q,P*) equal to fvc(Q,CP*);
22./*第2步:为数据集P构建Filter-Rtree FRT*/
23.Create Filter-Rtree FRT of datasetP;
25.Letube the root node of FRT;
26.for every child entryciofudo
27.If |ci|≥|Q.σ-τ| and |ci|≤|Q.σ+τ| then
28.Insert the child nodeuiintoL;
29.WhileLis not empty do
30.Pop the head entryeofL;
31.Ifeis a leaf node then
32.Ife∩fvc(Q,P*)≠∅ then
33.Let list be the inverted list contained bye;
34.Letp1,…,pfbe the results after performing an approximate string search merging algorithm(e.g.,MergeSkip algorithm) with list;
35.Fori=1,…,fdo
36.Ifpiis contained in fvc(Q,P*) then
37.Insertpinto ResultSet;
38.Else
39.Letw1,…,wfbe children MBRs of nodee;
40.Fori=1,…,fdo
41.Ifwi∩fvc(Q,P*)≠∅ then
42.Insert the child nodewiintoL;
ReturnResultSet;
CHFilterRtree算法求出数据集P的凸包,判断查询点q的位置是否在凸包内部,如果在,说明查询点在数据集P上不存在反远邻,返回空集;否则继续.利用得到的凸包计算查询点q的最远voronoi单元,这个单元将作为查询区域作用于其后的Filter-Rtree上.为数据集P创建Filter-Rtree,整个Filter-Rtree结构存储于外存中.Filter-Rtree的第一层根据查询关键字的长度剔除掉那些不可能满足阈值条件的点;满足条件的关键字长度分别对应着一个Rtree子树,在各个Rtree子树上以之前得到的最远voronoi单元执行空间范围查询,找到与单元相交的Rtree叶子结点,再根据position filter取出我们想要的倒排列表,分别对每个倒排列表执行近似关键字查询合并算法,分别判断所得关键字匹配点是否在最远voronoi单元中,如果是,则点是要找的最终结果,即查询点的一个近似关键字反远邻对象.
5 实验结果与分析
5.1实验设置
测试平台为一台PC机,配置为i5-2400四核CPU,主频为2.80GHz,8GB内存;7200转500GB硬盘,系统为Linux.算法由GNU C++语言编程实现.磁盘页面大小为4KB.实验使用的真实数据集CA来自开源项目Open Street Map Project,包含1,983,155条元组,每个元组包含一个标识,一个二维坐标和一组字符串描述文本.
5.2预处理结果分析
三种算法预处理时都要构建外存空间索引,其中,CHFCsJoin和CHFCASS是串行处理方式,在空间查询部分构建的是传统的Rtree索引,而CHFilterRtree算法则需要构建FilterRtree.对CA数据集预处理,分别构建索引,记录其所占空间及构建时间,实验次数为3次,取记录的均值,如表1所示.
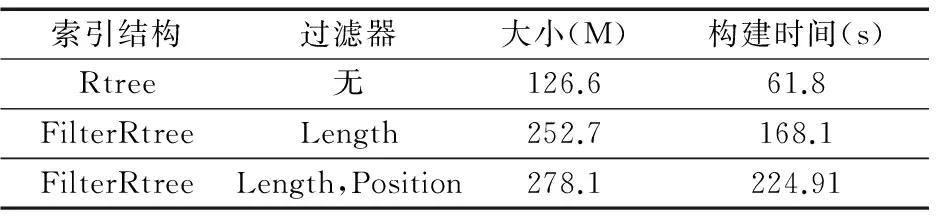
表1 索引构建代价
从表1可以看出,FilterRtree索引较传统Rtree索引占更多地外存空间,构建时间也明显高于Rtree,这是由于FilterRtree将记录关键字信息的倒排列表加入到R-tree中,还加入了特定的Filter.而在FilterRtree加入两种过滤器的构建代价也要明显大于只加入一种过滤器.由于FilterRtree索引是外存索引,构建的代价较大,其插入更新的代价也很大,因此,此适用于更新周期较长的数据集,每次数据集更新,索引将被重新创建.
5.3查询结果分析
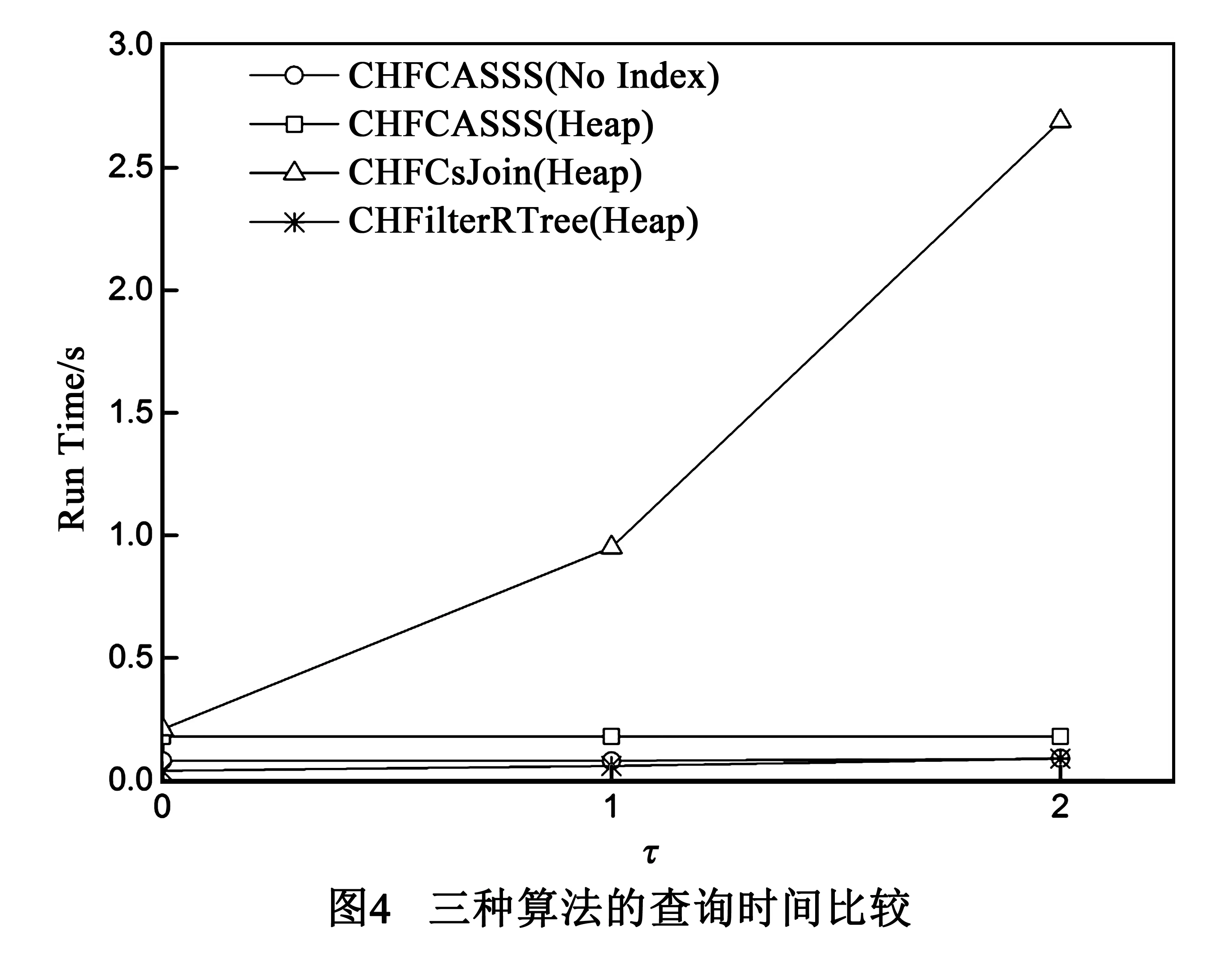
考虑到图3中在处理倒排列表时,使用了基础的Heap算法.使用在处理性能上更优的MergeSkip算法,试图提高三种算法查询性能.从图5可以看出,采用MergeSkip算法处理字符串数据的方法可以有效减少三种算法的查询时间,提高算法性能,而对CHFCsJoin算法的影响尤为显著.这是由于CHFCsJoin算法首先处理全部查询点的文本数据,文本数据量很大,MergeSkip算法的优越性得到了较好的体现,而CHFCASSS算法是对满足空间条件的点处理其文本信息,数据量相对小的多,MergeSkip算法效果不明显,CHFilterRtree算法采用Filter-Rtree索引结构,查询性能明显优于之前两种算法,而因其分批处理倒排列表,倒排列表的规模很小,Heap算法和MergeSkip算法对其查询性能的影响忽略不计.
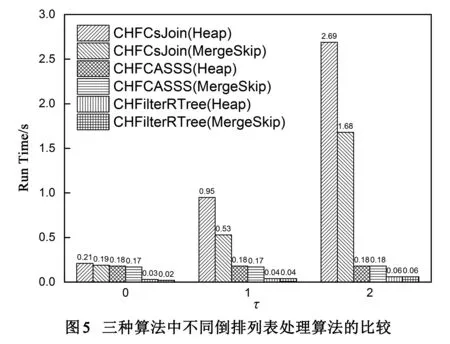
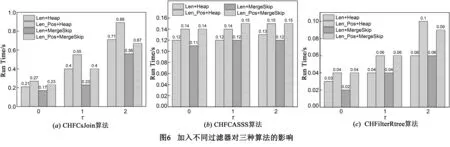
在倒排列表索引中加入不同的过滤器也会最终影响三种算法的查询性能.如图6所示,无论是在处理倒排列表时采用Heap或MergeSkip算法,仅加入了Length过滤器的效率要略优于加入Length和Postion过滤器,这也验证了文献[11]所指出的过滤器的使用原则,即过滤器并非加入的越多越好,过滤器的加入具有数据集相关性,不同的数据集可能有不同的过滤器最优搭配方式.
6 结论
[1]Feifei Li,Bin Yao,Mingwang Tang,et al.Spatial approximate string search[J].TKDE,2013,25(6):1394-1409.
Wang Jin-bao,Gao Hong,Li Jian-zhong,et al.Index supporting spatial approximate keyword search on disks[J].Journal of Computer Research and Development,2012,49(10):2142-2152.(in Chinese)
[3]Jiaheng Lu,Ying Lu,Gao Cong.Reverse spatial and textualknearest neighbor search[A].SIGMOD 2011[C].Athens:ACM,2011.349-360.
[4]Bin Yao,Feifei Li,Piyush Kumar.Reverse furthest neighbors in spatial databases[A].Proceedings of the 25th International Conference on Data Engineering[C].Shanghai:IEEE,2009.664-675.
[5]Gísli R Hjaltason,Hanan Samet.Distance browsing in spatial databases[J].ACM Trans Database System,1999,24(2):265-318.
[6]Bin Yao,Feifei Li,Piyush Kumar.Knearest neighbor queries and KNN-Joins in large relational databases (almost) for free[A].Proceedings of the 26th International Conference on Data Engineering[C].Long Beach:IEEE,2010.4-15.
[7]Flip Korn,Suresh Muthukrishnan.Influence sets based on reverse nearest neighbor queries[A].SIGMOD 2000[C].Dallas:ACM,2000.201-212.
[8]Rimantas Benetis,Christian S Jensen,Gytis Karciauskas,et al.Nearest and reverse nearest neighbor queries for moving objects[J].The VLDB Journal,2006,15(3):229-249.
[9]蒋涛,高云君,张彬,等.不确定数据查询处理[J].电子学报,2013,41(5):966-976.
Jiang Tao,Gao Yun-jun,Zhang Bin,et al.Query processing on uncertain data[J].Acta Electronica Sinica,2013,41(5):966-976.(in Chinese)
[10]Sunita Sarawagi,Alok Kirpal.Efficient set joins on similarity predicate[A].SIGMOD 2004[C].Paris:ACM,2004.743-754.
[11]Chen Li,Jiaheng Lu,Yiming Lu.Efficient merging and filtering algorithms for approximate string searches[A].Proceedings of the 24th International Conference on Data Engineering[C].Cancún:IEEE,2008.257-266.
[12]Ian De Felipe,Vagelis Hristidis,Naphtali Rishe.Keyword search on spatial databases[A].Proceedings of the 24th International Conference on Data Engineering[C].Cancún:IEEE,2008.656-665.

邰伟鹏男,1979生出生于安徽马鞍山,博士研究生,副教授.研究方向为时空数据库、移动互联网.
E-mail:taiweipeng@ahut.edu.cn
岳建华男,1964年出生于山东济宁,教授,博士生导师,研究方向为地球物理,GIS系统.
邓育男,1990年出生于安徽六安,硕士研究生.研究方向为时空数据库.
陈业斌男,1971年出生于安徽滁州,教授.研究方向为时空数据库.
秦锋男,1962年出生于安徽马鞍山,教授.研究方向为人工智能.
Approximate String Reverse Furthest Neighbors Search
TAI Wei-peng1,2,YUE Jian-hua1,DENG Yu2,CHEN Ye-bin2,QIN Feng2
(1.SchooloftheEarthScienceandResources,ChinaUniversityofMiningandTechnology,Xuzhou,Jiangsu221008,China;2.SchoolofComputerScience,AnhuiUniversityofTechnology,Ma’anshan,Anhui243032,China)
The points of spatial dataset usually consist of the spatial information and the described text information.The problem of approximate string reverse furthest neighbors search(ASRFNS) query is defined to search all points in a spatial dataset that take the given query point as its furthest neighbor while their text satisfies the string similarity constraint.Based on the existing reverse furthest neighbors search algorithm and approximate string search algorithm,we proposed two solution algorithms:the convex hull furthest cells join algorithm(CHFCsJoin) and the convex hull furthest cell approximate string serial search algorithm(CHFCASSS).In order to further improve the query performance,we also proposed an efficient algorithm of the convex hull furthest cell filter-Rtree(CHFilterRtree) which contains disk resident structure of space and keyword information.With the real dataset experiments and analysis,the results demonstrate that our proposed algorithms obtained a good performance.
approximate string search;reverse furthest neighbors search;spatial database;disk resident index
2014-10-15;修回日期:2014-04-12;责任编辑:梅志强
国家自然科学基金项目(No.61003311);安徽高校省级自然科学研究重大项目(No.KJ2014ZD05);安徽高校省级自然科学研究重点项目(No.KJ2013Z023,No.KJ2013A058);安徽省振兴计划资助项目(No.2013ZDJY073)
TP311
A
0372-2112 (2016)06-1343-06
