基于协同矩阵分解的评分与信任联合预测
2016-08-09张维玉耿玉水
张维玉,吴 斌,耿玉水,朱 江
(1.北京邮电大学智能通信软件与多媒体北京市重点实验室,北京 100876;2.齐鲁工业大学信息学院,山东济南 250353)
基于协同矩阵分解的评分与信任联合预测
张维玉1,2,吴斌1,耿玉水2,朱江1
(1.北京邮电大学智能通信软件与多媒体北京市重点实验室,北京 100876;2.齐鲁工业大学信息学院,山东济南 250353)
信息评分预测和信任预测是社交评价网络中的两大基本问题.为应对在提高两类基本问题预测准确性过程中遇到的评分数据与信任关系数据稀疏问题,本文提出了一种基于协同矩阵分解的信息评分与信任预测联合模型.该模型在将评分矩阵与信任关系矩阵进行协同分解时,既能保证被分解的两个矩阵分解过程共享用户潜在变量,又能兼顾两个矩阵分解过程中能够各自获得反映本领域知识相关性的表达.使用分解得到的多个相关低维潜在变量矩阵乘积即可做出评分与信任两个问题的预测.两个真实网络数据集上的实验验证了提出模型有效性和先进性.
推荐算法;信任预测;概率矩阵分解;社交推荐网络
1 引言
随着Web2.0技术和计算机网络技术的不断发展,社交媒体已成为人们进行信息分享、意见表达和结交朋友的主要媒介.一类社交媒体(如:Epinion等)可以方便用户对各种信息进行评论,同时还允许用户对看到的信息进行评分(Rating),另外,这类社交媒体还具备让用户根据对其他用户做出的评分信息的喜好程度来建立信任(Trust)或朋友关系的功能.这类社交媒体的流行使人们相对传统社交媒体更容易获得信息,更容易结交朋友.然而人们在享受这种便利的同时,也在面临着信息过载的困扰.如何更好地向用户推荐潜在有用的信息以及可信任的用户,是社交媒体亟需解决的两大核心问题.
目前信息推荐和好友推荐所面临的主要问题是数据稀疏和冷启动两个方面.在以往研究中,朋友推荐和信息推荐一般分开进行.然而,在社交媒体中用户与用户之间的信任关系和用户与信息之间的评分关系是有关联的.建立信任关系的用户在评价信息的时候更容易做出一致的评分,同时,在信息评分相似的用户间也更容易建立信任关系.基于这一假设,我们将对信任关系的预测和用户对信息评分的预测进行联合研究,旨在同时在这两个问题上获得更好的预测效果.具体来讲我们首先将社交媒体中信任和评分两类关系使用两个矩阵进行描述,然后对这两个矩阵进行协同矩阵分解.协同分解过程中保持潜在用户特征不变,以使两个矩阵分解过程中能够共享特征信息.另外,两个矩阵分解过程中还各自引入一个表达本领域潜在特征相关性的矩阵,使其分解过程能够充分表达领域内的知识特征.协同矩阵分解的结果是一组低维潜在特征矩阵,如潜在用户特征矩阵,潜在信息特征矩阵等.使用多个相关潜在特征矩阵的乘积即可做出评分与信任两类问题的预测.
2 相关工作
信任预测属于链路预测的范畴.链路预测的定义最早由Kleinberg等人在文献[1]中给出.信任预测方面的文献目前主要可以分为无监督信任预测和有监督信任预测两类.无监督信任预测主要是基于信任传播开展研究的,文献[2]最早使用信任传播来研究信任预测的问题.文献[3]使用矩阵分解的方式将信任预测的问题转换为一个优化问题进行求解.有监督信任预测问题本质上讲就是构建一个二元分类器.文献[4]将一个在线社交网络上的分类特征进行了整理,并使用得到的网络特征对分类器进行训练从而进行最终的信任预测.文献[5]则从异质信任关系的角度研究了信任预测、信息推荐等问题.
评分预测是推荐系统的主要功能.传统的推荐系统主要分为两类:基于内容过滤推荐算法和基于协同过滤推荐算法.而基于协同过滤推荐算法又可细分为:基于记忆的方法和基于模型的方法.其中基于内容过滤推荐算法在扩展性方面较差通常无法灵活融合多方面有用信息,而协同过滤算法则可灵活融合显式或隐式评分数据进行推荐.
近年来,矩阵分解算法已成为推荐系统的主流方法.传统的矩阵分解方法有:奇异值分解[6]、非负矩阵分解[7]等方法.为了从概率生成过程角度描述矩阵分解的过程,文献[8]提出了概率矩阵分解方法,该方法适用于观测不完整的评分矩阵.文献[9]提出了一种协同矩阵分解的方法,该方法的优势在于可以同时对多个评分矩阵进行分解,并且分解的过程中可以共享一些潜在特征信息.文献[10]使用协同矩阵分解的方法研究了信息推荐问题,该文章从迁移学习的角度利用用户与信息间的喜好矩阵作为辅助信息进而实现用户对信息的评分预测.文献[11]首次把信任预测和评分预测进行联合研究,但是该文献提出的是一种基于潜在变量的随机游走模型.文献[12]提出了一种基于受限信任关系和概率矩阵分解的推荐方法.
3 问题定义
社交评价网络:是一种包含两种类型节点和两种关系的异质网络.两种类型的节点分别为:用户和信息,分别记为U和I.两种类型的关系分别为用户与用户之间的信任关系和用户与信息之间的评价关系.社交评价网络中的两类关系可以使用两个矩阵表达,即信任关系使用矩阵T表示,评价关系使用矩阵R表示.社交评价网络的结构一般如图1所示:

信任与评价联合预测:在社交网络中,已知观测到的不完整的信任关系和评分关系,利用两种关系的相关性,同时推断出缺失的信任关系与评分信息.
4 JRTPCMF模型
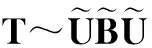
我们假设用户u在信息i上的评价用rui表示,它可以由潜在用户特征向量Uu∈1×du,潜在信息特征向量Vi∈1×dv和矩阵B∈du×dv的乘积得到.为了说明上的方便,我们设定du=dv=d.因此我们可以定义出rui的一个条件概率分布:
(1)
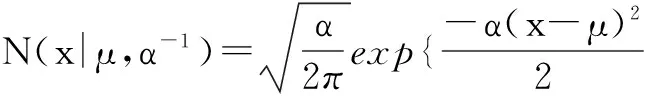
(2)
(3)
P(B|β)=N(B|0,(β/q)-1I)
(4)
ln P(U,B,V|R,αr,αu,αv,β)
P(Uu|αu)P(Vi|αv)P(B|β)]yui
(5)

是一个常数.对于矩阵T使用上述类似方法得到其后验概率:
(6)
将上述两个后验概率进行加权求和,最终我们可以将提出的联合预测模型的优化问题整理为:
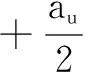
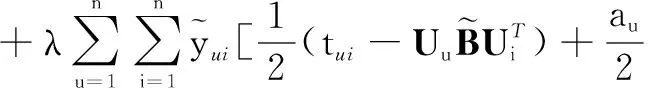

s.t.U∈n×d,V∈m×d
(7)

(1)固定矩阵B和V,求解矩阵U.
我们使用文献[10]中类似的方法,采用解析的方式得到矩阵U的更新公式,具体过程如下:

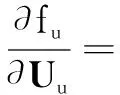

(8)
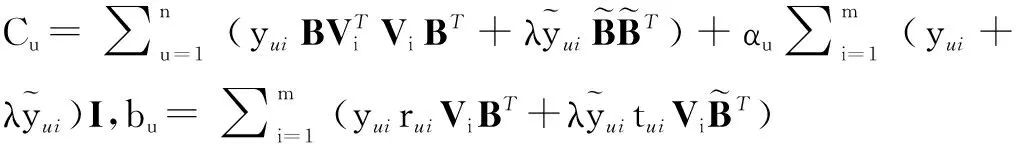
使用上述类似方法,我们固定B和U,可以得到矩阵V的更新公式如式(9)所示:
(9)
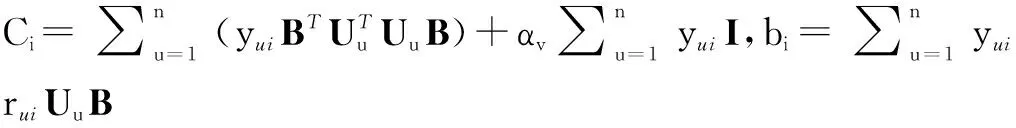
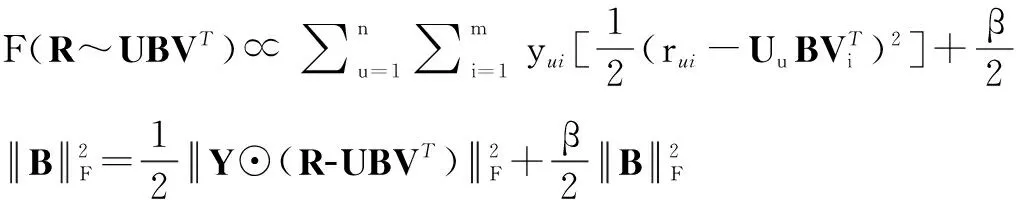
(10)

(11)
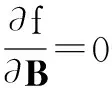
vec(B)=(AT+βI)-1vec(Z)
(12)

5 实验结果及分析
5.1数据集
为了验证提出模型的有效性和先进性,我们使用两种真实的网络数据集进行实验.其中Epinion是一个信息产品资讯网站,Flixster.com则是一个著名社交服务网站.两个数据集的基本信息统计情况如表1所示.
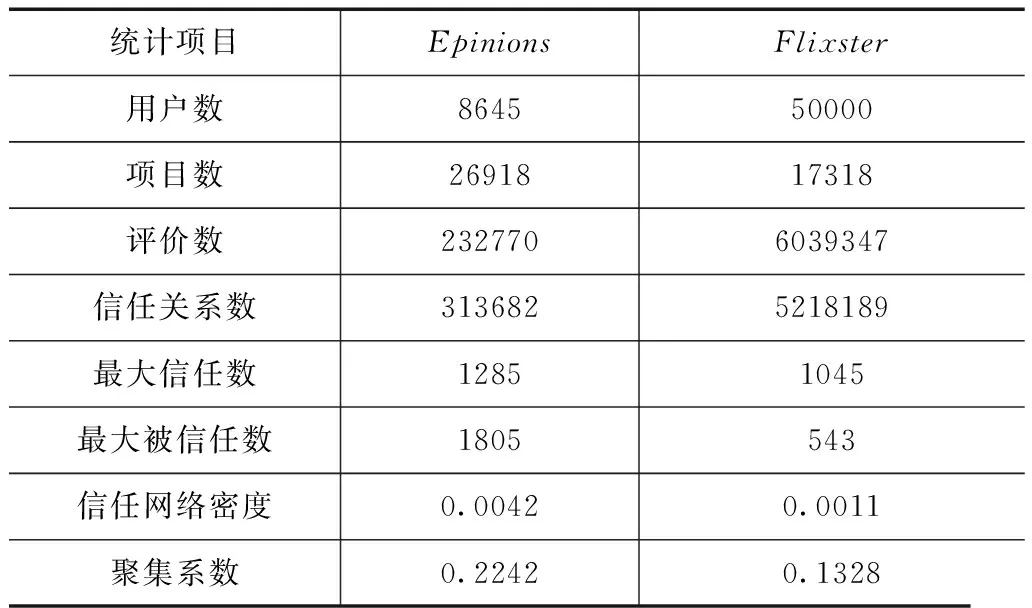
表1 数据集基本信息统计表
5.2评价指标
对于信息评价预测问题,我们使用最流行的MAE(Mean Absolute Error)指标进行评估,定义如下:
(13)
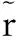
对于信任预测问题,我们使用文献[3]等广泛采用的AR(Average Recall)指标来进行评价,定义如下:
(14)
其中N是测试用户的个数,TNu代表用户u真实的信任关系列表,而TLu则代表预测算法给出的信任列表,此处我们将N设定为5.
5.3实验设定
对于信息评分和信任预测两个问题,我们各自选取三个目前流行的算法进行对比实验.其中,三个信息评分算法分别为:PMF(Probabilistic Matrix Factorization)[8]、CPMF(Constrained Probabilistic Matrix Factorization)[8]和SoRec[13].三个信任预测算法分别为:TP(Trust Propagation)[2]、MF(Matrix Factorization)[14]和hTrust[3].
对于矩阵分解类算法在进行预测时,潜在变量的维数与最终预测的准确度密切相关.我们通过使用随机抽取的数据来训练模型,并观察预测准确度与维数的关系,最终发现当潜在变量维数达到20后,各算法预测的准确度增加非常缓慢.因此,本文各矩阵分解类算法的潜在变量维数d均设定为20.另外,在没做特殊说明的情况下,本文给出的预测结果都是各算法在参数最优的情况下获得.本文中进行对比实验的所有算法均使用MATLAB语言进行实现,程序运行主机为一台安装了Centos 6.0操作系统的PC服务器,主机内存为32GB,CPU主频为2.8GHz.
5.4实验结果
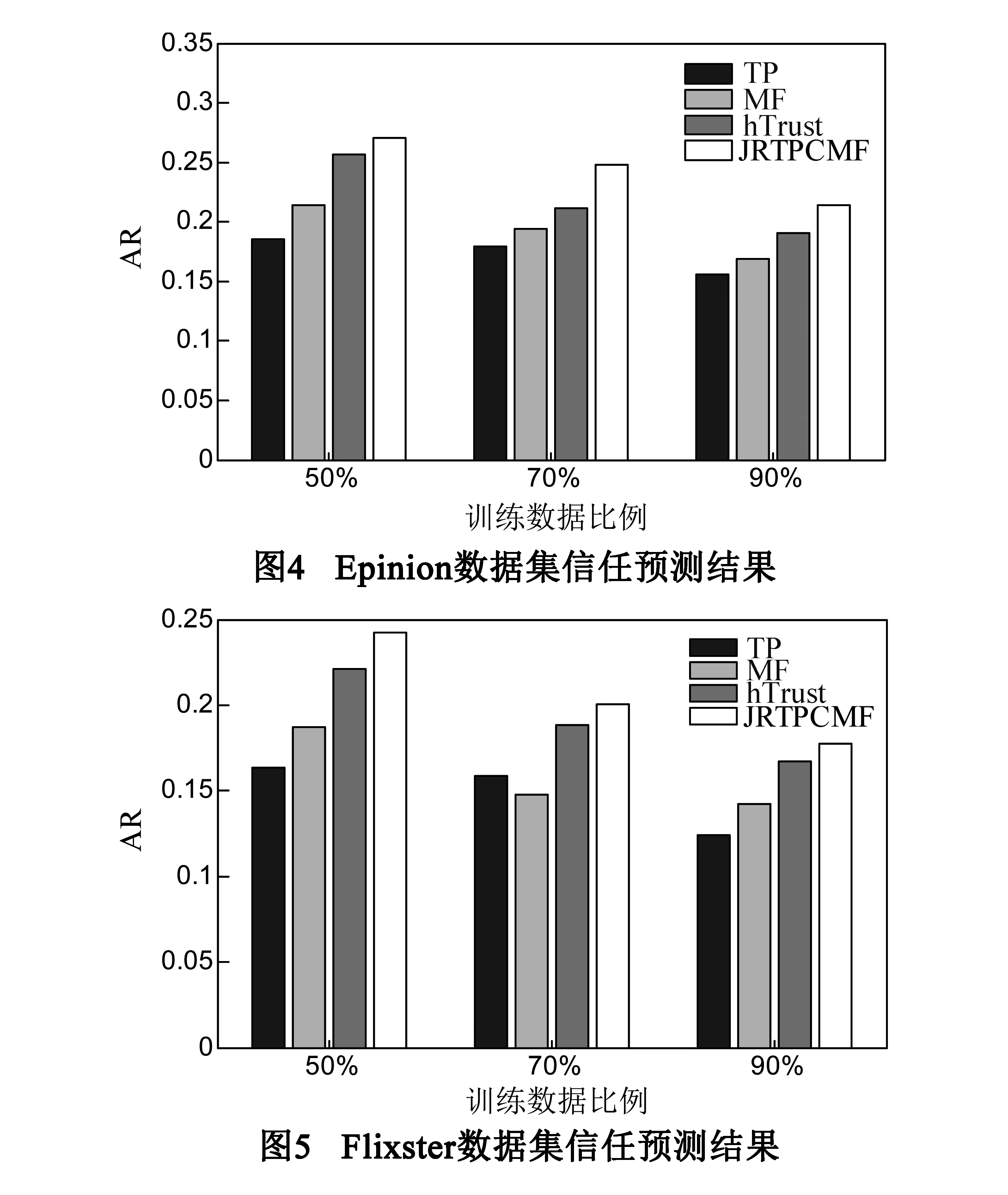
我们从训练数据评分矩阵R中随机选出M个评分,并将这M个评分作为验证数据集从而来确定αu,αv,αr以及β的参数值分别为{0.1,0.1,1,1}.然后,在训练时我们分别随机选取数据集的50%,70%和90%作为训练数据集来对模型进行训练,数据集中剩余部分作为测试集对预测算法的效果进行测试,我们采取交叉验证的方式进行实验.实验得到的预测结果分别如图2~图5所示.
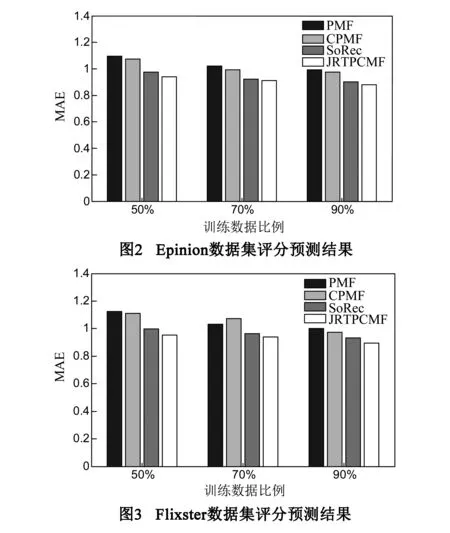
在信息评分预测结果中,可以看到PMF效果最差,其他三种算法的预测效果都要比PMF好不少.这是因为PMF在进行矩阵分解时,仅使用了评分矩阵R,而矩阵R本身又非常稀疏,所以算法在学习过程中并不能将真实的预测过程包含其中.SoRec和提出的JRTPCMF虽然在进行信息评分预测时都使用了矩阵R和T的信息,但是JRTPCMF的预测效果明显要好于SoRec,分析原因应该是JRTPCMF在矩阵分解时,既能像SoRec算法那样共享潜在用户特征信息,又能对两种领域知识引入各自相关性矩阵,从而在表达用户评价信息产生过程方面更具优势.另外,各对比算法在两个数据集上的预测效果是一致的,这说明在不同社交评价网络中,利用信任关系都可以缓解评价数据集上的数据稀疏问题.
在信任预测结果中,四种对比算法的预测准确率并没有随着训练数据比例的增加而提升,反而出现了不同程度的下降.究其原因应该与我们所使用的数据集不足够大有关.TP算法在四个算法中预测效果最差,这是因为它使用的数据仅是矩阵T,而矩阵T的稀疏性本身就是对信任预测问题的一大挑战.除TP以外其他三个算法都是基于矩阵分解的,在预测中都获得了较好的结果,这说明基于矩阵分解的方法在解决该类问题时具有较大的优势.hTrust算法虽然也借助了评分信息来帮助信任的预测,但是在两个实验数据集上其预测效果都不如提出的JRTPCMF.这是因为提出的JRTPCMF在进行矩阵分解时能够使评分信息域和信任关系信息域互相借助彼此的领域信息,而不是像hTrust算法那样只是单向借助评分信息解决信任预测问题.
6 结论
本文基于协同矩阵分解提出了一个信任与评分联合预测的模型,该模型在对评分矩阵和信任关系矩阵进行协同分解时,既能保证分解过程共享潜在用户特征,又能兼顾两个矩阵的分解能够各自表达本领域内的特征信息相关性.在两个真实网络数据集上对提出模型和最新主流算法进行了对比实验,实验结果验证了提出模型的有效性和先进性.下一步工作将重点研究面向大数据集的并行矩阵分解算法以更好地解决信任与评分预测的问题.
[1]Liben Nowell D,Kleinberg J.The link-prediction problem for social networks[J].Journal of the American Society for Information Science and Technology,2007,58(7):1019-1031.
[2]Guha R,Kumar R,Raghavan P,et al.Propagation of trust and distrust[A].Proceedings of the 13th International Conference on World Wide Web[C].New York:ACM,2004.403-412.
[3]Tang J,Gao H,Hu X,et al.Exploiting homophily effect for trust prediction[A].Proceedings of the Sixth ACM International Conference on Web Search and Data Mining[C].Rome:ACM,2013.53-62.
[4]Liu H,Lim E P,Lauw H W,et al.Predicting trusts among users of online communities:an epinions case study[A].Proceedings of the 9th ACM Conference on Electronic Commerce[C].Chicago:ACM,2008.310-319.
[5]Tang J,Gao H,Liu H.mTrust:discerning multi-faceted trust in a connected world[A].Proceedings of the Fifth ACM International Conference on Web Search and Data Mining[C].Seattle:ACM,2012.93-102.
[6]Lee D D,Seung H S.Algorithms for non-negative matrix factorization[A].Proceedings of Advances in Neural Information Processing Systems[C].2001 556-562.
[7]Luo X,Zhou M,et al.An efficient non-negative matrix-factorization-based approach to collaborative filtering for recommender systems[J].IEEE Transactions on Industrial Informatics,2014,10(2):1273-1284.
[8]Mnih A,Salakhutdinov R.Probabilistic matrix factorization[A].Proceedings of Advances in Neural Information Processing Systems 2007[C].Vancouver,1257-1264.
[9]Singh A P,Gordon G J.Relational learning via collective matrix factorization[A].Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].Las Vegas:ACM,2008.650-658.
[10]Pan W,Yang Q.Transfer learning in heterogeneous collaborative filtering domains[J].Artificial Intelligence,2013,197:39-55.
[11]Yang S H,Long B,Smola A,et al.Like like alike:joint friendship and interest propagation in social networks[A].Proceedings of the 20th International Conference on World Wide Web[A].Hyderabad:ACM,2011.537-546.
[12]印桂生,张亚楠,董宇欣,韩启龙.基于受限信任关系和概率分解矩阵的推荐[J].电子学报,2014,42(5):904-911.
YIN Gui-sheng,ZHANG Ya-nan,DONG Yu-xin,HAN Qi-long.A constrained trust recommendation using probabilistic matrix factorization[J].Acta Electronica Sinica,2014,42(5):904-911.(in Chinese)
[13]Ma H,Zhou D,Liu C,et al.Recommender systems with social regularization[A].Proceedings of the fourth ACM International Conference on Web Search and Data Mining[C].Hong Kong:ACM,2011.287-296.
[14]Zhu S,Yu K,Chi Y,et al.Combining content and link for classification using matrix factorization[A].Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval[C].Amsterdam:ACM,2007.487-494.

张维玉男,1978年6月生于山东兖州.现在北京邮电大学攻读博士学位,研究方向为社交网络分析、数据挖掘和机器学习.
E-mail:zwy@bupt.edu.cn

吴斌男,1969年11月生于湖南长沙.现为北京邮电大学博士生导师,研究方向为图数据挖掘、智能信息处理.
Joint Rating and Trust Prediction Based on Collective Matrix Factorization
ZHANG Wei-yu1,2,WU Bin1,GENG Yu-shui2,ZHU Jiang1
(1.Beijing Key Laboratory of Intelligent Telecommunications Software and Multimedia, Beijing University of Posts and Telecommunications,Beijing 100876,China; 2.School of Information,Qilu University of Technology,Jinan,Shandong 250353,China)
Trust prediction and information item rating are two fundamental tasks for social rating network systems.In response to data sparsity of trust relation and rating information encountered when improving the accuracy of predicting the two basic problems,we present a joint model of rating and trust prediction based on collective matrix factorization.In our model,trust relation matrix and information rating matrix are factorized into latent features matrixes collectively.We can make full use of correspondence among users and information items by sharing latent user feature.Moreover,our model can capture the data dependent effect of trust domains and rating domain separately.By using those learned latent features matrixes multiplication,we can obtain predictions of trust and rating.Experimental results on two real network data demonstrate that our model is more accurate than other state-of-the-art methods.
recommendation algorithms;trust prediction;probabilistic matrix factorization;social rating networks
2015-02-06;
2016-01-20;责任编辑:李勇锋
国家973重点基础研究发展计划项目(No.2013CB329606);国家自然科学基金(No.71231002,No.61375058)
TN911.23
A
0372-2112 (2016)07-1581-06
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.07.009
