论辞格负熵流的语篇建构
——以李清照的《武陵春》为例
2016-08-02王鹤
王 鹤
(河南财经政法大学 外语学院,河南 郑州 450046)
论辞格负熵流的语篇建构
——以李清照的《武陵春》为例
王鹤
(河南财经政法大学 外语学院,河南 郑州 450046)
[摘要]本文拟依据耗散结构理论,通过对组篇辞格负熵流信息的考量,验证其对语篇的建构作用。研究发现,无论结构型还是语义型组篇辞格,一个修辞变项在语篇中的出现频次越多,其负熵流信息就越大,以此导致其有序程度也相应地高,其组篇比率也相应地越高,与其相关的系统也就越有序;反之亦然。可见,负熵值是衡量语篇的信息性及其系统有序性的可靠参数,组篇辞格的负熵流创生是语篇建构的有效手段。
[关键词]组篇辞格;耗散结构;负熵流信息
修辞,即文辞或修饰文辞,是在语言使用过程中,利用多种语言手段以收到尽可能好的表达效果的一种语言活动。[1]狭义上的修辞只指文字修辞,广义上的修辞还包括文章遣词造句、谋篇布局的全过程。组篇辞格就是为了布局谋篇、提升语言艺术性所使用的修辞方法,是增强语篇表达效果的有效手段。[2]作为系统科学方法论的一种,耗散结构理论对信息科学和语言学(包括句法学和语义学)领域中的许多问题都具有普适性。本文在耗散结构理论视阈下,用信息熵函数式对组篇辞格进行量化研究,探讨其结构和语义的负熵流创生过程。
一、组篇辞格的耗散结构理论解读
“耗散结构理论”(Dissipative Structure)是以比利时科学家普利高津(I. Prigogine)为首的布鲁塞尔学派于1969年提出的。[3]该理论认为:“一个远离平衡态的开放系统,通过不断与外界交换物质和能量、信息,在外界条件达到一定的阈值时,经过涨落,系统可能发生突变即非平衡相变,由原来的混乱无序状态转变为一种在时间上、空间上或功能上的有序状态”。[4]这种在远离平衡的非线性区形成的新的稳定的有序结构,由于需要不断与外界交换物质和能量才能维持,故称为耗散结构。熵是耗散结构里用来表达无序程度的量,熵越大,系统越混乱,此所谓正熵,是负熵的对立面。依据Shannon的信息理论,[5]一个开放系统的熵变化dS可表示为:dS=diS+deS。因为系统本身产生的熵diS总是大于0,从外界吸收的熵deS可以为正,也可为负,所以,当deS<0,而|deS|>diS时,系统的总熵值dS<0。也就是说,当从外界吸收的负熵流足以抵消系统本身产生的熵时系统方能从无序走向有序。
语篇是在词、句基础上研究语言的基本单位之一,可以看做耗散结构中的开放系统;用辞格对语言进行的雕琢是优化语篇的重要手段,即用以抵消语篇系统本身冗赘(系统熵)的负熵流增加语篇的信息性。组篇辞格是为了布局谋篇及提升语言艺术性所使用的修辞手法,是“辞格修辞的扩大和深化,有助于加强文章的表达效果”。[2]从结构和语义方面探讨开放语篇系统中组篇辞格的负熵流创生过程将为明确理解组篇辞格,深入赏析经典作品,有效建构达意和优美的语篇及广泛开展语篇教学提供一个全新的视角。
二、组篇辞格负熵流创生的实证研究
如果说功能语言学中所运用的主述位信息理论是研究已知信息和新信息在语言中的分布状况的话,那么信息论中的信息熵理论就是对语言中的信息进行具体的量化计算,以其结果可以对主述位理论作出有效的验证和补充。这一操作过程涉及到语料的遴选,辞格的分析,分句的处理,信息函数的运算,以及对其运算结果的评估。
1.信息熵理论
当我们利用最大熵原理这一数学方法时,实质上是我们承认物质系统内的熵自动地应当处于约束条件所允许的最大取值状态下。[6]所谓信息,就是对事物状态、存在方式和相互联系进行描述的一组文字、符号、语言、图象或情态。信息的特征在于能消除事情的不确定。[7]负熵的科学定义应为:当一个开放系统的总熵增小于系统内部的熵增时,可以说系统产生了负熵流,或者说系统引进了负熵。在耗散结构中,负熵起了非常关键作用。[8]负熵即是系统信息性的直接参照。
“信息熵理论”(The Information Entropy Theory)是克劳德·香农(Claude Shannon)于1948年在将信息定义为某种特定信息出现概率的基础上提出的解决信息量化度量问题的方法,并进一步指出,负熵流信息即信息量H是由信息符号Pi出现的概率而导出的统计值,其计算公式为:H =-∑PilogPi,其中对数log以2为底,信息熵以比特(bit)为单位。信息熵和热力学熵是紧密相关的。在信息熵理论中,系统有序程度越高,信息熵越低;系统有序程度越低,信息熵越高。[9]也就是说,熵与信息内容的不确定性相同:信息熵系统内变量的不确定性越大,熵也越大,把它搞清楚所需要的信息也就越多,信息量也就越大。因为不可逆的信息销毁过程会导致系统熵增加,而信息产生的过程能为系统引入负(热力学)熵,所以热熵和信息熵在数量上是相同的,只是符号相反,互为负量。
组篇辞格的信息熵是语篇系统从无序到有序而引入的负熵流信息量。本实证研究将以宋代著名女词人李清照(1084-1155)的《武陵春》[10]为例,运用信息熵公式计算出其组篇辞格的负熵流信息量,进一步验证组篇辞格的负熵流创生对语篇系统有序化所产生的影响。
2.语料分析
(1)语义阐释
《武陵春》
风住尘香花已尽,日晚倦梳头。
物是人非事事休,欲语泪先流。
闻说双溪春尚好,也拟泛轻舟。
只恐双溪舴艋舟,载不动、许多愁。
《武陵春》是李清照在宋高宗绍兴五年(1135年)于浙江金华避难时所作,全词充满了“物是人非事事休”的痛苦和对故国故人的忧思,塑造了一个孤苦凄凉的才女形象。
该词以第一人称的口吻,由表及里、从外到内、步步深入、层层开掘,上阕侧重于外形,下阕偏重内心,将深沉忧郁的旋律融汇在其优美的语言和意境之中。上阕第一句“风住尘香花已尽”,以从风吹雨打、落花遍地到雨过天晴的情景变化作为作者慨叹春天、感慨自己人生变化的导火索。词人每每想起往日春景,只觉“物是人非”,于是更加悲伤,以至于“日晚倦梳头”、“欲语泪先流”。李清照写泪,先以“欲语”作为铺垫,然后让泪夺眶而出,简单五个字,看似平易,用意却无比精深,把那种难以控制的满腹忧愁一下子倾泻出来,[11]感人肺腑、动人心弦。下阕第一句“闻说双溪春尚好”,突然笔锋一转,想要到金华郊外的双溪“也拟泛轻舟”了。“春尚好”、“泛轻舟”措词轻松,节奏明快,恰到好处地表现了词人一刹那间的喜悦心情。“轻舟”一词为下文的愁绪做了很好的铺垫和烘托,引出“只恐”小小的“舴艋舟”带不走作者长期深沉的惆怅。至此,上阕所说的“日晚倦梳头”、“欲语泪先流”的原因,也得到了深刻的揭示。[12]
(2)辞格分析
李清照的作品形式上善用白描手法,自辟途径,语言清丽;其论词强调协律,崇尚典雅、情致,提出词“别是一家”之说,反对以作诗文之法作词。[13]其炼字造句之功力和文学造诣从《武陵春》这首词便可见一斑。我们把这首词的修辞结构制作成表1。
表1《武陵春》的修辞结构
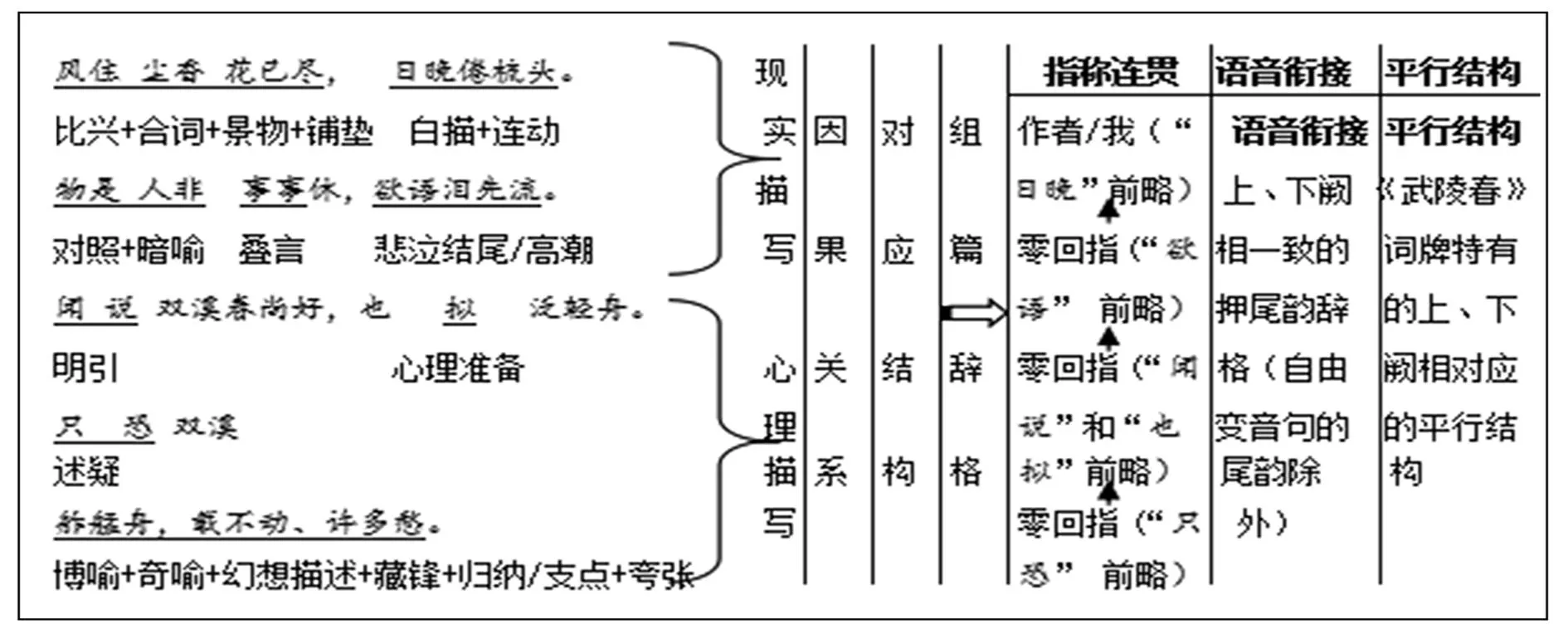
《武陵春》一词虽简炼含蓄,但却巧妙地运用了包括比兴、合词、景物、铺垫、白描、连动、对照、暗喻、叠言、悲泣结尾/高潮、明引等多种修辞手法。 这首词还充分运用了指称连贯、尾韵衔接、平行结构和一致式结构四种组篇辞格,使得它无论是在结构上、语义上还是在韵律上都毫无瑕疵地浑然一体。其中“日晚倦梳头”、“欲语泪先流”、“闻说双溪春尚好”、“也拟泛轻舟”、“只恐双溪舴艋舟”五个分句分别省略了主语“我(作者)” ,采用的是指称连贯中的“零回指”的方法以避免重复,增强词的连贯性。上阕“风住尘香花已尽“、“日晚倦梳头”、“物是人非事事休”、“欲语泪先流”,四句中的后三句采用了押尾韵的修辞格,而下阕 “闻说双溪春尚好”、“也拟泛轻舟”、“只恐双溪舴艋舟”、“载不动、许多愁”中的后三句也同样采取了押尾韵的组篇辞格,以加强韵律和语音衔接的效果。根据《武陵春》词牌特有的上、下阕相对应的结构,本词的一、二句“风住尘香花已尽”、“日晚倦梳头”,三、四句“物是人非事事休”、“欲语泪先流”和五、六句“闻说双溪春尚好”、“也拟泛轻舟”,相互之间呈平行结构,使得行文整齐流畅,朗朗上口;本词中没有涉及到修辞的文字都属于一致式结构,也即直白式结构,分别是“休”、“双溪春尚好”、“也”、“泛轻舟”、“双溪”。
3.组篇辞格的信息熵运算
(1)变量遴选
信息熵研究的是某种特定信息出现的频率,相应地,辞格信息熵即是指特定语篇中某种修辞格信息出现的频率,而我们此处所说的辞格信息熵主要指的是组篇辞格信息在其所在语篇中出现的频率。组篇辞格研究的是布局谋篇,以使行文更流畅生动的修辞方法,因此对组篇辞格不宜从词的角度研究,而是应该以分句作为基本单位。在计算组篇辞格信息前,需要对信息熵运算的相关数据进行预处理,也即进行变量遴选。变量及变量出现次数的准确性是信息熵运算的基础,辞格信息熵的计算也是如此。我们首先要明确地分析语篇中组篇辞格的形式和种类,其次是确定需要研究的组篇辞格变量,最后才是仔细研究分析每一种需要研究的组篇辞格变量出现的位置及次数。
按照以上变量遴选方法,《武陵春》全篇八个分句共出现指称连贯、尾韵衔接、平行结构和一致式结构四种组篇辞格,也就是四个变量。其中指称连贯属于语义型组篇辞格,而尾韵衔接和平行结构属于结构型组篇辞格。指称连贯(变量1)分别在“日晚倦梳头”、“欲语泪先流”、“闻说双溪春尚好”、“也拟泛轻舟”、“只恐双溪舴艋舟”五个分句中各出现1次,即共5次;尾韵衔接(变量2)分别在上阕 “日晚倦梳头”、“物是人非事事休”、“欲语泪先流”和下阕 “也拟泛轻舟”、“只恐双溪舴艋舟”、“载不动、许多愁”各出现3次,即共6次;平行结构(变量3)在一、二句“风住尘香花已尽”、“日晚倦梳头”,三、四句“物是人非事事休”、“欲语泪先流”和五、六句“闻说双溪春尚好”、“也拟泛轻舟”分别出现2次,即共6次;一致式结构(变量4)一共12个字,分别是第三句中的“休”,第五句中的“双溪春尚好”,第六句中的“也”和“泛轻舟”,以及第七句中的“双溪”。
(2)运算过程
信息熵的运算过程,指的是将特定信息出现的频率代入到上述信息熵计算公式里,从而计算出以比特为单位的熵值的过程。同样地,辞格信息熵的运算过程,主要指的是将组篇辞格变量出现的概率代入到公式H =-∑PilogPi中,从而得出组篇辞格负熵流信息量的过程。
按照变量遴选方法,在信息熵函数式的基础上,对《武陵春》中四个组篇辞格(指称连贯、尾韵衔接、平行结构和一致式结构)变量进行分句处理和运算,具体计算方法如下:
① 指称连贯的负熵流信息。由表1可知,指称连贯作为语义型组篇辞格,在该语篇中多以对作者零回指的形式出现,占全部8个小句中的5个。这样,在分句时,全篇8个小句,设每个变量出现的概率为:Pi=1/8,它们以主语形式出现的频次是5,则指称辞格的信息量计算如下:

② 尾韵衔接的负熵流信息。在全篇8个小句中,设每个变量出现的概率为:Pi=1/8,以相同尾韵连接的频次是6,则尾韵辞格的信息量计算如下:
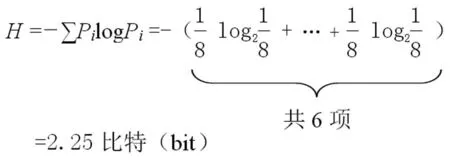
③ 平行结构的负熵流信息。在全篇8个小句中,设每个变量出现的概率为:Pi=1/8,以平行结构搭配的频次是6,则平行结构的信息量碰巧也是:
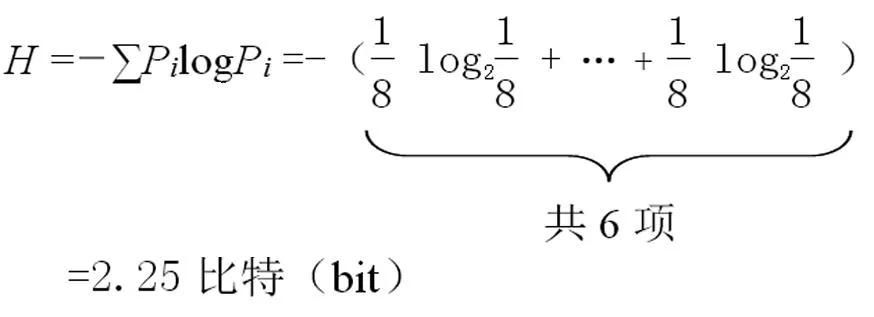
④ 一致式结构的负熵流信息。实际上因直白式词汇在该语篇中的数量较少,加之其又不起关键语篇连接作用,因此它们对组篇信息的贡献极小,但为了公允起见,也为了以此作为一个参照系,在此有必要将其看做一个组篇变项。在将其数值代入信息熵函数式运算时,关键在于运算前的信息预处理程序上。因它们太分散而不能独立成句,这就需要先让其取一个均值,即以全篇49字除以8个小句,平均每个小句6.125字,再以直白式词汇总数除之,即得到:12÷6.125≈2个小句。设每个变量出现的概率为:Pi=1/8,以一致式结构出现的频次是2,则一致式结构的信息量计算如下:

(3)结果分析
按照信息熵理论,系统有序程度越高,信息熵越低;系统有序程度越低,信息熵越高。本实证研究部分通过计算组篇辞格《武陵春》结构信息熵和语义信息熵的负熵流信息量,进一步分析和比较各种组篇辞格的信息熵值。下面将指称连贯、尾韵衔接、平行结构和一致式结构这四个变项的组篇数据制作成表2,以便对其做出清晰的比较。
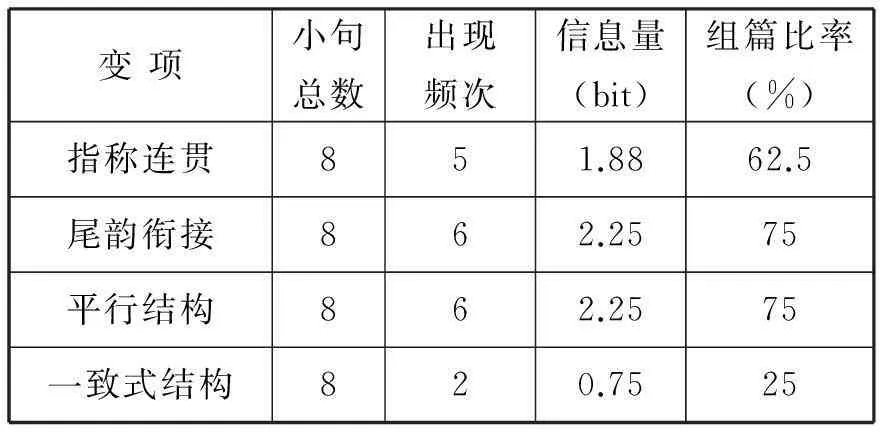
表2 《武陵春》修辞结构的组篇变项数据
由表2可以看出,负熵流信息量最低的是一致式结构,只有0.75比特。《武陵春》中的一致式结构数量很少,只有 “休”、“双溪春尚好”、“也”、“泛轻舟”、“双溪”12个字,而且也没有起到连接语篇的关键作用,所以信息量的值最小。也就是说一致式结构对这首词的结构和语义表达都没有起到至关重要的作用,因此,组篇辞格比率仅为25%,也是这首词中四种组篇辞格里最低的一个。
指称连贯的负熵流信息量为1.88比特,组篇比率为62.5%。指称连贯是组篇辞格中用于语义衔接的辞格,1.88比特的语义负熵流信息量远高于一致式结构,相比之下,说明本词中“日晚倦梳头”、“欲语泪先流”、“闻说双溪春尚好”、“也拟泛轻舟”、“只恐双溪舴艋舟”通过省略主语“我(作者)”,运用零回指的方法使整个语篇有效地衔接在一起,加强了语篇一气呵成的连贯性。因此在语篇中实时使用一些指称连贯的修辞手法,既能避免不必要的重复和赘述,又能让语篇衔接得更紧密,语义更完整。
尾韵衔接和平行结构都属于组篇辞格中用于结构形式建构的辞格,在本词中,二者的负熵流信息量恰好相同,都高达2.25,组篇比率也因这两种组篇辞格出现的频次均为6次而高达75%。
尾韵衔接出现在上阕“风住尘香花已尽”、“日晚倦梳头”、“物是人非事事休”、“欲语泪先流”和下阕 “闻说双溪春尚好”、“也拟泛轻舟”、“只恐双溪舴艋舟”、“载不动、许多愁”中。尾韵衔接的负熵流信息量达到最高的2.25比特,说明《武陵春》通过押尾韵的方式,不仅使词本身读起来朗朗上口,也使语篇的结构形式被很好地建构起来,所以整篇词结构更严谨,形式更规范。由此我们可以看出,在语篇中恰当使用尾韵衔接的组篇辞格手法,能使语篇结构更紧凑,行文更流畅。
平行结构体现在《武陵春》词牌特有的上、下阕相对应的结构中,分别是:一、二句“风住尘香花已尽”、“日晚倦梳头”,三、四句“物是人非事事休”、“欲语泪先流”和五、六句“闻说双溪春尚好”、“也拟泛轻舟”。也是因为出现了6次,平行结构的负熵流信息量和组篇比率分别高达2.25比特和75%。如此之高的负熵流信息量说明平行结构除了让语篇看起来整齐,也能很好地建构语篇。由此可见,在语篇中适当地使用平行结构,不仅能使语篇结构紧凑整齐,还能使文章衔接流畅,气势磅礴。
综观表2的数据统计,我们可发现,无论结构型还是语义型组篇辞格,一个修辞变项在语篇中的出现频次越多,其负熵流信息就越大,以此导致其有序程度也相应地高,其组篇比率也相应地越高,与其相关的系统也就越有序。相反,低比值的修辞变项和一致式结构的数据显示,一个结构在语篇中的出现频次越少,其负熵流信息就越小,组篇比率相应地也就越低,而其正熵值就越大。以此导致其无序程度也相应地高,与其相关的系统也就越混乱。可见,负熵值是衡量语篇的信息性及其系统有序性的可靠参数。
[参考文献]
[1]张瑜.翻译的修辞学研究[D].南京:南京师范大学外国语学院,2013.
[2]应守岩. 论辞格组篇[J]. 杭州教育学院学报,1994,(1).
[3]姜璐.熵——系统科学基本概念[M].沈阳:沈阳出版社,1997.
[4]曾庆宏,沈小峰译.从混沌到有序:人与自然的新对话[M].(比)伊·普里戈金,(法)伊·斯唐热著.上海:上海译文出版社, 2004.
[5]Shannon C.E.1948. A Mathematical Theory of Communication[J]. BSTT 27:379-423.
[6]王彬.熵与信息[M].西安:西北工业大学出版社,1994.
[7]陈宜生,刘书声.谈谈熵[M].长沙:湖南教育出版社,1993.
[8]景玉红.人体系统与科研系统的耗散结构特征[J].山西高等学校社会科学学报,2004,(2).
[9]王身立.耗散结构理论向何处去——广义进化与负熵[M].北京:人民出版社,1989.
[10]琮琼.婉约词译注[M].太原:山西古籍出版社,1999.
[11]黄晓娟. 论李清照词的语言艺术特色[J].齐齐哈尔师范高等专科学校学报,2006,(1).
[12]石杨. 浅谈李清照词的语言特色[J].遵义师范高等专科学校学报,1999,(2).
[13]王令.试论李清照词的意境创造[J].中州学刊,2008,(4).
[责任编辑:康邦显]
[收稿日期]2016-02-22
[基金项目]本文系国家社科基金项目《中外主权冲突情势下基于修辞策略的国家舆论研究》(14BXW049),教育部人文社会科学研究项目《RST中耗散结构的阈限:辞格的负熵流创生及其语篇建模》(11YJA740096)的阶段性成果。
[作者简介]王鹤(1980-),女,河南郑州人,讲师,研究方向为功能语言学及应用语言学。
[中图分类号]H15
[文献标识码]A
[文章编号]1671-5330(2016)03-0102-05
