基于语料库的莫言小说英译语言特征考察
2016-07-20黄永新张黎黎
黄永新,张黎黎
(石家庄铁路职业技术学院,河北石家庄 050041)
基于语料库的莫言小说英译语言特征考察
黄永新,张黎黎
(石家庄铁路职业技术学院,河北石家庄050041)
摘要:本研究采用自制“莫言小说平行语料库”,利用语料库技术统计和整理了各部小说的基础语料库数据、词汇密度以及词长分布等数据,发现长篇小说能够较好地体现语言特征的稳定性,亦即翻译质量的稳定性,而短篇小说的语言特征则呈现出多样性。这些研究数据和结论可以作为时代背景下中国文学翻译参照的标准。
关键词:语料库;语言特征;莫言;文学翻译
一、引言
2011年10月,中共中央审议通过了推动中华文化大发展大繁荣的决定,制定了中华文化走出国门,不断增强中华文化国际影响力的战略目标。作为中华优秀文化对外传播的主力军,文学翻译工作日益引起中国政府的重视、文学界及翻译界的关注。但是中国文学输出与西方文学输入存在巨大的逆差,在西方国家的出版物中,原文是中文的翻译作品所占份额很少,法国有10%,美国仅3%;而中国从西方国家引进并翻译成中文的作品达到了我国出版总量的一半以上[1]。所以整体上我国文学走出去仍然任重而道远,需要中国政府及学界坦然面对,冷静分析并总结现有经验,从而更好地指导当今时代背景下我国总体层面上的文学翻译工作。
莫言获得2012年“诺贝尔文学奖”的消息在中国乃至世界掀起了一股“莫言热”,这一事件引起了全世界范围内对中国文学的关注,一定程度对于推动文学事业的对外发展具有积极意义。作为中国唯一一位诺贝尔文学奖得主,莫言的作品在国际社会取得了非常好的口碑,一定程度上可以说其英译作品是比较“成功”的译本。本研究选取莫言的小说英译本为研究对象,通过分析这些译本自身详细的语言学特点,可以总结出当今时代背景下中国文学译本需要满足的条件及具备的特点。
二、语料库构建
研究所采用的语料库为自制的“莫言小说平行语料库”,初步计划库容约100万字(以源文本汉语字数为准)。收录的语料为所有莫言小说的英语译本,文本为全文收录,包括长篇小说和中短篇小说。所有语料经扫描仪扫描、OCR字体识别、文本清洁、语句对齐等一系列步骤,最终满足平行语料库检索软件CUC_ParaConc对语料的检索格式要求。研究选用的语料库工具包括BFSU PowerConc、AntConc、Cuc_ParaConc、Readability Analyzer及NLPIR汉语分词软件等。在借鉴前人经验的基础上,本研究将从标准化类符/形符比、平均词长、平均句长、语篇可读性、词长分布、词汇密度等方面探讨莫言小说英译本的语言特征。
三、研究方法
语料库翻译研究现阶段一个明显的趋势即打破之前单语类比或单语加双语平行的研究模式,变为根据研究需要而建立的多重复合对比模式,语料库可分可合[2]。本研究选取莫言的8部短篇小说和5部长篇小说的英语译本。巧合的是这些莫言小说全部是由被称作“中国现当代文学首席翻译家”葛浩文先生翻译的,这样有助于莫言规律性的一些语言特征在译文中得以较为统一的重现,亦即有助于保证翻译质量的一致性。本研究将采用多视角的切入点,从各个角度提取语料数据,从宏观视角而非特定的某部作品来描述莫言小说英译本具备的语言特征,以总结出满足时代需要的中国文学译文的语言条件和特点。
四、研究结果分析
1.基础语料库数据
借助语料库工具AntConc及Readability Analyzer可分别获取莫言各部小说的词、句等基础语言数据(表1)。
类符/形符比(type/token ratio,TTR)指文本中所使用的不同词汇与总词汇数量的比率,通常用来衡量某个文本中使用词汇的多样性[3]。但是文本越长,形符数越多,类符数则不一定增多,这样的话类符/形符比就会越来越小。因此,通常以标准化类符/形符比为准(STTR),计算出文本中每1000词的TTR,然后取平均值[4]。统计结果显示,短篇小说的STTR变化幅度较大(图1),最大0.3695,最小0.2242;而长篇小说的STTR则变化幅度较小(图2),均为0.12左右。
就平均词长来说,短篇小说亦呈现出较大的变化性,最大为4.3,最小3.9;而长篇小说有三部平均词长均为4.3,另两部为4.1和4.3,变化幅度很小。而且,相对而言短篇小说整体上不如长篇小说的平均词长数值大,说明长篇小说使用的长词数量较多。表1显示,短篇小说的平均句长基本与长篇小说相同,说明这些翻译作品在句子层面的变化幅度基本相等。但长、短篇小说分开来看,依然是短篇小说的平均句长变化幅度高于长篇小说。
语篇可读性是衡量文章难易程度的一个指标,能在宏观层面发现翻译文本是否存在简化特征。Flesch Reading Ease(弗莱士易读度)是反映文本可读性指标的一种常用统计方法,其计算依据是句子的词数和句子中含的音节数等,数值介于0到100之间,数目越大,文章越容易读。大多数英语原创文本的易读度数值约为60-70,数值为70-79均属于相当容易(fairly easy)的范围。本研究采用语篇可读性分析软件Readability 1.0统计得出每一部莫言小说的易读度数据。表1显示全部作品的易读度数据为80.0左右,说明难度要远远低于英语原创文本,印证了翻译文本的简化特征。具体来说,短篇小说的易读度介于74.3-88.2,变化幅度大;而长篇小说的该数据为76.0-80.2,变化程度较为平缓。
总体而言,短篇小说的各项基础语料库数据变化幅度较大,而长篇小说相应数据的变化则趋于平缓,变化较小。说明长篇小说能够较好地体现语言特征的稳定性,更应该针对长篇小说来提炼总结其翻译经验。下文我们将通过其他数据形式来进一步验证该结论。
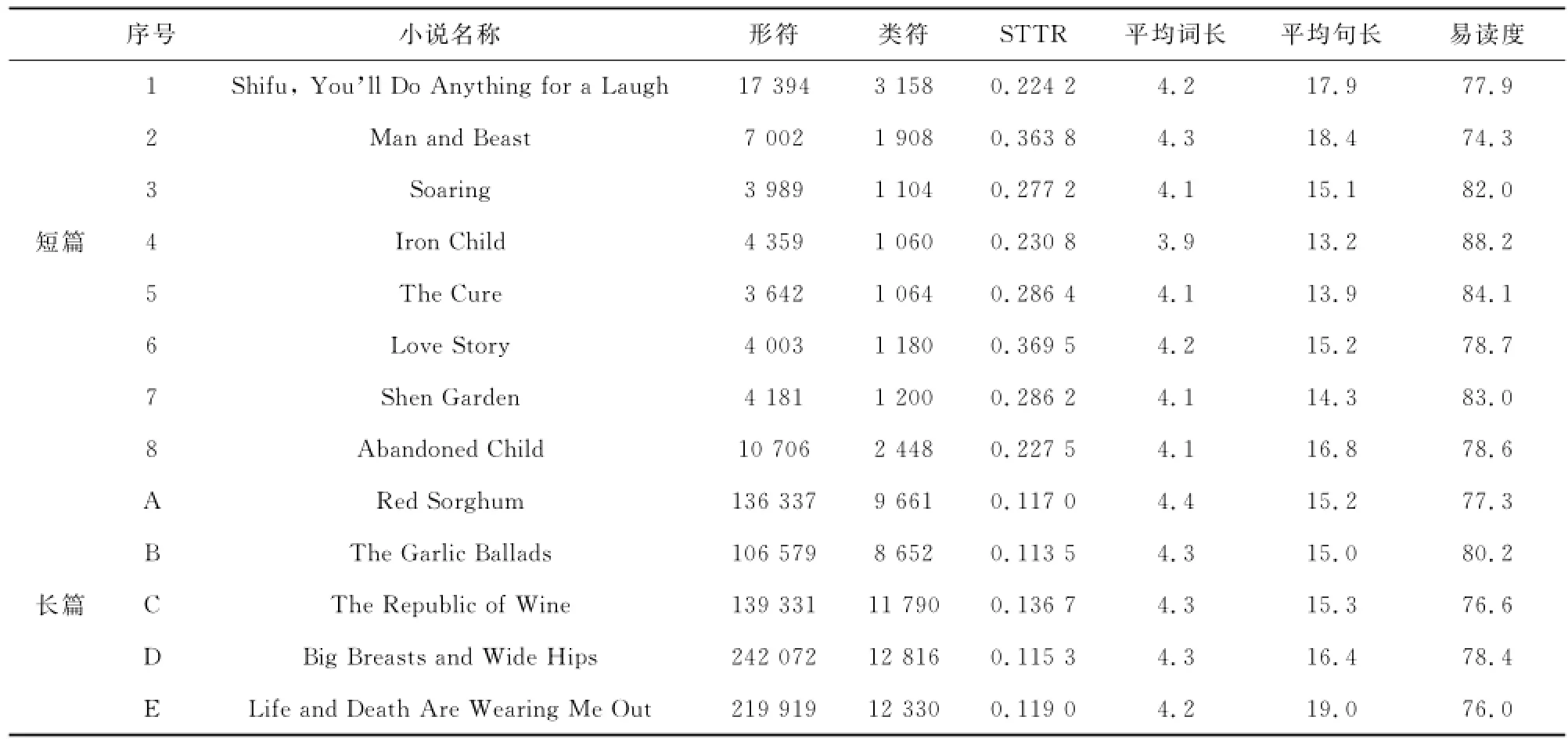
表1 莫言小说语料库词、句等基础语言数据表

图1 短篇小说STTR变化曲线
2.词汇密度及实词比例
词汇密度(Lexical Density)指实词与总词数比值的百分比,可以衡量语篇的信息负载量[5]。实词包括名词、实义动词、形容词和副词。Laviosa曾证实英语译语的词汇密度为52.87%,英语源语的词汇密度为54.95%,并得出结论:译语具有词汇密度较低的特点[6]。经词性标注及分类统计后,我们得出莫言小说英译本的词汇密度介于57.2%与62.4%之间(表2)。说明这些译本的词汇密度都高于Laviosa统计出的译语词汇密度值,表明这些莫言小说英译本不具备明显的翻译文本语言特征,词汇丰富度高于原创英语源语,整体上这些莫言小说英译本的信息负载量较大。相比较而言,短篇小说的词汇密度变化幅度大(图3),长篇小说的词汇密度则趋于稳定(图4)。

图2 长篇小说标STTR变化曲线
至于从每部作品中各项实词的比例来看,名词比例最高,达到25%左右;动词比例次之,略低于20%;形容词和副词所占比例约为7%。相对而言,依然是长篇小说的四项实词比例的变化幅度小于短篇小说。
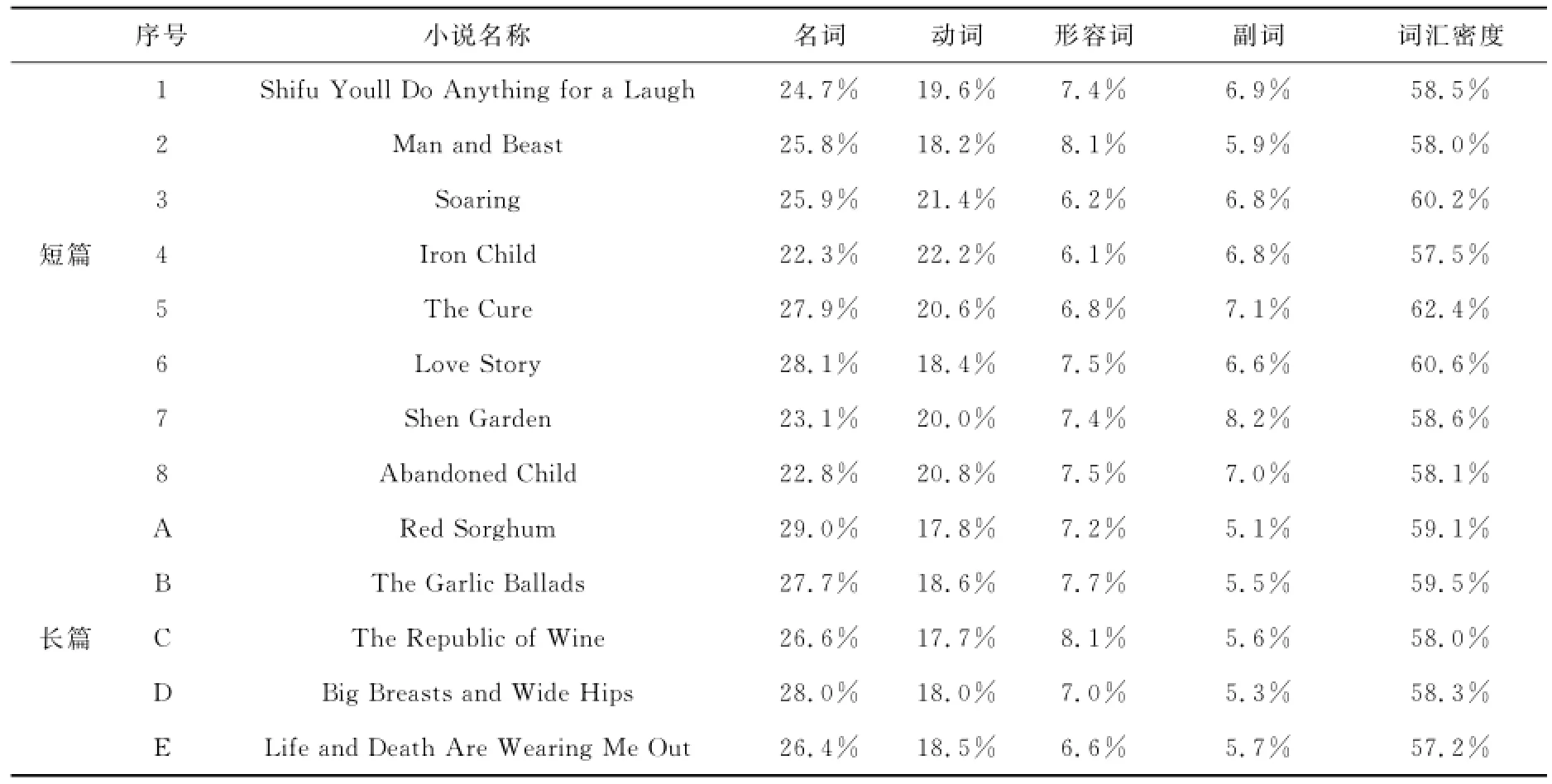
表2 莫言小说语料库实词比例统计表
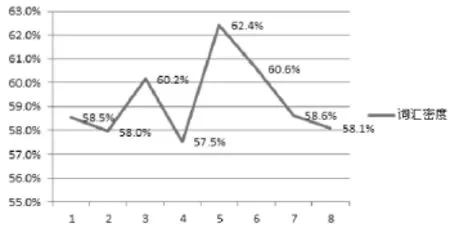
图3 短篇小说词汇密度变化曲线
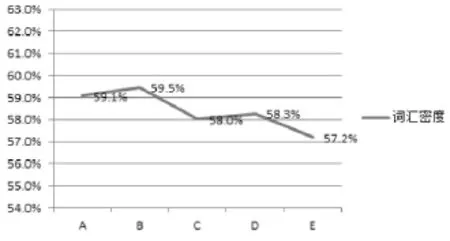
图4 长篇小说词汇密度变化曲线
3.词长统计
就平均词长来看,短篇小说的平均值为4.1,长篇小说的平均值为4.3,说明短篇小说词汇较简单,阅读难度相对容易。进一步观察发现(表3),长、短篇小说都是3个字母的单词所占比例最大,短篇小说平均占22.1%,长篇小说平均占22.2%,二者基本相同。其他长度的单词所占比例由高到低依次为4个字母(16.0%-18.9%),2个字母(13.7%-16.9%),5个字母(12.4%-15.4%),6个字母(9.0%-10.9%)。整体来看各种长度的单词分布情况,长、短篇小说基本呈现出相同的趋势(图5,图6)。另外,2-6个字母的单词总量分别占短篇小说的78.6%和长篇小说的76.9%,二者相近且总值接近80%,说明这些小说主要采用2-6个字母的单词,单词较短,阅读难度较低。

表3 莫言小说语料库词长分布统计表

图5 短篇小说词长分布图

图6 长篇小说词长分布图
五、结语
从基本语料库统计数据来看,如标准化类符/形符比、平均词长、平均句长、易读度等,莫言小说中的短篇小说相应的数据变化幅度较大,而长篇小说的相应数据则变化平缓,说明长篇小说能够较好地体现语言特征的稳定性,亦即翻译质量的稳定性。而且,实词比例以及词长分布亦能很好支持上述观点。当然,并非短篇小说的翻译质量不均衡,其统计数据的不稳定性可能由于源文语言特征的多变性而导致译文的语言特征多样性。但无论如何,毕竟长篇小说的各项语言数据较为稳定,可以作为我们的重点研究对象,通过长篇小说总结出的语言数据可以作为时代背景下中国文学翻译参考的标准。具体来说,这些数据标准化类符/形符比为0.1203、平均词长为4.3、平均句长为16.2、易读度为77.7、词汇密度为58.4%(其中名词27.5%,动词18.1%,形容词7.3%,副词5.4%),词长分布中3个字母的比例最高,为22.2%,2-6字母的单词所占比例接近80%。
尽管本研究取得了上述一些发现,但上述研究结果仍旧需要在更大规模的语料库中进行验证,如这些语言特征是否在译者葛浩文先生的其他译著中同样能够得以体现。如果能够体现,则说明这个标准可以推行;如果不能体现,就需要进一步研究导致这些差异的原因。另外,即使这个标准成立,在具体推行时仍需要进一步细化,以进一步提升这个标准的可实施性。
参考文献:
[1]许方,许钧.翻译与创作——许钧教授谈莫言获奖及其作品的翻译[J].小说译介与传播研究,2013(2):4-10.
[2]黄立波,王克非.语料库翻译学:课题与进展[J].外语教学与研究,2011(6):911-923.
[3]黄立波.基于语料库的翻译文体研究[M].上海:上海交通大学出版社,2014:52.
[4]梁茂成,李文中,许家金.语料库应用教程[M].北京:外语教学与研究出版社,2010:9.
[5]Libo Huang.Style in Translation:A Corpus-based Perspective[M].Shanghai and Berlin:Shanghai Jiao Tong University Press and Springer-Verlag Berlin Heidelberg,2015:84.
[6]Laviosa,Sara.Core patterns of lexical use in a comparable corpus of English narrative prose[J].Meta,1998(4):557-570.
On Corpus-based Language Features of Mo Yan’s Novels
HUANG Yongxin,ZHANG Lili
(Shijiazhuang Institute of Railway Technology,Shijiazhuang, 050041,China)
Abstract:Based on the self-built Parallel Corpus of Mo Yan’s Novels,this study statistically calculates and sorts the diverse basic corpus data,lexical density and distribution of word length of every novel by using corpus technologies.The results show that long novels are capable of symbolizing stability of various language features,that is,the stability of translation quality;while short novels present language diversity.These research data and conclusions can be taken as referential standards in the background of Chinese literary translation nowadays.
Key words:corpus;language feature;Mo Yan;literature translation
中图分类号:H059
文献标识码:
文章编号:1008-469X(2016)02-0054-05
收稿日期:2016-02-14
基金项目:2014年度河北省社会科学基金项目《基于语料库的莫言小说英译语言特征研究》(HB14YY008)
作者简介:黄永新(1978-),男,河北鹿泉人,教育学硕士,副教授,主要从事语料库翻译、外语教学研究。
