基于大数据的网络供应商信用评估模型
2016-07-09付永贵朱建明
付永贵 朱建明
一、引言
进入21世纪以来,电子商务在全世界得到了迅猛发展,然而因交易的电子化、跨时空、全天候、平台虚拟性等特点,电子商务供应商信用评估较之传统商务产生了更高的难度,虽然目前很多电子商务交易系统设置了顾客对供应商交易信用的评估平台,但在实际运行中由于顾客的侧重点各异,单笔交易的个性化特点太强,导致单个顾客对某一供应商的信用评估结果无法取信,电子商务供应商信用评估效率不高的问题依然没有得到解决。因此,如何获取交易主体身份、行为、交易特点等多方面信息,并据此有效地进行信用评估是进一步提高电子商务效率的一个关键。
在实际工作中,中国目前对企业信用进行评估主要遵照《GB/T 22116—2008企业信用等级表示方法》的规定,即按照企业的履约能力、风险程度、经营状态、不确定因素对经营与发展的影响水平等因素评估企业的信用度水平,按照企业信用度由高到低分成AAA、AA、A、BBB、BB、B、CCC、CC、C、NR共十类,其中AAA、AA、A、BBB四类为信用度合格供应商的评价标准。比较有代表性的企业信用评估发布网站如企业信用网(http://www.bgcheck.cn),有很多电子商务企业在此网站注册并公布了自己的信用等级。
经过对电子商务交易主体及其交易模式的特性进行分析可以发现,网络供应商通常不是商品的生产者,更多的情况是一个交易网站及众多在此网站注册并进行网络销售的供应商集合。客户进行信用评价时更加注重网站的规模、发展时间、提供信息的完整度、商品质量、供应商声誉、商品种类、资产状况、负债状况、供货周期、商品价格、物流配送方式、配送周期、售后服务内容、售后服务时间、供应商发展前景等,因此,目前《GB/T 22116—2008企业信用等级表示方法》对网站及供应商进行的信用评估结果不能形成对顾客购物决策的有效指导,网络供应商信用评估需要顺应电子商务交易的特性及顾客的根本需求,通过构建更有针对性的评估指标体系对信用度进行总体评估。
从学术研究及应用的角度进行分析,早期各研究应用领域主流的信用评估模型以线性模型为主,近几年则以在神经网络模型基础上构建信用评估模型居多。
目前电子商务领域信用评估的研究成果已经很多,比如彭丽芳等(2007)[1]提出通过交易完成后交易双方对对方信用反馈的多次积累作为评判交易者信用的依据。殷红(2013)[2]提出借助信用评价制度、支付机制、担保机制、争议解决机制等提高网络交易交易方的信用。廖华和张旭辉等(2014)[3]提出在C2C信用评价模型中增加售前、售中、售后的隐性信用因素构建模型。王俊峰和吴海峰(2014)[4]提出网络交易时综合B2C企业运营能力、偿债能力、发展能力、网络经营能力等多方面因素给出企业信用度的评价结果。贾艳涛和虞慧群(2010)等[5]综合考虑交易金额、交易双方信誉度、交易次数、差评次数、未评价交易等因素,采用动态计算的方式构建C2C的可信信用评价模型。陈鑫铭和冯艳(2009)[6]设计了一套基于基本信用、职业信用、交易信用的信用评估体系及基于AHP方法的C2C电子商务信用评估模型。郭亦涵和郑植(2011)[7]提出在评价商家信用时以产品质量、信息质量、配送质量、服务质量指标作为基础,使用模糊综合评价法给出指标权重,同时在指标体系构建中要综合考虑评价者信用、交易金额、交易时间等因素。李瑞轩等(2009)[8]按照商品价格区间分布来对成功交易加分,按照信用等级的扣分系数来对失败交易扣分,以解决信用欺诈;设计了风险计算方法,根据历史交易情况及当前交易价格评估当前交易风险。
综合现有电子商务领域信用评估的研究成果可以发现,目前的研究中所构建的指标体系及模型以交易主体传统既定的信用评估指标体系及模型为主,数据源则以既定交易系统等固定数据源为主,由于指标体系比较简单,数据的来源受限使得模型的评估结果不够精确,不能很好地实现对电子商务交易主体信用的评估,而信用问题恰恰是电子商务交易主体交易过程中最为关注的问题。因此电子商务交易主体信用评估效率问题成为决定目前电子商务交易频率及效率的关键因素,成为制约电子商务发展的瓶颈。
随着互联网的发展,互联网所产生的数据量快速增长,云时代的来临,使得大数据越来越成为人们关注的热点,不可否认,大数据正冲击和影响着人们的生活。有关大数据的概念,大数据研究机构Gartner的定义是“大数据是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产”。图1为历年来互联网数据总量统计结果(单位:ZB)。

图1 互联网数据总量统计及预测
数据来源:IDC统计及预测数据。
大数据时代的来临,给电子商务交易信用管理带来了重大契机,目前基于大数据的电子商务交易信用问题已经得到了学术界的关注,一些专家学者也进行了相应的理论研究。比如:章向东和钟为亚(2014)[9]提出大数据时代我国信用评级业应该进行评级体系重构,并使用演化博弈模型就互联网平台与信用评级机构之间是否进行大数据信息提供合作进行了收益分析。李海强(2014)[10]针对供应链企业信用贷款的不足,指出了大数据环境下供应链企业信用贷款风险评价的特点,并通过实例进行了分析。Jenkins和Patrick(2014)[11]提出ZestFinance使用大数据实现金融业的信用评估。Wisniewski(2013)[12]提出使用人的行为大数据实现征信。方湖柳和李圣君(2014)[13]提出使用大数据信息实现食品安全的事前、事中、事后智能化监管。从实际应用中来看,使用大数据进行信用评估比较成功的当属美国的FICO公司与ZestFinance公司,其信用评估主要面向互联网金融,其中ZestFinance公司使用大数据对互联网金融进行信用评估更为成功;另外,国内的阿里小贷也建立了基于大数据的征信系统。
对国内外基于大数据的电子商务交易信用管理理论与实践进行分析,目前基于大数据的电子商务交易信用管理的研究尚处于初级阶段,理论研究尚处于大数据对电子商务交易信用管理的价值分析阶段,研究方法很少,应用方面案例的内容也属于尝试、探讨性的,没有形成对现实理论研究及实践应用的指导性成果。
与其他电子商务类型相比,B2C电子商务涉及面广,交易频度高,顾客随机性大,因此B2C电子商务网络供应商的信用评估更具必要性和普遍性。基于以上分析,本文以B2C电子商务为例,将电子商务交易放到大数据环境中,分析了网络供应商信用大数据的来源及数据处理流程,分析了基于大数据的网络供应商信用博弈行为,使用逐步回归法提出构建基于大数据的网络供应商信用评估指标体系的具体方法,并使用部分调整模型及带权重的径向基神经网络模型构建了基于大数据的B2C网络供应商信用评估模型,最后通过实证分析说明了模型的构建过程并验证了模型的效率。
二、网络供应商信用大数据来源分析及处理
大数据环境下,与网络供应商信用管理相关的数据资料来源不断增加,其数据来源既包括网络供应商提供的数据资料、第三方信息系统(行业相关信息系统及与供应商本身有关的信息系统)提供的数据资料、从互联网中抓取获得到的数据资料,这些数据资料既有与电子商务交易直接有关的数据,也有与电子商务交易无关但可以支持网络供应商信用评估的数据资料,数据资料来源不固定,即使数据分析人员事先也不能完全确定数据的具体来源。这些数据源提供的数据资料数据量巨大、内容丰富、格式多样化。对于网络供应商提供的数据资料要使用具体的监管措施确保所提供数据资料的真实性;对于第三方信息系统提供的数据资料要与第三方建立联系,取得第三方的同意;对于从网上抓取的数据资料要建立有效的爬行算法,确保所抓取到数据的正确性和时效性。这些数据金矿可以为电子商务供应商信用评估提供更加全面、完整、准确的数据。
大数据给电子商务交易信用评估提供了新的机遇,但如何处理大数据也给人们提出了新的挑战。通过大数据构建电子商务交易信用评估指标体系时要对指标体系内各项指标之间的相关性及重要程度进行分析,对于重要但没有引入的指标变量要引入指标体系,对于与其他指标变量相关性程度很高而对信用评估结果影响不大的指标变量则要剔除;既要考虑指标对应数据的清洗,去除错误、不必要和冗余的数据,又要考虑数据格式的变换,确保数据格式的一致性并且是信用评估模型易于处理的数据格式。其处理流程如图2所示。

图2 网络供应商信用大数据处理流程
三、基于大数据的网络供应商信用博弈行为分析
对于网络供应商来说,顾客对其信用评估的结果既包括当期信用评估结果,又包括顾客对供应商的前期信用评估结果,顾客对供应商的前期信用评估结果会很大程度上影响顾客对供应商当期信用评估的总体结果。因此,网络供应商信用评估的总体结果是由顾客对供应商当期信用评估结果及对供应商所有前期信用评估结果综合形成的。
网络供应商作为一个理性经济人,其提供信息的真实度会因顾客对其信用水平的获取能力而产生博弈,为了有效地对供应商信用博弈(这里的信用博弈指供应商对提供信息真实度的选择)行为进行分析,做以下假设:
H1:为了研究方便,设供应商当期(第t期)总体信用评估结果只受前一期(第t-1期)信用评估结果的影响;设当期总体信用评估结果为F(t),上一期总体信用评估结果为F(t-1);设供应商的总体信用评估结果即是供应商的效用值,即对于供应商来说,U(t)=F(t)。
H2:设通过大数据分析技术捕获供应商提供虚假信息欺瞒顾客的概率为γ。
H3:设供应商当期提供真实信息概率为πt,则提供虚假信息欺瞒顾客的概率为1-πt;供应商上一期因提供虚假信息被捕获对当期供应商信用评估结果的影响为-k(1-πt-1,γ),-k(1-πt-1,γ)随1-πt-1取值增大而减小,随γ取值增大而减小(这里k为函数,其取值是期望值);-k(1-πt-1,γ)≤0且当γ=0时,-k(1-πt-1,γ)=0,当1-πt-1=0时,-k(1-πt-1,γ)=0;即供应商由于上一期提供虚假信息被捕获将会造成当期信用评估结果的下降。
H4:设顾客对供应商总体信用评估结果中当期信用评估结果占比为δ(0≤δ≤1),则顾客对供应商上一期信用评估结果在供应商当期总体信用度评估结果中的占比为1-δ。
H5:设顾客对供应商当期信用评估结果为f(t),对供应商上一期的信用评估结果为f(t-1)。
H6:设如果供应商提供虚假信息欺瞒顾客成功其总体信用评估结果将提高m,如果失败其总体信用评估结果将下降n。
则供应商当期(第t期)总体信用评估结果为:
F(t)=πt(δf(t)+(1-δ)f(t-1))
+(1-πt)(δ(γ(f(t)-n)
+(1-γ)(f(t)+m))+(1-δ)f(t-1))
-k(1-πt-1,γ)
(1)
同理,供应商上一期(第t-1期)总体信用评估结果为:
F(t-1)=πt-1(δf(t-1)+(1-δ)f(t-2))
+(1-πt-1)(δ(γ(f(t-1)-n)
+(1-γ)(f(t-1)+m))
+(1-δ)f(t-2))-k(1-πt-2,γ)
(2)
计算公式(1)+公式(2)并整理得:
F(t-1)+F(t)=δf(t)+f(t-1)+(1-δ)f(t-2)
+(2-πt-πt-1)δ(m-(m+n)γ)
-k(1-πt-1,γ)-k(1-πt-2,γ)
=δf(t)+f(t-1)+(1-δ)f(t-2)
+(1-πt)δ(m-(m+n)γ)
-k(1-πt-1,γ)+(1-πt-1)δ(m-(m+n)γ)
-k(1-πt-2,γ)
(3)
供应商追求两期总体信用评估结果和的最大值max(F(t-1)+F(t)),即公式(3)的最大值。
对公式(3)进行分析,δ为固定值,f(t)、f(t-1)、f(t-2)是不同期网络供应商信用评估结果;(1-πt)δ(m-(m+n)γ)-k(1-πt-1,γ)是γ的单调减函数,即随着大数据分析技术捕获供应商欺瞒顾客其信用水平能力的提高,网络供应商总体信用度评估结果会更低。因为0≤πt≤1,且(1-πt)δ(m-(m+n)γ)-k(1-πt-1,γ)是关于πt,γ的连续函数。所以存在以下情况:
1.当γ=0时,(1-πt)δ(m-(m+n)γ)-k(1-πt-1,γ)≥0;当γ=1时,(1-πt)δ(m-(m+n)γ)-k(1-πt-1,γ)≤0。
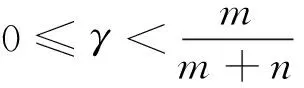
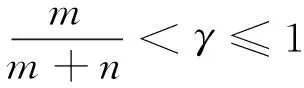
同理可以对(1-πt-1)δ(m-(m+n)γ)-k(1-πt-2,γ)与πt-1,γ的关系进行分析。
结合-k(1-πt-1,γ)、-k(1-πt-2,γ)的定义、特点进行分析,当大数据分析技术捕获供应商欺瞒顾客其信用水平能力较低时,供应商会更多地欺瞒顾客;随着大数据分析技术捕获供应商欺瞒顾客其信用水平能力达到一定程度时,供应商提供真实商品信息会是更明智的选择。
以上通过博弈分析得到了大数据技术对网络供应商信用评估的价值。
四、基于大数据的网络供应商信用评估指标体系构建
由于不同的商品其特性不同,顾客所关注的信用指标重要程度不同,所以在建立供应商信用评估指标体系时,针对不同类型商品的供应商,其所选取的指标体系将是不同的。基于大数据的网络供应商信用评估指标体系在传统网络供应商信用评估指标体系的基础上经过专家研究、讨论,提出以下备选指标体系(Ia):网站的规模(I1)、发展时间(I2)、提供信息的完整度(I3)、商品质量(I4)、供应商声誉(I5)、商品种类(I6)、资产状况(I7)、负债状况(I8)、组织管理结构(I9)、领导理念(I10)、供货周期(I11)、商品价格(I12)、物流配送方式(I13)、配送周期(I14)、售后服务内容(I15)、售后服务时间(I16)、供应商发展前景(I17)、供应商商品质量改进意愿(I18)。
备选指标体系(Ia)各指标的特性及量化值如表1所示。
通常,对于一个既定的电子商务网站来说,对应于网络供应商的信用指标体系所包含评估指标的取值单纯依靠其交易系统是无法完整获取的,只有将供应商信用评估相关数据获取的来源尽可能地扩大,借助大数据分析技术,对网络供应商信用评估相关大数据进行分析才能获取。
对于某一类商品的网络供应商,其信用评估最终指标体系Ic的选取过程为:
1.借助大数据分析技术得到所有样本网络供应商(同一类商品的网络供应商)备选信用评估指标体系(Ia)所包含的信用评估指标各时期(进行研究分析的时间段)取值,同时获取各样本网络供应商各时期标准信用评估结果(由权威机构或者专家给出),由专家研究、讨论建立针对该类商品的网络供应商的信用评估基础指标体系(Ib)。

表1 备选指标体系(Ia)各指标的特性及量化值
2.使用逐步回归法按照备选指标体系(Ia)中指标变量对评估结果变量影响的显著程度大小来决定这些指标变量引入Ib或者从Ib剔除,最终得到指标体系Ic。
逐步回归法的理论基础及最终指标体系Ic的计量经济学模型选取过程为:
设由基础指标体系包含的指标有Ib={I1,I2,…,Is},共s个。设样本数据为n,即研究n个样本网络供应商(s+1 f′(t)=β0+β1I1t+β2I2t+…+βsIst+ut (4) 对于n个样本,其表达式分别为: f′(1)=β0+β1I11+β2I21+…+βsIs1+u1 f′(2)=β0+β1I12+β2I22+…+βsIs2+u2 … f′(n)=β0+β1I1n+β2I2n+…+βsIsn+un 其矩阵表达式为: f′=Iβ+u (5) 其中: β为参数,u为扰动项。 使用最小二乘估计法,f′(t)拟合模型的表达式为[14]: (6) 计算并化简得矩阵形式方程组: (7) 对于线性回归模型来说,总平方和(TSS)=回归平方和(ESS)+残差平方和(RSS)[14]。为了表述方便,RSS通常记为S。 对于Ij∈Ia且Ij∉Ib,其偏回归平方和为Vj=S-S′,Vj为偏回归平方和,S为基础指标体系变量的残差平方和,S′为引入指标变量Ij后的残差平方和。 基于以上理论基础,对指标变量的引入与剔除方法介绍如下[15]: 1.引入一个指标变量。 进行逐步回归引入一个指标变量时,应是所有未引入变量中偏回归平方和最大的一个,假设这一变量为Ik(Ik∉Ib),则Vk=max{V(1,2,…,s)-},其中I(1,2,…,s)-∈Ia且I(1,2,…,s)-∉Ib,V(1,2,…,s)-为I(1,2,…,s)-的偏回归平方和。 当Ik引入后,对于其他I(1,2,…,s)-指标变量可以参照以上方法逐步引入。 2.剔除一个指标变量。 进行逐步回归剔除一个指标变量时,应是所有引入指标变量中偏回归平方和最小的一个,设这一变量为Il(Il∈Ib),则Vl=min{V(1,2,…,s)},其中I(1,2,…,s)∈Ib,V(1,2,…,s)为I(1,2,…,s)的偏回归平方和。 当Il剔除后,对于其他I(1,2,…,s)指标变量可以参照以上方法逐步剔除。 (8) 因为一个网络供应商的总体信用度评估结果是由顾客对供应商当期信用度评估结果与顾客对供应商前期信用度评估结果综合影响而形成的,为了研究方便,本文只构建包括当期信用度评估结果与前一期信用度评估结果的供应商总体信用度评估结果的部分调整模型(本节分析基于大数据的网络供应商信用度的计算,不考虑信用风险因素,因此信用评估模型与第三节供应商信用博弈分析模型构建思想基础不同,二者信用的侧重点有区别): F(t)=δf(t)+(1-δ)F(t-1) (9) 同理可得: F(t-1)=δf(t-1)+(1-δ)F(t-2) (10) …… 因此,前n-1(n为有限值)期供应商信用度评估结果表达式为: F(t-(n-1))=δf(t-(n-1)) +(1-δ)F(t-n) (11) 将前各期供应商信用度评估值逐渐回代,计算并化简可得: F(t)=δf(t)+δ(1-δ)f(t-1)+δ(1-δ)2f(t-2) +…+δ(1-δ)n-1f(t-n+1) +(1-δ)nF(t-n) (12) 为了运算简便,设第t-n期供应商总体信用度评估结果只由该期顾客对供应商的信用度评估结果决定,即设F(t-n)=f(t-n),代入公式(12)可得: F(t)=δf(t)+δ(1-δ)f(t-1)+δ(1-δ)2f(t-2) +…+δ(1-δ)n-1f(t-n+1) +(1-δ)nf(t-n) (13) 有关径向基神经网络模型的构建方法及相应的聚类算法可以参阅傅荟璇和赵红(2010)[16]、郭小燕和张明(2013)[17]、汪中等(2009)[18]、索红光和王玉伟(2008)[19]、李梦雨(2012)[20]等的研究。径向基神经网络模型结构图如图3所示。 图3 径向基神经网络结构图 使用K-Means方法求解径向基高斯函数中心C。本文构建网络供应商信用评估径向基神经网络模型的基本思路如下: 1.随机选取h个训练样本(h个网络供应商信用评估指标值向量)作为聚类中心Ci,i=1,2,…,h。 2.计算所有样本与聚类中心的欧氏带权重距离||Xj-Ci||。 定义Xj与Ci的欧氏带权重距离为: 其中,Xj=Xj(1,I1,I2,…Im),Ci=Ci(1,Ci1,Ci2,…Cim)。 3.按最近邻规则确定样本Xj的归属。 4.重新调整聚类中心。 计算各个聚类集合新的聚类中心,如果聚类中心发生变化,则转到第2步,否则聚类过程结束。 5.计算σi。 6.定义径向基神经网络模型的信用度计算函数。 (14) 7.计算wi(i=1,2,…,h)。 当输入Xj(1≤j≤g,g为样本总数)时,Ci结点的输出为: φji=φ(||Xj-Ci||),j=1,2,…,g;i=1,2,…,h。 则隐层的输出矩阵为: φ=[φji]。 令f=(f1,f2,…fg)T,W=(w1,w2,…wh)T,则f=φW,且W=(φTφ)-1φTf。 对于某一网络供应商k(非样本),将其按信用度计算函数计算得到的当期fk(t)及前n期fk(t-1),fk(t-2),…,fk(t-n)计算结果代入公式(13),即可得到这一网络供应商当期的总体信用度评估结果Fk(t),进一步设置评估等级取值范围,确定网络供应商的信用等级。 以服装类商品为例,并设对应网站为网络供应商。实例选择95个网站进行分析(确保这95个网站是有代表性的网站,即其信用评估结果涵盖了优、良、中、差四个等级;基于隐私考虑,这里隐去网站名称)。其信用评估及结果分析过程如以下步骤所示: 1.使用网络爬虫结合搜索引擎从互联网大数据中(包括交易网站交易数据、交易评论、新闻、论坛以及其他相关网站数据资料)采集各网站2013.1—2014.12各时期(2013.1—2013.6,2013.7—2013.12,2014.1—2014.6,2014.7—2014.12)相关信用大数据;其中有一部分网站信用评估相关数据是由一些机构或者个人等第三方数据源提供的,还有一部分网站由于无法获取信用评估相关数据,但通过专家研究给出了这些网站各时期的信用评估指标取值及标准信用度评估结果(模拟数据)。 2.针对信用评估备选指标体系Ia的各指标含义及其在生活、网络中的可能取值编写信用评估指标语义字典,语义字典包括各指标的取值及其对各指标特性的反映。 3.对于任一网站,结合各指标的语义字典对该网站相关信用大数据进行分析,按照相关信用大数据中各时期各指标取值量化结果进行指标期望值计算(比如对于某一网站的信用评估指标I1,对其某一时期相关信用大数据进行分析后,数据资料中反映其取值特性为“大”的比例为A,反映其取值特性为“中”的比例为B,反映其取值特性为“小”的比例为1-A-B,则其指标量化期望值为A×1+B×0.5+(1-A-B)×0=A+0.5B),最终获得各网站各时期对应Ia的各指标的量化取值。 4.进一步经过专家研究、讨论后确定网站基础指标体系Ib={I1、I2、I4、I7、I8、I12、I14、I15、I16、I18},给出网站信用度值所属的信用评估等级(优[0.90,1.00]、良[0.80,0.89]、中[0.70,0.79]、差[0,0.69])。 6.将这30个样本网站第一期各网站Ic各指标取值及标准信用度评估取值作为样本数据进行训练,得到第一期网站信用度计算函数(本文为计算方便在以后三期也只使用了第一期的网站信用度计算函数)。 7.使用网站信用度计算函数计算除这30个样本网站以外其他65个网站2013.1—2014.12各时期的信用度评估结果。 8.给定δ=0.5,将步骤7计算结果代入公式(13),确定其他65个网站最后一期的总体信用度评估结果。 9.确定并对比最后一期专家给出的其他65个网站的标准信用度评估结果所属的信用评估等级与通过信用评估模型计算出的各网站总体信用度评估结果所属的信用评估等级,得出65个网站最后一期信用评估模型总体信用度评估结果相对于专家给出的标准信用度评估结果的正确率;进一步将与专家给出的65个网站最后一期标准信用度评估结果相差不超过0.1的信用评估模型总体信用度评估结果也作为正确结果,计算其评估正确率。 10.进一步调整δ=0,δ=0.1,δ=0.2,δ=0.3,δ=0.4,δ=0.6,δ=0.7,δ=0.8,δ=0.9,δ=1.0,重复步骤8、9。 11.针对相应网站及相应类别的商品建立纯线性回归模型、纯径向基神经网络模型并按照相应数据(样本数据集为30个样本网站第一期相关数据,测试数据集为65个网站最后一期相关数据)进行各网站信用度的评估计算,得到不同模型评估结果的正确率。具体结果如图4、图5所示。 对于某一网站(设专家给出其标准信用度评估结果为0.85,这样设只是为了图形比较说明,没有实际含义),因为F(t)=δf(t)+(1-δ)F(t-1),当δ=0.5时,给出F(t)的理论取值示意图如图6所示。 图4不同模型评估正确率 图5正确结果扩充|专家结果-模型结果|≤0.1部分 图6 F(t)理论取值示意图 若F(t-1)=f(t)+Δf(Δf≥0),则模型评估结果F模(t)=f(t)+(1-δ)Δf,这一值随δ的增大而减小,基于此,做以下情况分析: 1.当专家评估网站的F专(t)≥F(t-1)时,δ=0时模型评估结果与专家评估结果差距最小,此时的评估正确率最高。 2.当F专(t)≤f(t)时,δ=1时模型评估结果与专家评估结果差距最小,此时的评估正确率最高。 3.当f(t) 对本文的理论基础及实证取得的结果进行分析,得到如下研究结论: 当假设专家非常理性时,专家对网站信用评估结果会处于第3种情况f(t) 对于F(t-1)=f(t)-Δf(Δf≥0)的情况会有类似分析结果。 另外,通过对销售农产品类、书籍类、玩具类、化妆品类商品的网站建立相应的信用评估模型并进行相应的评估结果分析,也取得了较好的评估正确率分析结果。 本文针对目前中国电子商务交易发展的趋势及顾客购物关注的问题提出网络供应商信用评估的意义。以B2C电子商务为例,针对网络供应商信用评估的特点提出借助大数据技术实现网络供应商的信用评估,分析了基于大数据的网络供应商信用博弈行为,使用逐步回归法构建了网络供应商信用评估指标体系,构建了基于部分调整模型及带权重径向基神经网络模型的网络供应商信用评估模型,通过实例数据对模型运行的有效性进行了验证。对于其他类型的电子商务供应商信用评估问题及其他交易主体的信用评估问题,本文的研究方法具有一定的参考价值和指导意义。 在本文实证分析阶段,因为样本数据选取具有很大的随机性,所以得到的参数也具有很大的随机性。因为目前各网站数据结构特点不一,信用评估数据资料也相对不完善,同时存在着数据资料冗余、可信度需要考证等问题,所以在研究过程中对数据资料进行了清洗、过滤,对于样本网站信用度标准值、评分标准的确定采用了专家给定的形式,对于模型有些输入输出数据也采用专家修正的形式。 本文的研究在目前电子商务交易主体信用评估标准、思想体系不完善的情况下提出来虽然在实际运行中还有一定的欠缺,但其研究方法有一定的借鉴意义,今后将继续深入研究,使这一模型指标体系及相应参数的确定更加客观、准确,数据更加真实、可靠,以提高评估结果的正确度。 [1]彭丽芳,陈中,李琪.网络交易中信用评价方法研究[J].南开管理评论,2007,10(2):76-81. [2]殷红.网络交易中的私人秩序[J].华东师范大学学报(哲学社会科学版),2013,1:94-102. [3]廖华,张旭辉.基于隐性信用因素评价的C2C 卖方选择模型研究[J].云南财经大学学报,2014(3):134-139. [4]王俊峰,吴海洋.基于改进的 TOPSIS法的B2C企业信用评价[J].软科学,2014,28(6):21-24. [5]贾艳涛,虞慧群.基于C2C的可信信用评价模型[J].计算机工程,2010,36(18):256-258. [6]陈鑫铭,冯艳.C2C电子商务信用评估体系研究[J].图书情报工作,2009,53(14):134-137. [7]郭亦涵,郑植.C2C电子商务网站信用评价模型研究[J].北京邮电大学学报(社会科学版),2011,13(4):21-25. [8]李瑞轩,高昶,辜希武,等.C2C 电子商务交易的信用及风险评估方法研究[J].通信学报,2009,30(7):78-84. [9]章向东,钟为亚.大数据时代我国信用评级业重构研究[J].湖南师范大学社会科学学报,2014,6:95-100. [10]李海强.依托大数据解决供应链企业信用贷款问题的研究[D].上海:华东师范大学硕士学位论文,2014,3:1-67. [11]Jenkins,Patrick.Big Data Lends New Zest to Banks’ Credit Judgments[N].Financial Times,2014,6:20-21. [12]Wisniewski.Behavioral Data Startup Combines Big Data with Credit ‘Traffic School’[J].American Banker,2013,178(186):8. [13]方湖柳,李圣君.大数据时代食品安全智能化监管机制[J].杭州师范大学学报(社会科学版),2014,11:99-104. [14]潘省初.计量经济学中级教程(第2版)[M].北京:清华大学出版社,2013,8:8-18. [15]傅德印,张旭东.EXCEL与多元统计分析[M].北京:中国统计出版社,2007,3:90-96. [16]傅荟璇,赵红.MATLAB神经网络应用设计[M].北京:机械工业出版社,2010,9:98-101. [17]郭小燕,张明.带权重的RBF神经网络银行个人信用评价方法[J].计算机工程与应用,2013,49(5):258-262. [18]汪中,刘贵全,陈恩红.一种优化初始中心点的K-means算法[J].模式识别与人工智能,2009,22(2):299-303. [19]索红光,王玉伟.一种用于文本聚类的改进k-means算法[J].山东大学学报(理学版),2008,43(1):60-64. [20]李梦雨.中国金融风险预警系统的构建研究——基于k-均值聚类算法和BP神经网络[J].中央财经大学学报,2012,10:25-30.



五、基于大数据的网络供应商信用评估模型




六、实证分析




七、总结
