一种基于深度学习的人体交互行为分层识别方法
2016-06-22尹坤阳谢立东徐素霞
尹坤阳,潘 伟,谢立东,徐素霞
(厦门大学 信息科学与技术学院,福建省仿脑智能系统重点实验室,福建厦门361005)
一种基于深度学习的人体交互行为分层识别方法
尹坤阳,潘伟,谢立东,徐素霞*
(厦门大学 信息科学与技术学院,福建省仿脑智能系统重点实验室,福建厦门361005)
摘要:本文把人体交互行为分解为由简单到复杂的4个层次:姿态、原子动作、复杂动作和交互行为,并提出了一种分层渐进的人体交互行为识别方法.该方法共有3层:第1层通过训练栈式降噪自编码神经网络把原始视频中的人体行为识别为姿态序列;第2层构建原子动作的隐马尔科夫模型(hidden Markov model,HMM),并利用估值定界法识别第1层输出的姿态序列中包含的原子动作;第3层以第2层输出的原子动作序列为输入,采用基于上下文无关文法(context-free grammar,CFG)的描述方法识别原子动作序列中的复杂动作和交互行为.实验结果表明,该方法能有效地识别人体交互行为.
关键词:人体行为识别;深度学习;隐马尔科夫模型(HMM);上下文无关文法(CFG);Kinect
人体行为识别在计算机视觉领域中占有重要地位,它在视频监控、医疗监护、人机交互和运动分析等诸多领域有着广泛的应用[1].在过去的几十年中,研究者们提出了大量的行为识别方法,这些方法可以分为2类:单层行为识别方法和分层行为识别方法[2].
单层行为识别方法又可分为时空法[3]和序列法[4].时空法把输入视频当作一个三维的时空体(XYT),而序列法把输入视频视为特征向量序列.单层行为识别方法直接从图像序列中表示和识别人体行为;而分层行为识别方法往往会有2层或者更多的层次,底层直接处理输入图像,高层把低层的识别结果作为输入继续进行识别工作.与单层行为识别方法相比,分层行为识别方法需要较少的训练数据,更容易融入先验知识.
分层行为识别方法可分为3类:统计方法[5]、句法方法[6]和基于描述的方法[7].统计方法通过构造基于状态模型的连接层次概率表示和识别人体行为;句法方法采用特定的语法规则对高层行为进行建模,常见的语法规则有上下文无关文法(context-free grammar,CFG)和随机CFG;基于描述的方法通过描述子动作之间的时间、空间和逻辑关系表示人体行为.与上述2种分层行为识别方法不同,基于描述的方法虽然把复杂动作当作简单子动作的组合,但只有满足一定条件的子动作组合才被视为复杂动作.
很长时间以来,神经网络领域的研究者意识到使用多层非线性的网络组合会达到更好的效果,但在训练时容易陷入局部最优,多层神经网络的性能反而更不理想.2006年Hinton等[8]提出逐层初始化降低多层神经网络训练难度,掀起机器学习的第2次浪潮.Larochelle等[9]进一步提出栈式降噪自编码神经网络,这种神经网络在训练数据中加入噪声,显著地提高了学习的效果.在基于描述的行为识别方法领域,Allen[10]为描述子动作之间的时间关系提出了一组时间描述子,后来这些描述子被其他研究者广泛采用.Ryoo等[11]采用基于CFG的描述方法表示人体行为,提出逻辑描述子(与、或和非)增强空间和时间描述子对子动作关系的表示能力.但这些识别方法使用彩色相机采集数据,光照条件、衣服的纹理甚至人的影子都会影响识别效果.使用Kinect深度相机采集数据,可以有效消除光照变化和复杂背景的影响,提高人体行为识别的鲁棒性[12].苏竑宇等[13]构建了基于支持向量机(support vector machine,SVM)和隐马尔可夫模型(hidden Markov model,HMM)二级模型识别日常行为,他们使用了Kinect采集的数据集,但并未涉及交互行为.
本文提出了一种新的分层行为识别方法.与文献[11]的方法相比,该方法第1层使用深度神经网络,提高了识别方法的可扩展性;第2层提出的估值定界法提高了对原子动作分割的效率和准确度;第3层设计了1组新型空间描述子,引入人脸朝向,增强了对交互行为的描述能力.Kinect提供的骨骼信息是由人体轮廓估算而来,骨骼信息不能有效获取人体接触及遮挡信息,因此本文选取轮廓图像作为输入,而不采用骨骼信息,同时采用彩色图像识别人脸朝向.
1识别方法概述
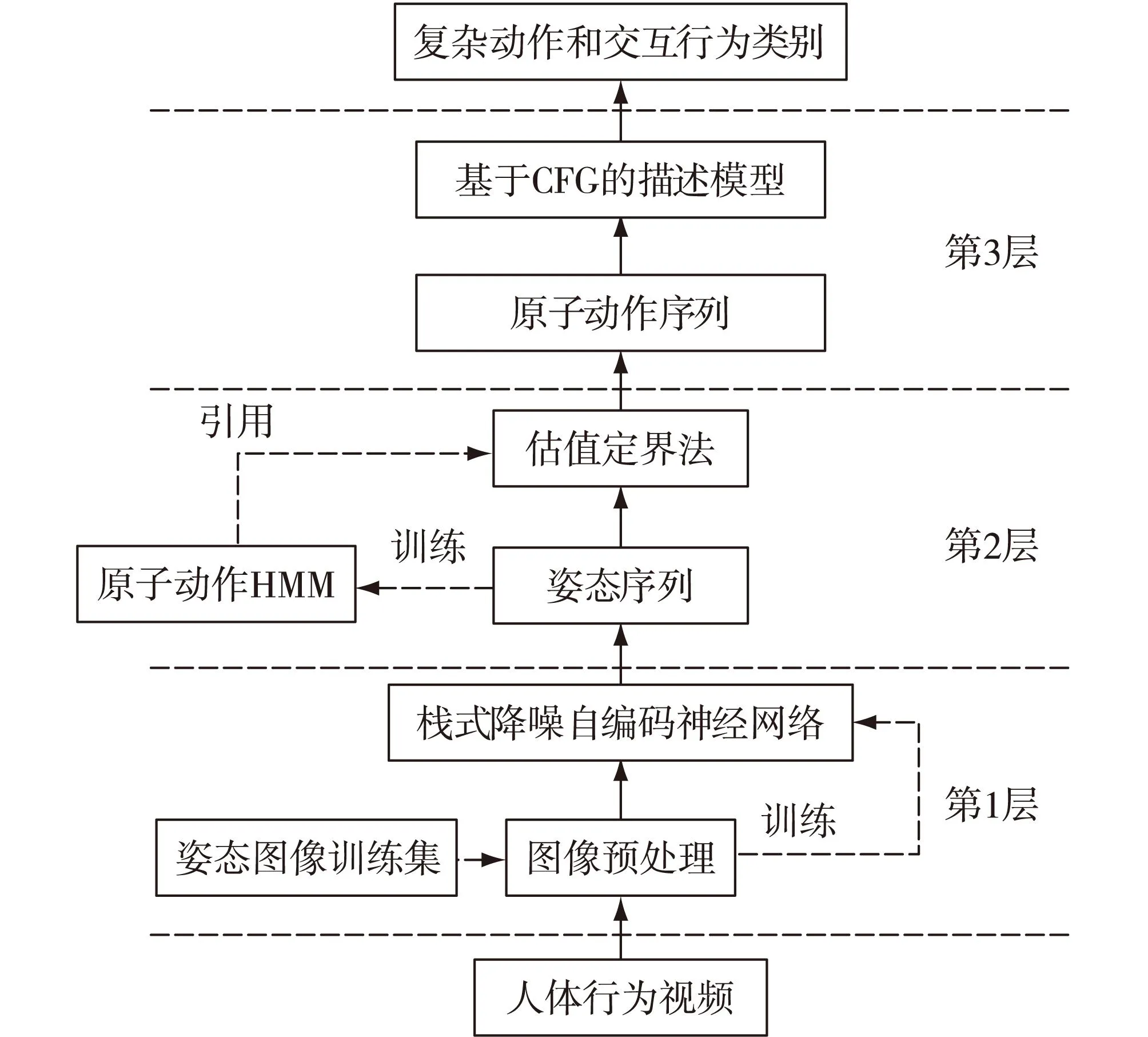
图1 识别方法框图Fig.1Processing flow of the recognition system
本文采用分层的交互行为识别方法,算法框架见图1.该识别方法共有3层:第1层把采集到的视频图像进行预处理,提取图像中包含人体的部分,并转换成同样的大小,然后输入采用深度学习算法的栈式降噪自编码神经网络进行分类,识别出每帧图像中的人体行为姿态;第2层把第1层输出的姿态序列作为输入,用估值定界法对姿态序列进行分割,找出原子动作的起止点,输出原子动作序列;第3层的输入是第2层输出的原子动作序列,根据基于CFG的描述规则,识别原子动作序列中的复杂动作和交互行为.这种方法需要训练栈式降噪自编码神经网络、构建原子动作的HMM和基于CFG的描述模型:其中栈式降噪自编码神经网络由姿态图像训练集图像预处理后训练而成;原子动作HMM的训练数据来自原子动作训练集,动作视频图像预处理后通过栈式降噪自编码神经网络进行识别,输出姿态序列,进而构建原子动作的HMM;基于CFG的描述模型则根据复杂动作和交互行为的子动作之间的时间关系和执行者之间的空间关系添加规则,构建各个复杂动作和交互行为的描述模型.
2第1层:基于深度学习的姿态识别
姿态是对图像中整个人体的抽象和描述,每帧图像中的人像都属于某个姿态.第1层识别工作完成时,每帧图像就可以用姿态表示.本文构建了一个新型的栈式降噪自编码神经网络识别图像中的人体姿态[14],识别过程如图2所示.

图2 姿态识别过程图Fig.2Processing flow of pose recognition
2.1图像预处理
Kinect能够实时获取人体轮廓信息,采集的视频分辨率为240×320.为了减少计算量,图像预处理时提取图像中的人体部分并缩放至28×28.具体过程如下:在图像中找到人体上下左右的边界点,去掉超出边界点的部分,对剩余的矩形采用线性插值法,缩放至28×28,把这784个像素点的数值作为一个行向量保存起来.至此,图像预处理工作完成.
2.2构建栈式降噪自编码神经网络
栈式降噪自编码神经网络采用深度学习算法,由多层稀疏自编码器组成,每层的输出是后一层的输入.构建栈式降噪自编码神经网络需要设计隐层层数及每层节点数,同时设计良好的学习率能加快学习过程.

图3 不同参数对深度学习性能的影响Fig.3The different building performance on human action dataset
为了选取合适的节点数,先构建一个3层BP神经网络,其中输入层节点数为784.隐层的节点数从10递增到1 100,迭代次数从25递增到100.从图3(a)可以看出,当节点数小于200时(上下层节点数比例约为0.25),神经网络性能良好,当节点数大于600时,神经网络性能就变得很差.因此对每个隐层节点数选为上一层节点数的25%左右,这样,整个网络结构像一个金字塔,从输入层到输出层节点数依次减少.
学习率的不同会影响深度学习的收敛速度,为了使深度神经网络能更快的收敛,本文使用自适应学习率更新算法:
LR(i+1)=
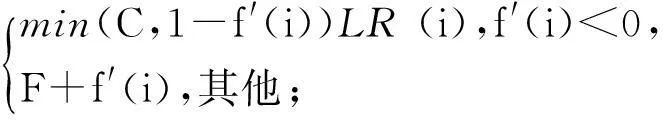
(1)
LR(0)=F;
(2)

(3)
其中LR(i)表示i时刻的学习率,C和F分别为学习率的上限值和下限值,f(i)是i时刻的均方误差,f′(i)是i时刻和i-1时刻均方误差的差值.
为了保证学习率在合适的范围内,选取C=3,F=0.1.图3(b)中有几种固定学习率和自适应学习率时神经网络的性能对比,可以看出采用自适应学习率能显著提高神经网络性能.
2.3姿态识别实验结果
对构建的深度学习方法与其他机器学习算法进行比较,进行比较的算法有采用径向基核(radial basis function,RBF)的监督学习算法SVM、集成学习算法随机森林(random forest)、深度学习算法RBF神经网络(network)和深度信念网络(deep belief network,DBN).所有算法使用同一个数据集,即姿态图像训练集,包含待识别原子动作中的全部姿态图像.表1表明栈式降噪自编码神经网络(ours)相对其他算法识别性能有很大的提升.

表1 不同算法识别准确率的比较
3第2层:基于估值定界法的原子动作识别
原子动作是人体部分肢体就能完成的动作,比如伸手就是一个原子动作.它们由多个姿态组成,往往不能进一步分解为更小的有意义的动作.为了提高姿态序列中原子动作及其起始点的效率和准确度,本文提出了估值定界法.
3.1原子动作的识别
经过第1层的姿态识别后,人体行为视频就变成了一个姿态序列.基于原子动作训练集的姿态序列,本文采用Baum-Welch算法构建了12个动作的HMM(即表2中的原子动作).识别时把似然度值最大的类别作为识别结果,以收回手臂(hand_withdraw)为例.表2是该动作各HMM下的似然度值,其中最大的是-15.700 8,即识别结果是hand_withdraw.整个测试集的识别准确率为85.29%.
3.2原子动作的起止点
如果视频流中包含多个原子动作,可以采用HMM估值问题,对连续帧动作依据似然匹配度进行划分.参考文献[11]的前向后看算法,本文加入静态原子动作的判定标准,提出了估值定界法.

表2 原子动作hand_withdraw的似然度值
注:-Inf表示似然度值超出数值范围.
前向后看算法在找到动作的终止点前和前向算法一样,若HMM似然度值在t帧超过阈值,就把t帧当作原子动作的终止点.找到终止点后,该算法用后向算法寻找原子动作的起始点.当找到原子动作起止点后,该算法从t+1帧开始识别视频中的下一个动作.如果碰到站立(stand)这种既能当作原子动作又能和其他姿态组成新的原子动作,前向后看算法识别结果往往不尽如人意.估值定界法有效地解决了这个问题:如果在t帧时视频的某HMM似然度值一直小于静态阈值且达到一定时间,就认为视频中发生了该HMM所表示的动作,动作的终止点设为t-3,不需要执行后向算法,直接从t-2开始识别视频流中的下一个动作.
对于输入的视频,识别方法在第1层识别图像中的人体姿态,输入视频就变成了一个姿态序列.接着采用估值定界法识别姿态序列中的原子动作并找出它们的起止点,最后融合间隔小于阈值的相邻相同动作,输出最后的识别结果.
用符号表示姿态,其中1表示stand,2表示hand_stay_stretch,伸手图像序列表示为:
[1,1,1,1,1,1,1,2,2,2,2,2,2,2].
用估值定界法识别上面的符号序列,最终结果如表3所示.

表3 原子动作的分割与识别
4第3层:基于CFG的交互行为识别
单人动作可以分为原子动作和复杂动作.复杂动作是指由2个或以上原子动作组成的动作,它的子动作可以是原子动作或者其他复杂动作,但只能由一个人完成.如果一个动作有2个或以上的参与者,那么这个动作就是交互行为.该层用基于CFG的描述方法表示和识别交互行为.
4.1基于CFG的行为表示
本文参考了文献[11]提出的基于CFG的行为表示方法,重新设计了一组空间描述子描述动作执行者的空间关系,并引入人脸朝向增强对行为的表示能力.
4.1.1时间、空间和逻辑描述子
时间描述子描述子动作之间的时间关系.Allen[10]提出的时间描述子有:“before”、“meets”、“overlaps”、“starts”、“during”和“finishes”.若a和b是两个动作,起始和终止用下标表示,时间描述子定义如下:
空间描述子描述动作执行者之间的空间关系.Ryoo等[11]定义了2个空间描述子:“near”和“touch”.Aksoy等[15]在他们的语义场景图中定义了4种空间描述子:“absence”、“no connection”、“overlapping”和“touching”.本文融合两者提出一组新的空间描述子:“far”、“near”、“touch”和“overlap”.

逻辑描述子包含与、或和非,可以加强时间描述子和空间描述子对行为的表示能力.它们的定义和传统数理逻辑中的定义一致.
4.1.2人脸朝向
人脸朝向也能增强描述子对行为的描述能力,当2人的动作是相互靠近或者相互离开时,人脸朝向可以作为执行者所做动作的方向.Face++在多项世界人脸识别比赛中名列前茅,他们的核心算法使用深度学习[16].本文采用Face++提供的云API识别人脸朝向,通过云API,每个头像会返回83个关键点信息,把这83个信息点用九宫格分为9个区域,统计每个区域关键点的数量,则形成一个九维的特征向量.人脸朝向分为3类:左、中和右.实验中人脸数据共有6 000帧,取自拍摄的姿态图像训练集和原子动作训练集中的图像,采用随机森林进行训练识别,识别精度达到97.63%.
4.2单人复杂动作的识别
单人复杂动作的识别,即识别视频中的子动作及它们之间的时间关系.以握手(handshake)为例,这个复杂动作可以分为3个子动作:“hand_stretch”、“hand_stay_stretch”和“hand_withdraw”.
经过姿态识别后,复杂动作握手的图像序列变为姿态序列,用符号表示为:
[1,1,1,1,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,1,
1,1,1].
接着用估值定界法找出上述序列中子动作的起止点,此处前向阈值为-7,后向阈值为-10,静态连续帧个数为5.表4为最终输出结果.

表4 复杂动作分割示例
注:以握手的子动作为例.
3个子动作的时间关系满足:
meets(hand_stretch,hand_stay_stretch)&
meets(hand_stay_stretch,hand_withdraw)
符合基于CFG的描述方法对握手这个动作的定义,从而识别出握手这个行为.
4.3交互行为的识别
通过单人复杂动作的识别,得到每个人的动作在时间上的关系;根据人脸朝向,得到动作执行者所做动作的方向;再加上空间描述信息,就能准确表示交互行为.以交互行为ShakeHands为例(图4).

图4 交互行为ShakeHands的图像和剪影序列Fig.4The images and silhouettes of interactive ShakeHands
图5中PR表示图像右边的人,PL表示图像左边的人.识别单个人的动作时,发现PR和PL都有一个握手的复杂动作,并且在hand_stay_stretch阶段,2人相互接触,他们的关系描述如下:

很明显这些子动作之间的关系满足ShakeHands的定义,并由人脸朝向可知,2人的动作分别指向对方,即在这段视频中识别出交互行为ShakeHands.
4.4实验结果
采集的交互动作数据集共有10组,每组都包括“Approach”、“Depart”、“Hello”、“ShakeHands”和“Punch”,还有1个动作“Point”作为干扰.Approach是2人走近,Depart是2人走远,它们的子动作均是walk,需要的空间描述子分别为far和near.Hello是2人打招呼,可以不需要空间描述子.ShakeHands是2人握手,而Punch是一人拳打另一人,两者都需要空间描述子touch.
第1层识别出每帧图像中的人体姿态,第2层用估值定界法识别出原子动作和它们的起止点,第3层采用基于CFG描述的方法识别交互行为.表5是最终的识别结果,可以看出虽然视频数据集较小,但仍能达到很好的识别结果,数据集总体识别准确率为82%.

图5 交互行为ShakeHands识别示意图Fig.5Illustration of ShakeHands recognition
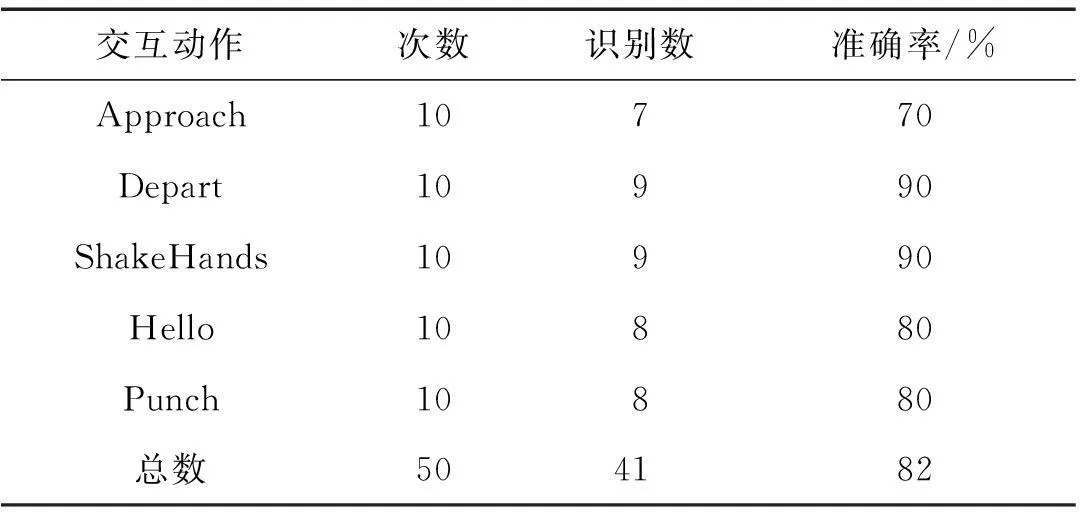
交互动作次数识别数准确率/%Approach10770Depart10990ShakeHands10990Hello10880Punch10880总数504182
5结论
本文提出了一种分层的交互行为识别方法.该方法针对普通摄像机采集数据进行人体行为识别时难以提取图像中的人体部分,容易受到光照条件和背景色彩的影响,且不易消除人影等问题,使用能获取深度信息的Kinect采集数据.Kinect利用深度信息能有效解决上述问题,实时跟踪视野中的人体.本文还采用栈式降噪自编码神经网络识别图像中人体姿态,由于深度学习能自动学习数据特征,提高了行为识别方法的可扩展性和适应性.在对姿态序列进行分割时,该方法对静态原子动作的识别进行了优化,提出的估值定界法提高了原子动作分割的效率和准确率.针对数据集较小的问题,该方法采用基于描述的分层行为识别方法,方便融合先验知识,引入人脸朝向增强了描述子对行为的描述能力,实验结果显示提出的方法能有效识别人体交互性行为.
单个Kinect采集数据时,视觉范围和角度都有一定的局限,遮挡问题难以消除,对人体行为识别影响较大.因此在未来的工作中,我们将采用多个Kinect采集数据,以减少遮挡和角度等因素的影响.
参考文献:
[1]POPPE R.A survey on vision-based human action recognition[J].Image and Vision Computing,2010,28(6):976-990.
[2]AGGARWAL J K,Ryoo M S.Human activity analysis:a review[J].Acm Computing Surveys,2011,43(3):1-43.
[3]SHEIKH Y,SHEIKH M,SHAH M.Exploring the space of a human action[C]∥2005 IEEE International Conference on Computer Vision(ICCV).Beijing:IEEE,2005:144-149.
[4]NATARAJAN P,NEVATIA R.Coupled hidden semi markov models for activity recognition[C]∥2007 IEEE Workshop on Motion and Video Computing(WMVC).Austin:IEEE,2007:10.
[5]OLIVER N,HORVITZ E,GARG A.Layered representations for human activity recognition[C]∥2002 IEEE International Conference on Multimodal Interfaces(ICMI).Pittsburgh,PA:IEEE,2002:3-8.
[6]JOO S W,CHELLAPPA R.Attribute grammar-based event recognition and anomaly detection[C]∥2006 IEEE Conference on Computer Vision and Pattern Recognition Workshops(CVPRW).New York:IEEE,2006:107.
[7]GUPTA A,SRINIVASAN P,JIANBO S,et al.Understanding videos,constructing plots learning a visually grounded storyline model from annotated videos[C]∥2009 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Miami,FL:IEEE,2009:2012-2019.
[8]HINTON G E,SALAKHUTDINOV R R.Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.
[9]VINCENT P,LAROCHELLE H,LAJOIE I,et al.Stacked denoising autoencoders:learning useful representations in a deep network with a local denoising criterion[J].Journal of Machine Learning Research,2010,11:3371-3408.
[10]ALLEN J F.Rethinking logics of action and time[C]∥2013 International Symposium on Temporal Representation and Reasoning (TIME).Pensacola,FL:IEEE,2013:3-4.
[11]RYOO M S,AGGARWAL J K.Recognition of composite human activities through context-free grammar based representation[C]∥2006 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). New York:IEEE,2006:1709-1718.
[12]ZHANG Z.Microsoft kinect sensor and its effect[J].IEEE Multimedia,2012,19(2):4-10.
[13]苏竑宇,陈启安,吴海涛.基于 SVM 和 HMM 二级模型的行为识别方案[J].计算机与现代化,2015,5:1-8.
[14]XIE L,PAN W,TANG C,et al.A pyramidal deep learning architecture for human action recognition[J].International Journal of Modelling Identification and Control,2014,21(2):139-146.
[15]AKSOY E E,ABRAMOV A,WORGOTTER F,et al.Categorizing object-action relations from semantic scene graphs[C]∥2010 IEEE International Conference on Robotics and Automation (ICRA).Anchorage,AK:IEEE,2010:398-405.
[16]FAN H,CAO Z,JIANG Y,et al.Learning deep face representation[EB/OL].[2014-03-12].http:∥arxiv.org/abs/1403.2802.
A Hierarchical Approach Based on Deep Learning for Human Interactive-action Recognition
YIN Kunyang,PAN Wei,XIE Lidong,XU Suxia*
(Fujian Key Lab of Brain-like Intelligent Systems,School of Information Science and Engineering,Xiamen University,Xiamen 361005,China)
Abstract:This paper discusses the recognition of interaction-level human activities with a hierarchical approach.We classify human activities into four categories:pose,atomic action,composite action,and interaction.In the bottom layer,a new pyramidal stacked de-noising auto-encoder is adopted to recognize the poses of person with high accuracy.In the middle layer,the hidden Markov models (HMMs) of atomic actions are built, and evaluation demarcation algorithm is proposed to detect atomic actions and speed up calculations.In the top layer,the context-free grammar (CFG) is used to represent and recognize interactions.In this layer,a new spatial predicate set is proposed and face orientation is introduced to describe activities.We use Kinect to capture activity videos.The experimental result from the dataset shows that the system possesses the ability to recognize human actions accurately.
Key words:human action recognition;deep learning;hidden Markov model (HMM);context-free grammar (CFG);Kinect
doi:10.6043/j.issn.0438-0479.2016.03.019
收稿日期:2015-08-29录用日期:2015-11-20
基金项目:国家自然科学基金(60975084)
*通信作者:suxiaxu@xmu.edu.cn
中图分类号:TP 391
文献标志码:A
文章编号:0438-0479(2016)03-0413-07
引文格式:尹坤阳,潘伟,谢立东,等.一种基于深度学习的人体交互行为分层识别方法.厦门大学学报(自然科学版),2016,55(3):413-419.
Citation:YIN K Y,PAN W,XIE L D,et al.A hierarchical approach based on deep learning for human interactive-action recognition.Journal of Xiamen University(Natural Science),2016,55(3):413-419.(in Chinese)
