一种改进的链路预测好友推荐方法
2016-06-20杜亚军孟庆瑞
付 霞,杜亚军*,吴 越,孟庆瑞
(1.西华大学计算机与软件工程学院,四川 成都 610039;2.西藏飞跃智能科技有限公司,西藏 拉萨 850000)
一种改进的链路预测好友推荐方法
付霞1,杜亚军1*,吴越1,孟庆瑞2
(1.西华大学计算机与软件工程学院,四川 成都610039;2.西藏飞跃智能科技有限公司,西藏 拉萨850000)
摘要:为从海量用户中筛选出与目标用户相似度最高的用户作为好友进行精确推荐,提出一种链路预测好友推荐算法。通过用户之间的链路关系推荐出与目标用户相似性最高的Top-N个用户;分别计算目标用户与这Top-N个用户之间的标签相似性以及共同好友相似性,并对其分别赋予相应的权值;根据权值计算目标用户与其他用户之间的综合相似度;对综合相似度进行排序,为目标用户推荐出与其相似度最高的用户。以腾讯微博用户推荐为例进行实验,结果表明,该推荐算法的精确率比单一链路预测算法高8%。该算法能在一定程度上提高好友推荐的准确率。
关键词:在线社交网络; 链路预测;朋友推荐; 相似度; 标签
1研究现状
随着Internet技术的快速发展,以微博为代表的在线社交网站日益成为人们日常交流、娱乐、通信的重要平台,其用户规模也与日俱增。例如国外的Facebook、Twitter,以及国内的豆瓣、新浪微博、人人网等都拥有数亿用户,并将持续增加。在这些在线社交网站上,用户不仅把现实生活中的人际关系搬到网络上,而且根据个人的兴趣爱好建立了与线下无关的单纯的线上朋友关系。在线社交网站和现实生活类似,在没有好的推荐方法下是很难找到好朋友的[1];因此,在庞大的社交网站中,用户选择添加哪些用户作为自己的好友成为了一个难题。社交网站中的好友推荐系统就是针对这一问题而提出的。
针对好友推荐问题,国内外研究者提出了许多相关算法[1-17],主要有基于链路预测算法和协同过滤算法等。
链路预测[2]方法的基本思想是针对2个未建立链接的节点,若它们的邻节点的集合有大量重合部分,这2个节点在未来某时刻建立链接的可能性就很大。D.Liben-Nowell等[3]提出了一种最早的社交网络链路预测模型,其实验证明了节点间的未来交互是可以通过监视邻居节点来提取的。傅颖斌等[2]提出了基于链路预测的微博用户关系分析方法。P.Alexis等[4]通过一种快速的链路预测方法来推荐好友,该算法能很好地为目标用户推荐出线下认识的好友以及关系较强的好友,提高了推荐算法的精确度。Michael等[1]提出一种“你可能认识的人”的算法,该算法可以克服社交网络图过于庞大的困难,保持图的实时更新,同时可以利用该图产生好友推荐,对大数据量的图结构有了高效率的遍历和搜索。FoF(friend-of-friend)算法[5-8]的思路是利用朋友关系的传递性为目标用户推荐好友。FoF方法认为在一个庞大的社交网络上,若2个独立的节点之间存在越多的共同节点,则这2个节点在将来就有更高可能性建立链接。
协同过滤算法在推荐系统中得到了广泛的应用。Typestry是最早提出来的一个基于协同过滤算法的推荐系统,它要求目标用户需要明确指出与自己兴趣爱好相似的其他用户[9]。针对用户规模的增加,文献[10-11]加入用户曾经使用过的项目属性,提出基于用户聚类的协同过滤推荐算法,该算法在一定程度上缩小了近邻用户搜索范围;但由于缺少对目标用户的兴趣分析,聚类会丢失部分用户数据。文献[12]充分利用标签信息,采用标签共生分布来计算标签相似度。张杨[13]在经典的推荐系统的基础之上,给出一个基于标签的双向协同过滤模型DCMu,通过社会化标签,将用户的已评分项目分为正向(喜欢)和负向(厌恶)2大类,并在用户初始模型的基础上计算正反用户之间的相似关联性。胡文江等[14]采用好友之间的关系推荐和喜好标签的相似度推荐相结合的方法,提出了一种改进的推荐算法。张怡文等[15]提出一种基于共同用户和相似标签的协同过滤算法,抽取共同关注用户作为共同项目,加入体现用户兴趣的自定义标签数据。这类基于标签或共同好友数的方法虽然能有效地得到用户的兴趣等信息;但由于目前的语义相似度计算存在较大误差,如果仅仅依据标签等属性指标计算用户之间的相似度,会导致推荐结果误差较大。
虽然基于协同过滤的推荐系统在现实中得到了广泛的应用,但协同过滤推荐技术仍存在精确度低、数据稀疏[16]、冷启动[17]和可扩展[18]等问题。
为解决链路预测不能很好地描述用户本身的兴趣和特征的缺点以及协同过滤算法的数据稀疏问题,提高好友推荐准确率,本文提出了一种结合链路预测和标签等属性的改进的链路预测好友推荐算法。
2相关工作
2.1社交网络关系图
本文要实现的朋友推荐算法采用腾讯微博的数据作为数据集。通过调用腾讯微博开放平台所提供的API[19]获取数据,通过朋友之间的链接关系构建与种子账号相关的社交网络关系。在腾讯微博中,每个账号都有“偶像”与“听众”2种关注与被关注的形式,假设有账户A、B,他们有如下几种关系:1)A是B的偶像,即B是A的听众;2)A是B的听众,即B是A的偶像;3)A与B相互收听;4)A与B没有直接的收听关系。用户与用户之间在社交网络图中用有向图来表示用户间的收听关系。
社交网络关系图定义为G=(V,E)表示所构建的社交网络关系图,其中V表示社交网络关系图中的所有朋友节点的集合,E表示所有边的集合。e=(vi,vj)表示从vi指向vj的有向边,vi的偶像是vj,其中e∈E,表示节点间的收听关系,vi,vj∈V,表示节点集中的2个朋友节点。
2.2基于链路预测的朋友推荐算法
用sim1(vx,vy)来表示社交网络图中的vx、vy2个节点之间的相似度,其计算公式[4]为
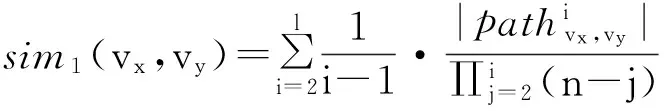
(1)
2.3基于标签和共同好友数的推荐算法
在本文中,对标签和共同好友数相似性均采用杰卡德相似系数计算。杰卡德相似系数是用于比较有限样本集合的相似性和差异性的统计量[20]。2个集合A和B交集元素的个数在A、B并集中所占的比例,称为这2个集合的杰卡德系数,用符号J(A,B)表示。其公式为
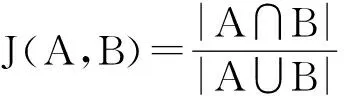
(2)
如果集合A、B均为空集,定义J(A,B)=1。显然0≤J(A,B)≤ 1。J值越大,2个样本的相似度越大。
3改进的链路预测好友推荐算法
本文首先根据用户之间的链路关系,通过单一的链路预测算法推荐出与目标用户相似性最高的Top-N个用户;接着通过标签相似算法和共同好友算法分别计算目标用户与这Top-N个用户之间的标签相似性和共同好友相似性,并为它们赋予相应的权值,从而计算目标用户与其他用户之间的综合相似度;最后对综合相似度进行排序,为目标用户推荐出与其相似度最高的用户。
3.1基于链路预测算法的伪代码
根据式(1),将基于链路预测的朋友推荐算法的伪代码表示如下。
input:局部社交网络中的节点集合,其中隐含了链接关系,vij∈V表示第i层的j节点;局部社交网络中朋友链接的最大长度l;局部社交网络中节点总数n。
output:局部社交网络中各节点与种子节点之间的相似度集合。
Begin
Step1:在种子用户及其直接朋友的基础上构建朋友链长最多为2的局部社交网络SN2
fork=1ton//计算链路长度为2的节点与种子节点的相似度
end for
Step2:在SN2的基础上构建朋友链长最多为3的局部社交网络SN3
fork=1ton//计算链路长度为3的节点与种子节点的相似度sim1
end for
End
3.2基于标签的好友推荐算法
3.2.1标签推荐算法的思想
标签所表示的是用户的兴趣爱好。将这些标签作为关键字,并以此来组成用户标签的偏好向量。在做推荐的时候,将目标用户的标签和其他用户的标签进行相似度的比较,将相似度高的用户推荐给目标用户。
在腾讯微博中,每个用户都可以为自己添加不同的标签来表示自己的兴趣和爱好。将用户的标签用一个列表表示,每个列表对应一个用户及其标签。用户A的标签列表可以表示为UAT={〈A,tag1〉,〈A,tag2〉,〈A,tag3〉,…,〈A,tagn〉},用户B的标签列表可以表示为UBT={〈B,tag1〉,〈B,tag2〉,〈B,tag3〉,…,〈B,tagn〉}。如果要计算用户A、B之间的相似度,只需要通过计算他们标签之间的相似度来间接计算他们之间的相似度。如果用户间的标签相似度越高,那么在社交网络中他们就越有可能成为好友,这里称为兴趣最相似的好友。其公式为:
(3)
其中t1,t2分别为2个用户的标签,如果2个标签相同,值为1,否则为0。根据式(2),用户间的标签相似性计算公式为
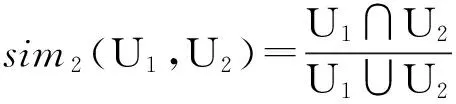
(4)
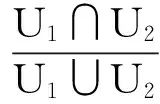
3.2.2标签推荐算法伪代码
Input:所有的朋友节点n的标签列表,种子节点A的标签列表。
Output:节点与种子节点的相似度。
BEGIN:
For 所有朋友节点 do
计算节点的标签与种子节点标签相同的个数
End for
计算节点与种子节点的相似度
Return sim2
End
3.3基于共同好友数的好友推荐算法
3.3.1共同好友推荐算法思想
不管是在社交网络还是现实生活中,人们一般可以通过朋友的朋友来认识新的朋友。本文主要通过计算用户与目标用户之间共同关注的人的数量来衡量2个用户之间的相似度。2个用户共同关注的人所占比例越多,那么他们就越有可能成为朋友。目标用户A关注的人的集合A={UA1,UA2,UA3,…,UAn},用户B关注的人的集合B={UB1,UB2…,UBn},然后计算A和B集合中共同的粉丝数。其计算公式为:
(5)
其中UAi,UBi分别表示A、B集合中的粉丝,如果2个用户UAi,UBi相同,则值为1,否则值为0。根据式(2),基于共同好友数的相似度计算公式为
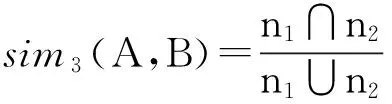
(6)

3.3.2共同好友推荐算法伪代码
Input:所有的朋友节点n的朋友列表,种子节点A的朋友列表。
Output:节点与种子节点的相似度。
BEGIN:
For 所有朋友节点 do
计算节点的朋友与种子节点朋友相同的个数
End for
计算节点与种子节点的相似度
Return sim3
End
3.4改进的链路预测好友推荐方法
3.4.1算法思想
结合基于链路预测、标签相似和共同好友相似的算法,构造本文的推荐方法。其相似度公式为
Sim=psim1+qsim2+(1-p-q)sim3。
(7)
式中:p、q是权值参数,p表示基于链路预测推荐算法的权重,q表示基于标签相似算法的权重;sim1表示用户在基于链路预测推荐算法下与目标用户的相似度;sim2表示用户在基于标签相似算法下与目标用户的相似度;sim3表示用户在基于共同好友数相似算法下与目标用户的相似度。在实验过程中通过分析p、q采用不同值对推荐结果的影响,不断修改参数值使得推荐效果最佳且收敛。Sim即为用户与目标用户之间的综合相似度。取出Top-N个Sim作为推荐对象。
3.4.2算法伪代码
改进的推荐算法伪代码实现如下。
input:数据集。
output:推荐好友列表。
Begin
Step1:循环利用式(1),计算用户x,y之间的链路预测相似度sim1。
Step2:根据sim1的值输出好友列表Top-N进入下一阶段。
Step3:循环利用式(4)计算Top-N好友和目标用户的标签相似度sim2。
Step4:循环利用式(6)计算Top-N好友和目标用户的共同好友相似度sim3。
Step5:输入p、q的值。
Step6:循环利用式(7)得到最终的相似度Sim。
Step7:输出推荐的好友列表。
End
4实验结果与分析
4.1实验环境
硬件配置为内存2 GB、硬盘230 GB、网卡10/100 M。软件配置为操作系统Windows 7、数据库SQL SERVER 2008 R2、开发工具VS 2010。
4.2数据集
实验中的数据是通过调用腾讯微博开放平台所提供的API[20]来获取的,在实验过程中采用以授权用户为种子用户爬取与该用户直接、间接相关的其他朋友账户的信息并存入数据库,实验中共爬取了3层朋友信息,并将这些信息存放到数据库中。其中部分信息如表1—3所示。AllTheName表记录所用的相关用户的基本信息。Sim表记录相关用户与目标用户之间的相似度。RecommendFriendsDetialInfo表记录推荐好友的相关信息。

表1 AllTheName表

表2 Sim表
表3 RecommendFriendsDetialInfo表
4.3实验过程
在本文的推荐系统中,当用户点击推荐朋友按钮之后,会将与目标用户相似度最高的前50名用户按相似度降序排列显示在页面中,如图1所示。

图1 好友推荐
4.4实验评价指标
本文主要采用精确率、召回率来评价实验结果。精确率(P)为相关用户在Top-N个被推荐用户中的比例。召回率(R)为Top-N个推荐用户中相关用户的数量在总用户中的比例。文中的相关用户是指目标用户可能添加为好友的用户。
4.5实验结果
分别选择相似度高的前10、20、30、40、50名用户作为推荐对象,并在2种推荐算法下对推荐结果进行统计,其结果如表4所示。
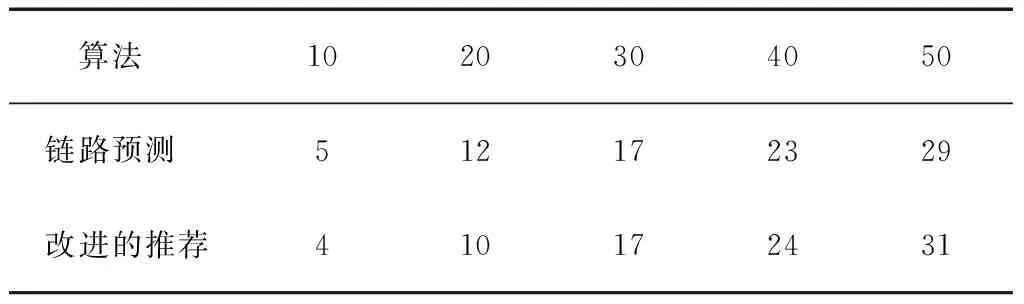
表4 推荐结果统计
根据表4的相关数据,分别计算了2种算法的精确率和召回率。图2—3示出2种算法在各种情况下的精确率和召回率。
P(单一链路预测)=58%;
P(改进的链路预测)=62%;
R(单一链路预测)=7.47%;
R(单一链路预测)=7.99%。
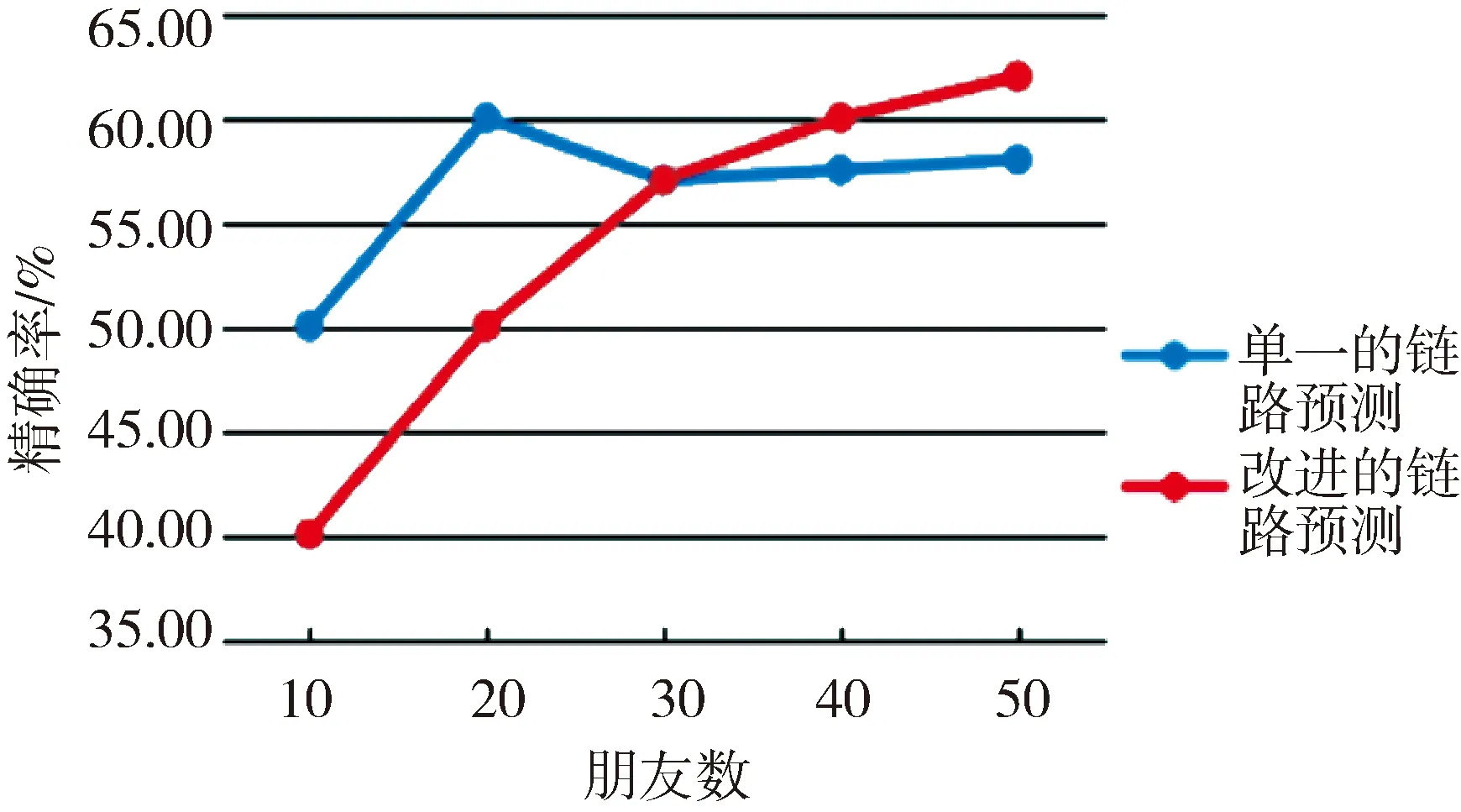
图2 精确率对比
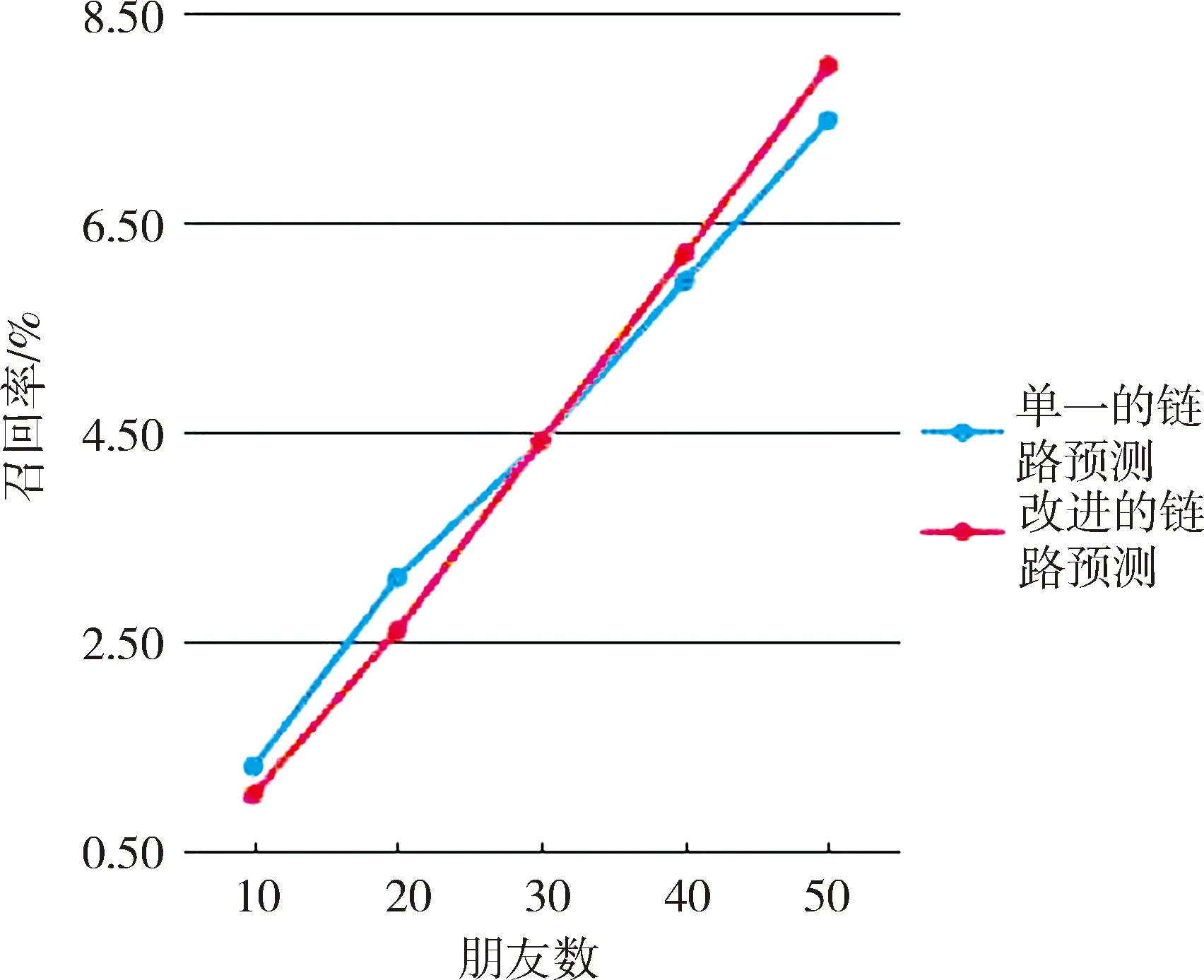
图3 召回率对比
可以看出,改进的链路预测算法能准确地向用户推荐新的好友,随着推荐用户数的增加,改进的链路预测算法的精确率和召回率都比单一的链路预测算法好,其中精确率比单一的链路预测算法高8%。
在实验的过程中笔者为权值参数p、q赋予不同的值会出现不同的推荐结果。例如当p=0.2,q=0.4时算法的精确率只能达到34.56%,远远达不到预期目标。通过多次实验比较与分析,得出p=0.8,q=0.1时实验结果最佳。
5总结与展望
本文在链路预测算法的基础上加入标签相似度和共同好友相似度,提出一种新的好友推荐算法。实验结果表明,本文的推荐算法解决了链路预测不能很好地描述用户本身的兴趣和特征的缺点以及协同过滤算法的数据稀疏问题,与单一的链路预测推荐算法相比,改进的链路预测算法能更好的为用户推荐出好友,提高了推荐的精确率。
实验中仍然存在着一些问题,由于腾讯微博中微博用户的兴趣标签比较少,造成了一定的数据缺失,这对权重的赋值有一定的影响。在接下来的工作中,希望能考虑更多的因素,使推荐效果更好。
参考文献
[1]Michael M, Dosbayev Y, Berlyant M. PYMK: Friend Recommendation at Myspace [C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data. New York, NY, USA: ACM, 2010: 999-1002.
[2]傅颖斌,陈羽中.基于链路预测的微博用户关系分析[J].计算机科学,2014,41(2):201.
[3]Liben-Nowell D,Kleinbe J. The Link-prediction Problem for Social Networks[J].Twelfth International Conference on Information and knowledge Management, 2003, 58(7):556.
[4]Alexis P, Panagiotis S ,Yannis M.Fast and Accurate Link Prediction in Social Network Systems[J].The Journal of Systems and Software,2012,85:2113.
[5]Chen Jilin, Werner Geyer, Casey Dugan, et al. Make New Friends, but Keep the Old: Recommending People on Social Networking Sites[C]//Proceedings of the SIGCHI Conference on Human Factors in Computing Systems.[s.l.]:ACM,2009:201-210.
[6]郑佳佳. 社交网络中基于图排序的好友推荐机制研究与实现 [D]. 杭州:浙江大学,2011 .
[7]Official Facebook Blog[EB/OL].[2015-09-09].http://blog.facebook.com/blog.php?Post=136103112130,2014.
[8]Joonhee K, Sungrim K. Friend Recommendation Method using Physical and Social Context [J]. International Journal of Computer Science and Network Security, 2010, 10(11): 116.
[9]Goldberg D, Nichols D, Oki BM, et al. Using Collaborative Filtering to Weave an Information Tapestry[J].Communications of the ACM, 1992, 35(12):61.
[10]王辉,高利军,王听忠.个性化服务中基于用户聚类的协同过滤推荐[J].计算机应用,2007,27(5):1225.
[11]黄国言,李有超,高建培.基于项目属性的用户聚类协同过滤推荐算法[J].计算机工程与设计,2010,31(5):1038.
[12]陈毅波,揭志忠,吴产乐.基于同义标签分组的协同推荐[J].湖南大学学报(自然科学版),2011,38(5):83.
[13]张杨.一种基于标签的双向协同过滤模型[D]. 长春:吉林大学, 2013.
[14]胡文江, 胡大伟, 高永兵,等. 基于关联规则与标签的好友推荐算法[J]. 计算机工程与科学, 2013, 35(2):109.
[15]张怡文, 岳丽华, 张义飞,等. 基于共同用户和相似标签的好友推荐方法[J]. 计算机应用, 2013, 33(8):2273.
[16]Sarwar B M,Karypis G ,Konstan J A,et al.Application of Dimensionality Reduction in Recommender System-A case study[C]// KDD Workshop on Web Mining for E-Commerce Challenges and Opportunities.Boston,MA:ACM,2000:82-90.
[17]Massa P,Avesani P.Trust-aware Collaborative Filtering for Recommender Systems [J].Lecture Notes in Computer Science,2004,3290:492-508.
[18]Vincent S-z,Boi Fahings.Using Hierarchical Clustering for Learning the Ontologies used in Recommendation Systems[C]//Proceedings of the 13th ACMSIGKDD International Confer-ence on Knowledge Discovery and Data Mining.San Jose,California,United States:ACM,2007:599-608.
[19]腾讯开放平台[EB/OL].[2015-08-10].http://wiki.open.qq.com/wiki/API文档.
[20]Wikipedia.Jaccard index [EB/OL].[2015-08-10].https://en.wikipedia.org/wiki/Jaccard_index.
(编校:饶莉)
A Modified Friend Recommending Method Based on Link Prediction
FU Xia1, DU Yajun1*, WU Yue1, MENG QingRui2
(1.SchoolofComputerandSoftwareEngineering,XihuaUniversity,Chengdu610039China;2.TibetFeiyueIntelligentTechnologyCo.,Ltd.,Lasa850000China)
Abstract:In order to select user who has the highest similarity with target user as a friend from the mass of the users, a modified friend recommending method based on link prediction is proposed in this paper. Firstly, through the links relationship, the Top-N users who have the highest similarity with the target user are recommended. Secondly, calculating the tag similarity and the common friends similarity between the target user and recommended Top-N users. Thirdly, giving appropriate weight to them,and calculate comprehensive similarity between target users and the recommend Top-N users. Finally, sorting users based on comprehensive similarity, and recommending the users who have the highest similarity to the target users. The experimental results show that the algorithm in this paper is higher than the single link prediction by 8% on accuracy.
Keywords:OSN; link prediction;friends recommendation; similarity; target
收稿日期:2015-08-14
基金项目:国家科技支撑计划项目西藏自然科学博物馆数字馆关键技术研究及集成示范 (2011BAH26B01);国家自然科学基金(61472329)。
*通信作者:杜亚军(1967—),男,教授,博士,主要研究方向为网络信息获取与处理。E-mail:duyajun@mail.xhu.edu.cn
中图分类号:TP181;TP391.3
文献标志码:A
文章编号:1673-159X(2016)03-0045-6
doi:10.3969/j.issn.1673-159X.2016.03.010
·计算机软件理论、技术与应用·
