云环境下海量方剂组方规律分析 *
2016-06-05窦鹏伟佘侃侃
窦鹏伟,王 珍,佘侃侃
(南京中医药大学信息技术学院 南京 210023)
云环境下海量方剂组方规律分析 *
窦鹏伟,王 珍**,佘侃侃
(南京中医药大学信息技术学院 南京 210023)
目的:结合云计算技术对海量方剂数据进行关联分析,揭示其内在的组方规律。方法:研究云环境下分析海量数据的关键技术,构建方剂组方数据的指标体系,结合MapReduce编程模型对Apriori算法进行改进,设计并利用基于云计算的海量方剂组方规 律分析平台对方剂数据进行关联分析。结果:以海量方剂组方数据 为例,探索方剂组方的一般规律,得出方剂药物间和症状与药物间的关联关系。结论:研究结论与实际应用相符,在一定程度上揭示了病证方药的内在规律,可以为临床病证辨证论治、遣药组方提供依据。在计算效率方面,云平台具有明显优势。
云计算 MapReduce 方剂组方规律 Apriori算法
方剂是中医药临床实践的原始记录,是经历了几千年积累的庞大数据集合,是宝贵的中医药资源和人类财富。据不完全统计,截止晚清的历代古方有近10万首。随着中医药事业的不断发展和古文献资料的研究挖掘,越来越多的珍贵方剂被发现和认可。面对纷繁复杂的海量方剂数据,如何对其进行有效解析,准确揭示其内在的组方规律,又是一项巨大挑战。
目前,最常用的研究方剂组方规律的科学方法是数据挖掘技术。通过对方剂数据进行特征、分类、聚类、趋向、偏差和特例现象的深层多维分析,来揭示“方-药-证”的复杂特殊关系,发现其隐含 的规则、模式和规律[1]。随着中医药方剂数量的与日俱增,传统的基于单一节点的数据挖掘模式已不能快速准确地完成海量方剂数据的分析与挖掘,而利用云计算技术能获取网络中强大的计算资源,将方剂组方规律分析中需要消耗大量计算资源的复杂计算通过网络分布到多节点上计算的方式成了新的有效解决方案[2]。云计算将计算任务发布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算能力、存储空间和各种软件服务,通常涉及的是动态易扩展的虚拟化资源[3]。
1 云环境下的MapReduce编程模式
计算能力取决于硬件计算资源,计算能力不足时需要增加硬件资源,冗余时就会造成硬件资源的浪费。因此,计算能力的获取和使用上存在着较大的制约。云计算正是用来解决这一问题的新的计算服务模式,其基本思路是集中计算资源来提供巨大的计算能力。目前最常用的并行计算模型是由谷歌公司提出的MapReduce编程模式。
MapReduce是一种新型的处理海量数据的编程模式,主要用于大规模数据并行计算。MapReduce为用户提供了分布式的文件系统,让用户能够方便快捷地处理大规模数据。在MapReduce编程模式中,所有的程序运算都被抽象为Map和Reduce这两个基本操作,在Map阶段,计算被分解成更小规模的计算,并在集群的不同节点上执行;在Reduce阶段,结果被逐步归并汇总。MapReduce编程模式借鉴的是函数式程序设计语言Lisp的思想,定义了Map和Reduce两个抽象的程序接口,由用户自主实现:① Map:(k1;v1)→[(k2;v2)];② Reduce:(k2;[v2])→[(k3;v3)]。
MapReduce的执行由两种不同类型的节点负责,Master和Worker。Master节点负责任务的调度和不同节点间数据的共享,Worker节点负责数据的处理。如图1,具体过程如下[4]:
①启动计算机集群,利用MapReduce提供的函数库将输入数据切分为N份;
②Master节点找出空闲的Worker节点,为其分配子任务;
③空闲的Worker节点获得Map子任务后读入相应的输入数据,并解析输入数据的key/value对,然后调用用户编写的Map函数进行数据的分析与计算;
④Map函数的中间结果缓存在内存中并周期性地写入本地磁盘;中间结果的地址会发送给Master节点,Master调用负责Reduce任务的Worker节点对中间结果进行Reduce处理;
⑤空闲的Worker节点分配到Reduce子任务后通过遍历获得Map子任务产生的中间结果,将不同的key和value进行结合,并作为参数传递给用户编写的Reduce函数进行处理;
⑥Reduce函数的处理结果被写入到一个最终的输出文件。当全部的Map子任务和Reduce子任务都完成后,Master节点将全部的Reduce结果返回给用户程序。用户程序对节点返回的结果数据再次进行合并,从而得到最终结果。
2 基于云计算的海量方剂组方规律分析平台的设计与实现
2.1 系统架构
基于云计算的海量方剂组方规律分析平台有3类节点,如图2。主控节点负责调度和协调计算节点间的工作进程,进行任务分配和算法调用,并接收计算节点返回的结果;数据节点负责存储海量方剂数据;计算节点根据任务单元中的数据源信息从数据节点中获取方剂数据,以主控节点指定的算法进行配伍规律挖掘,并把结果返回给主控节点。
2.2 方剂组方数据仓库指标体系

图1 MapReduce运行模型

图2 基于云计算的方剂组方规律分析平台

表1 方剂组方数据仓库指标体系
方剂组方数据具有多层关联结构,如药-药、药-症、药性-炮制、功效-主治、原方-加减方、加减方-变症等。其中,“证-药-方”是核心,针对“证”,选用“药”,配制“方”。而证又是由若干证候组成的,药包含性味、归经、功效,方则存在复杂的组配关系及加减变化。本文认为,要想准确揭示方剂组方规律,必须针对“证”、“药”、“方”建立合理的指标体系,指标体系的建立是进行预测或评价研究的前提和基础。
通过咨询数名相关领域专家和查阅大量文献资料[5,6],建立了方剂数据的一级指标因素集U={U1[类方],U2[主治证型],U3[证候],U4[组方],U5[用法],U6[禁忌]},如表1所示。然后依次建立了二级指标因素集U1={解表剂,祛暑剂,……,固湿剂},U2={风寒束表证,肺脾气虚证,……,肺肾两虚证},U3={恶寒,发热,……,咳嗽},U4={麻黄,芍药,……,川芎},U5={煎服,共研细末,……,外敷},U6={十八反,十九畏,……,服药禁忌}。
在方剂指标体系下,为了使海量数据更好地满足数据挖掘的要求,建立了星型的方剂数据仓库,如图3所示,其中包含方剂主库、主治证型库、证候库、药物库、用法库和禁忌库,各数据库间以线性或非线性关系相互关联。
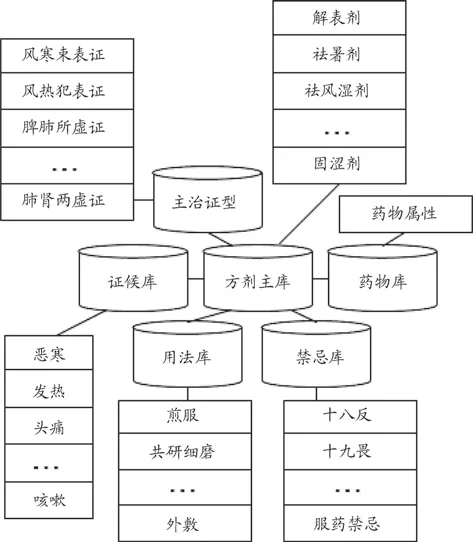
图3 云环境下的方剂组方数据仓库模型
2.3 基于云计算的海量方剂组方规律分析算法
数据挖掘技术在方剂研究特别是组方规律分析方面发挥着巨大的作用,其主要研究方法有分类、聚类[7-9]、关联规则[10-12]、神经网络[13-16]等,常见的算法有Apriori[17]、FP-Growth[18,19]、粗糙集理论[20-22]等。基于云计算的海量方剂组方规律分析平台采用改进的Apriori算法进行方剂药物间的关联规则分析。
2.3.1 Apriori算法
Apriori算法[23,24]是Agrawal和R.Srikant于1994年提出,是最有影响的挖掘布尔关联规则频繁项集的算法之一。Apriori算法挖掘最大频繁项集的基本思想是:首先找出事务中所有的频集,这些频集出现的频繁性需要满足预先设定的最小支持度;随后由频集产生强关联规则,这些规则必须满足最小支持度和最小置信度[25]。
在方剂组方规律研究中,将最小支持度(support)的阙值设为7%,最小置信度(confidence)的阙值设为60%。规则A=>B(其中A和B是项目的集合)的支持度和置信度分别定义为:
support(A=>B)=P(AUB); confidence(A=>B)=P(B|A)。
Apriori算法采用迭代的方式对数据集进行逐层搜索[26],主要步骤为:
①简单统计一个元素项集的出现频数,找出不小于最小支持度的项集,即一维最大项集。
②从第二步开始进行递归处理,直到没有最大项集产生。递归处理的方法是:在第k步中,根据第k-1步生成的k-1维最大项集构造k维候选项集,然后对数据仓库进行搜索,计算得到候选项集的支持度,通过与设定的最小支持度比较,确定是否是k维最大项集。
2.3.2 基于Map函数的Apriori算法
在经典的Apriori算法中,设N表示方剂数据仓库的总数据量,T表示最大的药物组方,Ln表示频繁n项集。第一次扫描数据仓库的时间为在后面的每一步中,连接消耗时间为剪枝消耗时间为扫描计数消耗时间为故有总时间消耗为
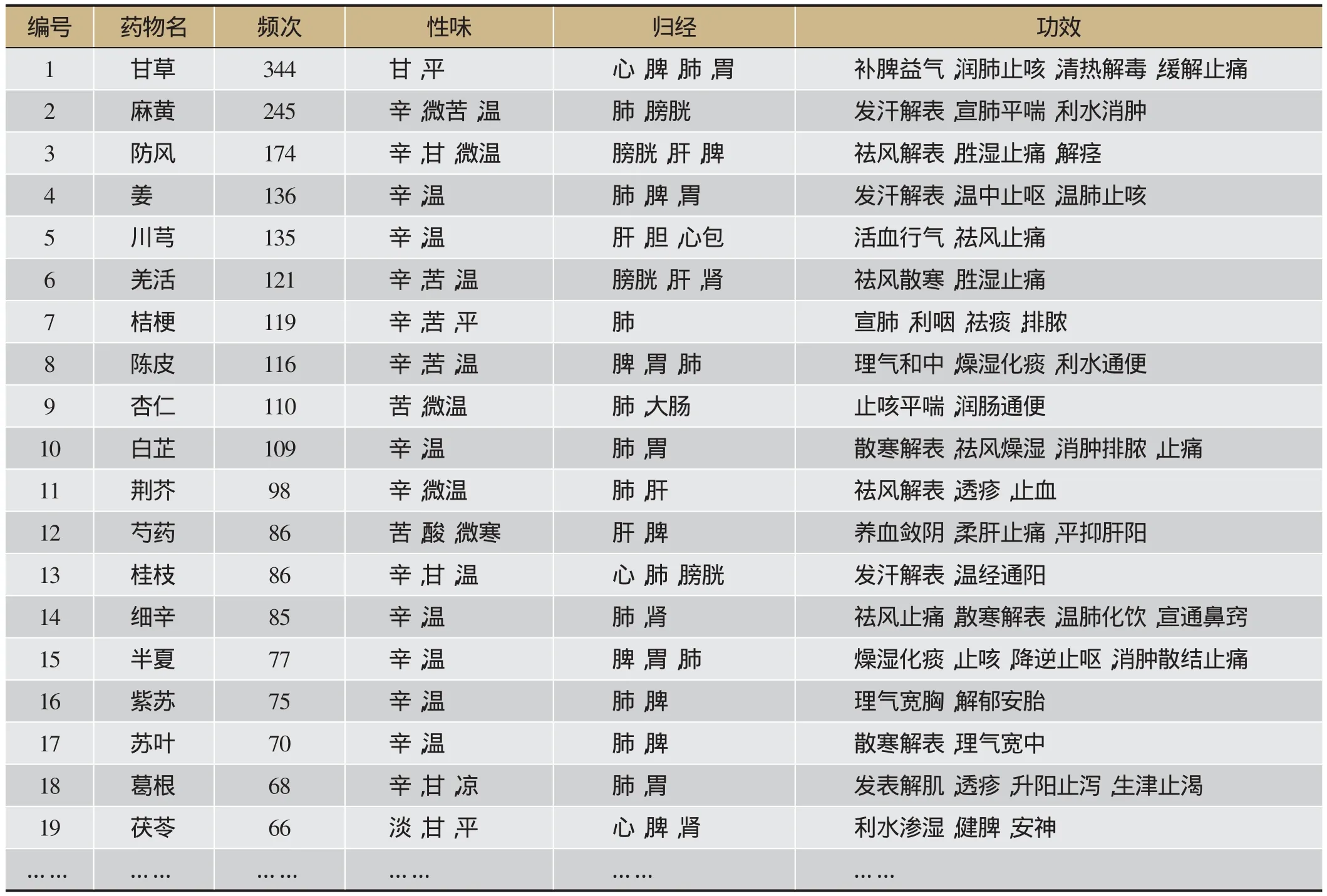
表2 基于频次的药物重要性分析
根据以上分析可知,在频繁2项集和频繁3项集的生成及其候选频繁项集的计数连接过程中有很大的时间消耗。针对传统的Apriori算法在海量方剂数据挖掘中时间消耗大、系统响应速度慢等问题,提出了云环境下基于Map函数的Apriori算法,通过给每个节点都附带Map程序,从而达到减少连接次数和扫描时间、降低时空消耗的目的,使得算法性能显著提高。
基于Map函数改进的Apriori算法伪代码如下:
F1=find_1_itemsets(d);//局部频繁1项集
for(k=2;Lk-1≠Φ;k++){
Ck=apriori_gen(Fk-1,d);//扫描数据库,计算t的支持度
for each transaction t∈dC1=subset(Ck,t);
for each candidate c∈C1
c.count++;}
generate pair <c,c.suppprt>
end for
return U <c,c.support> //返回支持度
3 方剂组方规律挖掘方法及实验结果分析
3.1 方剂组方规律挖掘方法
为了保证数据的准确性、可靠性和完整性,特选取《中医方剂大辞典》中的数10万首方剂作为数据来源。实验所采用的数据集是以风寒束表证为主治证型的1 240条辛温解表剂。
第一步,根据方剂组方数据仓库的一级指标,将1 240条辛温解表剂与“药物库”进行交叉比对,得到基于频次的药物重要性分析结果,如表2所示,共涉及438种药物。
第二步,将1 240条辛温解表剂与“证候库”交叉比对,进行证候指标抽取,并进行相应的证候频次统计,结果如表3所示。
第三步,将症状与药物进行云环境下的关联分析,得到药-药间的组方规律和症-药间对应关系,见表4、表5。
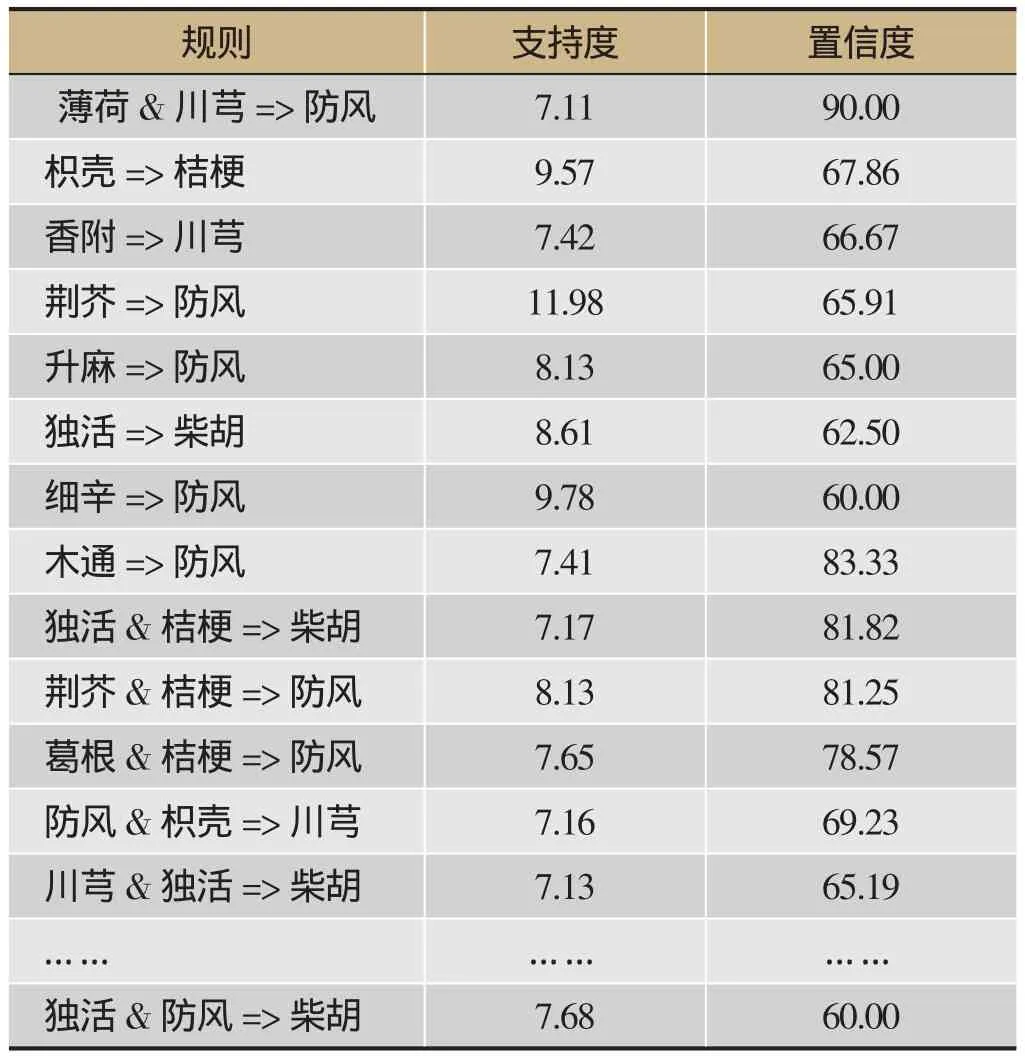
表4 药物间的关联关系/%(支持度≥7%,置信度≥60%)

表5 症状与药物间的关联关系/%
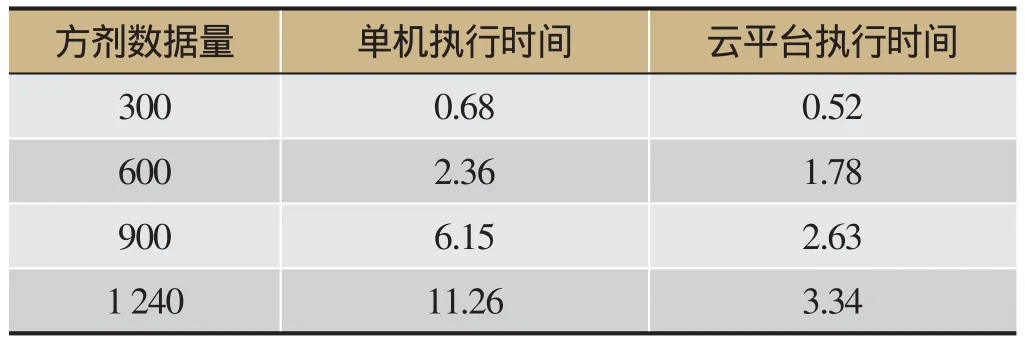
表6 执行时间对比/s
3.2 实验结果分析
分析表2、表3可以发现,甘草、麻黄、防风、川芎等药物在辛温解表剂中使用频繁,是主要用药;恶寒、恶风、头痛、发热、咳嗽、脉浮紧等症状在风寒束表证中出现的频次较高,为主要症状。
分析表4可以发现辛温解表剂中的常见药物组对,例如薄荷、川芎和防风是临床上治疗风寒束表证的一组基本药对。薄荷辛凉解热,川芎辛温香燥,防风辛甘微温,符合“君、臣、佐、使”、“寒温并用”的方剂配伍思想。
分析表5可以发现,恶寒、发热作为外感风寒的最基本症状,以桂枝、防风、川芎为主要用药,起到发汗解表的功效。而咳嗽大多由于风邪犯肺、肺气不宣而引起,与其相关的药物包括长于肃降肺气的杏仁、长于宣发肺气的桔梗、长于理气解表的紫苏和长于理气化湿的陈皮,多药配伍合用能够使肺气宣而有度、降而有节,卫阳营阴得以散布体表,抗御外邪,从而增强辛温解表的作用。针对痰饮症状,主要用药为陈皮、麻黄。当肌表受到邪气侵袭,肺的宣发肃降功能受到影响,导致津液输布失调,聚成而痰,故当使用理气药陈皮和宣肺药麻黄。以上结论均符合中医药方剂理论和临床实践,能够用于临床用药指导。
同时,云平台很好地体现了计算效率方面的明显优势,其执行时间远远少于单机执行时间,对比情况如表6所示。随着数据量的增大,云平台优势更加显著。
4 小结与展望
本文针对方剂研究中海量数据的存储问题和组方规律的挖掘问题,提出了在云环境下运用改进的Apriori算法对海量方剂数据进行分析的方法。该方法结合方剂组方数据仓库指标体系,将海量方剂数据存储在云环境中,然后在Map函数中利用改进的Apriori算法进行病证方药的关联规则的挖掘,既能够提高系统运算的效率,也能够保证挖掘结果的准确。实验证明了该方法的有效性,实验结果符合方剂配伍的实际应用,揭示了方剂配伍规律和方证对应关系。进一步工作是尝试配置响应速度快、负载均衡和高节点效率的云平台,进行多种方剂分析挖掘算法的比较研究,探寻适用于方剂组方规律研究的最优算法。
参考文献
1 蒋永光,胡波,刘娟,等.方剂配伍的数据挖掘可行性探索.四川中医, 2004, 22(8): 25-28.
2 程苗,陈华平.基于Hadoop的Web日志挖掘.计算机工程, 2011, 37(11): 37-39.
3 李勇.云计算对信息技术发展的影响.医学信息学杂志, 2010, 31(3): 1-5.
4 柯栋梁,郑啸,李乔.云计算:实例研究与关键技术.小型微型计算机系统, 2012, 33(11): 2321-2329.
5 蒋永光,李力,李认书,等.中医脾胃方配伍规律的数据挖掘试验.世界科学技术-中医药现代化, 2003, 5(3): 33-37.
6 佘侃侃,胡孔法,王珍.基于变精度容差粗糙集模型及属性敏感度约简的方剂配伍研究.世界科学技术-中医药现代化, 2014, 16(6): 1222-1228.
7 Ibáñez A, Larrañaga P, Bielza Cet al. Cluster methods for assessing research performance: exploring Spanish computer science.Scientometrics, 2013, 97(3): 571-600.
8 Jeong S, Choi J. The taxonomy of research collaboration in science and technology: evidence from mechanical research through probabilistic clustering analysis.Scientometrics, 2012, 91(3): 719-735.
9 Anil P, Jitendra A, Nishchol M. Analysis of different similarity measure functions and their impacts on shared nearest neighbor clustering approach.International Journal of Computer Applications, 2012, 16(2): 1-5.
10 Minaei Bidgoli B, Barmaki R, Nasiri M. Mining numerical association rules via multi-objective genetic algorithms.Inform Sciences, 2013, 233: 15-24.
11 Shaheen M, Shahbaz M, Guergachi A. Context base d positive and negative spatio-temporal association rule mining.Knowl-Based Sy st, 2013, 37: 261-273.
12 Jadav J J, Panchal M. Association rule mining method on OLAP cube.Int J Eng Res Appl, 2012, 2(2): 1147-1151.
13 Hinton G, Li D, Dong Y,et al. Deep neural networks for acoustic modeling in speech recogni tion.IEEE Signal Proc Mag, 2012, 29(6): 82-97.
14 Li J, Zhao R, Huang J,et al. Learning small-size DNN with outputdistribution-based criteria.Int erspeech, 2014, 6: 1910-1914.
15 Srivastava N, Hinton G, Krizhevsky A,et al. Drop out: A simple way to prevent neural networks from overfitti ng.J Mach Learn Res, 2014, 15(1): 1929-1958.
16 Rosenblatt F. The perceptron: a probabilistic model for information storage and organization in the brain.Psychol Rev, 1958, 65(6): 386-408.
17 陈连栋. Apriori算法在中医脾胃病方剂方面的研究.黑龙江科技信息, 2012, 2: 91.
18 刘闽碧.基于FP-Growth算法的中药配方数 据挖掘.医学信息, 2009, 22(12): 2629-2631.
19 董辉.基于改进FP-Growth算法的中药方剂配伍规律挖掘研究.赤峰学院学报(自然科学版), 2011, 27(9): 198-200.
20 张文东,李明壮,石小艳.基于粗糙集理论的属性约简算法.计算机工程与设计, 2008, 11(29): 95-97.
21 佘侃侃,胡孔法,王珍.基于加权变精度容差粗糙集模型的属性约简及应用研究.计算机科学, 2014, 41(11A): 351-353.
22 He X. Coefficient of variation and its applicati on to strength prediction of adhesively bonded Joints.International Conference on Measuring Technology and Mechatronics Automation, 2009: 602-605.
23 Rao S, Gupta R. Implementing improved algorithm over Apiori data mining association rule algorithm.International Journal of Computer Science And Technology, 2012, 3: 489-493.
24 Abu-Zanona A A, Jbara Y H, Al-Zawaideh F H. An improved algorithm for mining association rules in large databases.World of Computer Science and Information Technology Journal, 2011, 1(7): 311-316.
25 Erwin A,Gopalan R P,Achuthan N R. Efficient mining of high utility itemsets from large datasets. Springer Berlin Heidelberg,2008, 5012: 554-561.
26 Barber B, Hamilton H J. Extracting share frequent itemsets with infrequent subsets.Data Min Knowl Disc, 2003, 7(2): 153-185.
Analysis of Mass Prescriptions of Chinese Medicine in Cloud Environment
Dou Pengwei, Wang Zhen, She Kankan
(Institute of Information Technology, Nanjing University of Chinese Medicine, Nanjing 210023, China)
This study aimed to reveal the regularity of prescription data of tradition Chinese medicine (TCM) using cloud computing technology. Key technologies for analyzing massive data in the cloud environment were adopted. Then the index system of prescription data of TCM was set up. Combined with a programming model that named MapReduce, Apriori algorithm was improved in this study. And analysis platform for mining rules of massive prescription data were designed and used in association analysis. As a result, taking massive prescriptiondata for instance, general rules of prescriptions were explored; and the association links among prescription drugs, and incidence relation between symptoms and medicines were obtained. Experiment outcomes demonstrated that this conclusion was consistent with the actual application, which revealed the inherent discipline of diseases and prescriptions, and provided references for clinical diagnosis and prescription compatibility. In addition, cloud platform had obvious advantages in computational efficiency.
Cloud computing, MapReduce, regularity of prescription data, Apriori algorithm
10.11842/wst.2016.03.024
R289
A
(责任编辑:朱黎婷 张志华,责任译审:朱黎婷)
2015-09-25
修回日期:2015-12-07
* 国家自然科学基金委面上项目(81274095):中药挥发油成分与膜相互作用机制及专属膜制备基础研究,负责人:樊文玲;江苏省科技厅自然科学基金青年基金项目(BK20140958):多数据挖掘方法集成的方剂配伍规律挖掘模式设计与实现,负责人:佘侃侃;江苏省教育厅高校自然科学基金(14KJB520032):多数据挖掘方法集成的方剂配伍规律挖掘模式设计与系统实现,负责人:佘侃侃。
** 通讯作者:王珍,副教授,硕士生导师,主要研究方向:中医药大数据分析与挖掘、中医药信息系统与健康云建设。
