基于邻域的名词型数据分类方法
2016-06-01张本文孙爽博董新玲
张本文, 孙爽博,董新玲
基于邻域的名词型数据分类方法
张本文1*, 孙爽博2,董新玲2
(1.四川民族学院计算机科学系,四川康定 626001;2. 西南石油大学计算机科学学院,四川成都 610500)
基于邻域的分类器多用于处理数值型数据,本文提出针对名词型数据的规则生成及分类的技术。基于属性值定义对象的相似性度量,并由此获得每个对象的最大邻域;采用贪心策略依次选择邻域构建覆盖及对应的规则集;采用投票解决规则冲突。在四个UCI数据集上的实验结果表明,新方法的分类效果比ID3算法略好。
决策规则;分类器;邻域;覆盖约简
引言
分类是机器学习[1][2],数据挖掘[3]和模式识别[4]中的一个基本问题。分类即利用已知数据(训练集)获得知识,并对新的数据(测试集)的类别进行预测。分类算法有K近邻[5]、决策树[6]、逻辑回归、朴素贝叶斯、神经网络等。分类算法的应用领域非常广泛,包括银行风险评估、客户类别分类、文本检索和搜索引擎分类、安全领域中的入侵检测的应用等等。
基于邻域的分类方法已获得了国内外学者广泛关注。除了经典的K近邻[7]算法以外,还有Hu[8][9]等构造的基于邻域粗糙集模型的特征选择与规则生成算法来分类。邻域的定义有两种方法:其一是由邻域内所含对象的数量而定,如经典的K近邻;其二是根据在某一度量上邻域中心点到边界的最大距离而定,如Yao[10]等提出的邻域粗糙集模型。文献[11][12]通过随机化邻域属性约简,搜索一组分类精度较高的属性子集,在不同属性子集上采用邻域覆盖约简方法学习分类规则,文献[13]提出了基于邻域覆盖的规则学习分类方法。他们的邻域都是采用欧氏距离,比较直观且具有物理意义。而名词型数据的距离度量相对困难,因此未被考虑。
本文研究名词型数据的邻域,基于属性值定义了对象的相似性度量,并解决相应分类器构建和使用中的三个关键技术:规则生成、规则约简和冲突解决。首先为每个对象创建了最大邻域(或称覆盖块)来生成规则,每个覆盖块对应一条规则。这里的邻域与训练集中的对象密切相关,也就是前面提到的邻域的第二种定义。其次,通过采用贪心策略依次选择覆盖论域最大的覆盖块来约简规则。在测试阶测试阶段,测试样本完全有可能不满足通过训练学习的规则,也就会有一些测试样本无法分类,通过召回这一指标来衡量。最后在分类阶段采用简单投票的方法解决某个对象同时满足多条规则的情况。
将提出的方法应用于四个UCI数据集上,实验结果表明:将邻域的方法应用于名词型数据分类是可行的。随着训练规模的逐步增大,分类精度在多数数据集上表现良好,最后可以达到90%以上,并且也有很高的稳定性。召回指标在这些数据集中的表现也较好。综合考虑这两个指标,F1-measure值在Zoo这个数据集上是比ID3算法优秀的,Mushroom、Wdbc和Wine这三个数据集的性能和ID3基本相当。
1 相关概念
1.1 决策系统
决策系统广泛应用于数据挖掘和机器学习中。
定义1(决策系统)[14]:决策系统是一个三元组{,,}。这里是对象的非空有限集合,也叫做论域,是条件属性的集合,是决策属性的集合。
只讨论单一决策属性的名词型值的决策系统。这样也就记为{,,}{a, a,…, a}是条件属性,是唯一的决策属性。
1.2 不可分辩关系和弱不可分辨关系
在决策系统里,论域中的对象可以被任意的条件属性集划分成不同的子集。这些子集中的对象在该条件属性子集上的值是相同的,也就是说从该属性集上看,同一子集中的对象是无法区分的。因此可以通过条件属性值来描述决策系统中对象的这种不可分辨关系。
定义2(不可分辨关系)[15]:设为名词型值的决策系统,"Í",Î,那么属性子集上的不可分辨关系()定义如下:
(){()δ:() =(),"Î} (1)
显然这个不可分辨关系就是属性子集上的等价类。可以发现当且仅当两个对象在上的所有属性值均相同才能满足。这样的要求在许多应用领域太严格了,因此文献[15]提出了弱不可分辨关系这一概念。该概念大大放宽了对象属性值的要求,只要两个对象在属性子集上至少存在一个属性取值相同即可满足弱不可分辨关系。
定义3(弱不可分辨关系)[15]:设为名词型值的决策系统,"Í"Î,那么属性子集上的弱不可分辨关系定义如下:
{()Î:()()$Î} (2)
由此可见不可分辨关系是弱不可分辨关系的一种特殊情况。
1.3 邻域
不可分辨关系和弱不可分辨关系之间存在很多等级差别,为了量化这种等级差别,Zhao[15]提出了一个参数来表示这种不同级别的不可分辨关系。据此,本文提出名词型属性相似度的概念如下。
定义4(相似度):设{,,}为名词型决策系统,属性子集Í,论域中任意两个对象,的相似度是:
()=(,,)/||(3)
其中
()|{Î:()=()}| (4)
简记(,)(,,)。实际上,相似度这个概念和量化的不可分辨关系是一致的。本文暂不考虑属性约简[16]和测试代价[17]问题,即任意两个对象的相似度就是这两个对象属性值相同个数和所有属性数的一个比值,显然(,)Î[0,1]。当(,)1,那么对象,就是等价的;当(,)9,说明这两个对象的属性值完全不同。
可以通过决策系统中对象的条件属性值的异同来描述这些对象之间的关系。因此,名词型数据邻域的定义如下。
定义5(邻域):设Î,那么对象用相似度来描述的邻域是:
(,)={Î:(,)≥}(5)
这里的参数是用户给定的。显然(,)随着的减少会逐渐扩大,其邻域中的对象也会逐渐增加。当=1时,对象的邻域也就是的等价对象集合;当= 0时所有对象都是的邻域。因此一般不取0。在一个决策系统里面,更感兴趣的是每一个对象最小可能的值。
定义6(最小相似度):设{,,}为名词型决策系统,Í,={/||:Î{,,..., ||}},={,,...,},/{}={X,X,...,X},那么任意Î的最小可能的值为:
{:()Í,Î} (6)
取决于决策系统和对象自身。相应地,*的确定也就意味着对象的最大邻域的确立。
定义7(最大邻域):对于任意Î,其最大邻域如下:
() =(,) (7)
即的最大邻域是指通过来度量的论域空间中包含和具有相同的决策属性值的对象集合。
2 规则生成与分类算法
给定一个决策表{,,},条件属性集为{a, a,…, a},论域中的对象为{12, ... ,x}。每一个对象根据其属性的取值情况,即相似度,可以得到若干等价对象,逐步减少考虑的属性数量,保持引入邻域的对象要保持一致的决策属性。这样每一个对象都存在一个邻域,贪心选择覆盖正域对象数量最多的邻域。测试对象与这些选择出来的代表对象进行比较,采取投票的策略得到测试样本的类标号。
2.1 基于覆盖约简的规则生成
本文中规则生成的目的是获得一些代表对象及其最大相似度,它们构成的邻域里包含的对象具有相同的决策属性。首先消除矛盾对象,得到新的论域。其次为每一个里的对象计算其最大相似度和最大邻域。然后从这些邻域中贪心选择覆盖正域最大的邻域对象构成代表集合Y。对于另外的决策属性值的情况,采用完全相同的策略。所有的Y构成了能够覆盖整个论域空间的代表对象集合。最后,Y中的每一个对象都包含其自身的最大相似度,这样就构成了分类规则。
如算法1所示,(1)行将存储对象的一系列集合初始化,第(2)行消除矛盾对象得到新的论域空间。(3)-(5)行为每一个对象计算它的最小相似度和最大邻域。(6)行对内的对象按决策属性做出划分。(7)-(14)行针对每一个决策属性值求出它们的覆盖约简。这里有两重循环,外重For循环是由论域里对象的决策属性值的种类来决定的。(8)行将每一个X'赋给一个空集合。内循环从X'中每次选择一个对象使得它的邻域能够覆盖最多的对象,然后将选择出来的这个对象加入集合Y,并且要从中去除已选对象的邻域。(15)行是循环结束后得到的覆盖块的集合,也就是约简后的规则。

算法1:基于覆盖约简的代表生成算法(RG) 输入:决策系统S=(U,C,{d})的一定比例的子集TrainingSet。 输出:代表对象集合Y及覆盖集CR={(x, θx*)|xÎY}。 约束:YÍU并且ÈCR=POSC(d)。 (1)初始化Y,CR,U',X'均为空; (2)消除矛盾对象,得到新集合U'= POSC(d) ; (3)for (each xÎU') do (4) 计算θx*和nh*(x); (5) end for (6)计算决策属性对U'的划分: U'/d={X'1,X'2, … ,X'|vd|}; (7)for (i =1 to |vd|) do //代表及其覆盖块的选择 (8) X'= X'i; (9) while X'¹Æ do (10) 选择xÎ(U'Ç X'i )使得|nh*(x)ÇX'|最大; (11) Yi= YiÈ{x}; (12) X'= X'- nh*(x); (13) end while (14)end for (15)CR={(x, θx*)|xÎY}; (16)返回Y和CR。
2.2 基于邻域覆盖的分类测试算法
基于邻域覆盖的分类测试的重点在于测试对象符合多条规则的要求的情况下如何处理的问题。首先要计算测试对象和每一个代表对象的相似度。其次,并入符合相似度条件的代表到集合中。然后,测试对象与所有的代表对象比较完毕后,检测集合的情况,如果为空集说明没有该测试对象不符合任何规则的要求,则不给出预测值。最后将预测值给出集合X中对象数量最多的那一类别。
如算法2所示,(1)(2)两行初始化和符合规则的代表对象集合。(3)至(8)行将每条规则的代表对象和测试对象的属性值进行比较,得到相似度。将和这条规则的比较,如果符合要求则将该代表对象并入集合中。(9)至(13)行首先判断集合是否为空,如果为空,说明没有测试对象不符合任何规则的要求,不需要为其做出预测值。否则,(12)行则对其做出简单投票的预测。使其预测值为集合中数量最多的那一类别的决策属性值。

算法2:基于邻域覆盖的分类测试算法(NC) 输入:测试对象x',代表对象集合Y及覆盖集CR={(x,θx*)|xÎY}。 输出:x'的预测类别值d'(x') 。 (1)初始化测试对象与代表对象的相似度θ'=0; (2)初始化测试对象符合规则的代表对象的集合X=Æ; (3)for (each xÎY ) do //判断测试对象符合哪些代表的要求 (4) 计算测试对象和代表对象的相似度θ'=sim(x',x); (5) if (θ' ³θx*) then (6) X=XÈ{x}; (7) end if (8)end for (9)if (X=Æ ) then; (10) d'(x')=null; (11)else (12) d'(x')=argmax1£i£|vd||{xÎX|d(x)=i}|;//预测值为满足规则最多的类别。 (13)end if (14)返回预测类别值d'(x')。
3 实验分析
实验分析包含两部分,第一部份是实验数据的准备和设置,第二部分是实验结果分析和性能比较。
3.1 实验准备
首先,从UCI数据集上下载了4个数据集,分别是Zoo、Mushroom、Wdbc和Wine,数据描述如表1所示,每一个数据集上的实验方案都是一致的。其中后面两个数据集的数据类型并不是名词型数据,均对其作了离散化处理。为了体现不同的训练集和测试集数据比例,随机地将离散化后的数据集划分成两部份。训练比例分别从0.1到0.6,相应的剩余部份就作为测试集数据。Mushroom数据集的对象较多,并且训练样本较多之后的分类精度基本没有太大差异,因此将该数据集的训练比例调整为从0.02到0.12。由于是随机选择,对每一种分类比例,均做了十次实验,实验结果取其平均值和相应的标准差与Weka中的ID3算法作比较。

表1 四个数据集的基本描述 DatasetFeaturesClassInstances Wine143178 Zoo178101 Wdbc312569 Mushroom2328124
其次,由于训练和测试是相对独立的两部分数据。生成的规则用于测试的时候完全有可能有对象不满足任何规则。因此,需要采用三个流行的指标的恒量分类器的性能。一是分类精度(Precision,正确分类预测样本总数/做出分类预测的样本总数总数) ,二是召回(Recall,做出分类预测的样本总数/测试样本总数) ,最后一个指标是F-measure,这里采用流行的F1指标,也即()。
3.2 实验结果
表2显示两种算法在四个数据集的不同训练规模上的Precision的变化。分类精度在四个数据集上随着训练规模的增长都在提高,最终所有数据集的分类精度都达到90%以上,且Mushroom的分类精度很高达到99%以上;后三个数据集几乎每一种比例NC算法的分类精度都要高于ID3算法,有个别情况略低,比如Wdbc和Wine训练比例在0.3的时候以及Zoo的训练比例达到0.6的时候,但差距不是很大。表2显示的另一个标准差说明伴随训练比例的增长,Precision的稳定性逐步提高,Mushroom数据集的分类稳定性最高,但是NC算法的稳定性要小于ID3算法。
表3显示两种算法在四个数据集上不同训练规模上的Recall的变化。随着训练规模的增长,Recall值也在逐步增加,并且稳定性也逐步提高。NC算法在Zoo数据集上的Recall值都要高于ID3算法,在Mushroom、Wdbc和Wine这三个数据集上多数训练比例NC算法都稍弱于ID3算法,只有极个别训练比例NC算法的结果要稍强于ID3算法,但是整体而言差距不是很大。
图1是权衡了Precision和Recall两个相互制约的参数,得到F1-measure的变化图示。随着训练规模的增长,整体F1-measure的值都在增长。Zoo、Mushroom和Wdbc这三个数据集最终的F1-measure值达到了90%,Wine也达到了85%,尤其在Mushroom数据集上,F1-measure的性能最好,最后达到99.8%。四个数据集的结果显示Zoo的F1-measure值在NC算法上一直优于ID3算法,另外三个数据集上显示两种算法相差不大。

图1 NC算法和ID3算法分类结果比较
(a)Zoo, (b)Mushroom, (c)Wdbc, (d)Wine.
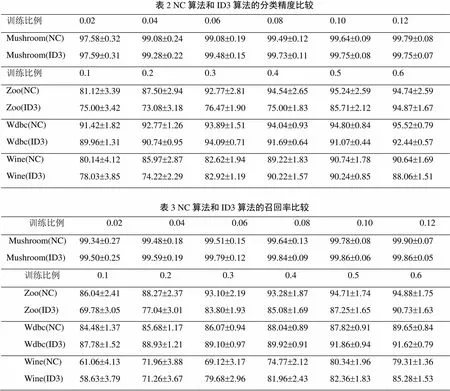
表2 NC算法和ID3算法的分类精度比较 训练比例0.020.040.060.080.100.12 Mushroom(NC)97.58±0.3299.08±0.2499.08±0.1999.49±0.1299.64±0.0999.79±0.08 Mushroom(ID3)97.59±0.3199.28±0.2299.48±0.1599.73±0.1199.75±0.0899.75±0.07 训练比例0.10.20.30.40.50.6 Zoo(NC)81.12±3.3987.50±2.9492.77±2.8194.54±2.6595.24±2.5994.74±2.59 Zoo(ID3)75.00±3.4273.08±3.1876.47±1.9075.00±1.8385.71±2.1294.87±1.67 Wdbc(NC)91.42±1.8292.77±1.2693.89±1.5194.04±0.9394.80±0.8495.52±0.79 Wdbc(ID3)89.96±1.3190.74±0.9594.09±0.7191.69±0.6491.07±0.4492.44±0.57 Wine(NC)80.14±4.1285.97±2.8782.62±1.9489.22±1.8390.74±1.7890.64±1.69 Wine(ID3)78.03±3.8574.22±2.2982.92±1.1990.22±1.5790.24±0.8588.06±1.51 表3 NC算法和ID3算法的召回率比较 训练比例0.020.040.060.080.100.12 Mushroom(NC)99.34±0.2799.48±0.1899.51±0.1599.64±0.1399.78±0.0899.90±0.07 Mushroom(ID3)99.50±0.2599.59±0.1999.79±0.1299.84±0.0999.86±0.0699.86±0.05 训练比例0.10.20.30.40.50.6 Zoo(NC)86.04±2.4188.27±2.3793.10±2.1993.28±1.8794.71±1.7494.88±1.75 Zoo(ID3)69.78±3.0577.04±3.0183.80±1.9385.08±1.6987.25±1.6590.73±1.63 Wdbc(NC)84.48±1.3785.68±1.1786.07±0.9488.04±0.8987.82±0.9189.65±0.84 Wdbc(ID3)87.78±1.5288.93±1.2189.10±0.9789.92±0.9191.86±0.9491.62±0.79 Wine(NC)61.06±4.1371.96±3.8869.12±3.1774.77±2.1280.34±1.9679.31±1.36 Wine(ID3)58.63±3.7971.26±3.6779.68±2.9681.96±2.4382.36±1.8385.28±1.53
4 结论与未来的工作
本文基于名词性对象的属性提出相似性度量的概念,在保持正域不变的情况下构建出最大邻域,并采用贪心策略选择覆盖最多论域对象的邻域作为分类的一系列规则。在分类阶段,对分类对象同时满足多条规则的情况采取简单投票方法对其分类。实验结果表明这种规则学习方法在处理名词型数据分类上是行之有效的。
未来将基于邻域覆盖这一模型,考虑不同的相似度度量方法来比较分类精度和稳定性,例如Eskin,Goodall 和Burnaby等学者提出的相似度度量方法以及与属性值发生频率有关的两种(Occurrence Frequency,Inverse Occurrence Frequency)。进而解决新模型下的属性选择问题。
[1] Freitag D. Machine learning for information extraction in informal domains [J]. Machine learning, 2000, 39(2-3): 169-202.
[2] Gruber S, Logan R W, Jarrín I, et al. Ensemble learning of inverse probability weights for marginal structural modeling in large observational datasets [J]. Statistics in medicine, 2015, 34(1): 106-117.
[3] Fayyad U, Piatetsky-Shapiro G, Smyth P. From data mining to knowledge discovery in databases [J]. AI magazine 1996,17(3) 37-54.
[4] Mu Y, Ding W, Tao D C. Local discriminative distance metrics ensemble learning [j]. Pattern Recognition. 2013, 46(8):2337-2349
[5] Denoeux T. A k-nearest neighbor classification rule based on Dempster-Shafer theory [J]. Systems, Man and Cybernetics, IEEE Transactions on, 1995, 25(5): 804-813.
[6] Li H X, Zhou X Z. Risk decision making based on decision-theoretic rough set: a three-way view decision model [J]. International Journal of Computational Intelligence Systems.2011, 4(1) 1–11.
[7] Zhang M L, Zhou Z H. ML-KNN: A lazy learning approach to multi-label learning [J]. Pattern recognition, 2007, 40(7): 2038-2048.
[8] Hu Q H, Yu D R, Xie Z X. Numerical attribute reduction based on neighborhood granulation and rough approximation [J]. Journal of Software. 2008, 19(3): 640-649.
[9] Hu Q H, Yu D R, Xie Z X., Neighborhood classifiers [J]. Expert Systems with Applications, 2008, 34(2):866-876.
[10] Yao Y Y, Yao B X. Covering based rough set approximations [J]. Information Sciences 2012, 200: 91–107.
[11] Zhu P F, Hu Q H, Yu D R. Ensemble Learning Based on Randomized Attribute Selection and Neighborhood Covering Reduction [J]. Acta Electronica Sinica . 2012, 40(2):273-279.
[12] Hu Q H, Yu D R, Liu J, et al. Neighborhood rough set based heterogeneous feature subset selection [J]. Information sciences, 2008, 178(18): 3577-3594.
[13] Du, Y., Hu, Q.H., Zhu, P.F. Rule learning for classification based on neighborhood covering reduction [J], Information Sciences, 2011, 181(24): 5457–5467.
[14] Yao Y Y. A partition model of granular computing [M]. Transactions on Rough Sets I. Springer Berlin Heidelberg, 2004: 232–253.
[15] Zhao Y, Yao Y Y, Luo F. Data analysis based on discernibility and indiscernibility [J]. Information Sciences, 2007, 177(22): 4959-4976.
[16] Min F, Zhu W. Attribute reduction of data with error ranges and test costs [J]. Information Sciences, 2012, 211: 48–67.
Neighborhood-based Classification for Nominal Data
ZHANG Benwen1*, SUN Shuangbo2, DONG Xinling2
(1. Department of Computer Science, Sichuan University for Nationalities, Kangding 626001, China 2. School of Computer Science, Southwest Petroleum University, Chengdu 610500, China)
Neighborhood-based approaches are popular in classifier building. However, existing approaches are more often designed for numeric data. In this paper, we propose rule synthesis algorithm with three techniques corresponding to rule generation, rule reduction, and conflict resolving. First, based on the similarity of instances, the maximal neighborhood of each instance is built. Each neighborhood corresponds to a decision rule. Second, since these neighborhoods form a covering of the universe, a covering reduction technique is proposed for rule reduction. The key to this technique is the greedy selection of the block covering the biggest number of uncovered instances. Third, a simply voting technique is developed for conflict resolving in the classification stage. Experimental results on four UCI datasets show that our algorithm is slightly better than the ID3 algorithm.
decision rule; classifier; neighborhood; covering reduction
1672-9129(2016)01-00038-06
TP 3
A
2016-07-04;
2016-07-22。
国家自然科学基金61379089,四川省教育厅科研项目基金13ZA0136。
张本文(1978-),男,四川雅安,讲师,主要研究方向:代价敏感,数据挖掘,粗糙集;孙爽博(1993-),男,湖北随州,硕士研究生,主要研究方向:代价敏感,推荐系统;董新玲(1991-),女,山东德州,硕士研究生,主要研究方向:推荐系统,关联规则等。
(*通信作者电子邮箱:zhbwin@163.com)
