等,抽取表格的表头和段落标题作为候选属性集合。利用领域无关的抽取模式捕获属性:平文本里仍然包含大量属性,为此我们提出如下两个适用于中文语言习惯的抽取模板:
P-1:<实体>的<属性>是
P-2:<属性>:<值>
在模式P-2中,单个句子除“:”外不能包含其他标点符号。此外,实验发现,字符长度过长的<属性>和<值>多为噪音,因此过滤掉大于10个字符的匹配结果。值得一提的是,模式P-1对应于英文属性抽取中普遍使用且效果较好的“the of is”模式,但在实际应用中该模式不是很有用。这一结果说明,中、英文之间存在的差异使得这些在英文数据上行之有效的方法应用于中文数据时失效,有必要提出针对中文的解决方案。
计算属性置信度:获得候选属性集合之后,我们采用基于频率的置信度计算方法来度量属性的质量。给定实体类别C,候选短语a是类别C的属性的置信度可以被计算为式(1)。

(1)
其中,ei为C中的一个实体,page(ei)为ei的描述页面,a∈page(ei)表示属性a可以从page(ei)中抽取出。
3.3 利用属性同义的特点扩展抽取
3.2节所述的方法可以获得一些高质量的属性,但是置信度得分较低的候选属性中仍然含有大量高质量的属性,这些属性由于不常出现而被遗漏。我们发现这些被遗漏的属性中许多与高置信度属性是同义的,据此,我们提出一种基于同义属性扩展的方法进一步抽取属性的不同表达形式。其中,属性的同义性分别从两个方面进行度量。
字面相似度:由于属性短语的长度较短,平均为4.7个汉字,许多常用的相似度度量方法(如编辑距离、Jaccard相似度)效果并不理想。例如,非同义属性“主频参数”和“主屏参数”的Jaccard相似度为0.6,而同义属性“摄像头”和“摄像头像素”的Jaccard相似度仅有0.4。此外,属性短语多来自相似的实体描述页面,缺少足够有区分度的上下文信息,因此,余弦距离等方法也不适用。为此我们做严格约束,仅当某一属性为另一属性的完全子串时才计算字面相似度,否则认为字面不相似,即给定两个属性短语a和b,字面相似度计算为式(2)。
surSim(a,b)=
(2)
其中a∈b表示a为b的完全子串,|a|表示属性短语a的字符长度。该公式的直观解释是两个属性短语重叠的字符数占两个短语平均长度的比值越大,则两个属性越相似。
语义相似度:给定两个属性短语a和b,分词之后记为a=和b=,对于任意的词对cij=,利用同义词典*http://ir.hit.edu.cn/phpwebsite/index.php?module=pagemaster&PAGE_user_op=view_page&PAGE_id=162计算其语义相似度,从而得到属性短语a和b的词语相似度矩阵C=[cij]m×n。该同义词典采用五层编码,可以看成一颗深度为五的词语树,叶节点为词语,位于同一颗子树上的词语均具有一定的语义关系。如果两个词语的共同父节点数量越多,说明两个词语的语义越相近。给定两个词语w和v,五层编码分别记为w=l1l2l3l4l5和v=h1h2h3h4h5,它们的语义相似度计算为式(3)。
(3)
其中prefix(*,*)表示两个五层编码的公共前缀的字符数量。
对于一个给定的词对序列seq={,,...,}(s为m和n的最小值),其语义相似度计算为式(4)。
(4)
属性a和b的语义相似度为所有可能的词对序列相似度中的最大值,形式化地表示为式(5)。
(5)
我们采用贪心的方法求解,每次从C中选取最大的cij并同时将wi和vj从属性短语中移除。属性短语最终的相似度为式(6)。

(6)
基于上述同义属性度量方法,我们提出一种扩展的属性置信度计算方法(算法1所示),该方法利用属性同义的特点有选择地提高低频属性的置信度,与3.2节中基于频率的置信度计算方法相比,可以获得更多高质量的属性,同时得到了同义属性集合。其中,算法1步骤9中的阈值在实验中设置为0.8。较高的阈值能够保证获得的同义属性的质量,但数量较少,反之,较低的阈值能够获取更多的同义属性但准确率会降低,可以根据具体应用需求进行调整。
4 实验与分析
4.1 实验设置
实验数据:实验使用百度百科作为数据集。值得注意的是,我们提出的系统框架和算法同样适用于其它中文在线百科,只需在解析HTML的实现细节稍作改动即可。截止到2013年4月20日,共采集1 199个实体类别的379 654个词条。由于无法对所有类别进行评价,选取“手机”、“NBA球星”、“国内高校”、“枪械”、“汽车”和“抗生素”六个类别,涉及热门领域“人物”、“产品”和新领域“机构”、“武器”等,各类别的实体数量见表1。
算法 1 基于同义属性扩展的属性抽取算法

输入:D⁃包含某类实体的百科页面集合输出:L⁃属性及同义属性列表1:抽取D中所有可能的属性,存入Temp2:对任意的ai∈Temp,计算conffre(ai),并降序排列3: forai∈Tempdo4: ifai∉Lthen5: 添加ai到L6: else7: 对任意的lj∈L,计算sim(ai,lj)8: 找到相似度最大的属性l∗,其相似度记为θ∗9: ifθ∗>thresholdthen10: 更新ai的置信度为conf=(1-θ∗)·conffre(ai)+θ∗·conffre(l∗)11: 添加ai到L,并标记l∗和ai为同义属性12: endif13: endelse14: endfor15:returnL
评价指标:人工标注评价抽取结果。为克服评价的主观性和不一致性,我们采用文献[2]中提出的评价指标:如果一个属性对描述该类实体来说是必要的,标记为“重要”;如果一个属性有用但不重要,标记为“一般”;如果一个属性是错误的,标记为“错误”,将标记转换为对应的分值用以计算结果的整体准确率,见表2。请六个研究人员分别独立标注,对于标注不一致的属性,则采取投票的方式来确定标注值。给定一个目标类别, 根据第3节中描述的方法可以得到一个按照置信度排序的属性列表,使用Precision@N(P@N)作为属性准确率的评价指标,即结果列表前N个属性的总得分除以N。
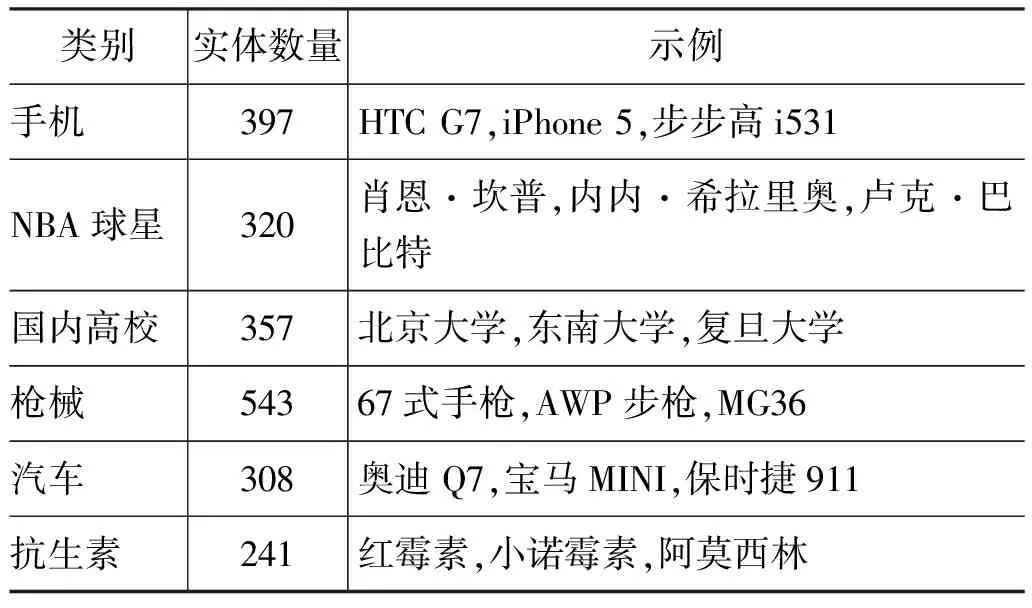
表1 各个类别的实体数量及样例
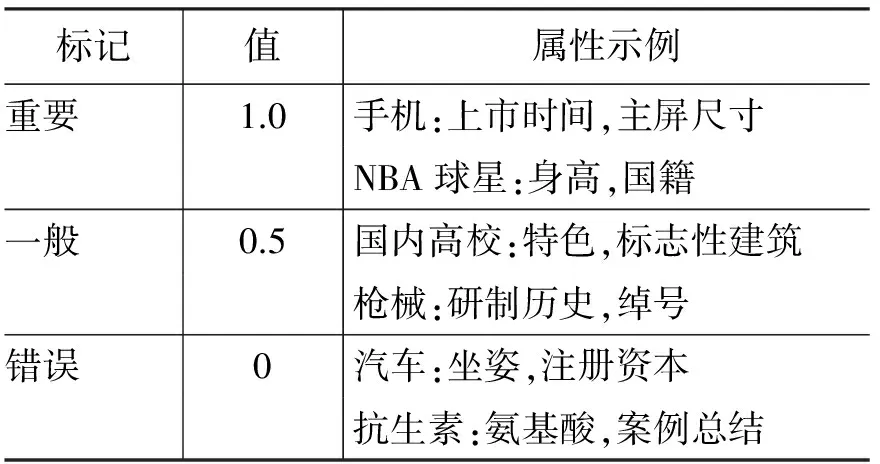
表2 人工标记的标签及举例说明
基准系统:由于缺少可比较的中文属性挖掘方面的工作,我们实现了一个在英文数据上具有代表性的方法[2]作为基准系统(记为BL)。该方法主要思想为,利用领域独立的模式来获取无结构文本中的属性,并且基于频率对属性排序。为了使之适用于中文,我们将原方法中的英文模式映射成等价的中文模式,事实上就是3.2节中提到的P-1模式。使用NLPIR汉语分词系统*http://ictclas.nlpir.org/对句子进行分词和词性标注,抽取“的”后面最长的名词短语作为属性。此外,我们还对比两组不同设置的运行结果,用以分析同义属性扩展带来的增量效果:
(RUN-1):仅使用3.2中的基于频率的方法获取属性,不做同义属性扩展。
(RUN-2):在RUN-1基础上,使用3.3中的方法进行扩展。
4.2 实验结果及其分析
准确率:图2展示了基准系统和本文方法的整体结果,为便于对比,表3列出了P@10、P@50和P@100三个特定点上的值。从图中可以看出,不同类别的抽取效果不尽相同,例如“国内高校”和“抗生素”,无论是我们的方法还是基准系统效果都比其他类别要差,这是因为“国内高校”多为复合属性,“抗生素”本身具有的属性就较少。由此可见,属性抽取的效果由实体类别本身的特点决定。
图2表明,RUN-1和RUN-2在六个类别上的准确率普遍比基准系统要高。基准系统在英文数据集上P@50的平均值在0.63以上,而应用在中文数据上P@50的平均值下降到0.55,可见中英文之间存在的差异使得在英文上表现良好的属性抽取方法并不适用于中文数据。RUN-1在P@50的平均值为0.78,这说明抽取的属性基本可用。值得注意的是,属性抽取方面的相关工作一般只考察前50个抽取结果,本文考察前100个抽取结果,由图2可以看出,基准系统的准确率下降较快,RUN-2最平缓。具体来说,基准系统在P@100的平均值仅为0.43,抽取的属性已基本不可靠,而RUN-2在P@100的平均值为0.83,抽取的属性仍具有较高的可信性。此外,RUN-2在P@50的平均值为0.86,说明通过3.3节的方法扩展进来的 同义属性并没有明显降低原抽取结果的准确性。
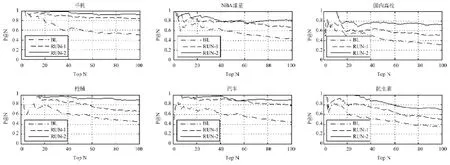
图2 前100个抽取结果的准确率
前N个结果的覆盖率: 一个实体类别的完整属性集合是不可知的,而人工枚举所有的属性也是不现实的,这是信息抽取尤其是属性抽取领域普遍面临的问题,许多研究工作放弃评估召回率而重点考察准确率。考虑到我们的目的是进行方法的横向比较,即对比不同属性挖掘算法在获得的属性数量上的差异,而不是为了得到真实的召回值,因此我们使用一种易处理的近似方案:将表1中给出的共2 166个实体的百科页面作为六个类别的全部数据,采用人工标注的方法评估抽取结果的覆盖率。显然,这仍是非常耗时的,我们只考察标记为“重要”的属性,因为其他属性重要性较低且容易发生标注不一致问题。
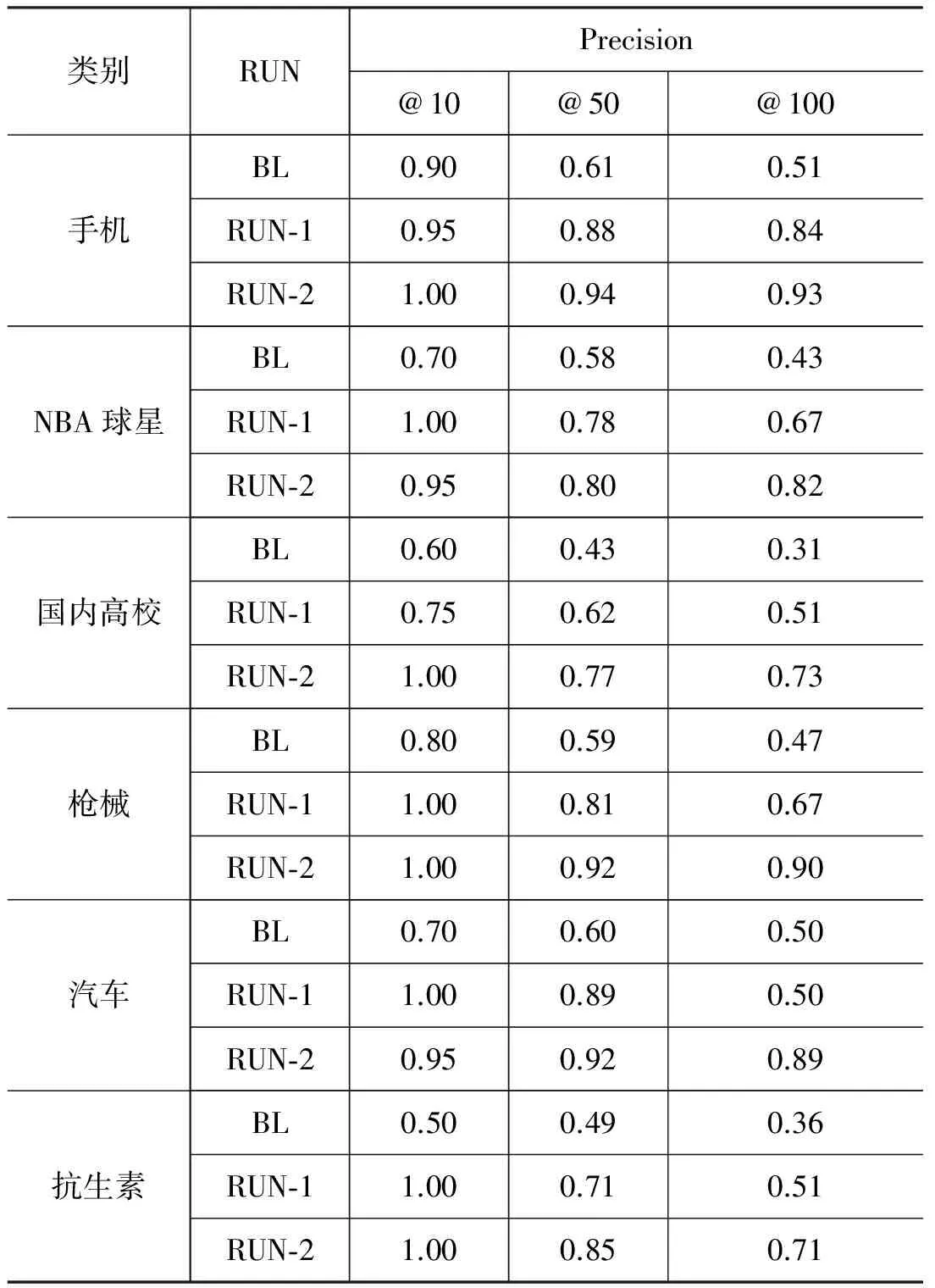
表3 前10、前50、前100个结果的准确率
表4给出了各类别在前10、前50和前100个抽取结果的覆盖率。由于不同类别具有属性的基数不同,类别和类别之间的覆盖率差距较大,但是这不影响横向对比。此外,表中的覆盖率值普遍偏低,这是由于我们只考察前100个抽取结果,例如“手机”共有917个属性,即使前100个抽取结果全对,覆盖率也仅有0.11。由表可知,RUN-2在六个类别上的覆盖率均比RUN-1高,这说明3.3节中提出的扩展方法确实获得了更多属性。
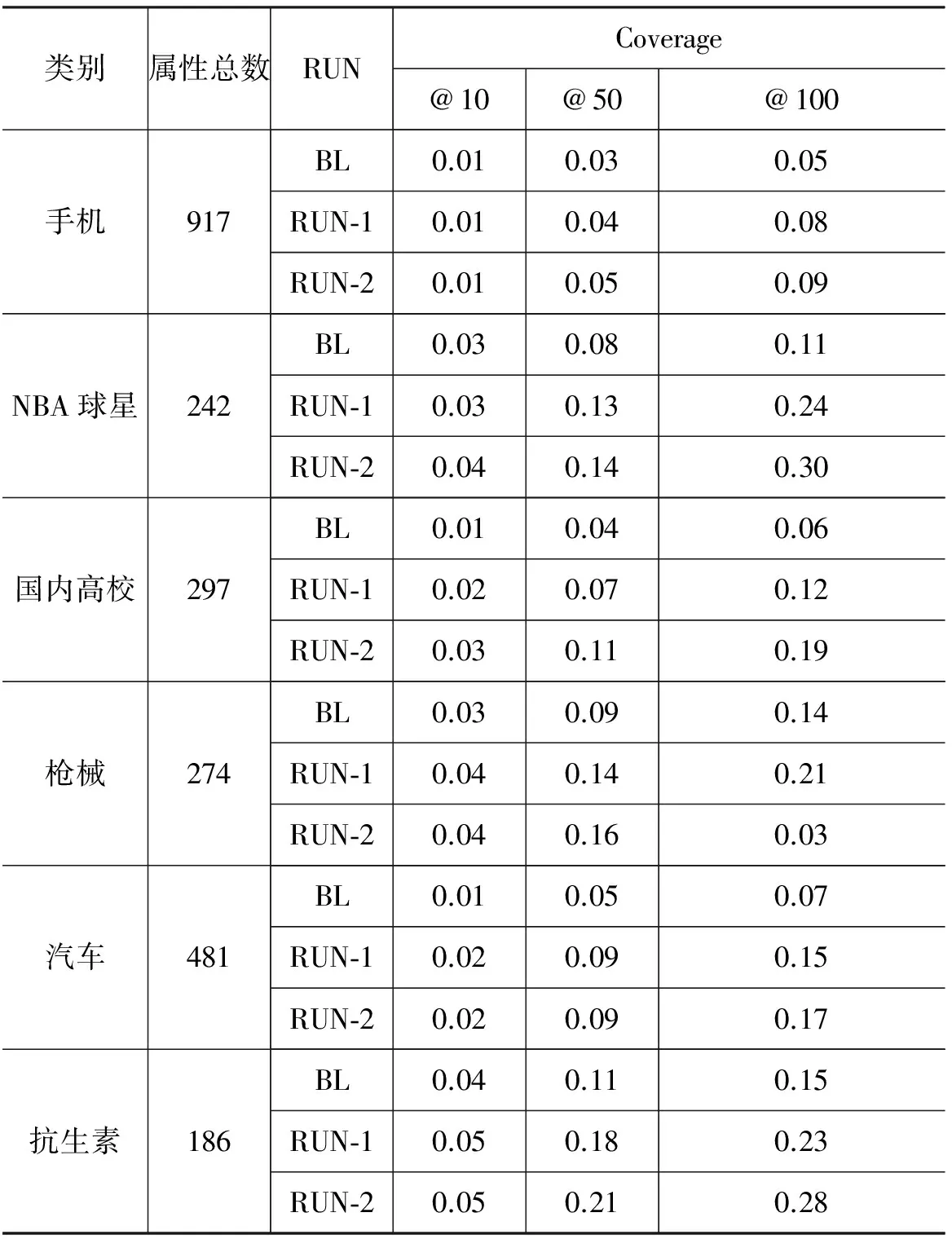
表4 前10、50和100个结果的覆盖率

表5 属性及同义属性部分结果
续表
同义属性评价:表5为同义属性集合的部分结果,“{}”中的为同义属性。由表可知,部分同义属性具有相似的字面形式,部分同义属性字面完全不同,例如,“配用弹种”和“可用子弹类型”。为进一步考察同义属性识别的效果,我们将同义属性识别看成聚类问题,从已被标注为“重要”的属性集合中随机选择10%的属性,人工标注并计算聚类Purity(公式7)结果见表6。
(7)
其中Si是类别i下待评测的聚类集,Rj是类别j下人工标注的聚类集。
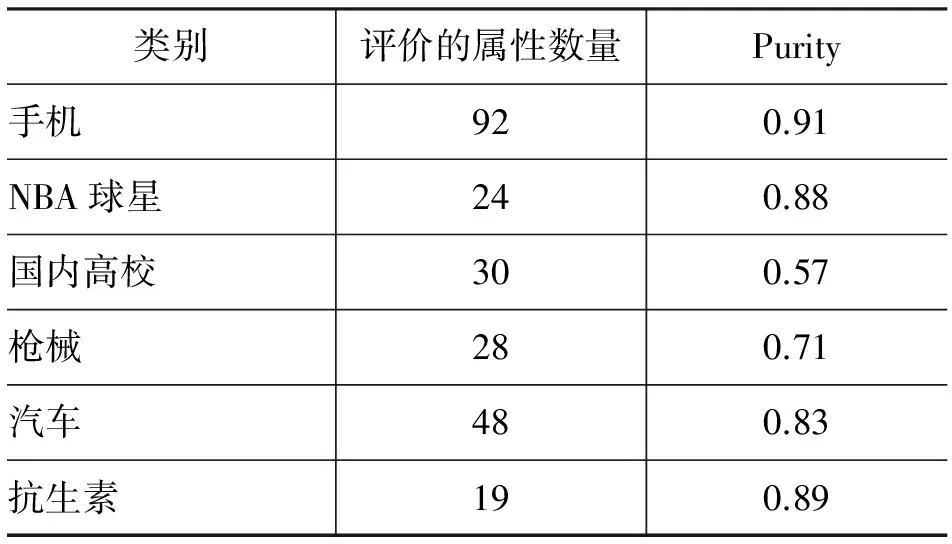
表6 同义属性识别效果
5 总结与展望
本文提出了一种以在线百科为数据资源,基于同义属性扩展的中文属性抽取方法,实验表明该方法在保证识别准确率的前提下能够有效地从在线百科中抽取出大量的属性名称,该方法与使用频率的抽取方法相比,能够获得覆盖范围更广的属性名称集合。
在本文方法中,我们通过识别同义属性,在一定程度上解决了属性名称的归一化问题。在未来的工作中,我们将进一步探讨和研究属性值的归一化问题以及属性上下位关系的自动识别问题,这些研究内容也是自动构建知识库需要解决的重要问题。
[1] Popescu A-M, Etzioni O. Extracting product features and opinions from reviews[M]Natural language processing and text mining. Springer London, 2007: 9-28.
[2] Pasca M, Van Durme B, Garera N. The role of documents vs. queries in extracting class attributes from text[C]//Proceedings of CIKM. Lisbon, Portugal, 2007: 485-494.
[3] Pasca M. Attribute extraction from conjectural queries[C]//Proceedings of COLING 2012. India, 2012: 2177-2190.
[4] Tokunaga K, Kazama J, Torisawa K. Automatic discovery of attribute words from Web documents[C]//Proceedings of the Natural Language Processing-IJCNLP 2005. Jeju Island, Korea, 2005: 106-118.
[5] Raju S, Pingali P, Varma V. An unsupervised approach to product attribute extraction[M]. Advances in Information Retrieval. Springer Berlin Heidelberg, 2009: 796-800.
[6] Lee T, Wang Z, Wang H, et al. Attribute Extraction and Scoring: A Probabilistic Approach[C]//Proceedings of ICDE. Brisbane, Australia, 2013: 194-205.
[7] Van Durme B, Qian T, Schubert L. Class-driven attribute extraction[C]//Proceedings of the 22nd International Conference on Computational Linguistics. Manchester, UK, 2008: 921-928.
[8] Ravi S, Paʂca M. Using structured text for large-scale attribute extraction[C]//Proceedings of CIKM. Napa Valley, California, 2008: 1183-1192.
[9] Lin D, Zhao S, Qin L, et al. Identifying synonyms among distributionally similar words[C]//Proceedings of IJCAI. Acapulco, Mexico, 2003: 1492-1493.
[10] Turney P. Mining the web for synonyms: PMI-IR versus LSA on TOEFL[C]//Proceedings of the 12th European Conference on Machine Learning. Freiburg, Germany, 2001: 491-502.
[11] Witten I, Milne D. An effective, low-cost measure of semantic relatedness obtained from Wikipedia links[C]//Proceeding of AAAI Workshop on Wikipedia and Artificial Intelligence. Chicago, USA, 2008: 25-30.
[12] Kim S, Toutanova K, Yu H. Multilingual named entity recognition using parallel data and metadata from Wikipedia[C]//Proceedings of ACL,Korea, 2012: 694-702.
[13] Han X, Zhao J. Structural semantic relatedness: a knowledge-based method to named entity disambiguation[C]//Proceedings of ACL, Sweden, 2010: 50-59.
[14] Suchanek F M, Kasneci G, Weikum G. Yago: a core of semantic knowledge[C]//Proceedings of WWW, Canada, 2007: 697-706.
[15] 叶正,林鸿飞,苏绥,等. 基于支持向量机的人物属性抽取[J]. 计算机研究与发展, 2007, 44: 271-275.
[16] 卢汉,曹存根,王石. 基于元性质的数量型属性值自动提取系统的实现[J]. 计算机研究与发展, 2010, 47(10): 1741-1748.
Synonymous Expansion Based Entity Attribute Extraction via Online Encyclopedia
LIU Qian1,2, LIU Bingyang1,2, HE Min3, WU Dayong1, LIU Yue1, CHENG Xueqi1
(1. CAS Key Laboratory of Network Data Science & Technology, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190,China; 2. University of Chinese Academy of Sciences, Beijing 100049,China;3. National Computer Network Emergency Response Technical Team/Coordination Center of China, Beijing 100029, China)
Entity attribute extraction is fundamental to information extraction and knowledge base construction. This paper proposes an approach to open-domain entity attributes extraction from the online encyclopedia. The method collects potential attribute phrases through a combination of the web page structure and the domain independent patterns. Then, the acquired attribute patterns are expanded by synonymous expansions, which in turn helps to obtain a set of synonymous attributes. Experimental results show that the proposed approach boosts the coverage of extracted attributes without losing the precision.
entity attribute;synonymous attribute;named entity,information extraction

刘倩(1984—),博士,主要研究领域为自然语言处理、命名实体识别、网络文本挖掘、信息抽取。E⁃mail:liuqian1104@126.com刘冰洋(1987—),博士,主要研究领域为自然语言处理、命名实体识别、新词发现。E⁃mail:liuctic@gmail.com贺敏(1982—),博士,主要研究领域为自然语言处理、网络挖掘、信息安全。E⁃mail:heminsmile@163.com
1003-0077(2016)01-0016-08
2013-08-10 定稿日期: 2014-05-10
国重点基础研究发展计划(973)(2012CB316303);国家重点基础研究发展计划(973)(2014CB340401);国家自然科学基金重点项目(61232010);国家科技支撑专项(2012BAH46B04);国家自然科学基金(61303156)
TP391
A

