基于SAO的专利结构化相似度计算方法
2016-05-04杜玉锋姜利雪张桂平
杜玉锋,季 铎,姜利雪,张桂平
(沈阳航空航天大学 知识工程研究中心,辽宁 沈阳 110136)
基于SAO的专利结构化相似度计算方法
杜玉锋,季 铎,姜利雪,张桂平
(沈阳航空航天大学 知识工程研究中心,辽宁 沈阳 110136)
该文提出了一种基于subject-action-object(SAO)的专利结构化相似度计算方法。传统的基于关键词的定量分析方法没有考虑专利自身的结构特点,忽略了对专利间内在关系的计算,该文弥补了传统的基于关键词的定量方法的不足。在SAO结构抽取过程中,将最新的实体抽取工具OLLIE引入到专利领域,得到了比传统SAO抽取工具更好的抽取结果。和传统的SAO方法相比,对Action元组进行了大量分析,通过重复大量实验,确定了Action元组的结构特征。最后,通过实验验证,将vector space module(VSM)模型和SAO结构进行融合,得到了比仅仅通过VSM模型进行相似度计算更好的结果。
数据挖掘;专利相似度;Subject-Action-Object(SAO)技术;实体抽取工具;OLLIE
1 引言
在当今的科技和工业领域,专利是一种重要的知识获取资源,据世界知识产权组织研究表明 ,全世界最新的发明创造信息 90%以上首先通过专利文献反映出来。然而,专利的有效性获取存在着如下三方面的问题: (1)全世界的专利数量每年大幅度增加[1];(2)分析专利是一项很耗时的任务,这需要大量的人力投入[2];(3)专利评定机构对专利的初始评定结果不尽如人意[3]。
因此,对专利的分析就显得尤为重要。专利分析的一个重要方面就是衡量专利的相似度,即通过对专利的聚类,进行专利的各方面研究。例如,(1)专利的现有技术分析,给定一篇专利,然后返回与其技术相关的其他专利;(2)专利的侵权分析,给定一篇被侵权的专利,然后找出和其内容重叠的其他专利;(3)专利地图的生成,通过专利的相似度矩阵,得到专利之间的直观表示图[4]。
传统的定量分析方法,对关键词的相似度计算是最常见的专利相似度计算方法[4-6]。将专利用关键词构成的词袋集合表示,然后构造关键词的空间特征向量,通过cosine等计算公式,得到专利之间的相似度[7]。Xu Feng,Leng Fuhai[8]在通过构造关键词的空间特征向量基础上,通过加入主成分分析法和层次聚类算法,将形态学分析引入进来。
然而,定量的分析方法没有考虑到专利自身所具有的结构特征,专利最重要的结构特征体现在产品、技术和两者的关系上。为了弥补定量分析方法的不足,专利分析中引入了“关系”概念。“关系”[9],用来表示“改变主体特征的行为”,为了表示这种关系,Subject-Action-Object(SAO)模型被广泛使用。
本文提出了基于SAO的专利结构化相似度计算方法。和传统的基于SAO方法相比,(1)通过实体抽取工具OLLIE抽取SAO三元组;(2)对抽取出来的元组A进行结构分析,提取出来的结构特征包括核心词,动词的ing形式,动词的被动形式,not形式,以及介词情况。
本文接下来的内容由四部分组成。第二节介绍了SAO技术和实体抽取工具OLLIE;第三节详细描述了本文提出的研究思路并给出了具体的研究步骤;第四节通过一个实验来验证研究思路,并给出了实验结果及分析;最后是“结论及展望”部分。
2 相关研究
2.1 SAO技术介绍
SAO结构的概念来源于theory of inventive problem sloving(TRIZ)理论,TRIZ理论是描述技术问题并解决技术问题的一套理论。这套理论是由Genrich Altshuller从20万篇专利中抽取技术信息,总结了描述专利中创新设计功能的关系,然后通过这些关系形成一种专利创新的思考模式[10]。SAO结构就是基于TRIZ理论中的关系函数形成的。SAO结构的基本单位是“key-concept”,而不是“key-words”[4];在一个SAO结构中,如果AO(Action-Object)代表对问题的描述,S代表解决问题的方法,那么SAO结构就可以认为是能表示问题解决的一种组织形式。例如,“battery energizes bulb”,“battery”是Subject,“energizes”是Action,“bulb”是Object,那么“battery”这个技术的目的是给“bulb”提供能量,即“battery”的功能是给“bulb”提供能量。
2.2 实体抽取工具OLLIE
OLLIE[11-15]是由华盛顿大学Oren Etzioni教授等人在2012年完成的信息抽取软件。抽取出的例子见表1。和传统的SAO抽取工具Knowlegist[16],PAT-analysis tool[17]相比,OLLIE的特色是加入了对语句的浅层句法分析,从而让抽取出来的实体更准确,同时,OLLIE学习了一些开放模板,从而可以更广泛地抽取SAO结构模型。

表1 OLLIE抽取出的SAO信息
3 研究步骤
本文将SAO结构引入到专利的相似度研究中,在相似度计算时,融合了基于关键词的定量分析方法和基于SAO结构的定性分析方法。本文的研究分为以下四个步骤。(1)SAO结构的抽取;(2)元组A的结构分析;(3)基于SAO结构的相似度计算;(4)专利的相似度计算,由基于VSM模型的定量分析方法和基于SAO结构的定性分析方法组成。流程见图1。
3.1 SAO结构的抽取
在专利中,概要被认为是平均信息量最大的专利部分,因此,本文选取专利的概要进行SAO结构抽取。本文采用的抽取工具是由华盛顿大学图灵实验室开发的OLLIE软件,OLLIE软件抽取出来的专利信息包括(S,A,O)三元组以及专利句子对应的词法和句法信息。
3.2 元组A的结构分析
在Subject-Action-Object(SAO)结构中,Subject和Object表示专利中产品或技术的主题词,作为专利中的实体,这类词一般不容易提取。Action表示Subject和Object之间的关系。由于专利自身的特点,专利中的动词一般很固定,而且容易获得。因此,本课题将SAO的研究主要集中Action元组中。
本文通过大量实验表明,A结构可以用core-verb,s1,s2,s3,s4五部分表示(见图2),其中core-verb表示核心动词,s1表示是否含有动词的ing形式,s2表示是否含有动词的被动形式,s3表示是否含有not形式,s4表示是否含有介词。
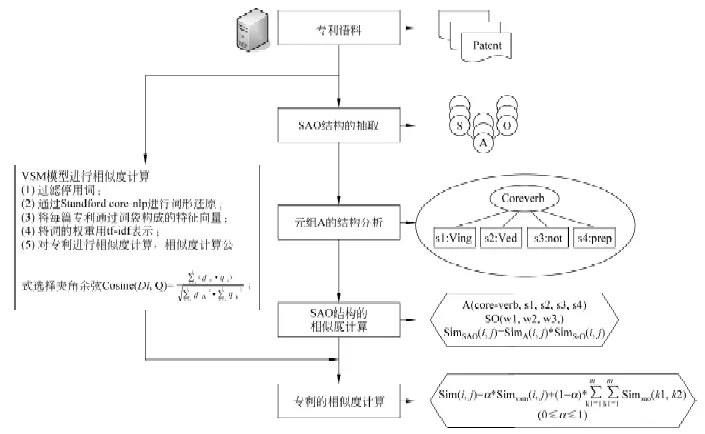
图1 研究步骤的主流程图
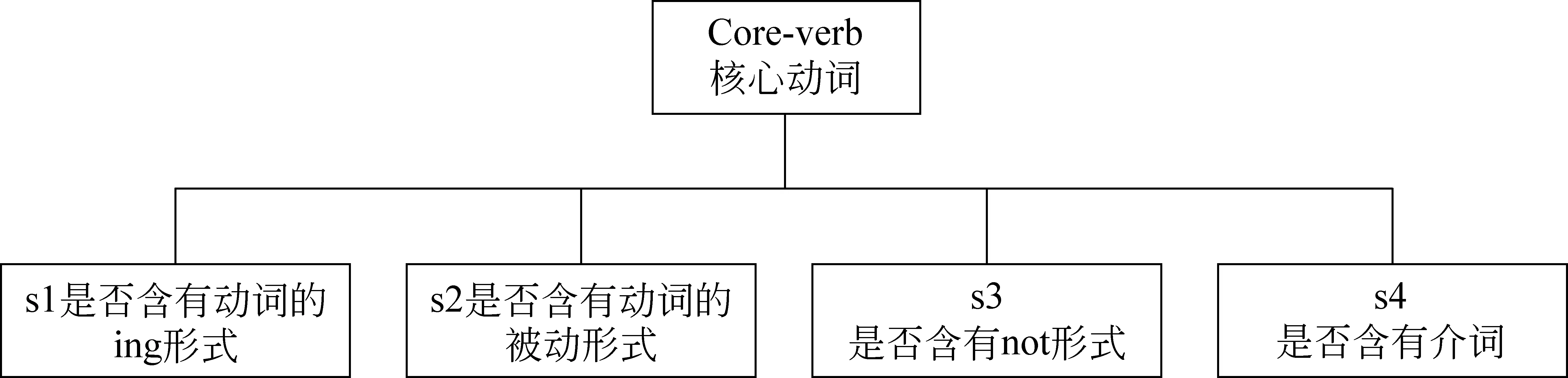
图2 A元组的结构图
从3.1中,本文可以得到A元组中每个词对应的词性和所属的语块信息,然后本文构造了一个基于词性和语块的A短语结构模板(例子见表2),包含4 000余条规则。其中,若si为0,则表示在对应的语块和词性条件下, 元组A不包含si部分;若si为1,则表示在对应的语块和词性条件下,元组A包含si部分。
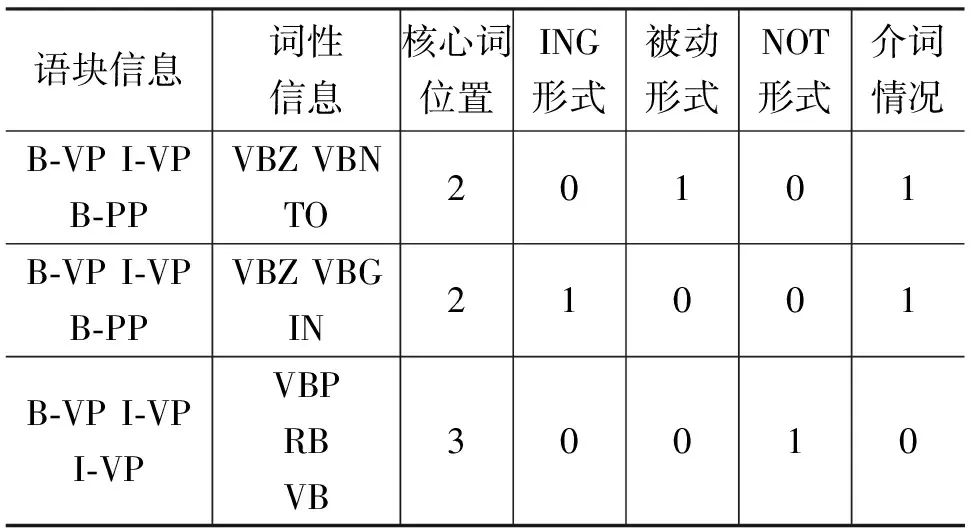
表2 语块词性规则模板
通过A短语结构模板,本文将元组A用特征向量表示。例如,“be subjected to”表示为(subjected,0,1,0,1),“is working on”表示为(working,1,0,0,1),“do not carry”表示为(carry,0,0,1,0)。
3.3 基于SAO结构的相似度计算
第i个SAO结构和第j个SAO结构的相似度等于对应A结构的相似度SimA(i,j)和对应S-O结构的相似度SimS-O(i,j)的乘积,表示为公式(1)。
(1)
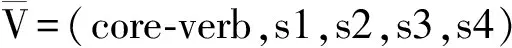
(2)
SimS-O(i,j)表示第i个SAO中的S-O元组和第j个SAO中的S-O元组的相似度结果。首先,将S-O元组中的词进行停用词过滤,然后构造S-O元组词的VSM矩阵,最后通过夹角余弦得到SimS-O(i,j)。
3.4 专利的相似度计算
本文的专利相似度计算方法是由基于关键词的定量分析方法和基于专利结构的定性分析方法两者融合得到的,见公式(3)。
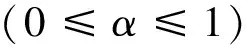
(3)
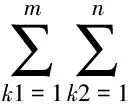
4 实验
本实验通过KNN算法对测试语料的每篇文档进行三次分类,分类的依据依次为IPC的主部(第一位数)、大类(前三位数)、小类(前四位数)。实验考查了在不同分类依据下SAO结构在专利相似度计算中所起的作用。
4.1 实验语料
本实验所用语料来自美国国家专利及商标局(USPTO)2004~2006年的专利语料,共56 000篇,语料内容有专利号,国际分类号(IPC)和概要组成。按照国际分类号的主部进行平均分配,A~H部各7 000篇。其中,训练语料为54 400篇,A~H部各6 800篇,测试语料为1 600篇,A~H部各200篇。语料分类情况见表3。
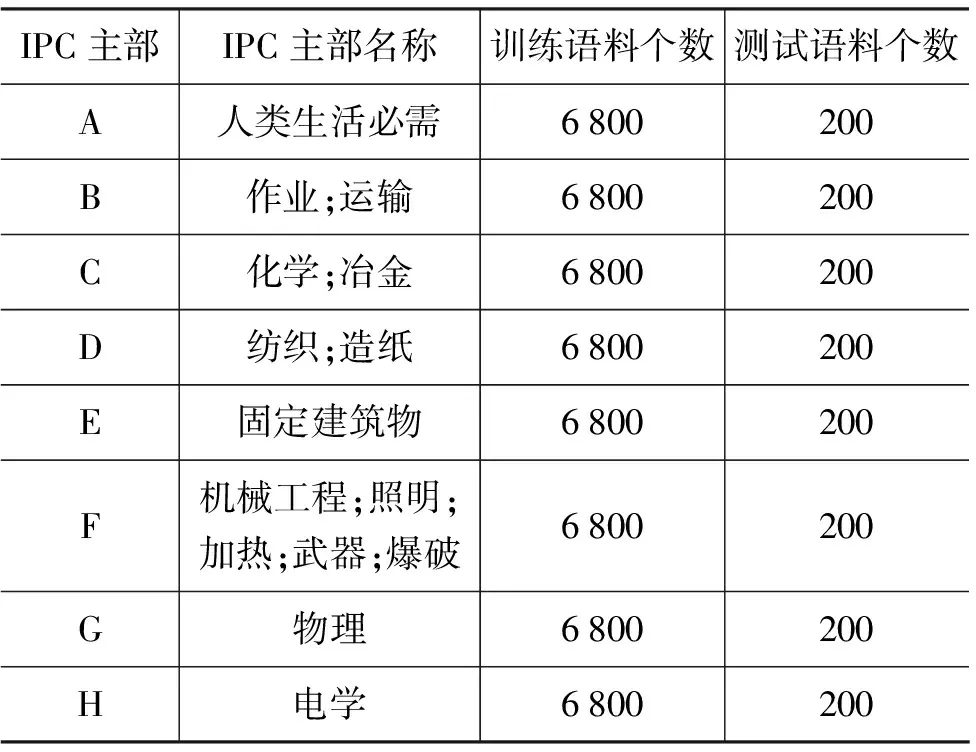
表3 语料分类明细
通过OLLIE软件,从54 400篇训练语料里面抽取出801 730个SAO结构,从1 600篇测试语料里面抽取出23 580个SAO结构,平均从每篇专利概要里面抽取出14.7个SAO结构。
4.2 评测方法
本实验通过KNN算法对测试语料的每篇文档进行分类。对每次分类的结果,设初始分值为0,当分类结果与测试文档本身的类别相符时,视为分类正确,分值加1;否则,视为分类错误,不加分。对于整个测试语料,准确率为总分除以文档的总数。见公式(4)。
(4)
4.3 实验结果与分析

表4 公式(3),VSM结果分析表
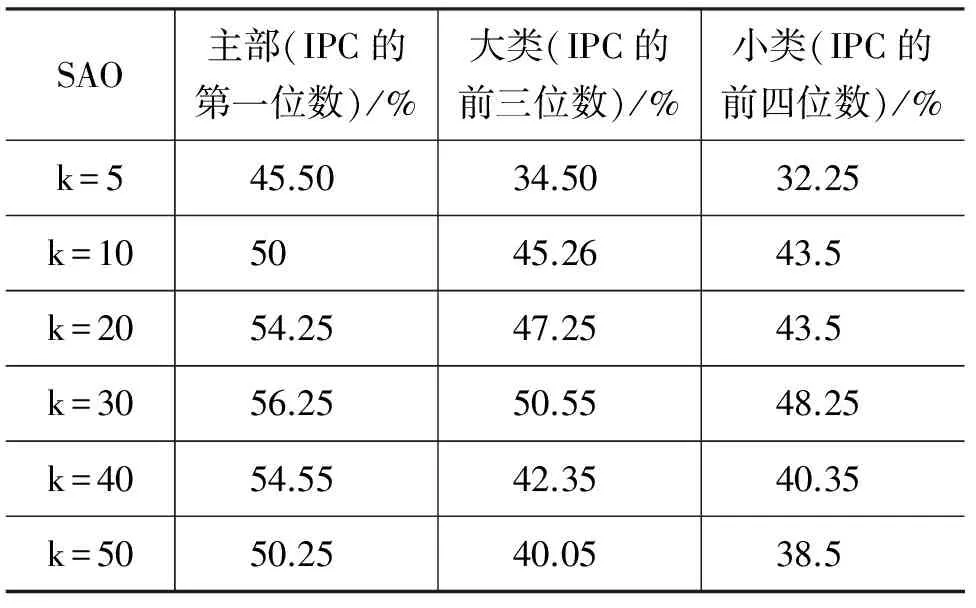
表5 公式(3),SAO结果分析表
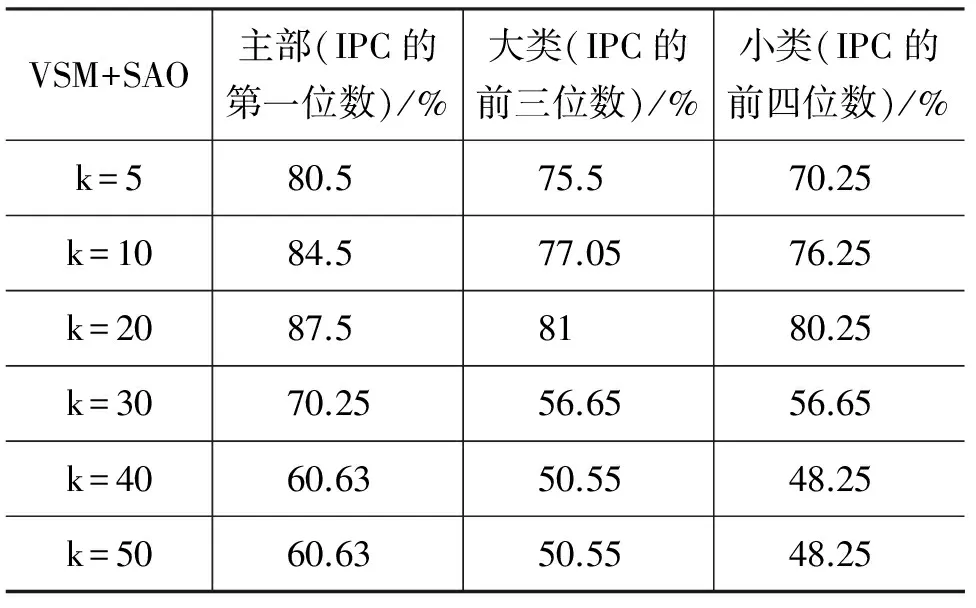
表6 公式(3),VSM+SAO结果分析表
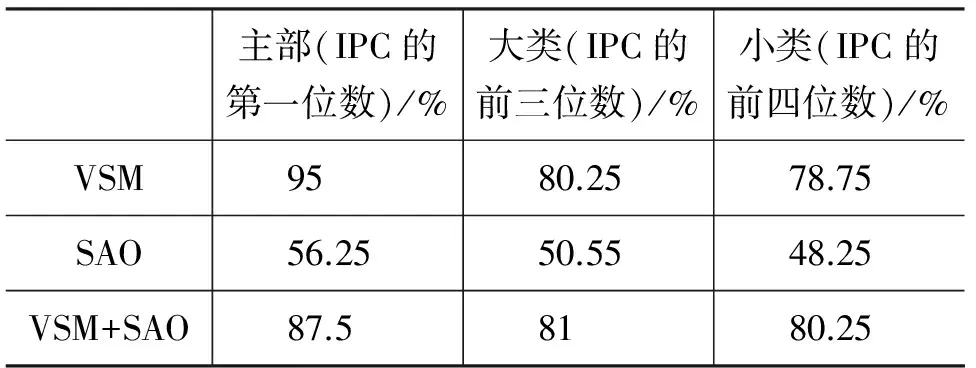
表7 VSM,SAO,VSM+SAO最优结果比较
从表4中可以看到,通过VSM模型进行专利的相似度计算,随着K值的增加,分类结果的准确率依次降低;从表5中可以看到,通过SAO结构计算专利的相似度,随着k值的增加,分类结果的准确率先升高,后降低,在k=30处达到最高值。这是因为,在SAO实验中,本课题是以Action为核心的,而表示Action的词代表着一种subject和object之间的关系,在这种关系下,对应的subject和object不需要一致,例如,“A includes B,C”,“D includes E,F”,subject和object之间的关系是“includes”,而第一个subject是“A”,第二个subject却是“D”。当k特别小的时候(k≤30),随着k值的增大,这种不一致现象越来越弱,导致准确率越来越高,当k增大的一定程度(k≥30),这种不一致现象可以忽略。通过表4和表5可以看到,仅仅通过SAO结构,并不能提高专利分类的准确率。因为SAO结构表示专利的内在关系,忽略了对专利中非结构化部分的考虑。
通过表7可以看到,VSM模型加SAO结构,在依据IPC的大类(前三位数)、小类(前四位数)进行分类时,效果最好。VSM模型是从整体上对专利进行分析;SAO结构仅对专利中结构化的部分进行考虑,侧重于对专利内容的深度挖掘。如果仅仅通过VSM模型进行专利的相似度计算,将会忽略专利中结构化的内容,如果仅仅通过SAO结构进行专利的相似度计算,将没有从整体进行考虑。两者结合才能起到更好的作用。在融合VSM模型和SAO结构时,公式(3)中参数α的确定是一个研究的难点,如果对专利进行简单分类的话,那么α取大值,说明更加偏向从整体上对专利进行分析,而忽略了专利的结构;如果对专利进行细致分类的话,那么α取小值,说明更加偏向从结构上对专利进行分析。对于本实验,将α的值从0,0.1,0.2,……,直至1,当α等于0.8时效果最好。
5 结论及展望
本文将SAO结构引入到专利的相似度计算方法中。通过对专利结构的分析,揭示了专利间的内在联系。在SAO结构中,本文分析了元组A的结构,将元组A用一个五元组来表示,使得SAO结构能更好地反应专利的内部结构。实验结果表明,在传统的基于关键词的定量分析方法中加入SAO结构,在依据IPC的大类(前三位数)、小类(前四位数)进行分类时,可以取得更好的效果。随着人们对专利分析的要求越来越高,专利分析已经从简单的基于关键词的分析,转变成基于“概念”的分析,针对这种转变,SAO结构将会在未来专利研究的过程中起到更加巨大的作用。
通过SAO结构计算专利相似度的过程中,本文是以A元组为主,弱化了S,O元组对最终计算结果的影响。接下来的工作,本研究打算先从大量专利中构建一个关于S,O元组的知识库,然后在计算专利相似度的过程中,将S,O元组也考虑进去。
[1] Bergmann I, Butzke D, Walter L, et al. Evaluating the risk of patent infringement by means of semantic patent analysis: the case of DNA chips[J]. R&D Management, 2008,38(5): 550-562.
[2] Yanhong L, Runhua T T. A text-mining-bases patent analysis in product innovative process[J]. Trends in computer aided innovation 2007: 89-96.
[3] Burke P F, Reitzig M. Measuring patent assessment quality-analyzing the degree and kind of (in)consistency in patent offices’ decision making[J]. Research Policy, 2007,36(9): 1404-1430.
[4] Lee B, Jeong Y-I. Mapping Korea’s national R&D domain of robot technology by using the co-word analysis[J]. Scientometrics,2008, 77(1): 3-19.
[5] Lee S, Lee S, Seol H, et al. Using patent information for designing new product and technology: Keyword based technology roadmapping[J]. R&D Management, 2008,38(2): 169-188.
[6] Yoon B, Park Y. A text-mining-based patent network: Analytical tool for high-technology trend[J]. The Journal of High Technology Management Research, 2004,15(1): 37-50.
[7] Moehrle M. Measures for textual patent similarities: a guided way to select appropriate approaches[J]. Scientometrics, 2010,85(1): 95-109.
[8] Xu Feng,Leng Fuhai. Patent text mining and informetricbased patent technology morphological analysis: an empirical study[J]. Technology Analysis & Strategic Management, 2012: 467-479.
[9] Savransky S D. Engineering of creativity: Introduction to TRIZ methodology of inventive problem solving[M]. London: CRC Press.2000:1-383.
[10] Altshuller G S. Creativity as an exact science: the theory of the solution of inventive problems[M]. New York: Gordon and Breach Science Publishers,1984.
[11] Michele Banko. Open information extraction for the web[D]. PHD thesis, University of Washington,2009.
[12] Thomas Lin. Leveraging Knowledge Bases in Web Text Processing[D]. PHD thesis, University of Washington,2012.
[13] Anthony Fader, Stephen Soderland, Oren Etzioni. Identifying relations for open information extraction[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing.2011.
[14] Oren Etzioni, Anthony Fader, Janara Christensen, et al. Open information extraction: the second generation[C]//Proceedings of International Joint Conference on Artificial Intelligence.2011.
[15] Mausam, Michael Schmitz, Robert Bart, et al. Open Language Learning for Information Extraction[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CONLL).2012.
[16] Goldfire Inventor, www.invention-machine.com.
[17] Cascini G. System and Method for performing functional analyses making use of a plurality of inputs[P]. European Patent Office, International Publication Number WO 03/077154 A2,2002.
[18] Tseng Y-H, Lin C-J, Lin Y-I. Text mining techniques for patent analysis[J]. Information Processing & Management, 2007,43(5): 1216-1247.
Patent Similarity Measure Based on SAO Structure
DU Yufeng, JI Duo, JIANG Lixue, ZHANG Guiping
(Knowledge Engineering Research Center, Shenyang Aerospace University, Shenyang, Liaoning 110136,China)
This paper proposes a metric for patents’ similarity based on Subject-Action-Object(SAO) structure. In contrast to the traditional approach based on key-words, this method captures the patent structure and consider the relationship among patents. To extract the SAO triple, this paper applies OLLIE, the latest entity information extraction tool, into the patent field. In addition, this paper investigates into the action element, outlining the structure of action element. Finally, this paper combines the SAO structure with the VSM module to calculate the patent similarity, achieving an improvement on the pure VSM based approach.
data mining; patent similarity; technology Subject-Action-Object(SAO); entity information extraction tool; Ollie

杜玉锋(1988—),硕士研究生,主要研究领域为信息检索。E⁃mail:DUYF1988@163.com季铎(1981—),博士研究生,副教授,主要研究领域为自然语言处理,信息检索。E⁃mail:jiduo_1@163.com姜利雪(1988—),硕士研究生,主要研究领域为信息检索。E⁃mail:jlxsnow@163.com
1003-0077(2016)01-0030-06
2013-07-10 定稿日期: 2014-00-00
国家自然科学基金(61073123);辽宁省教育厅项目(L2011031)
TP391
A
