LinkMF: 结合Linked Data的协同过滤推荐算法
2016-05-04黄山山王帅强
黄山山,马 军,郭 磊,王帅强
(山东大学 计算机科学与技术学院,山东 济南 250101;山东财经大学 计算机科学与技术学院,山东 济南 250014)
LinkMF: 结合Linked Data的协同过滤推荐算法
黄山山,马 军,郭 磊,王帅强
(山东大学 计算机科学与技术学院,山东 济南 250101;山东财经大学 计算机科学与技术学院,山东 济南 250014)
协同过滤(CF)是推荐系统中应用最为广泛的推荐算法之一,然而数据稀疏性和冷启动问题是协同过滤方法的两个主要挑战。由于Linked Data整合了关于实体的丰富且结构化的特征,可以作为额外的信息源来缓解以上两种挑战。该文中我们首次提出了结合Linked Data改进CF推荐算法,基于矩阵分解提出了一种新的CF模型——LinkMF,在保证推荐准确度的基础上利用Linked Data缓解数据稀疏性和冷启动问题。首先,我们从Linked Data中抽取项目的特征表示并为项目建模;然后提出新的相似度度量方法计算项目相似度;最后利用项目相似度约束和指导MF分解过程产生推荐。在MovielLens和YAGO标准数据集上的大量实验结果表明,LinkMF优于现有的一些CF方法,特别在缓解数据稀疏性和冷启动问题上取得很好地效果。
推荐系统;矩阵分解;Linked Data;数据稀疏性;冷启动
1 引言
随着互联网的迅猛发展和信息的爆炸式增长,用户无法从海量数据中获取对自己有用的信息,造成了信息超载的问题。同时,用户的个性化需求越来越突出,许多商业Web站点都希望能够尽量满足用户喜好,与用户建立稳固的合作关系。在这种背景下,推荐系统[1](Recommender System)应运而生,它能挖掘用户的历史行为信息发现用户兴趣,并及时主动的为用户推送与用户兴趣相符的项目。在过去的数十年中,推荐系统在学术研究和工业界都取得了长足进步,许多推荐算法被提出并得到日益完善。
协同过滤[1-2]是应用最为广泛的推荐算法之一,其基本思想是利用评分相似的最近邻居的评分数据向目标用户产生推荐,且不需要项目(item)的显式特征表示。协同过滤技术存在一些挑战: (1)冷启动问题[3]。当新用户或项目出现时,由于缺乏它们的偏好信息而无法产生推荐;(2)数据稀疏性问题[4]。当评分数据比较稀疏时,根据传统计算方法很难找到相似用户,这就导致推荐效果大大降低。以上这些问题的主要原因是数据不充分问题,为了提供有效的推荐,还需要合适并容易获取的更多数据来丰富用户或项目的表示形式。
最近几年,由于Web of Data的繁荣发展,越来越多的组织和机构通过遵循一定的规范——RDF/XML发布包含丰富信息和知识的语义数据库。这些语义数据库通过W3C的关联数据规范相互连接,使得互联网进化成一个更大的富含语义的、互联互通的知识海洋,也称为Linked Data[5]。Linked Data包含了多个领域的实体的结构化描述,例如,在电影领域,Linked Data提供了电影的导演、演员、类别、上映日期等。
这些结构化的数据可以用来建立推荐系统中项目的语义表示,从而改进传统的推荐算法。利用Linked Data设计推荐算法的研究还比较少,文献[6-8]使用Linked Data设计了基于内容过滤的推荐算法,免去了信息抽取和过滤过程,并取得了很好的推荐效果。然而,Linked Data还没有被应用于CF推荐算法。Linked Data提供了丰富的、结构化的信息,这些信息提供给我们更多额外的知识来弥补协同过滤算法中数据稀疏的问题。同样的,对于冷启动的项目,我们也可以获得除了评分以外的特征信息来为项目建模,从而提高对冷启动项目推荐的准确度。
本文探讨如何利用Linked Data来提高协同过滤推荐算法的推荐准确度,并希望能够缓解冷启动和数据稀疏性问题。目前为止,矩阵分解(MF)[9-10]是协同过滤算法中表现最好的推荐模型之一。本文基于MF模型,提出了项目相似度敏感的MF。首先,将推荐系统中的项目和Linked Data中实体对齐,并抽取特征表示;然后,根据特征表示设计合适的相似度度量方法,计算项目之间的相似度;最后,利用项目相似度获得最近邻,并约束矩阵分解过程。对比实验结果表明文中的方法具有更高的推荐准确度并能缓解数据稀疏和冷启动问题。
本文的创新性表现在: (1)首次利用Linked Data改进CF推荐算法;(2)基于MF提出了一种新的项目相似度敏感的矩阵分解算法;(3)实验证明了可以结合Linked Data缓解CF的数据稀疏和冷启动问题。
2 问题定义与相关工作
2.1 问题定义
在基于评分预测的推荐系统中,有m个用户U={u1,u2,...,um}和n个项目I={i1,i2,...,in},用户对项目的偏好信息用评分矩阵Rm×n表示。在评分矩阵中,Rij表示用户ui对项目ij的喜好,一般取值为1~5的整数。通常我们只能观测到极少部分的打分值,矩阵中99%以上的值都是缺失的[1]。推荐系统的任务是学习到一个函数f(ui,ij)能够为用户ui没有评过分的项目ij预测打分值,并把预测打分值比较高的项目推荐给ui。
2.2 相关工作
2.2.1 协同过滤
协同过滤[1-2]是最早提出、商业应用最广泛的个性化推荐算法,它利用用户的历史打分信息找到相似的用户或项目,然后基于相似的用户或项目的打分信息进行推荐。目前为止,矩阵分解[9-11]是协同过滤算法中推荐准确度最好的推荐模型。
矩阵分解的基本思想是通过将评分矩阵R分解成两个低秩的隐含特征向量P和Q,并使用P和Q的内积逼近原来的评分矩阵。评分矩阵的分解可以通过优化以下目标函数获得,如式(1)所示。
(1)
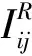
(2)
其中λP,λQ>0,是正则化项的参数。通过最小化以上目标函数就可以得到用户和项目的隐含特征向量P和Q。
MF有很多很好的性质: (1)许多优化算法比如梯度下降方法都能用于求解MF;(2)可扩展性好,可以处理百万的用户和项目;(3)有很好的灵活性,可以加入额外的因素来约束分解过程以达到更好的推荐效果。但是当评分矩阵过于稀疏或者存在新用户(项目),MF将不能产生有效的推荐结果。
2.2.2 Linked Data
Linked Data[5]是基于http URIs和语义网标准RDF将数据、信息和知识连接、发布和共享的一种技术,从而使任何人都能够借助整个互联网的计算设施和运算能力,在更大范围内,准确、高效、可靠地查找、分享、利用这些相互关联的信息和知识。在过去的几年中,越来越多的数据提供者和Web应用开发者将他们各自的数据发布到Web上,并且与其他知识库关联在一起,形成一个巨大的知识海洋。例如,DBpedia[12]、Freebase[13]、YAGO[14]等。Linked Data组织了丰富的、准确的并且结构化的数据,并提供SPARQL查询语言和其他API方便获取。
以YAGO为例,图1是从YAGO抽取出的关于实体Independence Day与其他实体和属性的关系示意图。
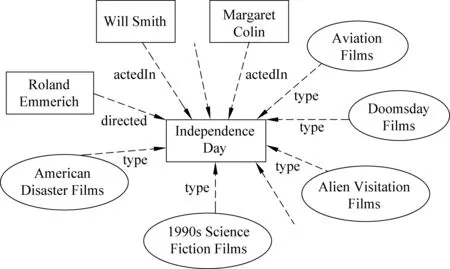
图1 Linked Data中实体与实体和属性的关系示意图
图1中方框表示实体,椭圆表示属性。图中只显示了一部分关于Independence Day与其他实体和属性的关系,其中还包括yago:created,yago:produced,yago:wasCreatedOnDate等关系。如果我们将推荐系统中的电影和YAGO的实体映射就可以获得电影的这些结构化信息来帮助推荐。
在文献[7]中,作者将Linked Data中的实体表示成集合的形式,并定义了类似于Jaccard相似度的相似度度量方式,但是并没有区分不同特征的重要性。例如,对于电影,人们通常只看type类似的电影,而不在乎演员列表是否相似。因此,为了弥补文献[7]中的不足,我们在后面提出了加权的Jaccard相似度度量方法。
3 结合Linked Data进行CF推荐
在本节中,我们基于MF利用Linked Data设计新的CF推荐算法。通过矩阵分解,我们可以得到用户和项目的隐特征向量Pi和Qj,然后基于Pi和Qj的内积预测评分。由于数据稀疏性,分解之后的项目隐特征向量不能准确代表项目的特征,从而导致预测的不准确性。在这里,我们基于这样一种假设: 在Linked Data中特征表示比较相似的项目经过矩阵分解之后对应的隐特征向量也应该是比较相似的。这样即使有些项目的打分信息很少,也可以通过约束其与相似邻居的隐特征向量近似,进而得到更准确的预测评分。基于普通的MF,我们结合Linked Data提出了项目相似度敏感的MF。
我们的工作主要包括以下部分: (1)将项目映射到Linked Data的实体,抽取相关特征为项目建模并定义相似度度量方式找到项目的最近邻;(2)利用项目最近邻约束矩阵分解,并进行推荐。下面我们依次介绍每个部分的主要工作。
3.1 在Linked Data中实体的特征表示
在文献[7]中,Linked Data中的实体被表示成集合的形式,但是没有区分不同类型的特征,类似的,我们定义了新的实体表示形式。
定义 1(Linked Data中实体特征表示)Linked Data是一个有多种链接类型的有向标记图G=(V1∪V2,A,L),其中V1为实体集合,V2为V1中实体的属性集合,A为G的有向边集,L={l1,l2,...,l|L|}表示link的类型集合。∀v1∈V1,v2∈V1∪V2,
例如,根据图1,F(Independence Day)={(directed, Roland Emmerich),(actedIn, Will Smith),(actedIn, Margaret Colin),(type, Aviation Films),(type, Doomsday Films),...}。在应用中,我们将在推荐系统中被推荐的对象和Linked Data中实体对齐并抽取特征表示,将项目按照以上形式为项目建模。
3.2 实体的相似度度量——加权Jaccard相似度
为讨论方便起见,推荐系统中的项目最多对应G中的一个实体。对于推荐系统中的两个项目,如果能分别映射到Linked Data中的实体vi和vj,就可以获得它们的特征表示F(vi)和F(vj)。Jaccard相似度是衡量集合相似度的常用度量方式,如2.2.2节所述,传统的Jaccard相似度没有考虑不同特征的重要性,使得相似度计算结果不尽人意。为了弥补文献[7]中的不足,我们提出了加权的Jaccard相似度度量方法。如果两个项目在重要性高的特征类型上拥有更多相同的特征,那么这两个项目越相似。
不同的特征类型对描述项目起到的重要程度可能不同,例如,电影的导演和上映日期。我们将F(v)按照|L|种不同的类型细分为F(v)=Fl1(v)∪Fl2(v)∪…∪Fl|L|(v),其中Fli(v)表示只与link类型为li相关的特征集合,有些link的特征集合可能为空。我们为不同link类型赋予不同的权值w={w1,w2,…,w|L|},满足‖w‖1=1。
另外,在Fli(v)中,不同的特征值包含的信息量是不同的。定义若f∈Fli(v),我们用类似于IDF的方式定义特征值f的信息量如式(3)所示。
(3)
其中n是推荐系统中能找到对应实体的数目,φf表示拥有特征值f的项目数目。如果拥有特征值f的项目越多,则f的IC(f)值越小。
衡量任意的两个实体的相似度时,∀vi,vj∈V1,定义vi和vj之间加权Jaccard相似度如式(4)所示。
(4)
对能够找到Linked Data中对应实体的项目,我们就可以计算两两之间的相似度。将项目之间的相似度表示成矩阵S,为了方便和计算效率,对任意项目i,我们只保留相似度最大的若干邻居项目,比如20个相似度最大的项目形成邻居集合N(i)。我们设置其余项目的相似度值为0,并进行行归一化使得∑Si,j=1。
3.3 项目相似度敏感的MF算法
最近几年,由于社交网络的迅速发展和普及,有些研究者利用用户的社会关系[15]或信任关系[16]来约束MF中用户隐特征向量的分解,并取得了很好的推荐效果。由于一般网站不提供建立社会或信任关系的功能和隐私保护的问题,很难获得关于用户的社交网络或信任网络。在本节中我们通过上节计算得到的项目之间的相似度关系来约束和指导MF中项目隐特征向量的分解,设计项目相似度敏感的MF算法。
我们基于这样一种假设: 在LinkedData显式特征上相似的项目在矩阵分解得到的隐特征向量上也应该是相似的。在这里我们根据项目之间的相似度提出两种不同的约束方法。
3.3.1 基于平均的相似度约束方法
在矩阵分解模型中,项目隐特征向量之间是相互独立的。然而,这种假设是不准确的。一些显式特征上比较相似的项目在分解之后的隐特征向量也应该是相近的。如果对一个项目观测到的打分值比较少,而它的相似邻居的打分值比较多,我们可以约束它与相似邻居的隐特征向量相近,使得这个项目得到与它的相似邻居相似的推荐结果。
具体地,我们根据项目在LinkedData中的显式特征计算相似度并得到项目ij的邻居集合,那么项目ij的隐特征向量应该和它邻居集合的平均隐特征向量相似,这种关系可以表示为式(5)。
(5)
其中N(j)表示项目ij的邻居集合,ij的隐特征向量表示为邻居项目隐特征向量的加权平均。因此,我们可以在目标函数(2)上加入约束项得到以下目标函数,如式(6)所示。
(6)
其中α>0,代表了项目ij多大程度上依赖于其邻居集合。式(6)约束矩阵分解过程使得项目的隐特征向量不是相互独立的,而是接近于相似邻居集合的隐特征向量的平均值。
可以通过梯度下降的方法迭代更新Pi和Qj得到目标函数(6)的局部极小值,如式(7)所示。
(7)
3.3.2 基于个体的相似度约束方法
在3.2.1节中,我们对矩阵分解进行约束使得vj的隐特征向量与邻居集合中的项目的隐特征向量的加权平均近似,这往往会导致信息的丢失。例如,一个项目i的邻居集合是{ii,ij,ik},相似度分别为0.6,0.3,0.3,它们的隐特征向量分别为[0.1,0.1]T,[1,1]T,[2,2]T。按照3.2.1节,项目i的隐特征向量应该近似为[0.96,0.96]T,这样就偏离了与它较为相似的项目的隐特征向量。尤其对比较独特的项目,与它相似的项目并不多,如果使用邻居集合中的项目的隐特征向量的加权平均更会得到偏离的结果,导致分解结果的不准确。
为了解决上述问题,我们又提出了基于个体的相似度约束方法。项目ij应该和相似度较大的邻居在隐特征空间中更为相似,而与相似度较小的邻居可以不太相似。因此,对邻居集合上的项目应该按照不同的权重给予不同的约束强度。相对应地,我们在目标函数(2)上加入以下约束,如式(8)所示。
(8)
其中β>0,与式(6)的α作用一致。当Sj,k比较大时,Qj和Qk应该更为接近。我们的目标函数变为式(9)。
(9)
同样的,通过梯度下降的方法迭代更新Pi和Qj来求得局部极小值,如式(10)所示。
(10)
3.4 模型复杂度分析
4 实验
4.1 实验准备
4.1.1 数据集和评价标准
我们选用了MovieLens-100k评分数据集和YAGO知识库作为Linked Data信息来源。Movie-Lens-100k包括943个用户和1 682个电影,每个用户至少给20个电影评过分,打分取值为1~5之间的整数。首先我们需要将MovieLens中的电影 title 映射到YAGO的entity并获取对应的特征表示。1 682个电影中有1 437个电影找到了匹配对象并抽取了电影的yago:type、yago:directed和yago:actedIn特征。
在实验中,我们采取五折交叉验证的方法,其中评分数据的80%作为训练集,剩余20%作为测试集。在基于评分预测的推荐系统中,均方根误差(RMSE)是最常用的准确性度量标准,RMSE定义为式(11)。
(11)
4.1.2 比较的方法
为了说明我们方法的有效性,我们将实现以下方法并比较推荐结果的准确性。
• Item-CF: 基于项目的协同过滤算法[2],采用pearson相似度,邻居数目设为10;
• CBCF: 结合基于内容和基于协同过滤的混合推荐算法[17];
• MF:在文献[11]中提出的基本的矩阵分解算法;
• LinkMF1-type:使用基于平均的相似度约束方法,只使用yago:type特征;
• LinkMF1-all:使用基于平均的相似度约束方法,利用yago:type、yago:directed和yago:actedIn特征,使用加权的Jaccard相似度度量方法;
• LinkMF2-type:使用基于个体的相似度约束方法,只使用yago:type特征;
• LinkMF2-all:使用基于个体的相似度约束方法,利用yago:type、yago:directed和yago:actedIn特征,使用加权的Jaccard相似度度量方法;
在以上模型中,我们设置矩阵分解的维度为20,λP=λQ=0.1,学习速率为0.0001。在使用加权的Jaccard 相似度度量方法中,通过几次实验,我们选取了推荐结果最好的权重分配,type、directed和actedIn特征权重分别为0.5、0.3和0.2。
4.2 实验结果与分析
4.2.1 参数选择
在我们的模型中,α和β控制了邻居项目集合对项目隐特征向量的影响程度。当α和β趋于0时,模型近似于基本的MF;当α和β越大时,项目隐特征向量受邻居项目集合的影响越大。图2显示了随着α和β变化时LinkMF1和LinkMF2两种不同模型在测试集的RMSE值的变化趋势。
从图2的两个图中可以看出,随着α和β逐渐增加时,RMSE都是先减小后逐渐增大,在α=β=0.3附近时取得最小值。因此可以说明结合Linked Data的项目特征可以提高推荐的准确度。当β>0.3时,LinkMF2-type和LinkMF2-all的RMSE值增加幅度相对比较大,这是因为待预测项目的隐特征向量与最相似邻居更为接近而偏离了自身的隐含特征使得推荐准确度下降。在后面的实验中,我们设置α=β=0.3。
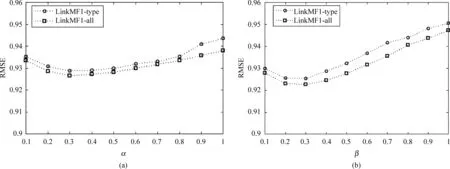
图2 不同的α和β值对推荐结果的影响
4.2.2 不同方法推荐效果比较
在实际的推荐系统中,数据稀疏度一般达到99%以上,因此在非常稀疏的数据集上能否取得较高的推荐准确度是衡量一个推荐算法实用性的重要指标。为了产生不同稀疏度的数据集,我们从Movie-Lens中分别抽取80%、60%和40%的评分数据作为训练集,这样,我们得到数据稀疏度分别为94.96%、96.22%和97.48%的数据集。表1比较了不同推荐算法在不同稀疏度的数据集上的推荐效果。
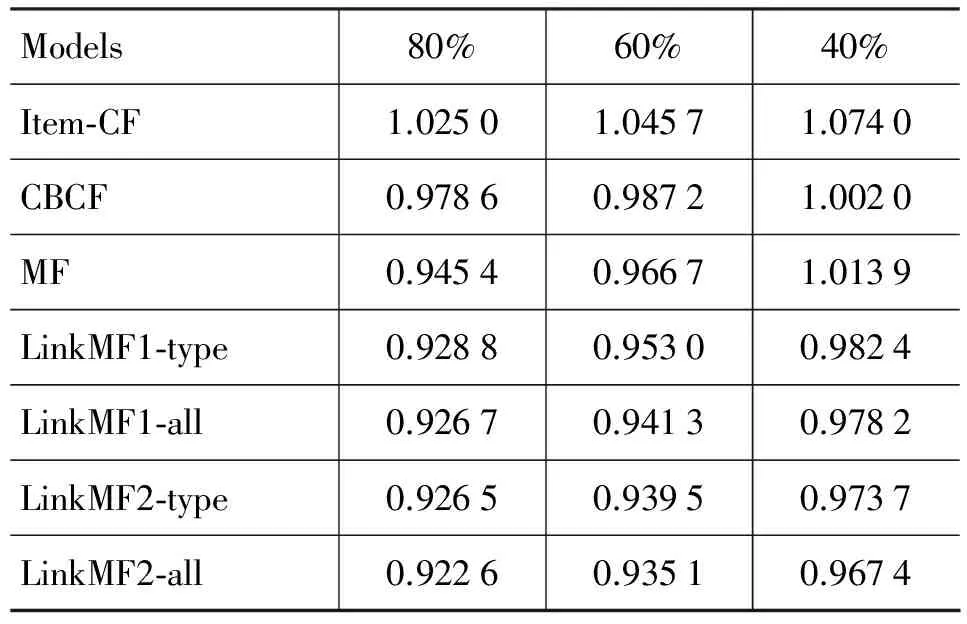
表1 不同推荐算法在不同稀疏度的数据集上的RMSE值
从表1中可以看到我们提出的模型比Item-CF和MF的推荐准确度都高,说明了结合Linked Data能比传统的协同过滤算法取得更好的推荐结果。而且,我们提出的模型比混合推荐算法CBCF也要好,LinkMF2-all始终能够取得最好的推荐效果。当训练集变得更稀疏时,所有的推荐算法的推荐准确度都有所下降,然而我们的模型下降幅度不大且推荐准确度仍然较高,说明了使用项目相似度来约束MF能够从一定程度上缓解数据稀疏问题。
从表1中还可以观察到使用全部的信息计算项目相似度来约束MF比只使用type信息能取得更高的准确性。而且基于个体的相似度约束方法比基于平均的相似度约束方法要好,这是因为基于平均的相似度约束方法使用加权平均而丧失了部分信息。
4.2.3 冷启动项目的推荐效果
在商务网站中,一般都存在长尾效应,这是由于大部分商品的购买人数和评分很少,从而处于“尾部”的商品很难被推荐出去。处于尾部的商品占了总商品数目的80%以上,提高对这些商品的推荐准确度能提高长尾商品的销售量,从而增加网站的利润。本实验中,我们使用80%作为训练集,将训练集中打分少于五个和十个的项目作为冷启动项目,比较不同推荐算法预测用户对冷启动项目打分的准确度。其中打分少于五个和十的项目分别占全部项目的25.6%和35.7%。
从图3中可以看出,对冷启动项目推荐时,混合推荐算法CBCF比Item-CF要好,这是因为CBCF首先利用基于内容的推荐算法对评分矩阵填充,给冷启动项目更多的打分。我们的模型要比基本的Item-CF、MF和CBCF推荐准确度都要高。其中LinkMF2-all的效果最好,与Item-CF和MF方法相比分别提高了16.2%和11.15%,相对于全部项目的提高幅度更高。
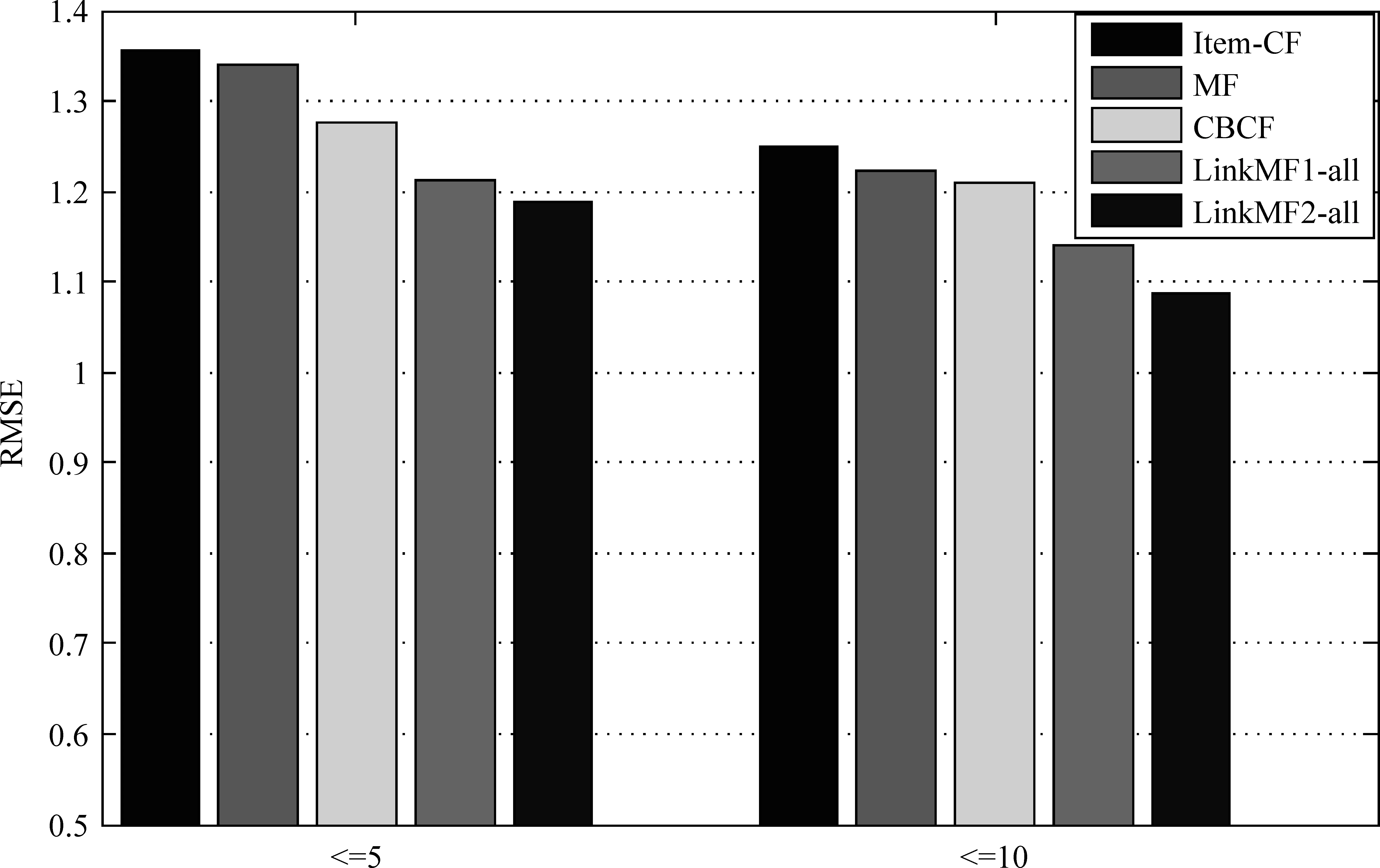
图3 对冷启动项目的推荐准确度比较
实验中我们还观察到随着α和β增大时,LinkMF模型对冷启动项目推荐时的RMSE逐渐减小,这是因为对冷启动项目的打分记录太少,需要更多的依赖于邻居项目才能更准确的预测评分。因此,在实际系统中,可以针对冷启动项目和非冷启动项目赋予不同的α和β值,这样可以进一步提高推荐准确度。
5 总结
为了缓解推荐系统中数据稀疏和冷启动问题,本文提出使用Linked Data提供的丰富的、结构化的信息设计项目相似度敏感的矩阵分解算法。通过分析在MovieLens-100k和YAGO上的实验结果,我们得出以下结论: (1)本文提出的两种模型在RMSE度量指标上优于基于项目的协同过滤方法和基本的矩阵分解算法;(2)我们的方法在比较稀疏的数据集上仍能够取得较好的推荐准确度;(3)利用Linked Data提供的信息能够缓解项目的冷启动问题,准确度提高11%以上;(4)基于个体的相似度约束方法比基于平均的相似度约束方法推荐性能要好;(5)利用更多的信息计算相似度可以提高推荐准确度。在以后工作中,我们希望能在更大数据集和其他推荐领域验证我们方法的有效性。
[1] G Adomavicius, A Tuzhilin. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions[C]//Proceedings of the IEEE Transactions on Knowledge and Data Engineering, 2005, 17(6):734-749.
[2] G Linden, B Smith, J York. Amazon.com recommendations: Item-to-item collaborative filtering[C]//Proceedings of the IEEE Internet Comput., 2003, 7(1):76-80.
[3] P Cremonesi, R Turrin. Analysis of cold-start recommendations in IPTV systems[C]//Proceedings of the RecSys, 2009: 233-236.
[4] 赵琴琴,鲁凯,王斌.SPCF: 一种基于内存的传播式协同过滤推荐算法[J].计算机学报,2013, 3:671-676.
[5] C Bizer, T Heath, T Berners-Lee. Linked data—the story so far[C]//Proceedings of the IJSWIS, 2009, 5(3):1-22.
[6] T Di Noia, R Mirizzi, V C Ostuni, et al. Linked open data to support content-based recommender systems[C]//Proceedings of the International Conference on Semantic Systems. 2012: 1-8.
[7] R Meymandpour, J G Davis. Recommendations using linked data[C]//Proceedings of the 5th PhD. workshop on Information and knowledge. ACM, 2012,8(4): 75-82.
[8] R Mirizzi, T Di Noia, A Ragone, et al. Movie recommendation with dbpedia[C]//Proceedings of the IIR, 2012.
[9] Y Koren, R Bell, C Volinsky. Matrix factorization techniques for recommender systems[C]//Proceedings of the Computer, 2009, 42(8):30-37.
[10] G Dror, N Koenigstein, Y Koren. Web-Scale Media Recommendation System[C]//Proceedings of the IEEE, 2012, 100(9): 2722-2736.
[11] R Salakhutdinov, A Mnih. Probabilistic matrix factorization. NIPS, 2008, 20: 1257-1264.
[12] C Bizer, J Lehmann, G Kobilarov, et al. Dbpedia—A crystallizationpoint for the Web of Data[J]. Journal of Web Semantics, 2009, 7(3): 154-165.
[13] K Bollacker, C Evans, P Paritosh, et al. Freebase: a collaboratively created graph database for structuring human knowledge[C]//Proceedings of the SIGMOD, 2008: 1247-1250.
[14] F M Suchanek, G Kasneci, G Weikum. Yago: a core of semantic knowledge[C]//Proceedings of the WWW, 2007: 697-706.
[15] H Ma, D Y Zhou, C Liu, et al. Recommender systems with social regularization[C]//Proceedings of the WSDM, 2011: 287-296.
[16] M Jamali,M Ester. A matrix factorization technique with trust propagation for recommendation in social networks[C]//Proceedings of the RecSys, 2010: 135-142.
[17] P Melville, R J Mooney, R Nagarajan. Content-boosted collaborative filtering for improved recommendations[C]//Proceedings of the 18th National Conference on Artificial Intelligence, 2002: 187-192.
LinkMF: Collaborative Filtering Recommendation Algorithm with Linked Data
HUANG Shanshan, MA Jun, GUO Lei, WANG Shuaiqiang
(School of Computer and Science Technology, Shandong University, Jinan, Shandong 250101, China; School of Computer and Science Technology, Shandong University of Fiance & Economic, Jinan, Shandong 250014, China)
Collaborative filtering (CF) is one of the most popular recommendation techniques in application. However data sparsity and cold start remain as two challenges in CF applications. Since Linked Data integrates rich and structured features about entities, this paper proposes the idea of leveraging Linked Data to improve CF recommendation algorithm. Based on matrix factorization (MF), we develope a novel CF model denoted as LinkMF, incorporating structured Linked Data to mediate data sparsity and cold start problems while preserving recommendation accuracy. In particular, we extract features from the Linked Data and construct the item profiles; then we propose new similarity metrics for dufferent items; and, finally, we incorporate the obtained item similarities into the basic MF model to constrain and improve the factorization process. Comprehensive experiments on MovieLens and YAGO benchmark datasets demonstrate the promising results of the LinkMF compared with the state-of-the-art CF models, especially in the data sparsity and cold start scenarios.
recommender systems; matrix factorization; Linked Data; data sparsity; cold start

黄山山(1990—),博士,主要研究领域为推荐系统、知识库和数据分析。E⁃mail:huangshanshansdu@163.com马军(1956—),博士,博士生导师,主要研究领域为信息检索、社会网络分析、推荐系统和数据挖掘等。E⁃mail:majun@sdu.edu.cn郭磊(1983—),博士,讲师,主要研究领域为推荐系统和社会计算。E⁃mail:leiguo.cs@hotmail.com
1003-0077(2016)01-0085-08
2013-07-16 定稿日期: 2014-05-08
国家自然科学基金(61272240,60970047,61103151),山东省自然科学基金(ZR2012FM037),山东省优秀中青年科学家科研奖励基金(BS2012DX017)
TP391
A
