网络游戏案例研究:用户行为分析和流失预测
2016-05-04过岩巍吴悦昕闫宏飞黄建兴
过岩巍,吴悦昕,赵 鑫,闫宏飞,黄建兴
(1. 北京大学 计算机科学与技术系,北京 100871; 2. 上海人人游戏科技发展有限公司,北京 100015)
网络游戏案例研究:用户行为分析和流失预测
过岩巍1,吴悦昕1,赵 鑫1,闫宏飞1,黄建兴2
(1. 北京大学 计算机科学与技术系,北京 100871; 2. 上海人人游戏科技发展有限公司,北京 100015)
用户流失预测在很多领域得到关注,目前主流的用户流失预测方法是使用分类法。网络游戏领域发展迅猛,但用户特征选取、特征处理和流失预测的相关研究较少。本文以一款网页网络游戏的用户记录为数据,对用户游戏行为进行分析对比,发现流失用户在游戏投入、博彩热情、玩家互动方面与正常用户存在显著差异;同时发现网络游戏数据存在样本分布不平衡、候选特征库庞大和干扰差异多等难点。在此分析基础上,本文探讨了网游用户的关键特征提取的关注方向,以及归一化和对齐化在特征处理中的关键作用。实验表明,本文提取的特征具有很好的区分度。
行为分析;特征提取;流失预测;网络游戏
1 引言
用户流失预测是一个被广泛关注的重要而困难的问题,在电信[1]、银行[2]、电子商务[3]等领域,有大量的相关研究。文献[1]表明,在电信业内赢得一个新客户所花费的成本约为300到600美元,大约是保留一个老客户所需成本的5~6倍。而在网络游戏领域的情况与电信领域是相似的。目前网络游戏的收费形式是以道具收费为主。这种收费方式的特点是游戏的基本内容免费,而对可选的游戏要素收费。此类游戏通过收费项目为用户提供便利,而部分用户也愿意为附加游戏要素付费以迅速提高游戏实力。这类游戏的主要收入来自于付费用户,尤其是频繁、大量地在游戏中消费的高付费用户。高付费用户数量占总数很小的比例,却是游戏运营商的主要来源。所以,在网络游戏领域,高付费用户流失预测是具有价值的研究问题。
通过考察用户流失预测的相关研究,发现目前对此类问题主流的处理思路是将其看作二分类的问题,使用有监督的机器学习方法来为用户标记类别。例如,文献[1-2,4]采用支持向量机,学习出支持向量用以分类;文献[5-6]采用逻辑回归,学习特征权重;文献[4,7-8]使用神经网络模型,模拟人类神经元相互作用;文献[4,9]使用决策树,在层层分支后给样本标记;文献[10-11]采用隐马尔可夫回归,将单状态回归拓展到多状态。
在用户流失预测问题中,特征提取是第一步。分析用户特征可从多方面入手: 文献[1,12]考察手机用户的消费情况,文献[3,12]关注用户的个人信息,文献[13]考察用户在角色扮演游戏中的动机。但这些文献几乎没有说明选择这些特征的原因。据我们所知,目前少有研究探讨如何提取网游用户的关键行为特征。因此,研究网游用户流失预测问题的首要挑战是梳理和分析庞大的原始用户游戏记录数据,从中找到可以有助于流失预测的信息并提炼出训练特征。然而,在网游数据中提取关键的特征是一项非常有挑战性的工作,以本文研究的游戏数据为例,原始记录共有32个数据表,每个表包含的具体游戏操作从两个到61个不等,共283个,即使只考虑直接操作,就有283个特征可供选择,若再考虑各种组合操作,则候选特征库将以指数级速度增长。
在对特定游戏分析用户游戏行为过程中,第二个挑战是: 网游用户流失分类具有以下难点: 1)类别标记难。流失用户没有标准的定义,随时间发展,用户可能在流失与非流失两个状态之间发生多次变动;2)数据不平衡。实际流失用户数量大大小于非流失用户数量,这种正常现象会影响机器学习方法的学习效果;3)样本容量小。单个服务器*支持一组用户在同一个环境里进行游戏的设备。相同服务器内的用户可以进行游戏交互,不同服务器的用户一般不能进行交互。平均70个用户*数据针对本文的特定游戏而言,这样的样本集容量过小不具说服力;4)干扰差异多。存在用户流失日期差异、开服*服务器开始投入使用时间差异和版本更新差异干扰。
通过对游戏数据的分析,本文探讨了网游用户特征提取的关注方向以及应对上述难点的特征处理方法。在本文后续叙述中,用户特指网游高付费用户。本文组织如下: 第二节描述用户流失预测问题并对用户数据进行挖掘分析;第三节介绍特征的提取和处理方法;第四节介绍实验设置和实验结果;最后对全文进行了总结,并介绍未来工作。
2 用户流失预测问题描述及行为分析
2.1 问题描述
用户进行游戏会产生许多游戏行为,最直接的结果就是在游戏服务器上产生大量的记录数据。游戏行为与用户游戏时的状态有关: 被游戏深深吸引时,用户投入大量时间,操作频繁且行为丰富;对游戏失去兴趣将离开时,用户往往减少游戏时间,不再喜好操作游戏。反过来,记录数据在很大程度上能反映用户游戏的状态。在上述背景知识下,用户流失预测问题形式化描述如下。
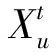
(1)
2.2用户类别划分
在分析不同类别的用户之间的差异之前,需先确定用户的类别归属。我们假设用户在离开游戏之前会表现出一定异常,该阶段称为流失倾向阶段。由于性格、年龄、职业以及其他不确定因素的影响,不同用户在流失倾向阶段的特点不同: 有的用户流失倾向明显且持续时间较长;而有的用户没有这一阶段或表现不明显,呈现突然离开游戏的现象。因此流失倾向阶段很难把握。我们从流失日期入手,将流失用户定义为永久性离开游戏或是偶尔(数天不足一次)登入游戏的用户。从这种定义出发,我们用以下启发式方法判定流失用户。
将用户u按时间顺序最近的k次登入日期记为t1、t2、…、tk,连续两次登入日期ti和ti+1之差记为di。记当前日期为tnow,用户最后一次正常登入日期为tu,last,则
(2)
式(2)中β是一个整数阈值,即如果存在一个最小的i使得di大于β,则tu,last置为ti,否则将tu,last置为tnow。可将tu,last之后的时间视为用户u已流失。这样做的好处是排除偶尔登入游戏的用户干扰。
用户类别标签按如下定义:
(3)
式(3)中,μupper和μlower分别是为tnow与tu,last之差设定的上下界阈值。介于μupper和μlower之间的用户的类别不好判断,舍弃这部分数据以减小标记误差。
对于流失用户而言,假设在其tlast之前T天表现出差异于非流失玩家的游戏行为。这个长度为T的阶段作为流失用户特征采样区间。为了达到提前预测的效果,可以将tu,last提前tahead天,tahead为自由参数。非流失用户采样区间在3.2节介绍。
2.3 用户行为分析
在人人游戏公司*http://www.renren.com/siteinfo/about支持下,我们得到该公司运营的一款网页网络游戏《乱世天下》*http://lstx.renren.com/从2011年9月至2012年8月的游戏记录数据。该游戏基于三国题材,以培养武将参与战斗为主要游戏内容。我们以公司提供的高付费用户名单上的用户的游戏记录作为数据集。按照上述用户类别划分法进行用户划分(取k=10,β=5,μupper=10,μlower=3),之后对用户整体情况以及两类用户的游戏行为差异进行了统计分析。
2.3.1 数据整体情况
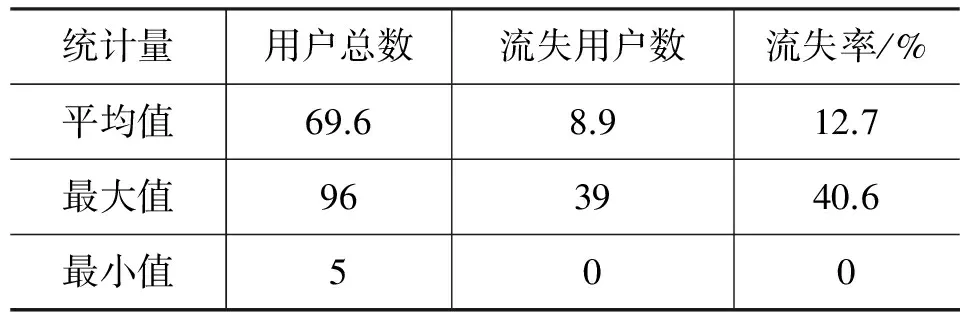
表1 单个服务器用户数量概况
用户数量分布不均: 数据集中共56个服务器,3 898个用户。其中496个流失用户,占用户总数12.7%,即流失率。流失用户与非流失用户分布不均衡在日常生活中是正常现象,但就分类而言,不均衡训练集会造成模型误差而影响分类效果。另外一个分布不平衡表现在服务器之间。单服用户数量统计如表1所示。从表1可以发现: 1)单个服务器的用户数量很少,这符合当前网页游戏市场情况: 网页游戏同等替代产品非常多,一款游戏所占市场比例很小;2)服务器之间差异较大,无论是用户数量还是流失率差异可达近两个数量级。以上两点决定了单个服务器的数据不适合单独作为数据集。
游戏操作行为丰富: 原始数据记录共有32个数据表,每个表包含的具体游戏操作从两个到61个不等,共283个。若仅仅考虑直接操作,就有283个特征可供选择。若再考虑组合操作,例如,1)用户相邻的登入游戏和登出游戏记录之间的时间差是在线时间长度;2)两个用户加入队伍的记录中队伍号码*游戏记录中用以标识队伍的变量相同表明二者发生了组队交互;3)用户在某天有关虚拟货币记录中的消耗量之和为该用户该天的虚拟货币支出总量,等等。通过计算多条记录而获取用户某方面信息的组合方式,则候选特征库大小将以指数级速度增长。其中有助于甄别流失用户的特征才是有价值的。
追求实力水平提升: 我们发现,用户每日进行最多的操作是战斗,平均每人每天进行44.2次,占游戏记录数10.1%,这是游戏的主要内容。除去与战斗相关的记录,记录数量最多的是关于武将的培养,占比5.5%,这是用户在游戏中提升实力水平的主要途径。可以总结,用户愿意为游戏内容的进展而提高游戏水平,推进游戏进度和提升游戏水平是用户游戏的目标。从投入和产出的角度来看,用户的游戏水平可视为其投入时间与金钱的产出。在我们的数据中,用户每月投入游戏的金钱人均值为4 258元,人均每天游戏在线时间8.75小时。通过我们亲身在该游戏中的体验,确认这部分投入量巨大的用户的游戏实力水平是最高的。
博彩要素深受欢迎: 在游戏中不乏热衷于依靠运气的博彩的用户。游戏开发者就是基于用户的这种爱好设计了与抽奖类似的概率事件: 用户付出一定费用则有概率获得高级物品。在我们研究的游戏中,有两点关于博彩的发现: 1)数量排行第三的记录是道具淘宝*一种与抽奖类似的行为,平均每人每天进行15.3次,占3.5%。数量排行紧接着的行为是出售道具,占3.4%。说明用户对淘宝获得的极大部分道具都不满意;2)用户在游戏中虚拟货币支出最多的操作是刷新任务*有概率刷出价值不等的游戏道具,人均支出量占虚拟货币总支出量44.5%。
流失日期线性分布: 第一个与最后一个流失用户的tlast之差为180。以第一个流失用户的tlast作为原点,截至日期t的用户流失总量与t的关系如图1所示。图1中横纵坐标变量呈现近似线性关系。在这181天中流失用户较均匀地离开游戏,因此在较短的时间窗口内流失用户的个数很少,平均每月为82人。这决定了不能在短期阶段截取数据作为样本。

图1 流失用户累积数量
2.3.2 用户类别差异
我们最大的发现是流失用户在流失倾向阶段游戏操作递减。我们将用户在tlast之前120天的游戏操作总数进行统计,按类别平均,结果如图2所示。
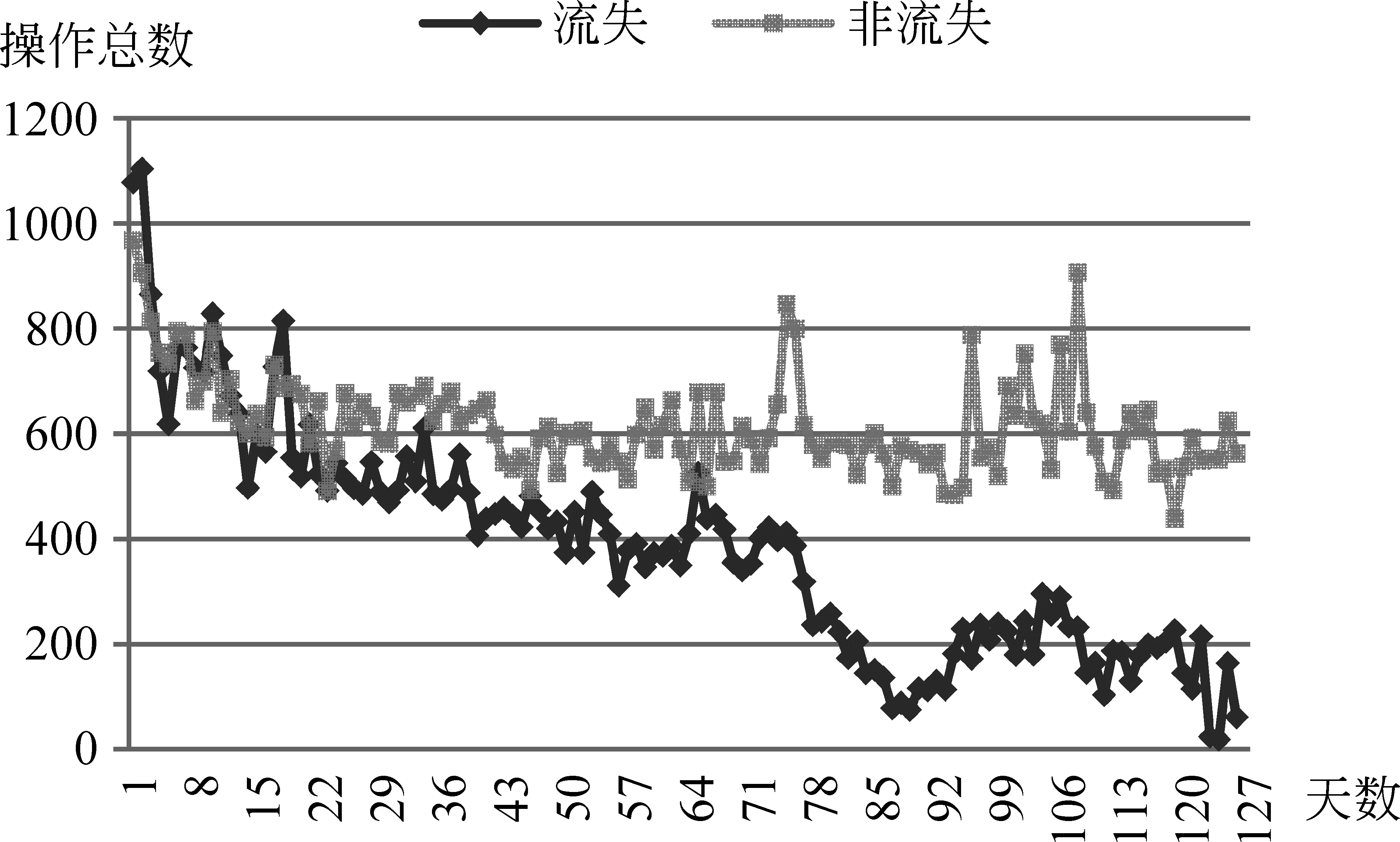
图2 最后120天用户人均记录数
从图中可以发现: 1)非流失用户每日的游戏操作数基本稳定;2)流失用户游戏操作逐日递减,到后期与非流失玩家存在显著差异。这说明了大部分要离开游戏的用户在游戏中操作减少。这也验证了我们关于流失倾向阶段假设的合理性。从投入和产出的角度考虑,我们考察了流失用户时间和金钱投入情况,得到以下数据: 流失用户最后一个月投入游戏的金钱人均值为1 154元,人均每天游戏时间5.43小时。与上一节中整体情况对比,即将流失的用户对游戏的投入大量减少。
为探究细节,我们将用户在tlast之前30天的各种操作记录进行统计和比较,图3给出了这一个月内用户主要15项操作情况。
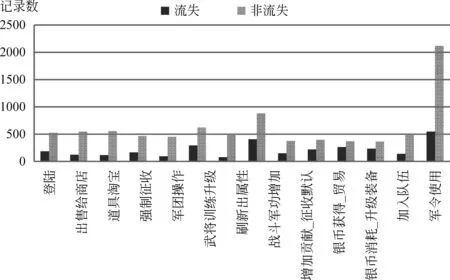
图3 最后30天部分游戏操作人均数量
可以发现: 1)流失用户主要游戏行为不变,依然是使用军令战斗。说明游戏的设定决定了游戏的基本内容,很难有较大的变动;2)流失用户操作数在绝对数上减少, 但大部分操作在相对数上没有明显变化,即各种操作基本上成比例减少;3)与其他操作不同,道具淘宝、刷出新属性、军团操作、加入队伍四个操作减少的幅度相对较大。前两个操作是依靠运气的博彩行为,后两个是与其他用户的交互行为。这说明。当用户有离开游戏的打算时对博彩和交互的热情明显下降。
从以上的分析中,我们不仅发现整体用户在数据集构成和游戏行为上的特点, 还挖掘出流失用户在游戏投入、博彩热情、玩家互动方面与正常指标存在显著差异。因此,我们提出在用户流失预测任务中,特征选取应重点考察游戏投入、博彩热情、玩家互动方向。
3 特征向量的选取和处理
3.1 特征选取
在数据分析基础上,我们发现平均而言流失用户在流失倾向阶段与非流失用户存在能够量化的差异,且应该关注用户的游戏投入、博彩、交互等方面。按照此思路,我们初步提取出17个特征用于区分流失用户与非流失用户。
初选的特征集可能存在冗余,如何用较少的特征降低训练成本而不明显影响训练效果是值得研究的问题。为精简特征,我们采用信息增益[12](InformationGain,IG)指标对特征在区分两类玩家的能力上进行评价,淘汰掉排名靠后的那些特征。通过信息增益的淘汰和实验,我们认为六个特征对于判别流失用户具有重要意义。具体实验在第四节介绍。表2描述了选出的特征。

表2 特征向量简介
① 多个用户组成的团体
3.2 特征处理
简单提取出特征向量,并不能有效发挥分类器的分类功能,也不能从大量用户中正确筛选出有流失倾向个体。这是因为: 1)直接将记录数值作为特征,导致不同的行为记录单位和数量级不同。例如,在线时间的单位为秒,数量级一般在10 000左右,而武将操作数量级一般是10。特征空间分布不平衡会导致部分特征失效,甚至学习障碍;2)流失用户流失日期不尽相同,即时间差异;3)服务器开服时间不同导致不同服的用户游戏进展不同,即服务器差异;4)版本更新游戏内容变化可能导致游戏行为发生极大变动,即版本差异。
上述2)~4)都会导致在不同阶段主流用户正常的游戏行为发生改变,多种差异的存在会干扰用户类别差异的学习。完美的数据集应该是同一个服务器在一段较小的时间窗口(例如,一个月)内的用户记录。但如前所述,许多网页游戏不能提供这样的数据集。因此对输入的特征向量进行处理是必不可少的。为排除干扰差异的影响,我们提出了单服归一和区间对齐两种处理方式。
3.2.1 单服归一
网络游戏的一大特点是其游戏内容会随时间展开发生变化,服务器差异、游戏进度差异、版本差异体现了这种变化。因而不同的服务器用户在相同时间段内正常游戏行为存在差异,相同的服务器用户在不同的时间阶段的正常游戏行为也存在差异,这给判别异常带来困难。
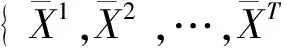
(4)
3.2.2 区间对齐
流失用户的采样区间是第二节中所述的流失倾向阶段,但非流失用户没有这一阶段。如果按照与流失用户同样的方法来选定采样区间,则所有非流失用户的采样区间都是数据集上的最后T天。那么就形成了这样一种现象: 非流失用户的特征从同一个时间阶段抽取,流失用户的特征来自分散的时间阶段。如前所述,时间差异会干扰分类,无形中增加了流失用户和非流失用户的差异。
为了排除干扰差异,我们提出区间对齐处理: 对于非流失用户ua,我们随机为其在同一个服务器内挑选一个流失用户ub,ub的采样区间为第二节所述的流失倾向阶段,ua的采样区间与ub对齐,选取同样一段时间窗口。我们进行了五次随机对齐进行实验,最终结果是五次实验的平均值。
4 实验设置与结果分析
4.1 实验工具、数据和评价指标
支持向量机(SVM)是目前实践效果最好的分类器之一。因此在实验中我们选择以RBF[13]为核函数的SVM分类器*http://www.csie.ntu.edu.tw/~cjlin/libsvm/。将第二节中所述的《乱世天下》数据集同时作为分类器的训练集和测试集,采用十倍交叉验证法(10-foldCrossValidation)。注意该数据集类别分布不平衡,不平衡数据集会损害分类能力。解决数据不平衡可在训练之前进行,如文献[14-15]中的采样法,也可在训练时对少数类别进行补偿,如文献[16]中的代价敏感参数法。对不平衡数据的处理方法将作为我们的未来工作,本文中不再讨论。本文采用简单的代价敏感参数法,在训练时将流失用户与非流失用户的权重比值设为3.5。
由于更关注流失用户的预测情况,因此我们采用与评价搜索引擎结果类似的指标: 正确率、召回率、F值[17]。对照如表3所示。

表3 联表
正确率P定义是预测为流失的用户中实际流失的比例,即TP/(TP+FP);召回率R定义是所有流失用户中被准确预测的比例,即TP/(TP+FN);F值是正确率与召回率的调和平均值,即PR/(αR+(1-α)P),0≤α≤1,本文中α取0.5,意味着正确率和召回率同等重要。
4.2 特征选取和处理的有效性
我们令T=6,tahead=4,进行了四组互为参照的实验来验证特征选取及处理的效果。基准组为进行单服归一和区间对齐的六个特征值,记为Criterion。另外三组作为对照,与Criterion仅存在一处差别,分别为: 1)Feature17,采用IG过滤之前的17个特征;2)NotNormalized,未进行单服归一;3)Not-Aligned,未进行区间对齐。实验结果如表4所示。
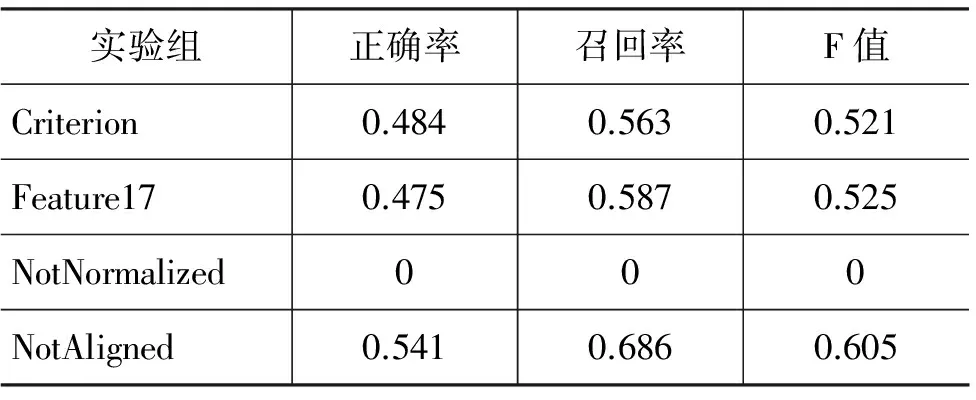
表4 对比实验结果
首先,Criterion与Featurel7的预测效果不相上下。Criterion比Featurel7的正确率略高,但召回率略低,综合的F值相差极小。可以认为IG排名低的特征倾向于将用户归为流失。这组对比实验也说明特征精简化对分类效果影响很小。其次,NotNormalized实验组极不正确地将所有用户都归为非流失。正如前所述,数量级差异巨大的特征空间分布不平衡,会导致学习障碍。实验证明归一化是必要的。最后,NotAligned的评价指标是最好的,F值比Criterion提高约0.08。但这并不意味着其具有较好的预测效果。相反,这是干扰差异使得结果呈现出分类效果更好的假象。这组实验证实了用户游戏行为在不同时间阶段存在着差异,也证明了我们提出的区间对齐方法能有效排除这种差异的干扰。
4.3 参数采样区间长度的影响
除了特征个数,另外一个影响特征规模的因素是采样区间的长度T。为考察该参数的影响,将T从2变动到14,评价结果的变动如图4所示。

图4 评价结果随T变动趋势
图4很清晰地展示了预测效果随T的增加先上升后下降。这是因为1)采样区间小时输入特征较少因而区分用户的能力有限;2)随着T增加输入特征量趋于合适,分类效果上升;3)T继续增加意味着考虑更长的采样区间,该区间的开始用户很可能未表现出明显的流失倾向,与非流失用户基本无异。此结果表明过多考虑时间靠前的特征会对预测带来负面影响。
5 总结与未来工作
在用户流失预测任务中,我们探索了一个较新的发展迅速的领域——网络游戏。基于一款实际运行的游戏数据,通过分析研究,我们提出网游用户特征的提取应重点考察游戏投入、博彩热情以及玩家互动等。基于此思路,我们提取了关键特征并进行单服归一、区间对齐等处理用于分类器训练,取得相对较好的用户流失预测效果。未来我们将对用户行为和特征处理进行更深入的分析和研究,并尝试更多不平衡数据处理方法,以取得更好的预测效果。
[1] 夏国恩, 金炜东. 基于支持向量机的客户流失预测模型[J]. 系统工程理论与实践, 2008, 28(1): 71-77.
[2] 应维云, 覃正, 赵宇, 等. SVM 方法及其在客户流失预测中的应用研究[J]. 系统工程理论与实践, 2007, 27(7): 105-110.
[3] 朱帮助, 张秋菊. 电子商务客户流失三阶段预测模型[J]. 中国软科学, 2010 (006): 186-192.
[4] Xie Y, Li X, Ngai E W T, et al. Customer churn prediction using improved balanced random forests[J]. Expert Systems with Applications, 2009, 36(3): 5445-5449.
[5] Morik K, Köpcke H. Analysing customer churn in insurance data-a case study[M].Knowledge Discovery in Databases: PKDD 2004. Springer Berlin Heidelberg, 2004: 325-336.
[6] Nie G, Wang G, Zhang P, et al. Finding the hidden pattern of credit card holder’s churn: A case of China[M].Computational Science-ICCS 2009. Springer Berlin Heidelberg, 2009: 561-569.
[7] 颜昌沁, 胡建华, 周海河. 基于 Clementine 神经网络的电信客户流失模型应用[J]. 电脑应用技术, 2009 (1): 7-12.
[8] Tsai C F, Lu Y H. Customer churn prediction by hybrid neural networks[J]. Expert Systems with Applications, 2009, 36(10): 12547-12553.
[9] Hung S Y, Yen D C, Wang H Y. Applying data mining to telecom churn management[J]. Expert Systems with Applications, 2006, 31(3): 515-524.
[10] Liu Y, Kalagnanam J R, Johnsen O. Learning dynamic temporal graphs for oil-production equipment monitoring system[C]//Proceedings of the 15th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2009: 1225-1234.
[11] Cheng H, Tan P N. Semi-supervised learning with data calibration for long-term time series forecasting[C]//Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2008: 133-141.
[12] 李航. 统计学习方法[M]. 第1版, 北京:清华大学出版社, 2012: 60-63.
[13] Chen S, Cowan C F N, Grant P M. Orthogonal least squares learning algorithm for radial basis function networks[J]. Neural Networks, IEEE Transactions on, 1991, 2(2): 302-309.
[14] Laurikkala J. Improving identification of difficult small classes by balancing class distribution[M]. Springer Berlin Heidelberg, 2001: 63-66.
[15] Estabrooks A, Jo T, Japkowicz N. A multiple resampling method for learning from imbalanced data sets[J]. Computational Intelligence, 2004, 20(1): 18-36.
[16] Elkan C. The foundations of cost-sensitive learning[C]//Proceedings of the International joint conference on artificial intelligence. LAWRENCE ERLBAUM ASSOCIATES LTD, 2001, 17(1): 973-978.
[17] Croft W B, Metzler D, Strohman T. Search engines: Information retrieval in practice[M].第1版, 北京: 北京机械工业出版社, 2009. 308-313.
[18] 朱世武, 崔嵬, 谢邦昌. 移动电话客户流失数据挖掘[J]. 数理统计与管理, 2005, 24(1): 62-69.
[19] Borbora Z, Srivastava J, Hsu K W, et al. Churn Prediction in MMORPGs using Player Motivation Theories and an Ensemble Approach[C]//Proceedings of the 2011 ieee third international conference on social computing (socialcom). IEEE, 2011: 157-164.
User Behavior Analysis and Churn Prediction: A Case Study on Online Games
GUO Yanwei1, WU Yuexin1, ZHAO Xin1, YAN Hongfei1, HUANG Jianxing2
(1. Department of Computer Science and Technology, Peking University, Beijing 100871, China; 2. Shanghai Renren Games Technology Development Co., Ltd., Beijing 100015, China)
The task of user churn prediction is a research issue in many fields. Currently the available solution usually built uopna classification models. For the online games which is developing rapidly, the churn prediction is not well addressed yet. This paper chooses certain online game user logs and analyzed user behaviors, finding significant differences in game investment, interests in lottery and player interaction between churn users and normal users. This paper also suggests that there are such challenges in online game data processing as the unbalanced data, the huge candidate features, the interference differences and so on. This paper also discusses the direction when selecting features, as well as the key role of normalization and alignment in feature processing. Experiments prove that the features selected by this paper are informative.
behavior analysis; feature selection; churn prediction; online games

过岩巍(1989—),硕士研究生,主要研究领域为搜索引擎与数据挖掘。E⁃mail:pkuguoyw@gmail.com吴悦昕(1989—),硕士,主要研究领域为数据挖掘、机器学习。E⁃mail:wuyuexin@gmail.com赵鑫(1985—),博士,讲师,主要研究领域为网络数据挖掘、自然语言处理。E⁃mail:batmanfly@gmail.com
1003-0077(2016)01-0183-07
2013-06-08 定稿日期: 2013-12-09
国家自然科学基金(U1536201,61272340);江苏未来网络创新研究院项目(BY2013095-4-02)
TP391
A
