基于Markov逻辑网的虚假评论识别方法
2016-05-04行娟娟
行娟娟
(西安外事学院 工学院, 陕西 西安 710077)
基于Markov逻辑网的虚假评论识别方法
行娟娟
(西安外事学院 工学院, 陕西 西安 710077)
为解决虚假评论识别的问题,该文提出一种基于Markov逻辑网的虚假评论识别方法。首先,对虚假评论内容和评论者行为的特点进行分析,选取评论内容特征和评论者行为特征;然后,根据特征定义一阶逻辑谓词和逻辑公式,并介绍了权重学习和推理的过程;最后,进行了对比实验,结果表明该方法的虚假评论识别取得了较好的效果。
Markov逻辑网;虚假评论;权重学习;自适应聚类
1 引言
虚假评价是指商家或者个人为了自身利益,对在线商品发表的推销、诋毁的评论。一直以来,虚假评论的泛滥严重制约着我国电子商务的发展。这些虚假评论在一定程度上影响了评论信息的参考价值,从而误导消费者,识别出在线商品虚假评论有非常重要的现实意义。近几年,随着电子商务的快速发展,关于在线商品虚假评论识别研究已经开展了很多工作,主要分为两类: 基于评论内容和基于评论者行为的虚假评论识别方法。
基于评论内容的虚假评论识别方法主要以评论内容为中心,需要对评论内容进行语义分析和情感识别。Ren等人[1]提出一种创新的PU学习框架来识别虚假评论,对于未标注评论集中的间谍样例首先使用狄利克雷过程混合模型DPMM对其进行聚类;然后混合种群性和个体性两种策略确定间谍样例的类别标签;最后使用两种主流多核学习算法SILP和LPSOLVE来训练最终的分类器,实验证明所提方法可以有效用于虚假评论识别。Rupesh等人[2]提出结合词汇特征和句法特征,利用有监督学习算法进行虚假评论识别,如SMO、决策树、朴素贝叶斯等,取得了很好的识别效果。Wang等人[3]根据评论内容的特性,提出了一种基于主题—对立情感依赖模型的虚假评论检测方法,该方法采用有监督学习分类器SVM对虚假评论进行检测。Banerjee等人[4]在分析真实评论和虚假评论语言特征的基础上,采用多种机器学习算法进行虚假评论的识别,提出语言特征和标题可以提高虚假评论识别准确率。Li等人[5]创建了一个多领域的黄金数据集,包括宾馆、饭店和医生三个领域的评论数据,并发现真实评论中包括更多的名词、形容词和介词,而虚假评论中动词、副词和人称代词较多。Li等人[6]提出一种分类算法MHCC,利用评论、用户和IP地址等信息构建异构网络进行虚假评论识别,并在PU学习框架中对该算法进行扩展,取得了更高的识别准确率。Li等人[7]针对虚假评论识别任务,提出一种基于流行排序算法的三层图模型,把虚假评论识别转换成了排序问题进行求解。Li等人[8]通过定义虚假主题、真实主题、领域主题以及背景主题,利用概率主题模型获取一条评论的主题分布,通过比较评论在虚假主题和真实主题上的概率大小来对虚假评论进行识别。Feng等人[9]定义并提取评论的上下文无关文法规则特征,采用SVM分类器对虚假评论进行检测,并在标准数据集上获得了一定分类率的验证。Diao[10]等人针对Blog本身的特点,使用规则初步过滤垃圾评论,对剩余评论,利用LDA对博客中的博文进行主题提取,结合主题信息进行判断,识别Blog空间的垃圾评论。
基于评论者行为的识别方法主要是从用户评分行为出发,根据用户的行为特征建立分类器的一种虚假评论检测方法。目前,在基于评论者行为的虚假评论检测方面,有很多研究者开展了相关工作。Mukherjee等人[11]提出利用虚假评论者可疑度作为隐性变量构建贝叶斯识别模型,通过分析虚假评论者的各种行为特点,如评论集中突发性、评论极端性等,认为虚假评论者与正常用户具有极为不同的行为分布。Lim等人[12]从用户评分行为出发,根据经验对虚假评论者行为进行建模,设置各种行为特征的权重,通过找到虚假评论的制造者从而达到检测虚假评论的目的。Qiu等人[13]从卓越亚马逊网站获取1 470个评论用户,按单指标选取、五个指标集成选取的方法确定最可能和最不可能成为垃圾评论者的评论用户各25个,并对这50个评论者进行人工标记,根据标记结果设计有监督的线性回归模型。Song等人[14]从评论者行为出发,定义评论自身基本特征以及评论之间的关联性特征,通过利用改进的聚类算法对评论数据进行聚类,然后计算每个聚类簇偏离整个评论数据集的程度,根据异常簇方法来识别虚假评论,提出一种基于自适应聚类的虚假评论检测方法,并且实验验证取得了较好的检测效果。
上述的虚假评论识别方法主要是基于评论内容或者评论者行为的检测方法,它们对虚假评论识别取得了较好的效果。Markov 逻辑网利用强大的一阶逻辑来表示知识,通过为每个一阶逻辑公式附加权重的方式,将一阶逻辑公式融合到概率图模型中,可以更好地解决在线商品虚假评论的识别问题。因此,本文综合考虑了评论内容和评论者行为特征,根据 Markov 逻辑网设计虚假评论识别规则,提出了一种基于Markov逻辑网的虚假评论识别方法。
2 基于Markov逻辑网的虚假评论识别
2.1 Markov逻辑网相关理论
Markov逻辑网是一种将一阶逻辑与概率图模型相结合的统计关系学习模型,能够很好的处理复杂性和不确定性问题[15]。基本思想是对一阶逻辑约束的放松,当一个世界违反了知识库中的一个规则,该世界发生的概率降低但不是不可能;而违反的越少则发生的概率越大。Markov逻辑网通过对每个公式都附加一个权值来表示该公式限制强度的大小,权值越大,满足该公式与不满足该公式的可能世界发生概率之间的差越大。
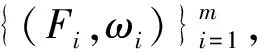
*fi(x))
(1)
其中,Z是归一化因子,i是第i条规则的权重,如果第i条规则为真,fi= 1,反之fi= 0。Markov逻辑网虚假评论识别方法的流程如图1所示。
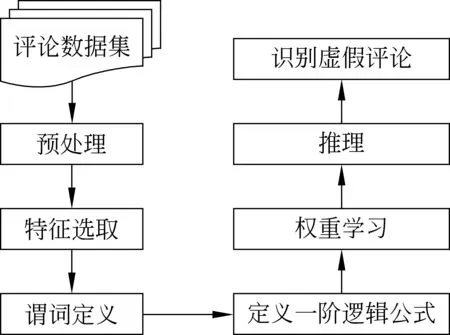
图1 Markov逻辑网虚假评论识别方法流程图
2.2 特征选取
评论内容和评论者行为特征是反映评论是否为虚假评论的重要特征。结合以往相关学者针对虚假评论特征的研究工作[13-14],本文选取相对更重要的六维特征,如表1所示。

表1 评论内容特征
(1) 特征1,即“评论内容包含对商品的体验感受词”。体验感受词往往在真实评论内容中频繁出现,而在虚假评论中出现的可能性较小,例如,实用、划算、一如既往的好、外观新颖、性能不错、正品 、便宜、耐心、态度好等等。真实评论内容与虚假评论内容中的词分布往往有很大的不同,选择评论内容中的体验感受词作为一种评论内容特征。
(2) 特征2,即“评论内容包含大量字母、数字”。虚假评论者有随意输入一些字母或者数字来凑字数的习惯,这样做的目的是节省评论的时间,但是这些字母和数字没有任何意义,在真实评论内容中很少出现。因此,选择评论内容中的大量字母、数字作为一种评论内容特征。
(3) 特征3,即“评论内容中第一人称和第二人称的比例”。消费者在电子商务网站上对所购商品做出的评论中,更多的是描述本人对商品的切身体会,往往表达的是我或者我们的体验,而不是你或者你们应该做什么。然而,在虚假评论中,评论者所做的评论往往跟上述所描述的情况是相反的,即表达的是你或者你们应该做什么。把第一人称代词我、我们与第二人称代词你、你们的比例作为一维特征,以此来反映评论的虚假程度。
(4) 特征4,即“评论者单位时间内所发表评论数”。虚假评论者在单位时间内所发表的评论数往往非常多,因此可以将评论者单位时间内发表的评论数作为一维特征,如果评论者在单位时间内发表的评论数过多的话,就表明该评论者是虚假评论者,其发表的评论也是虚假评论。
(5) 特征5,即“评论者发表评论次数和评论对象类别数量比例”。虚假评论者大多都是针对某一个产品或者某一类产品发表虚假评论,他们发表评论次数和评论对象类别数量相差非常大,而正常的真实评论者不会存在这种现象。因此可以将评论者发表评论次数和评论对象类别数量比例作为一维特征,如果评论者在评论者发表评论次数和评论对象类别数量比例相差很大,就表明该评论者是虚假评论者,其发表的评论也是虚假评论。
(6) 特征6,即“评论者评论该产品次数与购买该产品次数比例”。被雇佣的虚假评论者往往没有体验过自己评论的产品,也即从没购买过该产品,因此没购买产品而发表评论的评论者很可能是虚假评论者,或者评论者购买过一次产品,而发表多条评论的话,这样也可以认为该评论者是虚假评论者,这条评论也很可能是虚假的。
2.3 谓词定义
针对上一小节选取的特征,定义了下面七个一阶逻辑谓词。
(1) Topic (topic,review): 表示评论review属于虚假评论或者真实评论。
(2) HasWord (word,review): 表示评论review中包含了体验感受词word。
(3) HasManyLetterFigure (num,review): 表示评论review中包含num个字母或者数字。当且仅当评论review包含的字母或者数字数量达到评论内容字符数量一半时,为虚假评论。
(4) HasFirstAndSecond(flag,review): 表示评论review包含的第一人称代词和第二人称代词的比例。当且仅当第二人称代词的比例不小于第一人称代词的比例时,为虚假评论。
(5) ReviewNumber(num,reviewer): 表示评论者reviewer单位时间内所发表num个评论。当且仅当评论者每小时发表评论数大于10条时,为虚假评论。
(6) HasReviewAndCategory(flag,reviewer): 表示评论者reviewer发表评论次数和评论对象类别数量比例。当且仅当发表评论次数是评论对象类别数量的三倍及以上时,为虚假评论。
(7) HasReviewAndPurchase(flag,reviewer): 表示评论者reviewer评论产品次数与购买产品次数比例。当且仅当发表评论次数是购买该产品次数的两倍及以上时,为虚假评论。
2.4 一阶逻辑公式
根据虚假评论内容和评论者行为特点,综合考虑虚假评论内容和评论者行为特征,定义了以下六个一阶逻辑公式。
式(2)为:
HasWord(+word,review)⟹Topic(+topic,review)
(2)
该式表示的是体验感受词特征,如果评论review包含了词word,那么评论review就属于类别topic,“+”符号表示针对不同的词形成的闭谓词学习不同的权重。
式(3)为:
HasManyLetterFigure(num,review)⟹
Topic(topic,review)
(3)
该式表示的是大量字母、数字特征,如果评论review中包含了num个字母或者数字,那么评论review就属于类别topic,即虚假评论或者真实评论。
式(4)为:
HasFirstAndSecond(flag,review)⟹
Topic(topic,review)
(4)
该式表示的是第一人称和第二人称比例特征,是根据评论review中第一人称和第二人称比例情况,评论review属于对应的类别topic。
式(5)为:
ReviewNumber(num,reviewer)⟹
Topic(topic,review)
(5)
该式表示的是评论者单位时间内发表评论数特征,如果评论者reviewer单位时间内所发表num个评论,那么评论review属于对应的类别topic。
式(6)为:
HasReviewAndCategory(flag,reviewer)⟹
Topic(topic,review)
(6)
该式表示的是评论者发表评论次数和评论对象类别数量比例特征,是根据评论者reviewer发表评论次数和评论对象类别数量的比例情况,评论review属于对应的类别topic。
式(7)为:
HasReviewAndPurchase(flag,reviewer)⟹
Topic(topic,review)
(7)
该式表示的是评论者评论产品次数与购买产品次数比例特征,根据评论者reviewer评论产品次数与购买产品次数的比例情况,评论review属于对应的类别topic。
2.5 权重学习
Markov逻辑网的参数学习就是指在Markov逻辑网结构确定的前提下,进一步学习和优化模型的参数。具体来说,就是对每个一阶逻辑公式学习最优的权重ωi。本文利用判别式权重学习算法[16]来得到权重。在已知哪些谓词是查询谓词,哪些谓词是证据谓词的前提下,可以自然的将数据库分为两个集合: 证据谓词集合X和查询谓词集合Y,通过对条件概率式(8)),
(8)
求最大似然来学习权重ωi,其中,FY是一个包含闭查询谓词的公式集合。fi(x,y)是数据库中第i个公式的闭公式的真值个数,对式(8)的对数似然函数求偏导,可得式(9)。
(9)
式(9)中,精确的求Eω[fi(x,y)]的时间复杂度非常巨大,因此使用近似求解方法求解,使用马尔科夫链蒙特卡洛方法进行求解。
2.6 推理
Markov逻辑网推理的基本问题包括最大可能性推理,计算边缘概率和条件概率。本文只需要计算最大可能解释,因此只涉及最大可能性推理,下面简要介绍Markov逻辑网中最大可能性推理的方法。最大可能性推理的基本过程可以表述为: 给定证据变量集x,求变量集合y最可能处于的状态,即求式(10)。
(10)
在Markov逻辑网中,根据Markov逻辑网的联合概率公式,式(10)可以转化为式(11)。
(11)
其中,wi表示从句i的权重,fi(x,y)表示从句i的闭从句的真值数量。
因此,推理问题就转化为计算可满足从句带权重最大化的问题,即寻找一组变量的赋值使所有被满足的公式的权重之和最大。通常,可采用任何带权的可满足性问题解决器来处理这类问题,其效率并不比任何类型的标准逻辑推理方法低。事实上,如果Markov逻辑网体系中某些硬性的规则能够适当放松,则推理效率可能会更快。可以使用MaxWalkSAT算法[15]进行求解,测试结果表明,MaxWalkSAT算法可以在几分钟内处理包含上千个变量的可满足性问题。MaxWalkSAT算法的大致流程为: 首先对所有变量随机赋值,然后在所有未满足的从句中随机选取一个从句,改变从句中一个变量x的值。对于x的选取,有两种情况: 根据一定的概率随机选取,或选取这样一个变量,当该变量的值改变时,所有已满足的从句的权重之和将达到最大。变量x的选取体现了“随机”与“贪心”相结合的思想,避免了在局部寻优搜索中被卡住而导致算法不能正常收敛。
但是MaxWalkSAT需要将所有的公式和谓词都转化为闭公式和闭原子以后再进行求解,内存占用量过大,而在实际应用中,从句的数量非常大。LazySAT算法[17]采用一种“需要时再激活”的“惰性”思想,从而很好地解决了该问题。LazySAT算法针对一阶逻辑知识库中稀疏性的特点,即大多数闭原子的取值都为假,从而隐性地决定了大多数闭从句的取值都为真。LazySAT只将需要的原子和公式转化为闭原子和闭公式,可以很好的提高推理速度和节约内存。LazySAT算法以加权的一阶逻辑知识库为输入,使用两个队列active_atoms和active_clauses来分别保存激活的原子和从句。这两个队列使得LazySAT算法比MaxWalkSAT算法更有效地利用内存,大大降低了算法的空间复杂度,同时也在一定程度上降低了算法的时间复杂度。
3 实验与分析
3.1 语料说明
中文领域没有标准的虚假评论语料,本文抓取了2014年京东商城在服装、手机数码、食品、图书和化妆品五类商品中的评论数据,这些评论数据具有普遍性和概括性,能够使实验结果的准确性更高。对获取到的语料进行了人工标注,把评论数据标记为虚假评论、真实评论以及不确定这三个类别。评论类别的标注标准参照“30 Ways You Can Spot Fake Online Reviews”,该标准介绍了30种识别虚假评论的方式。每条评论数据由三个标注者独立进行标注,最终评论的类别依据多数原则来判断,例如,某条评论至少两个标注者将其标注为虚假评论,该条评论才是虚假评论。根据Kappa标准检查标注者的一致性,三个标注者间的Kappa值均大于0.6,则认为这三个标注者得到的虚假评论结果一致性正常,标注数据可用。最后把这些标注语料数据集分成了两类,一类作为训练集;另一部分作为测试集。本文使用判别式权重学习算法[15]在训练语料集上进行权重学习和优化,在测试语料集上进行识别性能测试,实验数据集如表2所示。
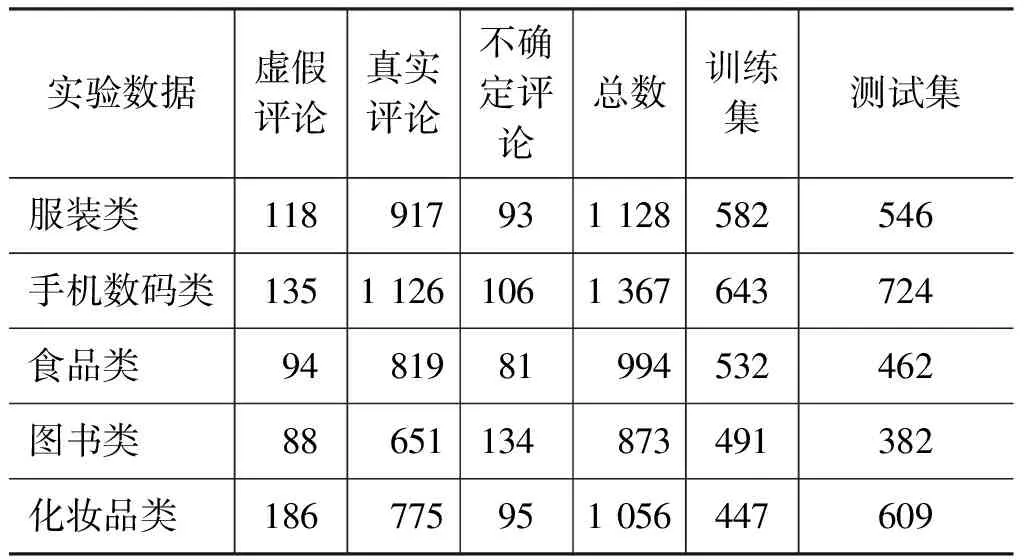
表2 实验数据集信息
3.2 实验设计与结果分析
为了能够更好地验证所提方法的有效性,设计了三个对比试验: (1)不同特征下虚假评论识别效果; (2)不同分类模型的识别效果; (3)不同方法的识别效果。
实验一 不同特征下虚假评论识别效果为验证融合评论内容特征和评论者行为特征的虚假评论识别效果,在使用本文所提算法的基础上,分别融合三类特征对虚假评论进行识别: (1)融合评论内容特征,即表1中的前三类特征,该方法记为M1; (2)融合评论者行为特征,即表1中的后三类特征,该方法记为M2; (3)融合评论内容特征和评论者行为特征,即表1中的全部特征,该方法记为M3。实验中采用的评价指标为准确率P、召回率R和F值。在数据集相同的情况下,实验结果如表3所示。

表3 不同特征下虚假评论识别结果

续表
从表3可见,M1方法得到的平均准确率、召回率和F值分别为65.40%、62.91%和64.11%;M2方法得到的平均准确率、召回率和F值分别为63.16%、60.56%和74.60%;M3方法得到的平均准确率、召回率和F值分别为74.60%、72.52%和73.54%。与M1、M2相比,M3方法对虚假评论识别的F值有了十个百分点左右的提高,证明了融合评论内容特征和评论者行为特征提高了虚假评论的识别效果。
实验二 不同分类模型的虚假评论识别效果为验证Markov逻辑网比其他有监督分类模型在虚假评论识别上有更好的预测性能,在融合相同特征(表1)的条件下,本文与一些常见的监督学习模型进行了对比实验,如最大熵(ME)和支持向量机(SVM)。实验采用的评价指标为准确率P、召回率R和F值,在数据集大小相同的情况下,实验结果如图2所示。
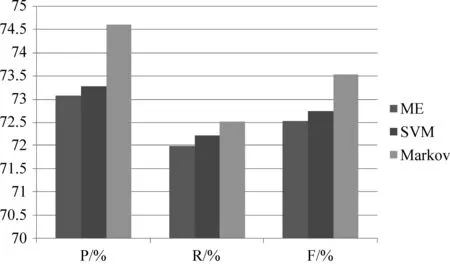
图2 不同分类模型的虚假评论识别结果
图2中在虚假评论识别上,在融合相同特征下,最大熵和支持向量机模型虚假评论识别的准确率、召回率和F值分别是73.08%、71.99%、72.53%和73.28%、72.21%、72.74%,而Markov逻辑网的识别准确率、召回率和F值达到了74.60%、72.52%、73.54%。与前面两个有监督分类模型相比,识别准确率、召回率和F值都有一定的提高。因此,在虚假评论识别上,Markov逻辑网比其他有监督分类模型具有更好的预测性能。
实验三 不同方法的虚假评论识别效果为验证所提方法的有效性,本文与一些权威期刊和国际顶级会议论文提出的方法进行了对比,把Ren等人[1]提出的基于PU学习框架的方法记为M1,把Li等人[8]提出的基于概率主题模型的方法[8]记为M2,把文献[6]中提出的基于异构网络的方法[6]记为M3,把本文所提的基于Markov逻辑网的方法记为M4。实验采用的评价指标为准确率P、召回率R和F值,在相同数据集情况下,实验结果如图3所示。
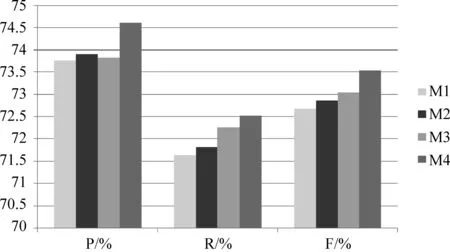
图3 不同方法的虚假评论识别结果
图3中与前三种方法相比,本文提出的基于Markov逻辑网的虚假评论识别方法各项指标都有所提升,具有更好的虚假评论识别性能。主要原因包括两个方面,第一本文使用了Markov 逻辑网,利用强大的一阶逻辑更好地表示虚假评论的特征知识,通过为一阶逻辑公式附加权重的方式,将公式融到概率图模型中进行虚假评论的识别推理,预测能力更强;第二在特征选择上,本文综合考虑了评论内容和评论者行为特点进行虚假评论识别,因此得到更好的识别效果。
4 结束语
针对虚假评论内容和评论者行为特点以及Markov逻辑网络对规则复杂性表达和不确定性推理的优势,本文提出一种基于Markov逻辑网的虚假评论识别方法,利用 Markov 逻辑网设计虚假评论识别规则,进行虚假评论识别。使用京东商城的商品评论数据集进行了对比实验,验证了提出方法的有效性。但是,随着规则复杂度的提高,形成的 Markov网非常庞大,使得参数学习和推理过程需要巨大的时间和空间代价,识别算法的速度会明显降低,目前只能进行离线识别。下一步工作是将该算法进行分布式架构设计,减少虚假评论识别时间,满足或者近似满足在线工作的需求。
[1] 任亚峰, 姬东鸿, 张红斌,等. 基于PU学习算法的虚假评论识别研究[J]. 计算机研究与发展,2015,52(3): 639-648.
[2] Rupesh K D, A K Singh. Identification of Fake Reviews Using New Set of Lexical and Syntactic Features[C]//Proceedings of the Sixth International Conference on Computer and Communication Technology 2015, 2015: 115-119.
[3] 汪建成, 严馨, 余正涛, 等. 基于主题-对立情感依赖模型的虚假评论检测方法[J]. 山西大学学报(自然科学版), 2015, 38(1): 31-38.
[4] S Banerjee, A Y Chua, J J Kim. Using supervised learning to classify authentic and fake online reviews[C]//Proceedings of the 9th International Conference on Ubiquitous Information Management and Communication, ACM, 2015: 88-94.
[5] J Li, M Ott, C Cardie, et al. Towards a general rule for identifying deceptive opinion spam[C]//Proceedings of the 52th Annual Meeting of the Association for Computational Linguistics, ACL 2014, Baltimore, Maryland, USA, 2014: 1566-1576.
[6] H Li, Z Chen, B Liu, et.al. Spotting fake reviews via collective positive-unlabeled learning[C]//Proceedings of the 2014 IEEE International Conference on Data Mining, ICDM 2014, Shenzhen, China, 2014: 899-904.
[7] J Li, M Ott, C Cardie. Identifying manipulated offerings on review portals[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013: 1933-1942.
[8] J Li, C Cardie, S Li. TopicSpam: a Topic-Model-Based Approach for Spam Detection[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, ACL 2013: 217-221.
[9] S Feng, R Banerjee, Y Choi. Syntactic Stylometry for Deception Detection[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, ACL 2012: 171-175.
[10] 刁宇峰, 杨亮, 林鸿飞. 基于LDA模型的博客垃圾评论发现[J]. 中文信息学报, 2011, 25(1): 41-47.
[11] A Mukherjee, A Kumar, B Liu, et.al. Spotting opinion spammers using behavioral footprints[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2013: 632-640.
[12] Lim E P, Nguyen V A, Jindal N, et.al. Detecting Product Review Spammers Using Rating Behaviors[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management, CIKM 2010: 939-948.
[13] 邱云飞, 王建坤, 邵良杉, 等.基于用户行为的产品垃圾评论者检测研究[J].计算机工程,2012,38(11): 254-257.
[14] 宋海霞, 严馨, 余正涛, 等. 基于自适应聚类的虚假评论检测[J]. 南京大学学报(自然科学), 2013, 49(4): 433-438.
[15] Richardson M, Domingos P. Markov logic networks[J]. Machine Learning, 2006, 62(1-2): 107-136.
[16] Parag Singla, Pedro Domingos. Discriminative training of markov logic networks[C]//Proceedings of the 20th National Conference on Articial Intelligence, Pittsburgh, Pennsylvania, 2005: 868-873.
[17] Singla P, Domingos P. Memory-Efficient inference in relational domains[C]//Proceedings of the 21st National Conference on Artificial Intelligence, Boston, Massachusetts, 2006: 488-493.
Fake Reviews Identification Based on Markov Logic Networks
XING Juanjuan
(Engineering College, Xi’an International University, Xi’an,Shanxi 710077, China)
In order to identify fake reviews, we propose a method of fake reviews identification based on Markov Logic Networks. Firstly, the characteristics of fake review content and reviewer behavior are analyzed,and the review content features and the reviewer behavior features are selected. Secondly, the predicates and the formulas are defined with the features,and the weight The experimental results and the inference are decriked. show that the proposed method has a good performance.
Markov logic networks; fake review; weight learning; adaptive clustering

行娟娟(1963—),硕士研究生,高级工程师,主要研究领域为电力电子及智能控制。E⁃mail:xjj_1963@sina.com
1003-0077(2016)05-094-07
2015-03-01 定稿日期: 2016-02-03
国家自然科学基金(61103242)
TP301
A
