基于高斯词长特征的中文分词方法
2016-05-04李治江
张 义,李治江
(武汉大学 印刷与包装系,湖北 武汉,430079)
基于高斯词长特征的中文分词方法
张 义,李治江
(武汉大学 印刷与包装系,湖北 武汉,430079)
中文分词是中文信息处理的基础,在语音合成、中外文翻译、中文检索、文本摘要等方面均有重要应用。在中文分词的任务中,存在的主要问题在于可用有效特征较少,分词准确率较低,如何有效的获取和使用分词特征是关键。该文从中文文本生成的过程出发,基于词长噪声的高斯分布特性,提出利用上下文的词长特征作为分词特征。实验表明,在封闭测试中,采用条件随机场模型,使用该特征对现有的实验结果有提高作用。
高斯词长;条件随机场;中文分词;自然语言处理
1 引言
中文分词是将中文文本中连续的字序列转变成词序列的过程,在语音合成、中英文翻译[1]、中文检索、文本摘要等方面均发挥着重要作用。
中文分词方法的研究方向大体分为三个方面。第一,使用预定义的词典信息,分词词典是词语规范、未登录词定义的集中体现。接着借助词典采用正向、逆向[2]、最大[3]、最小匹配查找词典,决定是否为词。采用词典信息的方法,最大的缺点就是对未在词典中出现的词语较难识别,需要采用其他方式予以弥补;第二,不使用分词语料,直接使用待分词语料库进行无监督的学习,使用的方法有互信息[4]、t-测试差、边界熵[4]、期望值最大化[5]、最小描述长度[6]、描述长度增益[7]等。无监督的学习方式不需要人工制作分词语料,然而需要手工设定提取阈值,并且单纯使用此方法的准确率没有超过90%;第三,使用人工制作的分词语料进行机器学习,研究人员从最大熵模型、CRF模型[8]、双层隐马尔科夫模型[9]或者他们的联合模式[10-11]进行研究,对于这种有监督的判别模型,主要利用分词语料的特征有词位特征、音律特征[8]、边界熵[4]、邻接多样性[12]、成语词特征[13]的基本特征。有监督的机器学习方法的最大优点是分词准确率相对较高,对分词语料的学习相对较为充分,但是对上下文特征的挖掘不充分,影响了分词准确率的进一步提高。本文针对有分词语料存在的前提下,利用语料库中的文本分词特征,从而提高分词效果。
本文从中文文本生成的过程出发,基于词长噪声的高斯分布特性,探讨了如何从上下文信息中获取分词所需的词长信息。接下来的文章组织方式为,第二节阐述了目前中文分词中对特征的依赖和还存在的问题;第三节讲述了上下文词长信息的获取和使用;第四节进行了相关实验和分析;第五节进行讨论与总结。
2 中文分词中的特征选取
中文分词的一个关键问题在于有效分词特征不是很多。机械分词使用的是词典中的编码特征(词典可以认为是一种标注并且编排好的学习语料),从而进行索引查找分词。这种编码特征的缺点在于人为制定了编码和分词之间的联系,对于新的分词和编码之间的联系不具有自学习的机制,从而导致歧义问题较高,OOV(out of vocabulary)的召回率低。例如,“将有/无数/学子/背负/着/青春/的/理想[14]”,这里的“无数”、“学子”、“数学”均为词典词。这里容易将“数学”提取出来,进了错误切分。OOV方面,仅仅依赖词典是无效的,因为对人名、机构名、地名进行穷举是不现实的。
在无监督的学习模型中,广泛使用了互信息特征、t-测试差特征、最小描述长度(MDL)等特征,模型可以从不经过加工的文本中发现词语,但也容易将已知的词语进行了割裂。由于这些特征对语境的上下文信息的使用是等同看待,或者不使用语境的上下文信息,这样会带来不合理的结果。例如,“后车/连续/鸣笛/这一/很多人/不以为然/的/不文明/行为/,/间接/导致/了/车祸/的/发生/。/”,这里的“不以为然”很容易被学习模型切分为“不/以为/然”,这样就把固有的成语割裂开来了。
在有监督的学习模型中,如条件随机场模型,对语料的学习和分析采用的特征有形态学特征、类型特征、音律特征、邻接特征(边界熵和邻接多样性等)。其中,类型特征和音律特征使用的是汉字本身的特性,成语词特征使用的是语料库的规则特征,与上下文语境的相关性不是很高。邻接特征考虑了上下文信息,但只使用的是上下文的全文联系特征。没有充分利用上下文的特征会出现分词不一致现象。例如,“防御/者/处于/驻/止/状态/,/而/进攻者/是/针对/防御者/的/这种/状态/进行/运动的/”[14]。这里“防御者”和“进攻者”都应该是一个词,而有监督的学习模型会出现这种切分不一致的状态。
综上,在目前的研究中,针对不同的应用环境和已存在的学习语料,各分词方法使用了不同的分词特征,然而可以看到这些特征在辅助构建分词模型的同时,也出现了不少问题。中文分词中需要找到上下文相关的高效特征,借助这些特征,相关的分词方法才可以进一步提高分词结果。
3 高斯词长特征及应用
中文文本的生成可以看作是将网状存储的知识节点输出为线性的中文文本表达的过程。如图1所示,左侧是中文文本知识在大脑中的网状存储示意图,每个节点是若干可以输出的知识元,某一知识节点与其他节点有着或强或弱的联系,当输出中文文本表达时,是一个网络知识节点转化为线性知识节点的过程。音律特征、邻接特征等用于找到这些知识节点的紧密程度。
由图1可知,知识节点网状图不是有向完全图,某个知识节点(如Ci)只与它附近的知识节点产生较强的联系,也部分受到较远节点的弱影响。基于这样的假设,如果利用条件熵特征、邻接多样性特征等,则是把全局的知识节点进行全连接,并把他们进行等价看待,这样就会导致偏差。如果利用状态概率和条件转移概率,则是弱化了知识网络图,只考虑较近的知识节点联系,这也是产生“标记偏执”的原因。
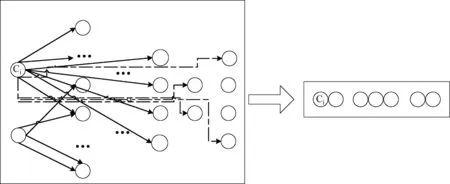
图1 网状知识节点转化为线性知识节点
本文选取该词附近的词长信息进行特征提取,在一定程度上利用了知识节点网状图的特点,由实验可以看出,上下文的词长特征对分词结果有提升作用。有关定义如下。
某字ai的词长(Lengthai)为该字在所在词的词长。某字ai的上下文词长(Lai)是指该字所在一定字序列范围内,在周围所在字的词长影响下的词长。本文使用了高斯函数作为词长计算卷积核,分词原子的词长Lai计算如式(1)所示。
(1)
其中,ai为第i个分词原子,n为上下文语境范围。当n=6时已经涵盖了上下文七个词语。
以bakeoff-2005年微软亚洲研究院的一条语料数据为例。通过式(1)计算“人们常说生活是一部教科书”在上下文语境下的词长,由表1 可以直观看出上下文词长与词长的不同。
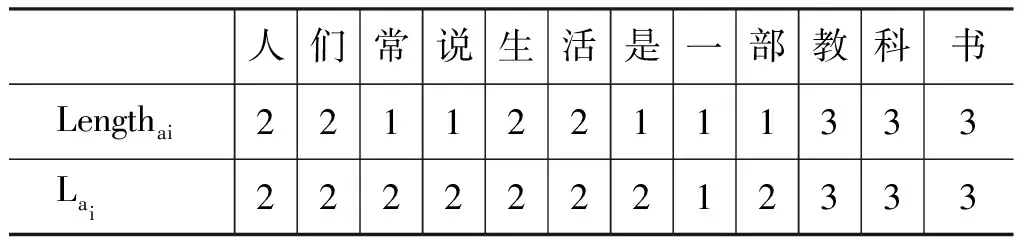
表1 高斯词长特征Lai计算举例(n=6,σ2=1)
高斯词长特征与判别模型(discriminated model)中的词典特征的区别在于,词典特征是直接查询一个封闭集合词典,来获得相应的词长特征,这种特征可以称之为词典长度。词典长度一般通过前向和后向最大匹配获得。上下文词长和词典词长的本质区别在于,词典词长是根据事先制定好的分词规律进行分词,从而制作的标准词长。上下文词长是从当前文档中,根据当下的分词语料获得符合当前分词语境的词长,对当前语料的上下文规律和分词规律学习的更为充分。例如,表1 中,“人们常说生活是一部教科书”中的“说”,因为前向最大匹配是1,所以它的前向词典长度是1,而本文中所指的通过上下文影响的上下文词长为2。
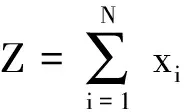
(2)
所以使用高斯函数作为词长计算卷积核是有效的。
高斯词长特征可以应用于基于有监督的学习方式中,包括多层学习模型和在无监督的学习模型进行辅助下的有监督的学习方式。在已有的基于机器学习的分词方法中,有监督的条件随机场模型[15-16],因为摆脱了“标记偏执[17]”问题,所以取得了较好的分词结果。下面以条件随机场(CRF)模型为例,说明高斯词长特征的对有监督的学习模型的促进作用。
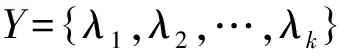
(3)
其中,Z是归一化因子,定义如式(4)所示。
(4)
由式(3)可以看到,CRF没有严格的独立条件假设,是在给定的需要标记的观察序列的条件下,计算整个标记序列的联合概率分布。而不是在给定的某一状态条件下,计算下一个状态的概率分布。因此,只有在整个序列化输入完成之后才能得到训练模型,这样,选取上下文特征作为输入序列,是计算了局部数据平滑后的全局指数函数。
对于线链CRF公式中的参数Y={λ1,λ2,…,λk}可以采用以下方法进行估计。参数估计的实质是对概率的对数最大似然函数求最值,即通过迭代直到函数收敛或迭代次数完成。
对于一个训练集D={(X1,Y1),(X2,Y2),…,(Xt,Yt)},其中{X1,X2,…Xt}是输入序列,{Y1,Y2,…Yt}是输出序列,如式(5)所示。
(5)
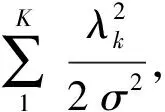
(6)
式(6)可以采用迭代或LBFGS算法来计算[18]。
4 实验与分析
由于bakeoff-2005年的实验语料较为全面、成熟、公开,大多数业内研究人员都会使用此语料进行测评评比[6, 12, 19],本研究同样使用此语料进行研究试验。
实验语料库的具体内容如表2所示。
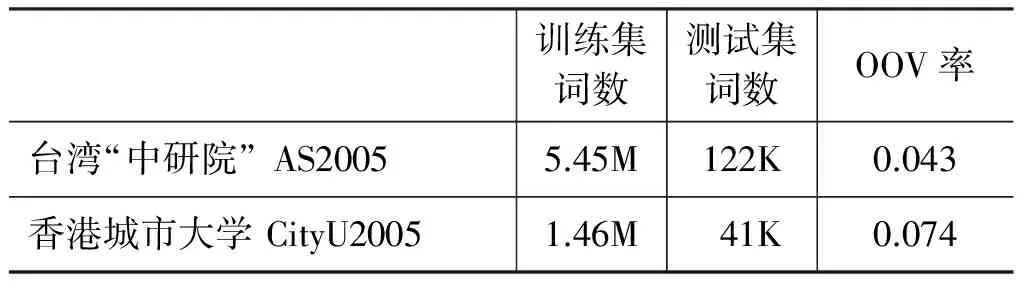
表2 试验语料库情况
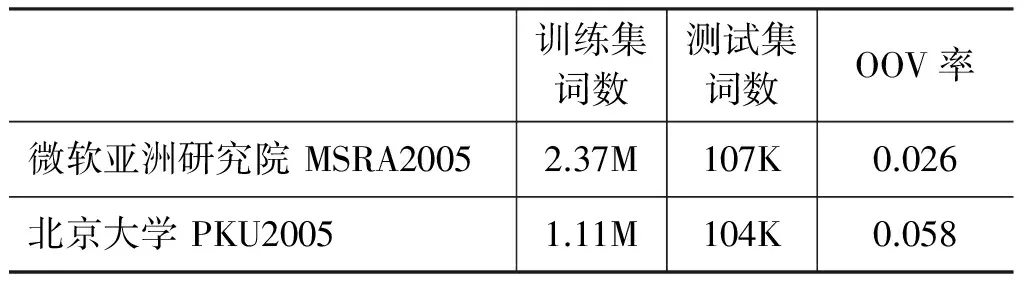
续表
CRF工具包使用支持多线程训练的CRF++ 0.58*开源代码来自http://crfpp.sourceforge.net。采用五窗口,C2, C1,C0,C-1,C-2, C-2C-1C0, C-1C0C1, C0C1C2, C-1C0, C0C1这十个特征,使用四标签。对PKU语料进行了统一编码转换。
表3中,F1代表当年的最好成绩,F2表示加词长特征后取得成绩,F代表增加的数量。同理,ROOV1代表2005年的最好召回率。ROOV3表示加高斯词长特征后取得的最好成绩,ROOV3表示增量。发现高斯词长特征的加入,对2005年的各项结果均有提升作用。
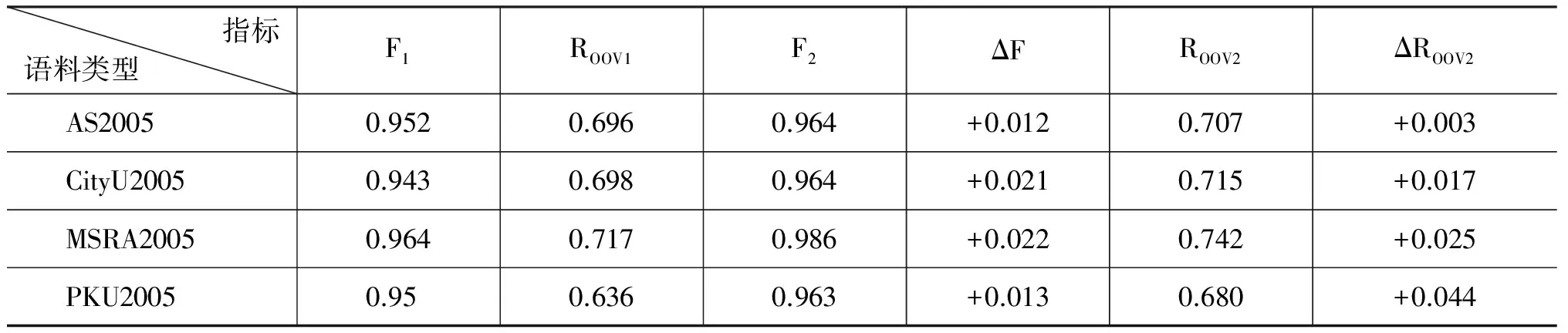
表3 bakeoff-2005年封闭测试成绩对比(+词长特征)
表4中,由于没有获取到SIGHAN2014 的比赛测试集,将之与参赛取得最好的队伍[12]相应的数据进行对比。F1代表2014年的发表的最好成绩,F3表示加词长特征后取得成绩,ΔF代表增加的数量同理,ROOV1代表2014年的发表的最好召回率。
ROOV2表示加词长特征后取得的做好成绩,ΔROOV3表示增量。可以看到高斯词长特征在F值上有一定的提升作用,然而ROOV的提升作用不是很明显,可能是参赛队伍针对未登录词进行后处理[12]的缘故。
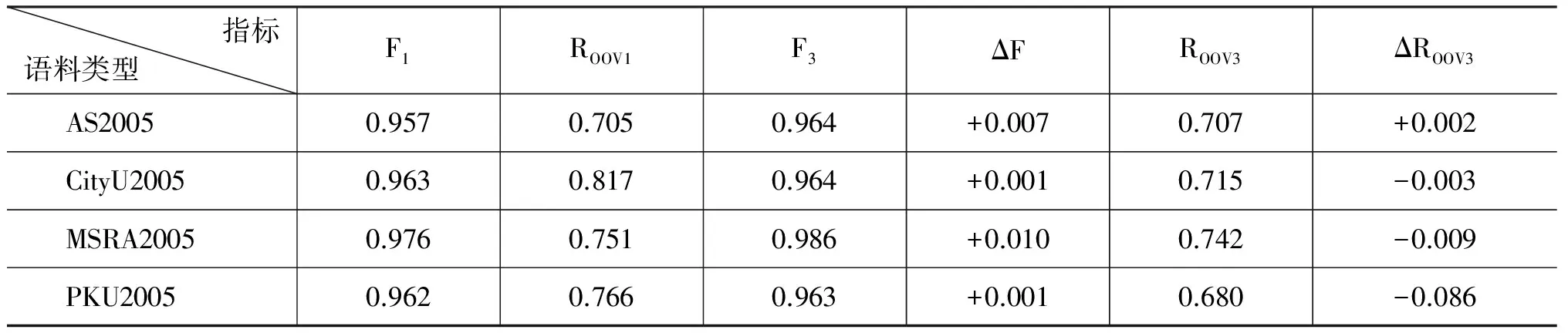
表4 与2014年公开数据进行的成绩对比
5 总结与讨论
中文分词是中文自然语言处理的基础环节,特征选取是中文分词任务的重要内容。从中文文本生成的角度看中文分词,中文分词是从线性 的 文 字 序列得到网状的知识节点的过程。本文提出的高斯词长特征是中文上下文信息的一种表现,可以消除词长噪声对分词模型的影响,通过CRF模型在bakeoff-2005的四个语料库的测试上可以看出,本特征的提取对提高分词的准确率是有效的。然而,上下文的词长特征是上下文特征的一个浅层特征,对未登录词的召回率作用不甚明显。如何挖掘和使用其他高效的上下文特征,以及如何进行解码时的后处理,是下一步值得思考的地方。
[1] Gao Jianfeng. Unsupervised chinese word segmentation for statistical machine translation[P]. US, US20090326916. 2009.
[2] Kirshenbaum, Evan R, Methods and systems for splitting a chinese character sequence into word segments[P]. US, US8539349. 2013.
[3] Jun Z, Z Zheng, W Zhang, Method of Chinese words rough segmentation based on improving maximum match algorithm[J]. Computer Engineering and Applications, 2014. 02: 124-128.
[4] Magistry, Pierre, Benoit Sagot. Unsupervised word segmentation: the case for Mandarin Chinese[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. 2012: 383-387.
[5] Peng Fuchun, et al. Using self-supervised word segmentation in Chinese information retrieval[C]//Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, SIGIR, 2002,44(2): 25.
[6] Magistry, B Sagot. Can MDL Improve Unsupervised Chinese Word Segmentation[C]//Proceedings of the Seventh SIGHAN Workshop on Chinese Language Processing. 2013.
[7] Zhao Hai, Chunyu Kit. Integrating unsupervised and supervised word segmentation: The role of goodness measures[J]. Information Sciences, 2011, 181(1): 163-183.
[8] Zhang Ruiqiang, Genichiro Kikui, et al. Subword-based Tagging for Confidence-dependent Chinese Word Segment[C]//Proceedings of the Association for Computational Linguistics, 2006: 961-968.
[9] Jiang Huixing, Zhe Dong. An double hidden HMM and CRF for segmentation tasks with pinyin's finals [C]//Proceedings of CIPS-SIGHAN Joint Conference on Chinese Language. 2010: 277-281.
[10] Wang Kun. Chengqing Zong, Keh-Yih Su. A Character-Based Joint Model for Chinese Word Segmentation[C]//Proceedings of the 23rd International Conference on Computational Linguistics. 2010: 1173-1181.
[11] 刘一佳等. 基于序列标注的中文分词、词性标注模型比较分析[J]. 中文信息学报, 2013(04): 30-36.
[12] Wu Guohua, et al. Leveraging Rich Linguistic Features for Cross-domain Chinese Segmentation[C]//Proceedings of the Third CIPS-SIGHAN Joint Conference on Chinese Language Processing, 2014: 101-107.
[13] Sun Weiwei, Jia Xu. Enhancing Chinese word segmentation using unlabeled data[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. 2011: 970-979.
[14] Duan Huiming, Zhifang Sui, et al. The CIPS-SIGHAN CLP 2014 Chinese Word Segmentation Bake-off[C]//Proceedings of the Third CIPS-SIGHAN Joint Conference on Chinese Language Processing. 2014: 90-95.
[15] 加羊吉等. 最大熵和条件随机场模型相融合的藏文人名识别[J]. 中文信息学报, 2014(1): 107-112.
[16] 吴琼,黄德根. 基于条件随机场与时间词库的中文时间表达式识别[J]. 中文信息学报, 2014(6): 52-58.
[17] Lafferty John, Andrew McCallum, et al. Conditional Random Field: Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the 18th International Conference on Machine Learning. 2001: 282-289.
[18] Wallach Hanna. Efficient Training of Conditional Random Fields[D]. University of Edinburgh.2002.
[19] 黄昌宁,赵海. 中文分词十年回顾[J]. 中文信息学报, 2007(03): 8-19.
Gaussian Distribution of Word Length for Chinese Word Segmentation
ZHANG Yi,LI Zhijiang
(School of Printting and Packaging,Wuhan University,Wahan,Hubei 430079,China)
Chinese word segmentation (CWS) is the foundation for Chinese information processing. This article proposed a feature of contextual word length based on Gaussian noise. The experiment results indicate that this feature can enhance the performance of the exit result.
contextual word length; conditional random field; Chinese word segmentation;natural language process

张义(1990—),硕士,工程师,主要研究领域为自然语言处理。E⁃mail:zhangyiaddress@foxmail.com李治江(1977—),博士,副教授,主要研究领域为视觉分析与检测,自然语言处理。E⁃mail:lizhijiang@whu.edu.cn
1003-0077(2016)05-0089-05
2015-04-14 定稿日期: 2015-06-18
武汉大学自主科研项目;国家科技支撑计划项目(2012BAH91F03)
