一种基于增广网络的快速微博社区检测算法
2016-05-04蒋盛益杨博泓姚娟娜吴美玲张钰莎
蒋盛益,杨博泓,姚娟娜,吴美玲,张钰莎
(1. 广东外语外贸大学 信息学院,广东 广州 510006; 2. 阿里巴巴,广东 广州 510620; 3. 广东外语外贸大学 南国商学院,广东 广州 510545)
一种基于增广网络的快速微博社区检测算法
蒋盛益1,杨博泓1,姚娟娜1,吴美玲2,张钰莎3
(1. 广东外语外贸大学 信息学院,广东 广州 510006; 2. 阿里巴巴,广东 广州 510620; 3. 广东外语外贸大学 南国商学院,广东 广州 510545)
微博是当前最流行的在线社交媒体之一,有效地检测出微博用户的社区结构,能够帮助人们理解微博社交网络的结构和用户的行为特征,从而为用户提供个性化的服务。然而,现有社区检测算法大多只考虑社交网络节点之间的直接链接关系,忽略节点自身的内容特征。针对此问题,提出一种基于增广网络的快速微博社区检测算法。该算法通过融合社交网络的链接信息以及用户在微博上所发布的博文内容信息构建增广网络,然后以模块度为目标函数快速挖掘增广网络中的主题社区。通过真实微博社交网络的实验表明,提出的算法能够高效地检测出社交网络的主题社区。
微博;社区检测;模块度;主成分分析;增广网络;主题社区
1 引言
进入Web2.0时代,人们交流的方式渐渐从传统的面对面交谈转换为在线社交网络上的互动。据CNNIC统计,截至2014年7月,我国微博用户规模已达到了2.75亿,微博已成为中国网民进行网络社交最主要的工具。有效地检测出微博网络中的社区结构,一方面能够为用户提供个性化的服务,另一方面也能为商家的定向广告投放提供依据[1]。
社区检测(community detection),也称作社团识别、社区发现,是指将网络划分成若干个子网络,使得同一子网络中节点间联系较大,不同子网络中节点间联系较小[2]。已有社区检测算法主要分为基于分裂的算法[3]、基于模块度的算法[4-6]、基于谱聚类的算法[7]等,其中常用的社区检测算法主要有GN算法[3]、CNM算法[5]、BGLL算法[6]和CPM算法[8]等。
然而,现有的社区检测算法大多只考虑节点之间的直接链接关系,忽略了节点自身的特征属性。对于微博社交网络,由于用户节点除了与其他用户的关注/粉丝关系特征之外,还包含了自身发布博文的内容特征,因此直接采用现有的算法对网络进行社区检测效果并不理想。在微博社区检测研究中,蔡波斯等人[9]提出了一种基于行为相似度的微博社区检测算法,该算法通过对用户人口特征使用主成分分析法构造用户特征,然后使用CPM算法检测出社区结构。闫光辉等人[10]提出了一种基于主题和链接分析的微博社区检测算法,该算法分析微博用户的链接及博文主题特性,提出了用户相关度的度量方法,并以此计算节点间的传递概率,然后使用标签传递算法对用户进行分类,进而得到社区检测结果。文献[11]提出了一种基于k-means聚类的微博社区检测算法,该算法先构建了微博网络模型,然后以LC模块度作为目标函数,最后采用k-means对网络节点进行聚类,通过优化目标函数实现微博社区检测。文献[12]提出了CLARANS算法,该算法首先利用提出的预处理方法对用户博文进行预处理,并提取用户特征,然后采用一种自适应的k策略对节点进行聚类,最后以聚类结果为依据,检测出微博的社区结构。虽然上述方法借助用户行为特征、主题和链接等信息,在一定程度上改进了社区检测的效果,但并没有充分考虑用户节点的文本内容和链接信息,并且对于大规模的微博网络,这些方法存在时间复杂度过高、检测精度不足等问题。
针对上述问题,本文提出一种基于增广网络的快速微博社区检测算法,该算法通过对用户的链接信息和内容信息进行加权融合构建微博用户网络模型,获得增广网络,并以模块度为目标函数,对增广网络进行快速社区检测,挖掘微博用户的主题社区。实验结果表明,相比于单纯考虑链接信息或文本内容信息的检测,提出算法能够获得更好的社区检测结果;与现有的方法相比,提出算法能够更高效的挖掘社交网络的社区结构,且检测出的社区具有主题特征。
本文余下章节安排如下: 第二节描述增广网络的构建方法,第三节中给出社区检测算法相关定义及算法步骤,第四节给出实验验证过程及分析,最后在第五节进行全文总结。
2 增广网络构建
为充分考虑微博用户的链接信息及用户自身的内容特征信息,本文通过规则加权融合的方式构建微博用户网络模型,即增广网络。构建增广网络的过程主要分为三个步骤: 用户内容相似度矩阵构建、用户链接相似度矩阵构建和融合内容和链接相似度矩阵。具体流程如图1所示。
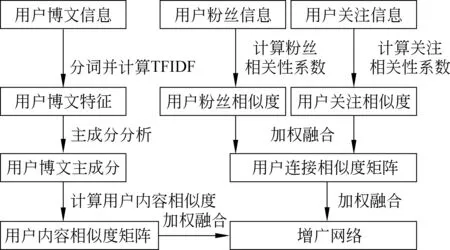
图1 增广网络构建流程图
2.1 用户内容特征提取
由于微博用户发布的博文常包含着不规范的网络用语,而这些网络用语大多是未登录词,传统的分词系统对微博博文进行分词的效果并不理想,因此本文采用结巴分词系统对用户微博博文进行分词。结巴分词基于Trie树结构生成句子中汉字所有可能成词情况所构成的有向无环图,并采用动态规划查找最大概率路径, 找出基于词频的最大切分组合。对于未登录词,采用了基于汉字成词能力的隐马尔可夫模型,使用了Viterbi算法[13]。
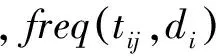
2.2 内容特征主成分分析
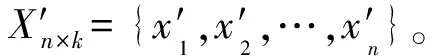
2.3 用户内容相似度矩阵构建
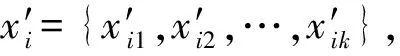
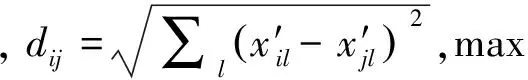
2.4 用户链接相似度矩阵构建
微博中的链接信息表现为用户的粉丝和关注信息。一般情况下,拥有共同关注和共同粉丝较多的两个用户之间存有较大的链接相似度。本文采用Jaccard相似性系数分别计算用户的粉丝相似度和关注相似度矩阵simfans和simfollows。用户的粉丝或关注相关性系数定义为:
式中,I和J分别表示用户i和用户j的粉丝或关注集,jacij即用户i与用户j之间的粉丝或关注相似度。根据计算出的用户粉丝相似度矩阵和关注相似度矩阵,定义用户链接相似度矩阵为:
式中,α为融合参数。
2.5 增广网络构建
在获得用户的内容相似度矩阵simc和用户的链接相似度矩阵sim1后,通过规则加权融合两个相似度矩阵,获得用户相似度矩阵,即增广网络sim。具体处理方法如式(5)所示。
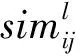
3 社区检测算法
研究表明,在微博社交网络中存在着各种各样的社区结构,有效地检测出微博的社区结构有利于用户体验和商业营销。为解决现有社区检测算法未充分考虑社交网络节点的链接信息和内容信息及时间复杂度过高的问题,本文提出一种基于增广网络的快速微博社区检测算法(AFastMicroblogCommunityDetectionAlgorithmbasedonAugmentedNetwork, 简称CD-AN),并对微博社交网络进行社区检测。
3.1 相关定义
定义1 模块度[4]是评价社区检测效果的指标。模块度越高,则表示社区检测效果越理想,社区内部更紧凑。其定义为:
式中,Aij为节点i和节点j的连边权重;ki和kj分别为与节点i和节点j有关联的连边权重之和;当ci=cj时,δ(ci,cj)=1,反之,则δ(ci,cj)=0;m为网络连边的权重之和。
定义2 当节点i转移社区时,其模块度增益[6]定义为:
式中,∑in为节点i转移到的社区内部连边权重之和;∑tot为与节点i转移到的社区内部节点有关的连边权重之和;ki为与节点i有关的连边权重之和;ki,in为节点i到转移到的社区内部节点的连边权重之和。
3.2 算法描述
本文提出算法的主要思路是: 首先通过分析微博用户发布的内容信息和链接信息,计算出用户的内容相似度矩阵和链接相似度矩阵,然后通过规则加权融合的方式融合用户的内容和链接信息,获得增广网络。对增广网络的每个节点,循环计算节点转移社区得到模块度增益,若最大模块度增益大于0,则将该点转移至获得最大模块度增益的社区中,从而不断提升模块度,当模块度不再提升或模块度增益均小于0时结束循环。算法伪代码如下所示:
算法 CD-AN
输入 用户集U,用户博文集D,用户粉丝集FS,用户关注集FL,最小模块度差值ξ,最大迭代次数T
输出 社区摘要
步骤
1) SEGMENT D→W;
2) COMPUTE TFIDF by formula(1);
3) TFIDF→ TFIDF-PC by PCA;
4) COMPUTEsimcbyformula(2);
5)COMPUTEsimfansandsimfollowbyformula(3);
6)COMPUTEsimlbyformula(4);
7)COMPUTEsimbyformula(5);
8)RandomsequenceofU;
9)COMPUTEqbyformula(6);
10)t=0;
11)WHILETrue:
12)FORuinU:
13)FINDneighcommofu;
14)FORncinneighcomm:
15)COMPUTEq-gainofu→nc;
16)MARKmaxq-gain;
17)IFmaxq-gain>0:
18)moveu→nc;
19)ELSE:
20)BREAK;
21)t+=1;
22)IFt>=T:
23)BREAK;
24)COMPUTEqlbyformula(6);
25)IFql-q<ξ:
26)BREAK;
27)RETURN;
4 实验结果与分析
4.1 实验数据
新浪微博是国内最为热门的网络社交应用。本文通过编写网络爬虫算法从新浪微博中爬取了真实的社交网络数据作为实验数据,爬取的数据内容包括了用户的关注信息、粉丝信息以及用户发布的博文信息。为了获取的数据具有实际性,本文以作者所在高校的微博用户为主要分析对象,通过设定学校教师等种子用户进行广度遍历爬取数据,最终得到的大部分微博用户都与所在的高校密切相关。
为去除网络中的“僵尸”用户,本文对数据进行了如下过滤: 1)粉丝或关注用户数少于五人的用户;2)关注数量为粉丝五倍的用户;3)发布博文少于五条的用户。在进行过滤处理后,最终选取了1 800位用户的数据进行实验。
由于用户发布的微博数量规模大,微博用户的用词多样,导致用户的内容特征向量维度较高。经过分词,计算TF-IDF后每位用户的内容特征向量包含了85 119个特征值。在设定信息利用率为大于85%,进行主成分分析后得到585个主成分,各个主成分信息利用率如表1所示。
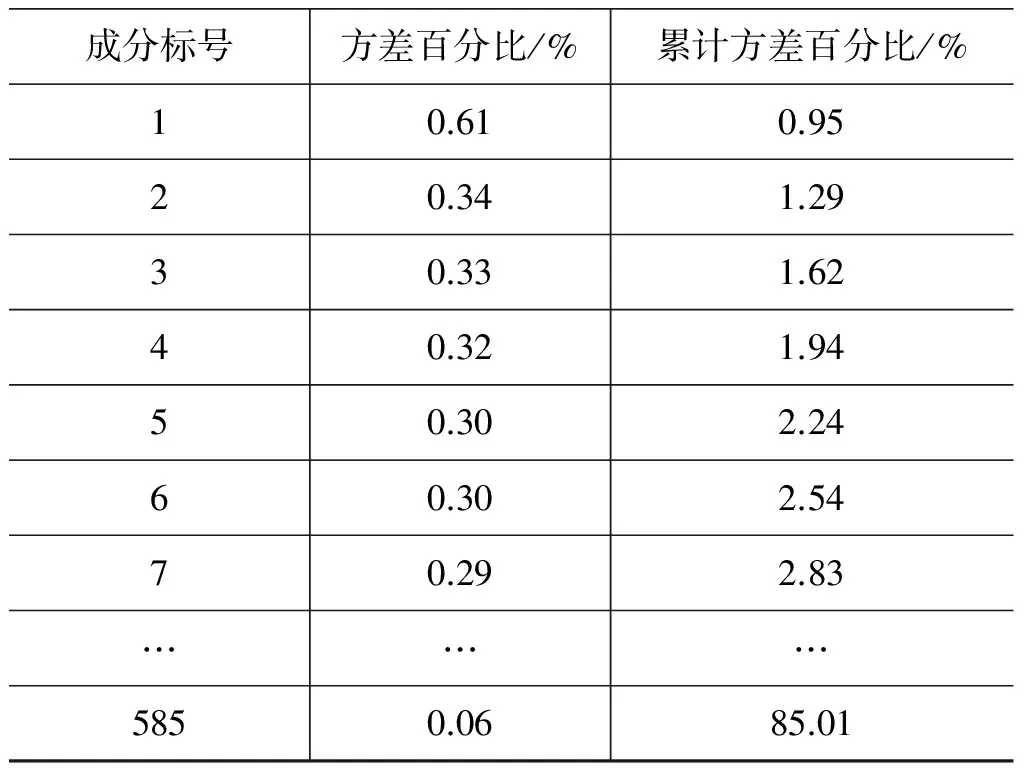
表1 主成分分析结果
4.2 参数实验
CD-AN在构建增广网络的过程中使用了两个融合参数α和β,为分析参数对算法进行社区检测时产生的影响,本文通过采用控制参数的方式,观察模块度随着参数变化而产生的变化,以选取最佳参数取值。
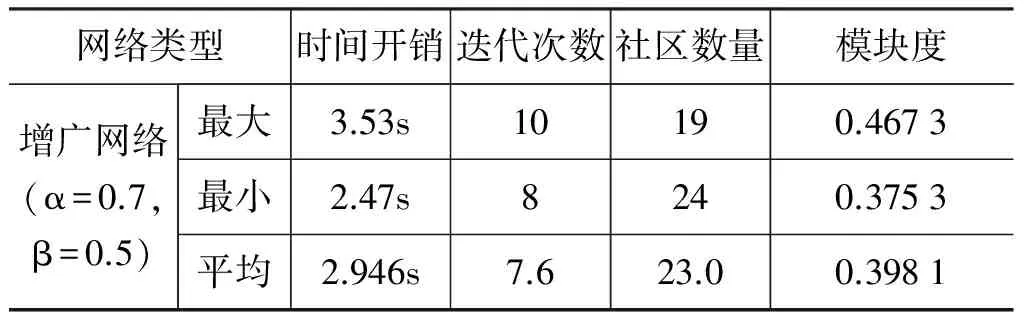
如图2所示,在试验中,我们控制了链接相似度矩阵融合参数α=0.5,观察融合参数β变化过程中模块度的变化,从图2可以观察,在初始阶段模块度出现陡增现象,随之在β变化过程中,模块度没有产生明显的变化。当选定β=0.5时,在图2中模块度随α的变化发生较大变化,且在α=0.7时模块度达到峰值。进一步试验选定α=0.7时,观察β变化过程中模块度的变化是否如α=0.5时一样,不发生明显变化。实验结果表明,α参数能够较大的影响社区检测的效果,而β参数对社区检测效果的影响不明显。在保留社区的主题特征下,当α=0.7,β∈[0.2,0.9]时,社区检测效果较为理想。
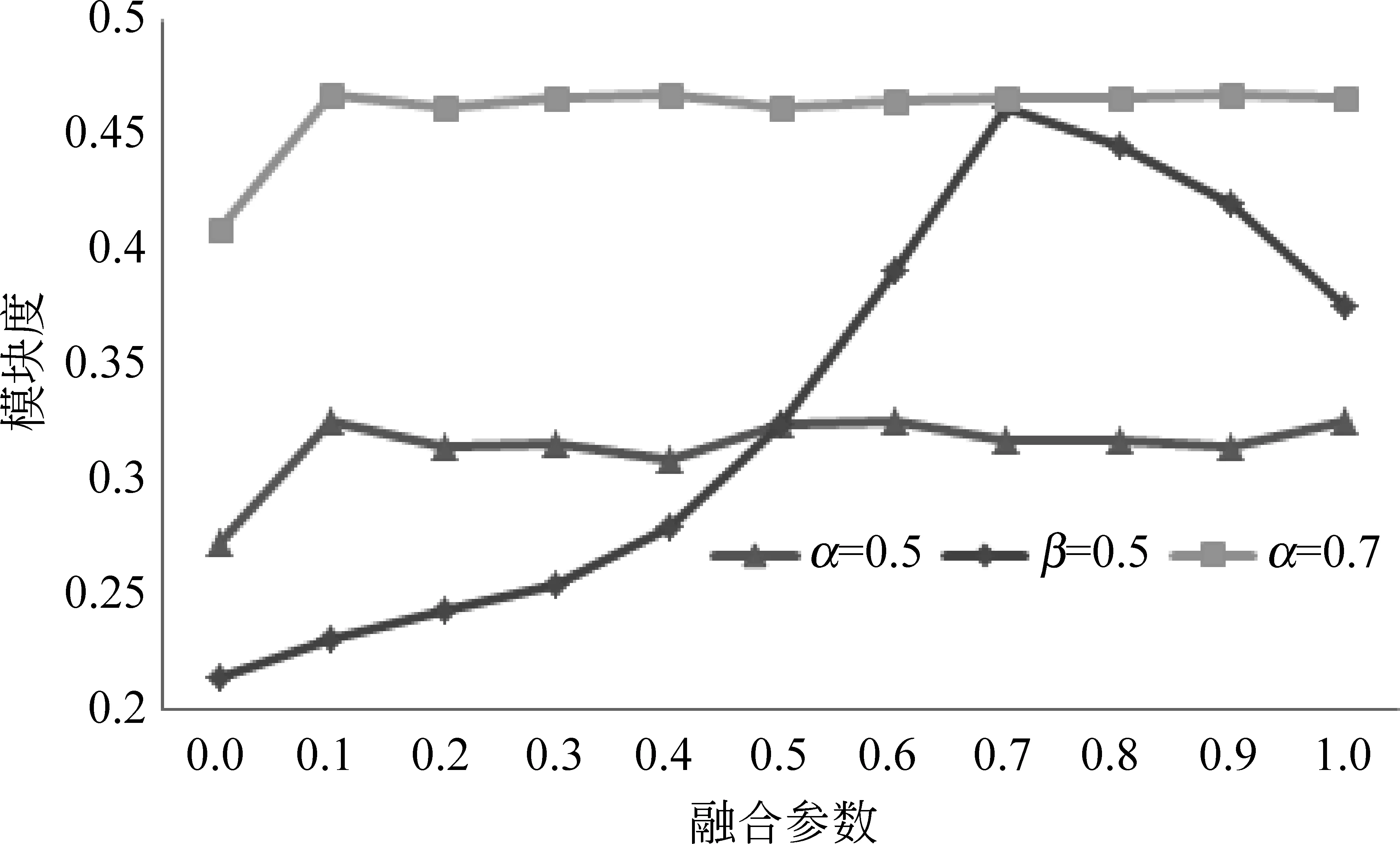
图2 参数改变对模块度的影响
4.3 增广网络的有效性验证
为验证融合文本内容和链接信息策略比只考虑链接信息或只考虑内容信息的社区检测结果更好,分别对用户链接相似度网络、内容相似度网络和融合内容与链接信息的增广网络进行社区检测。为去除用户顺序对算法在社区检测时产生的影响,对用户数据序列乱序并进行10次仿真实验。在实验中算法对三种网络进行社区检测获得模块度的最大值、最小值和平均值如表2所示。(本文实验平台的服务器配置为Intel(R)Core(TM)2 Duo CPU E8400 @ 3.00GHz x2,8.00GB内存,Python 2.7.3)
如表2所示,因为内容信息网络为全网络,与现实存在的社交网络并不相符,所以在只考虑内容信息时,检测出社区后的模块度很小,且达不到具有社区结构下界。
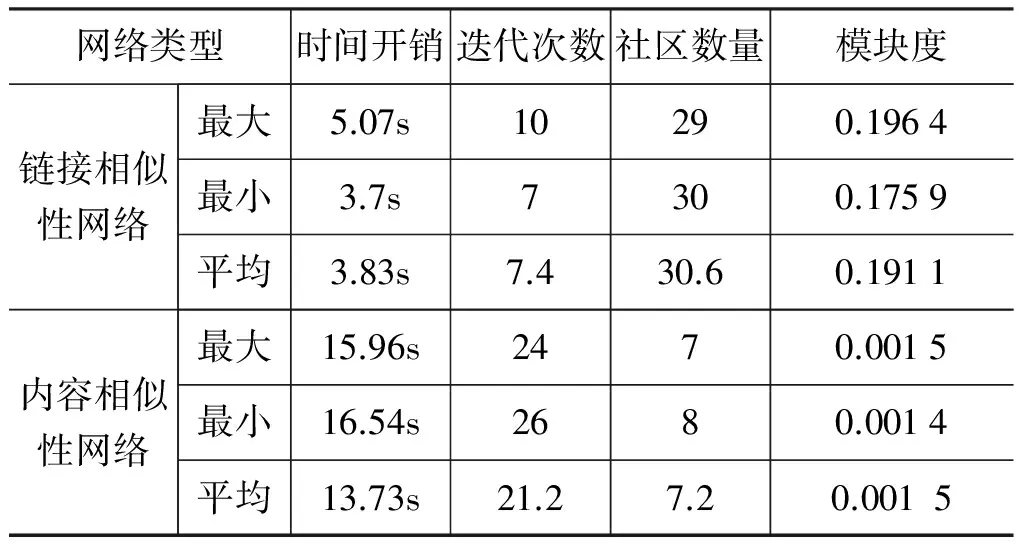
表2 三种网络社区检测结果
续表
相比于只考虑链接信息,在融合文本内容和链接信息的增广网络进行社区检测时,随着模块度的提升,社区数量快速地降低,使得检测过程中计算节点转移邻接社区的时间开销降低,且在收敛时模块度平均提升了0.185,是链接信息网络的2.083倍。
4.4 算法有效性验证
为验证本文算法相比于其他算法能在更少的时间开销上获得更好的社区检测结果,本文将CD-AN与CPM算法[8]进行实验对比,实验结果如图3至图5所示。在和CPM算法对比的实验中,本文控制节点数量(连边数量)这一变量对两算法进行了社区数量、模块度和时间开销对比。通过图3可以得出,当融合参数α=0.7,β=0.5时,随着节点数量的增加,本文算法检测出的社区个数与CPM算法较为一致,且随着节点增加,CD-AN在社区数量增长上更为平稳;在图4的模块度对比中能明显看出本文算法检测社区后计算出来的模块度均比CPM算法检测社区后获得的模块度高,即本文算法检测出的社区更为紧凑;在图5的时间开销对比上,随着节点(连边)的数量增加,CPM算法的时间开销增长比本文算法的时间开销增长更为明显。综上表明,CD-AN在社区数量稳定性、模块度和时间开销三个指标上均比CPM算法理想。
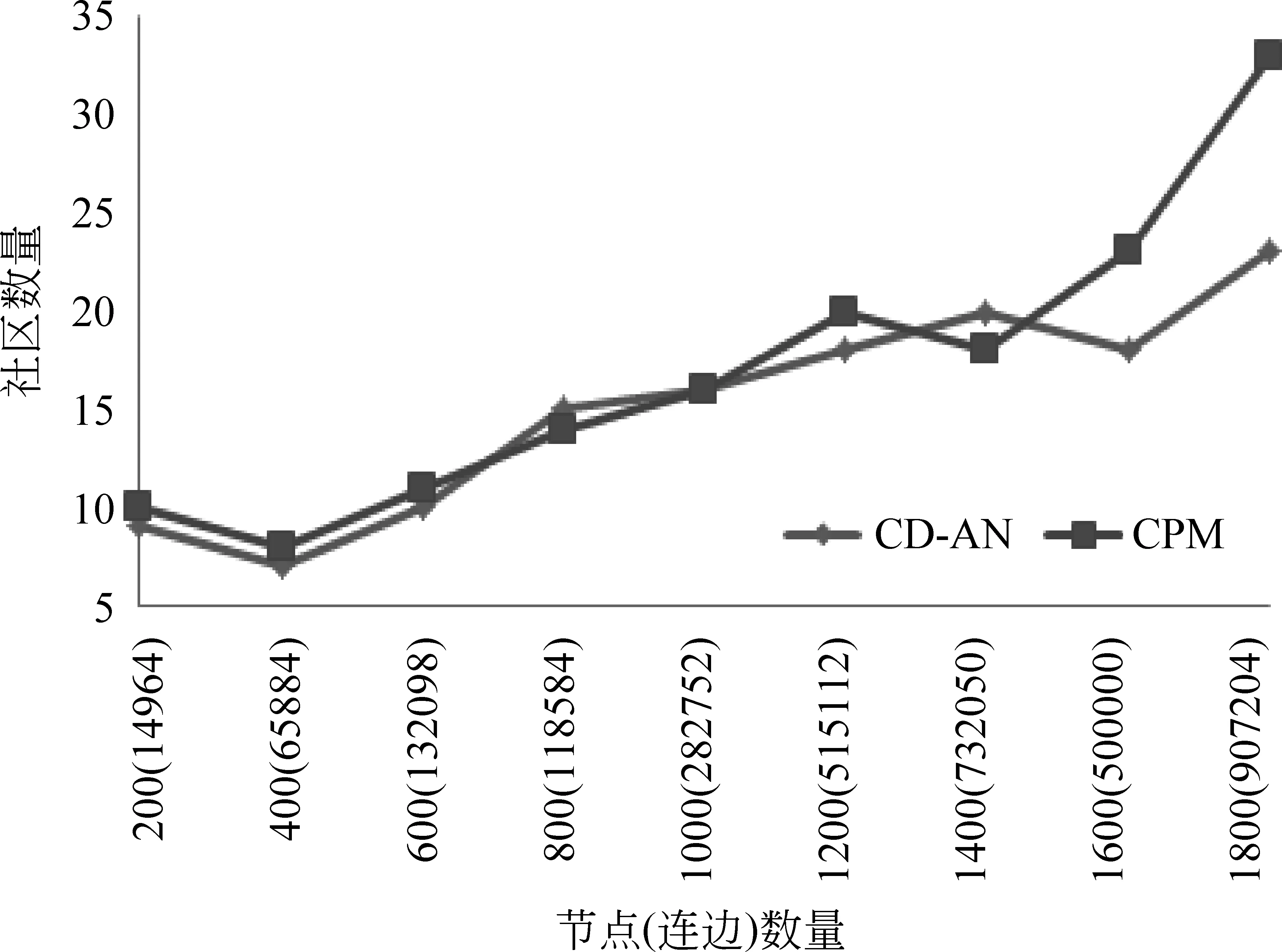
图3 检测出的社区数量对比图
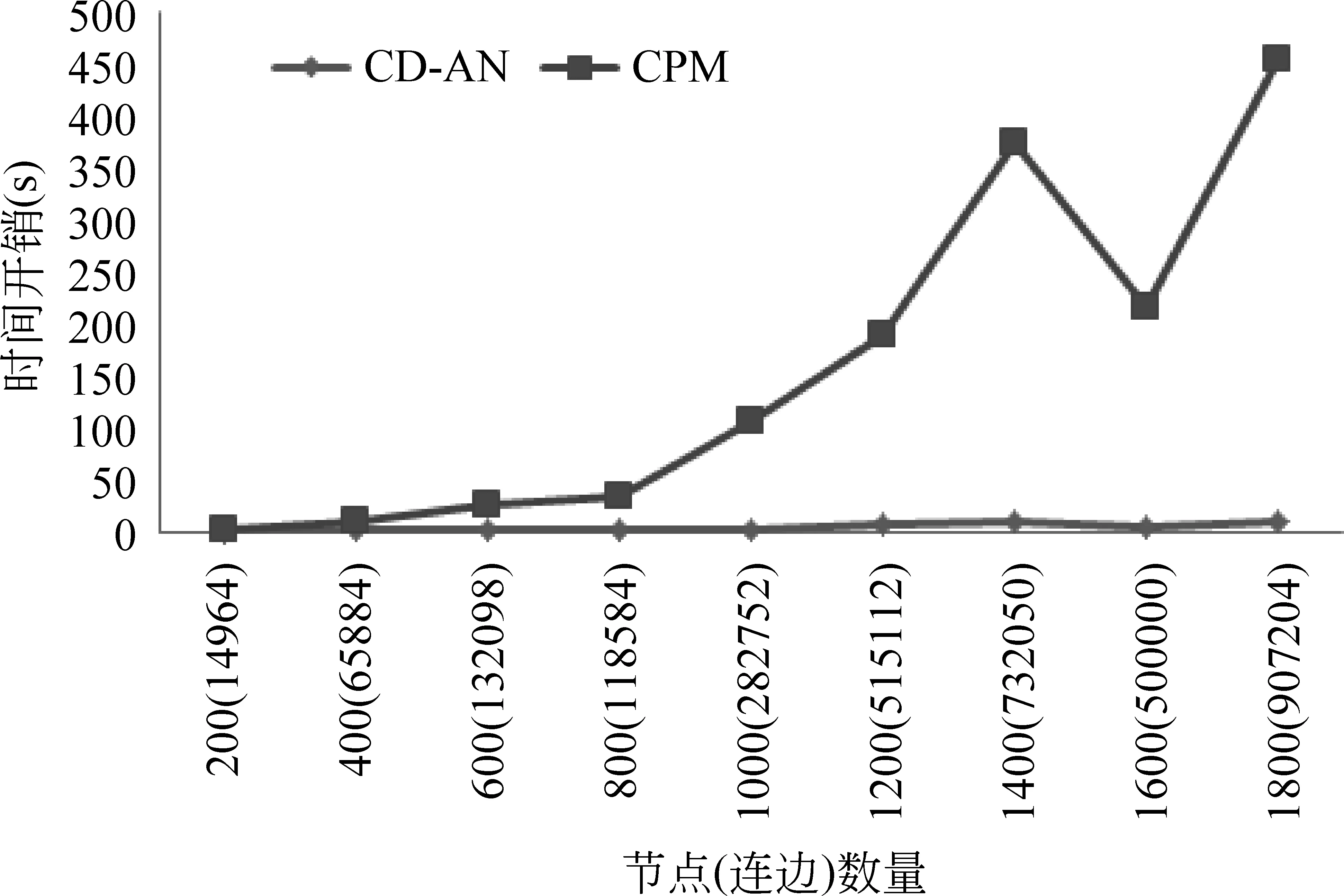
图5 时间开销对比图
4.5 社区检测效果分析
在选定融合参数α=0.7,β=0.5时,CD-AN在融合内容和链接信息的增广网络上社区检测效果如图6和表3所示。由图6可以看出微博社交网络中具有明显的社区结构特征,即在同一社区的节点之间联系较为紧密,在不同社区的节点之间联系较为松散。由表3可以看出,增广网络共划分出19个社区,其中大型社区(社区节点占有率>20%)有二个,中型社区(社区节点占有率>5%)有三个,其余均为小型社区。
4.6 社区主题特征分析
由于社区检测过程中考虑到了用户的内容信息,通过进一步的分析,可以得到各个社区所关注的主题。在过滤了一些共有或不带有主题含义的停用词如“微博”、“转发”、“客户端”、“今天”等后,选择排名Top 10的词作为社区的主题词集,并通过人工理解获得社区的主题描述。各个社区的主题分布如表4所示。
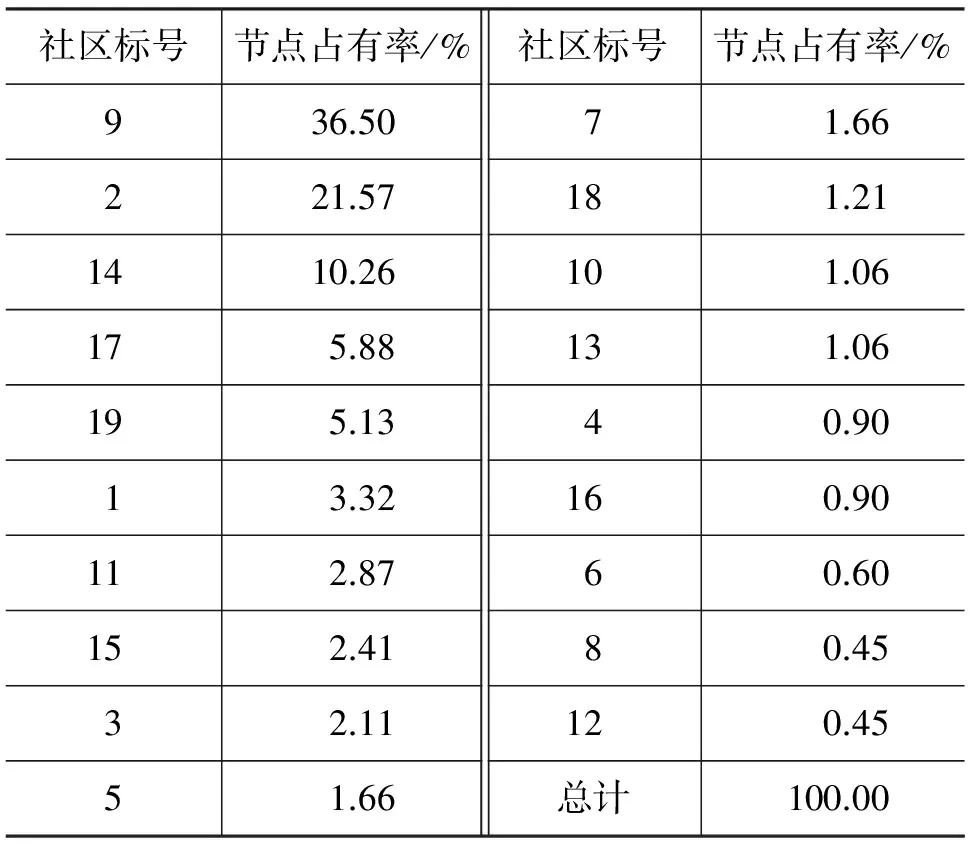
表3 各个社区的节点占有百分比

图6 融合内容和链接信息的增广网络社区检测结果

表4 各个社区的主题词集
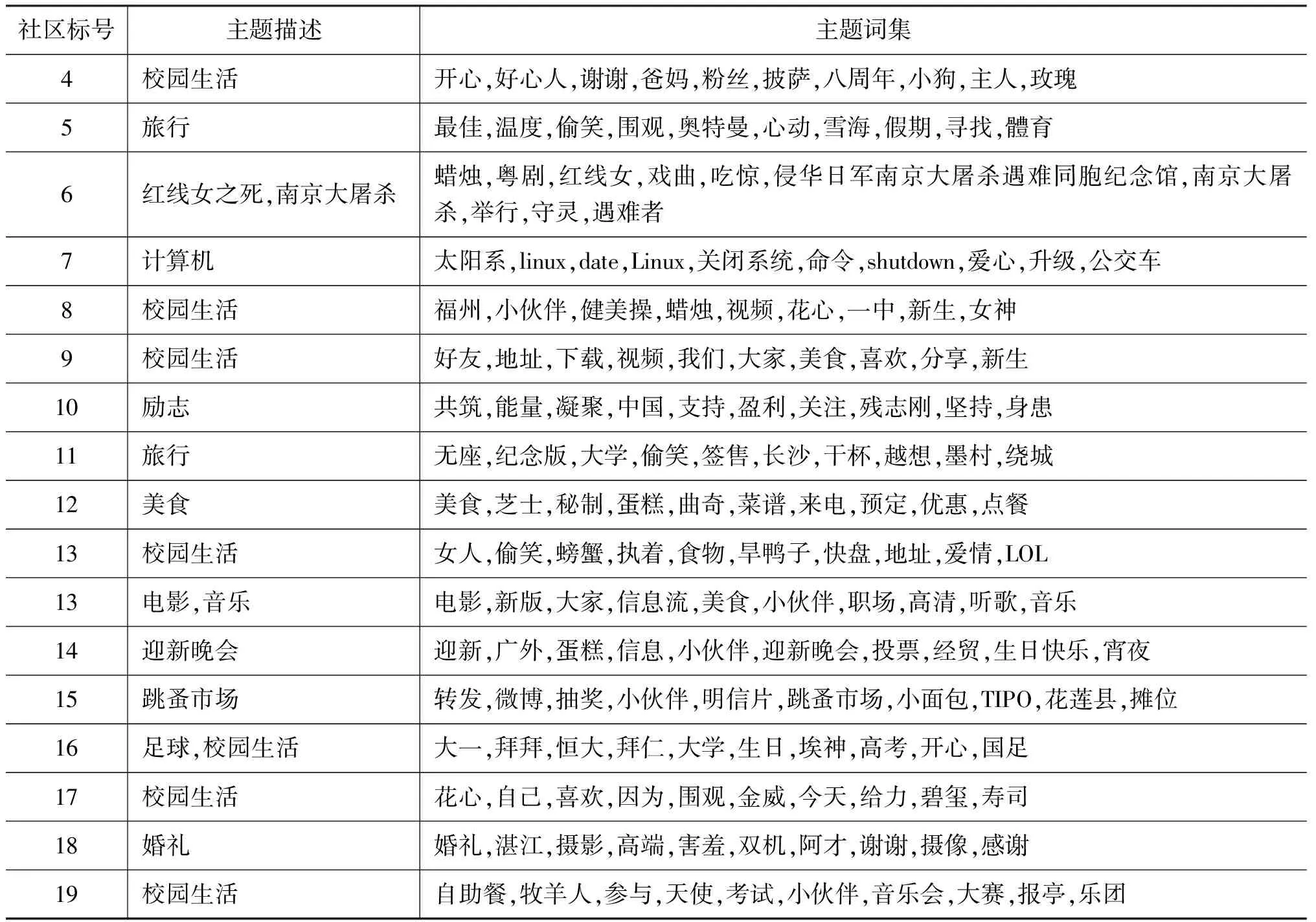
续表
由于实验数据中的用户大多为高校的学生,因此社区的主题特征带有校园生活内容的特征。部分社区具有明显的主题性,如社区14的主题可理解为“迎新晚会”;社区18的主题可以理解为“婚礼”等。部分社区包括1个以上的主题,如社区6的主题包括了“红线女之死”和“南京大屠杀”;社区13的主题包括“电影”和“音乐”。
5 结束语
微博作为当前最热的社交媒体之一,有效地检测出微博中的用户社区不仅能够为用户提供个性化推荐服务,而且也能够为商家提供定向广告投放的依据。然而,目前的社区检测算法大多只考虑了社交网络的链接信息,忽略了节点自身的内容特征,并且面向微博社交网络的社区检测算法存在时间复杂度过高的问题。针对上述问题,本文提出了一种基于增广网络的快速微博社区检测算法。该算法首先对用户发布的微博博文进行分析,获得用户的内容特征向量,并通过主成分分析对用户内容特征向量进行降维处理,提升了算法执行效率;其次通过Jaccard相关性系数计算用户链接相似,最后融合用户的内容相似度矩阵和链接相似度矩阵,获得用户的增广网络,并对增广网络进行快速的社区检测。实验结果表明: 相比于单独考虑链接信息或节点内容的社区检测算法,本文提出的方法能够高效地检测出较好的微博社区,且检测出的社区能够体现不同的主题特征。同时,与CPM算法相比,本文提出的方法时间开销更小,检测效果更好。
然而,由于新浪微博数据开放策略的限制,使得本文获取的实验数据量较少。在后续工作中,将采用本文算法对更大规模的社交网络进行社区检测,并通过分布式计算进一步提高算法的执行效率。
[1] 蒋盛益, 杨博泓, 吴美玲. 基于快速社区检测的协同过滤推荐算法[J]. 广西大学学报(自然科学版), 2013, 38(6): 1408-1412.
[2] Fortunato S, Castellano C. Community structure in graphs[M].Computational Complexity, Springer New York, 2012: 490-512.
[3] Girvan M, Newman M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences, 2002, 99(12): 7821-7826.
[4] Newman M E J. Analysis of weighted networks[J]. Physical Review E, 2004, 70(5): 056131.
[5] Clauset A, Newman M E J, Moore C. Finding community structure in very large networks[J]. Physical Review E, 2004, 70(6): 066111.
[6] Blondel V D, Guillaume J L, Lambiotte R, et al. Fast unfolding of communities in large networks[J]. Journal of Statistical Mechanics: Theory and Experiment, 2008(10): 10008.
[7] Donetti L, Munoz M A. Detecting network communities: a new systematic and efficient algorithm[J]. Journal of Statistical Mechanics: Theory and Experiment, 2004(10): 10012.
[8] Palla G, Derényi I, Farkas I, et al. Uncovering the overlapping community structure of complex networks in nature and society[J]. Nature, 2005, 435(7043): 814-818.
[9] 蔡波斯, 陈翔. 基于行为相似度的微博社区发现研究[J]. 计算机工程, 2013, 39(8):55-59.
[10] 闫光辉, 舒昕, 马志程, 等. 基于主题和链接分析的微博社区发现算法[J]. 计算机应用研究, 2013, 30(7): 1953-1957.
[11] Yang C, Ding H, Yang J, et al. Mining Microblog Community Based on Clustering Analysis[C]//Proceedings of the International Conference on Information Engineering and Applications (IEA) 2012. Springer London, 2013: 825-832.
[12] Huang T, Peng D, Cao L. Discovering Communities with Self-Adaptive k Clustering in Microblog Data[C]//2012 Proceedings of IEEE, 2012: 383-390.
[13] https://github.com/[OL].[2014-03-02].https://github.com/fxsjy/jieba
A Fast Microblog Community Detection Algorithm Based on Augmented Network
JIANG Shengyi1,YANG Bohong1,YAO Juanna1,WU Meiling2, ZHANG Yusha3
(1. School of Informatics, Guangdong University of Foreign Studies, Guangzhou,Guangdong 510006, China; 2. Alibaba Group, Guangzhou,Guangdong 510620, China; 3. South China Business College,Guangdong University of Foreign Studies, Guangzhou,Guangdong 510545, China)
Microblog is one of the most popular online social media nowadays. Identification of users’ community structure on Microblog can help people understand the community structure as well as users’ behaviors, and even provide personalized service for users. Currently, most of the studies on Microblog community detection algorithm focus on the link information, ignoring the information posted by users. To address this issue, a fast Microblog community detection algorithm based on augmented network is proposed. The algorithm constructs an augmented network by integrating users’ link information and content, on which community can be identified efficiently. Experimental results show that the proposed algorithm performs better in identifying the community structure of social networks in real Microblog network when compared with other algorithms.
Microblog; community detection; modularity; principal component analysis; augmented network; topic community

蒋盛益(1963—),教授,主要研究领域为数据挖掘与自然语言处理。E⁃mail:jaingshengyi@163.com杨博泓(1991—),硕士研究生,主要研究领域为用户关系挖掘和个性化推荐。E⁃mail:boryee@qq.com姚娟娜(1992—),学士,主要研究领域为数据挖掘、社会网络分析。E⁃mail:denayao@foxmail.com
1003-0077(2016)05-0065-08
2014-09-07 定稿日期: 2015-12-20
国家自然科学基金(61572145);广东省科技计划项目(2014A040401083);广东省哲学社会科学“十二五”规划项目(GD14YXW02)
TP391
A
