基于多层Markov网络的信息检索模型
2016-05-03廖亚男王明文左家莉吴根秀甘丽新
廖亚男,王明文,左家莉,吴根秀,甘丽新
(1. 江西师范大学 计算机信息工程学院,江西 南昌 330022;2. 江西师范大学 数学与信息科学学院,江西 南昌 330022;3. 江西科技师范大学,江西 南昌 330038)
基于多层Markov网络的信息检索模型
廖亚男1,王明文1,左家莉1,吴根秀2,甘丽新3
(1. 江西师范大学 计算机信息工程学院,江西 南昌 330022;2. 江西师范大学 数学与信息科学学院,江西 南昌 330022;3. 江西科技师范大学,江西 南昌 330038)
随着信息检索技术的不断发展,挖掘更加有效的信息来提高检索精度成为研究热点,已有的研究表明在检索过程中有效地融合各种信息将得到更好的检索效果。对一个具体查询而言,可以充分利用与已有查询的相关性、词语相关性和文档相关性等信息进行查询扩展和重构。基于这种思路,该文分别构造查询网络、词网络和文档网络,提出了多层Markov网络的信息检索模型,模型可以融合词间关系、文档间关系和查询间关系,为了有效降低计算量,给出了基于团计算模型。在标准数据集上的实验表明该文的模型能够有效融合三类信息,并较大幅度地提高检索效果。
信息检索;多层Markov网络;查询扩展;团
1 引言
信息检索的核心的问题是如何从海量信息中快速地检索出与用户需求相关的内容。Fox E A, Nunn G L[1]等提出并证明把有效的附加信息融合至信息检索中将产生更好的检索效果。查询扩展就是利用附加信息的方法来提高检索效果,为了改善信息检索中的召回率,这种方法将初始查询句增加新的关键字来重构查询,使查询包含更多的有效信息,从而找出更多的相关文档。
查询扩展的方法有很多种[2-4],除了人工查询扩展,即由用户自己人工修正查询以外,还有相关反馈的查询扩展,基于人工词典资源如WordNet,HowNet等相关语义词表的查询扩展[5]以及利用图形网络模型的查询扩展。左家莉等提出一种基于Markov网络的信息检索扩展模型[6],该模型通过对文档集的学习,构造了关于索引项和文档的Markov网络,将有利于检索的信息加入到检索中,从而改善检索结果。但是该工作只提取了词与词和文档与文档的一层关系,没有考虑他们之间的多层关系。盛俊等提出潜在语义的Markov网络检索模型[7],通过对文档集的学习,词之间和文档之间的潜在语义被提取出来,从而构造出Markov知识网络,然后利用Markov网络学习到的潜在语义信息进行检索。甘丽新等提出了一种基于Markov概念的信息检索模型[8],使用团的提取算法为每个查询在网络中提取最相关的扩展词进行查询扩展,该模型取得了良好的检索效果。但是该工作没有考虑文档间和查询间的相似度。付剑波等提出基于团模型的文档重排算法研究[9],此模型通过对文档集的学习,构造文档与文档关系的Markov网络,提取出文档团,应用文档团信息进行文档重排,但是该工作没有将文档团信息用于查询扩展中。
对一个具体查询而言,可以充分利用与已有查询的相关性、词语相关性和文档相关性等信息进行查询扩展和重构。基于这种思路,本文在前述工作基础上,提出了基于多层Markov网络的信息检索模型,首先通过计算词与词之间的相关性、文档与文档之间的相关性来构造词网络和文档网络,接着用基于团的Markov网络信息检索模型[8]得出的检索结果,即数据集中反馈出的每个查询所对应的一些相关文档,由这些文档计算出查询之间的相关性,从而构造出查询网络。然后对这三个网络空间分别做团的提取,最后将词团、文档团和查询团这三种关系结合在一起,重新计算文档与查询之间的相关概率即条件概率,从而提高检索性能。在本文的实验中将我们的模型与一些经典的模型进行比较,结果表明本文的模型检索性能更优。
2 基于多层Markov网络的信息检索模型
2.1 Markov网络的描述
Markov网络是一种不确定性推理的有利图形工具[10],可以较好地表示知识关联,我们可以从实例数据来训练获得Markov网络。由于Markov网络具有强大的学习功能,不需要构造边的方向,因此构造Markov网络比发现贝叶斯网络容易得多。用Markov网络中的无向边来解释信息检索中的语义关系更加直观恰当。Markov网络可以表示为一个二元组(V,E),V为所有节点的集合,E为一组无向边的集合,E={(xi,xj)|xi≠xj∧xi,xj∈V},E中的边表示节点之间的相关关系。如图1所示,通过词项间相关性得出的Markov网络结构中,每个词为一个节点,连接两节点的边表示两节点间的关系,用权重表示其相关性。当查询为“苹果笔记本”时,分别找到“苹果”的相关词“MacBook”、“电脑”、“香蕉”和“水果”,而“笔记本”的相关词又有“文具”、“电脑”等,可以发现“香蕉”、“水果”和“文具”这些词对于查询“苹果笔记本”基本上是没有关系的,如果直接把这些相关词全部作为扩展词加入检索中,势必会降低结果的准确率。因此本文选取与查询关键字形成最大团结构的相关词如“MacBook”和“电脑”为查询扩展词,从而达到语义比较集中。在本文中,分别以查询、词项和文档作为节点,计算查询间相关性、词项间相关性和文档间相关性,从而构造出查询网络、词网络和文档网络。

图1 Markov网络结构
2.2 基于多层Markov网络的信息检索模型描述
本文的模型融合查询间关系、词间关系和文档间关系,分为三层:查询子空间、索引词项子空间、文档子空间。如图2所示,每层空间都构成了一个推理网络,根节点分别为查询子空间的查询节点、词项子空间的词节点和文档子空间的文档节点。本文利用词与词之间的相关性来构造词项子空间,文档与文档之间的相关性来构造文档子空间,由基于团的Markov网络信息检索查询反馈[11]得到的相关文档的相关程度得出查询与查询之间的相关性来构造查询子空间。
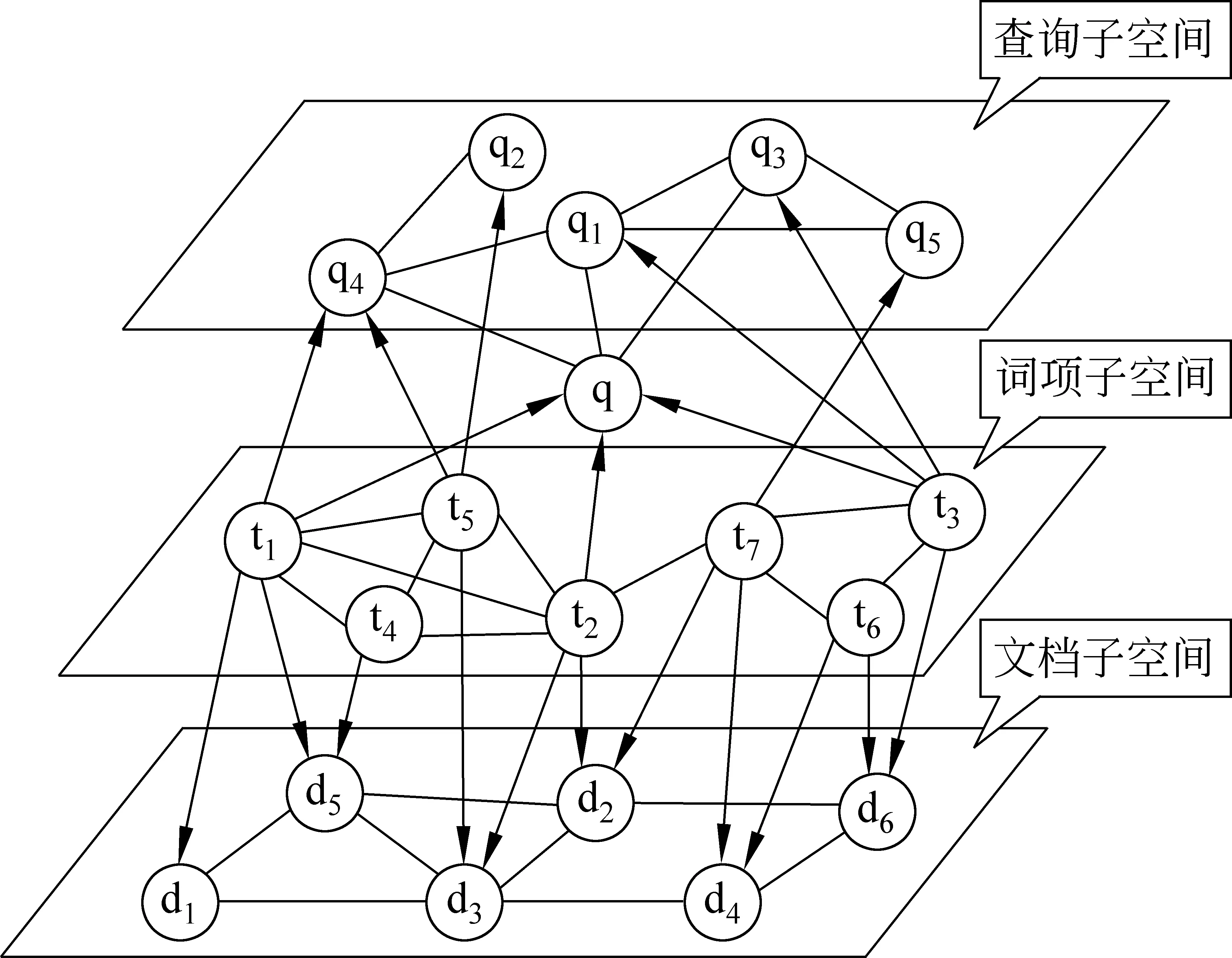
图2 基于多层Markov网络的信息检索模型
在图2中,qi代表查询子空间中的查询,q代表初始查询,ti代表词项子空间中的词项,di代表文档子空间里的文档,边的类型有五种。
(1) 对任意的ti∈q,有一条从ti指向q的边,这代表查询q中包含词项ti;
(2) 在词项子空间中,词与词之间有一条无向边,边的权重取决于词与词之间依赖的程度;
(3) 对任意的ti∈d,有一条从ti指向d的边,这代表文档d中包含词项ti;
(4) 在文档子空间中,文档与文档之间有一条无向边,边的权重取决于文档与文档之间的依赖程度;
(5) 在查询子空间中,查询与查询之间有一条无向边,边的权重取决于查询与查询之间的依赖程度。
在基于多层Markov网络的信息检索模型中,给定一个初始查询,我们要计算文档集中的文档和查询的相关概率。通过对Markov网络的学习,从构造的词项子空间中选择与查询词形成最大团结构的相关词作为查询扩展词,从文档子空间选择与查询词有边相连的文档形成最大团结构的相关文档信息,从查询子空间中选择与初始查询有边相连的查询形成最大团结构的相关查询信息,重新计算文档与查询之间的相关概率。
2.3 词项相关性的度量
在本文中均采用词的共现性来提取词与词之间的关系,计算词共现的词频时一般可以以整个文档、段落或是一个固定长度为窗口[12]。基于效率上的考虑,本文选择文档作为窗口单元,对文档集的倒排文件进行统计,两个词共现的次数越高,则相关性就越高。由于Markov网络检索模型中词与词之间的无向性,因此采用两个词的综合共现性来计算,即公式(1)~(3)。
(1)
(2)
(3)
其中ti和tj指两个词项,C(ti,tj)指在训练文档集中ti和tj在同一篇文档中同时出现的次数,C(ti)指在训练文档集中ti出现的次数,C(tj)指在训练文档集中tj出现的次数,Sim(ti,tj)指ti和tj之间的关系,Sim值越大,两个词的相关性越高。给定阈值η词,如果Sim(ti,tj)≥η词,则认为ti与tj相互依赖,即在多层Markov网络检索模型的词项子空间中有边相连。
2.4 文档相关性的度量
在本文中文档均表示为向量,采用文档向量之间的夹角来构造文档子空间,表示为公式(4)。
(4)
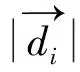
2.5 查询相关性的度量
大多数查询的主题在搜索时是模糊不清的,WangX,ZhaiCX等从网络搜索日志中组织搜索结果,从搜索日志数据中挖掘出给定查询的相似查询[13-14]。在本文中查询之间的关系由与查询相关的文档间的依赖关系所决定,利用基于团的Markov网络信息检索模型[8]得出的每个查询返回的文档,本文取每个查询返回的前两篇相关文档,把这两篇相关文档信息合并,通过计算文档间的相似度来确定查询间的相似性,即式(5)。
(5)
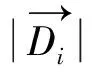
2.6 团的提取

3 文档与查询间的相关概率
在基于多层Markov网络的信息检索模型中,给定查询q,可以计算文档集D中任意文档dj∈D和查询q的相关概率p(dj|q),根据p(dj|q)值的大小给文档集中的文档排序,从而得出相关文档。由左家莉等提出一种基于Markov网络的信息检索扩展模型[6]可得公式(6)。
(6)
其中ti指一个词项,假定
wi,q和wi,j可以选用多种权重计算方式,分别表示为式(7)和式(8)。在本文的实验中,我们采用BM25 类似权重方式来计算权重。
(7)
其中α为归一化因子,tfti指ti在q中出现的频率,tft指构成q的所有的t在q中出现的频率。
(8)
其中,N指文档集中的文档数,nti指出现ti的文档数,fti指该文档出现ti的次数,dlti指该文档的长度,avedl指文档集中所有文档的平均长度,K和b是经验参数。
在检索阶段,本文以最大团为单位,基于词团,把词作为一个概念整体扩展进来,与原始查询词重新组成一个新查询,通过修正词的权重,重新构造文档和查询之间的相关性,计算文档与查询的相关概率p′(dj|q)。由公式(6)修正得到公式(9)。
(9)
其中t和tk指词项,θ指平滑参数(0≤θ≤1),Cmax(t)指包含t的最大团集,sim(tk,t)指tk和t的相关程度。
然后基于文档团,计算新查询与文档所在团的其他文档dk的相关概率p′(dk|q),如式(10)所示。
(10)
基于查询团,计算文档与初始查询所在团的其他查询qi的相关概率p′(dj|qi),如式(11)所示。
(11)
最后通过文档间的相似性和查询间的相似性,由公式(9)、(10)和(11)可得出文档和查询的最后相关概率公式式(12)。
(12)
其中α(0≤α≤1)为基于文档子空间的平滑参数,β(0≤β≤1)为基于查询子空间的平滑参数,通过调节平滑参数,使得模型达到检索性能的最优状态。Cmax(dj)指包含dj的最大团集,Cmax(q)指包含q的最大团集,sim(dk,dj)指文档dk和dj的相关程度,sim(q,qi)指查询q和qi的相关程度。
4 实验设计和结果
一个标准的测试集一般包括一个文档集、一组查询和每一个查询相对应的相关文档集(由专家判断)。本文实验的测试集由Adi、Med、Cran、Cisi及Cacm五个标准测试文档集组成,它是一个较常用的测试数据集,常用于对检索系统的性能评价,该测试集的文档较小,且评价效果良好。具体内容如表1 所示。
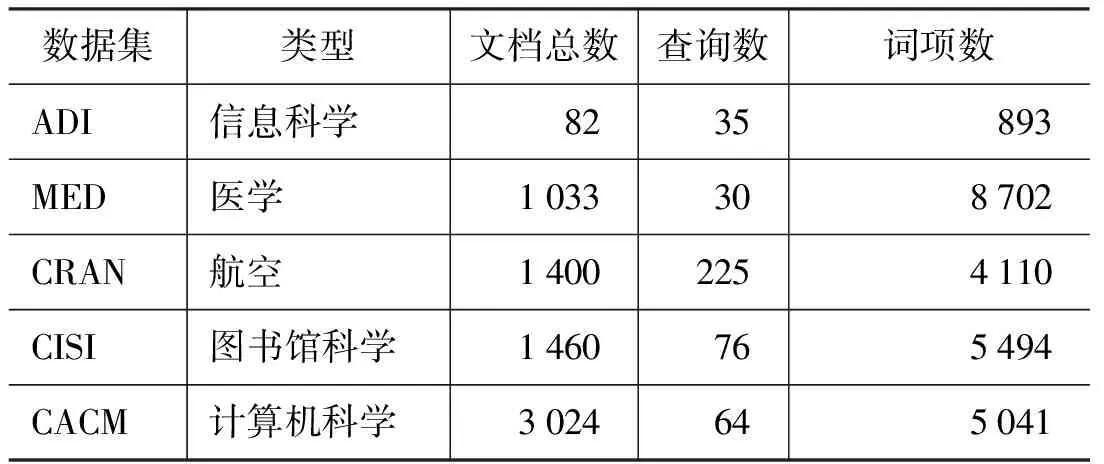
表1 实验中的数据集
本文模型中有θ、α、β这三个参数以及阈值η词、η文档、η查询,调整这些参数和阈值的大小,都会对实验结果有一定的影响。理论上,我们设置词团的权重最大,文档团权重次之,查询团权重最小。因此分别令α以0.02,β以0.01的增量;α以0.03,β以0.01的增量;α以0.03,β以0.02的增量进行实验比较,最终选择第一种方式。以数据集Adi为例,当θ取0.025,η词取0.6,η文档取0.1,η查询取0.3,调整文档权重参数α和查询权重参数β的值,图3说明其对实验结果的影响。
在图3中,横坐标指α的值,实验中β的值为α/2,纵坐标指平均准确率,3-Avg指在三个召回率点(0.2,0.5,0.8)上每一个查询对应精度的平均值,11-Avg指在11个召回率点(0,0.1,…,1.0)上每一个查询对应精度的平均值,这也是我们实验中采用的评价指标。实验表明,在一定范围内α越大,检索结果越好,但达到一定值以后结果开始变差。其中在α=0.16,β=0.08时,实验结果达到最优。为了得出扩展词权重参数θ对检索结果的影响,我们同样取β=α/2的情况下,改变θ值,表2为Adi数据集下的最优检索结果。

图3 α和β值的调整对实验结果的影响

表2 Adi数据集中取不同θ值的最优检索结果
本文把基于团的Markov网络信息检索模型作为Baseline,与我们提出的基于Markov网络的多层信息检索扩展模型(简称MMR)做实验对比。表2表明,在数据集Adi中,无论是在3-Avg还是11-Avg上,我们的模型检索效果都明显优于Baseline,其中在θ=0.025时检索结果达到最优。实验中我们还发现改变θ的值对实验结果影响不是很大,这是因为在Adi中,词项的数量相对较少。
最后,我们取MMR的最优检索效果和其他一些经典检索模型分别在Adi、Med、Cran、Cisi及Cacm这五个标准测试文档集上做对比实验。在实验中,由于Adi数据集中的词项个数比较少,因此词之间的相关性阈值取0.6,其余四个数据集取0.7。由于Cacm数据集文档比较多,因此文档相关性阈值取0.2,其余四个数据集取0.1。由于Cran数据集查询比较多,因此查询相关性阈值取0.5,其余四个数据集取0.3。由于本模型中词的权重最大,因此词团的最大团的个数变化会使实验结果产生波动。在实验中每个数据集加入的词团个数大约在(15,30)之间,所有的文档最大团和查询最大团都加入考虑。实验表明本文模型的实验效果不仅优于Baseline模型,而且明显比其他一些经典模型如hits模型,tf模型,idf模型,tf*idf模型和BM25模型要好。实验结果见表3和表4。
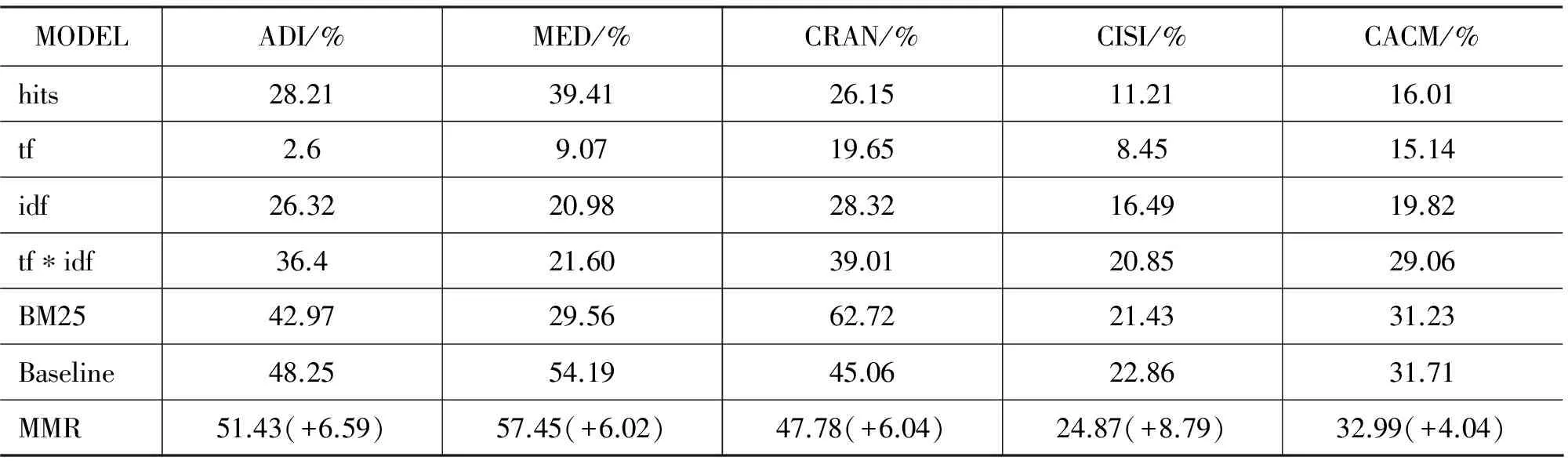
表3 3-Avg实验结果
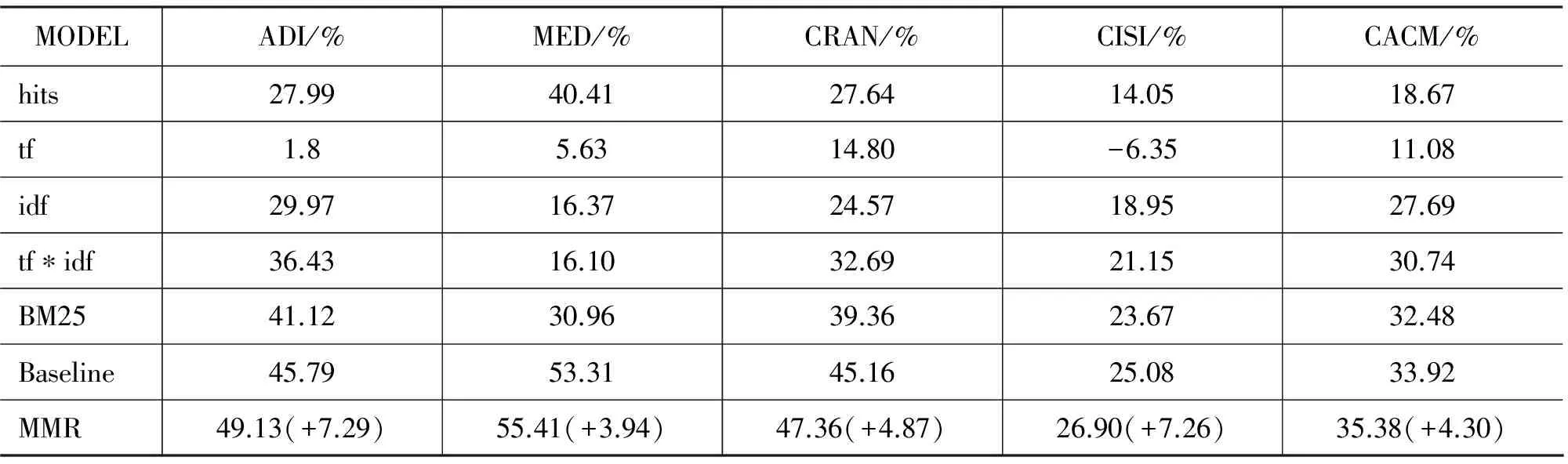
表4 11-Avg实验结果
5 总结与展望
本文提出并实现了基于多层Markov网络的信息检索模型,我们以词与词、文档与文档和查询与查询之间的关系构造Markov网络,为了有效降低计算量和避免加入较多的噪音信息,通过分别设定阈值,提取词团、文档团和查询团信息,给这些信息分别赋予不同的权重,加入到信息检索的过程中,并计算文档与查询的最终相关概率。实验结果表明,本文所提出的模型可有效提高检索的效果。
进一步的工作有: (1)本文以文档为窗口单元计算词与词之间的相关性,未来我们将考虑以段落或是句子为单元进行计算;(2)本文利用向量夹角度量文档与文档之间的相关性,未来我们将会考察其他的方法;(3)本文用基于词团的方法得出的相关文档来计算查询与查询之间的相关性,在今后我们可以利用查询日志来更好地刻画查询之间的关系;(4)本文的实验基于Adi、Med、Cran、Cisi和Cacm这五个相对较小的数据集,在未来可以考虑使用一些大数据集。
[1] Fox E A, Nunn G L, Lee W C. Coefficients of combining concept classes in a collection[C]//Proceedings of the 11th annual international ACM SIGIR conference on research and development in information retrieval. ACM, 1988: 291-307.
[2] 王斌 译.信息检索导论[M].第一版.人民邮电出版社,2010.
[3] 贺宏朝,何丕廉,陈霞.利用人工和自动生成的资源进行中文信息检索查询扩展[J]. 计算机工程与应用,2002,21:18-20.
[4] 张敏,宋睿华,马少平.基于语义关系查询扩展的文档重构方法[J].计算机学报,2004,27(10):1395-1401.
[5] Richardson R, Smeaton A F, Murphy J. Using WordNet as a knowledge base for measuring semantic similarity between words[R]. Technical Report Working Paper CA-1294, School of Computer Applications, Dublin City University, 1994.
[6] 左家莉,王明文,王希.基于Markov网络的信息检索扩展模型[J].清华大学学报:自然科学版,2005,45(1):1847-1852.
[7] 盛俊.潜在语义的 Markov 网络检索模型的研究[D].江西师范大学,2006.
[8] 甘丽新. 基于 Markov 概念的信息检索模型[D]. 江西师范大学, 2007.
[9] 付剑波,王明文,罗远胜,等.基于团模型的文档重排算法研究[J].中文信息学报,2009,23(1):71-78.
[10] 何盈捷, 刘惟一. 由 Markov 网到 Bayesian 网[J]. 计算机研究与发展, 2002, 39(1): 87-99.
[11] Xu Y, Jones G J F, Wang B. Query dependent pseudo-relevance feedback based on wikipedia[C]//Proceedings of the 32nd international ACM SIGIR conference on research and development in information retrieval. ACM, 2009: 59-66.
[12] 黄萱菁,张奇,邱锡鹏 译.现代信息检索[M].第一版.机械工业出版社,2012.
[13] Hu Y, Qian Y, Li H, et al. Mining query subtopics from search log data[C]//Proceedings of the 35th international ACM SIGIR conference on research and development in information retrieval. ACM, 2012: 305-314.
[14] Wang X, Zhai C X. Learn from web search logs to organize search results[C]//Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval. ACM, 2007: 87-94.
[15] Metzler D, Croft W B. Latent concept expansion using markov random fields[C]//Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval. ACM, 2007: 311-318.
An Information Retrieval Model Based on Multilayer Markov Network
LIAO Yanan1, WANG Mingwen1, ZUO Jiali1, WU Genxiu2,GAN Lixin3
(1. School of Computer Information Engineering, Jiangxi Normal University, Nanchang, Jiangxi 330022, China; 2. School of Mathematics and Information Science, Jiangxi Normal University, Nanchang, Jiangxi 330022, China; 3. Jiangxi Science & Technology Normal University, Nanchang, Jiangxi 330038, China)
The information retrieval usually can be improved by combining more information mined from the retrieval process. To fully take advantage of the existing queries correlation information, terms and documents for query expansion and reconstruction, we propose an information retrieval model based on multilayer Markov network. The Markov network is constructed by the correlation of query network, term network and document network. A clique model is further designed to speed up the computation. The experiments on the standard data sets have indicated that our model can integrate information of three aspects effectively for an improved effect of retrieval.
information retrieval; multilayer Markov network; query expansion; clique

廖亚男(1990-),硕士,主要研究领域为信息检索与数据挖掘。E⁃mail:yaya1022good@163.com王明文(1964-),通信作者,博士,教授,主要研究领域为信息检索、数据挖掘、机器学习。E⁃mail:mwwang@jxnu.edu.cn左家莉(1982-),博士,副教授,主要研究领域为信息检索、文本挖掘。E⁃mail:august813cn@hotmail.com
1003-0077(2016)01-0056-07
2013-08-17 定稿日期: 2014-04-20
国家自然科学基金(61272212,61462043,61462045);江西省自然科学基金(20122BAB211032,20151BAB217014);江西省高校人文社会科学青年基金(JC1312)
TP391
A
