基于N-Gram模型的蒙古语文本语种识别算法的研究
2016-05-03马志强张泽广刘利民冯永祥苏依拉
马志强,张泽广,闫 瑞,刘利民,冯永祥,苏依拉
(内蒙古工业大学 信息工程学院,内蒙古 呼和浩特 010080)
基于N-Gram模型的蒙古语文本语种识别算法的研究
马志强,张泽广,闫 瑞,刘利民,冯永祥,苏依拉
(内蒙古工业大学 信息工程学院,内蒙古 呼和浩特 010080)
互联网上蒙古语文本正在不断地增加,如何让网络中的蒙古语内容为搜索引擎和舆情分析等应用提供服务引起了社会的高度关注。首先要解决如何采集网络中蒙古语文本数据,核心是准确识别网络中蒙古语文本的问题。该文提出了基于N-Gram模型的平均距离识别算法,建立了一个能够对目标语种识别的实验平台。实验结果表明,识别算法能够很好地从中文、英文、蒙古文以及混合语言文本中识别出蒙古语文本,准确率达到99.5%以上。
语种识别;N-Gram模型;平均距离识别算法;蒙古语文本
1 研究背景
蒙古语是古老的民族语言之一,是内蒙古自治区的通用语言文字。蒙古语语言文字是一种以词为单位竖写的语言,词与词之间用空格分开,采取从上到下,从左到右的书写顺序。蒙古语语言文字有33个字母,其中7个元音、17个基本辅音和9个借词辅音。字母可以放置在词首、词中和词尾等不同位置,构成不同的词[1-2]。同时,蒙古语语言文字采用双字节编码,蒙古语语言文字也称为蒙古文。互联网上蒙古文内容正在不断增加,如何让网络中的蒙古文内容为搜索引擎和舆情数据分析等应用提供服务引起了社会的高度关注。为此,首先要解决如何采集网络中蒙古语文本数据,核心是准确识别网络中蒙古语文本的问题[3]。
蒙古文语种识别是一个文本语种分类问题[4]。研究者们在语种分类算法上开展了两个方面的研究:基于规则方法的研究和基于统计方法的研究[4-8]。首先,在基于规则方法的研究中,需要人工总结出语言知识并将其转换成系统规则[4],常见的具体做法就是利用特定语种中常见的字符串进行正则表达式匹配[5]。但基于规则的方法存在以下缺点:需要人工辅助和识别准确率不稳定[6-8]。其次,在基于统计方法的研究中,主要是基于N-Gram模型的文本语种识别算法研究[9-11]。文献[4]提出了基于N-Gram的Bayes算法,能够将维吾尔文从阿拉伯文、哈萨克文和柯尔克孜文等以阿拉伯字母为基础书写的类似文字中识别出来。最终网页论坛的识别准确率达到98.9%,微博客的识别准确率达到96.6%。但它需要进行多次计算,增加了返回结果的时间,降低了识别效率;文献[6]提出了基于 N-Gram 模型的最小距离算法,具有容错性强、适合处理含有噪音的文档及占用很小的存储与计算。在语种识别上达到了一个99.8%,但在语种识别时针对多语种。文献[5]针对汉、日等双字节编码语种,提出了基于字符层马尔科夫语言模型的EM算法,取得了较高的识别率,但其针对的是词间无空格分割的语种。
综合计算性能与识别准确率的考虑,在 N-Gram 模型上提出平均距离识别算法,建立了一个能够对目标语种识别的实验平台。实验结果表明,识别算法能够很好的从中文、英文、蒙古文以及混合语言文本中识别出蒙古文,准确率达到99.5%以上。
2 平均距离识别算法
定义1 目标语种文本可以表示成由音素、音节、字母或字组成的序列,形式化为C1C2…Ci-1CiCi+1…Cm-1Cm(1≤i≤m),Ci称为最小分割单元[12]。文本的N元切分模型为集合G,G={gi|gi=CiCi+1…Ci+N-1,1≤i≤m-N+1,N≤m},N称为滑动窗口的长度。L=|G|,表示集合中元素的个数。目标语种文本的N元切分模型如图1所示。
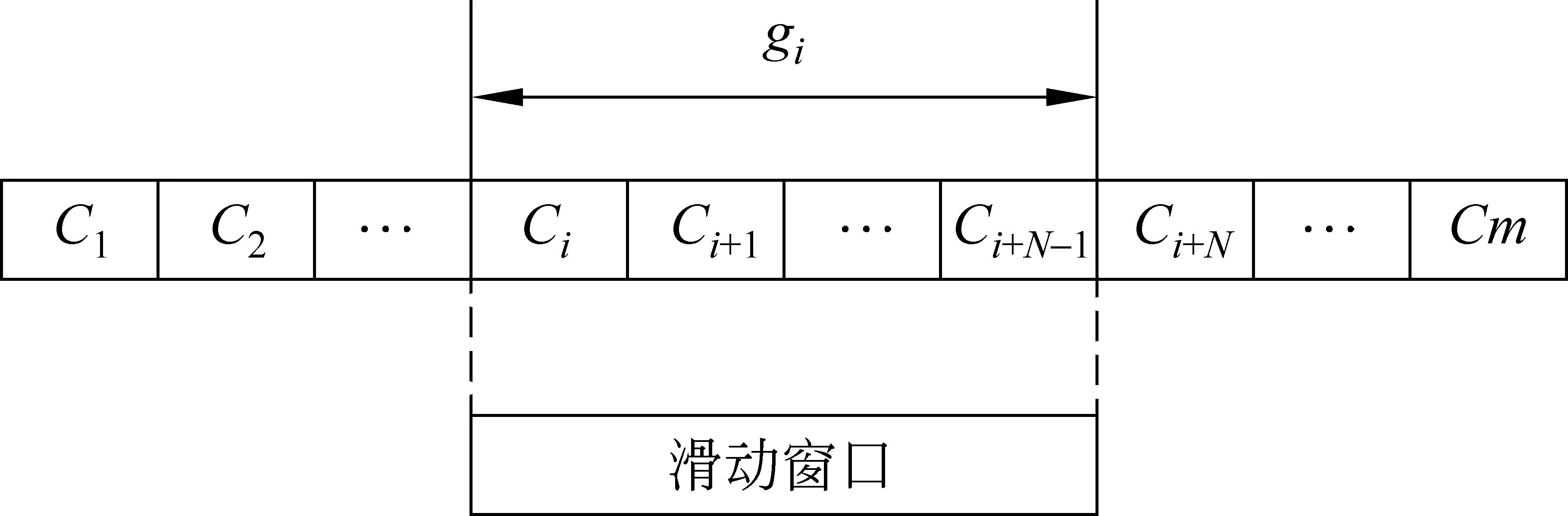
图1 目标语种文本N元切分模型
当N等于2、3和4时,分别称为二元(bigram)、三元(tri-gram)和四元(quad-gram)切分模型。例如,以蒙古文为例,图2中的左侧蒙古文文本(译为: 内蒙古)的bigrams、tri-grams和quad-grams如图2中右侧所示。

图2 蒙古语文本切分模型样例
定义2 统计N元切分模型中的gi,并按照降序排列,得到N元模型。训练模型称为TM,测试文本模型称为IM。gi在模型中的索引称为位置,表示为 pos(gi)。TM中的位置表示为posTM(gi),IM中的位置表示为posIM(gi)
定义3gi在IM与TM的位置差的绝对值称为gi的距离,即dis(gi),见式(1)。
(1)
其中find表示gi是否在TM模型中。当find=1表示gi在TM中,find=0表示不在。
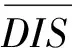
(2)
平均距离识别算法:
输入: 训练模型TM,测试文本,阀值T。
输出: 是否为目标语种
Step1: 计算测试文本的N元测试模型IM; //具体见N元模型计算算法
Step2: for (i= 1;i≤ LIM;i++)
Step3: for (j= 1;j≤ LTM;j++)
Step4: Begin
Step5: if (find == 1)
Step6: dis(gi)=|posIM(gi)-posTM(gi)|;
Step7: else
Step8: dis(gi) = MAX;
Step9: DIS = DIS + dis(gi);
Step10: End;
Step13: 输出测试文本为目标语种;
Step14: else
Step15: 输出测试文本为非目标语种;
Step16: END;
N元模型计算算法:
输入: 文本,N。//N表示滑动窗口的大小
输出: N元模型
Step1: 读取文本,按照标点符号提取句子S;
Step2: REPEAT
Step2: for (k= 1;k≤ L(Si)-N+1;k++) //L(Si)表示Si句子的长度
Step3: Begin
Step4:gk=CkCk+1...Ck+N-1;
Step5: count[gk]++;
Step6: End;
Step7: UNTIL全部句子处理完;
Step8: sort(count[g]); //按照gram出现次数降序排序
Step9: 输出全部的gi和次数统计;
Step10: END;
3 蒙古语文本语种识别模型
基于N-Gram的蒙古文文本语种识别过程如图3所示。整个过程分为三个阶段: 训练阶段、测试文本预处理阶段和识别阶段。
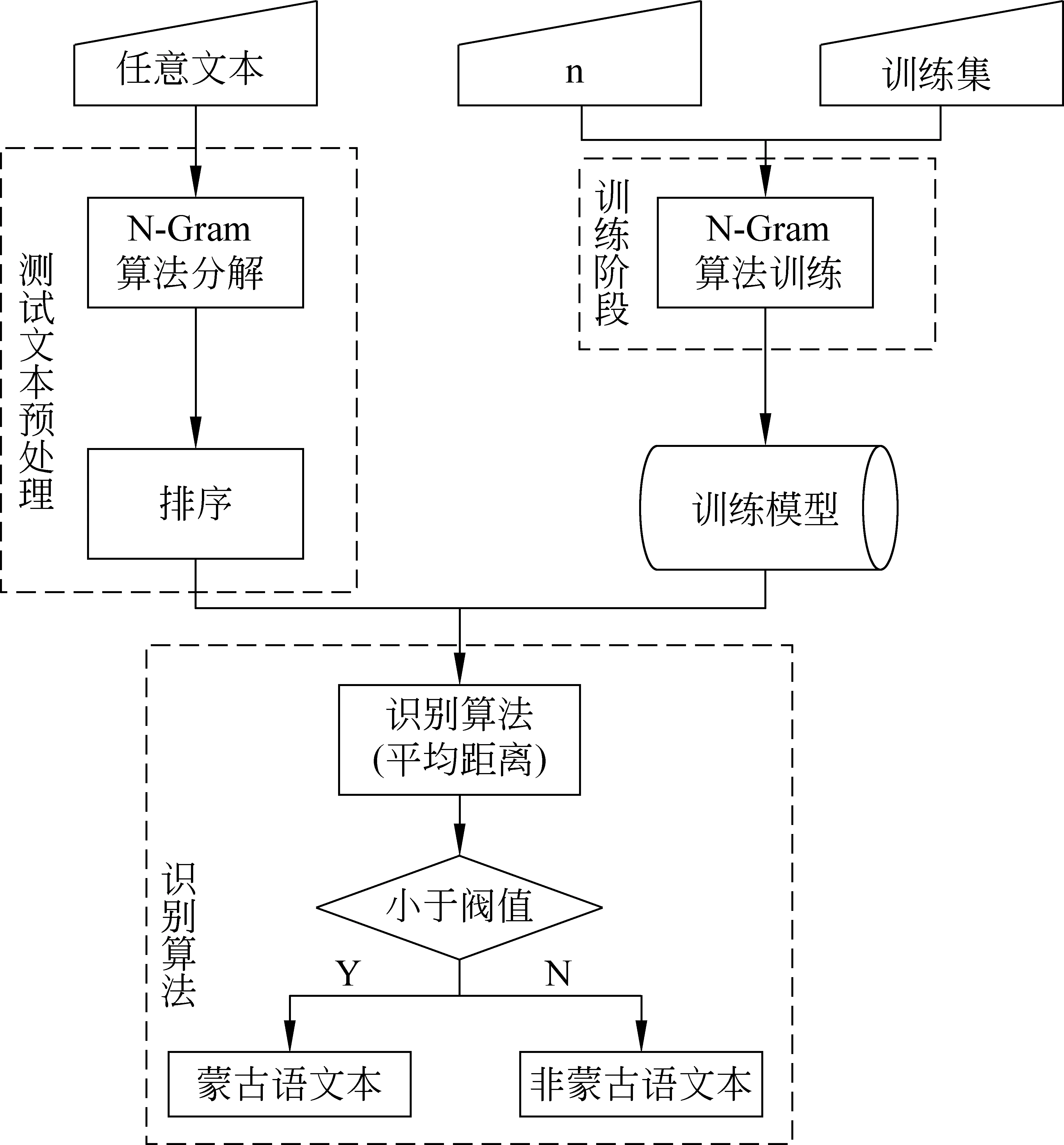
图3 基于N-Gram的蒙古语文本识别过程
在训练阶段中,输入N值与训练集,进行基于N-Gram算法的模型训练,最终得出训练模型;在测试文本预处理阶段,对于任意输入的未知语种文本内容,进行N-Gram算法进行切片,切片结束后并按照频率进行排序,得到预处理后的grams;在识别阶段中,输入预处理后的grams与训练模型,识别算法把计算结果与阀值进行比较,最终得出分类结果。
识别过程中包括三个关键问题,分别是: N-Gram算法中的N值选取、训练模型的降维处理以及平均距离识别算法中参数的确定。
3.1 N的选取
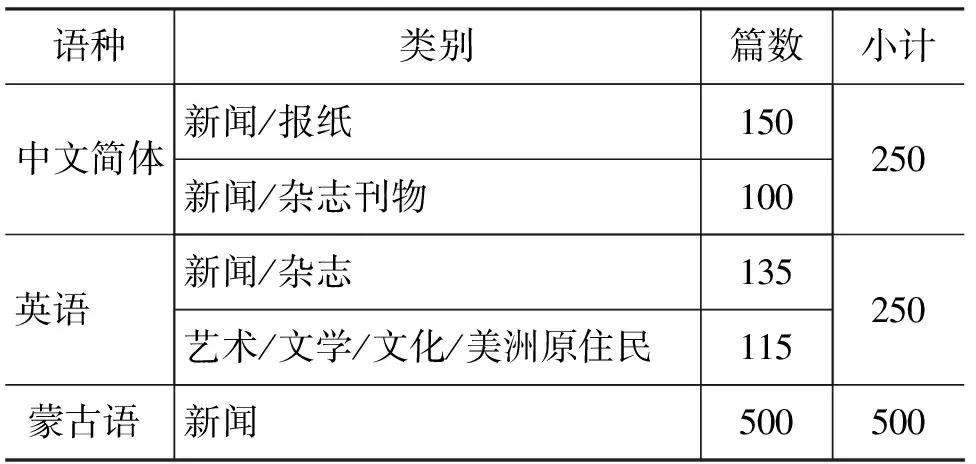
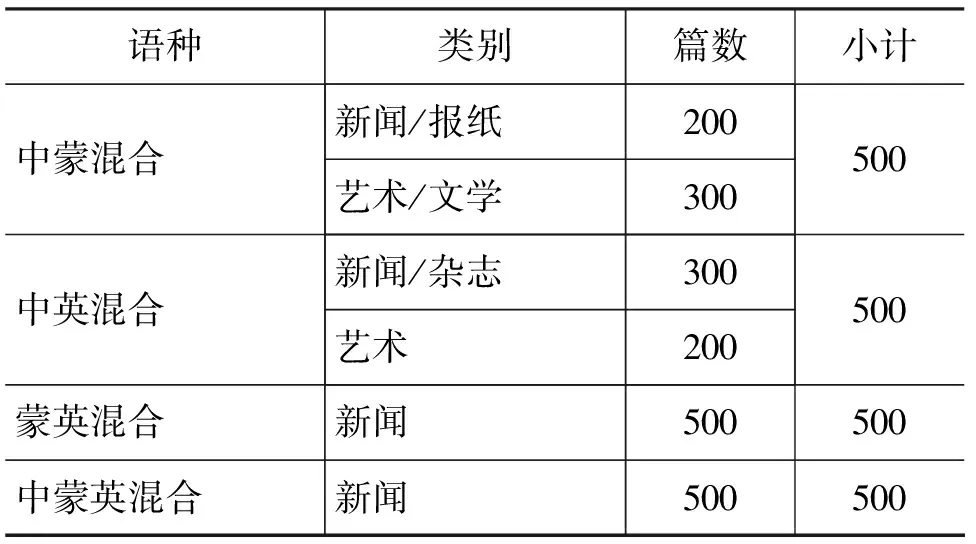
由于蒙古语文本的语料库无法从ODP等提供语料的人工目录上去获得,所以通过人为手工从互联网上抽取网页中的蒙古语文本,建立了大小为496KB的蒙古语文本语料库作为训练集[13]。并分别采用bigram,tri-gram进行训练,最后得出了bigram训练模型和tri-gram训练模型如图4所示。
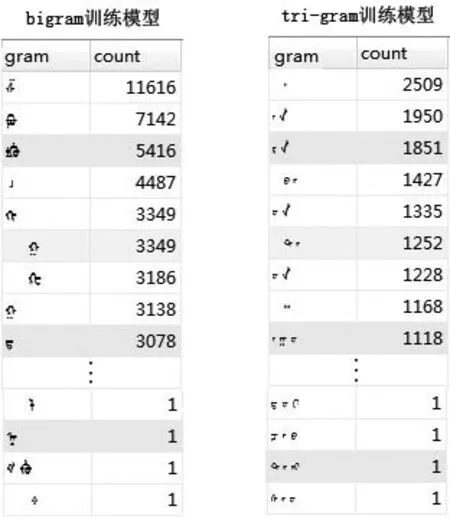
图4 bigram与tri-gram训练模型图
定义5 在训练模型中,min(x)代表前x个grams出现频率的最小值,gc(y)代表频率为y的gram总数。
从gram总数、min(x)、gc(y)以及训练时间四个方面对bigram与tri-gram训练模型进行比较,比较结果如表1所示。
通过表1中数据可以看出: 与bigram相比,基于tri-gram的训练模型数据聚集程度较低,呈现出一定的稀疏性[14-15],最终采用N=2的模型。
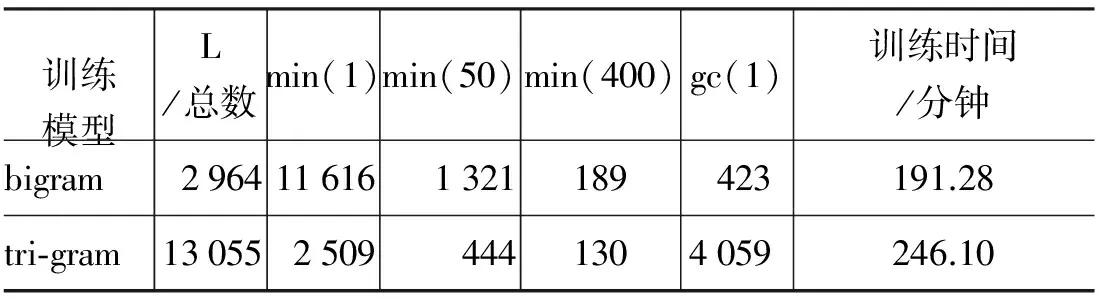
表1 bigram与tri-gram的训练模型比较实验
3.2 模型降低维度处理
训练模型预处理的目的是为了得到一个优质的具有典型代表的训练模型,得出的训练模型既要求具有代表性,又能考虑后期的识别性能[16]。
定义6 初始的训练模型表示为TMI,TMI的长度表示为LTMI。用count(gi)表示gi出现的次数;k表示TMI中的索引。在TMI中前k个gi出现的总次数nk表示为:
(3)
定义7 给定TMI,前t个grams出现次数与gram出现总次数的比值r表示为:
(4)
由式(4)可以得出: (1)f′(t)>0 (2)f″(t)<0 (3)渐近线为r=1。因此函数曲线随着t的增长f(t)严格单调递增且递增程度逐渐下降,且逐渐趋近于r=1。函数曲线如图5所示。
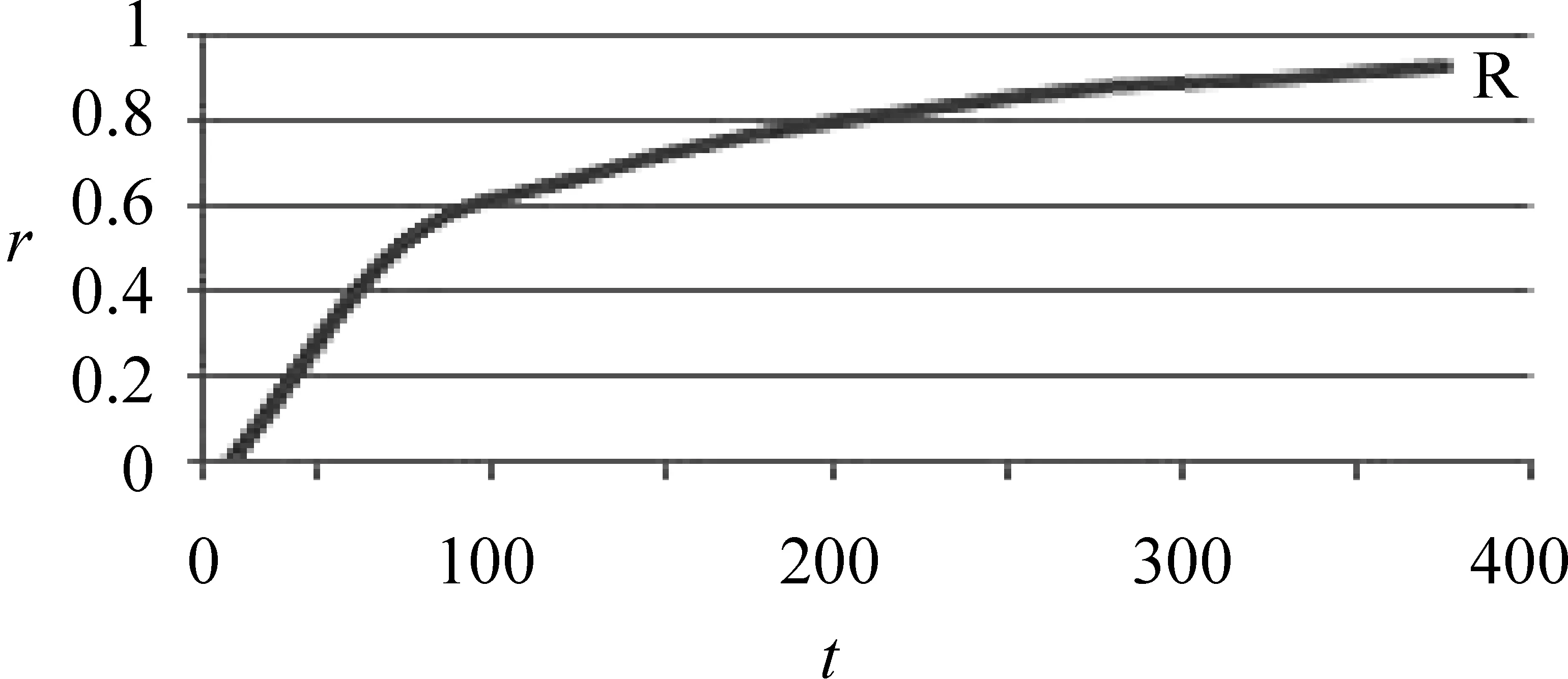
图5 r=f(t)的函数曲线
定义8 已知(t0,r0)为曲线上的一点,则在该点的斜率kt0表示为:
(5)
当kt0≥1时,前t0个grams具有明显的聚集特性,当kt0<1时,前t0个grams开始表现出稀疏特性[17]。
根据定义8,分别令t0等于200,300与400,计算kt0,结果如表2所示。
通过表2可以得出,当t0=300时,kt0=1,证明前300个grams具有一定的聚集特性。 从而取前300个grams作为训练模型TM。
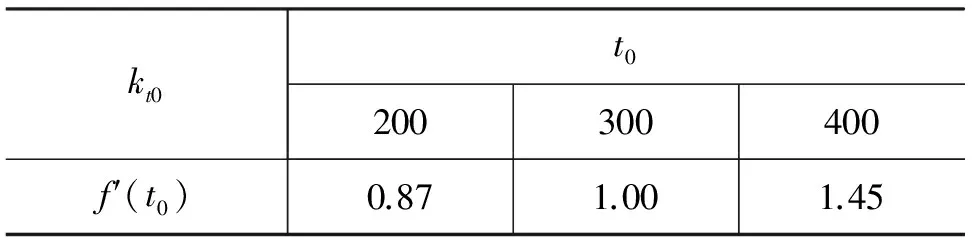
表2 kt0计算结果
3.3 平均距离识别算法中参数的确定
3.3.1MAX确定
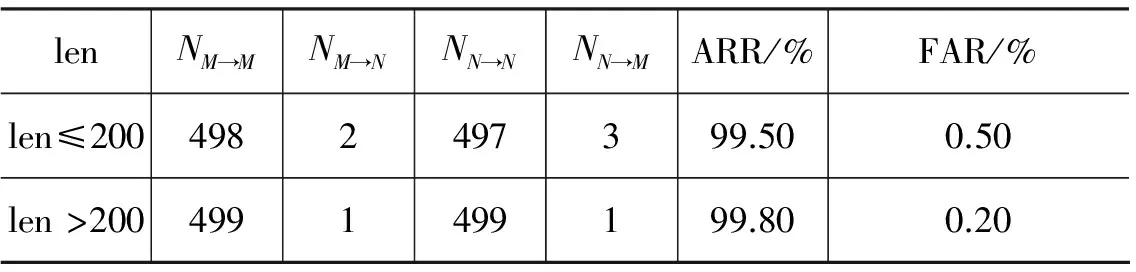
给定r=f(t)的函数曲线,设(t0,r0)为曲线上的某一点。把位于(t0,+∞)区间内的曲线等价于经过(t0,r0)点的一条直线r=kt+b,其中k代表斜率,b代表与Y轴的交点。已知在t=t0处斜率为kt0,根据r=f(t)函数的曲线特性,在(t0,+∞)区间里k的取值范围为:0 定义9 覆盖性训练模型。覆盖性训练模型TMA是一种理想状态,指包含了该目标语种文本的所有grams。包含的gram总数表示为LTMA。 根据定义9,设r=f(t)的函数曲线对X轴方向的最大值估计就是LTMA,则LTMA表示为: (6) 当k=kt0时,LTMA的值表示为l0。 显然,LTMA的取值区间为(l0,+∞)。这里取最小值l0+1作为MAX。即: (7) 3.3.2 阀值确定 定义10 在训练模型TM中,能找到系统的gram的概率为w0,不能找到的概率为w1。如果找到,则该项距离取最大值d0,如果没找到,则该项最大距离取d1。 根据定义10,并假设所有的目标语种文本grams均能在TMI中找到。则如果是蒙古文,它的T值计算公式如式(8)所示。 (8) 首先,d0与d1的计算公式如式(9)所示。 (9) (10) 即如果找到,则找到的最大距离为LTM-1,否则最大距离为MAX。 其次,w0与w1的计算见式(11)与式(12): (11) (12) 其中,f(i),f(j)代表第i个与第j个gram对应的频率值。 最终,把计算得到的d0、d1、w0与w1带入到式(8)中,计算阀值T。但该阀值只针对纯文本的模式,如果在混合模式下,应该适当地提高阀值。 4.1 数据来源 4.1.1 训练数据来源 根据文献[5-6],在文本语种识别方面,为了能够有效地抽取文本特征,需要选择一个合适大小的、能够把特征抽取出来的训练集合。因此,训练集合来自于蒙科立网站(http://mng.ulaaq.com/)的20个栏目下的500篇文章,大小为496kb。 4.1.2 测试数据来源 蒙古文的网页中经常混有中文和英文。因此,最终的测试语种类别有中文、英文和蒙古文。测试数据集包括单语种测试数据集与混合语种测试数据集[18]。测试数据来源于ODP(开源目录索引),如表3 和表4所示。 表3 单语种测试数据集的组成 表4 混合语种测试数据集的组成 4.2 实验结果分析 针对蒙古语文本语种识别问题,本文采用识别准确率(Accuracy Rate of Recognition,ARR)和误判率(False Positive Rate,FPR)作为重要评价指标。他们分别定义如下: (1) 识别准确率(ARR),定义为将测试集中蒙古文文本判别为蒙古文的概率与非蒙古文文本判别为非蒙古文的概率之和。计算公式如式(13)所示。 ARR= (13) (2) 误判率(FPR),定义为将测试集中蒙古文文本判别为非蒙古文的概率与非蒙古文文本判别为蒙古文的概率之和。计算公式如式(14)所示。 FPR= (14) 其中,NM→M表示将蒙古文文本判断为蒙古文的数目,NM→N表示将蒙古文文本判断为非蒙古文的数目,NN→N表示将非蒙古文文本判断为非蒙古文的数目,NN→M表示将非蒙古文文本判断为蒙古文的数目。 可见,ARR的值越高,FPR的值越低,则识别能力越强。 为了能够更好地识别蒙古语文本,分别对单语种和混合语种文本进行测试,并针对混合语种文本进行阀值的确定。 (1) 分别对单语种文本中的长、短文本进行测试,长短文本以200个字符长度为界限,测试文本长度用len表示。测试结果如表5所示。 表5 单语种文本测试结果 通过表5可以看出: ARR的值都相对较高,FPR的值都相对较低,即蒙古文能够从中、英、蒙的单语种文本模式中以一个高的准确率被识别。 (2) 对混合语种文本的阀值确定进行实验。对混合语种文本中的蒙中、蒙英、中英和蒙中英分别进行测试,蒙古文与其他语种文本的混合比例为1∶1。混合文本的平均长度为300个字符。在测试集相同的情况下,用不同的阀值对其进行测试,以确定阀值。测试结果如表6所示。 表6 混合语种文本测试结果 通过表6可以看出: 只有当T=385时,ARR的值最高,FPR的值最低,即此时识别能力最强。因此,在混合文本下,阀值T设定为385。 结束语 本文通过对文本语种识别的深入分析与研究,并结合蒙古文的实际书写特点,对蒙古语文本语种识别展开了研究。首先,利用N-Gram模型进行模型训练与测试文本预处理;然后,在识别阶段,采用平均距离算法作为目标语种识别算法,并搭建了一个目标语种文本识别实验平台;最终,对单语种文本和混合语种文本进行测试并对混合文本下的平均距离识别算法的阀值确定进行实验研究,结果得到了一个较高的识别准确率和一个较低的误判率。但本文在混合语种文本测试中,测试集合中的蒙古文与其他语种文本的混合比例仅是≤1∶1,对混合比例>1∶1的混合文本语种识别还有待进一步研究。 [1] 金良,散旦玛,玉英.传统蒙古文编码及其应用现状分析[J].语文学刊,2012,4:16-18. [2] 清格尔泰.现代蒙古语语法[M].呼和浩特: 内蒙古人民出版社,1999. [3] Denis Shestakov. Current Challenges in Web Crawling[C]//Proceedings of the 13th International Conference. ICWE 2013:518-521 . [4] 倪耀群,曹鹏,许洪波等.网络维吾尔文判别及其文本长度下界的探讨[J].中文信息学报, 2012, 26(6):109-115. [5] 冯冲, 黄河燕, 陈肇雄等. 基于字符层马尔科夫模型的多语种识别[J].计算机科学,2006, 33(1): 226-228. [6] Cavnar, William B, John M. Trenkle. N-Gram-based text categorization[J]. Ann Arbor MI 48113.2 (1994): 161-175. [7] 付强,宋彦,戴礼荣. 因子分析在基于GMM的自动语种识别中的应用[J]. 中文信息学报,2009,23(4):77-81. [8] 刘伟伟,吉立新,李邵梅,何赞园. 基于区分加权干扰属性投影的语种识别方法[J]. 中文信息学报,2012,26(6):59-64. [9] 朱云霞. 结合聚类思想神经网络文本分类技术研究[J].计算机应用研究, 2012,29(1): 155-157. [10] 刘巍巍,张卫强,刘加. 基于鉴别性向量空间模型的语种识别[J].清华大学学报, 2013, 53(6): 796-799. [11] 李惠,刘颖. 基于语言模型和特征分类的抄袭判定[J].计算机工程, 2013, 39(5):230-234. [12] 张泽华, 苗夺谦, 钱进. 邻域粗糙化的启发式重叠社区扩张方法[J]. 计算机学报, 2013, 36(10): 2078-2086. [13] Grefenstette G. Comparing Two Language Identification Schemes[C]//Proceedings of the 3th International Conference on Statistical Analysis of Textual Data, Rome, Italy. 1995. [14] Pingali P, Varma V. Multi-lingual Indexing Support for CLIR using Language Modeling[J]. IEEE Data Eng. Bull., 2007, 30(1): 70-85. [15] Nguyen D T, Nguyen C T. Cross-Lingual Information Retrieval Model for Vietnamese-English Web Sites[C]//Proceedings of the Computer Modeling and Simulation, 2010. ICCMS’10. Second International Conference on. IEEE, 2010, 4: 254-257. [16] Malisiewicz T, Gupta A, Efros A A. Ensemble of exemplar-svms for object detection and beyond[C]//Proceedings of the Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011: 89-96. [17] Chelba C. Exploiting syntactic structure for natural language modeling[J]. Johns Hopkins Universit, 2000: 225-231. [18] Lipka, Nedim, and Benno Stein. Identifying featured articles in Wikipedia: writing style matters. Proceedings of the 19th international conference on World wide web[C]//Proceedings of the ACM, 2010: 1147-1148. N-Gram Based Language Identification for Mongolian Text MA Zhiqiang, ZHANG Zeguang, YAN Rui, LIU Limin, FENG Yongxiang, SU Yila (School of Information Engineering, Inner Mongolia University of Technology, Hohhot, Inner Mongolia 010080, China) With the rapid increasing of Mongolian texts on the Internet, it is of practical significance to identify them before further processing. This paper proposes an average distance recognition algorithm based on N-Gram model, and an experimental platform is established. Experimental results show that the presented algorithm can identify Mongolian text from Chinese, English, or even mixed-language texts, with an accuracy of above 99.5%. language identification; N-Gram model; average distance recognition algorithm; Mongolian text 马志强(1972-),硕士,副教授,主要研究领域为蒙古文信息检索、语音识别。E⁃mail:mzq_bim@163.com张泽广(1988-),硕士研究生,主要研究领域为蒙古文搜索引擎。E⁃mail:zhangzeguang88@sina.com闫瑞(1988-),硕士研究生,主要研究领域为蒙古语语音识别。E⁃mail:yanrui309@163.com 1003-0077(2016)01-0133-07 2014-09-01 定稿日期: 2014-10-20 国家自然科学基金(61363052);内蒙古自治区自然科学基金(2014MS0608);内蒙古自治区高等学校科学研究项目(NJZY12052);内蒙古工业大学重点基金(ZD201118) TP391 A4 实验设置与结果分析