基于时空局部性的层次化查询结果缓存机制
2016-05-03朱亚东郭嘉丰兰艳艳程学旗
朱亚东,郭嘉丰,兰艳艳,程学旗
(1. 中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190; 2. 中国科学院大学,北京 100049)
基于时空局部性的层次化查询结果缓存机制
朱亚东1, 2,郭嘉丰1,兰艳艳1,程学旗1
(1. 中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190; 2. 中国科学院大学,北京 100049)
查询结果缓存可以对查询结果的文档标识符集合或者实际的返回页面进行缓存,以提高用户查询的响应速度,相应的缓存形式可以分别称之为标识符缓存或页面缓存。对于固定大小的内存,标识符缓存可以获得更高的命中率,而页面缓存可以达到更高的响应速度。该文根据用户查询访问的时间局部性和空间局部性,提出了一种新颖的基于时空局部性的层次化结果缓存机制。首先,该机制将固定大小的结果缓存划分为两层:页面缓存和标识符缓存。对于用户提交的查询,该机制会首先使用第一层的页面缓存进行应答,如果未能命中,则继续尝试使用第二层的标识符缓存。实验显示这种层次化的缓存机制较传统的仅依赖于单一缓存形式的机制,在平均查询响应时间上,取得了可观的性能提升:例如,相对单纯的页面缓存,平均达到9%,最好情况下达到11%。其次,该机制在标识符缓存的基础上,设计了一种启发式的预取策略,对用户查询检索的空间局部性进行挖掘。实验显示,这种预取策略的融合,能进一步促进检索系统性能的有效提升,从而最终建立起一套时空完备的、有效的结果缓存机制。
页面缓存;标识符缓存;启发式预取
1 引言
为了应对繁重和高度动态变化的用户查询流量,各种优化技术已被现代搜索引擎采用。缓存技术是其中一种重要的优化手段,在搜索引擎系统的多个层面上进行了部署和利用,以降低系统负载。在系统的底层,有针对索引结构的倒排链缓存,用以减少与磁盘的I/O通信[1-3];在搜索引擎的上层,有针对重复查询的结果缓存,以避免查询的重复执行,从而提高查询处理的能力[2-9];此外,还可能有其他中间层次的缓存,如针对多个term倒排链交集的缓存[10],定位缓存和top-k缓存等[11]。
本文主要针对查询结果的缓存展开研究。文献[7]第一个公开提出,将结果缓存作为降低查询响应时间的一种手段。文章中,作者研究了查询日志的分布,并比较了几种时下的缓存策略。作者表明,静态缓存的性能普遍较差,而基于LRU或LFU的动态缓存可以获得较好的性能。文献[8]学习了查询日志局部性的几种形式,提出除了在服务器端进行结果的缓存外,还可以在用户端对查询的结果进行缓存。Lempel和Moran的工作中[6],提出了一种新的结果缓存策略,称之为PDC(概率驱动缓存)策略。它是一种改进的预取缓存机制,用于处理其他结果页(第一页之后的结果页)的查询请求。Fagni等人提出了一种混合结果缓存策略,称之为SDC[1](静态-动态缓存)。该策略维持了一个静态缓存和动态缓存。静态缓存存入了在过去较长时期内频繁出现的一些查询,动态缓存则通过一定的缓存策略如LRU等进行管理,存入的是近期频繁访问的查询结果。Baeza-Yates等人也提出了一种与SDC较为类似的混合策略,其采用了双动态缓存的结构[9]。Gan和Suel研究了基于权重的结果缓存,将查询的处理代价也作为缓存管理策略考虑的要素之一。此外,作者还提出了一种新的基于特征的缓存策略,文中的实验结果显示该策略取得了较大的性能提升[5]。
比较有意思的是,最近Altingovde等人讨论了一种混合结果缓存的使用[13],与本文的思想较为类似,但在很多方面又有着巨大的差异。首先,二者依赖的模型架构基础完全不一样,本文是建立在一种典型的商业分布式架构基础上(具体见第二章节的分析),并认为这种三层的层次性架构(memory-doc server-disk)是层次性缓存机制有效性的理论基础;其次,作者没有从理论上对自己文中的思想进行分析论证,只是简单的实验评估。而本文则从理论建模的角度,对本文提出的层次化缓存机制进行了充分有效的分析;最后,本文还在此基础上提出了一种基于标识符缓存的启发式预取策略,用以挖掘用户查询的空间局部性。这种预取策略的融合,很好地挖掘和拓展了层次化缓存机制的效用,从而进一步促进整个系统性能的有效提升,最终建立起一套对时间局部性和空间局部性都能有效捕捉的,完备的查询结果缓存机制。
结果缓存主要有两种形式:页面缓存和标识符缓存。给定一个固定大小的内存,标识符缓存可以存储大量的缓存条目,这一数目远大于页面缓存[1]。标识符缓存中的缓存条目是一个有序的 (根据相关度排序) 整数标识符集合,通常只有几十字节大小 (在每页10个结果的标准形式下,如10*8Byte),而页面缓存条目是可以直接返回给用户的HTML页面,一般为几KB大小 (如10*512Byte)。在页面缓存上的命中可以立即返回查询结果,而在标识符缓存上命中后,仍需要读取文档服务器以生成相应的HTML页面。所以,对于给定的内存资源,页面缓存机制可以达到较高的响应速度,而标识符缓存可以获取较高的命中率。以往的大多数工作都集中于页面缓存的应用或某一种单独形式的应用。
本文基于用户查询访问的时间局部性和空间局部性,提出了一种新颖的层次化缓存机制,这种缓存机制对页面缓存的高响应速度和标识符缓存的高命中率,进行了总体的均衡。对于有限的内存资源,我们对每一层应占用的内存大小进行了充分的讨论,以获得最优化的性能提升。然后,我们在不同缓存大小的情形下,对本文提出的结果缓存机制进行了讨论和评估。相对于单独的页面缓存和标识符缓存,我们的层次化缓存机制带来了更好的性能提升。同时本文还提出了一种基于标识符缓存的启发式预取机制,挖掘用户查询的空间局部性。实验显示这种预取机制的融合,能进一步地发掘层次化缓存机制的效用,带来更大的性能提升。
文章的其余部分组织如下:第二节描述了几种基本的缓存机制以及本文提出的层次化的结果缓存机制,并对每一种策略下的平均查询响应时间进行数学建模,然后比较分析;第三节根据用户查询的空间局部性,结合标识符缓存的优势,提出了一种启发式预取的策略;第四节对文章提出的缓存机制和预取策略进行了实验评估;第五节对文章进行了总结并简单阐述了将来的工作。
2 层次化的结果缓存机制
我们将详细论述本文提出的层次化的结果缓存机制。首先我们介绍了两种传统的结果缓存机制,然后对每一种策略下的查询的平均响应时间进行了分析和对比评估。
2.1 系统概述
一个典型的大规模网络搜索引擎系统如图1所示,它是由一定数目的检索节点组成的分布式架构。在这些检索节点之上,有一个额外的代理节点。它负责将接受到的用户查询转发到相应的检索节点,同时收集返回的检索结果。然后代理节点根据他们的相关度得分,对这些结果进行合并排序,从而产生一个有序的文档标识符集合。最后根据这些文档标识符,从文档服务器中获取URL和相关的文档摘要信息等,然后生成相应的HTML页面返回给用户[1]。检索结果的缓存通常部署在代理节点上面。
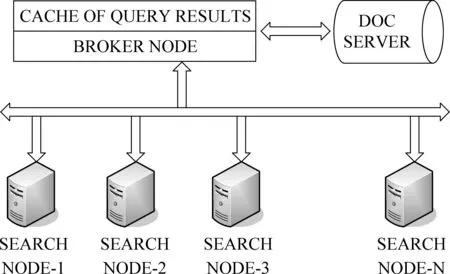
图1 带有结果缓存的大规模分布式网络搜索引擎构架
根据上面的处理流程,在没有结果缓存的情况下,查询的平均处理时间t1可表述为式(1)。
(1)
其中trank指查询的排序处理时间,这一过程包括索引倒排链的读取,计算排序等,最终提供了一个有序的文档标识符集合;tsummay表示根据这些文档标识符从文档服务器中读取相关摘要内容花费的时间;tgenerate表示根据摘要内容生成HTML页面耗费的时间。事实上,相对于trank和tsummay,将摘要内容生成HTML页面耗费的时间非常少,tgenerate可忽略不计。所以此时t1可表示为式(2)。
(2)
2.2 页面缓存机制
以往的工作大多集中在页面缓存的应用上,这里我们也采用该机制作为我们的评估基准(baseline)。这种机制下,查询的基本处理流程如图2(a)所示。t2表示在页面缓存机制下,查询的平均处理时间,如式(3)所示。
(3)
这里,a表示页面缓存的命中率;tinsert1表示插入一个条目到页面缓存耗费的时间;tread1表示从页面缓存读取一个缓存条目耗费的时间;trank和tsummay含义与公式(1)中的相同。
2.3 标识符缓存机制
结果缓存还可以采用标识符缓存的形式,这种机制下, 基本的查询处理流程如图2(b)所示。t3表示在标识符缓存机制下,查询的平均处理时间,并表示为式(4)。
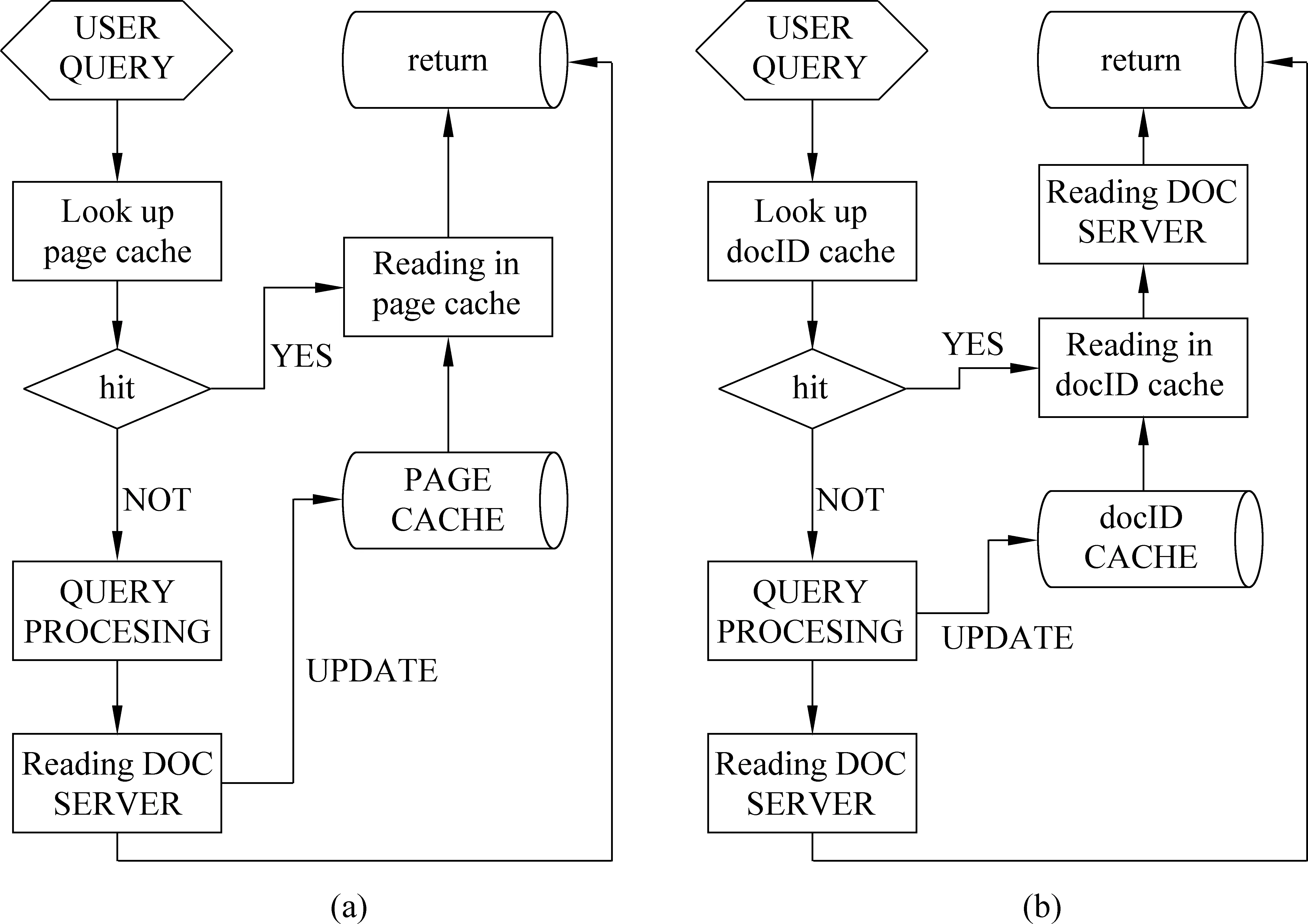
图2 传统的结果缓存机制: (a)页面缓存处理机制, (b)标识符缓存处理机制
(4)
其中,b表示标识符缓存的命中率;tinsert2表示插入一个条目到标识符缓存耗费的时间;tread2表示从标识符缓存中读取一个条目耗费的时间;trank和tsummay含义与公式(1)中的相同。
2.4 层次化的结果缓存机制
这种机制同时融合了页面缓存和标识符缓存,并以一个合适的比例对二者在结果缓存中的大小进行了划分。这种机制下,查询的处理流程如图3所示。t4表示在该机制下查询的平均响应时间,并表示为式(5)。
(5)

图3 层次化的结果缓存处理机制
其中,a表示页面缓存的命中率;b表示标识符缓存的命中率;其他参数的含义与公式(2)~(4)中相同。
2.5 时间代价分析
显然,t1,t2,t3和t4分别表示在没有结果缓存、页面结果缓存、标识符结果缓存、层次化结果缓存四种情况下的平均响应时间。对于一个特定的网络搜索引擎系统,一些参数的值如:trank,tsummay,tinsert1,tread1,tinsert2和tread2都可以直接测试出来,是一个较为稳定的常数值。在本文后续实验章节中,我们提供了这些参数的估值(参见表2)。这里我们以本文的实验环境为例,将这些参数的估值代入公式(3)~(5)得到公式(6)~(8)。
(6)
(7)
(8)
页面缓存VS标识符缓存:我们首先对t2和t3进行对比分析,如式(9)~(10)所示。
t2-t3=30.91(1-a)-(30.91-30.5b)
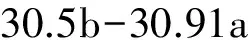
(9)
(10)
在本文的实验环境中,每一个页面缓存条目的大小是5KB(10*512Byte)左右,每一个标识符缓存条目大小是80B(10*8Byte)。对于固定大小的内存,标识符缓存提供的缓存条目数是页面缓存的64倍。所以在相同的缓存管理策略下,标识符缓存的命中率始终大于等于页面缓存的命中率,即a≤b总是成立的。
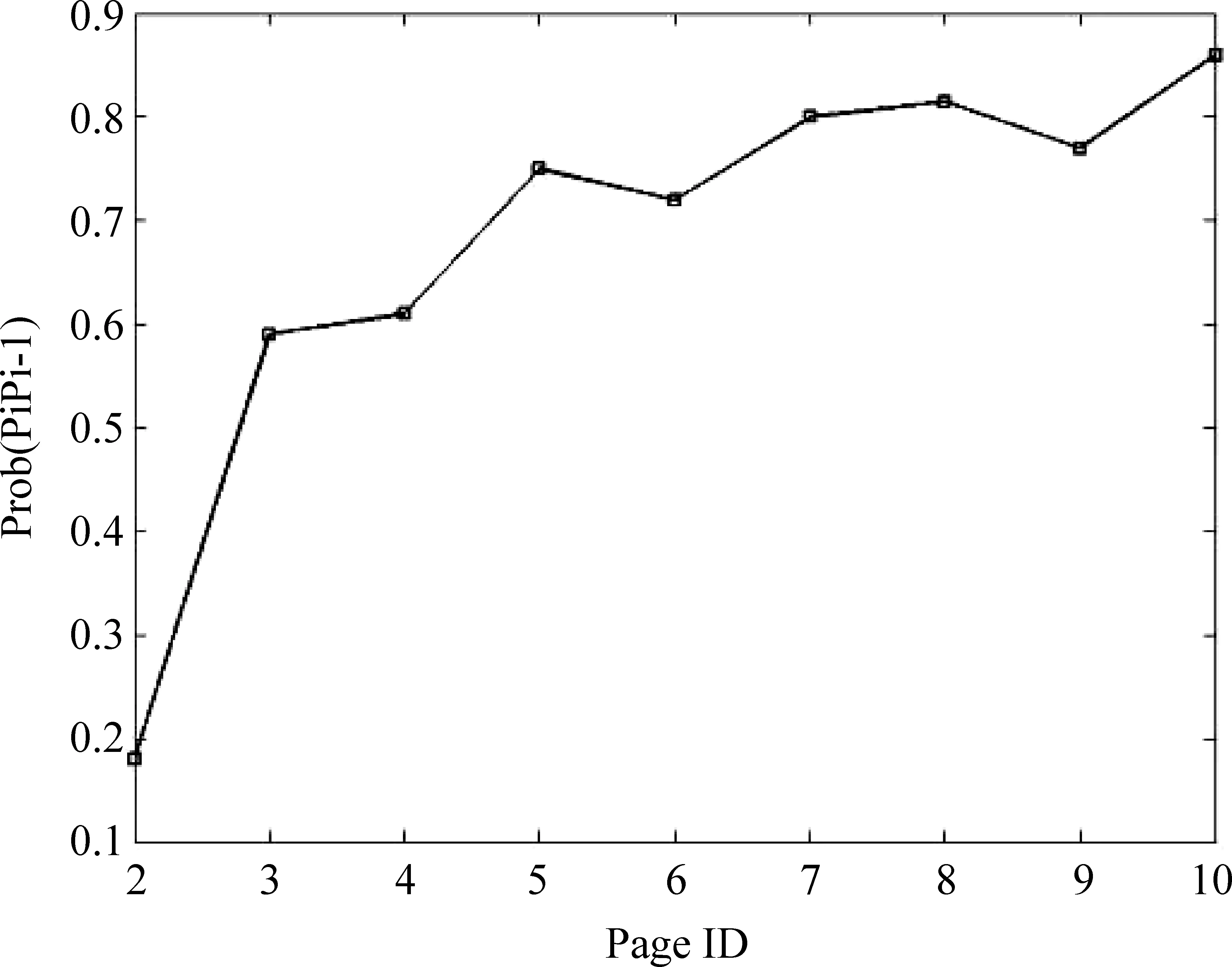
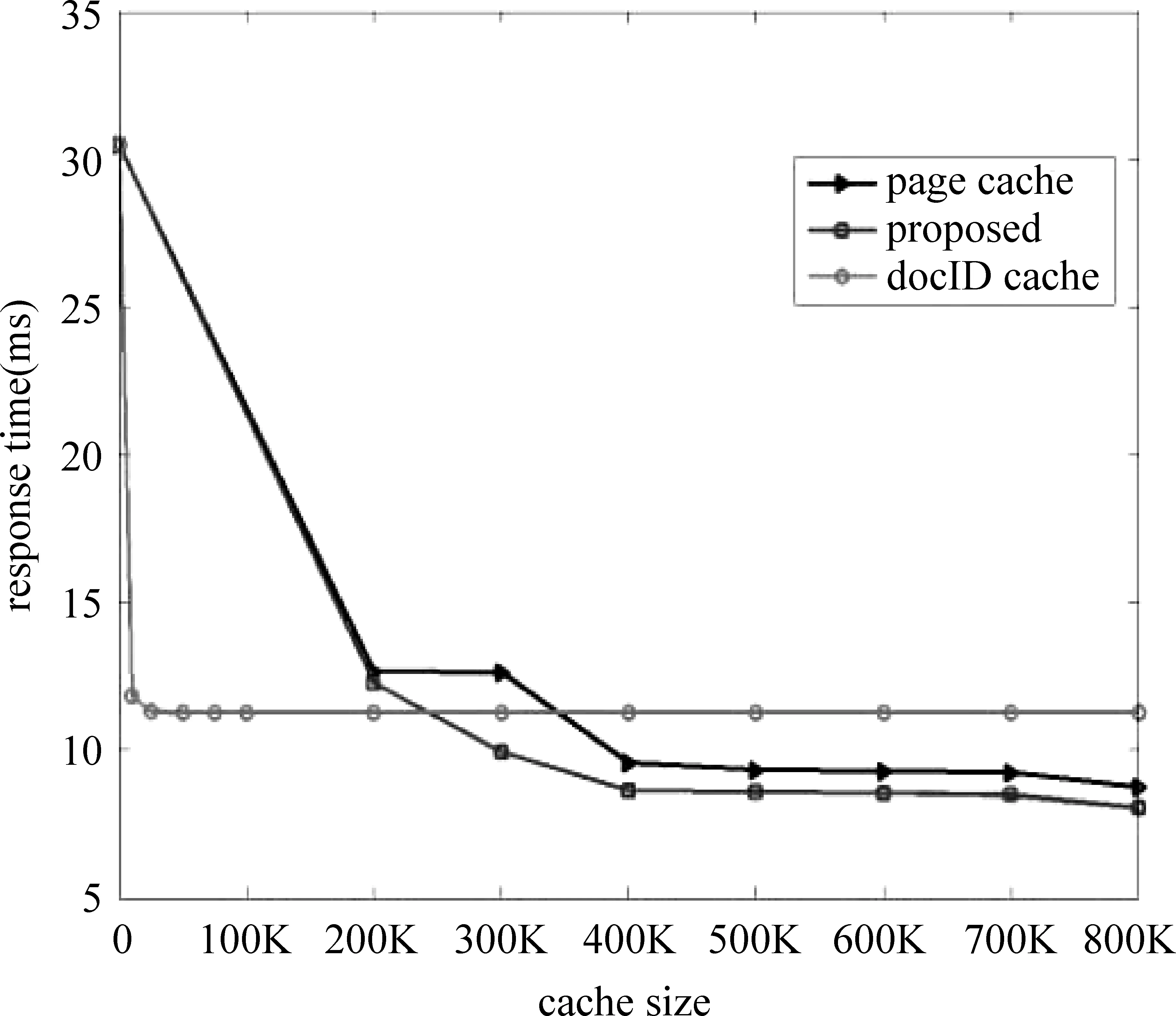
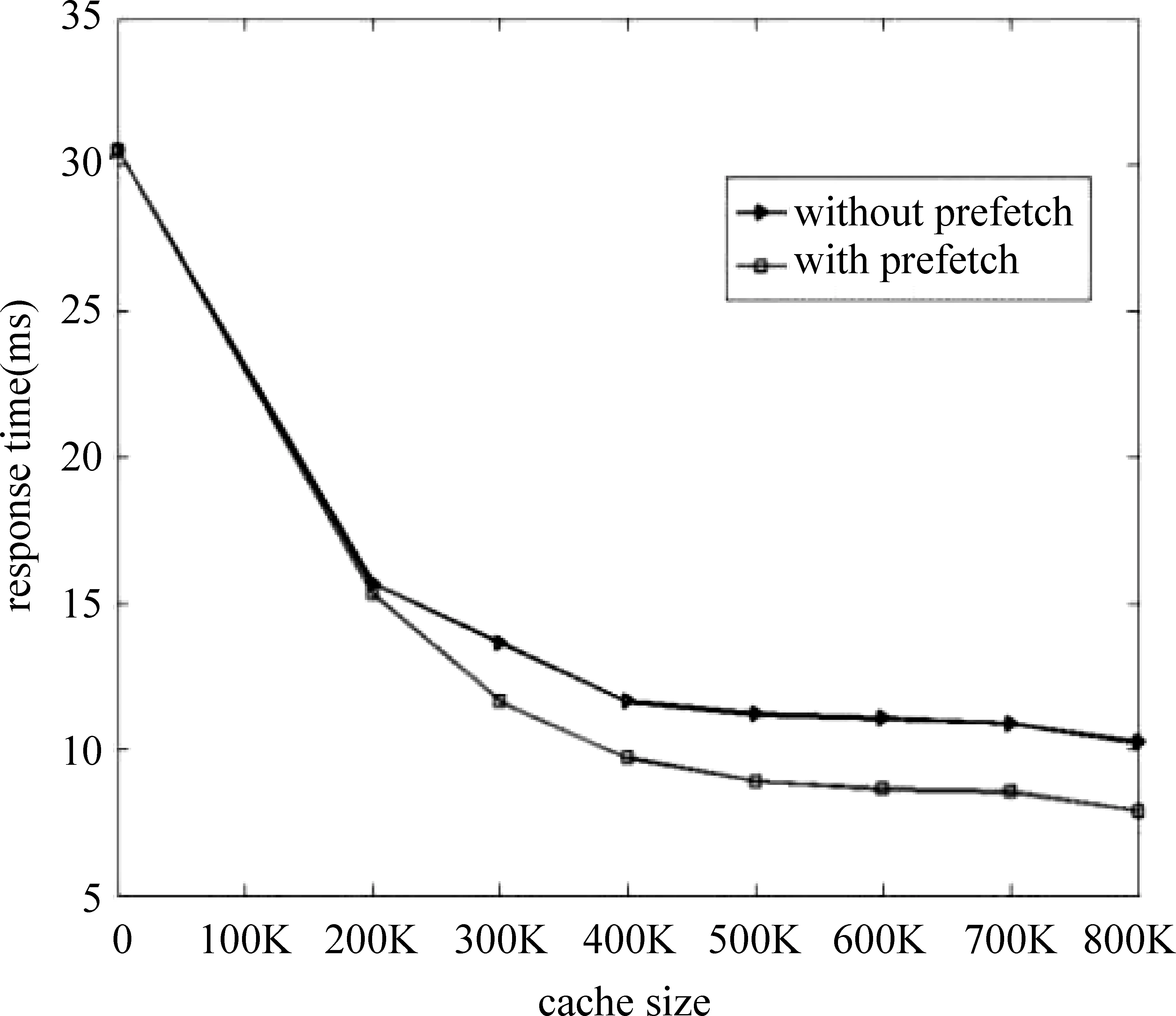
当a>0.9867b时,也即b≥a>0.9867b,有t2 页面缓存VS层次化缓存: 对于t2和t4,直接的理论上的比较是困难的。因为两个表达式中的参数a的值并不相同。由于页面缓存单个条目的大小是标识符缓存条目的64倍,因此,如果我们拿出页面缓存中的很小一部分用于标识符缓存,一方面对页面缓存的命中率几乎没有影响,另一方面由标识符缓存带来的性能增益却是非常可观的。例如,对于有300K个缓存条目的页面缓存,如果我们拿出5K个条目用于标识符缓存,带来的页面缓存命中率上的变化可忽略不计,即参数a没有变化 (实验显示,在相同缓存策略如LRU的情况下,页面缓存在300K个缓存条目和295K个缓存条目下的命中率几乎不变),而对应的标识符缓存却能额外的提供320K(5K*64)个缓存条目,显然,这极大提高了结果缓存的命中率。在这种情况下,层次化缓存机制较页面缓存带来的性能提升,可表示为式(11)。 (11) 例如,b=10%,那么相应的性能提升可达9.86%。 事实上,我们可以从局部性原理的角度对层次化缓存机制进行评估。如图4中所示,这种层次化缓存机制类似于计算机系统中的存储层次模型。最上面的一层拥有最快的速度和最高的成本,最下面的一层拥有最慢的速度和最低的价格。相对于页面缓存机制,层次化缓存机制增加了一个中间层次,这个层次拥有相对高的速度(文档服务器的读速率tsummary),但相对低廉的价格。这样,每一层都作为下面一层的高速缓存,充分利用了局部性原理,很好地融合了速度与成本的目标。 图4 层次化结果缓存与存储层次架构对比 最优划分:对于层次化结果缓存机制,在结果缓存中,对页面缓存和标识符缓存各自层次大小的划分,存在一个均衡。找到一个最优划分使性能最大化是非常重要的。由上面t4的表达式可以发现,t4的大小取决于a和b(页面缓存和标识符缓存的命中率),而a和b除了跟每部分的缓存大小相关外,还跟缓存策略以及实际中具体的用户查询行为有关。所以,我们不能从理论上直接指出使t4最小化的精确划分。然而,基于上面章节的分析,我们可以获得一些有意义的建议: • 对于一个有限的相对较小的结果缓存,我们倾向于将绝大部分的结果缓存空间划分给标识符缓存; • 对于一个相对较大的结果缓存,我们倾向于拿出一个较小比例的缓存空间用作标识符缓存,而将大部分的检索结果缓存到页面缓存中; 图5 用户请求下一页的概率 事实上,用户的查询行为除了具有时间局部性,还具有空间局部性。本章节在层次化缓存机制的基础上,进一步挖掘用户查询的空间局部性,提出了一种基于标识符缓存的启发式预取策略。 我们以部分AOL检索服务的查询日志为例(2006年3月1日到31日),对查询日志中用户翻页的可能性进行统计,结果如图5所示。它表示的含义为,当给定同一个话题的第(i-1)个页面的请求后,用户点击第i个页面的概率。由图中可知,当用户点击了第一页后,其点击第二页的概率只有0.2左右,而当用户请求了第二个页面后,其则有很大的可能性(概率大于0.5)继续请求第三个页面,其他以此类推。事实上,通常绝大数的用户查询请求都不会超过前三个页面[15]。根据这一系列查询日志的统计特征,同时结合标识符缓存自身的优势:即能用较小的缓存空间提供大量的缓存条目,我们提出了一种基于标识符缓存的启发式预取策略,如表1表示。其中query (keywords, m, n)是一个向后端检索平台提交的用户查询形式,查询内容为keywords,m为用户请求的结果页面号,n表示需要在标识符缓存中缓存的,从m开始的连续n个结果页面。 表1 一种基于标识符缓存的启发式预取策略 整个预取策略是非常简单的:当第一个结果页面被请求并且不在任一层次的结果缓存中(首先在页面缓存中查找,其次是标识符缓存),我们会对查询进行扩展,然后向后端的检索平台请求第一和第二两个结果页面,并插入到标识符缓存中;当第二个结果页面被请求,它通常会立即返回给用户,然后向后端检索平台继续请求后续的三个页面,并插入到标识符缓存中。通过这种方式,我们仅对那些具有很大访问可能性的有限结果页面进行预取。这样我们在限制由预取带来的额外后端负载的同时,最大化了系统的响应速度。 总体上,我们对那些有较大访问可能性的、有限的结果页面进行了预取,同时利用了标识符缓存的空间优势,有效地压缩了由预取带来的额外空间开销,相对于传统的依赖于页面缓存的方法,显然具有更大的优势。这样在层次化缓存机制的基础上,融合启发式的预取策略,建立了一套完备有效的结果缓存机制,很好地促进了Web检索性能的提升。 4.1 数据和实验设置 实验中,我们采用了AOL检索服务2006年3月1日到31日之间的查询日志。并从中随机选取了一部分的查询子集,包含了7 172 919条查询。我们采用了文献[5,11]应用的规则,对查询日志进行预处理,这其中包括去除停用词,移除只包含停用词的查询。在4.2节实验中,我们对那些对后续结果页面访问的查询请求(ItemRank>10)也予以移除 。处理后的日志集合包含6 587 522条查询,这里面包含2 326 676条不同的查询,其中1 417 612条查询仅仅出现过一次,399 657条查询出现过两次。统计显示这些查询的频率服从Zipf分布[12,14-16]。实验中,这些查询日志按时间顺序执行,前60%(3 952 513)用于缓存系统的预热,剩下的40%(2 635 009)用于测量性能参数。我们在一个单独的机器上,采用一个优化版本的Lucene进行索引的建立和查询的处理。该机器采用8 Intel(R) Xeon(R) CPU E5410@2.33GHz以及16GB的RAM。真实的应用场景中,一般会存在一个检索节点集群,例如,Katta* http://katta.sourceforge.net/部署的分布式检索框架。这里我们采用的是单个检索节点的实验场景,一方面是出于简单高效的考虑;另一方面是因为,本文关注的是前端代理节点上的查询结果缓存的策略机制,对于后端检索节点,可以看成一个黑盒,而不关心具体的部署细节。另外,我们采用相同的两台机器搭建一个文档服务器,在上面部署一套voldemort* http://project-voldemort.com/,其中配置的bdb缓存是4GB。我们索引了近700万文档,其中包含大约150万的Wikipedia网页。 表2展示了在第二节中提到的相关参数的估值。由于页面缓存和标识符缓存都在一个内存中,所以tinsert1和tread1,与tinsert2和tread2有相同的值,我们统一用tinsert和tread代替。这些参数的估值可以作为参考,代入到第二节中的时间代价公式中,以简化相关的理论分析。 表2 实验中的参数估值/毫秒 4.2 层次化缓存机制评估 图6展示了在三种缓存机制下的平均响应时间,其中横轴表示页面缓存条目数(每一个页面缓存条目粒度大小是5KB),纵轴表示查询的响应时间(response time),单位毫秒(ms)。对于层次化的结果缓存机制,我们采用了固定的50K页面缓存条目用于标识符缓存。结果显示,较传统的页面缓存机制,层次化的缓存机制获得了平均9%的性能提升。最好的地方甚至超过11%,如在300K条目数的情形。在我们的实验中,每一个页面缓存条目的大小是5KB(10*512B),每一个标识符缓存条目的大小是80B(10*8B),一个页面缓存条目能提供64倍的标识符缓存条目。因此,对于标识符缓存机制,即便仅占据20K页面缓存条目数,其依然能提供高达1280K(20K*64)个标识符缓存条目。显然,当标识符缓存的大小超过30K页面缓存条目,所有测试集中的查询都将被缓存,因此,之后的标识符缓存曲线呈水平不变的趋势。另外,我们发现当缓存大小小于400K条目时,相对于页面缓存,标识符缓存具有更好的性能。随着缓存大小的增加,由标识符缓存带来的性能增益逐渐减少,页面缓存和层次化缓存之间的间隔也逐渐减小。 图6 平均响应时间对比 图7 200K缓存条目数下的最优划分 图8 800K缓存条目数下的最优划分 图9 是否融合预取机制下的性能对比 图7、图8对页面缓存和标识符缓存的最优划分进行了研究分析。我们分别采用了200K和800K两种大小的缓存资源,用以模拟有限的小缓存资源和较大的缓存资源两种情形。其中x轴表示用于标识符缓存的空间比例大小,y轴是响应时间,单位毫秒(ms)。在图9中,当全部的缓存大小用于标识符缓存时,获得了最低的响应时间。这种情形下(即一个有限的较小的缓存空间),相对于页面缓存,标识符缓存具有更好的查询性能,所以我们倾向于保留绝大多数的缓存空间用于标识符缓存,这也与2.5节中的分析一致。在图7中, 当10%的缓存空间用于标识符缓存时,获得了最佳的性能。事实上,随着可用的缓存空间的增大,由标识符缓存带来的性能增益逐步减小。进一步说,只有当标识符缓存占据较小的空间比例的时候,才能一方面将大部分的查询结果缓存在页面缓存中,很好地发挥页面缓存的性能优势;另一方面也可以很好地利用标识符缓存的优势,即用较小的缓存空间提供大量的缓存条目,对二者的优势进行有效的均衡。 4.3 基于标识符缓存的启发式预取策略的评估 大量的日志统计显示,通常的用户查询请求仅仅访问了结果页面的第一页[15]。在4.1和4.2节的工作中,我们依照文献[5]的方法,将查询日志中对后续结果页面(ItemRank>10)的查询请求去除。这样,我们在不考虑查询预取的情况下,对本文提出的层次化缓存机制进行了有效的评估。事实上,用户的查询除了具有时间局部性,还具有空间局部性。我们对实验的日志数据进行了重新处理,将那些对后续结果页面的查询请求进行了保留。然后我们对融合了预取策略的层次化缓存机制进行实验评估,实验结果如图9所示。显然融合了预取策略的层次化缓存机制,在查询响应时间上,能带来进一步的性能提升,并且随着缓存大小的增大,提升进一步增强并趋于稳定。总体上,我们对那些有较大访问可能性的,有限的结果页面进行了预取,同时利用了标识符缓存的空间优势,有效地压缩了由预取带来的额外空间开销,相对于传统的依赖于页面缓存的方法,显然具有更大的优势。 结果缓存是搜索引擎中一种有效的优化手段,用于降低查询响应时间,提高系统吞吐率。对于有限的内存资源,本文提出的层次化缓存机制能获得很好的性能提升。同时在此基础上,我们还提出了一种基于标识符缓存的启发式预取策略,用以挖掘用户查询行为的空间局部性。实验显示,这种预取策略的融合,能进一步促进整个系统的性能提升。至此,我们建立起了一套完备有效的结果缓存机制,很好地促进了Web检索系统的性能提升。在将来的工作中,我们会针对实时搜索引擎中(如新闻搜索,微博搜索)的缓存一致性问题进行进一步的研究[17-20],使本文提出的层次化缓存机制具有更广泛的应用场景。 [1] P Saraiva, E de Moura, N Ziviani,et al. Rank-preserving two-level caching for scalable search engines [C]//Proceedings of the SIGIR, 2001:51-58. [2] R Baeza-Yates, F Saint-Jean. A three-level search-engine index based in query log distribution [J].SPIRE,2003. [3] R Baeza-Yates, A Gionis, F Junqueira, et al. The impact of caching on search engines [C]//Proceedings of the SIGIR, 2007. [4] T Fagni, R Perego, F Silvestri, et al. Boosting the performance of Web search engines: Caching and prefetching query results by exploiting historical usage data [J]. ACM TOIS, 2006:24(1):51-78. [5] Q Gan, T Suel. Improved techniques for result caching in Web search engines [C]//Proceedings of the WWW,2009:431-440. [6] R Lempel, S Moran. Predictive caching and prefetching of query results in search engines [C]//Proceedings of the WWW, 2003:19-28. [7] E Markatos. On caching search engine query results [J]. Computer Communications, 2000,24(7):137-143. [8] Y Xie, D O’Hallaron. Locality in search engine queries and its implications for caching [C]//Proceedings of the IEEE Infocom, 2002. [9] R Baeza-Yates, F Junqueira, V Plachouras, et al. Admission policies for caches of search engine results [J]. SPIRE,2007. [10] X Long, T Suel. Three-level caching for efficient query processing in large Web search engines [C]//Proceedings of the WWW,2005:257-266. [11] Mauricio Marin, Veronica Gil-Costa, Carlos Gomez-Pantoja. New Caching Techniques for Web Search Engines [C]//HPDC’10,2010:20-25. [12] D Puppin, F Silvestri, R Perego, et al. Load-balancing and caching for collection selection architectures [C]//Proceedings of the INFOSCALE, 2007. [13] Altingovde I, Ozcan R. Second Chance: A Hybrid Approach for Dynamic Result Caching in Search Engines [C]//Proceedings of the ECIR’11, 2011:510-516. [14] J Wang, S Shan, M Lei, et al. Web search engine: characteristics of user behaviors and their implication [J].Science in China, 2001,44(F): 351-365. [15] David J Brenes, Daniel Gayo-Avello. Stratified analysis of AOL query log [J]. Information Sciences. 2009,179:1844-1858. [16] C Silverstein, M Henzinger, H Marais,et al. Analysis of a Very Large AltaVista Query Log [J]. Technical Report 014, SRC (Digital, Palo Alto), 1998. [17] Sadiye Alici, Altingovde I, Ozcan R. Time-based Result Cache Invalidation for Web Search Engines [C]//Proceedings of the SIGIR’11, 2011. [18] B B Cambazoglu, F P Junqueira, V Plachouras, et al. A refreshing perspective of search engine caching [C]//Proceedings of the WWW,2010:181-190. [19] R Blanco, E Bortnikov, F Junqueira, et al. Caching search engine results over incremental indices [C]//Proceedings of the SIGIR, 2010:82-89. [20] S Alici, I S Altingovde, R Ozcan, et al. Timestamp-based cache invalidation for search engines [C]//Proceedings of the WWW,2011:3-4. A Hierarchical Search Result Caching Based on Temporal and Spatial Locality ZHU Yadong1, 2, GUO Jiafeng1, LAN Yanyan1, CHENG Xueqi1 (1. CAS Key Lab of Network Data Science and Technology, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. University of Chinese Academy of Sciences, Beijing 100049, China) In a result cache, either document identifiers (docID cache) or the actual HTML pages (page cache) can be stored to accelerate the response speed. For a fixed memory size, the docID cache can achieve a higher hit ratio while the page cache can obtain higher response speed. This paper proposes a novel hierarchical result caching scheme based on temporal and spatial locality, in which the result cache is firstly split into two layers: a page cache and a docID cache. In our scheme, page cache will be the first choice for answering some queries, and then the docID cache. In terms of average query response time, the results show that the proposed approach achieves a substantial performance improvement than baseline method by 9% on average, and up to 11% in the best situation. Secondly, the scheme also designs an adaptive prefetching strategy based on docID cache. The experiments show that the proposed scheme combined with the prefetching strategy can lead to an additional performance improvement. And we finally build a complete and effective result caching scheme by capturing the temporal and spatial locality of user search behaviours. page cache; DocID cache; query response time 朱亚东(1985—),博士,主要研究领域为信息检索,机器学习与数据挖掘。E⁃mail:zhuyadong1985@126.com郭嘉丰(1980—),博士,副研究员,主要研究领域为信息检索,机器学习与数据挖掘等。E⁃mail:guojiafeng@ict.ac.cn兰艳艳(1982—),博士,副研究员,主要研究领域为统计机器学习,信息检索和数据挖掘等。E⁃mail:lanyanyan@ict.ac.cn 1003-0077(2016)01-0063-08 2013-10-12 定稿日期: 2014-05-15 国家973计划(2014CB340401,2012CB316303);国家863计划(2014AA015204);国家自然科学基金(61472401,61433014,61425016,61203298,61572473) TP391 A
3 基于标识符缓存的启发式预取策略

4 实验评估



5 总结和将来的工作

