基于混合模型的生物事件触发词检测
2016-05-03李浩瑞林鸿飞杨志豪张益嘉
李浩瑞,王 健,林鸿飞,杨志豪,张益嘉
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
基于混合模型的生物事件触发词检测
李浩瑞,王 健,林鸿飞,杨志豪,张益嘉
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
语义歧义增加了生物事件触发词检测的难度,为了解决语义歧义带来的困难,提高生物事件触发词检测的性能,该文提出了一种基于丰富特征和组合不同类型学习器的混合模型。该方法通过组合支持向量机(SVM)分类器和随机森林(Random Forest)分类器,利用丰富的特征进行触发词检测,从而为每一个待检测词分配一个事件类型,达到检测触发词的目的。实验是在BioNLP2009共享任务提供的数据集上进行的,实验结果表明该方法有效可行。
触发词;生物事件;歧义;丰富特征;组合学习器
1 引言
随着新的生物医学文献的爆炸性增长,越来越多的关系抽取方法得以提出,用来从生物医学文献中抽取有用的信息。近几年,事件抽取以其有表现力的结构化呈现而流行,广泛地应用于系统生物学,涉及到从对通路的产生和标注提供支持到数据库自动产生母体数据和丰富数据库数据等领域。生物医学事件与蛋白质-蛋白质交互关系(PPI)等二元关系不同,它包含了生物实体以及实体之间的交互关系。这些生物事件能够完整地代表原始关系的生物医学意义,所以从文本中自动地识别生物事件变得非常有意义。生物医学事件抽取就是一个在医学研究文章中自动检测分子交互关系描述的过程[1]。它的目的是从非结构化的文本中抽取关于预先定义事件类型的结构化信息。
生物医学事件抽取在BioNLP2009共享任务(以下称BioNLP’09)之后开始在领域内流行。在BioNLP’09结束之后出现了许多事件抽取系统。一般来说这些系统可以分为两类: 基于机器学习的系统和基于规则的系统。在BioNLP’09中性能最好的Uturku系统是泛化的系统,并采用了支持向量机(SVM)来进行事件抽取[2-3]。Uturku系统把事件抽取的整个过程分成了触发词检测和事件元素检测两个部分。该系统的特点是严重依赖高效、先进的机器学习技术和一系列从每个句子完全依存分析中产生的特征[4]。在BioNLP’09的任务1中排名第三的ConcordU系统是本次评测中最好的基于规则的系统[2]。另外,在BioNLP2011共享任务的四个大任务中获得三个任务性能第一的FAUST系统探索使用了模型的组合,它使用的基础模型是Umass对偶分解模型和斯坦福事件分析器。该系统的先进之处在于它使用了斯坦福事件分析系统的预测结果,并通过与对偶分解模型进行组合来求得最终的结果[5]。目前大多数的事件抽取系统关注的是整个事件抽取的过程,将触发词检测作为一个单独问题进行研究的比较少见。检测生物事件触发词是事件抽取过程中一个非常重要的步骤,触发词检测的性能对它之后的步骤的性能有很大的影响,它在事件抽取中起到了至关重要的作用。David等人提出了一种使用向量空间模型(VSM)和条件随机场(CRF)相结合的方法,建立触发词检测的语义消歧系统(WSD)[6]。该方法是将每个出现的歧义词表示成一个向量,向量的每一维代表了一个特征的出现或者缺失,在该系统的训练过程中,系统为每个词类型的每个含义产生一个单一的质心向量。该系统在BioNLP’09的数据集上进行了实验,并取得了较好的效果。
事件抽取通过识别文本中触发词和参与的实体来发现触发词和实体之间的关系。作为整个事件抽取流程中的基础步骤,事件触发词检测的性能对整个事件抽取过程的性能有着至关重要的影响。在触发词检测过程当中,语义歧义使得触发词检测有一定的难度。如下面的例1~例3中,单词“expression”在例1和例3中是触发词,而在例2中不是触发词。而是触发词的情况下,该单词在例1和例3标识的事件类型也是不同的类型。因此,很难判定诸如“expression”这类单词是否是触发词或者在是触发词的情况下它们标识的触发词的类型。
例1 It activates Prot18 geneexpressionin T lymphocytes.
例2 ......, theexpressionwas enhanced at 30 min.
例3 theexpressionof c-fos mRNA was suppressed at 30 min
受到之前提及系统的启发,特别是FAUST系统的原理,本文利用组合学习器的方法,使用从原始句子和句子依存分析树中产生的特征来进行触发词检测。在实验的过程中,除了使用一些常用的文本特征,如词特征,还从依存分析树中发掘了很多特征。把这些特征应用到两个判别原则完全不同的学习器中,即支持向量机(SVM)和随机森林(Random Forest)。最终,根据每个学习器单独预测性能的好坏指派权值,对两个分类器输出的结果进行线性加权组合得到最终的输出结果。实验结果表明,组合学习器能够获得比单独使用任何一个学习器更好的效果。
2 相关工作
2.1 依存句法分析器
依存分析树是用来表示一个句子中词与词之间的语法关系。依存分析器用来构建一个句子的依存关系树。在依存分析树中每一个节点代表一个词,每一条边代表了两个词之间的关系。本文使用的是GDep[7]依存分析器,图1中是句子“AML and Ets proteins regulate the I alphal germtine promoter.”的依存分析树。
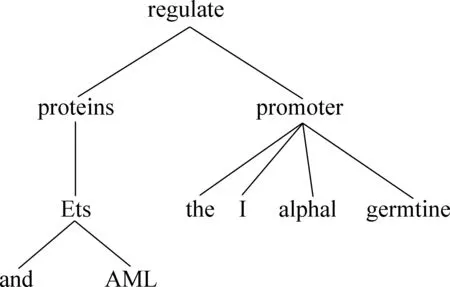
图 1
2.2 相关学习器
组合总是做出类似决策的学习器是毫无意义的[8]。将决策原则不同的分类器进行组合,分类器在决策时可以进行互补。本文采用了两个基础的分类器: 一个是支持向量机,它是基于线性判别的决策理论;另一个是随机森林,它是基于决策树的决策理论。这两个分类器在决策原理上是不相同的。接下来简要介绍一下本文中使用的分类器和它们的决策原理。
2.2.1 支持向量机
支持向量机是一种基于线性判别的方法,它使用Vapnik原则,即在解决实际问题之前总会把解决一个较为简单的问题作为第一步[9]。支持向量机的目的是学习一个能够将训练集里的正例和负例分开的超平面。超平面到任意一边离超平面最近点的距离标为间隔。支持向量机的目的是找到能够使得间隔最大化的最优间隔超平面,同时又使得分类器的泛化误差最小。
假设有训练样本(xt,yt),xt是n维特征空间中的一个向量,yt是类别标签-1代表负例,+1代表正例。图2中超平面w*x+w0= 0将训练样本正确的分离并且最大化超平面w*x+w0= 1 和w*x+w0= -1之间的间隔。超平面可以通过求解公式(1)而得到。
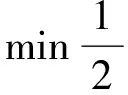
(1)
通过引入拉格朗日因子α,超平面可以最终表示为公式(2)。
(2)
式(2)中的K(xt,x)被称为核函数。经过计算,根据f(x)的符号给待预测点x分配相应的类别标签。

图2 线性可分情况下支持向量机的最优分离超平面
2.2.2 随机森林
随机森林(简称RF)是一种使用了一组未修剪的决策树的分类算法。每一棵分类树都是使用了数据的引导样例,并且在每一个数据分割中变量的候选集是整体变量的一个随机子集[10]。随机森林使用两种方法来构建树:一种是装袋法,它是一种对于组合不稳定学习器比较有效的方法[11-12];另一种是随机变量选取法。假设给定一组分类器C1(x),C2(x),...,Ck(x)和从随机向量的分布中随机抽取的训练集X,Y,定义间距函数为公式(3)。
(3)
此处I(x)是指标函数。所谓间距,是用来衡量给一个样本X,Y投票时,投它是正确类票数平均数超过投它是其他类票数平均数的程度。间距越大,学习器在分类时得到的结果就越可信。在随机森林中,第k个分类器可以表示成另一种形式,即Ck(x) =C(X,Θk)。对于大多数的树而言,随机森林遵循强大数定理并遵循如下的结构: 随着树的数量增加,可以肯定的是对于所有的Θ序列,PE*收敛于H[13]。其中H可表示为公式(4)。
(4)
通过描述可以看到随机森林的决策机制和之前选的第一个分类器(SVM)的决策机制是不同的。
除了决策机制,本文选用随机森林作为第二个学习器的原因是在分类任务中随机森林有非常优秀的性质。主要有以下两点性质促使了本文的实验使用随机森林。
首先,使用强大数定律表明了随机森林是收敛的,所以过拟合不是问题;
其次,是随机森林的泛化误差,泛化误差的形式为公式(5)。
(5)
此处X,Y标明了概率是在X,Y空间上的。泛化误差的上限可以表示成两个参数的形式,这两个参数分别表示了每一个单独分类器的准确性和各分类器之间的依赖性。
3 实验方法和结果
3.1 相关特征
本文使用一些常用的特征和一些从句子的依存分析树中发掘的特征。主要包括下列几种特征。
词特征:词特征主要包含词本身以及由GDep产生的词干和这个词在句子中的词性。
词袋特征:词袋特征是指候选词周围的词,包括了候选词前边和后边的N个词。考虑到特征的维数和特征的表现能力,本文将N设定为8。
依存分析特征:依存分析特征主要来自于GDep解析器的解析结果,包括了候选词的依存信息和候选词在依存分析树中的路径信息以及候选词在依存分析树中的父节点和子节点的信息。
N元特征:N元特征主要包括以候选词为中心的一个范围内的N元词组,主要是三元组和二元组。这些N元特征丰富了词袋特征的表现[14-15]。
距离特征:距离特征用来衡量候选词和最近的蛋白质之间的距离。触发词是和蛋白质紧密相关的,一个距离蛋白质近的候选词比一个距离蛋白质远的候选词更有可能是触发词。本文定义的距离指的是在原始语句中候选词到最近蛋白质所包含的单词的个数(在距离统计时将蛋白质包含在内)。统计发现,在BioNLP’09的训练集中大部分的触发词是靠近蛋白质的。图3中表示的是在BioNLP’09的训练集中触发词和其距离最近的蛋白质的分布图,例如,有超过1 200个触发词与蛋白质相邻,距离定义为1,接近1 600个触发词与蛋白质距离是2。
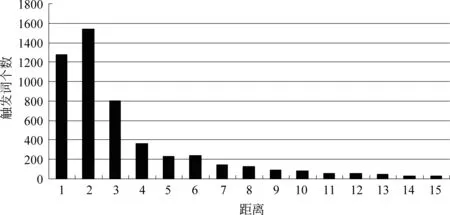
图3 触发词个数与距离最近的蛋白质的关系图
依存路径特征:相同的候选词在一个句子里是触发词而在另一个句子里不是触发词。经过研究,在例4和例5两个句子中,expression在例4中是触发词而在例5中不是触发词。
例4 Prot24 can directly inhibit STAT-dependent early response gene expression induced by both IFNalpha and Prot25 in monocytes by suppressing the tyrosine phosphorylation of Prot23.
例5 IL-10 preincubation resulted in the inhibition of gene expression for sev-eral IFN-induced genes...
使用了依存分析器之后,在依存分析树中构建从蛋白质到根节点的路径。例4中的expression在该路径上并且是触发词;而例5中的相同单词没有在这个路径上并且不是触发词。经过对训练集的验证,发现有超过60%的触发词有这个特性,因此实验中本文采用了这个特征来鉴别一个候选词是否是触发词。
3.2 数据集和方法
大多数的BioNLP共享任务的事件抽取过程是分成两个模块的,包括触发词检测和事件元素检测。事件触发词的检测在事件抽取中的作用至关重要,它的目的是识别出每一个事件触发词以及事件的类型。本文主要集中于触发词检测的相关工作。
本文使用的数据集是BioNLP’09任务的数据集,它源于GENIA事件语料库。语义消歧(WSD)系统[6]采用的同样是该数据集,表1展示的是该数据集预定义的九种事件类型。
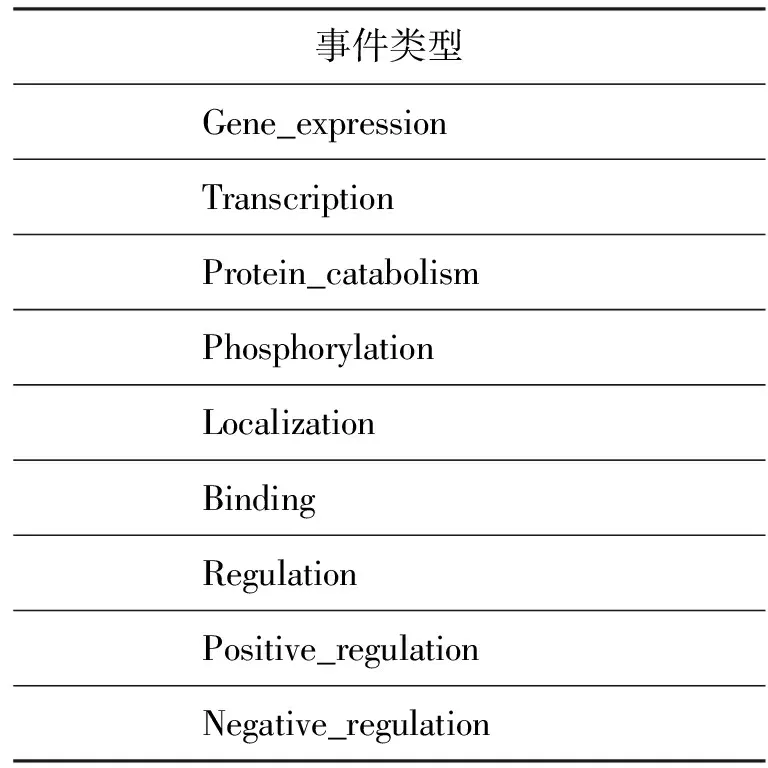
表1 九种事件类型
本文将触发词检测看成一个给候选词标注类别的问题[16]。目的是为触发词的候选词分配一个事件类型,将非触发词的候选词标记为非触发词。本文进行触发词检测的方法是首先在训练集中建立触发词字典,在测试集中根据触发词字典寻找候选的触发词。采用组合学习器,将每一个候选词单独的进行事件类型的标注。本文将触发词看成单词,多个单词构成的词组触发词由短语中第一个非停用词代替。因为词组触发词不便于对测试集检测时进行字典查询。经过统计,训练集中的6 376个触发词中只有489个触发词是词组,约占7.6%。
本文使用了当前性能先进的多分类速度最快的分类器LibSVM[17]和不会过拟合且泛化误差有上限的随机森林。多分类支持向量机有一个正则化参数,这个参数可权衡模型的复杂度和训练误差。多分类支持向量机在训练样本的数量和每一个训练样本非零特征的平均数量上都是线性增长的,这个性质使它成为更适合本文目的的学习方法。实验采用了径向基(RBF)核函数,并且把shrinking和概率参数设为1。通常来说,在随机森林中,随着树的数量的增加,随机森林的精确率随之提高,但模型的复杂度也随之增加。另一个参数是用来随机选择属性的个数。实验将随机森林的随机数种子设为默认值。出于各方面考虑选择了150棵树和150个随机特征来进行实验。
实验使用相同的特征对两个模型进行单独训练,并用训练好的模型对BioNLP’09的发展集进行预测。之所以使用发展集是因为BioNLP’09组织者没有给出测试集的答案。在得到两个模型的输出结果后,根据模型的准确率将两个模型的输出结果进行线性加权组合。具体的方法是对每一个候选实例,通过把两个模型的输出概率进行加权相加重新计算候选实例属于各个类别的概率。最终将候选实例标记为重新计算后概率最大的一类事件类型。
3 实验结果分析
本文对组合模型和每个单独的模型在Bio-NLP’09发展集上的输出结果进行了分析。本文系统和语义消歧系统(以下简称WSD)的性能比较如表2所示,其中描述了本文与WSD方法在每一个事件类型的性能,以及系统总体性能上的对比。
从表2中可以看出,本文方法与WSD方法在准确率上几乎相同,但是获得了优于WSD方法的召回率。
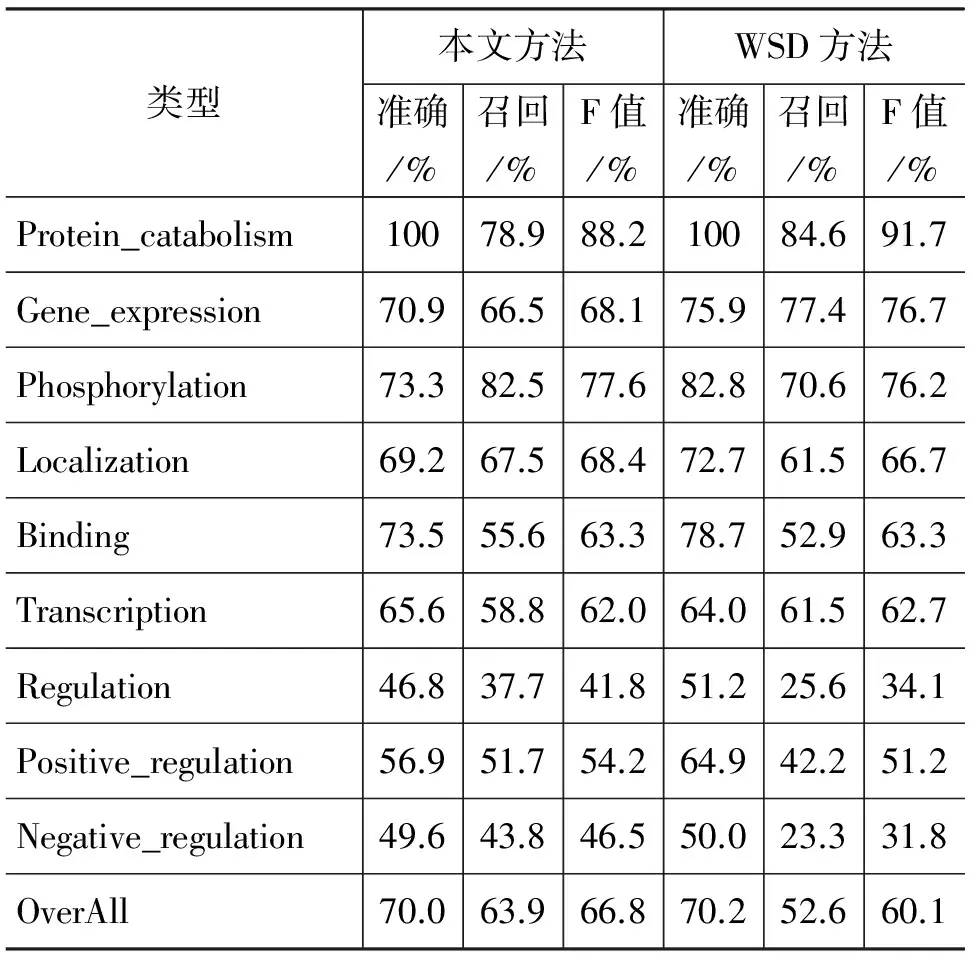
表2 本文方法与WSD方法的性能比较
通过表2和图4可以发现,regulation, positive regulation, negative regulation这三类事件相比于其他类型的事件是更难检测的。这三个类型的F值都在55%以下,而其他类型的F值在60%以上。导致这种情况的主要原因是这三个类型是复杂的事件类型,它们包含了网状的关系和更多的事件元素,因此更难检测。本文系统性能最好的事件类型与WSD方法相同,是Protein_catabolism类型。值得注意的是,本文的系统在regulation, positive regulation, negative regulation这三类复杂事件的检测上相比于WSD有较好的性能。正是由于在检测这三类复杂事件中具有较高的性能,本文系统的整体性能超过了WSD系统。
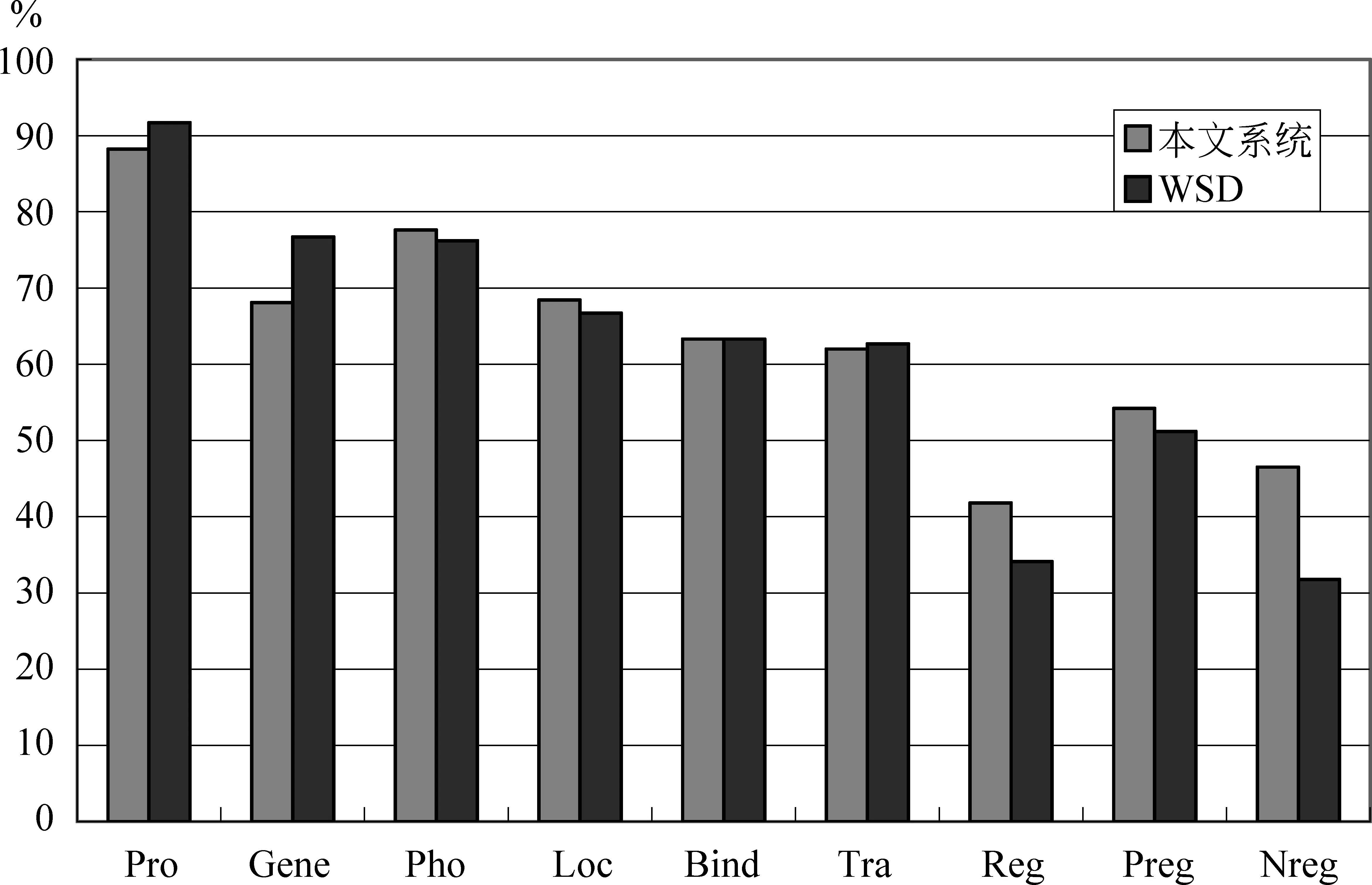
图4 本文系统和WSD系统在各个事件类型上的性能比较
表3所呈现的是每一个单独的学习器和组合后的学习器的最好的性能。与WSD方法相比较,本文的支持向量机使用了训练集的全部实例来构建模型,以及比较多的特征,并对参数和核函数进行了调整。在随机森林模型中,使用30多组实验来调整树的数目和随机属性选取个数这两个参数。最终,综合考虑性能和时间消耗,实验选取了150棵树和150个随机属性的随机森林模型,它的性能如表3所示。在组合了两个学习器之后,实验得到了比单独使用任何一个学习器性能都好的结果。本文获得了66.8%的F值,比单独使用支持向量机的方法高出1%,比WSD方法高出了6.7%。

表3 单个学习器与组合学习器的性能比较
表4给出了比较详细的错误分析。实验的目的是找到每一个触发词并给它们标注一个事件类型,因此只对发展集上624个错误实例进行分析。首先,有113个实例是有多于一个单词的词组触发词构成的,这种情况本文是做了简化处理的,所以在检测的过程中根本不能发现词组触发词。另外,有18个触发词是包含“-”的,这些单词在实验中也是被忽略的。有198个触发词是在发展集中出现过,而没有在训练集中出现过,这些词就不会出现在触发词字典中,从而无法检测到它们。还有295个触发词被错误的分类,包括将类型标注错误和将触发词标注成为非触发词。

表4 错误分析
最后,从表5中可以看到,虽然随机森林在发展集中找到了比较少的触发词,但随机森林仍然将支持向量机认为是触发词的25个词正确的排除,使得在找到正确触发词个数相同的情况下,提高了组合学习器系统的召回率。
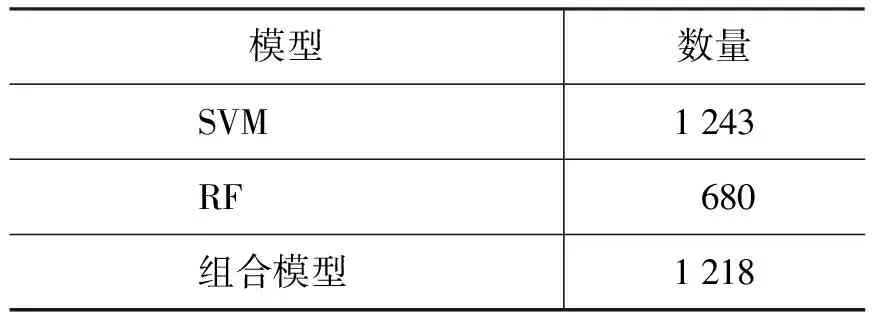
表5 各模型找到的触发词的个数
4 结束语
本文展示了一个使用丰富特征和组合学习器方法进行事件抽取触发词检测的系统。使用的特征能够充分利用句子的信息和句子的依存关系信息。选用的学习器是根据不同的决策原则进行组合,从而在决策时能够互补。本文的方法与WSD方法以及单独使用任何一个分类器相比都取得了较好的效果。
在后续工作中,将继续使用本文的方法研究事件抽取的整个过程,希望能够从理论方面找到更多的能够决策互补的学习器加以利用。
[1] Björne J, Salakoski T. Generalizing biomedical event extraction[C]//Proceedings of the BioNLP Shared Task 2011 Workshop. Association for Computational Linguistics, 2011: 183-191.
[2] Kim J D, Ohta T, Pyysalo S, et al. Overview of BioNLP′09 shared task on event extraction[C]//Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing: Shared Task. Association for Computational Linguistics, 2009: 1-9.
[3] Björne J, Ginter F, Heimonen J, et al. Learning to extract biological event and relation graphs[C]//Proceedings of the 17th Nordic Conference on Computational Linguistics (NODALIDA′09). 2009: 18-25.
[4] Björne J, Heimonen J, Ginter F, et al. Extracting complex biological events with rich graph-based feature sets[C]//Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing: Shared Task. Association for Computational Linguistics, 2009: 10-18.
[5] Riedel S, McClosky D, Surdeanu M, et al. Model combination for event extraction in BioNLP 2011[C]//Proceedings of the BioNLP Shared Task 2011 Workshop. Association for Computational Linguistics, 2011: 51-55.
[6] Martinez D, Baldwin T. Word sense disambiguation for event trigger word detection in biomedicine[J]. BMC bioinformatics, 2011, 12(Suppl 2): S4.
[7] Sagae K, Tsujii J. Dependency parsing and domain adaptation with LR models and parser ensembles[C]//Proceedings of the CoNLL Shared Task Session of EMNLP-CoNLL 2007. 2007: 1044-1050.
[8] Alpaydin E. Introduction to Machine Learning[M]. London:The MIT Press Cambridge, Massachusetts, 2010: 419-445.
[9] Cortes C, Vapnik V. Support-vector networks[J]. Machine learning, 1995, 20(3): 273-297.
[10] Díaz-Uriarte R, De Andres S A. Gene selection and classification of microarray data using random forest[J]. BMC bioinformatics, 2006, 7(1): 3.
[11] Hastie T, Tibshirani R, Friedman J. The elements of statistical learning[M]. New York: Springer, 2001.
[12] Breiman L. Bagging predictors[J]. Machine learning, 1996, 24(2): 123-140.
[13] Breiman L. Random forests[J]. Machine learning, 2001, 45(1): 5-32.
[15] Qi H, Li K, Shen Y, et al. An effective solution for trademark image retrieval by combining shape description and feature matching[J]. Pattern recognition, 2010, 43(6): 2017-2027.
[16] Vlachos A. Two strong baselines for the BioNLP 2009 event extraction task[C]//Proceedings of the 2010 Workshop on Biomedical Natural Language Processing. Association for Computational Linguistics, 2010: 1-9.
[17] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning (ICML’01). 2001:282-289.
A Hybrid Approach to Trigger Detection in Biological Event Extraction
LI Haorui, WANG Jian, LIN Hongfei, YANG Zhihao, ZHANG Yijia
(School of Computer Science and Technology, Dalian University of Technology, Dalian, Liaoning 116024, China)
Word sense ambiguity challenges the trigger detection in biological event extraction. This paper proposes a hybrid method combing different learners trained with rich features to deal with word sense ambiguation for trigger detection. Specifically, we address the trigger detection by assigning an event types to each token, adopting a multi-class SVM classifier and Random Forest. Experiments on the BioNLP 2009 shared task dataset show that this method achieved a good performance.
trigger detection; biological event; ambiguation; rich features; combination of learners

李浩瑞(1987—),硕士,主要研究领域为机器学习、生物医学文本挖掘。E⁃mail:irlihr@163.com王健(1967—),博士,教授,主要研究领域为信息检索、文本挖掘、自然语言处理。E⁃mail:wangjian@dlut.edu.cn林鸿飞(1962—),博士,教授,博士生导师,主要研究领域为信息检索、文本挖掘、情感分析、社会计算和自然语言处理。E⁃mail:hflin@dlut.edu.cn
1003-0077(2016)01-0036-07
2013-08-10 定稿日期: 2014-05-10
国家自然科学基金(61572098,61572102,61300088,61272373);辽宁省自然科学基金(2014020003)
TP391
A
