非物质文化遗产知识本体构建系统的设计与实现——以西藏“锅庄”、“堆谐”为例
2016-04-27黄永陆伟程齐凯邓胜利武汉大学信息管理学院湖北武汉430072武汉大学信息检索与知识挖掘研究所湖北武汉430072
黄永,陆伟,程齐凯,邓胜利(武汉大学信息管理学院湖北武汉430072;武汉大学信息检索与知识挖掘研究所湖北武汉430072)
非物质文化遗产知识本体构建系统的设计与实现——以西藏“锅庄”、“堆谐”为例
黄永,陆伟,程齐凯,邓胜利
(武汉大学信息管理学院湖北武汉430072;武汉大学信息检索与知识挖掘研究所湖北武汉430072)
摘要:本文以“锅庄”、“堆谐”两种具有代表性的西藏非物质文化遗产为例,分析了西藏非物质文化遗产知识本体构建的重难点,对其中的关键问题如领域数据集构建、领域文本分词、本体标注、本体关联、本体可视化等进行了研究,在此基础上设计并实现了一个面向文本与多媒体数据的非遗知识本体构建系统,并在此基础上构建了一个具有一定规模的非遗知识本体库。
关键词:非物质文化遗产;本体构建;本体系统
陆伟(1974-),男,辽宁鞍山人,现为武汉大学信息管理学院教授,博士生导师,主要研究方向为信息检索、知识管理、数据挖掘等。
一、引言
根据联合国教科文组织《保护非物质文化遗产公约》中的表述,非物质文化遗产(以下简称非遗)是“以口头传承、表演艺术、民俗活动和手工技能为代表的人类知识,它们共同构成了以民族文化为表现形式的文化空间”,从多种角度诠释了一个民族关于自然和宇宙的传统知识与朴素哲学。中华文化积淀深厚,流传久远,其所产生的非遗资源表现出总量巨大、门类繁多、体系庞杂等特点。
西藏非物质文化遗产资源丰富,但是受限于地理环境、气候、文化传统、保护手段,这些文化资源正面临着难以传承的风险。固化保护是非物质文化遗产保护的重要手段,在固态保护中,利用信息技术已经成为固化保护的重要发展趋势。本文则以西藏非物质文化遗产两种重要的舞蹈“锅庄”、“堆谐”为例,研究本体技术在非物质文化遗产保护中的应用。
非遗保护作为一种技术、流程、标准与制度有机结合的工作,在当代遗产保护的大潮中已经得到了充分肯定。与此同时,人们普遍地意识到,非遗分类组织作为非遗保护的重要基础工作,其有效性直接影响着非遗保护的效果。缺少准确科学的组织分类方法与手段,非遗保护人员难以科学认识非遗对象,也无法准确描述非遗对象,保护策略的制定自然就无从谈起。
我国非遗保护工作从20世纪末起步以来,取得了较大的成就。在非遗的组织分类方面,“十一五”以来,主题分类、等级分类、地域分类等分类组织方法已经形成。总体看来,上述分类方法都是单线索分类组织思想的产物,单线索的分类组织方案存在效用不足的问题,根源在于它不能很好地描述非遗项目中存在的复杂关系,并且非物质文化遗产保存格式多样,例如文本、音频、视频,单一组织方式不能对各种类型资源充分集成。因此需要一种新型的组织形式用于描述非遗项目中的复杂关系,并且能够对多种类型的资源进行整合。
本体是共享概念模型的形式化规范说明[1],能够在语义和知识层次上描述信息,自被提出以来就引起了国内外众多科研人员的关注,并在许多领域得到了广泛的应用,如知识工程、数字图书馆、信息检索、异构信息的处理和语义网等。使用本体能够很好地对非遗项目的内在复杂关系进行描述,对非遗资源进行有效整合及组织,从而能够对非物质文化的保护有促进作用。
本文以“锅庄”、“堆谐”两种具有代表性的西藏非物质文化遗产为例,分析了西藏非遗知识本体构建的重难点,对其中的关键问题,如领域数据集构建、领域文本分词、本体标注、本体关联、本体可视化等进行了研究,在此基础上设计并实现了一个面向文本与多媒体数据的非遗知识本体构建系统。本文还建构了一个具有一定规模的非遗知识本体库。
本文在第二部分对本体及非物质文化遗产保护相关研究进行阐述;第三部分详细描述本体构建系统的框架;具体的技术细节将在第四部分阐述;第五分部对本体构建过程进行描述;最后对本文进行总结,并给出下一步工作。
二、相关研究
截至目前,非遗本体构建方面尚没有出现研究成果。与该主题相关的研究存在于本体研究、文化遗产本体研究两个方面。
(一)本体研究
流行的定义,将本体定义为“给出构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成的规定这些词汇外延的规则的定义”[2]。Studer等给出了本体的另一个定义,认为“本体是共享概念模型的明确的形式化规范说明”。本体的核心是共享概念模型,包括共享概念、共享动词、共享名词等[3]。就本体的构造而言,尽管各个本体设计有所不同,但一般可以将本体的内在要素归结为个体(实例)、类(概念)以及附加在实例和概念之上的约束、规则、公理。由于本体在人工智能(AI)、信息架构(IA)等领域的巨大前景,本体得到了广泛的研究。主要的本体研究课题包括概念和分类体系、本体描述语言、本体工程、本体推理,本体在信息共享、信息检索等领域的应用,基于本体的数据集成、语义网等。另外,也出现了一些非常有影响力的本体构建实例,如词汇本体Word-net[4],电子商务应用本体CContology,植物本体PlantOntology[5]。此外本体构建工具protégé[6]常用于本体构建中。
(二)文化遗产本体研究
文化遗产研究领域,本体方案有CIDOC CRM[7]、CDWA、AAT、TGN此外,基于已有的或者自行设计的本体,特别是围绕CIDOC CRM本体框架,出现了大量的研究成果。本体构建方面:文献[8]对CIDOC CRM本体框架做了细致的介绍,文化遗产的发布和展示方面,文献[9](P851-856)介绍了利用语义网络的文化遗产出版展示方法,文献[10](P757-758)论述了文化遗产的展示方案,列举了如分布地图网络关系图等多种展示和利用方法;文化遗产的开发利用方面:文献[11](P75-79)介绍了一种以本体推理和聚类技术为基础的文化遗产自动描述和价值发现方法,该方法包括输入、分析、智能推理发现、可视化四个步骤。国内对于文化遗产本体的研究也出现了一些成果,包括CIDOC CRM的应用,传统节日的本体建构、基于地理本体的文物信息模型构建等[12][13]。但总的来说,相比国外,国内的研究还处在起步阶段,多是对已有本体的应用,缺乏原创的成果。
(三)西藏非物质文化遗产保护
西藏自治区是我国非物质文化遗产大区,非物质文化遗产基础深厚、特色鲜明。非遗保护工程2005启动,2011年西藏非物质文化遗产保护中心成立,这是西藏非物质文化遗产保护的一个重要里程碑。文献[14]探讨了新媒体语境下西藏非物质文化遗产传承与保护的数字化技术。文献[15]对西藏非物质文化遗产的分类与保护进行了研究。
本体既能对非物质文化遗产内部错综复杂的关系进行很好的描述,又能够进行资源整合。目前没有面向非物质文化遗产保护的非遗知识本体构建系统,本文以西藏两种舞蹈“锅庄”“堆谐”为例,论述面向非物质文化遗产保护的知识本体构建系统的设计与实现方案。在下一部分将详细论述系统的整体框架以及系统实现中的难点。
三、系统框架
本体是一种对领域中的概念及关系的一种规范说明,不同的本体构建方法就有不同的系统结构。本文将本体的构建定义为概念及概念关系的发现,并不涉及本体中公理的构建等工作,因此,(概念实例,关系,概念实例)三元组的发现成为了本文本体构建的核心。在本文中使用概念表示本体中的实体类别,例如“锅庄”是一类舞蹈的名称即是概念,使用概念实例表示具体的实体,例如锅庄舞蹈中的“醉酒锅庄”,使用属性表示概念之间的关系,例如“锅庄”的一种别称是“歌庄”,也即是概念实例“锅庄”有一种属性为“别称”,属性值对应于另外一种概念实例“歌庄”,也即是三元组(锅庄,别称,歌庄)。通过对数据集中所有三元组也即是概念及概念关系挖掘之后,领域本体的构建也就基本完成。

图1:本体构建系统框架图
根据上述思路,本体构建系统(如图1所示)主要有三个模块构成,分别是领域数据集构建、本体构建、本体可视化及检索。
领域数据集构建模块主要完成领域数据的收集、处理、加工、存储工作,解决本体构建的数据问题;领域数据集构建一支是领域问题的首先需要面对的问题,主要难点在于:领域数据相较于一般问题不同,其主要特点就是数量少、收集困难等,这都阻碍了领域数据收集工作的进行;其次,领域知识识别困难,在领域本体构建过程中最重要的就是概念识别,如果无法正确的识别领域中的概念,概念的关系也就无从谈起。因此,本体构建中领域数据集构建难点主要包括数据收集以及领域概念识别。
本体构建模块主要分为本体定义,即定义领域本体的概念和属性,基于文本的本体标注,多媒体本体关联三个模块解决本体构建问题;本体定义主要包括概念定义以及属性定义,对领域中可能涉及的概念及其属性进行定义。基于本文的本体标注在本体定义的基础上从文本中标注出概念实例以及使用属性标注实例之间的关系,并且通过学习对可能存在的三元组进行提示;本体关联是将媒体数据如视频、音频等中的关键帧、片段关联到已经构建的本体概念实例中去。在本模块主要的难点就是本体标注以及本体关联。
可视化及检索模块则是对构建本体进行可视化以及检索,解决本体展示问题。本系统采用树形结构对构建的本体进行展示,并且集成本体检索功能,对本体的具体信息进行展示,包括属性、属性值,文本信息、多媒体数据信息等。
这里主要对本文系统的框架及三个主要模块进行了阐述,针对每个模块的难点以及解决方法将在之后进行详细论述。
四、领域数据集构建
(一)领域数据集的难点
领域数据集构建模块是本体构建系统的基础模块,其主要负责为本体系统其他模块提供准确的数据,主要包括数据收集、数据处理、数据存储等步骤,对应于不同的步骤分别对应以下难点:
1、领域数据收集
领域数据尤其是特定领域对象的领域数据,数据量一般较小。数据源一般分为两种:一种是网络,另外一种现有文献书籍。现有文献书籍中对于非物质文化遗产项目一般都是从文化、艺术等层次进行描述,而对于具体特定的对象描述较少,并且一本书籍数不超过10万字,其中描述特定领域对象的文字更少,因此从现有书籍中获取领域数据是不现实的。丰富的领域数据是本体构建的关键,所以,本文针对当前数据问题,提出了一种基于查询扩展的领域数据集构建方法,该方法根据种子关键词从网络中获取数据,能够极大地丰富领域数据。
2、领域概念识别
领域概念是区别于其他领域的“专有名词”,例如本文中的“锅庄”、“堆谐”,对于领域知识不了解的人无法确认这个词汇的意义,甚至可能认为这不是一个词汇。可以说,领域概念的正确识别是数据处理中另一个重要问题,在本体构建系统中,概念识别问题本质上是一种领域分词问题,也即是对上述所述的领域词汇进行正确分词。本文则是通过对一般分词的改进使之适用于领域分词问题。
(二)基于bootstrapping的领域数据收集
领域本体构建都是数据驱动的,领域语料库的大小将决定了本体的构建效果,但是领域本体构建的领域特性限制了数据资料可获得性,于是本文提出了一种基于bootstrapping的领域本体构建方法。
该方法主要动作就是完成从搜索引擎中获取更多的关于该领域的资料。例如在搜索引擎中搜索“锅庄”一词,一次返回700条,但是这些数据显然不能满足本文的要求和目标,所以本文需要在搜索引擎中挖掘出更多的语料,本文的方法就是通过查询扩展进而实现,但是区别于一般的查询扩展算法,一般的查询扩展是为了完成搜索引擎获取更多与查询query更相关的文档提高查准率,本文是从相反的角度来从搜索引擎获得更多文档来提高查全率。
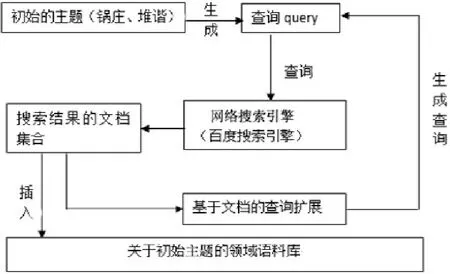
图2:基于bootstrapping的领域语料构建
基于bootstrapping方法的领域语料库构建是一种结合查询扩展技术从搜索引擎中不断迭代出搜索结果的过程。其中主要步骤为查询扩展和迭代过程。通过bootstrapping的方法中的扩展出来的查询词是与原主题相关的,所以能够用于构建领域语料库。
通过这种方法构建语料库的原因主要是因为在搜索引擎中本文给出一个关键词,搜索引擎只能返回给本文优先的条目数,本文采用这种方法主要目的就是从搜索引擎中挖掘出更多的主题相关的语料,用于构建数据库。
经过实验,本文的结果如下:
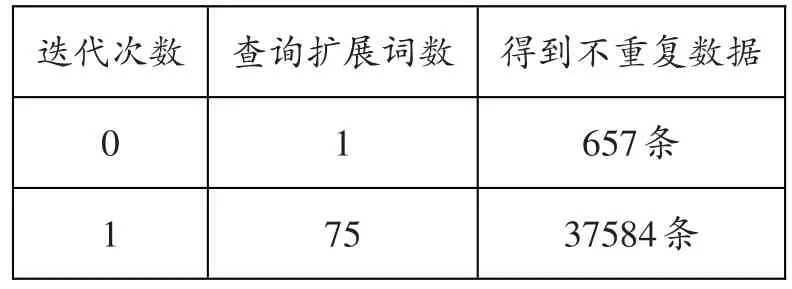
表1:语料库构建结果
通过多次的扩展查询,可以获得更多的结果,本文只进行一层扩展,获得了37584条数据,数据总体大小超过500M,能够满足本体构建的基本需求。
(三)领域分词方法
领域分词问题一直是领域数据集处理的重点和难点,一般领域分词方法都是在一般分词工具的基础上加入领域词表,通过领域词表对分词效果进行改进。本文也是使用领域词表改进分词效果,因此领域词表的构建也就成为领域分词的关键。
本文认为对于一个领域,其领域特有词汇会在已有的学术文献的关键词中出现,因此,本文使用“锅庄”、“堆谐”、“藏族舞蹈”等词汇在学术论文库中进行搜索,将搜索结果中论文的关键词作为领域词加入到领域分词工具的词表中。本文使用中科院分词器NLPIR[16][17]对数据进行分词。
五、本体构建
(一)本体定义
本体定义是领域本体框架的定义,主要包括概念和属性两种,本文以锅庄和堆谐为例进行本体构建,因此,本文的概念只包括两种舞蹈“锅庄”、“堆谐”,其余实体作为两种舞蹈的属性实例。


图3:本体定义包括概念定义及属性定义
如图3所示,本体定义包括概念定义以及属性定义两个模块,分别对本文所涉及的概念以及属性进行定义。本文的本体构建对象是“锅庄”、“堆谐”两种舞蹈,本文本体定义的主要框架如图4所示。主要包括基本属性以及总体属性,基本属性包括动作、地域、场景、服饰、功用、流程,总体属性包括别名、简介、子类、传承人、出现时间等以及多媒体属性。其中一些属性例如地域、多媒体属性是可以关联到现有的地域本体以及多媒体本体当中。
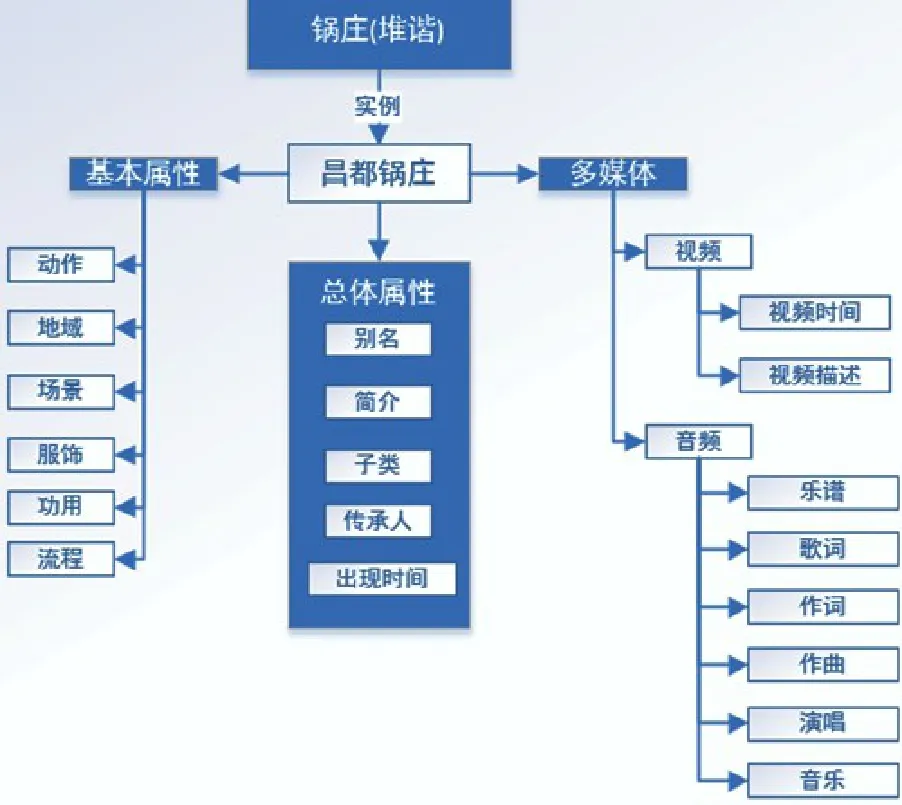
图4:本文本体定义框架
上述的本体定义框架是对本体构建的基本要求,在本体标注过程中可以根据具体的情况使用属性定义对属性进行修改和扩充。
(二)基于文本的本体标注
本体标注是在所收集的领域数据之上根据本体定义标注出三元组的过程。该过程本系统主要包括人工标注、潜在关系推荐两个模块。首先将领域数据使用领域分词进行分词,将每一个词作为标注的对象,在系统中点击标注对象弹出菜单,对概念实例和关系进行标注。该步骤一般是由人工完成,对已经标注的概念实例及关系,会在所有的文档中进行显示和关联。

图5:标注页面
在本体的文本标注过程中采取了一种辅助人工标注的方法,该方法是一种基于种子的模式提取方法。模式是指用于提取概念以及概念关系的模板。例如:
“锅庄分为了大锅庄和小锅庄等”
上面的一句中说明了锅庄的一种上下位的关系,它的模板是:
< C >分为< C1 >和< C2 >等
其中C表示了概念替代概念的符号,该模式下就说明了概念C是由概念C1和概念C2的父类,也就找出了三种概念C、C1、C2,C是C1和C2的上位概念。上面描述的是一般的模式识别的方法,它有自己的优点如准确率高,简单等,但是模板的制定通常需要人为参与,导致了这种模式识别方法虽然准确率高但是不能大规模展开,并且人为的制定模式耗时耗力。

图6:基于种子的模板自动提取
所以本文使用一种基于种子的模式提取方法,该方法是一种无监督方法(如图6所示),它主要在数据库中搜索已经有的种子模板,并提取相对应的模板中的概念,并使用这种概念实例去搜索语料库中的所有句子,从每个句子中提取出来各自的模板,最终采用投票机制,选取出能够代表这种关系的模板。然后不断地迭代,选出所有的模板。
根据该方法提取出关于上下位关系以及包含关系的模板库,用于进行概念提取和概念关系识别,从而辅助人进行文本的实例标注。
(三)多媒体关联
非物质文化遗产项目最常用的保存方式是多媒体格式,如视频、音频、图片等,如何将这些多媒体关联到本文所构建的本体是本模块的关键问题。因此本系统在文本标注的本体之上进行多媒体关联。
在本系统中主要对视频数据进行本体关联,包括视频关键帧和视频片段。如图7所示,视频通过暂停继续来进行截取关键帧,并且标注者能够与前面定义的本体以及实例相关联。通过获取视频的开始时间和结束时间完成视频片段的标注。
在本系统中使用是进行FFMPEG[18]完成视频的关键帧的提取工作。

图7:视频标注系统界面
(四)可视化及检索
在本系统中使用树形结构对构建的本体进行可视化(如图8),以锅庄、堆谐两个舞蹈种类为根节点,然后对概念实例进行展示,对于每一个舞蹈概念,如果标注其属性则对舞蹈的属性进行展示。点击某一个具体的舞蹈实例,可以查看其具体信息,包括文本、图片、视频(如图8)。


图8:本体可视化树及具体信息展示
本系统通过文本标注及多媒体关联方法构建了超过具有1万多个实例及关系,2000多幅图片,500多段视频。通过树形结构,在使用树形结构进行表示时,使用异步加载技术进行数据的请求和展示,而加速可视化的速度。
由于本体中的概念实例数量超过了人浏览能力,本文引入了检索技术对本体中的概念、属性进行索引和检索。在本系统中本体检索使用Lu⁃cene[19]检索,首先对本体中各个域进行索引,对于检索到的结果按照概念实例进行排列,分别列出概念的属性及属性关系,关联的关键帧、视频片段,视频片段可以通过点击播放。
六、总结
本文提出了一种面向非物质文化遗产保护的非遗知识本体构建系统,首先给出了本文系统的总体架构,并且分别对系统中的三个模块的难点及解决方法进行了详细的叙述,分别解决了领域数据收集、领域分词、文本标注、多媒体关联等问题。在构建的本体基础上使用树形工具对本体进行可视化,并且集成了本体检索功能。本文使用本体构建系统以锅庄、堆谐两种西藏舞蹈为例,构建了实体数量超过1万条的本体,证明了本体系统的可用性以及其在非遗保护方面的有效性。
[参考文献]
[1]Studer R,Benjamins V R,Fensel D.Knowledge engineer⁃ing:principles and methods[J].Data Knowl Eng 25(1-2),Data & Knowledge Engineering,1998(25).
[2]邓志鸿,唐世渭,张铭,等.Ontology研究综述[J].北京大学学报(自然科学版),2002(5).
[3]Borst W N.Construction of engineering ontologies for knowl⁃edge sharing and reuse[M].Universiteit Twente,1997.
[4]Fellbaum C.WordNet[M].Blackwell Publishing Ltd,1998.
[5]Plant Ontology Consortium web site at http://www.plantontol⁃ogy.org.
[6]protégé开源软件网站,http://protege.stanford.edu/.
[7]The CIDOC CRM http://www.cidoc-crm.org.
[8]Surhone L M,Tennoe M T,Henssonow S F.CIDOC Concep⁃tual Reference Model[J].Archive2 Official,2010,40(5).
[9]Hyvönen E,Mäkelä E,Kauppinen T,et al.CultureSampo:A National Publication System of Cultural Heritage on the Se⁃mantic Web 2.0.[M]// The Semantic Web:Research and Appli⁃cations.Springer Berlin Heidelberg,2009.
[10]Hyvönen E.Semantic Portals for Cultural Heritage[M]// Handbook on Ontologies.Springer Berlin Heidelberg,2009.
[11]Collao Jr A,Díaz-Kommonen L,Kaipainen M,et al.Soft ontologies and similarity cluster tools to facilitate exploration and discovery of cultural heritage resources[C]//Database and Expert Systems Applications,2003.Proceedings.14th Interna⁃tional Workshop on.IEEE,2003.
[12]刘宏哲,鲍泓,余杰华.基于CIDOC CRM的虚拟博物馆语义网络架构[J].计算机应用研究,2006(4).
[13]肖婷.应用CDWA标准描述数字宋画作品的探索[J].图书情报工作,2011(9).
[14]常凌翀.新媒体语境下西藏非物质文化遗产的数字化保护与传承探究[J].西南民族大学学报(人文社会科学版),2011(11).
[15]马宁.论西藏非物质文化遗产的分类和传承保护[J].西藏民族学院学报(哲学社会科学版),2008(1).
[16]NLPIR汉语分词系统2013版。http://ictclas.nlpir.org/.
[17]刘群,张华平,俞鸿魁,程学旗.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004(8).
[18]FFmpeg is a complete,cross-platform solution to record,convert and stream audio and video.http://www.ffmpeg.org/.
[19]Lucene,The Apache Software Foundation http://lucene.apache.org.
[责任编辑王聪华]
[校对梁成秀]
基金项目:本文系西藏民族大学协同创新中心重点研究项目“西藏文化产业发展公共信息服务平台研究”(项目号:XT15037);国家科技支撑计划项目“虚拟旅游与文化资源协同系统研发与应用”(项目号:2012BAH33F00)的阶段性研究成果。
作者简介:黄永(1991-),男,山东菏泽人,现为武汉大学信息管理学院在读博士研究生,主要研究方向为信息检索、数据挖掘。
收稿日期:2015-12-16
中图分类号:G122
文献标识码:A
文章编号:1003-8388(2016)01-0020-07
