前后缀与特征词相结合的地名地址提取
2016-04-11王克永刘纪平
王克永,刘纪平,罗 安,王 勇
(1. 山东农业大学,山东 泰安 271018; 2. 中国测绘科学研究院,北京 100830)
前后缀与特征词相结合的地名地址提取
王克永1,2,刘纪平2,罗安2,王勇2
(1. 山东农业大学,山东 泰安 271018; 2. 中国测绘科学研究院,北京 100830)
Extracting Toponomy and Location Based on the Combination of Prefix and Suffix with Feature Words
WANG Keyong,LIU Jiping,LUO An,WANG Yong
摘要:随着地理信息与计算机技术的发展,网络中的非结构化地名地址数据越来越多,逐步成为地理信息更新的重要途径之一。针对互联网中地名地址的存在方式及结构特点,本文提出了一种前后缀与特征词相结合的地名地址识别提取方法。首先利用HMM训练进行分词,接着通过地名地址前后缀词库进行候选地名切分与预提取,最后根据特征词进行匹配过滤,实现对地名地址的准确提取。试验结果证明,本文方法提高了地名地址识别的准确率和召回率,很大程度上解决了未登录地址提取问题。
关键词:前后缀;特征词;HMM分词;地名地址
随着互联网技术的发展,多源网络中广泛存在数量庞大、种类繁多的新闻、报道、军事、生活信息,它们大多是文本数据,不容易被自动挖掘与提取。然而,蕴藏在文本中的地理信息不仅能为政府关注各类事件的分析、研究和决策提供支撑,而且还可以丰富地理信息的内容[1],可以利用GIS软件进行空间分析与应用[2]。目前,地理信息中地名地址搜索大多利用关键词[3-4]及其出现词频统计结果进行分析和应用,导致搜索数据存在模糊、歧义等问题,使地名地址识别的准确率降低。因此,从海量网络资源中抽取准确的地名地址信息显得格外重要。
地名地址识别是从文本数据中识别具有空间位置表达能力的地名地址要素,如带有行政区划的组织机构、门楼地址、餐饮、购物商场等。目前,国内外主要相关研究成果可以分为基于字典与统计的地名地址识别、基于规则的地名地址识别及基于机器学习的地名地址识别三方面。翟凤文等提出了一种字典与统计相结合的中文分词方法,提高了交集型歧义切分的准确率,并且在一定条件下解决了语境中高频未登录词问题[5];李宏波提出的分词词典和统计分析相结合的解决方案,合理解决了歧义词和未登录词两大难题[6];赵伟等结合规则和语料库统计两种分词方法进行分词[7];张雪英等以大规模地名词典和地址数据库为数据源,提出了中文地址的数字表达方式,提高了识别的准确率[8];马学峰分析了地名地址规律,整合了地名地址数据库[9];潘正高在构造内部规则和外部规则的同时,采用了概率统计的中文命名实体的识别方法[10];李丽双等提出了支持向量机(SVM)与规则相结合的中文地名自动识别方法,得到了SVM识别地名的机器学习模型[11]。
本文在研究国内外方法的基础上,根据前人提出的隐马尔可夫模型(HMM)进行语义训练与分词,将中文文本分成多个独立词语,并利用语义库提取的前后词缀对HMM分词结果进行候选地名地址的预提取,再结合构建的地名地址特征词库对候选地名地址进行匹配过滤。
一、地名地址识别提取
网络中涉及的地名地址具有种类繁多、样式复杂及未登录词出现频率高等特点,导致地名地址的提取难度大且识别精度低。结合网络中中文地名地址的上下文特征,本文提出一种基于前后缀的地名地址识别与提取方法,具体技术流程如图1所示。首先利用训练出的HMM对中文文本信息进行自动分词,将整个中文文本信息切分成若干个独立的词语;然后根据建立的地名地址前缀词库和后缀词库,对切分的文本信息进行前后缀匹配,从而将前后缀之间的文本提取出来作为候选地名地址,形成候选的地名地址库;最后通过构建的地名地址特征词库,对候选地名地址库进行一一比对和过滤,将其中不包含地名地址要素的文本信息剔除,实现中文地名地址的自动识别与提取,有效提高地名地址识别的准确率。
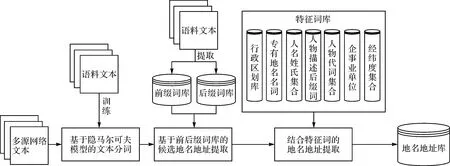
图1 地名地址识别流程
1.基于隐马尔可夫模型(HMM)的文本分词
前后缀词库中的词语涉及范围大,格式不统一,为了避免前后缀词将完整的地址进行切分,需要对网络文本信息进行分词预处理。本文采用隐马尔夫模型(HMM)对网络文本进行中文分词,将整个中文文本信息切分成若干个独立的词语,为下一步基于前后缀的候选地名地址提供基础。
隐马尔卡夫过程是一种双重随机过程,结合传统HMM的特征,本文利用海量网络地名地址文本信息对HMM参数进行自学习训练得到最佳分词参数,确保分词后地名地址的完整性。具体HMM描述与训练过程如下。
隐马尔夫模型是个五元组模型N、M、A、B、π,它们表现的意义分别是:
N={q1,q2,…,qN},表示状态的集合,地名地址识别中,有单字成词、词首、词中、词尾4种状态。
M={v1,v2,…,vM},表示观察值的有限集合。
π={πi},表示状态的初始概率。
A={aij},aij=P(qt=Sj|qt-1=Si),转移概率矩阵,本文中为S的4种状态之间的转换,理论上有42种转换,考虑到地名识别的实际情况,只有单字成词→单字成词、单字成词→词首、词首→词中、词首→词尾、词中→词中、词中→词尾、词尾→词首、词首→单字成词8种转移。
B={bjk},bjk=P(Ot=vk|qt=Sj),为观察值概率分布矩阵。
一般而言,A、B确定后,M与N也能够确定,因此给定一系列观察样本,从而可以将HMM描述为λ(π,A,B)模型,满足某种优化条件,使P(O|π)最大,具体重估迭代公式如下
2. 基于前后缀词库的候选地名地址预提取
在基于HMM分词的基础上,利用前后缀词库进行地名地址前后缀词语的队列匹配,即首先通过地名前缀词语进行词语的逐一匹配,然后根据与该前缀词语对应后缀词的权重进行地名地址后缀词的匹配,只有当前后缀词语完全匹配成功后,才将中间的文本信息串连起来,作为候选地名地址,最终形成候选地名地址库。
由于候选地名地址提取的准确性在很大程度上依赖于前后缀词库的丰富程度,因此本文采用大量网络文本信息作为语料库,利用常伴随地名地址同时出现的前缀词与后缀词的频率与词性,通过机器自学习的方式来自动丰富与完善地名地址前后缀词库(部分前后缀词库如图2、图3所示),并通过前后缀词词性与搭配情况,构建前后缀词库对应连接关系,即为前缀词所对应的后缀词赋予权重,提高后缀词匹配分词的速度与准确性,具体赋予权重公式如下


图2 前缀词库部分前缀词

图3 后缀词库部分后缀词
具体过程如下:本文以1998年1月一条新闻为例,首先去除语料库中每条新闻开始的时间(如19980101-02-003-003/m),以避免时间造成的误差;然后对专属名词与地名地址进行合并,有效统计地名地址的前后缀词词性及对应出现的频率;最后统计后缀词中相同词出现的频率,词性频率与词的频率相加作为前缀词确定下后缀词出现的权重。如“[那曲/ns 地区/n]ns”合并为“那曲地区/ns”,“[西藏/ns 自治区/n 政府/n]nt”合并为“西藏自治区政府/nt”,根据地址(ns)出现的位置提取前后缀,在“今晚/t 的/u 长安街/ns 流光溢彩/l”中,提取出地址“长安街/ns”的前缀是助词(u)“的”,后缀是习用语(l)“流光溢彩”。在提取的过程中,根据前缀助词(u)确定权重由大到小的后缀词,并依次匹配,直至匹配到出现的后缀词“流光溢彩”。
3. 结合特征词的地名地址提取
利用地名地址元素特征对上文形成的候选地名地址库中地名地址逐一进行匹配,剔除未包含地名地址要素及不符合地名地址构词规则的噪音信息,提取包含地址元素特征词的地名地址,确保地名地址识别与提取的正确性与效率,主要包括特征词提取与特征词过滤。
(1) 特征词提取
1) 候选地名地址中包含行政区划要素的则作为地名地址信息,具体公式为:AdminLib[i]∈Loc(wait)⟹Loc(y),其中AdminLib为行政区划库(精确到村级),如北京、济南、海淀等,i为集合中的一个元素;Loc(y)为地名地址集合。
2) 提取包含专有地名名词的候选地名地址作为地名地址:Loclist[i]∈Loc(wait)⟹Loc(y),其中Loclist为专有地名名词集合,如河流、湖泊、道路等。
3) 候选地名地址中含有经纬度信息的作为地名地址:Lonlat[i]∈Loc(wait)⟹Loc(y),其中Lonlat[i]为经纬度词,如东经、北纬、西经、南纬。
4) 含有企事业单位特征词的候选地名地址作为地名地址:Unit[i]∈Loc(wait)⟹Loc(y),其中Unit[i]为企事业单位词,如公司、学校、客运站、展览馆、银行等。
(2) 特征词过滤
1) 含有姓氏且含有人物描述词的候选地名地址判断为非地名地址:Familyname[i]∈Loc(wait)&&Figurelist[i]∈Loc(wait)⟹Loc(n)[11],其中Familyname为人名姓氏集合,如赵、钱、孙等;Figurelist为人物描述后缀词,如女士、先生、叔叔、阿姨等;Loc(n)为非地名地址集合。
2) 候选地名地址中既含有人物代词也含有人物描述后缀词的被判断为非地名地址:Pronlist[i]∈Loc(wait)&&Figurelist[i]∈Loc(wait)⟹Loc(n),Pronlist为人物代词集合,如你们、我们、他等。
二、试验与结果分析
由于新华社网站的新闻具有权威、报道精准、传播范围广、涉及范围大等优势,本文选取新华社网站上的新闻文本作为试验数据,利用Web爬虫技术,采集新华社网站的1200条数据记录。同时为了验证本文提出方法的有效性和优越性,试验将基于本文提出的方法与HMM分词方法进行对比,并将试验数据进行人工判读,最终采用召回率R、准确率P、F值(F-Measure)来反映本文方法和HMM分词方法的区别,具体计算公式如下
本试验将1200条数据分为300条、600条、900条、1200条4种样本进行对比试验,采用前缀词1483个,后缀词2312个,企事业单位特征词204个,专有地名名词138个,姓氏名词4100个,人物描述后缀词86个,人物代词52个,行政区划库数据精确到村级,试验结果见表1。试验结果显示,1200条新闻信息时,本文提出的方法准确性为92.11%,召回率达到89.13%,F值达到90.60%,其中F值对比如图4所示。

表1 两种方法对比 (%)

图4 4种样本识别F值对比图
本文方法对地名地址识别的准确率和召回率都高于HMM分词方法。通过分析发现,其原因是在地名地址识别时,对于出现频率不高的词语,HMM分词方法学习度不够,从而引起错分,而本文方法经过前后缀预提取与特征词匹配过滤后,可以有效地将错分地址组合到一起,并提取出来。同时,为了测试方法的应用效果,本方法已经在基础地理信息更新中得到了相应的应用,通过识别并提取网络上地理信息网站发布新闻中的地名地址数据,实现对地理信息数据库中的原始数据更新,系统如图5所示。
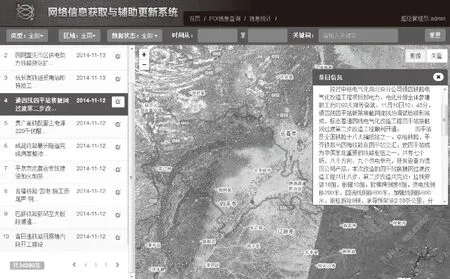
图5 地名地址提取与定位效果
三、结束语
本文提出了前后缀与构词规则相结合的地名地址识别方法,充分考虑了网络地名地址前后缀词库及未登录词的结构特征,利用训练的HMM分词技术,实现了地名地址的自动识别与提取,提高了地名地址的识别准确率、召回率,最后通过与传统地名地址识别方法的对比试验,验证了本文方法的有效性,并将本方法应用在基础地理信息更新领域。
参考文献:
[1]刘纪平,张福浩,王亮,等.电子政务地理信息服务[M].北京:测绘出版社,2014:136.
[2]马照亭,李志刚,孙伟,等.一种基于地址分词的自动地理编码算法[J].测绘通报,2011(2):59-62.
[3]曾文,鄢军霞.城市GIS地名定位工具的设计及应用[J].地球科学:中国地质大学学报,2006,31(5):725-728.
[4]王平,薄正权.地名地址数据采集方法与实践[J].城市勘测,2013(2):54-57.
[5]翟凤文,赫枫龄,左万利,等.字典与统计相结合的中文分词方法[J].小型微型计算机系统,2006,27(9):1766-1771.
[6]李宏波.词典与统计相结合的中文分词算法研究[J].武汉理工大学学报(信息与管理工程版),2010,32(6):907-913.
[7]赵伟,戴新宇,尹存燕,等.一种规则与统计相结合的汉语分词方法[J].计算机应用研究,2004,21(3):23-25.
[8]张雪英,闾国年,李伯秋,等.基于规则的中文地址要素解析方法[J].地球信息科学学报,2010,12(1):9-16.
[9]马学峰.湛江市地名地址数据库设计与实现[J].测绘通报,2014(S1):288-291.
[10]潘正高.基于规则和统计相结合的中文命名实体识别研究[J].情报科学,2012,30(5):708-712.
[11]李丽双,黄德根,陈春荣,等.SVM与规则相结合的中文地名自动识别[J].中文信息学报,2006,20(5):51-57.
[12]陈玉萍,张秀. 地名地址普查与建库研究[J]. 测绘通报,2015(6):103-107.
[13]数字城市地理信息公共平台地名/地址编码规则.中华人民共和国行业标准:GB/T 23705—2009[S].北京:中国标准出版社,2009.
[14]邹崇尧,朱贵方,赵双明. 基于搜索引擎技术的地名地址定制查询研究[J]. 测绘通报,2014(8):92-94.
[15]李荣,胡志军,郑家恒.基于遗传算法和隐马尔可夫模型的web信息抽取的改进[J].计算机科学,2012,39(3):196-199.
中图分类号:P208
文献标识码:B
文章编号:0494-0911(2016)02-0064-05
作者简介:王克永(1990—),男,硕士生,主要从事3S技术集成与应用。E-mail: yongkewang@126.com
基金项目:国家863计划(2012AA12A402;2013AA12A403);中国测绘科学研究院基本科研业务费(7771403)
收稿日期:2015-01-27; 修回日期: 2015-11-06
引文格式: 王克永,刘纪平,罗安,等. 前后缀与特征词相结合的地名地址提取[J].测绘通报,2016(2):64-68.DOI:10.13474/j.cnki.11-2246.2016.0050.
