基于CRFs的哈萨克语名词短语自动获取
2016-01-19孙瑞娜a新疆财经大学a统计与信息学院社会经济统计研究中心乌鲁木齐830012
●孙瑞娜a,b(新疆财经大学a.统计与信息学院,b.社会经济统计研究中心,乌鲁木齐 830012)
基于CRFs的哈萨克语名词短语自动获取
●孙瑞娜a,b(新疆财经大学a.统计与信息学院,b.社会经济统计研究中心,乌鲁木齐830012)
[关键词]哈萨克语;名词短语;互信息;条件随机场
[摘要]基于哈萨克语文本语料特点,分析名词短语构成规则,结合互信息(MI)知识,建立了哈萨克语名词短语特征模板,利用条件随机场(CRF)模型实现哈萨克语名词短语自动获取。实验表明,哈萨克语名词短语获取正确率达到95.2%,获取性能高于基于规则、基于规则与互信息结合的抽取方法。
随着web2.0的迅速发展,互联网成为民众获取信息的重要来源,同时也是人们传播信息和表达观点的重要渠道。民众通过网络平台对国家政策或突发事件发表意见,及时对这些评论信息进行有效处理分析,可以帮助决策者了解社情民意。
网络评论文本由句子组成,表示句子语义的主要成分是主语、谓语和宾语。在进行评论文本主题识别时,主语和宾语是识别文本主题的关键因素,而主语和宾语的用词中名词和名词短语是语义表达的主题,也是评论文本主题识别研究中的一个重要特征。本文结合哈萨克语名词短语构成规则,以互信息(MI)为工具,利用规则和条件随机场(CRF)结合的方法,针对哈萨克语评论文本中名词短语的自动获取,辅助后期进行哈萨克语网络舆情分析中web评论文本主题识别的研究工作。
1 需求及技术思路
1.1研究现状
目前,英语、汉语等语言的信息处理在理论方法和具体应用上已经有了大量研究成果。大多数学者对短语的识别都是在语料库的基础上进行的,有基于规则、统计、规则和统计集成三种识别方法。Church[1]较早展开了英语名词短语的识别,将英语的基本名词短语识别问题转换为和词性标记同构的问题,并利用基于词性标记N元同现的统计最优法来实现识别;文献[2]在Church的研究基础上,采用了基于转换的错误驱动学习方法来解决基本名词短语抽取问题,并得到了召回率88%的实验结果;文献[3]利用最大熵方法进行日语实体名词抽取;文献[4]利用基于韩语名词短语左右边界规则的方法,在语料库中抽取名词短语;文献[5]结合基于支持向量机与基于条件随机场的方法进行汉语最长名词短语识别;文献[6]结合语料特点,对“N1+N2”型结构的名词短语进行特征分析;文献[7]利用短语结构构成特征与清华树库语料短语特征混合方法,提高短语识别率。查阅近年来国内外的重要文献,哈萨克语在名词短语自动获取已经有了前期的研究工作,但是识别的正确率与其他语言相比还较低。
哈萨克语属于阿尔泰语系突厥语族的克普恰克语支,书写方式是从左到右,语法结构理论上有四种排列,即SOV、SVO、OSV、OVS,通常用SOV(主+宾+谓)结构确定句子词序和语类,这与汉语词序有很大不同,并且哈萨克语是黏着语言类型,形态结构比汉语、英语复杂。同时,哈萨克文没有像汉语、英语中建立好的语义网,因此,对哈萨克语名词短语的自动获取与汉语、英语相比更困难。
1.2需求分析
哈萨克语名词短语是一种重要的组块类型,其自动获取对文本语义理解、信息检索、网络舆情分析等领域都有重要意义。在对Web评论文本进行主题识别过程中,能否准确的获取其中的名词短语起着重要的
作用。虽然哈萨克语名词短语自动获取已经有了前期的研究工作,如文献[8]使用基于规则的方法进行了探讨,封闭测试准确率为80%;文献[9]等利用N-gram和互信息相结合的方法实现了哈萨克语名词短语的抽取,封闭测试准确率82.5%,但是识别的正确率与其他语言相比还较低。因此,为避免名词短语获取的错误累积对后期网络舆情分析中Web评论文本主题识别等研究工作的影响,需要进一步提高哈萨克语名词短语获取的正确率。
1.3技术思路
哈萨克语名词短语自动获取的具体实现思路如图1所示。(1)将从网站获取的哈萨克语版网页中的评论文本,进行去噪处理,仅保留哈萨克语文本,按照哈萨克语句子结束的标点符号对文本进行自动分句。(2)采用新疆大学的哈萨克语词干切分、词缀提取及词性标注系统,将文本进行词干切分及词性标注,保存为XML文档。(3)分析哈萨克语文本语料特点,归纳名词短语构成规则,结合互信息知识,建立哈萨克语名词短语特征模板,利用条件随机场模型最终实现哈萨克语名词短语的自动获取。
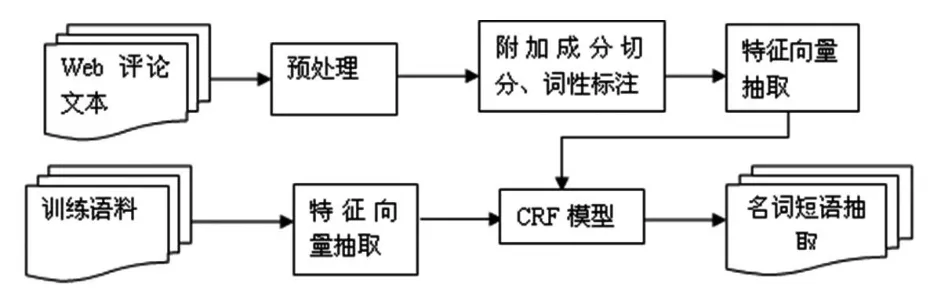
图1 技术思路
2 实现方案
2.1哈萨克语名词短语自动获取
正确判断评论文本的倾向性,需要先确定文本的主题,而名词短语是评论文本主题识别研究中的一个重要特征,高效的名称短语自动获取技术,能有效降低人工标注的工作量。本文通过分析哈萨克语文本语料特点,归纳名词短语构成规则,将规则与CRFs模型相结合,并将互信息知识作为CRFs模型中的一个特征属性,建立了哈萨克语名词短语识别特征模板,实现哈萨克语名词短语自动获取。
(1)条件随机场模型。条件随机场(Conditional Random Field,CRF)是Lafferty等[10]提出的一种用于序列数据标注的条件概率模型。其原理是:给定的数据序列随机变量X,标注结果序列随机变量Y的条件概率分布P(Y|X),要求条件概率P(Y/X)最大。令x={x1,x2……xn}表示输入的需要标注的观察序列集,y={y1,y2……yn}表示标注序列集。在给定观察序列条件下的标记序列的概率可以写成:

其中,每个fk是观察序列x中位置为i和i-1的输出节点的特征;每个gk是位置为i的输入节点和输出节点的特征;λ和u是特征函数的权重;Z(x)是归一化因子。对于输入句子的词语序列x,最佳名词短语标注序列y满足如下公式

CRFs建模时,能够充分地利用上下文信息作为特征,特征选择灵活,移植性强,获取的信息丰富,广泛应用于序列标注,词性标注[11]、语块识别[12]等问题,取得令人满意的结果。
(2)基于CRFs的哈萨克语名词短语的语法规律。在利用CRFs模型进行哈萨克语名词短语获取时,特征模板的选取是名称短语获取的关键,而CRFs模型特征模板的设计来源于语言的语法规律。因此,结合《现代哈萨克语实用语法》[13]知识,通过观察大量名词短语以及上下文后,总结出了哈萨克语名词短语的一般规律。
①短语特征规律。哈萨克语的词序与汉语词序有很大不同,通常用SOV(主+宾+谓)结构确定句子词序和语类,其最基本的短语规则为:Rule:IP→SI,S→KP VP,KP→NP K,VP→KP V。其中:S-句子,KP-格短语,NP-名词性短语,VP-动词性短语。例如:(我们学校明天开课)(我们的学校)是由代词和名词构成的名词性短语NP(在汉语中是偏正短语),(我们的学校开课)是由名词短语和动词构成的动词性短语VP(在汉语中是主谓短语),(明天开课)是由副词和动词构成的动词性短语VP(在汉语中是偏正短语),因此哈语名词短语获取需要结合该短语结构特点。
②词的构成特征规律。哈萨克语作为一种典型的黏着性语言,单词是通过在词干后按一定的顺序连接各种词缀(又称构形附加成分)来构成的,如(在你们的班里)是由词干(班)和附加成分构成的。这种特征规则可以有效识别哈萨克语的名词短语,因此,本文归纳了对识别名词短语有帮助的部分名词构形附
加成分,并将其作为CRFs模型的一个特征属性。部分名词构形附加成分见表1。

表1 名词构形附加成分
③名词搭配结构规律。哈萨克语的名词短语,中心词多为名词。该规律可以分为五种搭配结构。第一种,名词和名词搭配,如:新疆日报;第二种,数量词和名词搭配,如:一首诗歌;第三种,动词和名词搭配,如:要讲的话;第四种,形容词和名词搭配,如:明亮眼睛;第五种,以副词与形容词修饰,中心词为名词的搭配,如:非常困难的任务。因此,该规律能够作为名词短语发现的特征在CRFs模型中使用。
④连接词所连接的并列结构规律。以连接词所连接的并列结构多为名词短语,如:连接词所连接的形容词结构高而且美观;连接词所连接的名词结构:新疆和甘肃。该规律可以作为名词短语获取特征。
(3)特征模板定义。依据对哈萨克语语料中名词短语特征的分析,本文选择了常用的特征:词(word)、词性(pos)、构形附加成分(affix)、互信息(MI)来进行CRFs模型的模板定义。
互信息是用来度量一个集合中两个事件之间的相互依赖程度的信息度量单位,二元互信息是两个事件的概率的函数,公式如下
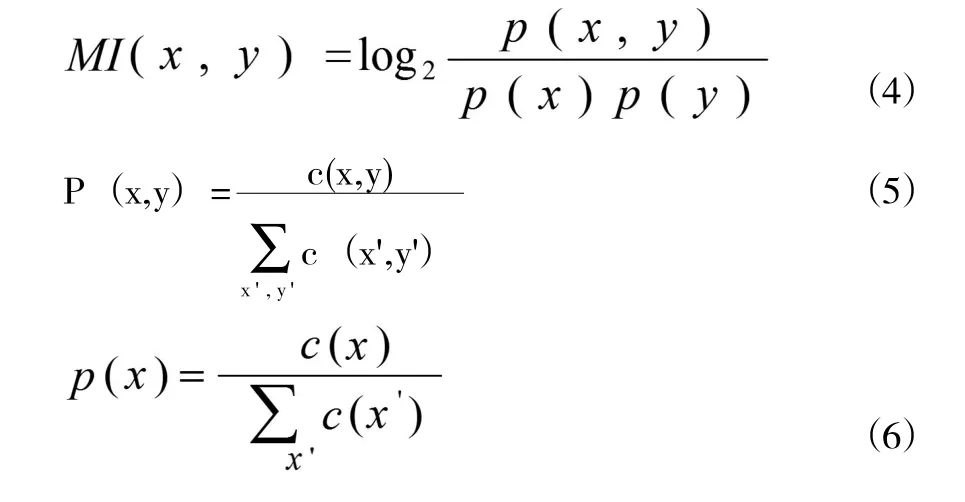
c(x,y)指语料中,词x和词y的共同出现的频率,c(x)指词x在语料库中出现的频率。通过对c(x, y)和c(x)的统计,利用互信息公式(4)计算词与词之间的互信息。如果词x和词y结合非常紧密,互信息就越大,反之越小。通过互信息特征可以判断该类字串组是否可以拆分标记。
结合哈萨克语名词短语的规律,制定了实验中使用基于CRFs的四类特征模板。在词序选择上,重点考虑当前词以及其前后两个词内的词序列,即当前词word(0)、当前词前1个词word(-1),当前词后1个词word(1),当前词前第2个词word(-2),当前词后第2个词word(2),具体设计见表2。

表2 特征模板示例
①词性搭配特征模板。名词短语与其词语的词性特征高度相关,可以得到特征模板:当前词词性与其相关的前后词的词性。如特征模板pos(-1)pos (0),pos(0)pos(1),pos(-1)pos(1);当前词词性与其前后各1个词词性pos(-1)pos(0)pos(1);当前词词性与其前1,2个词词性、与后面1,2个词词性pos(-2)pos(-1)pos(0);pos(0)pos(1)pos(2)。
②词和词性搭配特征模板。以当前词为中心,抽取与其相关的前后词及词性。如当前词与其前后各1个词的词性pos(0)word(0)pos(1);当前词与前1个词词性pos(-1)word(0)、当前词与后1个词的词性,word(0)pos(1)等。

③词性和构形附加成分搭配特征模板。哈萨克语词的构形附加成分对名词短语的识别有一定帮助,抽取当前词性与前后词的词性及附加成分,可以得到特征模板,如:当前词的词性及附加成分、前1
词的词性pos(-1)pos(0)affix(0);当前词的词性、后1词的词性及附加成分pos(0)pos(1)affix(1);当前词的词性、前1词的词性及附加成分affix(-1)pos(-1)pos(0)等。
④词和词之间的MI值搭配特征模板。词和词之间的MI值可以衡量词和词结合的紧密程度,能判断该字串组是否可以拆分标记为名词短语,为此定义特征模板为:当前词与前1词及二者的MI值MI(-1)word(-1)word(0);当前词与后1词及二者的MI值word(0)word(1)MI(1)。
3 系统实现
采用C#语言,改写CRF工具包,整理语料进行哈萨克语名词短语的抽取。系统主要包括三个模块。
(1)语料预处理模块。进行名词短语识别前需要先对识别文件进行预处理工作,将语料组织成符合识别模块接口标准的形式。将从网站获取的哈萨克语版网页中的评论文本,进行去噪处理,仅保留哈萨克语文本,按照哈萨克语句子结束的标点符号对文本进行自动分句。采用新疆大学的哈萨克语词干切分及词性标注系统,将文本进行词干切分、词缀的提取及词性标注,保存为XML文件,具体格式见图2。

图2 XML文件
(2)训练模块。通过定义的四类特征模板对语料库文本进行特征抽取,建立特征集,利用CRFs模型对特征集合进行训练,计算特征权值并进行保存。
(3)识别模块。识别模块的主要任务是对一条待识别名词短语的哈语句子,给出对应的名词短语标注序列,本实验采用IB02的表示方法进行名词短语抽取标识,将每个词分为三类标记:“B”名词短语首部、“I”名词短语内部、“O”名词短语外部,对测试语料中的每个词进行BIO标注,即输出y∈{B,I,O}。识别结果见图3。
4 应用效果评估
4.1实验过程
实验语料主要来自天山网、人民网的哈萨克文版以及一些大型的哈萨克文BBS网站,内容涵盖新闻、文学、生活等,充分保证了语料的多样性。对网页中的文本进行去噪处理,仅保留哈萨克语文本,将获取的335个评论文本,进行词干切分、词缀提取及词性标注,保存为XML文档,再利用文献[8]基于规则的方式对语料文档进行名词短语标注,后期人工校正。

图3 名词短语识别结果
将整理后的语料分为训练语料和测试语料进行名词短语的抽取,实验采用5倍交叉验证的方法,即将语料分为相等的5份,其中4份作训练语料,1份作测试语料进行名词短语获取实验。首先在训练模块用训练语料对CRFs模型进行训练,然后在识别模块自动标注测试语料中的名词短语。CRFs的特征模板采用上表2所示的4类特征模板。
4.2实验结果
对名词短语识别的实验结果进行评估时,有三个重要的评测指标,分别是正确率、召回率和F值,定义如下

其中a指名词短语正确获取的个数,b指名词短语错误获取的个数,d指未获取的名词短语个数。实验结果见表3。

表3 实验结果
从结果来看,实验达到了较满意的效果,目前获取方法的正确率与汉语、英语等语言的名词短语在封闭测试下自动获取的正确率基本接近,达到了95.2%,但相比其他语言实验结果获取的召回率较低,尚需进一步提高。
4.3实验比较
将文献[8]、文献[14]所进行的名词短语识别的实验过程重现,进行封闭测试,并与本文中的实验
结果进行比较,结果见表4。

表4 实验数据比较
从表4可以看出,在使用相同语料的情况下,进行封闭测试,本实验采用的规则和CRFs结合的方式,实验结果的正确率高于基于规则方法,高于基于规则和互信息结合的方法,达到95.2%。
4.4实验分析
从以上实验结果来看,名词短语获取的方法是有效的,正确率提高到95.2%,但目前获取方法的召回率较低,尚需进一步提高。对名词短语获取模型的错误结果进行分析,便于将来进一步改进。(1)在CRFs模型中,抽取所用的特征:词性和构形附加成份,在目前语料库加工中存在标注及切分的错误,对实验有一定影响,后期需要修正语料库错误。(2)在特征选择上,后期还可以借助更丰富的信息,如结合语义等信息。(3)实验所用的语料是需要人工校对,由于精力有限,使得名词短语获取的语料规模有限,这也使得统计不够全面。
[参考文献]
[1]ChruchKW.AStochasticPartsProgramand Noun Phrase for Unrestricted Test:proceedings of the 2nd Conference on Applied Natural Language Processing,Austin,TX [C].USA:Kluwer Academic Publicshers,1988:136-142.
[2]Ramshaw L,Marcus M.Text Chunking Using Transformation-Based Learning[C]//Proceedings of 3rd Workshopon Very Large Corpora.Massachusetts:Association forComputational Linguistics,1995:82-94.
[3]K Uehimoto,et al.Named entity extraction based on a maximum entropy model and transformation rules[C]//Proceedingsof the38th Annual Meeting ofthe AssociationforComputational Linguistics,2000:326-335.
[4]安帅飞,毕玉德.韩国语名词短语结构特征分析及自动提取[J].中文信息学报,2013,27(5):205-210.
[5]钱小飞,侯敏.基于混合策略的汉语最长名词短语识别[J].中文信息学报,2013,27(6):16-22.
[6]刘志杰,等.搜索引擎日志中“N1+N2”型名词短语研究[J].现代图书情报技术,2010,26(12):58-63.
[7]谢靖,等.CSSCI语料中短语结构标注与自动识别[J].现代图书情报技术,2012(12):32-38.
[8]孙瑞娜,古丽拉·阿东别克.基于规则的哈萨克语基本名词短语识别研究[J].计算机应用研究, 2010,27(12):4511-4513.
[9]Gulila Altenbek,Ruina Sun.Kazakh Noun Phrase Extraction based on N-gram and Rules:2010 International Conferenceon Asian Language Processing[C].Harbin,Heilongjiang,China:IEEE computer society,2010:305-308.
[10]Lafferty J.et al.Conditional Random Fields:ProbabilisticModelsfor Segmentingand Labeling Sequence Data[C]//Proceedings of the 18th International Conf on machineLearning,2001:282-289.
[11]S Lakshmana Pandian,T V Geetha.CRF Models for Tamil Part of Speech Tagging and Chunking[C].International Conferenceonthe Computer Processingof Oriental Languages-ICCPOL,Hong Kong,2009:11 -22.
[12]He Saike,et al.Multi-task learning in conditional random fields for chunking in shallow semantic parsing [J].PACLIC23-Proceedings of the 23rd Pacific Asia Conferenceon Language,InformationandComputation,2009,1:180-189.
[13]张定京.现代哈萨克语实用语法[M].北京:中央民族大学出版社,2004:98-167.
[14]孙瑞娜,古丽拉·阿东别克.哈萨克语基本名词短语自动识别研究与实现[J].中文信息学报. 2010,24(6):114-119.
[收稿日期]2014-10-27 [责任编辑]刘丹
[作者简介]孙瑞娜(1982-),女,新疆财经大学讲师,研究方向:网络舆情,信息检索。
[基金项目]本文系国家自然科学基金项目“基于网络社群的网络舆情演化分析及突发事件预警机制研究”(项目编号:71261025),新疆财经大学社会经济统计研究中心项目“新疆互联网舆情倾向性调查与分析研究”(项目编号:050313C08),“新疆区情民意网络调查系统设计与网络舆情调查分析”(项目编号:050312C08),新疆财经大学校级科研基金项目“基于统计方法的新疆民文网络舆情情感倾向性分析技术研究”(项目编号:2013XYB005)阶段性成果之一。
[文章编号]1005-8214(2015)08-0101-05
[文献标志码]B
[中图分类号]TP391.1;G254.29
