Stolt插值在多核多DSP上并行实现∗
2016-01-10梁之勇
梁之勇
(1.中国电子科技集团公司第三十八研究所,安徽合肥230088;2.数字阵列技术重点实验室,安徽合肥230088;3.孔径阵列与空间探测安徽省重点实验室,安徽合肥230088)
0 引言
ωK算法的主要流程包括二维傅里叶变换、参考函数相乘,距离频域Stolt插值、二维傅里叶逆变换,Stolt插值完成了残余距离徙动校正、残余二次距离压缩、残余方位压缩,这样便实现了所有目标的聚焦。
Stolt插值是双精度运算,同时随着测绘带变大,128K点甚至更大点数插值也越来越多。传统单核DSP在片内内存、运算能力、数据吞吐等方面的能力不足问题也随之出现。TI公司新推出的多核DSP TMS320C6678可以有效地解决Stolt插值的处理瓶颈。
1 理论分析
设照射区某点目标到飞行航迹垂距为R x,则对回波信号进行两维傅里叶变换后的回波相位[2]
可表示为
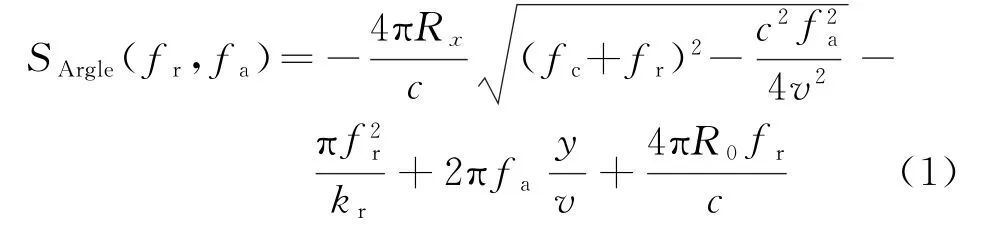
式中,v为平台飞行速度,fc为雷达中心频率,fr为距离向频率,fa为方位向频率,y为目标方位位置,c为光速,R0为雷达采集起始距离。
对式(1)进行参考距离函数补偿,补偿函数相位可表示为
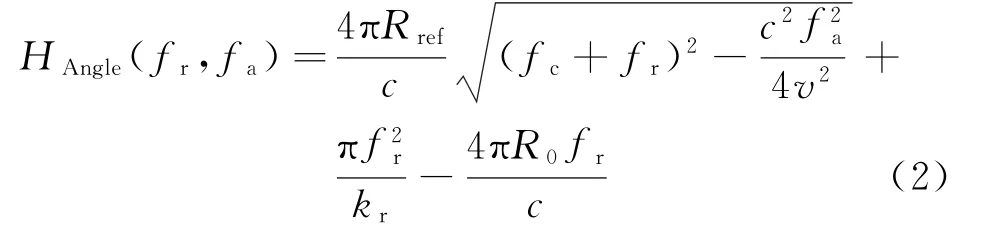
补偿后的信号为
半年末,我们对下半年的市场进行展望,发布了《逢八魔咒难逃 下半年如何应对》的封面文章。彼时我们认为,上半年尤其是二季度市场的暴跌情形,除了有国内去杠杆紧信用的负面因素在里面,更多是受中美贸易摩擦的影响,外患大于内忧的背景下,我们给出了“关注内需桃花源 现金流佳好种田”的观点,并提出三个配置思路,一是规避中美贸易战的不确定性,寻找内需板块的确定性;二是选择现金流良好的公司;三是关注海外资金配置A股的方向。这些方向上的主要标的集中在上证50中,而后者在三季度的表现为5.11%,显著跑赢大盘。
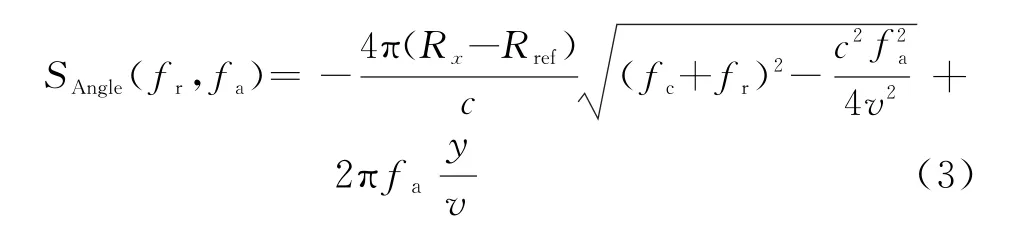
对不同的fa,通过对数据进行Stolt插值,可将信号变换成关于f′r的线性函数,即
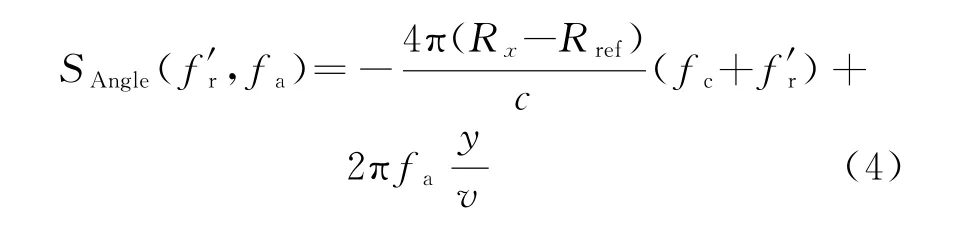
fr为距离向频率向量,为非线性向量。f′r为插值后距离向频率向量,为线性向量。两者关系为
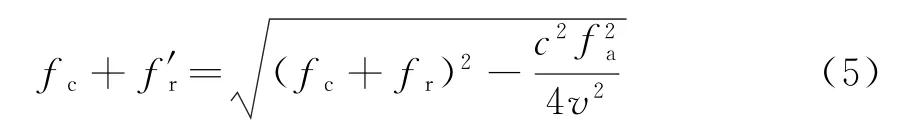
常规成像只需将式(4)作两维逆傅里叶变换就可得到该目标的两维脉冲压缩响应。因此可以看出Stolt插值是ωK算法的核心。
2 多核多DSP上设计实现
随着分辨率、作用距离、测绘带宽等指标越来越高,系统计算量也越来越大,而Stolt插值为双精度复杂运算,所需要的计算时间也大大增加。传统的SAR成像处理器ADSPTS101、ADSPTS201等已经不能满足系统实时性要求[3]。TI公司新推出的C6678,该芯片内部有8核,运算能力强,主要性能[4-5]如下:
1)C6678单片处理能力:内核主频最高1.25 GHz,浮点运算能力达到160 GFlops;
2)内部存储资源:单片C6678每核内置32KB L1P、32KB L1D、512KB L2,同时8个内核共享4MB L3SRAM;
3)外设接口:SRIO接口可以支持4个1X、2个2X、1个4X,每一个通道最高速率5 Gbit/s,PCIe接口有2个通道,每个通道最高速率支持5 Gbit/s;Hyper Link接口有4通道,支持的带宽高达50 Gbit/s。
2.1 硬件平台介绍
本文采用的基于C6678的通用信号处理硬件平台如图1所示。
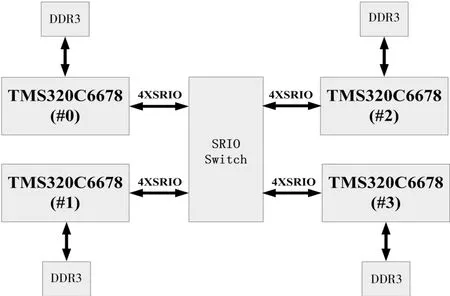
图1 TMS320C6678通用信号处理平台
该信号处理平台单板主要性能如下:
1)定点处理能力达到1280 GMACs、浮点处理能力最高640 GFlops;
2)单板外挂32GB DDR3;
3)SRIO:Switch实现4个6678的SRIO之间的交换。
2.2 任务分配
在一个成像孔径内距离向处理点数为Ran-Lenth,方位向处理点数为Azm Lenth。Stolt插值在距离向操作,同时方位向之间没有耦合,因此4片C6678按照方位向平均分配任务,每片DSP的8核按照距离向分配任务,如图2所示。具体如下:DSP0处理0~1/4Azm Lenth,DSP1处理1/4~1/2Azm Lenth,DSP2处理1/2~3/4Azm Lenth,DSP3处理3/4~1Azm Lenth。DSP片内8核按距离向任务分配如下:核0处理0~1/8Ran Lenth,核1处理1/8~2/8Ran Lenth,核2处理2/8~3/8Ran Lenth,核3处理3/8~4/8Ran Lenth,核4处理4/8~5/8Ran Lenth,核5处理5/8~6/8Ran Lenth,核6处理6/8~7/8Ran Lenth,核7处理7/8~1Ran Lenth[6]。通过上述任务分配实现了多核多DSP并行处理,极大地提高了系统实时性。

图2 4 DSP任务分配
2.3 内存分配
为了提高实时性,所有计算变量、缓冲均存放在片内RAM上,L3有4MB,空间分配如表1所示,从内存分配可以看出最大能支持128K复数点Stolt插值。

表1 L3内存分配
L2有512KB,主要存放插值缓冲区,及插值后频率向量,由于L2是各核独有的,因此每核只需要插值点数的1/8存储空间,具体分配如表2所示。

表2 L2内存分配
2.4 程序设计
按照任务分配,一条距离线的Stolt插值由8个核同时完成。插值流程是首先将输出分成8段,计算每段输出频率范围,为保证分段插值结果正确,输入频率范围至少要等于输出频率范围;然后根据输入频率范围和输入每点频率计算各核插值起始点和插值结束点位置;最后将各核对应起始点和结束点适当扩大,输入频率范围便大于输出频率范围,以保证交界处插值结果正确性。8核Stolt插值计算流程如图3所示。
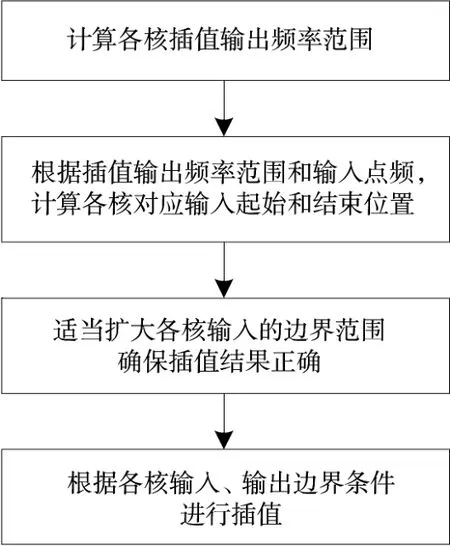
图3 8核Stolt插值流程
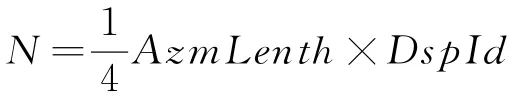
3 实验结果
3.1 并行DMA CHAIN设计效率分析
Stolt插值测试环境:DSP主频1 GHz,DDR3时钟700 MHz,距离向8 192点插值。表3为插值时间。从图中可以看出8核并行插值运算时间需要31 795时钟周期,取数据时间为11 612时钟周期,存数据时间为11 620时钟周期。没有DMA CHAIN完成插值总时间为55 027时钟周期。采用DMA CHAIN技术后时钟周期为32 395时钟周期,比插值计算时间略多,主要是因为DMA配置和启动需要一些时钟周期数。前者时间较长主要是因为取数、计算、存数整个流程是串行的,后者在采用DMA CHAIN技术后存取数和计算是并行的,时间性能提高了41.13%。因此DMA CHAIN技术有效地提高了插值的实时性。
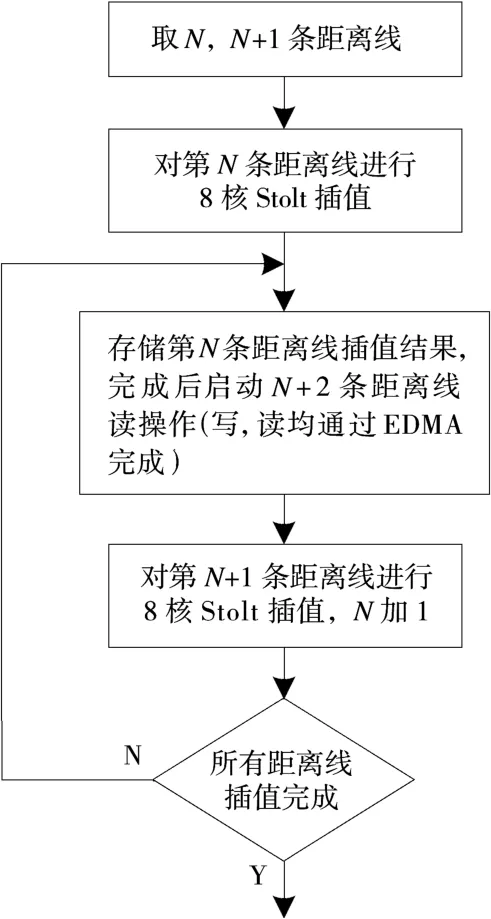
图4 DSP计算流程

表3 插值时间分析
3.2 多核Stolt插值结果分析
在Stolt插值多核分段的具体实现中,相邻分段之间如何处理,是一个需要特别关注的问题。正常情况下多核任务分配是将输入、输出平均分成8段进行插值,程序中距离向处理点数为8 192点,输入频率为0到8 191线性递增,输入幅值为对应频率的一半,输出频率向量根据式(5)计算得到,这样便可通过Stolt插值计算输出的幅值。该情况下插值结果如图5所示,可以看出部分插值结果有异常值。图6为局部放大图,从图中可知第1024点插值结果为0,该点是核0和核1分段交界处。图5中插值异常值均出现在核间交界处。原因是将输入、输出平均分8段来计算,输入输出处理的点数一样,但是输入和输出每点频率不一致导致输入输出频率范围不对应,导致各核交界处插值结果有误。
本文采用的方法是将输出分成8段,程序自动计算输入范围。插值结果如图7所示,各核交界处的插值结果均已正确。
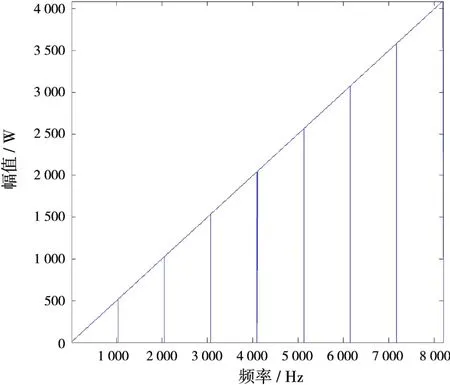
图5 8核插值结果
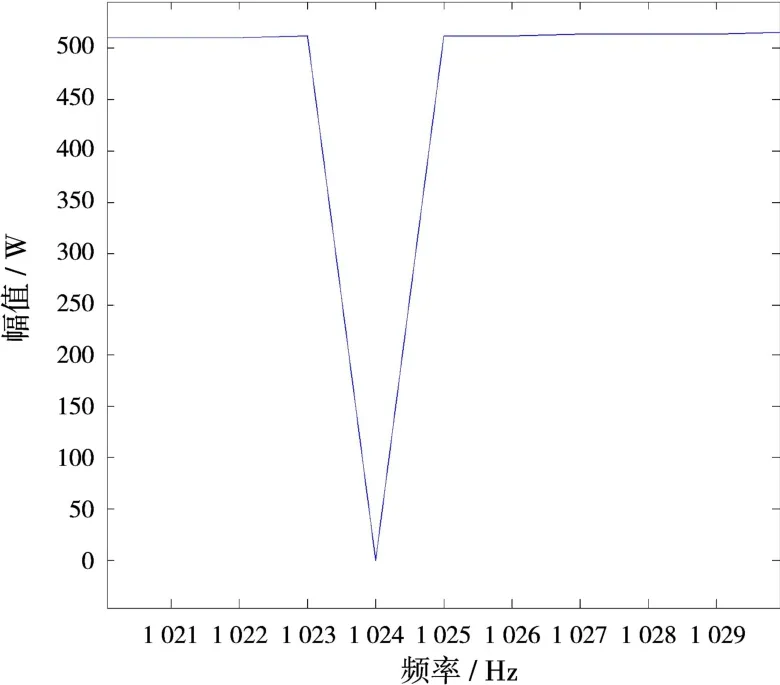
图6 插值结果局部图
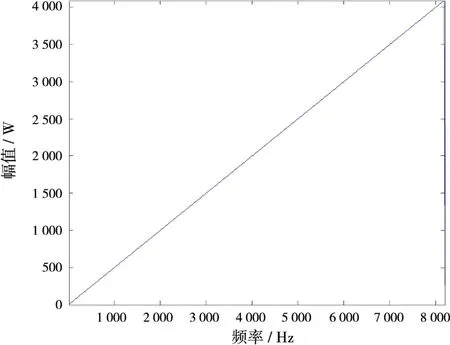
图7 改进后8核插值结果
4 结束语
随着SAR向大测绘带和高分辨率发展,ωK成像算法核心Stolt插值对计算量和计算精度要求越来越高,传统DSP面临处理能力不足的问题。本文采用了 TI公司新推出的DSP TMS320C6678,该DSP内置8核,浮点运算能力达到160 GFlops。文中从任务分配、内存分配、程序实现三个方面论述了Stolt插值多核多DSP并行实现,同时采用DMA CHAIN技术使Stolt插值实时性得到提升,为解决SAR成像实时处理的瓶颈提供了一种可行的方案。
[1]刘燕,孙光才,邢孟道.大场景高分辨率星载聚束SAR修正ω-k算法[J].电子与信息学报,2011,33(9):2108-2113.
[2]CUMMING I G,WONG F H.合成孔径雷达成像:算法与实现[M].洪文,胡东辉,译.北京:电子工业出版社,2012:219-230.
[3]刘书明,罗勇江.ADSP TS20XS系列DSP原理与应用设计[M].北京:电子工业出版社,2007:1-50.
[4]郝朋朋,周煦林,唐艺菁,等.基于TMS320C6678多核处理器体系结构的研究[J].微电子学与计算机,2012,29(12):171-175.
[5]TMS320C6678 Multicore Fixed and Floating-Point Digital Signal Processor[Z].Dallas,Texas:Texas Instruments,2015.
[6]夏际金,常越,梁之勇,等.多核DSP信号处理并行设计[J].雷达科学与技术,2013,11(6):617-620.
