信息管理技术视角下微博研究综述与趋势分析*
2015-12-31崔金栋于圆美王新媛孙遥遥
崔金栋,于圆美,王新媛,孙遥遥
1 信息管理视角下的微博研究
微博凭借实时性和便捷性成为重要的网络应用,其聚集的大量用户和相对自由的言论信息使之成为把握社会脉搏的重要工具。微博信息管理专指从微博信息出发,并不考虑各种规则制度的约束力。早在2006年,就有外国学者关注微博信息管理,国外研究建立在对Twitter研究的基础上。笔者在IEEE数据库中检索发现,国外研究的Micro-blog就是Twitter,研究有很强的个案性,难以在其他微博系统上推广使用,直至2009年才出现具有推广意义的研究成果。国外的研究倡导以法治和规范约束微博信息,同时强调通过采用新的微博信息管理技术使微博信息的组织、传播等环节实现规范化和可控化。我国对微博信息管理的研究始于2010年,除倡导在用户管理上进行引导外,技术层面的关注点集中于微博信息组织、传播与用户个性化推荐,这三方面恰恰描述了微博信息的生命周期。
2 微博信息组织研究
学术界并没有统一的“信息组织”定义,信息管理领域认可的信息组织专指有序化和结构化,是指通过某种方式使信息便于获取、使用和存储。微博信息组织是指建立某种结构化的数据结构,使微博信息能得到有效重组和整合。截至目前,网络信息资源的组织方式包括文件管理和数据库管理,微博的底层数据管理也使用这两种组织方式,但不局限于此。微博需把信息数据和服务结合在一起,对其组合和再造,从这个角度来讲,微博信息的组织方式是重组与再造。利用RSS技术,微博可实现信息的聚合和推送,有明显的信息自组织特点。随着数据挖掘技术和网络传播技术的发展,信息组织方式会进一步发展,微博会更加智能和方便。
Kaplan A等研究微博允许用户之间交换短内容,如句子、图像和视频链接等信息组织形式的机理[1];VELIKOVICH L等研究微博消息内容特点、活跃时间特点、趋势话题特点[2];LEED H、SCHLEYERT等归纳前人的研究成果,阐述微博信息组织研究的局限性,认为看起来有序是由于限定了用户和使用领域,尤其是学术界和某些特定领域对微博使用的有序化并不具有推广性[3]。我国学者的研究也有局限性。刘鲁等对基于机器学习的中文微博情感分类进行实证研究[4];王晶等对基于信息数据分析的微博研究进行梳理,提出微博信息传播三大构件的概念,归纳此类研究的内容及方法,总结国内外围绕微博信息传播三大构件取得的研究成果[5];章成志等研究不同领域的用户标签主题表达能力差异,认为标签主题在微博信息组织中应处于主导作用,并以腾讯微博为例进行验证[6];吴丹、王艳妮阐述微博标签的重要性,认为标签在微博信息组织中的作用无可替代[7];潘婵等基于微博用户标签与关键词的用户行为分析,研究微博信息组织,说明前期的微博信息组织研究具有局限性,尤其是一些实证分析,并以娱乐和学术两个领域标签的差异性否决一些研究成果[8];李林红、李荣荣根据自组织理论,认为新浪微博社会网络是自组织系统,从整体网络、个体网络、小团体、小世界效应构建模型,以“可持续发展”话题为例,采用滚雪球抽样方法,对网络用户间的“发布、转发、评论、@、回复”关系进行实证研究[9];刘风光、朱爱菊介绍微博的信息组织方式,探讨微博信息质量的分析原则[10-11];胡媛利用自然语言处理和数据挖掘技术,通过分析微博中的信息内容、用户的社会网络和交互情况以及研究某条信息传播运动过程来揭示微博中非正式信息交流规律及其信息交流机制[12];王晓光等通过对新浪博文的发布者、发博途径、博文内容、转发数、评论数、关注数、粉丝数等的统计,分析微博信息结构和传播模式的差异,说明微博用户的表征差异性,探究微博信息产生互动的结构性要素、发生机制。这些研究使微博信息的组织更加有序化,丰富了微博信息组织的研究内容,使网络信息组织理论有了新的突破[13]。
3 微博信息传播研究
微博大大提高了信息传播速度和广度,信息传播包括粉丝和转发两种路径。粉丝路径是指博主的粉丝可实时接收和阅读博主发布的信息,该路径是将博文直接分发给粉丝而产生的。转发路径是指博主发布的某一博文如果得到粉丝认可,被转发并同步到粉丝的微博中,这样,博主粉丝的粉丝同样可以实时接收该博文,造成信息的传播超越最初博主的朋友圈,实现更快更广的传播。粉丝通常会在转发时进行评论,导致相关话题增多,促使微博得到更广泛的传播。图1为影响微博信息传播因素的示意图。

图1 微博传播影响因素示意图
社会网络理论被微博研究者充分挖掘,以“关注”与“被关注”为关联纽带,以用户为节点,通过分析用户节点和整个社会网络的中心性等若干指标,解析微博社会网络,并通过定量方式发现微博传播特征[14];田占伟等利用复杂网络理论方法,对微博信息传播网络建模,基于信息网络节点的出入度、路径两个指标进行分析,解释微博信息传播的小世界、高度中心化等特征[15];吴凯等提取影响转发行为的四类特征,利用机器学习中的逻辑回归模型分析预测个体转发行为,在此基础上融入用户个体差异,建立基于行为预测的信息传播模型[16];田占伟与刘臣基于PA算法提出信息分享预测模型,以微博用户的共享需求为前提条件,以2013年的新浪微博数据验证预测模型[17];袁毅等以事件为主线,分析传播过程中的用户行为,利用分析软件绘制事件的微博信息传播图,阐述影响微博信息传播的内外部因素[18];刘燕锦以社交网站和微博为对象,运用社会网络分析法,对比两者的传播模式,分析同属于关系型的媒介技术平台是否因为功能设置的差异而造成信息在使用者之间流动的差异[19];刘继、李磊发现在网络舆情传播模式中,单关键点型传播模式以强势节点为主,传播速度快,多关键点型传播模式的多个强势节点通过桥节点进行信息交互,传播影响大,链式型传播模式由于缺乏强势节点,信息传播扩散能力较弱,但传播层次较深[20];陈波等研究微博信息舆论的控制问题,研究成果以传染病模型为基础,通过分析影响传染力的因素实现对网络舆情微博信息传播的有效控制策略[21];钱颖等提出与陈波等不同的结论,发现舆情信息和微博信息具有记忆性,传染病模型描述的微博信息传播在某些场合和舆情信息传播并不是很一致[22];唐晓波等借助共词网络等工具对微博信息传播进行预测,使用图论对现实中的舆情问题进行分析和建模[23];张赛、徐恪提出一种三角和算法用于探测用户粉丝数阈值,该算法根据散点分布的统计规律来估计使微博热度达到某一值的粉丝数的临界值[24];郭浩等为了定量研究用户影响力,提出基于用户消息传播范围的用户影响力量化定义,给出用户影响力的计算方法[25]。
国外研究者更热衷于使用统计分析来研究微博的传播规律。NARAYANAM R、NARAHARI Y提出线性阈值模型(linear threshold model,LTM),基本思想是一个节点转为活跃状态的概率会随着周围活跃节点个数的增多而增大,如果一个节点邻居中的活跃节点数量超过一定阈值,该节点将转为活跃状态[26];M.EFRON等对微博信息传播的研究偏好在应用领域,研究结果强调在数据挖掘、电子商务领域的应用[27];B.SUH、L.HONG等重点研究微博信息分享过程涉及的两个主体:用户个人行为和信息本身[28];Yu Louis、Asur Sitaram、Huberman Bernardo A对比西方和我国微博信息传播的不同特点,通过构建指标体系对东西方微博信息的特有传播现象进行研究[29]。上述研究成果说明微博信息传播具有复杂性和混沌性,使微博信息传播预测性的难度增加,这恰恰是微博舆论爆发的源泉。
4 微博用户推荐研究
微博在信息组织和传播中最具特色的地方在于其个性化的信息推荐,有两种方式,即推荐个性化的微博内容和推荐拥有共同兴趣的用户。
早期的微博用户推荐源于微博用户的个性化研究需要。Zhiheng X、Ru L、Xiang L等倡导使用词包模型(Bag of words)分析用户兴趣,建立影响力回归方程来研究用户推荐[30];Yu L,Asur S和杨成明等通过研究Twitter、新浪微博,抽取微博平台提供的各项字段,从用户性别、地域、影响力等多个角度揭示微博用户的行为特征,以达到用户推荐的目的[31];张中峰等认为驱使动态社会发展的最主要机制是同质性,即微博用户双方相互关注是因为他们拥有共同的兴趣爱好[32];胡文江等提出基于关联规则和标签的个性化好友推荐策略,结合共同好友和用户标签相似性两个特征向量,使得推荐好友更准确、更具个性化[33];涂存超等通过对用户个人简介中的词语和标签之间的关系进行建模,同时利用其社交网络结构作为模型的正则化因子[34],提出网络正则化的标签分发模型(NTDM),为用户推荐标签;覃梦河等发现结合人际关系的传统分类,通过因子分析找出强关系构建因子,对帮助用户拓展社交网络关系有很好的参考意义和实践价值[35];徐志明等将用户现实关系应用于用户推荐的相关实验,基于社交信息的用户相似度取得了较好的推荐效果[36];Naruchitparames J、Gunes M 等在IEEE大会上提出FOF理论(好友的好友理论),为微博好友推荐的研究提供了新的理论依据[37];Chechev M、Georgiev P等倡导基于内容的好友推荐能够深层次挖掘用户的隐性兴趣[38];Hannon J、Mc Carthy K、Smyth B等的研究表明基于多维度的好友推荐准确率更高;通过比较基于内容和基于协同过滤的好友推荐方法,发现两者都能进行高质量的推荐,但若将两者结合,推荐效率更高[39];Krestel R、Fankhauser P倡导对微博信息或者资源进行标注(即标签),利用标签相似性来推荐好友,以大大提高信息或资源的推荐效率与准确度[40]。
近年国内外关于微博用户推荐的研究集中在推荐算法和推荐模型上,这些研究既有早期关于k-means算法、WAF算法,也有目前备受关注的LDA主题推荐模型。杨尊琦等基于k-means算法实现微博用户推荐功能,以新浪微博达人为研究对象,提取他们关注的名人以及机构进行归类,基于共链关系将统计结果制成相关性矩阵,导入SPSS软件中进行k-means聚类,结果发现具有相似性的兴趣用户可以聚为一组[41]。
LDA主题推荐模型是微博用户推荐研究中最为火热的一种用户推荐模型,国内外大量学者都对其进行了深入的研究。Blei D等研究LDA模型的始祖——LSA,认为在微博中应用LSA能更好地实现近似于人类的理解关系,即将表面信息转化为深层次的抽象[42];Tang Xuning、Yang CC将LDA引入超参数,形成文档-主题-单词三层的贝叶斯模型[43];Hong Liangjie、Davison B利用LDA模型将两个主题模型合并,以搭积木的方式形成新的主题模型[44];Zhao Wayne Xin等假设一个单独的微博帖子通常只有一个主题,对ATM模型进行扩展,提出Twitter-LDA模型[45]。
我国对LDA的研究多是结合新浪等微博提供商的实证研究。唐晓波等基于社会关系理论中的同质性理论和三元闭包关系理论,从社会关系和内容两个维度向社交网络用户推荐同道合的朋友,并利用LDA的扩展模型UserLDA对新浪微博用户进行兴趣主题建模,通过用户主题概率分布矩阵计算用户相似度,以进行TopN二级好友推荐[46];邸亮、杜永萍发现LDA主题模型可用于识别大规模文档集中潜藏的主题信息,但对微博短文本的应用效果并不理想,将标准的文档-主题-词的三层LDA模型变为用户-主题-词的用户模型,利用该模型进行用户推荐[47];张培晶、宋蕾对基于LDA的微博文本主题建模方法研究进行述评,分析LDA模型的特征及其用于微博类网络文本挖掘的优势,介绍和评述微博环境下现有的基于LDA模型的文本主题建模方法,并对其扩展方式和建模效果进行总结和比较[48];唐晓波等提出微博热度的概念,将其引入LDA模型的趋势挖掘研究中,构建基于微博热度的LDA模型,通过API采集微博数据的实验,得到更直观的微博热度表,并得出更具有说服力的挖掘结论[49];唐晓波还与王洪艳实现了基于潜在语义分析的微博主题挖掘模型构建,提出根据微博信息特点进行有针对性的预处理后,使用基于先验概率的潜在语义分析模型LDA进行微博主题挖掘,并在LDA建模基础上,设计文本增量聚类算法,进一步实现主题结构识别,从而使用户更好地理解主题[50];余传明等基于LDA模型在吉布斯抽样过程中得到两个矩阵:特征词-主题矩阵和微博-主题矩阵,利用LDA模型对要构建的文档向量空间矩阵进行降维[51]。微博信息用户推荐研究多是根据用户兴趣,利用LDA模型等主题推荐模型来实现,但LDA模型是基于词频统计分布的,缺乏语义性,解决这方面问题的研究成果并不多。
5 技术层面下微博信息管理的研究趋势
技术层面的微博信息管理包括微博信息组织、传播及用户推荐三部分。从上述综述可看到,国内外研究正向纵深化、个性化和融合化发展,具体表现在微博信息组织的规范化、微博信息传播的可控化以及微博信息推荐的个性化与精准化三个方面。
5.1 微博信息组织的规范化——本体与大众分类法的融合
微博作为信息生产系统,由“混沌”到组织化的过程可看作“信息自组织”过程。微博信息的发布与扩散在本质上处于不可逆状态,而且受用户真实身份、虚拟空间的个人魅力、发布内容的关注度、用户登录和更新频率等因素的影响,微博客网站中的信息一直处于动态变化的不均衡状态,为准确描述微博信息组织和传播过程,对其进行建模是必不可少的。
本体作为有效表现概念结构形式化的语义模型,虽然有构建复杂、需人工参与的缺点,但部分研究成果已可成熟应用。本体的构建过程通过获取相关领域的知识,加以规范化的描述,形成形式化、结构化的定义,为信息与知识建模提供明确无歧义的定义。可想象,经过本体技术规范化的微博信息具有明确的含义和结构化的特点,在微博信息组织和传播控制领域带来的益处是显而易见的。因此,利用本体技术对微博信息进行有效的规范和结构化,提升微博信息描述事件的精度和准度,从而达到消除歧义、提升信息组织效率的目的成为研究热点。
Floksonomy作为微博传统信息组织方式,本质是基于标签语法层次的简单聚合分类,再加上语言本身的复杂性和用户标注的随意性,信息组织的清晰度和资源查询的准确度都较低,同时无法解决近义异形词滥用的问题。本体与大众分类法的有效融合成为解决上述问题的有效途径。利用本体和大众分类法的融合,构建适合微博信息组织的架构形式成为大势所趋,即构建一种基于Folksonomy的微型本体架构来进行微博信息的规范化,为消除歧义和提升结构化微博信息的应用打下基础。这种微型本体架构既可以结合Folksonomy的优点,让所有用户参与本体构建,降低微博信息本体的构建成本和复杂度;又可以拥有本体的优点,形成结构化的、无歧义的、易控制的信息组织结构,便于信息的管理和传播。目前崔金栋、徐宝祥、王新媛等人在这方面开展了研究,取得了一定的成果[52]:以自组织和本体建模理论对微博信息的组织过程进行规范化,形成结构化的信息组织结构;进入到微博信息传播阶段,再通过本体建模理论对传播中的信息进行重新建模,图2展现了其构造的微博信息管理的概念模型。
5.2 微博信息传播的可控化——混沌性与可控性的博弈
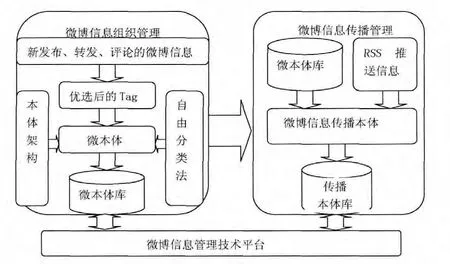
图2 微博信息管理技术概念模型
现有的微博信息传播可控性研究主要是指从建模的角度对微博信息传播临界点表征进行建模,通过对这些表征信息抽取而成的微博信息传播具体事件的监测,达到微博信息传播预警的目的,但这种方法往往具有滞后性。微博信息的传播一旦超越临界点便难以控制,这成为研究者的共识。因此,广大学者希望在临界点产生前对传播信息的临界表征进行分析和鉴别,从而实现对信息传播的规范和抑制。但微博信息平台是一个复杂系统,混沌性带来的初值敏感性极强,表现为一条微博在转发中常由于某一突发事件的出现造成微博信息传播生态的失控,特别是某个网络意见领袖的评论或异样见解的发酵引起整个信息传播的突然爆发。这种爆炸状的微博信息传播是传染病模型所不能描述的,整个微博信息生态系统在临界点附近所表现出来的临界行为只能用复杂系统论的突变论和混沌论去描述。以系统学视角研究传播过程的约束和管制,从而达到在技术层面上加强微博信息管理的目的成为微博信息传播研究的新趋势。钟映竑等已开始从微博信息传播的混沌性中去发现混沌吸引子,探讨混沌性中的可控性[53]。
5.3 微博用户信息推荐的个性化和精准化——多级推荐和模型融合
微博信息推荐本质上属于微博信息组织的内容,但是由于涉及到用户角色,微博信息推荐已不是单纯的信息组织问题,而是融合了信息传播的若干内容,成为建立在微博信息组织与传播之上的一种用户服务功能。目前,由于用户数据稀疏性和用户信息的非结构化,推荐不准确成为影响微博发展的制约因素。以多级过滤和融合推荐模型为趋势的个性化推荐和精准化推荐成为微博用户信息推荐研究的主流。新的微博推荐系统结合了用户的偏好、话题之间的相似度、状态之间的相似度等推荐模式,取得良好的推荐效果。另外,针对用户信息的非结构化问题,以简化的本体架构为数据结构来构建微博信息推荐系统的底层数据库,结合改进的LDA模型进行微博信息和用户推荐,从而有效提高微博信息推荐的精度和质量,也成为微博信息研究的一个新方向。图3展示了融合后的用户层面的微博信息管理概念模型。
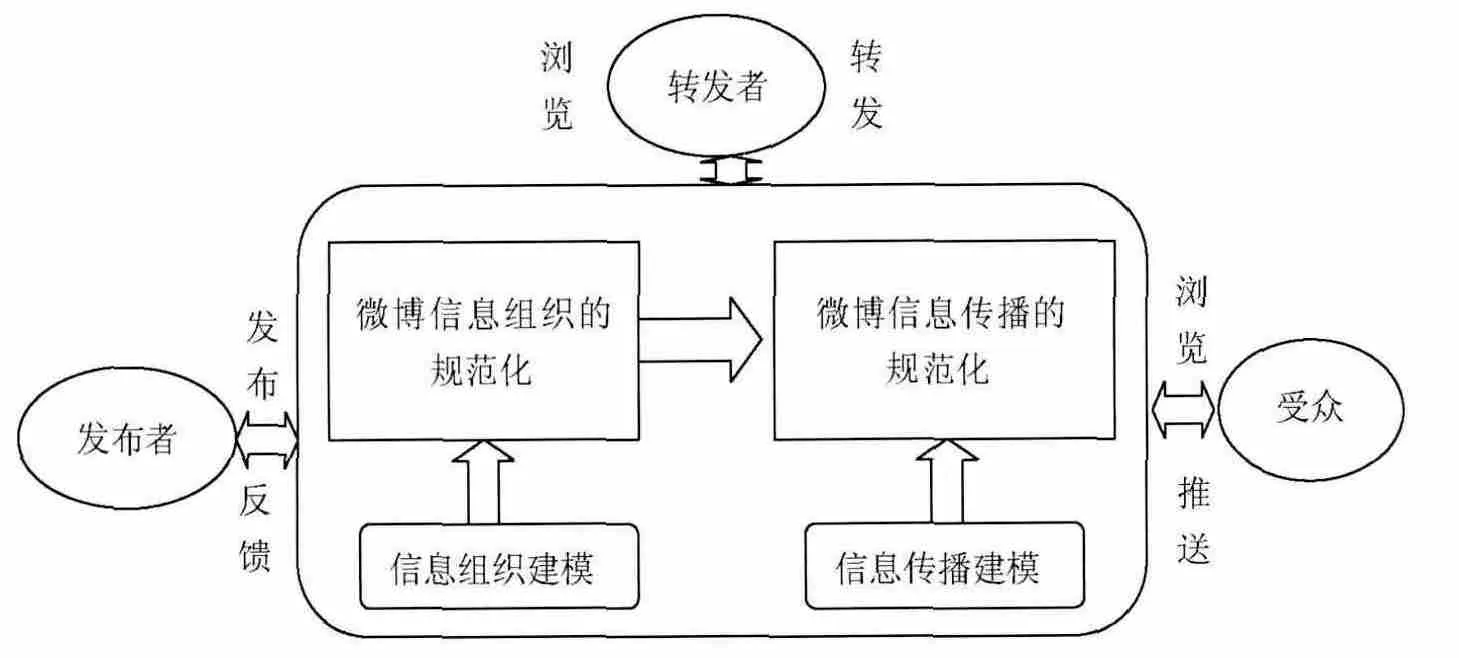
图3 用户层面的微博信息管理概念模型
6 结语
研究信息在微博网络上的组织及其传播的性质、规律,进而研究如何控制、引导舆论,具有非常重要的理论价值和现实意义。笔者在技术层面上梳理了国内外关于微博信息管理的主要文献,并对其进行分析,阐述了微博信息组织、信息传播和用户推荐三方面的研究热点;在解析相关研究成果的同时,总结了现有研究的不足;最后,笔者提出了技术视角下微博信息管理研究的新趋势——微博信息组织的规范化、微博信息传播的可控化以及微博用户信息推荐的个性化,这些研究试图通过构建新的微博信息组织模型和传播模型,解决技术层面上微博信息管理的弊端,实现微博信息有效管理的新突破。
[1] Kaplan A.Users of the world,unite!The challenges and opportunities of Social Media[J].Business Horizons,2010,53(1):59-68.
[2] VELIKOVICHL,BLAIR-GOLDENSOHNS,HANNANK,et al.The viability of Web-derived polarity lexicons[C]//Proceedingsof the North American Chapter of the Association for Computational Linguistics.Stroudsburg,PA:Association f or Computational Linguistics,2010:777-785.
[3] LEEDH,SCHLEYERT.Social tagging isnosubstitute for controlled indexing:acomparison of medical subj ect headingsand CiteULiketagsassigned to231,388 papers[J].Journal of the American Society f or Information Science and Technology,2012,63(9):1747-1757.
[4] 刘鲁,刘志明.基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012,48(1):1-4.
[5] 王晶,朱珂,汪斌强.基于信息数据分析的微博研究综述[J].计算机应用,2012,32(7):2027-2029.
[6] 章成志,何陆琳,丁培红.不同领域的用户标签主题表达能力差异研究——以中文微博为例[J].情报理论与实践,2013,36(4):68-71.
[7] 吴丹,王艳妮.社会标签的规范性研究——学术论文标注[J].图书馆,2012(1):85-88.
[8] 潘婵,冯利飞,丁婉莹,等.基于标签—关键词的用户行为分析[J].情报杂志,2010,29(3):139-142.
[9] 李林红,李荣荣.新浪微博社会网络的自组织行为研究[J].统计与信息论坛,2013,28(1):88-94.
[10]刘风光.网络博客尧微博的信息组织方式和信息质量分析原则[J].价值工程,2013(8):185-186.
[11]朱爱菊.从对人的关注和浏览中获取信息——新浪微博中的信息组织与信息获取机制分析[J].情报杂志,2011(5):161-164.
[12]胡媛.微博客中基于时序的非正式信息流机制研究——以sina微博为例[J].图书情报知识,2011(4):111-117.
[13]王晓光.微博客用户行为特征与关系特征实证分析——以新浪微博为例[J].图书情报工作,2010(14):66-70.
[14]平亮,宗利永.基于社会网络中心性分析的微博信息传播的研究——以Sina微博为例[J].图书情报知识,2010(6):92-97.
[15]田占伟,隋玚.基于复杂网络理论的微博信息传播实证分析[J].图书情报工作,2012(8):42-46.
[16]吴凯,季新生,刘彩霞.基于行为预测的微博网络信息传播建模[J].计算机应用研究,2013(6):1809-1812.
[17]田占伟,刘臣.基于模糊PA算法的微博信息传播分享预测研究[J].计算机应用研究,2013(30):51-54.
[18]袁毅.微博客信息传播结构、路径及其影响因素分析[J].图书情报工作,2011,55(12):26-30.
[19]刘燕锦.社交网站和微博的信息传播比较——以社会网络分析结果为依据[J].东南传播,2012(9):65-68.
[20]刘继,李磊.基于微博用户转发行为的舆情信息传播模式分析[J].情报杂志,2013,32(7):74-77.
[21]陈波,于泠,刘君亭,等.泛在媒体环境下的网络舆情传播控制模型[J].系统工程理论与实践,2011(11):2040-2050.
[22]钱颖,张楠,赵来军,等.微博舆情传播规律研究[J].情报学报,2012(12):1299-1304.
[23]唐晓波,宋承伟.基于复杂网络的微博舆情分析[J].情报学报,2012,31(11):1153-1163.
[24]张赛,徐恪,李海涛.微博类社交网络中信息传播的测量与分析[J].西安交通大学学报,2013,47(2):124-130.
[25]郭浩,陆余良,王宇,等.基于信息传播的微博用户影响力度量[J].山东大学学报(理学报),2012,47(5):78-83.
[26]NARAYANAMR,NARAHARI Y.Ashapley value-based approach to discover influential nodes in social networks[J].IEEETranson Automation Science and Engineering,2011,20(1):130-147.
[27]M.EFRON.Inf ormation Search and Retrieval in Microblogs[J].Journal of the American Society for Inf ormation Science and Technology,2011,62(6):996-1008.
[28]B.SUH,L.HONG,P.PIROLLI.Want toberetweeted-Large scale analytics on f actors impacting retweet in Twitter network[C]//IEEE,2010:177-184.
[29][31]Yu Louis,Asur Sitaram,Huberman Bernardo A.What trends in Chinese social media[C]//Proceedings of the 5th SNA-KDDWorkshop on Web Mining and Social Network Analysis(SNA-KDD’11).NewYork:ACMPress,2011.
[30]Zhiheng X,Ru L,Xiang L,et al.Discovering User Interest on Twitter with a Modified Author-Topic Model[C]//Proceedings of the 2011 IEEE/WIC/ACM International Conf erences on Web Intelligence and Intelligent Agent Technology.Washington DC,USA:IEEEComputer Society,2011.
[32]张中峰,李秋丹.社交网站中潜在好友推荐模型研究[J].情报学报,2011,30(12):1319-1325.
[33]胡文江,胡大伟,高永兵.基于关联规则与标签的好友推荐算法[J].计算机工程与科学,2013,35(2):109-113.
[34]涂存超,刘知远,孙茂松.社会媒体用户标签的分析与推荐[J].图书情报工作,2013,57(23):24-35.
[35]覃梦河,晋佑顺.基于微博显性结构特征的用户强关系研究[J].图书馆学研究,2013(3):58-63.
[36]徐志明,李栋.微博用户的相似性度量及其应用[J].计算机学报,2014,37(1):207-218.
[37]Naruchitparames J,Gunes M H,Louis S J.Friend recommendations in social network topology[C]//Evolutionary Computation(CEC), 2011 IEEE Congresson.NewOrleans:IEEE,2011.
[38]Chechev M,Georgiev P.Amultiview conent-based user recommendation scheme f or f ollowing users in TWITTER[C]//4th International Conference,SocInfo 2012.Berlin:Springer Berlin Heidelberg,2012.
[39]Hannon J,McCarthy K,Smyth B.Content vs.tags for friend recommendation[M]//Max Bramer,Miltos Petridis.Research and Development in Intelligent Systems XXIX.London:Springer,2012:289-302.
[40]Krestel R,Fankhauser P.Personalized topic-based tag recommendation[J].Neurocomputing,2012,76(1):61-70.
[41]杨尊琦,张倩楠.基于k-means算法的微博用户推荐功能研究[J].情报杂志,2013,32(8):142-144.
[42]Blei D.Probabilistic Topic Models[J].Communicationsof the ACM,2012,55(4):77-84.
[43]Tang Xuning,Yang CC.TUT:AStatistical Model for Detecting Trends,Topics and User Interests in Social Media[C]//Proceedings of the 21st ACMInternational Conference on Information and Knowledge Management.NewYork,USA:ACMPress,2012:972-981.
[44]Hong Liangj ie,Davison B.Empirical study of topic modeling in Twitter[C]//Proceedings of the First Workshop on Social Media Analytics(SOMA’10) .NewYork:ACMPress,2010:80-88.
[45]Zhao Wayne Xin,Jiang Jing,Weng Jianshu.Comparing Twitter and traditional media using topic models[C]//Proceedings of the 33rd European Conference on Information Retrieval(ECIR’11).Berlin,Heidelberg:Springer-Verlag,2011:338-349.
[46]唐晓波,祝黎,谢力.基于主题的微博二级好友推荐模型研究[J].图书情报工作,2014,58(9):105-113.
[47]邸亮,杜永萍.LDA模型在微博用户推荐中的应用[J].计算机工程,2014,40(5):1-11.
[48]张培晶,宋蕾.基于LDA的微博文本主题建模方法研究述评[J].图书情报工作,2012,56(24):120-126.
[49]唐晓波,向坤.基于LDA模型和微博热度的趋势挖掘[J].图书情报工作,2014,58(5):58-63.
[50]唐晓波,王洪艳.基于潜在语义分析的微博主题挖掘模型研究[J].图书情报工作,2012,56(24):114-119.
[51]余传明,张小青,陈雷.基于LDA模型的评论趋势挖掘:原理与实现[J].情报理论与实践,2010,33(5):103-106.
[52]崔金栋,徐宝祥,王新媛.基于微本体构建的微博信息管理机理研究[J].情报资料工作,2013(5):50-55.
[53]钟映竑.基于混沌情景预测方法的微博信息扩散建模与仿真研究[J].价值工程,2014(7):225-228.
