自然语言处理技术在中高职课程衔接中的应用
2015-11-26申玫徐宁赵晓玲
申玫+徐宁+赵晓玲
摘要:在中高职课程衔接的实际中,存在着中高职专业设置不对口、专业课程内容重复等问题。为了选择对口专业及查找重复课程,采用人工手段对教育教学文件进行分析研究,效率低、精确性差。而使用计算机自然语言处理技术对中高职教学文件中的文本数据进行分析,可以快速获得中高职相关专业之间的相似度及专业课程内容之间的重复度,为课程设置提供科学依据。将自然语言处理技术用于青岛远洋船员职业学院“船舶工程技术”专业中高职课程衔接问题上,对相关文件进行分析,得到合理的结论。
关键词:中高职衔接;自然语言处理技术;课程设置
中图分类号:G712 文献标识码:A 文章编号:1672-5727(2015)11-0060-04
中高职教育课程衔接主要存在两个方面的难题:其一,中高职教育没有实行专业归类对口招生报考制度,造成中高职专业设置的对应关系不明确,各院校自行选择对接专业,造成很多中职专业在升高职时不对口。其二,中高职专业课程内容重复,使中职毕业生升入高职时重复学习相同的课程内容。
在我国,中高职课程衔接仍然依赖于专家经验。对口专业的判断及重复课程的筛选是通过对“人才培养方案”和“课程标准”等文本文件的内容进行人工分析。面对多个专业,每个专业数十门课程,采用人工分析,工作效率低,专业的对口程度和课程重复程度难以精确的衡量。为了科学高效地进行中高职课程衔接,不能仅仅依赖经验和人工分析,而应该运用计算机技术,对各院校多年积累的课程数据文件进行深入分析研究,使中高职课程衔接方法具备精确性和实用性。如何让计算机对“人才培养方案”和“课程标准”等文本文件进行自动识别分析是科学高效进行中高职课程衔接的关键。
自然语言处理(Natural Language Processing,简称NLP)就是用计算机来处理、理解以及运用人类语言(如中文、英文等),它属于人工智能的一个分支,是计算机科学与语言学的交叉学科,又常被称为计算语言学,是计算机科学领域与人工智能领域中的一个重要方向。 自然语言处理技术可以实现文本分类聚类、文本自动摘要、机器翻译、检索系统、问答系统、人机交互等诸多功能,其中重要的一项任务就是文本相似度分析。文本相似度分析最为著名的应用案例之一是搜索引擎,如谷歌、百度等,人们能通过输入文字来查找相关的新闻等网络资源,另外,在检测学术论文是否抄袭方面文本相似度也有其关键技术的应用。所谓文本相似度计算是指利用计算机自动计算文本间的相似程度,文本相似度是表示两个或多个文本之间相似程度的一个度量参数,相似度大,说明文件相似程度高,反之文件相似程度就低。
本文运用自然语言处理中的文本相似度算法对中高职课程相关的文本数据进行分析,能够快速地找出中高职对口专业,指导课程衔接方案的合理设置。
一、 自然语言处理中的文本相似度算法
文本相似度度量任务就是衡量两个文本之间语义相似的程度,是自然语言处理中一个非常重要的任务。常规的文本相似度度量方法是将文本转化词汇的集合,分析每个词在单个文本中出现的次数以及在整个语料库中出现的次数,进而利用每个文本的词频信息构建为一个向量,并利用向量间的余弦相似度或Jaccard相似度等方法计算文本之间的相似度。图1显示了文本相似度算法的主要流程。

(一)预处理
计算机可以快速地计算出两列数组之间的相似度,也可以分析出两个矩阵之间的相似度,但对于两篇文本来说,相似度的计算要相对复杂。因为,文本是非结构化的数据,数据挖掘的算法要应用到文本对象之上,就必须对文本进行预处理,使其结构化,即将文本转化为数组或向量。对于中文文本的预处理技术主要包括中文分词和停用词过滤两个方面。
1.中文分词技术
中文文本与英文文本不同,词与词之间没有空格,读者阅读时要根据经验和语言知识来自行分词。因而,计算机对于中文的处理相对于以英文为代表的西文处理存在更大的难度。现有的分词方法主要有:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。对于分析者来说,自行开发中文分词算法难度较大,目前有很多开源的软件和在线工具都可以完成分词工作,如Jieba、SCWS、中科院张华平开发的ICTCLAS 、武汉大学沈阳开发的ROST-CM等。
2.停用词过滤
在文本处理中,有一些词出现频繁但意义不大,为了提高文本的分析速度和精度,须将这些词忽略。比如,“的”、“在”、“是”等几乎是中文文本中出现频率最高的词,这类词对文本相似度的计算会产生不良的干扰。对于这类问题的解决,可以利用现有的“中文停用词表”将这些词进行过滤删除。但是较为精确的方法是计算文本中每个词的TF-IDF值,将TF-IDF值为0的词删除。
TF-IDF是用来评估某一词汇对于一个文件集或一个语料库中的其中一份文件的重要程度的统计方法。词汇的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。比如,“船体的认识”被分词后变成“船体”、“的”、“认识”,其中“的”是停用词,而“船体”和“认识”这两个词在计算文本相似度中的重要程度是不同的。“船体”这个词较为专业,“认识”这个词较为普通,在中高职院校的教学文件中几乎每篇都会出现“认识”这个词。当某个词在所有文本中都会出现,那么,它对文本相似性也就没有贡献了。
(二)基于余弦相似度的文本相似度算法
经过预处理之后,两篇文本被转换为两份词汇表数据,分别用向量D1(n)和D2(m)来表示,其中n和m表示两表中词汇的数目。文本相似度工作就是计算分析D1(n)和D2(m)的相似度。具体步骤如下:
(1)将两份词汇表中重复多次的词合并,并将两份词汇表汇总成一个总词汇表,用向量A(p)表示,其中p表示词汇的数目,p≤m+n。
(2)计算A(p)中的词在D1(n)和D2(m)中出现的次数,分别用向量B1(p)和B2(p)表示。

根据余弦公式计算cos兹=,即计算B1(p)和B2(p)这两个向量的夹角余弦,当夹角为0时,余弦值为1,意味着两个向量重合,即两文本相同。也就是说余弦值越接近1,两文本越相似。
二、中高职课程衔接文本数据来源
近年来,中高职教育衔接是我国教育领域的研究热点,各级教育部门颁发了一系列文件,如《教育部关于推进中等和高等职业教育协调发展的指导意见》、《国家中长期教育改革和发展规划纲要(2010—2020年)》、《山东省中等职业学校教学指导方案》等。在进行文本相似度分析时,要合理选择相关文本进行研究。本文所选的数据来源有以下两个方面:
判断对口专业的文本文件主要有:地方教育部门或行业指导委员会制定的各专业教育教学指导性文件,如《山东省中等职业学校教学指导方案》或各中高职院校制定的《人才培养方案》。中等职业学校专业教学指导方案是中等职业学校专业建设和专业教学的基本指导文件,内容包括教学计划和各门课程的课程标准。人才培养方案是人才培养的总体设计,反映着一个学院人才培养的指导思想和整体思路,关系着学院人才培养的内容、途径和质量。
衡量专业课程内容重复情况的文本文件主要有:地方教育部门、行业指导委员会或院校制定的人才培养方案和课程标准。其中课程标准是指规定某一学科的课程性质、课程目标、内容目标、实施建议的教学指导性文件,是衡量课程内容重复度的主要依据。
三、实例分析
青岛远洋船员职业学院是一所高职院校,其船舶工程技术专业,在面对机械制造技术、焊接技术应用、电气运行与控制等多个中职专业的毕业生时,如何能对口接收并进行合理的课程设置,是学院开展中高职教育衔接的关键。
(一)选择对口专业
根据教育部颁发的《中等职业学校专业目录》(2010年修订),将山东省教育厅开发的6个中职专业(船舶建造与维修、焊接技术应用、机械制造技术、机电技术应用、电气运行与控制、旅游服务与管理)的教学指导方案与青岛远洋船员职业学院“船舶工程技术专业”人才培养方案进行文本相似度分析,得到数据结果,如图2所示。

通过对人才培养方案进行文本相似度分析,可以看出,高职“船舶工程技术”专业的三个方向“船体”、“轮机”和“电气”,与6个中职专业的相似程度各不相同:与“船体方向”对口的中职专业,按相似度依次为“船舶建造与维修”、“焊接技术应用”、“机械制造技术”;与“轮机方向”对口的中职专业,按相似度依次为“船舶建造与维修”、“机电技术应用”、“机械制造技术”;与“电气方向”对口的中职专业,按相似度依次为“船舶建造与维修”、“机电技术应用”、“机械制造技术”、“电气运行与控制”。
本文选择“旅游服务与管理”作为与其他专业对比的参考专业,与船舶工程技术三个方向均不对口,相似度极低,与生活常识相符合。
(二) 判断重复课程
中高职对口专业经常会出现课程内容重复的问题,专业对口程度越高,其课程重复的可能性就越大。通过分析课程标准的文本相似度,可能得到课程内容的重复程度,从而指导课程安排和课时分配,避免中职学生升入高职后重复学习。
图3以中职“船舶制造与修理”专业与高职“船舶工程技术”专业船体方向为例,将4门高职课程分别与9门中职课程进行了文本相似度分析。为了直观判断出中职课程与高职课程之间的相关度,将高职的任一课程与所有中职课程对比绘制成折线图,如图2所示。将高职机械设计、电工基础、结构制图、修造工艺这4门课与中职9门课程进行比较,可以得出以下结论。
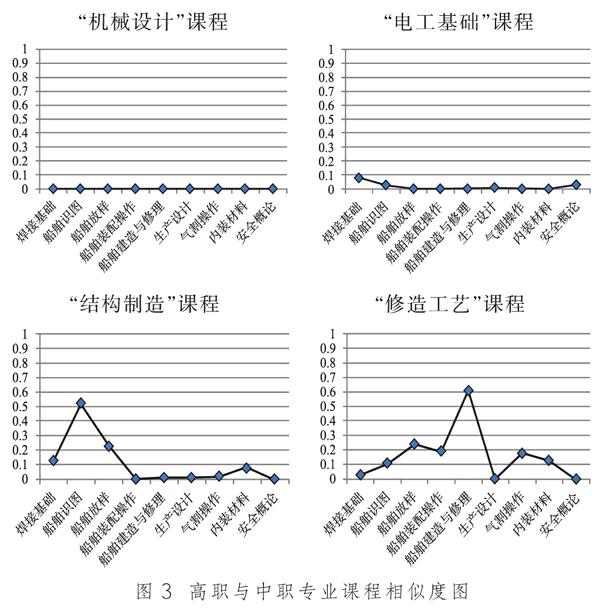
第一,高职机械设计课程与中职各课程相似度均不高,说明课程内容没有重复;第二,高职电工基础课程与中职各课程相似度均不高,说明课程内容没有重复;第三,高职结构制图课与中职船舶识图课的相似度非常高,说明课程内容重复;第四,高职修造工艺课与中职船舶建造与修理课的相似度非常高,说明课程内容重复。
通过对每门课程的“课程标准”的文本相似度进行分析,可以准确快速地得出各门课程重复程度,对与中职课程重复程度高的高职课程,如“结构制图”和“修造工艺”等应考虑免修或适当减免学时。
运用自然语言处理技术,分析文本文档、为课程设置提供可靠依据,在中高职教育课程衔接领域是全新的尝试。本文通过使用自然语言处理技术,对中高职衔接相关教育教学文件进行文本相似度分析。通过青岛远洋船员职业学院的实验验证,这种方法可以定
量地对中高职教育衔接时对口专业进行筛选,以及对重复课程进行判断,取得了良好的分析效果,具有较强的科学性和应用性。
将自然语言处理引入中高职教育衔接领域,可以充分利用现有的教学文件数据,提高各项教育教学决策的速度和准确性,促进了职业教育水平的整体提高。随着自然语言处理技术的不断发展,通过计算机可以高速地对海量数据进行分析,这些数据不仅包括院校原有的教育教学文档,还包括行业发展趋势、社会人才需求等文本数据,并自动生成适应社会发展情况的“人才培养方案”、“课程标准”等教育教学文档,从而实现教育决策的“人工智能”。
