基于Logistic回归模型的中国英语学习者双及物构式选择研究
2015-11-06严敏芬周倩倩
严敏芬,周倩倩
(江南大学 外国语学院,江苏 无锡 214122)
基于Logistic回归模型的中国英语学习者双及物构式选择研究
严敏芬,周倩倩
(江南大学 外国语学院,江苏 无锡 214122)
本研究将中国学习者英语语料库中的st2和st6两部分语料作为低水平和高水平学习者的英语输出的数据来源,将自建的人教版初高中英语教材语料库作为低水平学习者的英语输入的数据来源,在3个语料库中检索双及物构式,用Logistic二元回归模型考察6种限制双及物构式选择的分布偏向在中国英语学习者输出双及物构式中的相对作用和共同作用,并分析学习者是否对输入中展现的双及物构式的分布偏向敏感。结果发现,学习者输出双及物构式时同时考量输入中展现的多种分布偏向的影响,输入与输出中各分布偏向的相对影响力存在广泛的一致性;高水平学习者对更多分布偏向敏感,且因各分布偏向间的相互作用和压制,其习得顺序与作用力大小无关。这说明,语言学习是循序渐进、动态的过程,学习者能掌握输入中复杂的语义、语篇信息及其分布特征。
双及物构式;构式选择;Logistic二元回归模型;分布偏向
一、引言
双及物构式包括两个子构式:双宾构式(Double-object Dative Construction,简称DO)和与格构式(Preposition-object Dative Construction,简称PO)。双及物构式选择是指说话者在表达“所有物转移”这一概念时,基于其语言知识及当下语境对这两个语义相近的子构式所作的选择。如:
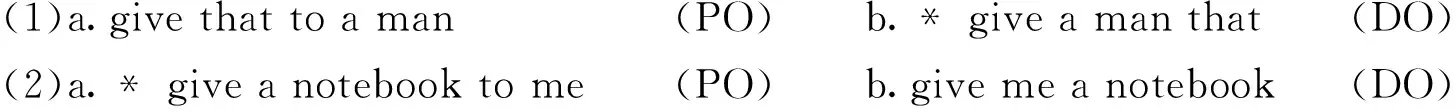
例(1a)较例(1b)使用频率更高,例(2b)较例(2a)使用频率更高,换言之,被选择的可能性更大。英语中存在大量句法构式,说话者可以选择同属一个构式范畴内的不同子构式来表达某个意义或概念[1]145。语言输出就是一个不断选择的过程。基于用法的理论认为语言学习受输入驱动,是经验性的。说话者知道具体动词出现在不同时态、不同语态、不同及物性构式中的相对频率,以及与其搭配的典型主语、宾语等等。这类信息是通过经验输入而习得的,说话者能从复杂的输入中概括出其分布特征和频率信息,语言学习中很重要的一点就是逐渐强化共同出现的语言成分之间的联系[2]。这一理论认为,说话者是在从输入中概括出的分布特征及频率信息的基础上对双及物构式作出选择的。
本研究从基于用法的习得观出发,采用统计分析模型——Logistic二元回归来考察不同二语水平的中国英语学习者对输入中展现的限制双及物构式选择的语义、语用等多种分布偏向是否敏感,各分布偏向的影响强度与输入中的情况是否一致,以及学习者敏感的分布偏向的类别是否随二语水平的提高而增加。
Logistic二元回归模型被广泛应用于二元转换的语言现象中,如双及物构式选择、属格转换、主动/被动语态转换等,其优势在于可以同时统计多种自变量对因变量的预测力大小,统计每个自变量相对于其他自变量的“相对”作用力。目前,国内关于中国英语学习者双及物构式选择的研究主要考察每种分布偏向的“绝对”影响力大小,这与双及物构式在自然情境下产出的认知心理过程不符。本研究是对构式与定量语料库研究方法的一次运用,旨在与前人通过语法判断等研究方法得出的结论和发现相互补充。
二、文献回顾
(一)分布偏向效应
Tomasello(2003)认为在功能分布分析的过程中,语言成分被归入不同的范畴,一个范畴内的成员有着相同的交际功能,成员间因频率差异产生分布偏向,分布偏向又使得固着度产生层级性[3]。分布偏向存在于不同范畴间,存在于同一范畴的不同成员间,也存在于同一成员的不同槽孔(slots)间。由此,基于用法模型的双及物构式选择研究又可分为以动词槽孔的分布偏向和以名词性槽孔/论元的分布偏向为取向的研究。
双及物构式的述谓动词这一槽孔的分布偏向一直是研究的热点,如Inagaki(1997)[4],Mazurkewich和White(1984)[5],Ambridgeetal. (2012)[6],韩百敬和薛芬(2014)[7]等。无论是在母语还是二语习得中动词的频率高低,特别是用于PO/DO中的相对频率,对双及物构式的习得有重要影响。然而,动词槽孔的分布偏向绝不是双及物构式选择的唯一决定因素[8],push和pull用于DO中的频率较低,但是在例(3a)和例(3b)的语境中,其DO的用法却为本族语者所接受[9]。
(3)a.As player A pushed him the chips,all broke loose at the table.
b.Nick joked. He pulled himself a steaming piece of the pie.
双及物构式的名词性论元/槽孔的分布偏向虽然没有得到学者们同等的重视,但是却对双及物构式选择的研究有着不可忽视的影响作用,Collins(1995)[10]、Gries(2003)[11]、Arnold(2000)[12]、何晓炜(2008)[13]、王寅(2011)[14]等学者都对此进行过理论探讨或实证探究。具有不同语义和语篇特征的双及物构式名词性论元——接受者(recipient)和客体(theme)有着不同的分布偏向:非定指的、非代词的、含新信息的、无生命的、抽象的、词数多的名词性论元通常被置于定指的、代词性的、含旧信息的、有生命的、具体的、词数少的论元之后。例(1b)和例(2a)因为违背了接受者和客体的分布偏向,所以很少被使用;而例(3a)和例(3b)虽然用了push和pull这两个高频PO动词,但是因为接受者和客体的语义、语篇特征符合DO的分布偏向,因此成了合理的使用。DO/PO中接受者和客体的分布偏向见图1。

图1 DO/PO中接受者和客体的分布偏向
(二)分布偏向习得研究
国外学者在母语习得领域对双及物构式名词性论元的分布偏向进行了大量的实证探索。Marneffeetal. (2012)考察了母语为英语的儿童及他们的父母对双及物构式中接受者和客体两个论元的语义、语篇特征的分布偏向的敏感程度,统计数据表明儿童从很早起就对多种分布偏向敏感,并且在对每种分布偏向的敏感程度上与父母相似,这说明儿童能注意到儿向语中复杂的分布特征[15]。Stephens(2015)也发现了儿童能对输入中的名词性论元的语义、语篇特征的分布偏向进行分析概括,并在此基础上输出双及物构式[16]。
目前,国内鲜有实证研究考察名词性论元的语义、语篇特征的分布偏向对中国英语学习者双及物构式习得的影响,且国内学者的研究尚未深入细致地考察多种分布偏向间的相互作用、多种分布偏向的相对作用和共同作用。之前的研究如杨江锋(2013)[17]、王琳琳(2013)[18]等,只考察了每种分布偏向独立于其他分布偏向的“绝对”影响力大小,而Logistic二元回归模型统计的是每个自变量相对于其他自变量的“相对作用力”。本文采用Logistic二元回归模型,同时统计分析6种分布偏向(定指性definiteness、代词性pronominality、可及性accessibility、生命度animacy、具体性concreteness、成分长度length)对双及物构式选择的共同作用力和相对作用力,并建立教材语料库,旨在发现中国英语学习者是否对输入中展现的名词性论元的语义、语篇特征的分布偏向敏感。本文的具体研究问题为:
1)中国英语学习者对双及物构式的选择是否同时受到多种语义、语篇特征的分布偏向的影响?如果是,那么影响中国英语学习者双及物构式选择的分布偏向是否与教材语料一致?
2)各分布偏向的影响强度——对中国英语学习者双及物构式选择的预测力大小是否与教材语料一致?
3)中国英语学习者敏感的分布偏向的类别是否随二语水平的提高而增加?习得早的分布偏向对双及物构式选择的影响强度是否大于习得晚的分布偏向?
三、研究方法
(一)语料来源
本文选取中国学习者英语语料库(CLEC)[19]中的高中(st2)和大学英语专业三四年级(st6)两个部分的语料作为低水平中国英语学习者和高水平中国英语学习者的英语输出的数据来源,高中(st2)和大学英语专业三四年级(st6)的语料库容量各为20万词。
中国学习者英语语料库建库期间(1995—2000),人教版JuniorEnglishforChina和SeniorEnglishforChina为全国中学生统一使用的初高中英语教材,因而人教版的英语教材与中国学习者英语语料库中高中学生的输出语料(st2)存在共时性对应关系。鉴于双及物构式表达“所有物转移”是基本概念,中国英语学习者在初中阶段就开始频繁接触这一构式,所以笔者研究团队搜集录入了人教版初中和高中英语教材,语料容量为30万词,以此作为本文低水平中国英语学习者的英语输入的数据来源。虽然教材不能完全覆盖低水平中国学习者的英语输入,但是在20世纪90年代末互联网尚未普及的现实下,学校英语教材是中学生主要的英语输入来源。中国学习者英语语料库的高水平英语学习者为大学英语专业三四年级学生(st6),其英语输入来源广泛,若将高水平学习者的英语输入局限于教材显然不合理,故本文暂不考虑高水平学习者的输入情况。
(二)统计模型
Logistic二元回归模型适用于因变量为二分类的案例,在语言学领域被应用于二元转换的语言现象,如双及物构式选择、属格转换、主动/被动语态转换等。本研究中,Logistic二元回归模型考察在一系列既定的相互作用的自变量的影响下,某一构式被选择产出的概率大小,同时描述各自变量作用的大小及方向。回归模型如下:
①P=exp(z)/(1+exp(z)) ②z=Logit(P)=ln(P/(1-P))=β0+β1X1+β2X2+β3X3+…+βnXn
等式①中的P代表因变量中某一取值出现的概率:当1>P>0.5时,Logit(P)>0,模型预测结果为阳性(y=1);当0.5>P>0时,Logit(P)<0,模型预测结果为阴性(y=0)。等式②中的z为概率P经Logit变换后的值,即为概率P优势比的对数值,该等式描述了一系列自变量间的联系(X1,X2,X3,…Xn)。当所有自变量的值全为0时,由常数项β0单独决定结果概率;系数βn的数值和正负分别代表每个自变量Xn的作用力(预测力)大小及方向;exp(βn)是优势比(odds ratio,OR),表示自变量Xn每变化一个单位时,阳性结果(y=1)出现概率与不出现概率的比值是变化前的相应比值的倍数[20]165。
(三)检索方法及定义变量
用Tree-tagger2.0赋码工具对教材语料库和学习者语料库的st2、st6部分进行词性标注,根据DO/PO构式的词性组合,采用词性检索法,用语料库检索工具AntConc3.2.1提取出语料库中所有DO/PO构式,辅以人工筛选。鉴于Logistic模型对样本量有严格的要求,因变量中较少的那一类的数量除以10,就是模型中可以分析的自变量数量。本文从3个语料库中随机选取了3组容量为300的样本,其中DO和PO各占一半。最后,根据变量的定义标准,手动标记样本中DO/PO构式的接受者和客体的语义、语篇特征。
本文将要考察的6种分布偏向分别是定指性、代词性、可及性、生命度、具体性、成分长度,其中,只有成分长度是连续变量,其他都是二分类变量。参照Bresnan(2007)[9]79和Marneffeetal. (2012)[15]33-36对变量的定义方法,5种分类自变量的赋值水平如下:定指性(0=definite;1=indefinite),代词性(0=pronoun;1=nonpronoun),可及性(0=given;1=nongiven),生命度(0=animate;1=inanimate),具体性(0=concrete;1=nonconcrete)。因变量“双及物构式的选择”赋值水平为(y=0,DO;y=1,PO)。鉴于不具体的或抽象的接受者几乎不会出现在语言实际使用中,本文暂不考察接受者的具体性。
四、研究结果
笔者对从3个语料库中检索出的双及物构式的各项分布偏向进行手工标记,标记的数据录入SPSS统计软件,用Logistic二元回归模型对低水平中国英语学习者、高水平中国英语学习者及教材3组语料库数据的分析结果如下:
(一)低水平中国英语学习者(Low Proficiency,LP)
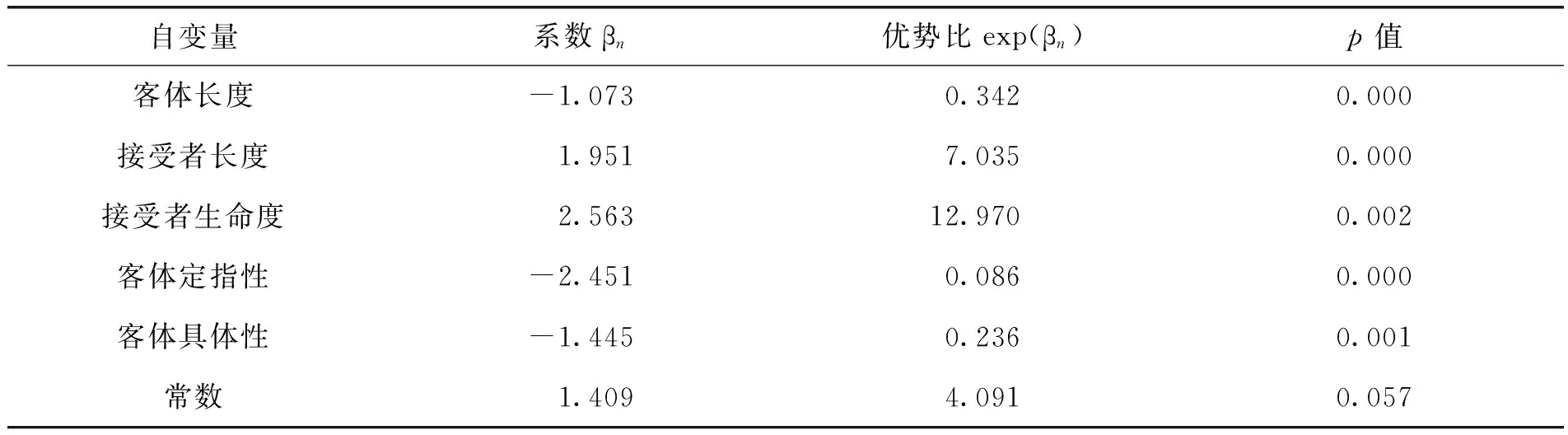
建立Logistic二元回归模型时,应该尽量引入对因变量有影响作用的变量,本文采用向后最大偏似然估计法,依次剔除p值最大且无统计学意义的候选变量,如此反复,直至再剔除变量就会显著降低模型拟合度[15]37。最终筛选出的5个自变量分别为:客体长度、接受者长度、接受者生命度、客体定指性以及客体具体性(见表1)。
表1 Logistic回归方程中的变量(LP)
自变量系数βn优势比exp(βn)p值客体长度-1.0730.3420.000接受者长度1.9517.0350.000接受者生命度2.56312.9700.002客体定指性-2.4510.0860.000客体具体性-1.4450.2360.001常数1.4094.0910.057
根据模型对系数的估计,各自变量对阳性结果(y=1,PO)出现的影响得以量化,系数的正负与大小反映了自变量影响的方向与程度。非具体、非定指的客体减小了PO出现的概率,而非生命体的接受者增大了PO出现的概率;接受者的长度与PO出现的概率成正比,而客体的长度与PO出现的概率成反比(见图2)。这5个自变量对PO/DO构式选择的预测与图1的分布偏向一致,说明低水平中国英语学习者对双及物构式中客体的长度、定指性、具体性以及接受者的长度、生命度这5项分布偏向敏感。表1中的常数即为前文等式②中的β0,当所有自变量取0值时,由常数项单独决定模型预测结果,即Logit(P)=1.409,Logit(P)>0时,模型预测结果为阳性(y=1,PO)。
自变量的系数可以转换为优势比,反映了PO/DO出现的相对概率,优势比的值域为0到∞,当其值大于1时,PO出现的概率增加,反之,DO出现的概率增加。例如,当接受者是非生命体时,PO出现的概率是DO的e2.563=12.970倍(见表1中的优势比项)。系数的绝对值体现了自变量对因变量的影响程度大小为:接受者生命度>客体定指性>接受者长度>客体具体性>客体长度。

图2 Logistic回归方程(LP)
Logistic回归方程的拟合效果可通过对因变量类别预测的正确率来判断(见表2)。低水平中国英语学习者的Logistic回归方程对DO预测的正确率达90.7%,对PO预测的正确率达88.7%,总体正确率为89.7%,拟合效果优良。
表2 Logistic回归方程的预测正确率(LP)

观察的构式预测的构式(界值=0.5)DO=0PO=1正确率DO=01361490.7%PO=11713388.7%总体正确率89.7%
(二)高水平中国英语学习者(High Proficiency,HP)
采用向后最大偏似然估计法,筛选出客体长度、接受者长度、接受者代词性、接受者可及性、接受者生命度、客体定指性、接受者定指性及客体具体性这8个自变量进入高水平中国英语学习者双及物构式选择的Logistic二元回归模型(见表3)。
表3 Logistic回归方程中的变量(HP)

自变量系数βn优势比exp(βn)p值客体长度-0.9880.3720.000接受者长度1.3183.7340.000

续表
注:接受者代词性这一变量的p值虽未达到p<0.05的显著水平,但是筛除这一变量将使模型的预测准确率或拟合度显著降低,因而被保留。
高水平学习者在双及物构式的接受者为非定指、无生命、新信息、非代词,或其长度增加时,选择PO构式的可能性增大;在客体为非具体、非定指或其长度增加时,选择DO构式的可能性增大(见图3)。这8个自变量所呈现的作用力方向与图1的分布偏向一致,说明高水平中国英语学习者对这8项分布偏向敏感。根据这8个自变量系数的绝对值大小,可知各自变量对因变量的影响程度大小为:接受者生命度>客体定指性>接受者定指性>接受者可及性>接受者长度>客体具体性>接受者代词性>客体长度。

图3 Logistic回归方程(HP)
高水平中国英语学习者的Logistic回归方程对DO预测的正确率达94.7%,对PO预测的正确率达91.3%,总体正确率为93.0%,拟合效果优良。
(三)人教版初高中教材语料库的统计数据(Textbooks,TB)
8个自变量经筛选进入了教材语料的Logistic回归方程,且作用力方向均与图1一致,按作用力由大到小排列为:接受者长度、接受者生命度、客体代词性、接受者代词性、客体可及性、客体定指性、客体具体性、客体长度(见表4、图4)。只有3个自变量未被筛选进入模型——接受者可及性、客体生命度、接受者定指性,说明语义、语篇特征的分布偏向在教材语料中得到了相对全面的展现。
表4 Logistic回归方程中的变量(TB)
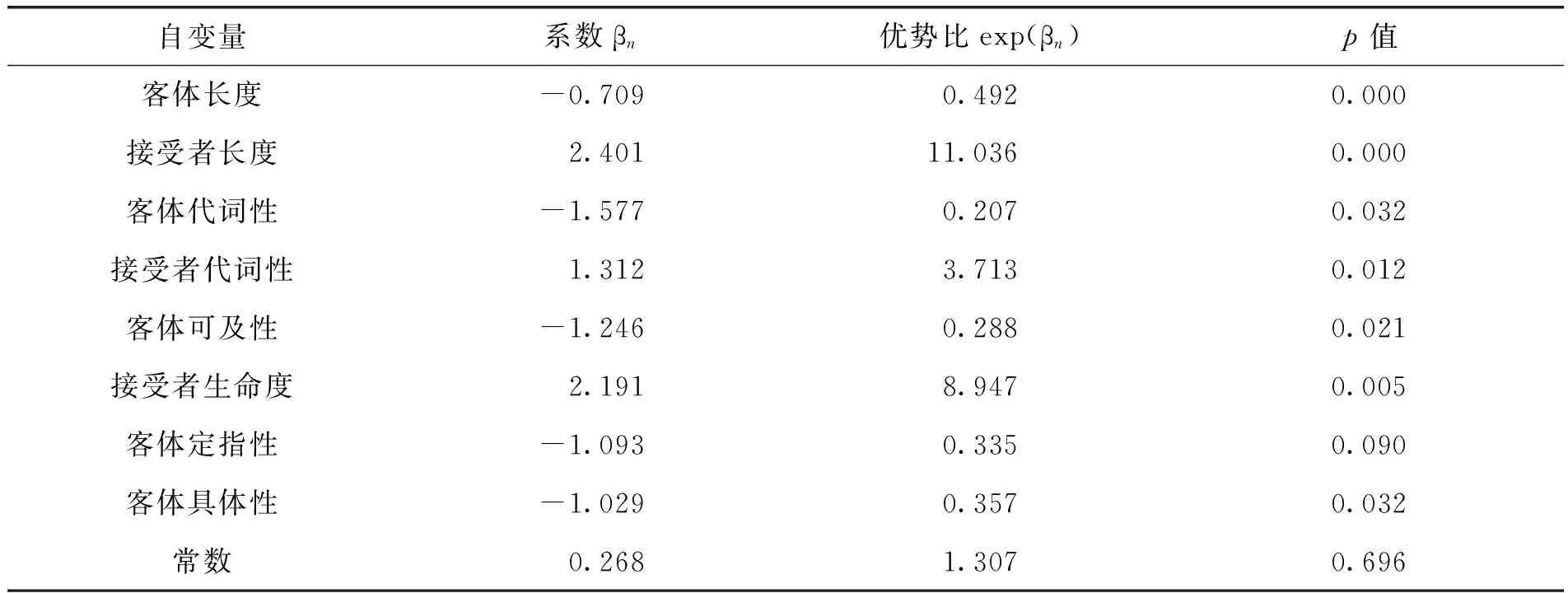
自变量系数βn优势比exp(βn)p值客体长度-0.7090.4920.000接受者长度2.40111.0360.000客体代词性-1.5770.2070.032接受者代词性1.3123.7130.012客体可及性-1.2460.2880.021接受者生命度2.1918.9470.005客体定指性-1.0930.3350.090客体具体性-1.0290.3570.032常数0.2681.3070.696
注:客体定指性这一变量的p值虽未达到p<0.05的显著水平,但是筛除这一变量将使模型的预测准确率或拟合度显著降低,因而被保留。
值得注意的是,在本文考察的11个自变量中,只有客体生命度未进入任何一组样本的回归模型。相反,接受者生命度在2组中国英语学习者的模型中是具有最强预测力的自变量,而在教材语料模型中其预测力也仅次于接受者长度。这说明,同一语义特征在不同论元上对双及物构式选择的影响并非是平衡均等的。

图4 Logistic回归方程(TB)
教材语料的Logistic回归方程对DO预测的正确率达94.7%,对PO预测的正确率达87.3%,总体正确率为91.0%,拟合效果优良。
五、讨论
(一)低水平学习者输出与输入的教材语料所展现的分布偏向
影响低水平学习者双及物构式选择的5项分布偏向由强到弱排列为:接受者生命度、客体定指性、接受者长度、客体具体性、客体长度。教材语料的8项分布偏向按影响强弱排列为:接受者长度、接受者生命度、客体代词性、接受者代词性、客体可及性、客体定指性、客体具体性、客体长度。低水平学习者敏感的5项分布偏向在教材中都有体现,并且这5项分布偏向对双及物构式选择的影响力强弱与教材基本一致,除了接受者长度在教材语料中是影响力最大的分布偏向,系数为2.401,即接受者每增加一个词长,PO出现的概率就增加e2.401=11.036倍。但接受者长度在低水平学习者语料中的影响力却小于接受者的生命度和客体的定指性,系数为1.951,即接受者每增加一个词长,PO出现的概率就增加e1.951=7.035倍。经独立样本t检验发现,客体长度在低水平学习者语料和教材语料中并无显著差异,而接受者长度在2组语料中的差异达到显著水平(p<0.05,见表5)。接受者长度在2组语料中的显著差异可能是其系数变化的原因之一,同时,各分布偏向间复杂的相互作用也影响着其系数的变化。
表5 客体长度与接受者长度在输入与输出中的差异(LP/TB)

客体长度低水平学习者教材接受者长度低水平学习者教材平均长度2.882.891.752.01标准差1.8212.0611.4241.779p值0.9670.046*
注:*p<0.05。
其余4项分布偏向对双及物构式选择的相对影响强弱在2组语料中是一致的:接受者生命度>客体定指性>客体具体性>客体长度。单独考察每项分布偏向影响下的双及物构式分布,可以发现低水平学习者语料和教材语料间更具体的联系。图5中的x轴代表每个自变量的2个取值水平,y轴代表Logit(P)的值域,即PO构式出现概率优势比的对数值。因变量的赋值水平为(y=0,DO;y=1,PO),Logit回归模型默认的界值(cut value)是0.5,概率P在(0,0.5)区间时,PO构式出现概率优势比的对数的值域为(-∞,0),模型预测结果为DO;概率P在(0.5,1)区间时,PO构式优势比的对数的值域为(0,+∞),模型预测结果为PO。
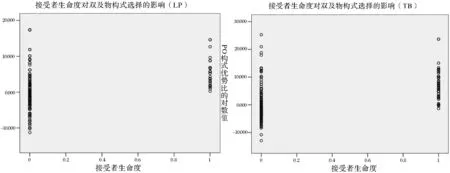
图5 既定变量下的PO优势比对数值散点图(LP/TB)
如图5所示,接受者为生命体时(0=animate),散点在y轴0点上下的分布没有明显区分,并未如理论预测的集中分布于y轴0点下方,即偏好选择DO;当接受者为非生命体时(1=inanimate),散点出现了以y轴0点为分界线的理想分布,可见此分布偏向对双及物构式选择的影响强弱在2个取值水平上存在差异,非生命体的接受者较生命体的接受者而言,发挥了更大的区分选择作用。因此,不仅不同论元的同一分布偏向存在影响强度差异,即客体的生命度为无影响因素,而接受者的生命度却发挥了较强的影响,而且这种影响强度差异也存在于同一论元的同一分布偏向的不同取值水平上。
表6 代词性/可及性/定指性的相关系数(LP/TB)

代词性/可及性客体接受者代词性/定指性客体接受者可及性/定指性客体接受者 低水平组0.400**0.450**0.659**0.437**0.517**0.397**高水平组0.550**0.375**0.718**0.523**0.408**0.183**教材组0.431**0.483**0.684**0.402**0.469**0.357**
注:**p<0.01。
低水平学习者组和教材组的客体的定指性虽然在各分布偏向的相对影响力排序中没有变化,但是其影响力系数在2组模型中有较大差异。当客体为定指时,教材组的回归模型预测PO出现的概率是DO的e-1.093=0.335倍,即DO是PO的0.335-1=2.99倍;低水平学习者组的回归模型预测PO出现的概率是DO的e-2.451=0.086倍,即DO是PO的0.086-1=11.63倍。客体定指性在低水平组比在教材组中对双及物构式的选择发挥了更大的影响。低水平学习者对教材语料中所展现的客体代词性、接受者代词性与客体可及性这3项分布偏向不敏感。可及性与代词性和定指性有着较高的一致性或相关性:旧信息通常是代词,且为定指;新信息通常是非代词,且为非定指。本文对3个语料库的接受者和客体的代词性、可及性与代词性进行了相关性分析,结果显示这3类分布偏向的相关系数在3个语料库中都达到p<0.01的显著性水平(见表6)。由此可知,进入教材组回归模型中的客体代词性、接受者代词性和客体可及性与客体定指性在双及物构式选择中发挥了协同作用,客体定指性在教材组中对结果的预测作用被分散,因而其影响强度小于低水平学习者组模型中客体定指性的影响强度。
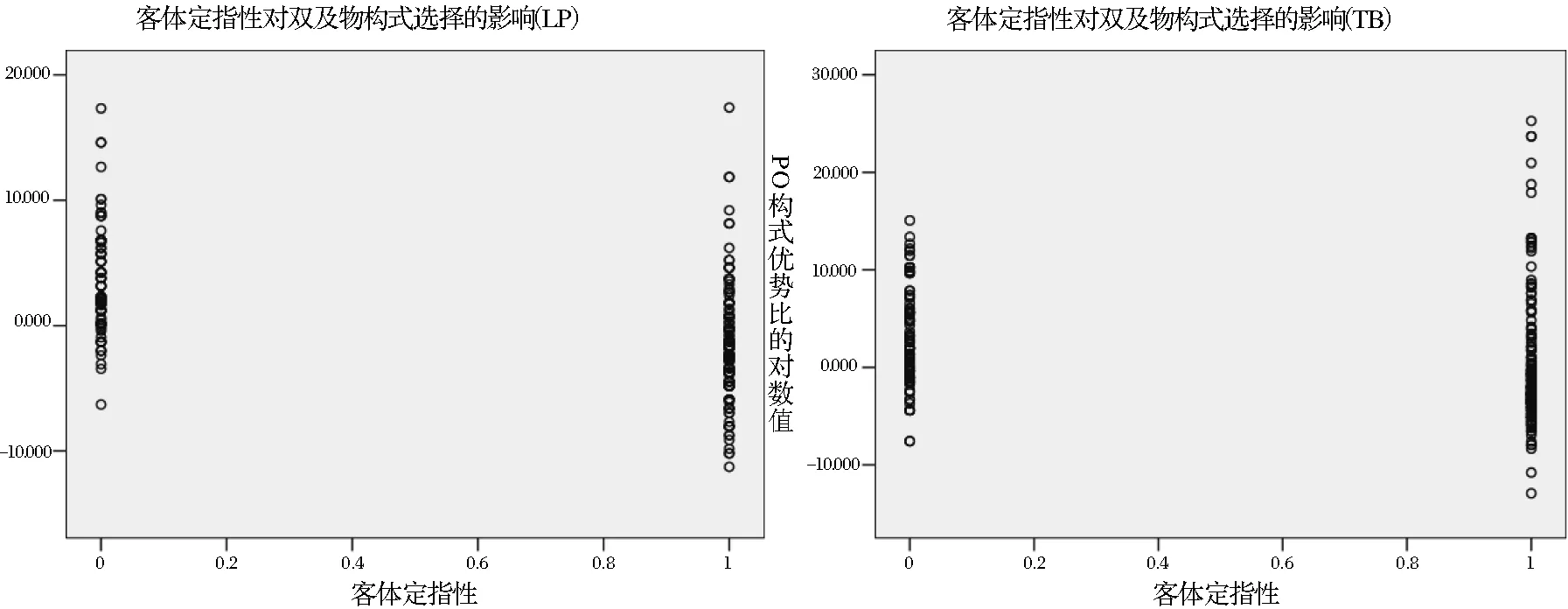
图6 既定变量下的PO优势比对数值散点图(LP/TB)
散点图为考察客体定指性对双及物构式选择的影响提供了更为微观的视角。如图6所示,当客体为定指时(0=definite),散点总体上集中于y轴0点上方区域,此时,回归模型的预测结果为PO;当客体为非定指时(1=indefinite),散点在y轴0点上下的分布无明显差异,换言之,非定指的客体在PO和DO中出现的概率相似。客体定指性与接受者生命度一样,其不同的取值水平对双及物构式选择的影响强度是不对称的,存在显著差异。
客体具体性对结果的预测力在教材组和低水平组中都仅大于最弱预测力分布偏向,即客体的长度。在教材组回归模型中,客体具体性的影响系数为-1.029;而在低水平组模型中,其影响系数为-1.445。非具体客体在教材组中出现于DO中的概率是PO的0.357-1=2.80倍,在低水平组中出现于DO中的概率是PO的0.236-1=4.24倍。可见,DO和PO的客体具体性并无显著差异。如图7所示,客体为具体物时(0=concrete),散点确实更倾向于分布于y轴0点上方;且当客体为抽象物时(1=nonconcrete),散点更集中于y轴0点下方,但客体具体性的2个取值水平上的散点并未如接受者生命度和客体定指性一样呈现出较为明显的以y轴0点为分界线的单向分布。简言之,客体的具体性对双及物构式选择具有一定的影响,但其区分力和预测力次于接受者生命度和客体定指性。

图7 既定变量下的PO优势比对数值散点图(LP/TB)
低水平中国英语学习者所敏感的5项分布偏向不仅在其所输入的教材语料中有所体现,且其中4项分布偏向的相对影响力强弱在2组回归模型中一致。此外,输入与输出间的复杂联系也体现在了更微观的层面上,相同论元的同一分布偏向的不同取值水平上存在的预测力强度差异在低水平学习者和教材数据中也保持了高度的一致。
(二)低水平学习者与高水平学习者输出语料所展现的分布偏向
影响高水平学习者双及物构式选择的8项分布偏向由强到弱排列为:接受者生命度、客体定指性、接受者定指性、接受者可及性、接受者长度、客体具体性、接受者代词性、客体长度。低水平组语料的5项分布偏向按影响强弱排列为:接受者生命度、客体定指性、接受者长度、客体具体性、客体长度。低水平组的5项分布偏向在高水平组语料中都得到了体现,且这5项分布偏向间的相对影响力强弱与高水平组一致。
表7 客体长度与接受者长度在高低水平组中的差异(LP/HP)

客体长度低水平组高水平组接受者长度低水平组高水平组平均长度2.883.181.752.46标准差1.8212.2981.4242.446p值0.044*0.000**
注:*p<0.05,**p<0.01。
如表7所示,高水平组学习者产出的双及物构式中的客体和接受者总体上长于低水平组,且2个水平组的长度差异均达到显著性水平。高水平组学习者随着二语水平的提高,能更加频繁地使用非谓语、定语从句等来说明客体和接受者,因此,接受者与客体的长度显著增加,例如:
(4)a.Our purpose is to give everybody a belief that only making people realize that crime is terrible,not divine and crime does not pay is the right way to deal with crime. (CLEC-st6)
b.More and more Battered Women Shelters are established in the world,with the purpose to give some help to the women who have suffered bad treatment of their husbands. (CLEC-st6)
接受者生命度在低、高水平组中的影响力系数分别为2.563和3.767,当接受者为非生命体时(1=inanimate),PO在低、高水平组出现的概率分别是DO的e2.563=12.970倍和e3.767=43.250倍。在高水平组,接受者生命度对结果的预测力显著增强。如图8所示,当接受者为非生命体时,2组的散点都集中分布于y轴0点上方,但高水平组在此取值水平上的散点数量明显多于低水平组,即高水平组使用了更多更具区分力的非生命体接受者,因而该分布偏向在高水平组中发挥了更强的预测力。李昱(2015)[21]认为生命度作为语义特征,是一个特征范畴,具有清晰的边界,较定指性、代词性、可及性等句法语用特征而言,具有更可靠、更广泛的跨语言共性,因而成了二语学习者习得与格转换这一语言现象时的有效线索;而定指性在汉语中是一个原型范畴,汉英在有定/无定这一对范畴的具体实现形式以及范畴化程度上都有显著差异。下文将考察低水平和高水平学习者在利用定指性这一线索来启动相应的双及物构式的异同。
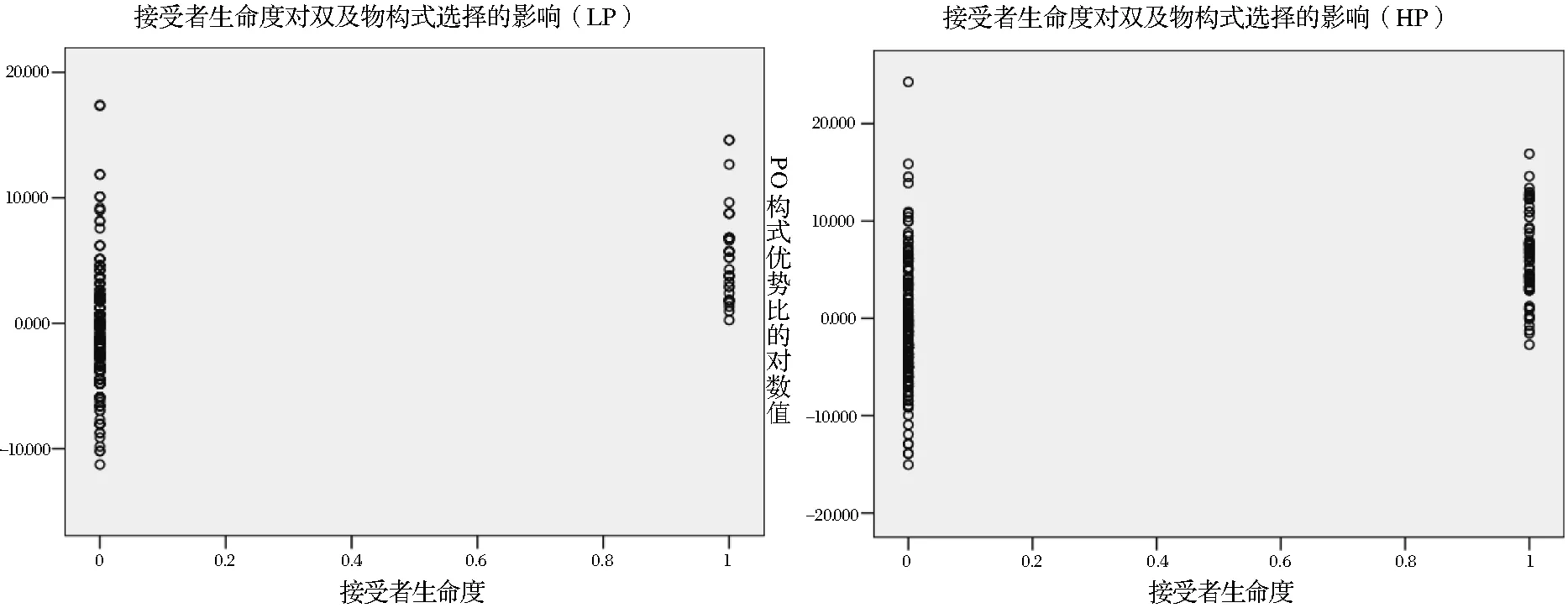
图8 既定变量下的PO优势比对数值散点图(LP/HP)
客体的定指性和接受者的定指性都进入了高水平组的回归模型,但在低水平组中接受者定指性未被筛选进入回归模型。如图9所示,高水平组的接受者定指性散点图再次展现了结果预测力的不均衡,这不仅体现在不同论元的同一分布偏向间,还体现在相同论元的同一分布偏向的不同取值水平间。当接受者为非定指(1=indefinite)时,散点密集分布于y轴0点上方区域,呈现出较为清晰的以y轴0点为分界线的单向分布,即非定指的接受者相对专一地出现在PO中。然而,定指的接受者没有表现出对PO或DO的明显偏好。据此,虽然定指性在汉英中存在较大差异,但中国英语学习者在其高水平阶段掌握了该分布偏向在双及物构式选择中的作用。

图9 既定变量下的PO优势比对数值散点图(HP)
高水平学习者比低水平学习者更频繁地使用非具体的客体,如图10所示,高水平组中非具体(1=nonconcrete)水平上的散点数量明显多于低水平组。低水平学习者在使用双及物构式时,多表达实物转移的概念,而高水平学习者更多地描述抽象概念的转移。客体的具体性在本文的3组回归模型中都属于影响力强度较弱的分布偏向,因而在与其他敏感的分布偏向共同预测结果时,常常受到其他分布偏向的压制。如例(5a),虽然客体为抽象概念,但是受到接受者的代词性、长度、可及性以及客体的长度等因素的制约,最终在多因素共同作用下,PO被选择;例(5b)也展现了其他分布偏向对客体具体性的制约,如接受者生命度、长度等。客体具体性虽然在高水平组没有明确偏好DO或PO,但这恰恰证实了双及物构式的选择的确受到多重因素的综合影响。
(5)a.In the same way the legalization of euthanasia will show its importance to the nation’s development. (CLEC-st6)
b.Though she has normal intelligence,this will only bring sorrow,frustration to her innocent mind. (CLEC-st6)
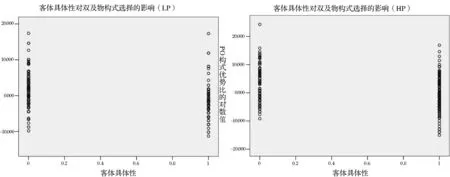
图10 既定变量下的PO优势比对数值散点图(LP/HP)
高水平组还对低水平组数据中未展现出的接受者的定指性、可及性与代词性这3项分布偏向敏感。接受者的定指性与可及性在Logistic回归方程中的系数大于早先习得的接受者长度、客体具体性和客体长度的系数,接受者代词性的系数也大于早先习得的客体长度的系数,说明各分布偏向被习得的先后顺序与其对双及物构式选择的影响力或预测力没有直接的因果关系。新的分布偏向被习得后,与早先被习得的分布偏向又发生复杂的相互作用和相互压制,因而习得的分布偏向的作用力不是固定不变的,而是动态变化的。
六、结语
双及物构式的习得涉及一个逐渐强化共同出现的语言成分之间的联系的过程,在这一过程中,共同出现的含不同语义和语篇特征的接受者和客体之间的联系也得到不断的强化。本研究在一定程度上论证了Marneffeetal. (2012)[15]54的发现,输出中各项分布偏向对双及物构式选择的影响力排序与输入基本一致。低水平中国英语学习者对输入中复杂的语义和语篇信息及其分布特征敏感,并在输出双及物构式时,基本复制了输入中对各分布偏向相对作用力的赋值。输入与输出的联系体现在了更微观的层面,即相同论元的同一分布偏向的不同取值水平上存在的预测力强度差异在低水平学习者和教材数据中也保持了高度一致。另外,语言学习是个循序渐进的、动态的过程,语言中某一方面的变化可能会导致其他方面的改变。随着二语水平的提高,接受者和客体的长度增加,其相对作用力的系数也发生了改变。高水平学习者比低水平学习者习得了更多的分布偏向,分布偏向的作用力大小与习得顺序无关,因为分布偏向间存在的相互作用和相互压制在不断重新权衡和分配现已习得的分布偏向的影响强度。
[1]Perek F. Argument Structure in Usage-based Construction Grammar[M]. Amsterdam:John Benjamins,2015.
[2]Ellis N. Frequency effects in language processing:A review with implications for theories of implicit and explicit language acquisition[J]. Studies in Second Language Acquisition,2002 (24):143-188.
[3]Tomasello M. Constructing a Language:A Usage-based Theory of Language Acquisition[M]. Cambridge:Harvard University Press,2003.
[4]Inagaki S. Japanese and Chinese learners’ acquisition of the narrow-range rules for the dative alternation in English[J]. Language Learning,1997 (47):637-669.
[5]Mazurkewich I,White L. The acquisition of the dative alternation:Unlearning overgeneralizations[J]. Cognition,1984 (16):261-283.
[6]Ambridge B,Pine J,Rowland C,et al.. The roles of verb semantics,entrenchment,and morphology in the retreat from dative argument-structure overgeneralization errors[J]. Language,2012 (88):45-81.
[7]韩百敬,薛芬. 中国英语学习者对英语与格转换的习得研究[J]. 外语教学与研究,2014 (46):759-770.
[8]许琪. 相对频率对中国英语学习者习得介词与格结构的作用[J]. 外语教学与研究,2012 (5):706-718.
[9]Bresnan J,Cueni A,Nikitina T,et al.. Predicting the dative alternation[C]//Boume G,Kramer I,Zwarts J (eds.). Cognitive Foundations of Interpretation. Amsterdam:Royal Netherlands Academy of Science,2007:69-94.
[10]Collins P. The indirect object construction in English:an informational approach[J]. Linguistics,1995 (33):34-49.
[11]Gries S T. Towards a corpus-based identification of prototypical instances of constructions[J]. Annual Review of Cognitive Linguistics,2003 (1):1-27.
[12]Arnold J,Wasow T,Losongco A,et al.. Heaviness vs. newness:the effects of complexity and information structure on constituent ordering[J]. Language,2000 (76):28-55.
[13]何晓炜. 双及物结构句式选择的制约因素研究[J]. 语言教学与研究,2008 (3):29-36.
[14]王寅. 构式语法研究(下卷):分析应用[M]. 上海:上海外语教育出版社,2011.
[15]Marneffe M C,Grimm S,Arnon I,et al.. A statistical model of the grammatical choices in child production of dative sentences[J]. Language and Cognitive Process,2012 (27):25-61.
[16]Stephens N. Dative constructions and givenness in the speech of four-year-olds[J]. Linguistics,2015(3):405-442.
[17]杨江锋. 基于SWECCL的中国英语学习者与格换位结构的习得研究[J]. 外语与外语教学,2013 (6):53-57.
[18]王琳琳. 基于多语体语料的英语双及物结构研究——以give为例[J]. 外国语,2013 (36):45-54.
[19]桂诗春,杨惠中. 中国学习者英语语料库[M]. 上海:上海外语教育出版社,2002.
[20]张文彤,董伟. SPSS统计分析高级教程(第2版)[M]. 北京:高等教育出版社,2013.
[21]李昱. 语言共性和个性在汉语双宾语构式二语习得中的体现[J]. 语言教学与研究,2015 (1):10-21.
AStudyonChineseEFLLearners’ChoicebetweenDitransitiveConstructionsBasedontheLogisticRegressionModel
YANMinfen,ZHOUQianqian
(SchoolofForeignStudies,JiangnanUniversity,Wuxi214122,China)
In this study,two sub-corpora in CLEC,namely st2 and st6,are adopted as the data sources for low proficient and high proficient learners’ output. A textbook corpus is built as the data source for low proficient learners’ input by the authors’ research team. Ditransitive constructions are first searched in three corpora. The binary logistic regression model is employed to analyze the relative and collective effects of six distributional biases in Chinese EFL learners’ production of ditransitive constructions,investigating if Chinese learners are sensitive to multiple distributional biases present in their input which constrain the choice between two ditransitive constructions. Results show learners’ choices are influenced by multiple biases and the pattern is similar to that in their input. Additionally,the parallel between input and output exists in a more specific and microcosmic way. High proficiency learners do acquire more distributional biases and the acquisition order exerts no influence on the relative effects of biases due to their interactions and coercion. These findings demonstrate the dynamic nature of language acquisition,which takes place incrementally,and learners are capable of picking up on the complicated cues present in their input.
ditransitive construction;choice of constructions;binary logistic regression model;distributional biases
H319
A
2095-2074(2015)05-0041-13
2015-09-01
江苏省普通高校研究生科研创新计划项目(KYZZ_0314)
严敏芬(1964-),女,江苏张家港人,江南大学外国语学院教授,文学博士;周倩倩(1990-),女,江苏启东人,江南大学外国语学院英语语言文学专业2013级硕士研究生。
