基于nave DD模型的财务困境预测
——来自制造业上市公司的经验数据
2015-09-17广东外语外贸大学广东广州510006
(广东外语外贸大学 广东广州510006)
一、引言
证券市场上总有相当比例的挂牌公司因为自身原因或外部原因而陷于经营困境之中,对企业的财务困境进行预测,有助于市场参与者更好地进行各种投资决策活动,避免遭受严重的损失。制造业作为衡量一个国家综合国力的重要标志,在国民经济的增长中发挥着重要作用。正确预测制造业上市公司的财务困境,有助于加快该行业的产业结构调整和升级,也有助于商业银行加强对制造业违约风险的防范。
目前,国际上关于企业财务困境预测的研究主要有3种方法或模型(Bauer&Agarwal,2014):(1) 基于会计信息的传统模型。主要是Altman(1968) 的 Z-score模型和 Ohlson(1980)的 Logistic 模型(孔德营、李晓峰,2012)。(2)基于市场信息的未定权益模型。该模型视债权为公司资产价值的一项看涨期权,以Black&Scholes(1973)和 Merton(1974)的期权定价理论为基础。(3)同时包含会计信息和市场信息的风险模型。Beaver,Mc-Nichols和 Rhie(2005)指出同时包含市场变量和会计变量的模型更具有综合性,会提高公司违约预测的有用性。
鉴于Merton模型较易被改进,美国 Mood’s KMV公司对 Merton模型做了进一步拓展,得出KMV模型,运用该模型可以对上市公司违约的可能性做出预测。关于Merton模型的另一项重要改进是Bharath&Shumway(2008)的na1ve DD模型,该模型假设债务的市场价值等于债务的面值,该模型的计算相对简单但是却和Merton DD模型拥有同样甚至更优的预测能力(Bharath&Shumway,2008)。
国内基于市场信息对财务困境预测的研究,主要是基于KMV模型进行的。包括两类:一类是不修正KMV模型,直接用国内的样本数据进行验证(马若微,2006);另一类则是在修正KMV模型的基础上,用国内的样本数据进行验证,以探求在我国的具体适用性 (鲁炜、赵恒珩、方兆本和刘冀云,2003;张泽京、陈晓红和王傅强,2007;张能福、张佳,2010;邹薇,2014 等)。 但是,较少有文献验证na1ve DD模型在我国上市公司的适用性。又由于行业特性,不同行业的违约距离存在着差异(曾诗鸿和王芳,2013)。因此,本文以制造业为例,研究na1ve DD模型对于财务困境预测的有效性,以期丰富国内的研究。

其中,V是公司资产价值,B为债务面值,μ为预期资产收益率,σv为公司资产价值的波动率,基于Merton模型正态分布的假定,预期违约概率(EDF)为:
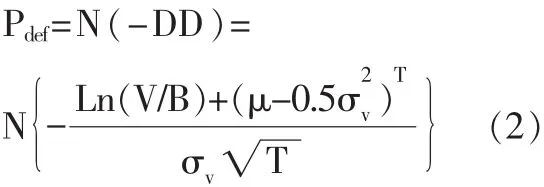
上述模型中,只有V和 σv是未知的。 在 Bharath&Shumway (2008)的nave DD模型中,假定债务市值等于债务面值,即公司资产价值(V)=权益市值(E)+负债面值(F)。 根据权益波动性和债务波动性之间的关系:

采用加权算法得到公司资产价值的波动性:

令公司期望收益率等于公司上年股票收益率,即:
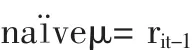
得出:


鉴于国内研究的惯例,本文只用违约距离来表示公司的违约情况,这样便于与国内学者的研究进行比较。即公司的nave DD越小,公司违约的概率越高。 Bharath&Shumway(2008)指出,nave DD模型要明显优于迭代算法及其他参数设定的Merton DD模型。
(一)样本选择
本文选择 2012、2013和 2014年首次被ST的制造业企业42个样本,筛选后得到31个ST样本,另外配对样本有31个,共62个样本,所有数据均来自于国泰安(CSMAR)数据库。筛选过程为:(1)考虑到 A股与 B、H 股市场的差异,剔除了4家同时发行A、B股或 H股的 ST公司;(2)由于需要验证被ST的前3年数据,因此需要剔除上市时间不满3年的公司,共3家;(3)根据会计年度、行业类别严格相等、资产规模相差在15%以内为标准,选择配对公司,共有4家公司找不到配对样本,予以剔除。
(二)关键参数的计算
1.权益价值的波动率σE。假设股票价格在第i天和第i+1天的价格分别为 Pi和 Pi+1,则股票收益率(μi)和日波动率(σ)分别为:
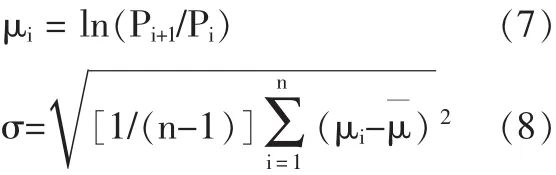
设年交易天数为Di,则年收益率标准差σE为:

2.股票年收益率rit-1。直接采用CSMAR数据库中的“不考虑现金股利再投资的年个股回报率”数据。
3.权益市值 E。由于我国特殊的国情造成了上市公司特殊的股权结构,因此我国学者研究了多种不同的方法解决非流通股的折算问题。本文借鉴曾诗鸿等(2013)的研究,将每股净资产与非流通股的股数的乘积作为非流通股的市值,即:权益市值(E)=流通股股数×年收盘价+非流通股股数×每股净资产。
4.债务面值 F。按照 Bharath&Shumway(2008)和多数学者的做法,设定F为流动负债与长期负债的一半之和,即:F=短期负债+0.5×长期负债。
5.到期时间 T。按照学者们研究的惯例,本文设定 T=1。
(三)结果分析
1.图形比较。图1是3年之间ST公司与非ST公司的na1ve DD的比较,从图中可以看出ST公司违约距离的值基本被包含在非ST公司的违约距离之内(注:黑线为非ST公司,灰线为ST公司)。
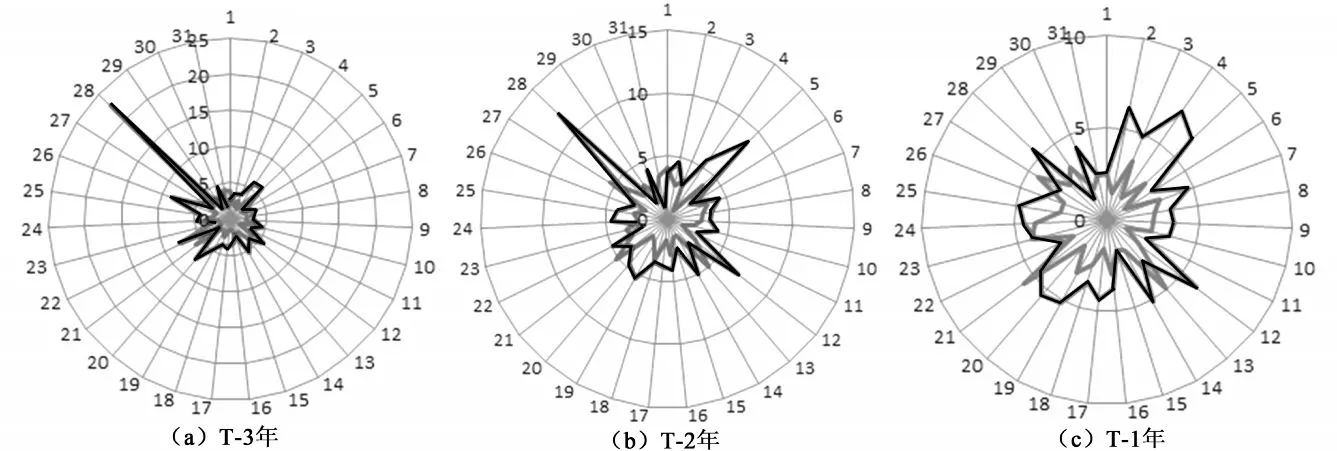
图1 ST公司与非ST公司naveDD的比较
2.配对样本T检验(见表1)。从ST公司和非ST公司两组样本进行的配对样本T检验的结果中可以看出,ST公司和非ST公司3年的均值差都在1%的水平上显著,说明在上市公司首次被ST的前3年的时间内,na1ve DD能显著地区别出ST公司和非ST 公司。 且 T-3、T-2、T-1年3年均值差异的显著性在逐渐增大,越是接近被ST的时候,违约距离均值的差异就越显著,这与张玲等(2004)的研究是一致的。因此,初步得出na1ve DD是一个适用于识别企业陷入财务困境的指标。

表1 样本均值差T检验

表2 logistic回归分析结果
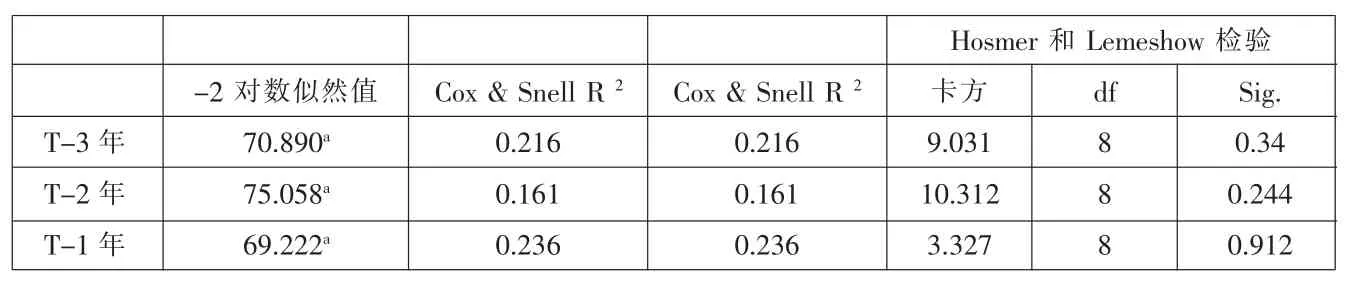
表3 回归模型的拟合指标
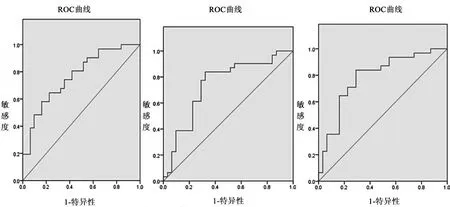
图2 ROC曲线
3.logistic回归分析(见表 2、表 3)。为了进一步证实na1ve DD具有判别公司是否发生财务困境的能力,以na1ve DD为自变量,以公司是否被ST作为因变量进行二元logistic回归。结果显示,公司在被ST的前3年,na1ve DD系数均显著为负,即na1ve DD与被ST(违约)的概率呈负相关,符合预期,其Hosmer和Lemeshow检验的结果也说明了na1ve DD的判别能力。

表4 ROC曲线面积
4.ROC曲线分析。用ROC曲线(ROC全名叫做 Receiver Operating Characteristic,可以用来判别模型的拟合程度,横轴表示实际是非ST公司但是却被预测为ST的比例,纵轴表示实际是ST公司、被预测为ST公司的比例。ROC曲线下的面积称为AUC,通常AUC的值越大,表示模型的准确度越高)来检验logistic回归模型的准确性。从上页图2和表4中可以看出,ROC曲线都在对角线以上,曲线下的面积都在0.7以上,且显著。ROC曲线下的面积在第T-1年时达到最大,说明越接近ST时,na1ve DD的预测能力越强,再次说明na1ve DD确实具有识别公司是否陷入财务困境的能力。
四、结论
本文以我国A股市场2012、2013和2014年首次被ST的制造业上市公司为研究样本,选取了公司被ST的前三年的数据,对na1ve DD模型预测财务困境的能力进行了研究,得出结论:na1ve DD模型能显著地区分出我国制造业上市公司中陷入财务困境的公司和尚未陷入财务困境的公司。但是本文的局限性在于:(1)不能根据公司na1ve DD的取值来判断公司所处的状态,即没有得出一个类似于Z-score模型的分割点;(2)没有将同作为Merton模型改进的na1ve DD模型与KMV模型进行对比,得出哪种模型预测能力更强。这些都将是后续研究的内容。
