基于局部变化性的改进编辑距离算法
2015-08-22王卫红
王卫红,李 君
(浙江工业大学计算机科学与技术学院,杭州310023)
·开发研究与工程应用·
基于局部变化性的改进编辑距离算法
王卫红,李 君
(浙江工业大学计算机科学与技术学院,杭州310023)
针对经典编辑距离算法在求解字符串相似度时计算效率过低的问题,提出一种改进的编辑距离算法。先求得2个字符串的最长公共前缀和最长公共后缀,再根据经典编辑距离算法得到2个字符串剩余部分之间的编辑距离,由反证法证明该编辑距离即为2个原始字符串的编辑距离。在此基础上,分析改进算法的优势并将其应用于网页篡改检测中。实验结果表明,与经典算法相比,改进算法在求解同一网址的网页相似度时具有更高的计算效率。
编辑距离;相似度;公共前缀;公共后缀;局部变化性;篡改检测
中文引用格式:王卫红,李 君.基于局部变化性的改进编辑距离算法[J].计算机工程,2015,41(7):294⁃298,304.
英文引用格式:Wang Weihong,Li Jun.Improved Edit Distance Algorithm Based on Local Variability[J].Computer Engineering,2015,41(7):294⁃298,304.
1 概述
字符串相似度问题在抄袭检测系统、数据清洗、信号处理、搜索引擎等领域具有广泛应用。根据计算所依据特征的不同,计算方法可以划分为3种方法[1⁃2]:基于字面相似的方法,基于统计关联的方法,基于语义相似的方法。基于编辑距离的相似度算法是基于字面相似方法中的一种,它从整体上考虑了文本上下文之间的语义关系,是一种经典而广为使用的方法。
近年来,对基于编辑距离相似度算法的研究偏重于算法效果的改善。比如考虑到字符串之间公共子串对相似度的影响,对相似度度量公式和编辑距离计算方法进行了改进[3]。可以通过拓展交换操作减少编辑操作的数量得到更理想的编辑距离[4]。针对中西文混合字符串,采用将汉字作为西文字符的等价单位、拼音编码、五笔编码3种方式计算编辑距离以获得更好的效果[5]。也有一些编辑距离在新领域的应用,比如将编辑距离应用于编程题自动评阅中[6]、改进编辑距离算法以解决网页搜索中简短域与用户查询之间相关性的排序问题[7]。考虑编辑距离算法计算效率这类问题比较少,比如基于Karp⁃Rabin和最长公共子串算法思想,可以使用串的散列值匹配来加快计算[8]。本文在这些算法的基础上,提出一种改进的编辑距离算法。
2 基于经典编辑距离算法的相似度计算
2.1 经典编辑距离算法
编辑距离是指由源字符串S转换到目标字符串T所需最少编辑操作数,所需要的操作数越少,2个字符串相关性越高。基本编辑操作有3种:(1)把串S中的一个字符替换为串T中的一个字符。(2)把串S中的一个字符删除。(3)在串 S中插入一个字符。
设2个字符串S=s1s2…sm和T=t1t2…tn。建立S与T的(m+1)×(n+1)阶矩阵LD:
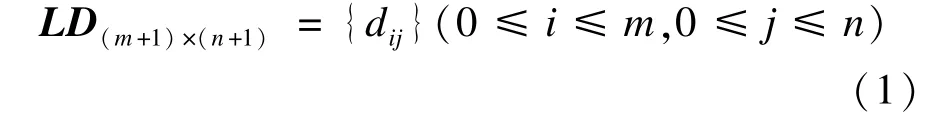
其中,di,j为s1s2…si和t1t2…ti之间的编辑距离。
可由以下公式求得矩阵LD中的di,j:
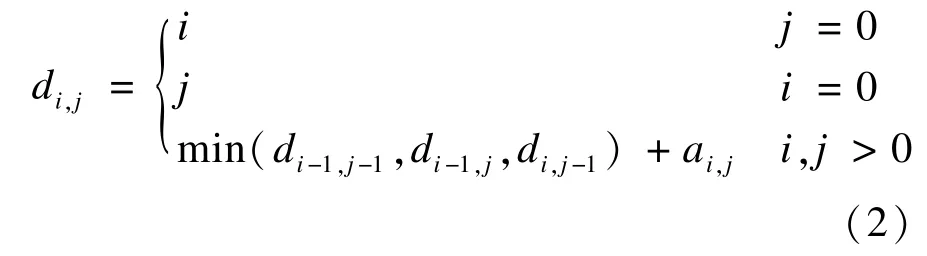
其中:
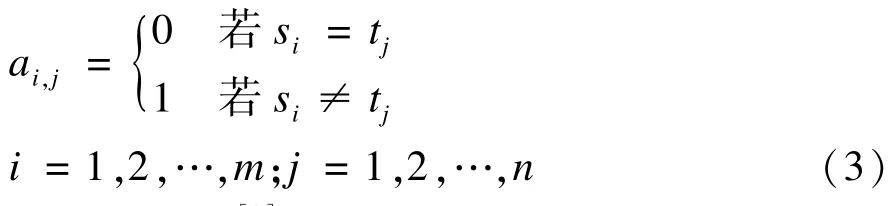
可动态规划[9]求解得编辑距离,即当i=1→m和j=1→n时依次根据上式求解di,j。所有di,j需要遍历一次,算法时间复杂度为O(mn)。矩阵LD右下角的元素dm,n为字符串S与T之间的编辑距离,即字符串S转换到字符串T所需最少的编辑操作次数。
2.2 基于编辑距离的相似度
可以由编辑距离获得2个字符串之间的相似度。直观上,2个字符串越相似,编辑距离越小,相似度越大。将编辑距离转化为值在[0,1]区间相似度的公式如下:
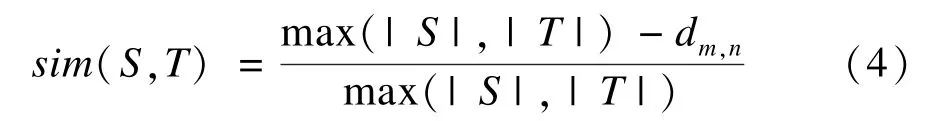
其中,|S|,|T|分别表示字符串S和T的长度;dm,n表示字符串S和T之间的编辑距离。sim(S,T)越大,表示2个字符串相似度越大。
3 网页篡改检测原理及现状
3.1 检测方案
网页篡改检测是指尽早发现网页被篡改,并通知相关方面采取应急措施。传统的检测方案集中于基于服务器端的网页篡改检测,这类方案尽管检测精度较高,但存在诸多不足之处:只适合单机部署,应用成本巨大;不适宜批量检测篡改;因为涉及到数据隐私、服务器第三方托管、系统稳定性等问题,很多单位不希望在服务器上安装不熟悉的软件。基于客户端的网页篡改技术能有效避免以上问题,而且能对网站的运行情况进行实时监测[10⁃11]。基于相似度的客户端网页篡改检测方法是其中一种简单有效的篡改检测方法。它将整个HTML文件看成一个字符串,使用相似度算法计算2个连续网页之间的相似度。对于特定网址,每隔相同时间爬取网页。由概率论可得,每次爬取的页面与上一页面的相似度服从指数分布,即概率密度和分布函数分别为:

根据中心极限定理[12]可知:当样本容量n取得充分大,统计量近似服从正态分布N(0, 1)。 即:

服从N(0,1)。
假设当前页面与上一页面的相似度值为s0,取显著性水平α为0.2。本文提出的2个对立假设如下所示:
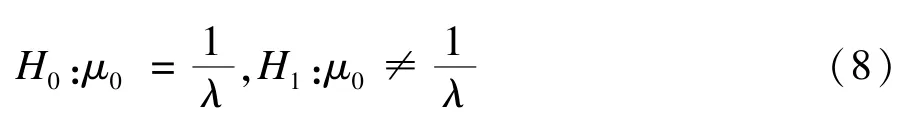
当α为0.2,查表可知Φ0.1=1.3。当Φ0.1>1.3时,即,则H0被拒绝,也即当前μ0值异常,应该触发报警,提示发生篡改[13⁃15]。
3.2 现有检测方案的不足
作为一种基于客户端的篡改检测方案,该方案从概率统计学上研究篡改问题,能在客户端批量检测大量网址对应网页是否发生篡改。在该方案中,其中一个步骤需要计算网页页面之间相似度。经典算法的时间复杂度为O(mn),当计算同一网址相邻时刻网页之间相似度时,往往需要花费几分钟甚至几个小时。这样的计算效率远远不能适应大规模批量网页篡改检测需要。与此同时,由于网页的局部性变化原理[8],即网页的更新方式是局部更新的,相邻网页之间往往存在很多公共相同部分,计算相似度时,需要很多多余的计算。基于这类情况,本文提出了一种改进的编辑距离算法。
4 改进的编辑距离算法
4.1 算法步骤
与同一网址相邻时刻网页之间存在很多公共字符串类似,很多时候,字符串之间存在局部性变化,此时,若按照经典算法求解编辑距离,往往存在很多多余的计算。针对这一情况,提出一种改进的编辑距离算法,算法流程如图1所示。设S=s1,s2,…,sm和T=t1,t2,…,tn,则可以先贪心求得S和T的最长公共前缀comprefix和最长公共后缀comsuffix,将S和T都在开头减去字符串序列comprefix和结尾减去字符串序列comsuffix后,再根据经典算法求得剩余部分的编辑距离C,则S与T的编辑距离为:

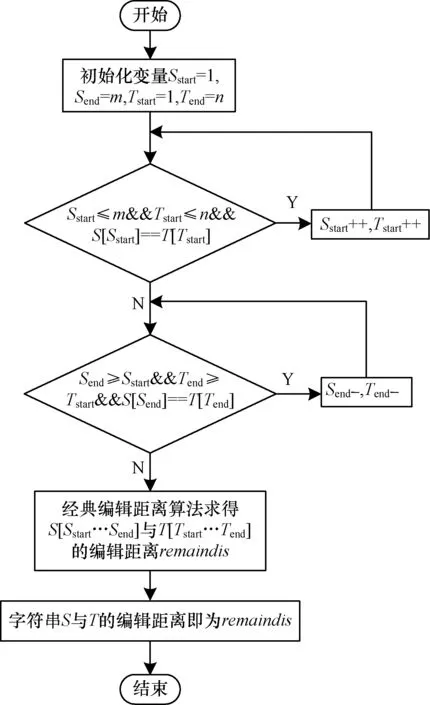
图1 改进算法流程
改进的编辑距离算法步骤如下:
Step1 初始化 Sstart= 1,Send= m,Tstart= 1,Tend=n。
Step2 如果 Sstart≤ m,Tstart≤ n,S[Sstart] =T[Tstart],则Sstart++,Tstart++,并跳转Step2。
Step3 如果 Send≥Sstart,Tend≥Tstart,S[Send] =T[Tend],则可得Send--,Tend--,并跳转Step3。
Step4 可以设 remainS=sSstart,sSstart+1,…,sSend和remainT=tTstartt,tTstart+1,…,tTend,使用经典的编辑距离算法 求 得 remainS和 remainT 的 编 辑 距 离remainDis。
Step5 求得S和T的编辑距离为:

4.2 算法正确性证明
假设改进的算法求得的解不是正确的编辑距离。设字符串A与B根据改进算法求得的解为dis(A,B)improve,根据经典的编辑距离算法求得的解为dis(A,B)true,由假设可得:
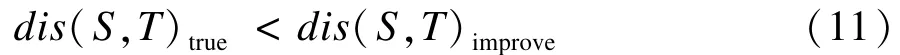
设在经典编辑距离算法中,编辑成T[1,2,…,Tstart-1]的S最短前缀字符串为 S[1,2,…,shstart-1],编辑成T[Tend+1,Tend+2,…,n]的 S最短后缀字符串为S[shend+1,shend+2,…,m]。 则:
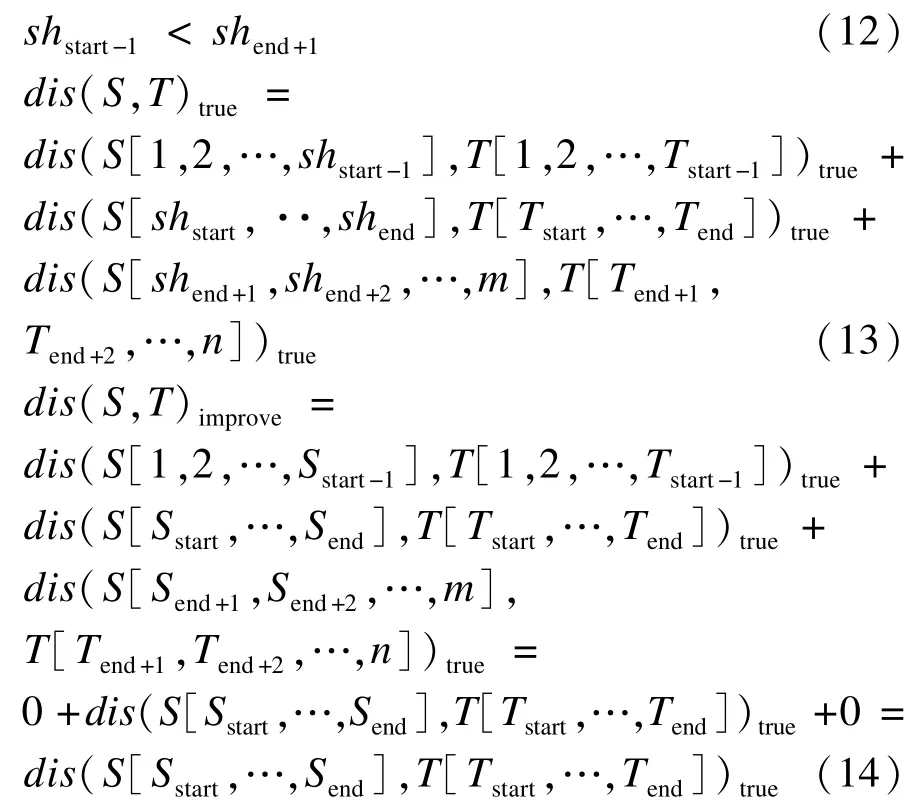
由图2改进算法正确性证明示意图可得S[1,2,…,shstart-1]与 T[1,2,…,Tstart-1]长度差为,两者的编辑距离至少为,即:
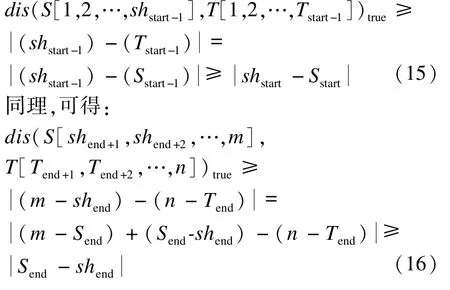
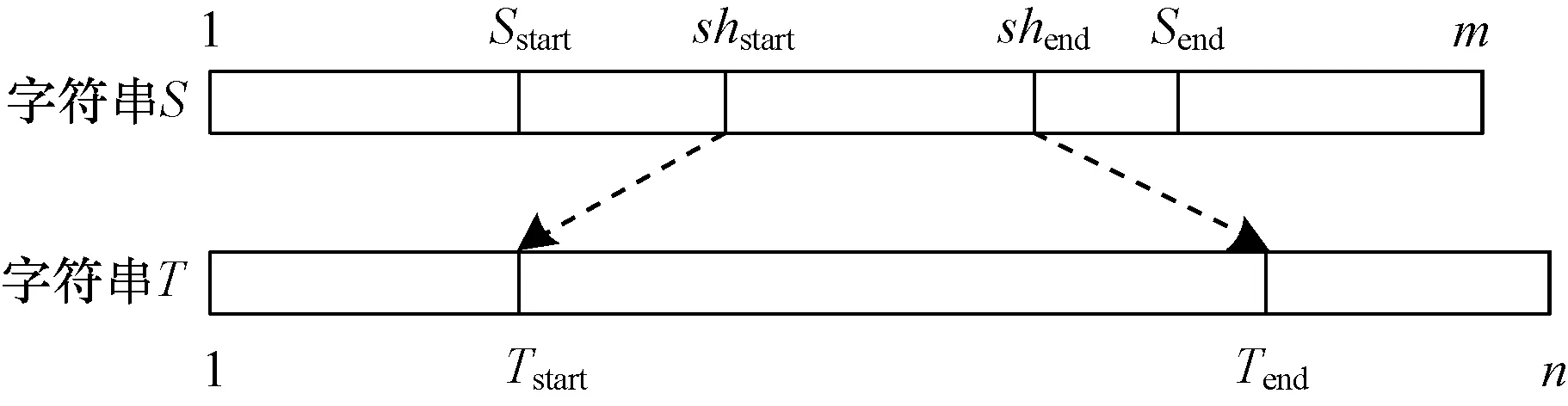
图2 改进算法正确性证明示意图
将S[Sstart,…,Send]编辑成 T[Tstart,…,Tend]的一些方案中,有一种方案详细步骤如下:
步骤1 将S[Sstart,…,Send]编辑成 S[shstart,…,shend]。 在这一编辑过程中,在字符串开头,当shstart<Sstart时,可以添加 S[shstart,shstart+1,…,Sstart-1]于S[Sstart,…,Send]开头,当 shiftstart≥Sstart时,可以在 S[Sstart,…,Send]开头处删除 S[Sstart,Sstart+1,…,shstart-1],编辑次数为。在字符串结尾,添加S[Send+1,Send+2,…,shend](shend>Send时)或删除S[shend+1,shend+2,…,Send](shend≤Send时),类似同理可得编辑次数为。这一过程中总的编辑次数为
步骤2 将S[shstart,…,shend]编辑成T[Tstart,…,Tend]。在这个过程中使用最优编辑次数的编辑方法,所得的编辑次数即为 dis(S[shstart,…,shend],T[Tstart,…,Tend])true。
在这个方案中,所需要总的编辑次数是:
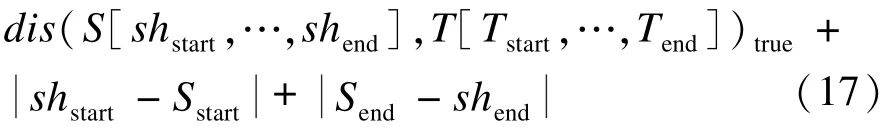
它必定大于 S[Sstart,…,Send]编辑成 T[Tstart,…,Tend]的最少编辑次数,即 dis(S[Sstart,…,Send],T[Tstart,…,Tend])true。 所以:

综合上述几个公式可得:

与假设不符合,假设不成立。改进的编辑距离算法所得解等于经典的编辑距离算法所得解,改进编辑距离算法正确性得到证明。
4.3 改进的编辑距离算法优势分析
改进的编辑距离算法可以分为2个部分:求解最长公共前缀字符串和后缀字符串部分,求解剩余字符串编辑距离部分。前者的时间复杂度为线性时间复杂度,后者的时间复杂度为O(mn)(其中,m,n分别为剩余部分2个字符串的长度)。在字符串长度相等条件下,前者的比例增大,所用时间增大,后者所用时间减小,但前者增大的幅度远没有后者减小的幅度大,所用总时间减小。
可见改进算法适用于求解具有较长最长公共前缀或后缀的字符串之间的相似度。在基于相似度的客户端网页篡改检测方法中[13⁃15],同一网址相邻时刻网页就是属于这类情况。由于网页的局部性变化原理[14],相邻网页之间往往存在很多公共相同部分,很多时候,2个网页字符串之间存在较长的最长公共前缀字符串和后缀字符串,使用改进算法能获得一定效果。编程题自动评阅也同样适用于该算法[6],在编程题自动评阅中,很多答案与标准答案具有很高的相似度,往往存在较长的最长公共前缀字符串和后缀字符串,这时改进的编辑距离算法具有更好的时间效率。
当2个字符串S和T开头处和结尾处都不相同时,改进编辑距离算法(最长公共前缀字符串和最长公共后缀字符串长度均为0)时间复杂度为O(mn)。其中,m,n分别为字符串S和T的长度,与经典编辑距离算法的时间复杂度一样,但是这种类似情况在基于相似度的客户端网页篡改检测和编程题自动评阅中较少发生,很多情况下字符串之间具有较长的最长公共前缀字符串和后缀字符串,此时具有较好的计算效率。总的来说,尽管有一些个体需要与经典算法类似的大量计算时间,但平均到单个个体上的平均计算时间,与经典算法相比,具有很大的改善。
5 实验与结果分析
为验证改进算法在计算效率方面的优势,将它与经典算法进行比较。考虑到在基于相似度的客户端网页篡改检测方法中,需要监测的网页具有局部变化性[14],即相邻网页之间往往具有较长的最长公共前缀或最长公共后缀,可以每隔一定时间下载固定网址的网页,分别使用改进算法和经典算法计算相邻网页之间的相似度,比较所用时间。
本文对3个网站每隔4个小时爬取并下载一张网页,为期一个月。对于每个网址下载的网页,分别按下载时间进行排序,共建立180个序列。对于这3个有序序列,从第11个网页到第30个网页,依次计算与前一个网页之间的相似度,记录计算到第n张网页时所用的总时间。分别使用2种算法计算相似度,测试环境为2 GHz Intel双核处理器、2 GB内存。使用C++实现算法。
图3~图5分别对应3个网址的实验结果。在计算相邻网页相似度时,相对于经典算法,改进算法在计算时间方面具有明显优势,同时这种优势并不是很稳定。在这3个网址中,经典算法所用时间基本是均匀增长的,这主要是由于经典算法的时间复杂度为O(mn)(其中,m,n分别为2个字符串的长度),第10张网页到第30张网页总的监测时间为44 h(大约2天),在这段时间里,这些网址的网页长度并没有发生很大的变化,从而导致计算同一网址相邻网页相似度时所需时间基本相等,总的累计计算时间基本呈线性增长。

图3 网址1中改进算法与经典算法的对比
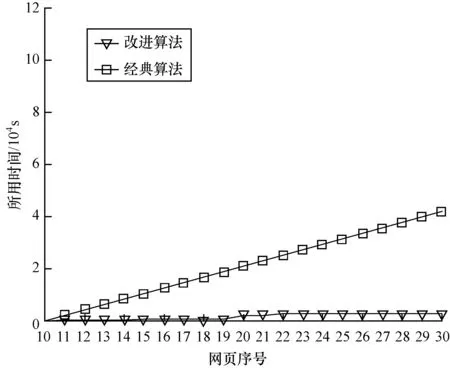
图4 网址2中改进算法与经典算法的对比
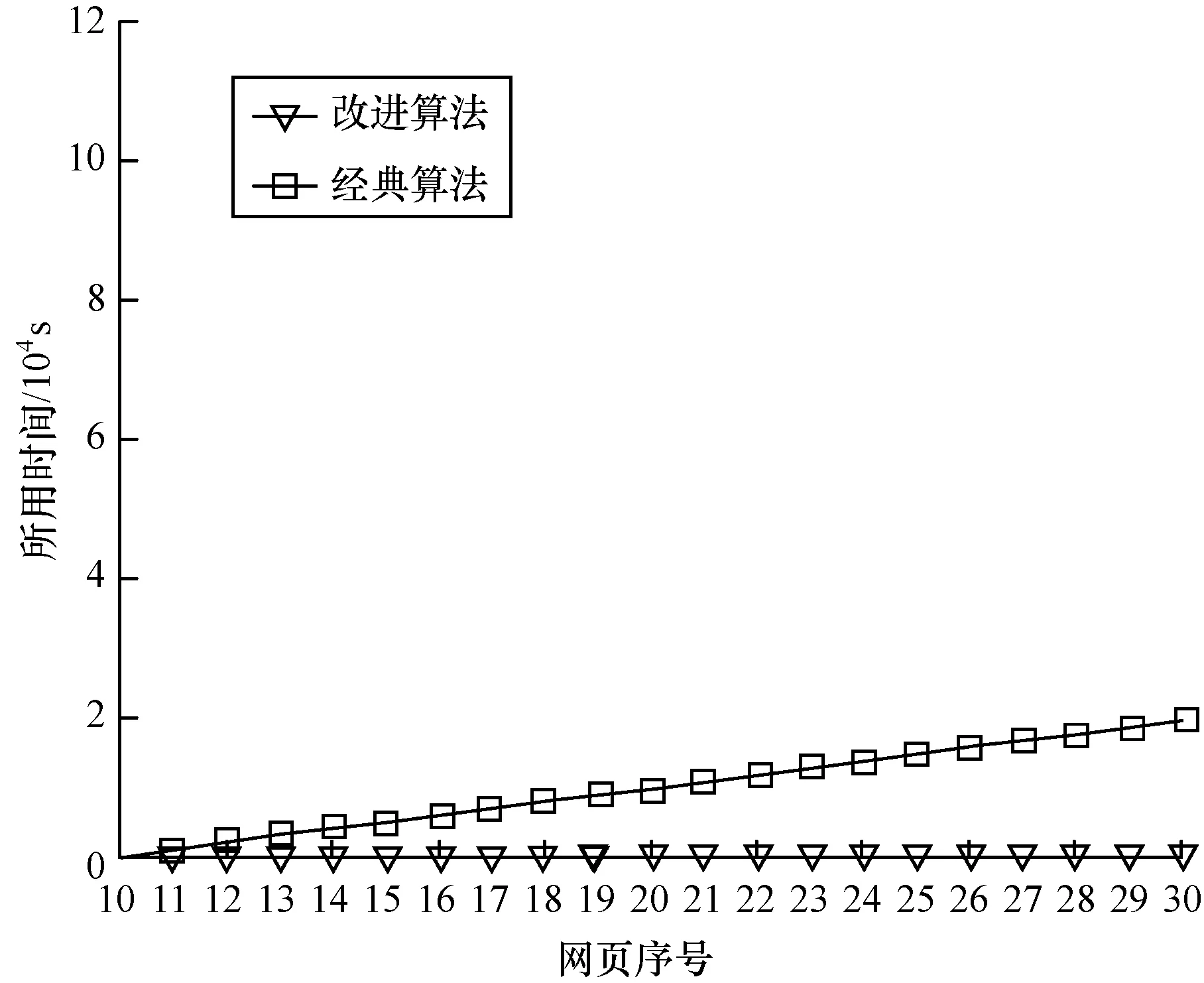
图5 网址3中改进算法与经典算法的对比
相对于经典算法,改进算法所需总的累计计算时间总体保持在较低水平,但在某些网页之间会发生跃变。产生这种情况主要是因为基于网页的局部变化性原理,大部分相邻网页在4 h内只动态更新一小部分甚至不更新。这些相邻网页动态更新部分的最前位置与最后位置之间距离差较小,即相邻网页之间的最长公共前缀字符串和后缀字符串总的长度较长,由此导致时间复杂度为O(n)部分数据量较大,时间复杂度为O(mn)部分数据量较小。此时总的计算时间由时间复杂度为O(n)部分的数据量决定,所花费的时间较少,反映到实验结果中,即在使用改进算法时,大部分情况下,总的累计计算时间随着计算相邻网页数量的递增,递增的幅度很小,对应曲线在大部分情况下保持基本水平状态。与之相反,在少数情况下,由于相邻网页动态更新部分的最前位置与最后位置之间距离差较大,即相邻网页之间的最长公共前缀字符串和后缀字符串总的长度较小,导致时间复杂度为O(n)部分数据量较小,时间复杂度为O(mn)部分数据量较大,总的计算时间由时间复杂度为O(mn)部分数据量决定,此时所花费的时间较大,反映到实验结果中,即改进算法对应曲线发生跃变。
改进算法在某些网页之间相似度所用时间与经典算法相比,差距并不是很大,比如计算网址 1第23个网页与第24个网页之间相似度,网址 2第19页与第20个网页之间相似度。但总体上,当计算所有从第11个网页到第30个网页这20个网页与它们前一个网页之间相似度所用总时间时,改进算法与经典算法相差悬殊。证明在计算批量网页相似度时,与经典算法相比,改进的编辑距离算法在计算效率上有很大提升。
6 结束语
本文分析了经典编辑距离算法及其在计算2个字符串相似度时存在的问题,基于局部变化性原理,提出了一种改进的编辑距离算法。实验表明,当求解大量相似字符串之间的相似度时,尽管该算法在少量字符串之间计算相似度时需要花费较多时间,但是与经典算法相比,该算法具有较高的计算效率。
[1] Nirenburg S,Domashnev C,Grannes D J.Two Approaches to Matching in Example⁃based Machine Translation[C]//Proceedings of the 5th International Conference on Theoretical and Methodological Issues in Machine Translation.Kyoto,Japan:UB/TIB Hannover,1993.
[2] 吴 波.改进的编辑距离算法的研究及其在电子政务中的应用[D].成都:电子科技大学,2011.
[3] 姜 华,韩安琪,王美佳,等.基于改进编辑距离的字符串相似度求解算法[J].计算机工程,2014,40(1):222⁃227.
[4] 赵作鹏,尹志民,王潜平,等.一种改进的编辑距离算法及其在数据处理中的应用[J].计算机应用,2009,29(2):424⁃426.
[5] 刁兴春,谭明超,曹建军.一种融合多种编辑距离的字符串相似度计算方法[J].计算机应用研究,2010,27(12):4523⁃4525.
[6] 周汉平.Levenshtein距离在编程题自动评阅中的应用研究[J].计算机应用与软件,2011,28(5):328⁃331.
[7] 薛晔伟,沈钧毅,张 云.一种编辑距离算法及其在网页搜索中的应用[J].西安交通大学学报,2008,42(12):1450⁃1454.
[8] 邓爱萍.程序代码相似度度量算法研究[J].计算机工程与设计,2008,29(17):4636⁃4638.
[9] Thomas H C,Charles E L,Ronald L R,等.算法导论[M].2版.潘金贵,顾铁成,李成法,译.北京:机械工业出版社,2006.
[10] 张振华.基于LAMP平台架构的网页防篡改系统设计与实现[D].北京:北京邮电大学,2010.
[11] 陈 洁.网页集中监控防篡改系统技术研究[D].成都:电子科技大学,2009.
[12] 盛 骤,谢式迁,潘承毅.概率论与数理统计[M].4版.北京:高等教育出版社,2008.
[13] 魏文晗.网页篡改检测系统的研究与实现[D].重庆:重庆大学,2013.
[14] 魏文晗,邓一贵.基于局部变化性的网页篡改识别模型及方法[J].计算机应用,2013,33(2):430⁃433.
[15] Davanzo G,Medvet E,Bartoli A.Anomaly Detection Techniques for a Web Defacement Monitoring Service[J].Expert Systems w ith Applications,2011,38(10):12521⁃12530.
编辑 顾逸斐
Im proved Edit Distance Algorithm Based on Local Variability
WANGWeihong,LIJun
(College of Computer Science and Technology,Zhejiang University of Technology,Hangzhou 310023,China)
For the low computational efficiency in solving the sim ilarity of two strings by traditional algorithm,an improved edit distance algorithm is proposed.It firstly obtains the longest common prefix and the longest common suffix of the two strings,and then gets the edit distance between the remainder of the two strings by traditional algorithm.Proof by contradiction is used to prove that this edit distance equals to the solution by traditional algorithm.On this basis,the improved algorithm is researched about the advantages and be applied to the Web tamper detection.Experimental results show that compared w ith the traditional algorithm,the improved edit distance algorithm has better computational efficiency in obtaining the sim ilarity between the pages in the same URL.
edit distance;sim ilarity;common prefix;common suffix;local variability;tamper detection
1000⁃3428(2015)07⁃0294⁃05
A
TP301.6
10.3969/j.issn.1000⁃3428.2015.07.056
国家自然科学基金资助项目(61340058);浙江省自然科学基金资助项目(LZ14F020001)。
王卫红(1969-),男,教授,主研方向:空间信息服务,网络信息安全;李 君,硕士研究生。
2015⁃01⁃30
2015⁃03⁃05E⁃mail:zjut_lijun@126.com
