基于鲁棒高阶条件随机场的视频自动分割
2015-08-22程婷婷郭立君黄元捷
程婷婷,郭立君,黄元捷
(宁波大学信息科学与工程学院,浙江 宁波315211)
·图形图像处理·
基于鲁棒高阶条件随机场的视频自动分割
程婷婷,郭立君,黄元捷
(宁波大学信息科学与工程学院,浙江 宁波315211)
针对交互式分割方法存在用户标注繁琐和过分割现象,以及仅考虑二元项不能获得图像中准确的物体边界等问题,结合鲁棒高阶条件随机场,提出一种视频自动分割方法。采用基于超像素显著性特征的分割方法对视频初始帧进行自动分割,其结果作为初始化种子建立模型。根据颜色信息设计高斯混合模型,基于纹理、形状等特征,利用联合Boosting算法训练Jointboost强分类器模型,通过条件随机场提高分割准确度。引入基于超立体像素的高阶项,增加像素与区域的关联,提高分割边界的平滑度。实验结果表明,该方法明显地提高了分割效果。
视频自动分割;高阶势;超立体像素;条件随机场;双模型融合;特征融合
中文引用格式:程婷婷,郭立君,黄元捷.基于鲁棒高阶条件随机场的视频自动分割[J].计算机工程,2015,41(7):261⁃268.
英文引用格式:Cheng Tingting,Guo Lijun,Huang Yuanjie.Automatic Video Segmentation Based on Robust Higher Order Conditional Random Field[J].Computer Engineering,2015,41(7):261⁃268.
1 概述
视频分割在计算机视觉领域具有广泛应用,包括目标检索、视频压缩、智能监控等。近年来,视频分割迅速发展,主要分为交互式分割[1⁃4]和自动分割[5⁃7]。前者一般指根据用户手动标记的若干前景和背景像素建立模型以实现分割的方法,后者主要指基于时空特征聚类的分割方法和自动获取关键对象的分割方法。
本文提出一种基于高阶条件随机场(Conditional Random Field,CRF)的视频前景对象自动分割方法。针对自动提取主要对象的分割方法时间复杂度高和无法在线分割的问题,采用基于超像素显著性特征的分割方法对视频初始帧进行自动分割。初始帧分割结果只包含前景和背景两类,避免了过分割现象,令其作为种子点训练概率模型,考虑到前景和背景颜色相近时,在颜色特征基础上增加局部特征能有效提高分割精度,在使用混合高斯模型描述颜色分布的同时,增加基于局部二值模式(Local Binary Pattern,LBP)、局部特征texton和尺度不变特征变换(Scale Invariant Feature Transform,SIFT) 的Jointboost分类器,利用上述双模型联合验证前景和背景种子点,并将双模型融入条件随机场框架中的一元能量函数。在条件随机场中加入高阶势能,增加像素和超立体像素的时空约束关系,以提高分割边界准确度。
2 背景介绍
在交互式分割领域,文献[8]最早将图割算法用于灰度图像前景提取。该算法首先需用户手动标注一部分像素作为前景和背景,然后在满足手动标注限制的条件下寻找最优解以实现分割。文献[9]利用混合高斯模型分别对彩色图像前景和背景像素的颜色特征建模,该概率模型用于计算能量函数中的一元项,根据邻域系统中每对像素空间和颜色的混合距离,计算能量函数中的二元项以平滑分割边界。文献[10]在提出Grabcut方法,该方法总体上仍基于图割算法和混合高斯模型框架,区别在于用户交互时增加一个矩形框,并通过迭代图割方式达到能量函数最小。以上算法只考虑了像素的颜色特征而忽略了其他特征,如纹理、形状等。文献[11]在图像中增加纹理通道,建立基于颜色和纹理特征的混合高斯模型,并在计算能量函数二元项时加入结构张量以有效利用纹理特征。但上述方法均需用户交互,甚至在分割不准确的情况下需再次交互以得到准确分割,这不仅增加了交互负担,而且前景和背景模型的建立对用户标记的差异敏感,所以传统的交互式图像分割方法只适用于以编辑为目的的视频应用,并不适用于以自动分割为基础的其他视频应用。
出于应用的考虑,视频自动分割技术得到重视,出现了基于时空特征一致性的视频自动分割方法[12⁃13],其主旨为令光亮和运动一致的像素组合使其成为立体区域,但在前景和背景无明显界限时,视频帧中前景对象被分割成多个区域,出现过分割问题。最近出现的基于对象性检测的自动视频分割方法解决了过分割问题,文献[6]使用谱聚类的方法从视频相邻帧的对象假设中检测出主要对象作为先验,但其缺乏相邻帧的对象形状预测,所以不能准确地分割快速移动的对象。而文献[5]采用有向无环图从视频帧的所有对象假设中提取主要对象并通过光流预测对象的形状,从而能够处理快速移动对象,但该方法提取视频所有帧中对象假设的过程非常耗时,使得整个算法的时间复杂度很高,另外,提取主要对象涉及整个视频从而无法在线分割。
3 先验信息初始化
建立前景和背景概率模型时需要种子点作为初始化信息。针对图 1(a)所示的原始图,使用SLIC[14]方法对初始帧进行无监督分割,获得如图1(b)所示的超像素。假定图像中只有二类对象(前景和背景),并设定其模型为基于显著性特征的有参函数Rf和Rb,根据每个超像素的得分给予前景或背景的标号,通过模型更新和超像素标号2个子过程迭代优化,取所有超像素标号划分中得分最大的组合作为分割结果。最终得到如图1(c)所示的前景和背景粗分割,将其作为初始化先验信息。由于初始化信息中包含分割错误的前景和背景像素,因此需使用概率模型迭代优化以提高分割精度。

图1 初始化示意图
4 高阶CRF结构
分割问题常被视为随机场中像素标记问题,即为图像中像素配置适当的标签使得随机场的后验概率最大。本文将视频分割理解为CRF中二值标记问题,假设{f1,f2,…,ft,…,fn}是视频帧序列,条件随机场X由顶点 V ={x1,x2,…,xN}、邻域系统 ε和子团(clique)C组成。顶点为取值范围L={0,1}的随机变量,0代表背景,1代表前景,邻域系统由所有像素在同一帧的8邻域组成,子团由超立体像素S构成。
根据Hammersley Clifford随机场定理可知,马尔科夫随机场的后验概率分布即为Gbbis分布:

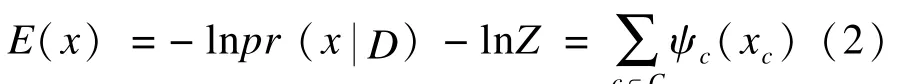
而条件随机场[15]本质上是给定了观察值集合的马尔科夫随机场,解决了其他判别式模型难以避免的标记偏置问题。
4.1 CRF中的一元项
视频分割中颜色是一项重要的特征,本文运用混合高斯模型描述像素的RGB颜色分布。考虑到前景和背景颜色相近时,增加局部特征texton、LBP和SIFT能有效提高分割精度,故基于这些局部特征训练一个Jointboost分类器。针对不同视频图像,将上述双模型以不同的权重结合计算一元项。
4.1.1 基于局部特征的Jointboost分类器
本文采用一种改进型的联合 Boosting算法[16]学习一个二类强分类器。选取的特征包括:(1)用于学习视频图像形状上下文信息的 texton特征[17];(2)用于处理对象尺度和旋转变化的 SIFT特征;(3)用于描述纹理信息的LBP特征。图2即为这些特征的映射图。

图2 特征映射图
联合Boosting算法在每次迭代r中找到一个最佳弱分类器hr(li),R个弱分类器叠加形成强分类器,其形式如下:

其中,每个弱分类器是一个决策树桩。
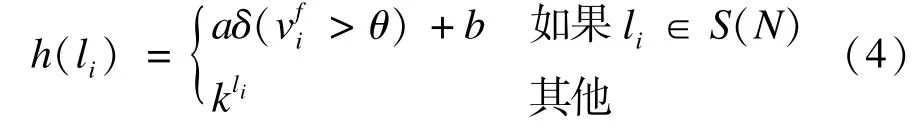
其中,δ(·)是取值为{0,1}的指示函数;S(N)是N的子集;是像素 i的特征值;θ为阈值。利用softmax转换方法,将式(3)变成概率形式:
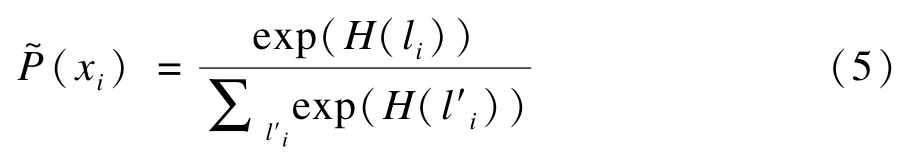
因此关于texton,LBP和SIFT特征的势能方程为:

4.1.2 混合高斯模型
文献[5⁃6,9]均使用高斯混合模型(GMM)描述像素RGB颜色空间分布,可见GMM能有效地描述颜色特征并具有判别性。本文根据初始化种子像素的颜色特征,分别建立前景高斯混合模型和背景高斯混合模型。定义 PGMM(xi)为像素 xi属于前景(xi=1)或背景(xi=0)的概率,一元项中采用该模型的负对数形式:
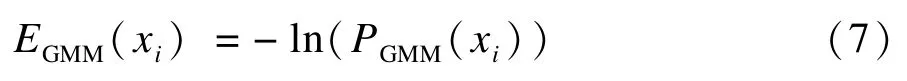
在不同视频图像中以上2个模型重要性有差异,因此设置参数α(0<α<1)控制其权重,在CRF中一元项的形式为:
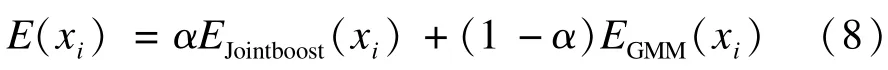
在本文实验中设置α=0.3时,使得颜色特征权重大于形状、纹理特征,其分割效果最佳。
在CRF结构中,根据先验信息得到的概率模型作为一元项初始化,结合下文的二元项和高阶项,使用迭代图割方法更新模型,直至能量函数最小。
在图3中,像素亮度越大表示属于前景概率越大,可以看出模型结合后前景分割更准确。

图3 概率映射图
4.2 CRF中的二元项
在CRF能量函数中二元项的作用是去除锯齿、平滑边界。在基于图割的分割方法中,二元项作用于相邻像素促进边界平滑,其形式如下:
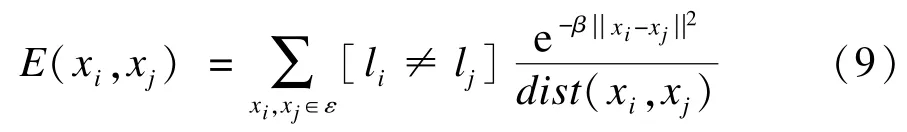
其中,第1项是二值函数,当li≠lj时为1,反之为0,li≠lj表示像素xi,xj在分割边界上;函数dist()用来度量像素 xi,xj的欧式距离;是二范式,计算相邻像素颜色差异;参数β控制分割边界平滑性与准确度,可用如下公式计算:
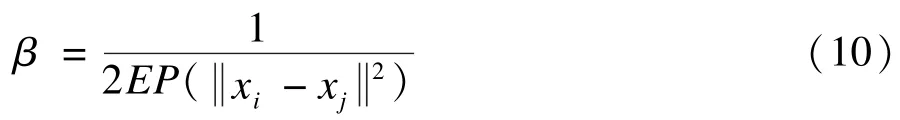
其中,EP()是相关数据的期望函数。
4.3 CRF中的高阶项
考虑到条件随机场中二阶项在提高分割精度的同时导致过平滑现象,引入高阶项,通过增加像素与所属区域约束关系以缓解二元项带来的负面影响。
本文将高阶项建立在时空一致的超立体像素上,实现视频分割中时空边界一致性。假设超立体像素具备2个属性:(1)每个supervoxel只属于一个对象;(2)每个supervoxel时空边界一致。首先使用streamGBH算法[18]对视频进行分割,获得如图4所示时空边界一致的超立体像素,然后创建高阶项约束超立体像素,使其内部像素标注保持一致。

图4 视频超立体像素

高阶项最初是以Potts模型引入计算机视觉。图像分割时在能量函数中增加高阶势能的作用是促使子团里所有像素标注一致,其形式如下:其中,表示子团c中像素个数,在本文中使用图4所示的超立体像素s作为子团,式(11)表明只有s中所有像素标注一样时高阶项为0,反之为。尽管这样可以促使标注一致,但式(11)太过严格与苛刻,假设 s中含有像素{x1,x2,x3,x4,x5,x6,x7},在标注分别为{1,1,1,1,1,0,1}和{1,0,1,0,1,0,1}的情况下,其代价函数是一样的。当视频聚类后获得的超立体像素属于不同对象或者时空边界不一致时,采用式(11)的高阶势函数作为像素和超立体像素间的标注约束将导致分割边界错误。为缓解这一问题,本文采用鲁棒的Potts模型[19],其定义如下:
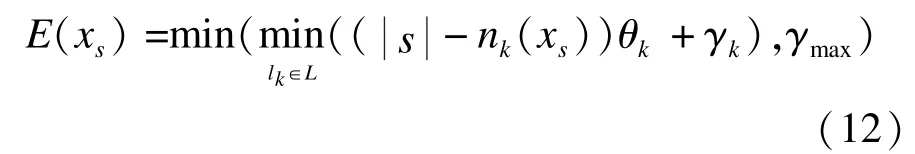
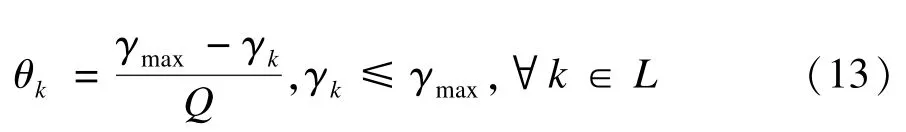
基于鲁棒的Potts模型和原始的Potts模型的高阶项均促使超立体像素中像素标注一致,但前者允许一部分像素的标注和超立体像素的主要标注不一致,其高阶势函数和标注不一致的像素个数成线性关系,而后者只要出现一个像素的标注和主要标注不一致将给予最大代价值,实验表明,鲁棒的Potts模型能有效改善分割边界。
因此高阶条件随机场框架中每帧的能量函数为以下形式:
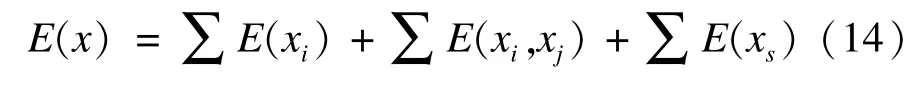
4.4 抗噪性分析
在CRF能量函数中一元项是最为关键的一项,本文训练双模型以计算一元项,其中基于 texton,LBP,SIFT特征训练Jointboost分类器,而SIFT特征对旋转、尺度变换、噪声保持一定的稳定性。另外,在CRF中引入基于超立体像素的高阶项,使得图像分割不仅与其像素特征相关,而且与其所属超立体像素相关,增加了像素与时空邻域像素的约束关系,提高了本文方法的抗噪性。图5(a)为加入密度为0.02椒盐噪声的图像,图5(b)是本文方法的分割结果,图5(c)是经滤波处理后的图像,而图5(d)为滤波处理后本文方法的分割结果,通过图5(b)和图5(d)对比可知,本文方法对存在噪声污染的图像分割具有抑制噪声的能力,而且抑制效果比通过滤波预处理更佳。

图5 椒盐噪声图像及分割结果
5 实验结果与分析
本文以Visual Studio 2012与OpenCV 2.43为开发平台,在CPU为Intel Corei3⁃2130 3.40 GHz,内存为4 GB的计算机上进行实验。实验所用数据库为来自文献[20]的5个视频序列和公开的SegTrack[21]数据库中girl和parachute视频。图6分别为文献[20]中5个视频序列(名称分别为 AN119T,DO01013,DO01030,DO01014,DO02001)的初始帧图像及其初始化结果,每个视频序列中包含至少一个前景对象。

这5个视频序列的分割难点分别在于:AN119T中牛在行进过程中头部钻入草丛引起的遮挡问题,DO01013中多匹马多前景对象问题,DO01030中向日葵复杂的边缘,DO010014中狐狸的影子,DO02001中滑雪人的快速移动。
为验证本文方法中模型的融合作用以及CRF中高阶项的作用,首先在5个视频序列的实验中分别比较了基于单模型的CRF方法(包括单独应用GMM模型的CRF_GMM方法、单独应用Jointboost分类器模型的CRF_Boost方法),双模型融合的CRF方法(CRF_GMM_Boost)以及本文提出的双模型融合加高阶项的方法。表1给出了上述4个方法在5个视频序列上分割结果,图像分辨率为352×288像素。表中使用平均错误像素数avg_err和错误像素率err_rate的方法衡量分割精确度,其计算方式如下:

其中,fi表示第i帧图像分割结果;XOR为异或操作;GT为第i帧的地面情况;n是视频总帧数;resolution指图像的分辨率。
从表1可以看出,虽然在DO01014视频中不含高阶项的方法效果更佳,但在AN119T,DO01013,DO01030和DO02001视频序列中本文方法的平均错误像素数均低于不含高阶项的方法,这表明高阶项能有效提高分割准确度。此外前2种方法的平均错误像素数均少后2种方法,这表明同时考虑颜色、纹理和 SIFT特征的模型能显著改善分割结果。
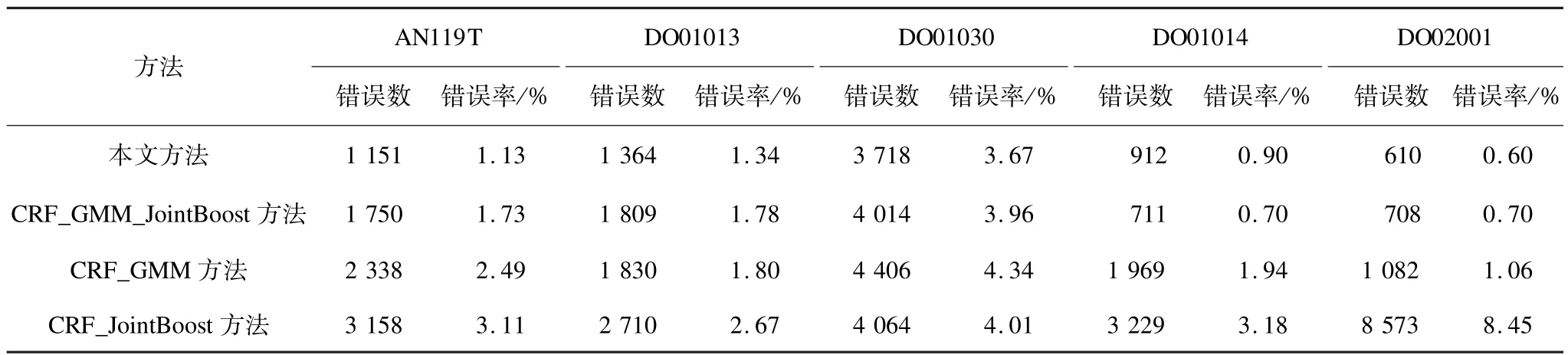
表1 错误像素数量和错误率统计
为进一步验证本文方法的分割效果,实验中还将本文方法和其他相近的方法进行比较,包括Textonboost[17],ALE方法[19]和 Akamine方法[20]。为了公平对比,Textonboost和ALE方法均为条件随机场框架下的分割方法,采用和本文同样的自动化方法获得初始化信息。而Akamine的方法[20]是基于显著性特征获得初始化先验。表2为本文方法与上述3种方法在5个视频序列中的定量对比结果。从中可以看出,本文方法的错误率均低于Akamine方法[20]、ALE[19]和 Textonboost[17]。 图7为使用本文方法的视频分割效果图,提取的牛、马和向日葵等前景皆更准确。

表2 定量分析结果对比 %

图7 本文方法分割结果
本文还在公开数据库SegTrack上测试本文方法的有效性,并与其他最新的有监督[21,23]和无监督[5⁃6,22]分割方法做定量对比实验。图8显示了本文方法的分割结果。表3为各种方法的定量分析对比,其中,girl视频中本文的分割结果优于其他方法的结果,而在parachute视频中文献方法[6]的结果最优,这是因为本文方法处理光照变化的视频分割存在一定的局限性。

图8 本文方法在SegTrack数据库中的分割结果
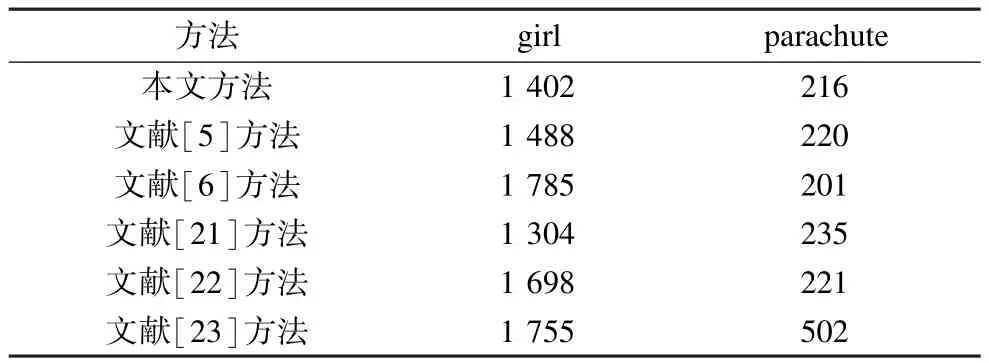
表3 各种方法在SegTrack数据集上的错误像素对比
本文采用图割算法求解CRF中能量函数最小,其时间复杂度为O(mn2),n和m分别为图中顶点数和边数,分别对应CRF中随机变量数和随机变量间相关边数。表4统计了实验中每个视频分割所用的总时间,各视频总帧数和分辨率存在差异,故所用时间也存在差异。
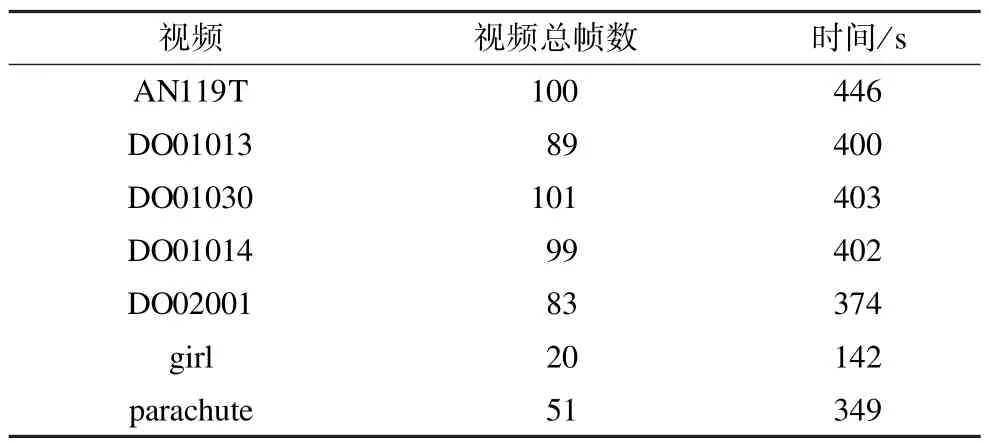
表4 各视频分割时间统计
6 结束语
本文提出一种基于鲁棒高阶条件随机场的双模型视频自动分割方法。通过基于超像素显著性特征的方法分割视频初始帧以获得初始化先验信息。根据初始帧图像的texton,LBP和SIFT特征使用联合Boosting算法训练一个强分类器模型,同时基于像素的RGB颜色信息学习GMM模型,使用双模型联合计算CRF中能量函数的一元项,并在CRF中加入基于超立体像素的高阶项,最后使用迭代图割算法使得高阶CRF中的能量函数达到最小。在与同类方法的对比实验中验证了本文方法在分割准确性方面的优势。在未来的工作中,可以研究将本文中的前景和背景分割扩展到语义分割,进而为视频场景分析打下基础。
[1] Price B L,Morse B S,Coheb S.LIVEcut:Learning⁃based Interactive Video Segmentation by Evaluation of Multiple Propagated Cues[C]//Proceedings of International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2009:779⁃786.
[2] Bai Xue,Wang Jue,Simons D,et al.Video SnapCut:Robust Video Object Cutout Using Localized Classifiers[J].ACM Transactions on Graphics,2009,28(3):1⁃11.
[3] Zhong Fan,Qin Xueying,Peng Qunsheng,et al.Discontinuity⁃aware Video Object Cutout[J].ACM Transactions on Graphics,2012,31(6):1⁃10.
[4] 吴 琳,李海燕.面向生物医学图像的交互式分割算法[J].计算机工程,2010,36(16):208⁃209,212.
[5] Zhang Dong,Javed O, Shah M.Video Object Segmentation Through Spatially Accurate and Temporally Dense Extraction of Primary Object Regions[C]//Proceedings of Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2013:628⁃635.
[6] Lee Y J,Kim J,Grauman K.Key⁃segments for Video Object Segmentation[C]//Proceedings of International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2011:1995⁃2002.
[7] 郭宝龙,侯 叶.基于图切割的图像自动分割方法[J].模式识别与人工智能,2011,24(5):604⁃609.
[8] Boykov Y Y,Jolly M P.Interactive Graph Cuts for Optimal Boundary and Region Segmentation of Objects in ND Images[C]//Proceedings of International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2001:105⁃112.
[9] Blake A,Rother C,Brown M,et al.Interactive Image Segmentation Using an Adaptive GMMRF Model[M].Berlin,Germany:Springer,2004.
[10] Rother C,Kolmogorov V,Blake A.Grabcut:Interactive Foreground Extraction Using Iterated Graph Cuts[J].ACM Transactions on Graphics,2004,23(3):309⁃314.
[11] Zhou Hailing,Zheng Jianm in,Wei Lei.Texture Aware Image Segmentation Using Graph Cuts and Active Contours[J].Pattern Recognition,2013,46(6):1719⁃1733.
[12] Cheng Hsien⁃Ting, Ahuja N.Exploiting Nonlocal Spatiotemporal Structure for Video Segmentation[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2012:741⁃748.
[13] Lezama J,Alahari K,Sivic J,et al.Track to the Future:Spatio⁃temporal Video Segmentation with Long⁃range Motion Cues[C]//Proceedings of Conference on Com⁃puter Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2011:20⁃25.
[14] Achanta R,Shaji A,Smith K,et al.SLIC Superpixels Compared to State⁃of⁃the⁃Art Superpixel Methods[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(11):2274⁃2282.
[15] Lafferty J,Mccallum A.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the 18th Inter⁃national Conference on Machine Learning.San Francisco,CA,USA:Morgan Kaufmann,2001:282⁃289.
[16] Torralba A,Murphy K P,Freeman W T.Sharing Features:Efficient Boosting Procedures for Multiclass Object Detection[C]//Proceedings of Conference on Computer Vision and Pattern Recognition.Washington,D.C.,USA:IEEE Press,2004:762⁃769.
[17] Shotton J,W inn J,Rother C,et al.Textonboost:Joint Appearance,Shape and ContextModeling for Multi⁃class Object Recognition and Segmentation[M].Berlin,Germany:Springer,2006.
[18] Xu Chenliang,Xiong Caim ing,Corso J J.Stream ing Hierarchical Video Segmentation[M].Berlin,Germany:Springer,2012.
[19] Kohli P,Torr P H.Robust Higher Order Potentials for Enforcing Label Consistency[J].International Journal of Computer Vision,2009,82(3):302⁃324.
[20] Akam ine K,Fukuchi K,Kimura A,et al.Fully Automatic Extraction of Salient Objects from Videos in Near Real Time[J].The Computer Journal,2012,55(1):3⁃14.
[21] Tsai D,Flagg M,Rehg JM.Motion Coherent Tracking w ith Multi⁃label MRF Optim ization[J].International Journal of Computer Vision,2012,100(2):190⁃202.
[22] Ma Tianyang,Latecki L J.Maximum Weight Cliquesw ith Mutex Constraints for Video Object Segmentation[C]//Proceedings of Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2012:670⁃677.
[23] Chockalingam P,Pradeep N,BitchfieldI S.Adaptive Fragments⁃based Tracking of Non⁃rigid Objects Using Level Sets[C]//Proceedings of International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2009:1530⁃1537.
编辑 顾逸斐
Automatic Video Segmentation Based on Robust Higher Order Conditional Random Field
CHENG Tingting,GUO Lijun,HUANG Yuanjie
(College of Information Science and Engineering,Ningbo University,Ningbo 315211,China)
This paper presents an automatic video segmentation method based on robust higher order Conditional Random Field(CRF),which alleviates the problem that interactive segmentation is time⁃consum ing and labor⁃intensive,and oversegmentation is generated in unsupervised segmentation,and simple pairw ise⁃pixel segmentation cannot get accurate boundary.It utilizes the saliency based segmentation of the first frame of video as initial seeds instead of user labeling.The Gaussian m ixturemodel and a strong jointboost classifier model are respectively learned on the features of color,texture and shape,the combination of both in CRF improves the accuracy of segmentation.It adds higher order potential based on supervoxel to solve the shortcom ing of oversmoothing of pairw ise⁃pixel segmentation.Experimental results demonstrate that themethod ismore effective and efficient than the state⁃of⁃artmethods.
automatic video segmentation;higher order potential;supervoxel;Conditional Random Field(CRF);double model fusion;feature fusion
1000⁃3428(2015)07⁃0261⁃08
A
TP391
10.3969/j.issn.1000⁃3428.2015.07.050
国家自然科学基金资助项目(61175026);宁波市自然科学基金资助项目(2014A610031,2014A610032);“信息与通信工程”浙江省重中之重学科开放基金资助项目(xkxl1426);宁波大学胡岚优秀博士基金资助项目(ZX2013000319);宁波大学人才工程基金资助项目(20111537)。
程婷婷(1989-),女,硕士,主研方向:计算机视觉;郭立君,副教授、博士;黄元捷,硕士。
2015⁃01⁃04
2015⁃02⁃19E⁃mail:guolijun@nbu.edu.cn
