潜在语义分析的英汉口译语料库挖掘
2015-08-17郑丽芳唐朝辉
郑丽芳,唐朝辉
(厦门理工学院外国语学院,福建 厦门 361024)
潜在语义分析的英汉口译语料库挖掘
郑丽芳,唐朝辉
(厦门理工学院外国语学院,福建 厦门 361024)
分析潜在语义分析的理论基础,结合英汉口译语料库的相关特点,提出了基于潜在语义分析的口译语料相似度的度量方法.基于PACCEL英汉口译语料库的实验表明,该方法的检索精度为0.79,召回率为0.59,F1为0.68,检索时间为1.124 s,在检索精度、召回率、F1值以及时间效率上均显著优于实验的参照方法.该方法能为用户提供更有效的检索推荐以及在扩展语料库时自动探析语料库存在的数据冗余,为语料库的构建和扩展提供了有效指导.
语料库;英汉口译;知识挖掘;潜在语义分析
1998年基于语料库的口译研究由Miriam Shlesinger首次提出[1].日本名古屋大学从1999年至2003年研究并开发了包含英语、日语的同传语料库(简称CIAIR),收录的撰写材料达到100万字,是当前规模最大的同声传译语料库[2].意大利博洛尼亚大学于2004年研发了“欧洲议会口译语料库”(简称EPIC)[3],库容约18万字,是一个包含英语、西班牙语、意大利语的多语平行同声传译语料库.除上述两个大型口译语料库之外,国外部分研究者开始独自研发中小型专题语料库,用实证研究的方式来补充传统的思辨内省模式的口译研究方式.
国内关于口译语料库的研究起步相对较晚,于2007年才陆续出现这方面的研究成果[4-6].目前依据语料库语言学通行模式建成并投入使用的口译语料库只有2个.2008年,文秋芳教授主持建立了中国大学生英汉汉英口笔译语料库(简称PACCEL)[7],是中国首个仅有的学习者口译语料库.由于其语料缺少充分标注,基于该语料库的口译研究较少.2010年,上海交通大学胡开宝教授主持研发了“汉英会议口译语料库”[4](简称CECIC),该语料库分为3部分:新闻发布会汉英平行语料子库、新闻发布会英语原创语料子库和政府工作报告汉英平行语料子库.语料来源为国内外新闻发布会口译活动,库容已从初期的19万字左右扩展为约54万字.文献[8]探讨了大规模英汉平行语料库的开发与其实用性,但目前基于该语料库的研究主要集中在翻译共性及汉英口译语言特征等领域,尚未涉及其在口译教学与培训中的应用.
虽然目前已经存在一定数量的英汉口译语料库,但对语料库的挖掘研究还相对较少.目前对知识库进行挖掘的模型中,统计语言模型是一种较为成熟、应用最为广泛的工具[9-12].针对英汉口译语料库的特点,本文结合潜在语义分析的理论,提出了基于潜在语义分析的英汉口译语料库挖掘方法,通过理论分析、实例推演以及实验证明了该方法的有效性.
1 潜在语义分析的相关概念
潜在语义分析方法基于统计学,具有严格的数学证明与理论推导,通过对统计信息对应的矩阵进行奇异值分解,提取数据的语义信息.在计算机不足以理解数据语义的情况下,潜在语义分析可以为数据“语义"的提取提供有力的支持.
1.1矩阵奇异值分解
奇异值分解(singular value decomposition,SVD)是线性代数中一种很重要的矩阵分解,多用于信号处理、自然语言处理等领域[13].
假设M是一个m×n的矩阵,其中的元素全部属于实数域,则矩阵可以表示成矩阵乘积,记为M=USVT,其中:U是m×m阶酉矩阵;S是半正定m×n阶对角矩阵;VT是n×n阶酉矩阵.把M=USVT称作矩阵U的奇异值分解.S对角线上的元素为矩阵M的奇异值,在求解矩阵奇异值分解时通常将奇异值由大而小排列,如下所示:
1.2语义空间与语义子空间
在对统计数据进行语义分析之前,要先构造统计信息对应的矩阵M,然后利用矩阵的SVD分解M=USVT来获取统计数据对应的语义子空间U与VT,处理过程中通常只需要取语义空间U,VT的前几列.
2 基于潜在语义分析的英汉口译语料库挖掘方法
英汉口译语料库的英语语料可以表示成“语料-词汇”矩阵的形式,矩阵中的每个值表示检索词汇在语料中的出现频率,如表1所示.通过使用矩阵SVD分解来提取“语料-词汇"矩阵的语义空间,从语义空间提取的语料相似度是语料中词汇对应的上下文语境统计信息的综合体现,从而可以更有效地计算出语料之间的语义相似度.处理过程如图1所示,具体处理流程如下:

表1 一个简化的英汉口译语料库英文语料
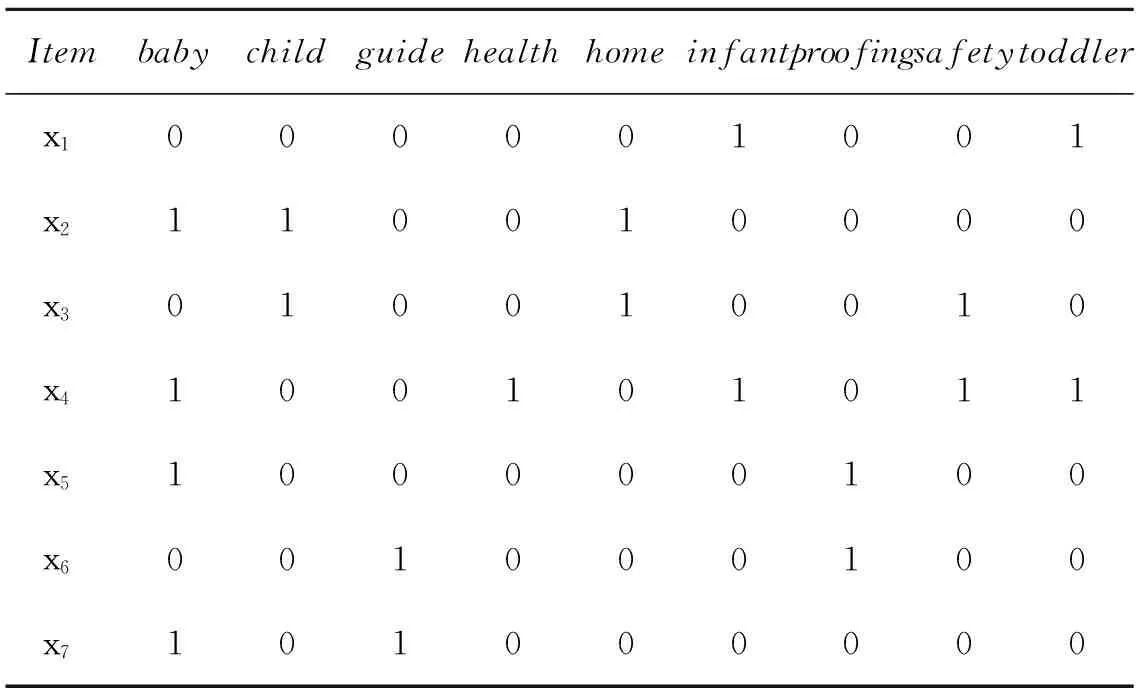
Itembabychildguidehealthhomeinfantproofingsafetytoddlerx1000001001x2110010000x3010010010x4100101011x5100000100x6001000100x7101000000
1)通过语料库获取“语料-词汇”矩阵M.当语料库具备一定的规模,这个过程通常会比较耗时,因为需要确定整个语料库的所有检索词汇表并计算出这些检索词汇在每个语料库中的出现频率.易知,该矩阵是高度稀疏的,即矩阵中存在很多的0.
2)对矩阵M进行奇异值分解M=USVT,得到语料语义空间以及词汇语义空间.其中:U表示语料语义空间;VT表示词汇语义空间;S中的值为“语料-词汇”矩阵M的非零奇异值,当以降序排列这些非零奇异值,同时取最大几个奇异值所对应的U的列与VT的行分别作为语料语义子空间、词汇语义子空间.通常当语料库达到一定的规模,语义子空间的存储规模至少要比M的存储规模小3个数量级(1 000倍).
3)在语料子空间计算两两语料之间、两两词汇之间的语义距离相似度/距离.在低维语料语义空间计算出来的语料之间的相似度,与在M中计算相似度相比,其计算速率和计算精度都会有很大的提高.
4)通过计算出来的语料语义相似度/距离,可以为语料库的使用者提供更准确有效的检索推荐.同时当有新的语料添加时,可以通过SVD分解的逆运算,计算出新的语料在原有词汇语义空间的投影,便可以得到该语料的语义向量,从而可以得出新语料与语料库原有语料的语义相似度,使得语料库的维护者可以更有效地维护语料库,不至于出现太多无效的语料冗余.
3 实验结果
本节通过实例推导与在实际语料库上的实验效果来验证基于潜在语义分析的英汉口译语料库挖掘方法的有效性.
为便于阐述,本文首先采用包含7个语料、9个检索词汇的一个简单英汉口译语料库,并且只考虑每个语料的英文部分.因为英汉口译语料库中语料相似度的度量通常是基于英文语料.如表1所示,其中xi表示英汉口译语料库中的一个英语语料,baby、child、guide、health、home、infant、proofing、safety、toddler表示语料库包含的词汇,表中每个值代表词汇在对应英文语料中出现的频率.最后在实际的语料库中验证潜在语义分析方法的有效性.
3.1基于语料语义子空间的语料相似度的度量
对表1对应的“语料-词汇”矩阵M进行奇异值分解,其结果对应的U、S、VT矩阵分别如下:
不失一般性,本例中取语义子空间的维度为2,记为δ=2,则U、VT中用方框圈起来的部分就是语料“语义”子空间,VT矩阵对应就是词汇“语义”子空间.
由U矩阵可知,7个语料在语料语义子空间的坐标分别为(0.252 7,-0.442 1)、(0.419 7,0.543 4)、(0.338 2,0.468 6)、(0.702 5,-0.498 5)、(0.267 2,0.121 7)、(0.096 1,0.107 9)、(0.267 2,0.121 7).

因为对称性,所以只需要计算对角线一边就可以了.距离越小,代表对应的语料相似度越大,反之亦然.

表2 语料在语料语义子空间中的距离度量结果
3.2基于词汇语义子空间的词汇相似度的度量
基于VT对应的词汇语义空间,可以计算出9个词汇在词汇语义子空间的坐标分别为(0.602 6,0.275 7)、(0.139 8,0.490 6)、(0.378 3,-0.298 3)、(-0.660 4,0.119 5)、(0.000 0,0.000 0)、(0.096 1,0.107 9)、(0.267 2,0.121 7).
同上,可以计算出9个词汇在词汇语义子空间中的语义相似度.这种词汇相似度计算方式的优势在于它不是基于词典中词条的解释,而是基于词语在所有语料中的上下文统计信息.可以看到,要有效计算出词汇的语义相似度,需要大量的语料上下文环境.本例中只有7个语料,不能很有效地获取足够多的词汇在语料上下文中的统计信息,因而无法有效计算出词汇间的语义相似度,但当语料库逐渐扩展到一定的规模,这种计算方法的优势将变得明显.
3.3潜在语义分析在PACCEL上的实验效果
《中国大学生英汉汉英口笔译语料库》[7],简称PACCEL,是国内目前使用较为广泛的语料库.本节实验采用的英汉口译语料库从PACCEL中抽取,将潜在语义分析方法应用到从PACCEL上抽取的英汉口译语料库;潜在语义分析的矩阵奇异值分解是离线处理,处理时间不必计入在线检索时间,且语义空间维度δ=3.
检索的任务是将语料库中的语料标记为检索语料的相似类(positive)或不相似类(negative).因此有4种情况:如果一个语料与检索语料相似并且也被预测成相似类,即为真相似类(truepositive),满足这类条件的语料个数记为TP;如果语料与检索语料不相似,但预测为相似类,则称之为假相似类(falsepositive),个数记为FP;如果语料与检索语料不相似并且该语料被预测成不相似类,称之为真不相似类(truenegative),个数记为TN;相似类被预测成不相似类则为假不相似类(falsenegative),个数记为FN.

表3 在PACCEL使用潜在语义分析的检索性能(δ=3)Table3 RetrievalinPACCELusingLSA(δ=3)性能指标常规检索方法潜在语义分析方法P0.630.79R0.320.59F10.420.68平均检索时间/s1.7321.124
实验采用检索精度(P)、召回率(R)以及P与R的加权平均F1值来衡量本文所提方法在PACCEL上的检索性能.计算公式分别为P=TP/(TP+FP),R=TP/(TP+FN),F1=2(P-1+R-1)-1.检索性能测试结果如表3所示.
由表3可知,潜在语义分析方法在PACCEL英汉口译语料库中的检索精度、召回率、F1值以及时间效率上均较显著地优于常规检索方法.由此可见,采用潜在语义分析方法挖掘英汉口译语料库,可以大大提高语料库的检索性能和效率;当语料库规模增大时,潜在语义分析方法的时间性能与检索性能会有相应的提升,因为语料会被更充分的统计,因而语义空间会更紧凑、更准确.
4 小结
本文通过引入潜在语义分析技术对所有英语语料对应的“语料-词汇”矩阵进行分析,得出“语料-词汇”矩阵的“语义”子空间;在得到的“语义”子空间进行英语语料之间的语义相似度度量、新语料与语料库中语料的相似度度量以及词汇之间的语义相似度度量,不但可以提高处理的时间效率,同时还可以提高计算的精度.实例证明,本文提出的基于潜在语义分析的英汉口译语料库挖掘方法对于具有一定规模的语料库是有效可行的.由于汉语语料处理存在分词上的困难,本方法在处理汉语语料时不能有效获取汉语语料的潜在语义,因此在后续的研究中将引入适当的中文分词机制以有效获取中文语料的潜在语义,从而提高英汉双语语料库的挖掘精度与效率.
[1]SHLESINGERM.Corpus-basedinterpretingstudiesasanoffshootofcorpus-basedtranslationstudies[J].Meta,1998(4):486- 493.
[2]张威.近十年来口译语料库的研究现状及发展趋势[J].浙江大学学报:人文社会科学版,2012,42(2):136-143.
[3]MONTIC,BENDAZZOLIC,SANDRELLIA,etal.Studyingdirectionalityinsimultaneousinterpretingthroughanelectroniccorpus:EPIC(Europeanparliamentinterpretingcorpus)[J].Meta,2005(4):114-129.
[4]胡开宝,吴勇,陶庆.语料库与译学研究:趋势与问题[J].外国语,2007(5):64-69.
[5]张威.口译语料库的开发与建设:理论与实践的若干问题[J].中国翻译,2009(3):54-59.
[6]胡开宝,陶庆.汉英会议语料库的创建与应用研究[J].中国翻译,2010(5):49-56.
[7]文秋芳,王金铨.中国大学生英汉汉英口笔译语料库[M].北京:外语教学与研究出版社,2008.
[8]赵巍,王雷.大规模英汉平行语料库的开发与实用性探讨[J].牡丹江师范学院学报:哲学社会科学版,2014(4):117-118.
[9]ZHOUGD,LUAKIMTENG.Interpolationofn-gramandmutual-informationbasedtriggerpairlanguagemodelsformandarinspeechrecognition[J].ComputerSpeechandLanguage,1999,13(2):125-141.
[10]STANLEYFCHEN.Buildingprobabilisticmodelsfornaturallanguage[D].Cambridge:HarvardUniversity,1996.
[11]NIESLERTR,CWOODLANDP.Variable-lengthcategoryn-gramlanguagemodels[J].ComputerSpeechandLanguage,1999,13(1):99-124.
[12]袁里驰.基于统计的句法分析方法[J].中南大学学报:自然科学版,2014,45(8):2 669-2 674.
[13]VIRGINIACKLEMA,ALANJLAUB.Thesingularvaluedecomposition:itscomputationandsomeapplications[J].IEEETransactiononAutomaticControl,1980,25(2):164-175.
(责任编辑雨松)
LSA-based Mining of English-Chinese Interpreting Corpus
ZHENG Li-fang,TANG Chao-hui
(SchoolofInternationalLanguages,XiamenUniversityofTechnology,Xiamen361024,China)
LSA-baseddatasimilaritymetricsintheinterpretingcorpusisthusproposedonanin-depthanalysisofthetheoreticalbasisoflatentsemanticanalysisinviewofthecharacteristicsofEnglish-ChineseInterpretingCorpus.ExperimentresultsbasedonPACCELshowthat:P=0.79,R=0.59,F1=0.68,t=1.124s,sothemethodissignificantlybetterthanthereferencedmethodformininginterpretingcorpusinretrievalprecision,recallrate,F1andtimeefficiency.Themethodprovidesmoreeffectivesearchrecommendationsandmakesautomaticdetectingofdataredundancywhenthecorpusisextended.
corpus;English-Chineseinterpreting;knowledgemining;latentsemanticanalysis
2014-10-01
2015-01-15
福建省教育厅科技项目(JB12252S,JB14082);厦门理工学院教改项目(JGY201315);国家级大学生创新项目(201411062043)
郑丽芳(1983-),女,讲师,硕士,研究方向为英语语料库.E-mail:2011110301@xmut.edu.cn
TP181;H315
A
1673-4432(2015)01-0086-05
