基于堆叠稀疏自动编码器的手写数字分类
2015-08-07林少飞盛惠兴李庆武
林少飞,盛惠兴,李庆武
(河海大学物联网工程学院,常州213022)
基于堆叠稀疏自动编码器的手写数字分类
林少飞,盛惠兴,李庆武
(河海大学物联网工程学院,常州213022)
将稀疏自动编码器(Sparse Autoencoder,SAE)模型应用于数字识别中,并通过多个稀疏自动编码器的堆叠构建了深度网络,采用非监督贪婪逐层训练算法(Greedy Layer-Wise Unsupervised Learning Algorithm)初始化网络权重,使用反向传播算法优化网络参数。利用堆叠稀疏自动编码器学习数字图像的特征,使用softmax分类器进行数字分类。经实验证明,与其它浅层学习模型对比,深度网络不仅进一步学习了数据的高层特征,同时还降低了特征维数,提高了分类器的分类精度,最终改善了手写数字的分类效果。
堆叠稀疏编码器;非监督贪婪逐层训练;反向传播算法;softmax分类器
1 引 言
手写数字识别(Handwritten Numeral Recognition,简称HNR)是模式识别学科的一个传统研究领域,主要研究如何利用计算机自动辨识手写的阿拉伯数字。经过几十年的发展,现有HNR技术取得了诸多进展,国内外都研发了相对成熟的产品。但当前多数分类、回归等学习方法都局限于浅层结构学习,如K最近邻节点算法(k-Nearest Neighbor algorithm,简称KNN)[1-2]、支持向量机(Support Vector Machine,简称SVM)[3-4]以及神经网络[5]。其局限性在于样本有限、计算单元对复杂函数的表示能力不足以针对复杂分类问题及其泛化能力受制约等。为克服这些问题,近年来兴起了深度学习的研究热潮。所谓深度学习,即是通过学习一种深层非线性网络结构,实现对复杂函数逼近,表征输入数据分布式表示,并展现其强大的从少数样本集中学习数据集本质特征的能力。
稀疏自动编码器作为深度学习中出现的变形结构,具有良好的学习数据集特征的能力。通过多个稀疏自动编码器(Sparse Autoencoder,SAE)的堆叠可以形成堆叠稀疏自动编码器(Stacked Sparse Autoencoder),堆叠稀疏自动编码器能够进一步学习数据集中的特征,同时降低特征维数。对于深度网络的训练,采用Hinton基于深信度网(Deep Belief Nets,DBN)提出的非监督贪婪逐层训练算法[6]。
采用深度学习中的稀疏自动编码器模型,建立了多层的堆叠稀疏自动编码器网络对MNIST数据集在matlab上进行仿真实验,对实验结果作了分析,并与现有一些识别方法的实验结果作比较,得出了结论。
2 理论与方法
2.1 自动编码器
假设一个未带类别标签的训练样本集合x(x∈[0,1]d),通过变换公式(1)将输入x变换为激活值y,(y∈[0,1]d)。x与y满足公式(1):

其中s是一个非线性函数,例如sigmoid函数。θ={W,b}为参数集合。然后通过变换公式(2)将激活值y反向变换为对原始输入x的一种重构表示z,y与z满足公式(2):

其中θ′={W′,b′}为参数集合。公式(1)、(2)两个参数集合中的参数W′,WT被限制满足如下关系W′=WT。最后通过不断修改θ和θ′使得平均重构误差L达到最小化。L定义为:

直观上讲,如果激活值能够对它的原始输入进行良好重构,那么就认为它保留了原始数据所含有的大部分信息[7-8]。现今自动编码器已应用于众多领域如语音识别,并取得巨大成就[9]。
2.2 稀疏编码
如果只是简单的保留原始输入数据的信息,并不足以让自动编码器学到一种有用的特征表示。例如,一个自动编码器,它的输入和输出具有同样维度,那么自动编码器只需学习到一个简单的恒等函数就可以实现数据的完美重构。而实际则希望它能够学习到一种更复杂的非线性函数,因此需要给予自动编码器一定的约束使其学习到一种更好的特征表示。这个问题可以通过使用概率型限制型玻尔兹曼机(Restricted Boltzmann Machine,RBM),稀疏编码(Sparse Auto-Encoder,SAE)或者去噪自动编码(Denoising Auto-Encoder,DAE)对含有噪声的输入数据进行重构来解决。一般情况下稀疏编码和去噪自动编码比玻尔兹曼机更有效。
稀疏编码算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。稀疏编码算法的目的就是找到一组基向量Øi,能将输入向量X表示为这些基向量的线性组合:

虽然形如主成分分析技术(PCA)能方便地找到一组“完备”基向量,但是这里是找到一组“超完备”基向量来表示输入向量X∈Rn(也就是说,k>n)。超完备基的好处是能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数ai不再由输入向量X唯一确定。因此,在稀疏编码算法中,有另一个评判标准“稀疏性”来解决因超完备而导致的退化问题。这里,定义“稀疏性”为:只有很少的几个非零元素或只有很少的几个远大于零的元素。系数ai是稀疏的意思就是说:对于一组输入向量,尽可能让少的几个系数远大于零。选择使用具有稀疏性的分量来表示输入数据是因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。有m个输入向量的稀疏编码代价函数定义为:
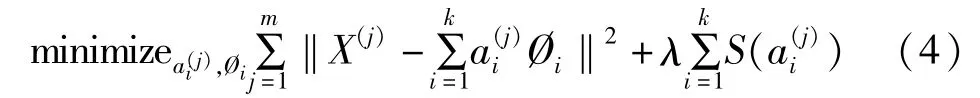

且公式(5)满足条件,‖Øi‖2≤C,∀i=1,...,k
2.3 逐层贪婪训练方法
Hinton基于深信度网(Deep Belief Nets,DBN)提出的非监督贪婪逐层训练算法是目前训练深度网络比较成功的一种方法[10]。简单来说,逐层贪婪算法的主要思路是每次只训练网络中的一层,即首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。在每一步中,把已经训练好的前k-1层固定,然后增加第k层(也就是将已经训练好的前k-1的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差)。
3 算法设计
3.1 深度网络的结构和训练方法
堆叠稀疏自动编码器网络本身不具有分类功能,它是一个特征提取器,所以要实现分类功能还需要在网络最后添加分类器,如支持向量机(SVM),贝叶斯分类器,softmax分类器等,本实验选用softmax分类器进行训练分类。
在本实验中,带有softmax分类器的堆叠稀疏自动编码器网络隐含层共有2层,网络结构图如图1所示,网络训练步骤如下:
(1)用大量的无标签原始输入数据作为输入,训练出(利用Sparse Autoencoder方法)第一个隐含层结构的网络参数,并将用训练好的参数算出第1个隐含层的输出。
(2)把步骤1的输出作为第2个网络的输入,用同样方法训练第2个隐含层网络的参数。
(3)用步骤2的输出作为多分类器softmax的输入,然后利用原始数据标签来训练出softmax分类器的网络参数。
(4)计算2个隐含层加softmax分类器整个网络一起的代价函数,以及整个网络对每个参数的偏导函数值。
(5)用步骤1,2和3的网络参数作为整个深度网络(2个隐含层,1个softmax输出层)参数初始化的值,然后用lbfs算法迭代求出上面代价函数最小值附近处的参数值,并作为整个网络最后的最优参数值。
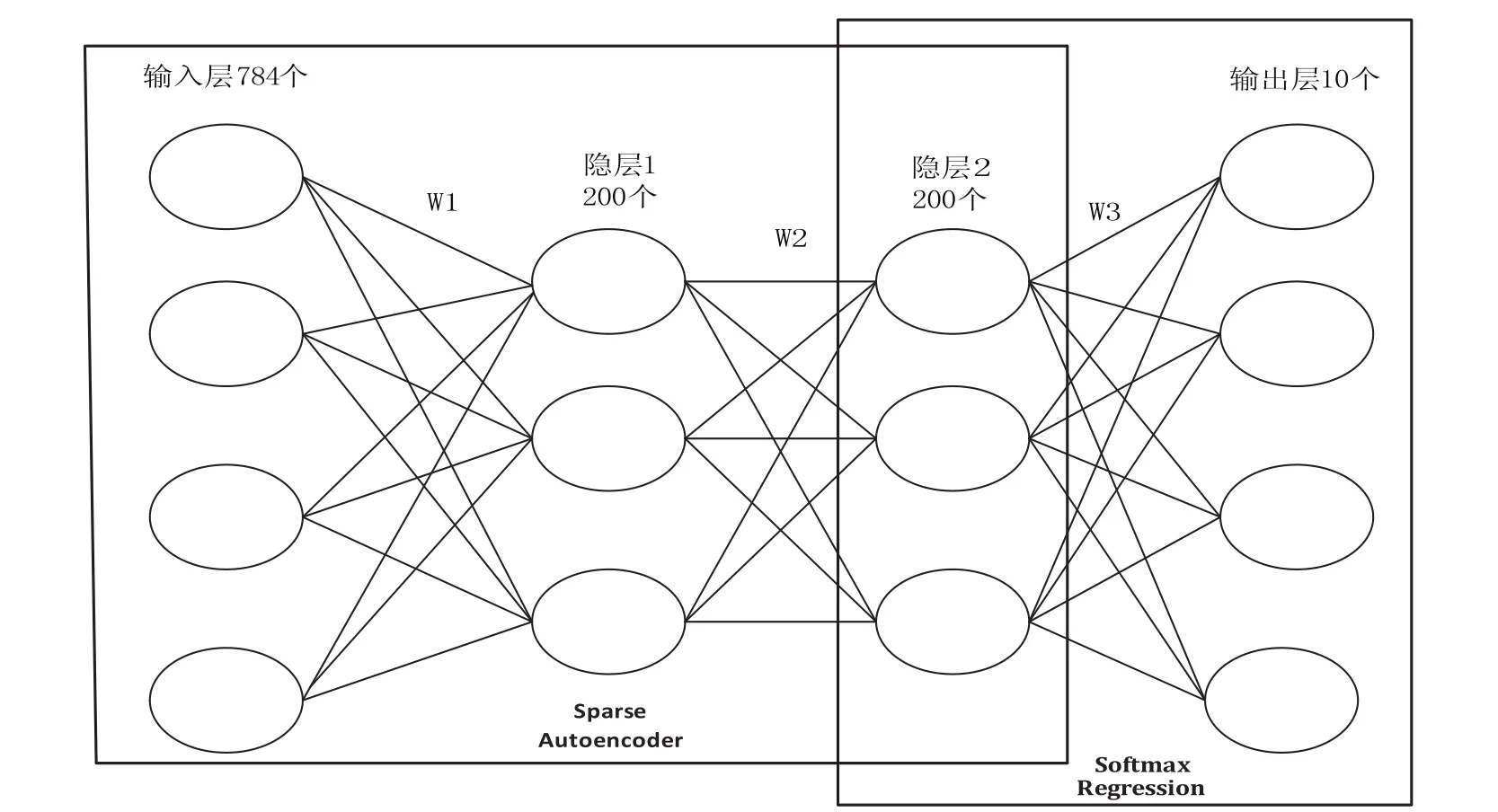
图1 网络结构图
上面的训练过程是针对使用softmax分类器进行的,而softmax分类器的代价函数是有公式计算的。所以在进行参数校正时,可以把所有网络看做是一个整体,然后计算整个网络的代价函数和其偏导,最后结合标签数据,将前面训练好的参数作为初始参数,用lbfs优化算法求得整个网络参数。
3.2 具体算法
由稀疏自动编码器堆叠构成的深度学习网络算法流程图如图2所示,主要步骤如下:
(1)将28×28的原始图像矩阵x作为输入,训练第一层稀疏自动编码器,得到参数θ1和由隐层单元激活值a1(隐层神经元节点的输出值,相当于3.1节中介绍的y)组成的向量A1。
(2)将A1作为第二层稀疏自动编码器的输入,继续训练得到第二层参数θ2和由激活值a2组成的向量A2。
(3)将A2和原始数据标签L作为第三层softmax分类器的输入,得到分类器的参数θ3。
(4)使用反向传播算法进行微调(fine tuning),算法描述如图2所示。
(5)利用训练好的网络对数据集进行分类,得到结果。
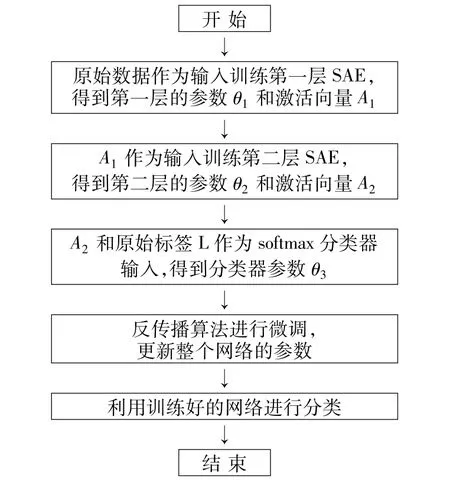
图2 算法流程图
4 实验及结果分析
实验基于Matlab平台实现,使用测试库为MNIST手写数字库数据集。MNIST字库,为Google实验室的Corinna Cortes和纽约大学柯朗研究所的Yann LeCun建立的一个手写数字数据库,该训练库中有60,000张手写数字图像,测试库有10,000张。
4.1 浅层分类器比较
比较浅层模型分类器knn、bp神经网络和softmax这三类分类器下的识别率,此时都是用二值点阵信息特征作为输入。其中bp神经网络是由输入层,隐含层,输出层构成的三层神经网络。用MNIST数据集对这三类分类器进行测试,结果如表1所示。
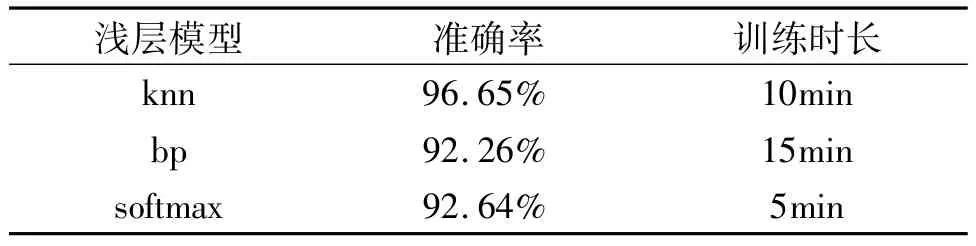
表1 浅层模型各分类器的识别效果
由表1可知,用二值点阵信息作特征时,knn的准确率为96.65%,比bp神经网络和softmax要高4个百分点左右,但总体来看,还是没有达到很高的准确率要求。
对于浅层模型来说,字符特征的选择和提取是构成识别系统的关键。根据文献[5],采用了其中的5类人工提取的字符特征分别对MNIST数据集进行测试。这5类特征分别是粗网格、七段特征投影、宽高比、端点以及穿线数,识别结果如表2所示。
由表2可知,不同的字符特征对识别效果影响很大,而且特征的线性叠加并没有对识别率有显著提高。
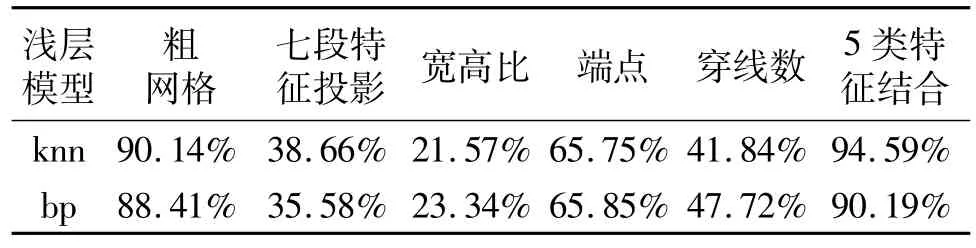
表2 各人工选取特征的识别效果
4.2 堆叠稀疏自动编码器
利用深度学习中的堆叠稀疏编码器网络对MINST数据集进行训练,并分类。
从表1、表2和表3的对比中可以看出,对MNIST手写体字库进行测试时,确实深层模型的识别率要比浅层模型有明显提高,微调过后的堆叠稀疏自动编码器网络的识别率可以达到98%。

表3 迭代次数对准确率的影响
此外深层模型未微调之前大概只有88.77%左右的准确率,微调后,增加了近10个百分点的准确率,而且随着迭代次数的增大而增大,所以微调对深度模型的准确率提高还是很重要的。这一点可以从图3中很清楚的看出来,第一层权值示意图中,迭代100次比迭代10次的数字笔画特征更清晰,更明显。
5 结束语
采用了堆叠稀疏编码器这一深度学习模型对手写体数字的分类问题进行研究,并在MNIST数据集上进行测试。与KNN,BP等浅层算法进行对比,得出深度学习在特征学习上具有自己的优势,并发现微调对准确率提高还是很重要的。
然而未能深入研究网络层数对特征学习的影响。对于网络训练而言,通常情况下训练数据越多,最终学到的特征将会更具鲁棒性。此外任何分类器的错分都无法彻底消除,只能不断提高分类效果,可采用集成分类器的思想。接下来将对这些问题进行深入研究。

图3 不同迭代次数的权值示意图
[1] Alkhateeb JH,Khelifi F,Jiang J,et al.A new approach for off-line handwritten Arabic word recognition using KNN classifier[C].//Signal and Image Processing Applications(ICSIPA),2009 IEEE International Conference on.IEEE,2009:191-194.
[2] Lee Y.Handwritten digit recognition using k nearestneighbor,radial-basis function,and back propagation neural networks[J].Neural computation,1991,3(3):440-449.
[3] Gorgevik D,Cakmakov D.Handwritten digit recognition by combining SVM classifiers[C].//Computer as a Tool,2005.EUROCON 2005.The International Conference on.IEEE,2005,2:1393-1396.
[4] Dolenko B K,Card H C.Handwritten digit feature extraction and classification using neural networks[C].//Electrical and Computer Engineering,1993.Canadian Conference on.IEEE,1993:88-91.
[5] 杜敏,赵全友.基于动态权值集成的手写数字识别方法[J].计算机工程与应用,2010,46(27):182-184.
[6] Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets[J].Neural computation,2006,18(7):1527-1554.
[7] Baldi P.Autoencoders,Unsupervised Learning,and Deep Architectures[J].Journal of Machine Learning Research-Proceedings Track,2012,27:37-50.
[8] Glüge S,B?ck R,Wendemuth A.Auto-Encoder Pre-Training of Segmented-Memory Recurrent Neural Networks[J].//Proceedings of the 21st European Symposium on Artificial Neural Networks,Computational Intelligence and Machine Learning(ESANN 2013).Bruges(Belgium).April 24-26,2013:29-34.
[9] Larochelle H,Erhan D,Vincent P.Deep learning using robust interdependent codes[C].//International Conference on Artificial Intelligence and Statistics.2009:312-319.
[10] Jaitly N,Hinton G E.Using an autoencoder with deformable templates to discover features for automated speech recognition[C].//The 14th annual conference of the International Speech Communication Association.Lyon.August2013:25-29.
Handw ritten Digital Classification Based on the Stacked Sparse Autoencoders
Lin Shaofei,Sheng Huixing,Li Qingwu
(College of Internet of Things Engineering,Hohai University,Changzhou 213022,China)
In this paper,the sparse autoencoders(Sparse Autoencoder,SAE)model is applied to the digital recognition,and a deep network is constructed by stacking a plurality of sparse autoencoders,using Greedy Layer-Wise Unsupervised Learning algorithm to initialize the weights of the network and back propagation algorithm to optimize the parameters of the network.The stacked sparse autoencoders are used to learn the features of the digital image,and the softmax classifier is used to conduct the digital classification.The experiments show that,comparing with other shallow learning models,the deep network not only studies the high-level features of the data,but also reduces the feature dimension and improves the precision of the classifier,which finally improves the classification effect of handwritten digits.
Stacked Sparse Autoencoder;Greedy Layer-Wise Unsupervised Learning Algorithm;Back Propagation Algorithm;Softmax classifier
10.3969/j.issn.1002-2279.2015.01.014
TP391
A
1002-2279(2015)01-0047-05
林少飞(1990-),男,安徽六安人,硕士研究生,主研方向:信息获取与处理。
2014-09-01
