基于语义关联的实例相似度计算方法及应用研究
2015-07-20梁少星
梁少星
(武汉大学信息管理学院,湖北武汉430072)
基于语义关联的实例相似度计算方法及应用研究
梁少星
(武汉大学信息管理学院,湖北武汉430072)
〔摘 要〕相似度计算方法的优劣直接影响到信息检索与推荐的效果。本文根据本体图模型中属性序列的特点,综合考虑层次关系和属性关系,在分析路径关联相似度、层次相交关联相似度及属性相交关联相似度的影响因素的基础上给出了实例之间综合语义相似度的计算方法。文章最后讨论了该相似度计算方法在解决基于内容的推荐中的过于专门化问题、协同过滤推荐中的稀疏性问题以及检索中查全率和查准率问题中的应用。
〔关键词〕语义关联;相似度计算;本体;属性序列
相似度计算是知识检索和知识推荐的基础及关键技术,其计算方法与资源和用户的建模及表示方式有关。本体建模由于其良好的概念层次结构、对逻辑推理的支持以及对知识的共享和复用,已成为主流的方法。
当前基于本体的相似度计算存在两大问题:
(1)为简化本体构建和相似度计算,较多考虑本体中的层次关系,忽略属性关系,影响了相似度计算的准确性。文献[1]计算相似度只考虑层次关系,忽略了属性关系,丢失了很多语义描述。文献[2-4]引入属性关系计算综合语义相似度,但考虑的属性关系过于简单,不具有普适性。
(2)侧重概念相似度计算的研究,较少有实例相似度计算的研究。计算概念相似度的目的在于可以将信息资源(如文本、网页等)特征表示为概念的集合,然后借助概念相似度计算信息资源的相似度。但在实例作为信息资源特征表示对象的应用中,需要计算实例相似度。文献[5]分析了实例相似度的影响因素,但受应用的限制,对实例相似度影响因素的分析不够全面。
本文分析了实例之间的层次关系和属性关系对相似度计算的影响,讨论了实例之间基于语义关联的相似度计算方法,并介绍了该计算方法在信息推荐和信息检索中的应用,期望改善内容推荐中的专门化问题、协同过滤推荐中的稀疏性问题以及检索中查全率和查准率不高的问题。
1 研究背景
1.1本体模型的构建
本体是共享概念模型的明确的形式化规范说明[6],可以理解和表达为一组概念的定义及其相互关系。可以将本体形式化表示为:O={C,I,RH,RP,A},其中C指概念,也称为类;I指实例,即类的具体实体;RH指概念或实例之间的层次关系(Hierarchy Relationship),包括概念之间的SubclassOf关系和概念与实例之间的InstanceOf关系;RP指概念之间或实例之间的属性关系(Property Relationship),是由用户自定义的对象属性,加强了人类的认知;A指公理。
本体模型构建一般考虑的是层次关系,表现为本体的树形结构。如若同时考虑层次关系和属性关系,则表现为更为复杂的图形结构。为简单说明,使用斯坦福大学开发的protégé4.3构建Movie本体。protégé4.3中的OntoGraf插件可以将Movie本体中的类、实例及关系以图形的形式更清楚地呈现出来。在OntoGraf中,本体表示为由节点和边组成的有向图,节点表示概念或实例,边表示属性。仅考虑层次属性RH时,本体表现为树形结构(图1),综合考虑层次属性RH和对象属性RP时,本体表现为图形结构(图2)。
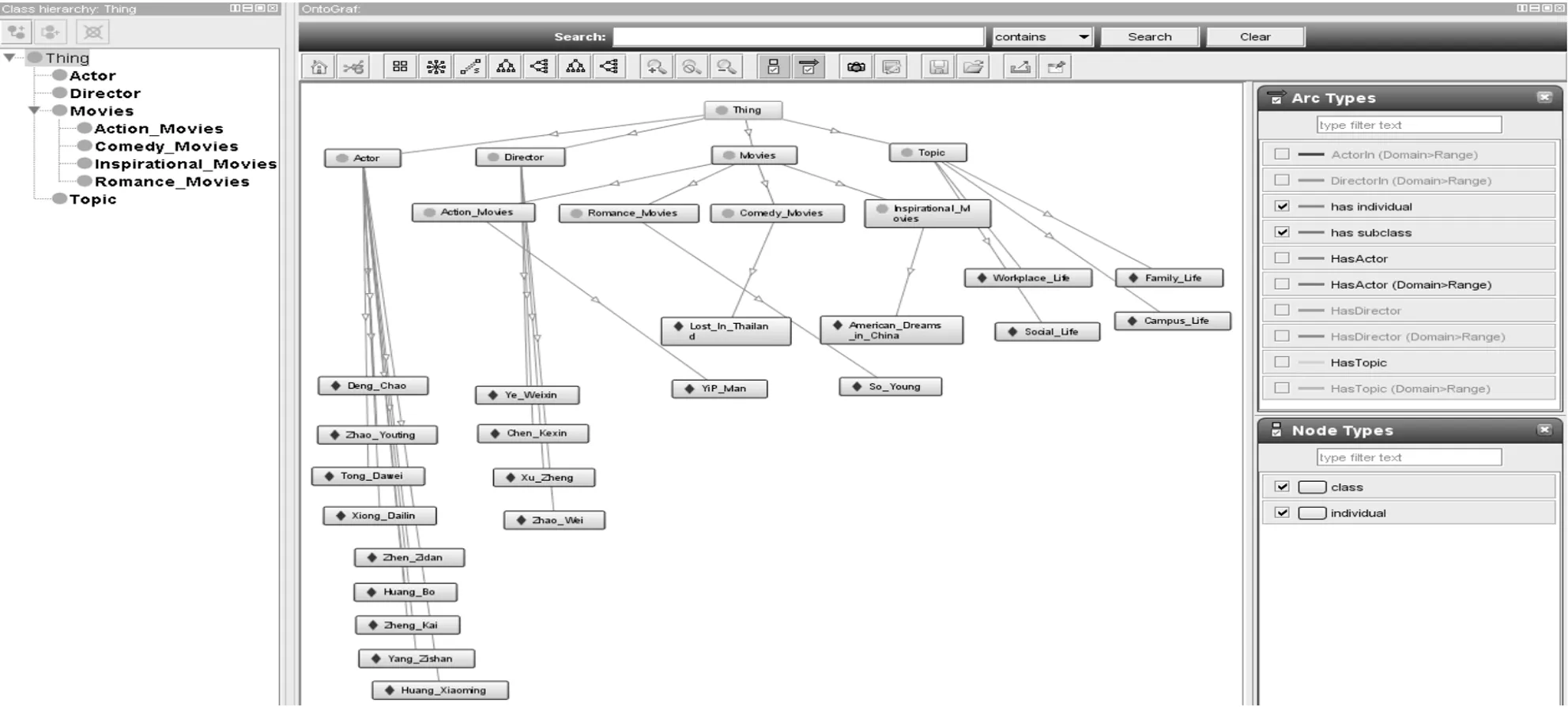
图1 仅考虑层次属性的Movie本体
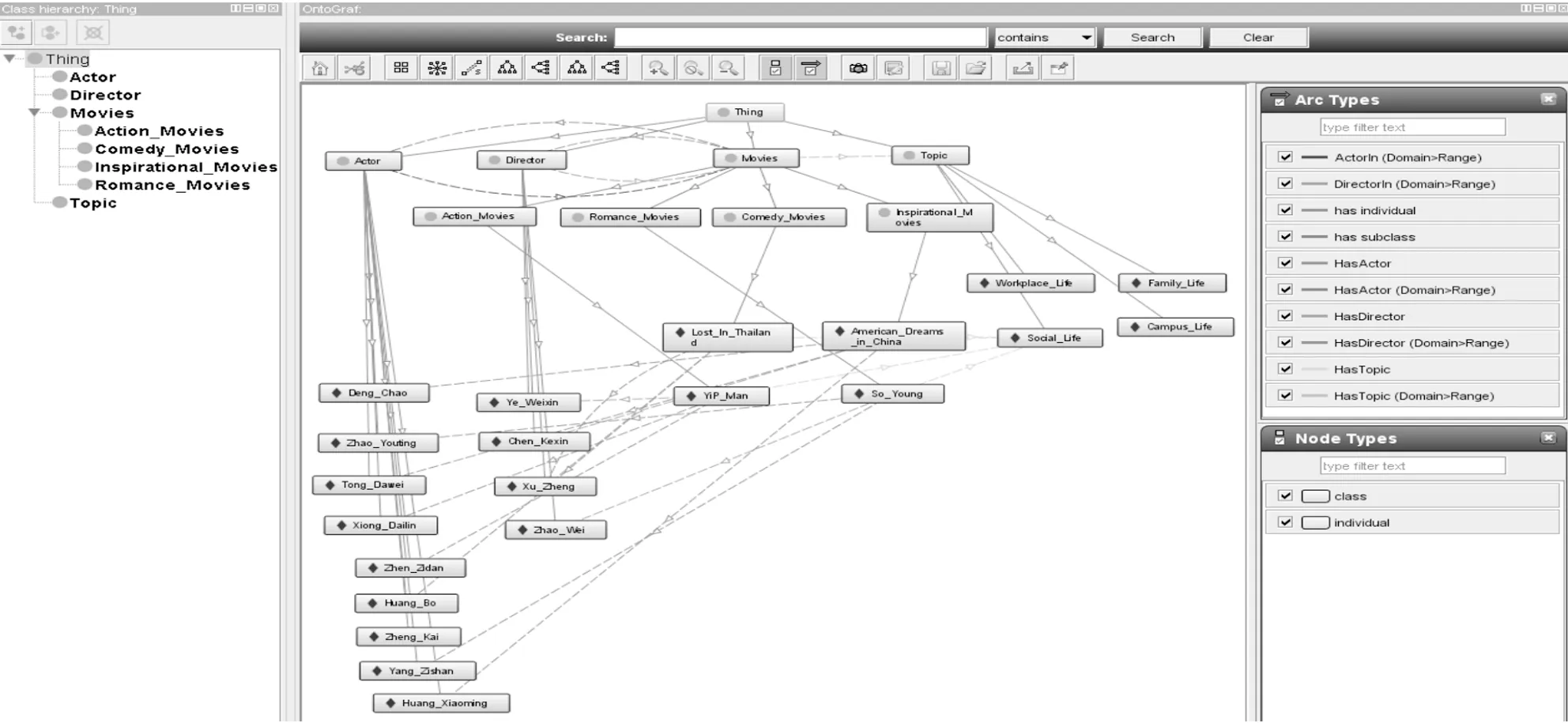
图2 综合考虑层次属性和对象属性的Movie本体
1.2属性序列
文献[7]首次提出属性序列的概念,但在属性序列的定义中仅考虑属性关系RP。本文根据实例相似度计算的需要,综合考虑层次属性RH和对象属性RP,重新对属性序列进行定义。
定义1在有向本体图模型中,如果存在n个属性p1,p2,……,pn将n+1个节点a1,a2,……,an+1连接起来(如图3所示),其中pi(1≤i≤n)∈RH∪RP,ai(1≤i≤n+1)∈C∪I,则称该有限属性集合为属性序列(Property Sequences,PS),形式化表示为:ps={p1,p2,……,pn}。属性序列的长度(length)即ps中属性的个数。
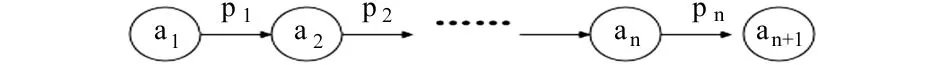
图3 属性序列示例图
定义2函数NodesOfPS()返回属性序列中属性所连接的所有节点,即NodesOfPS(ps)={a1,a2,……,an+1}。节点a1称为属性序列的起点(origin),节点an+1称为属性序列的终点(terminus)。
定义3如果属性序列ps1和ps2满足NodesOfPS(ps1)∩NodesOfPS(ps2)≠∅,则称两个属性序列相交(Joined Property Sequence),ai∈(NodesOfPS(ps1)∩NodesOfPS(ps2))称为相交节点(join node)。
1.3语义关联
本体图模型中,如果两个实例间存在连通路径,则称两个实例存在语义关联(Semantic Association,记为SA)。文献[7-9]将节点之间的语义关联分为路径关联和相交关联,但因其对属性序列定义的局限性,没有考虑层次属性RH对语义关联的影响,在应用上有局限性。
本文在定义1基础上,分析了实例间连通路径所包含的属性序列的特点,将实例之间的语义关联分为路径关联、层次相交关联、属性相交关联3类,其定义分别如下:
定义4存在一条属性序列ps,如果实例x和y分别是ps的起点和终点,且该属性序列中所有属性pi∈Rp,则称x、y之间存在路径关联(Path Association,记为PA)。
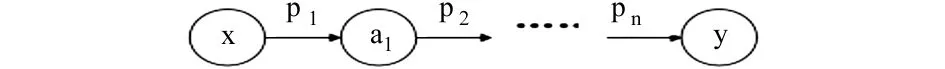
图4 路径关联
如果x和y之间存在路径关联,则x和y之间路径关联的长度等于属性序列的长度,即length(PA(x,y))=length(ps)。
定义5存在两条属性序列ps1和ps2相交,如果实例x和y同为ps1和ps2的起点或同为终点,且ps1和ps2中的所有属性pi∈RH,即实例x和y属于同一个类或相似类,则称x、y之间存在层次相交关联(Hierarchy Join Association,记为HJA)。
根据层次相交关联中实例x和y所属的类Cx和Cy是否相同,将层次相交关联分为两种情况:
(1)若Cx和Cy相同,即实例x和y为同一个类的实例,则ps1和ps2的相交节点为C(C=Cx=Cy),如图5(a)所示;
(2)若Cx和Cy不同,即实例x和y为相似类的实例,则ps1和ps2的相交节点为C(C≠Cx≠Cy),如图5(b)所示。

图5 层次相交关联
如果x和y之间存在层次相交关联,则层次相交关联的长度等于它所包含的2个属性序列的长度之和,即length(HJA(x,y))=length(ps1)+length(ps2)。
定义6存在两条属性序列ps1和ps2相交,如果x和y同为ps1和ps2的起点或同为终点,且ps1和ps2中属性p1∈RP,pi∈RH∪RP(2≤i≤n),即实例x和y具有共同或相似的属性,则称x、y之间存在属性相交关联(Property Join Association,记为PJA)。
根据属性相交关联中属性序列特点及相交节点的类型,将属性相交关联分为3种情况:
(1)实例x和y通过一个属性相交于实例I(Join Instance),此时实例x和y有共同属性,如图6(a)所示;
(2)实例x和y通过多个属性相交于实例I(Join Instance),此时实例x和y有相似属性a1和a2,如图6(b)所示;
(3)实例x和y通过多个属性相交于类C(Join Class),与第二种情况类似,此时实例x和y的属性实例a1和a2仍为相似属性,如图6(c)所示。

图6 属性相交关联
如果x和y之间存在属性相交关联,则属性相交关联的长度等于所包含的2个属性序列的长度之和,即length
(PJA(x,y))=length(ps1)+length(ps2)。
2 基于语义关联的实例相似度计算方法
本体优势在于其图形结构,图模型中节点之间的连通路径体现了节点之间的相似性。文献[10-11]将基于本体的语义相似度计算方法分为4类:基于距离的方法、基于内容的方法、基于属性的方法以及混合式方法,其中混合式语义相似度计算方法是对前面3种方法的综合考虑。本文采用混合式计算方法,综合考虑本体中的层次关系和属性关系,从语义关联的角度,分析实例之间的路径关联相似度、层次相交关联相似度和属性相交关联相似度的影响因素及算法,并对其进行综合。
2.1路径关联相似度的影响因素及算法
实例x和y之间可能存在多条路径关联,假设存在n条路径关联(如图7所示),第i条(1≤i≤n)路径关联的长度为length(PAi(x,y))。通过对图7进行分析,可知x和y之间路径关联相似度与以下因素有关:

图7 实例x和y之间的路径关联
(1)最短路径关联的长度min(length(PAi(x,y)))。实例x和y之间的最短路径关联越短,它们之间的中间结点越少,相似度也越大。
因此,实例x和y之间的路径关联相似度可以表示为:

公式(1)中a为可调节参数。
2.2层次相交关联相似度的影响因素及算法
层次相交关联是两个实例因存在共同祖先而产生的关联,层次相交关联侧重层次关系,体现实例之间的层次相似性。
一个实例可能属于多个类,即实例存在多重继承关系,实例多重继承导致实例x和y之间可能存在多条层次相交关联。假设存在n条层次相交关联且相交类为实例x和y的最近共同祖先(Lowest Common Ancestor,LCA)(如图8所示),depth(x)和depth(y)分别表示实例x和y的深度,实例深度等于实例所属类在本体树中的深度,depth(LCAi)为第i条层次相交关联中相交节点的深度,其中depth(LCA)=depth(LCA1)=depth(LCA2)=……=depth(LCAn)。通过对图8进行分析,可知x和y之间的层次相交关联相似度与以下因素有关:
(1)相交节点即最近共同祖先的深度depth(LCA)。最近共同祖先越深,实例x和y越具体,层次相交关联相似度越大。
(2)层次相交关联所在分支的最大深度max(depth(x),depth(y))。分支的最大深度越深,节点离共同祖先距离越远,节点之间的层次相交关联相似度越小。
因此,实例x和y之间的层次相交关联相似度可以表示为:

如果LCA为根节点,则层次相交关联相似度为0。
如果实例x和y属于同一个类(如图5(a)所示),则层次相交关联相似度为1,因为depth(LCAi)=depth(x)=depth(y)。

图8 实例x和y之间的层次相交关联
2.3属性相交关联相似度的影响因素及算法
属性相交关联是两个实例因存在共同属性或相似属性而产生的关联,属性关联侧重用户自定义对象属性关系,体现实例之间的属性相似性,如两部电影有同样的演员或相似的主题。
假设实例x和y之间存在n条属性相交关联(如图9所示),第i条路径相交关联的长度为length(PJAi),实例x和y的属性个数为m。通过对图9进行分析,可知x和y之间属性相交关联相似度与以下因素有关:
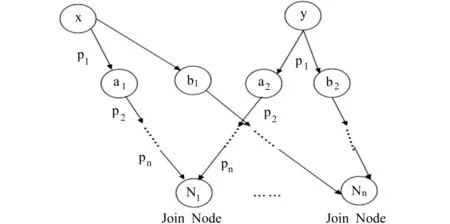
图9 实例x和y之间的属性相交关联
(1)属性相交关联条数n。属性相交关联越多,说明两个实例相同或相似的属性值越多,两个实例越相似。
(2)语义关联长度length(PJAi)。语义关联长度越长,说明两个实例相隔的路径越长,相似度越小。
因此,实例x和y之间的属性相交关联相似度可以表示为:
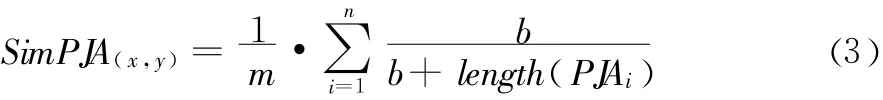
公式(3)中b为可调节参数。
2.4基于语义关联的综合语义相似度算法
两个实例之间可能存在多种语义关联,设路径关联相似度的权重为α(0≤α≤1),层次相交关联相似度的权重为β(0≤β≤1),属性相交关联相似度的权重为γ(0≤γ≤1),且α+β+γ=1,则本体中任意两个实例x和y的综合语义相似度为:
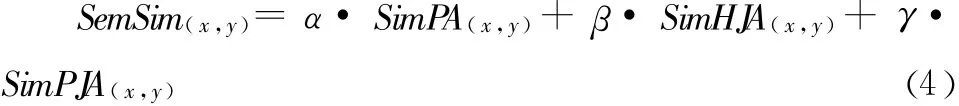
3 基于语义关联的相似度计算方法的应用
3.1在推荐领域的应用
常用的推荐方法有两种,分别是基于内容的推荐和协同过滤推荐。下面介绍语义关联在内容推荐和协同过滤推荐中的应用,并分析基于语义关联的实例相似度算法如何改善内容推荐的过于专门化问题和协同过滤推荐的稀疏性问题。
3.1.1在基于内容的推荐中的应用
基于内容的推荐策略的本质是计算项目与用户模型的相似度,向用户推荐与用户历史偏好语义相似度大的项目。
传统基于内容的推荐方法最大缺点在于过于专门化(Overspecialization)。受余弦相似度算法的限制,只有与用户偏好有相同属性的内容才会被加入最终推荐集呈现给用户,导致推荐结果过于专门化。
基于语义关联的方法可以提高推荐结果的多样性,改善过于专门化问题。基于语义关联的方法对过于专门化的改善体现在两个层面:
(1)用户偏好扩散。根据本体图模型中的连通路径,可以找到与用户模型中偏好实例存在语义关联的实例,这些实例组成一张网状图,从而实现了用户偏好的扩散。文献[5]利用扩散算法实现初始节点的继承关联扩散和路径关联扩散,发现存在内在联系的结点,但没有考虑实例之间的属性相交关联。文献[12-13]使用扩散激活技术(Spreading Activation Technique)根据路径关联和相交关联来发现与用户偏好有隐藏联系的结点,从而丰富最终的推荐结果集,但没有考虑实例之间的层次相交关联。在推荐应用中,可以根据定义4、定义5和定义6对初始节点进行全面的扩散,以发现更多与用户偏好存在语义关联的节点。
(2)相似度计算。根据偏好扩散后网状图中实例与用户模型的语义相似度来预测用户对该实例的兴趣度,并将相似度大于阈值的实例推荐给用户。
需要注意的是,用户对网状图中某实例的兴趣度不仅与该实例与用户模型的相似度有关,而且与用户模型中实例的兴趣度有关。用户模型中实例的兴趣度越大,与该实例语义相似度大的实例的兴趣度也越大。
设用户偏好扩散后的网状图中某实例为x,目标用户的用户模型Pu={(I1,D1),(I2,D2),…,(In,Dn)},其中Di为用户对第i个实例(1≤i≤n)Ii的兴趣度,则用户对实例x的预测兴趣度为:
通过公式(5)可知,在兴趣度预测时可以综合考虑实例之间的路径关联相似度、层次相交关联相似度和属性相交关联相似度,不仅向用户推荐与用户偏好有相同属性的项目,而且推荐与用户偏好语义关联的项目,最终提高推荐结果的多样性,改善过于专门化问题。
3.1.2在协同过滤推荐中的应用
协同推荐的本质是发现与目标用户偏好相同的邻居用户,将邻居用户喜欢的节目推荐给目标用户,因此邻居用户的发现是核心。邻居用户的发现需要借助用户偏好之间的相似性来计算。
传统协同过滤方法的最大缺点是稀疏性问题。受到用户相似度算法的限制,只有当用户喜欢更多相同的项目时才表明用户相似大,因此导致发现的邻居用户较少,产生了稀疏性问题,影响了推荐的质量和效率。
基于语义关联的方法可以将项目语义相似度加入用户相似度算法中,通过对用户相似度算法加以修正来优化最近邻的形成,最终改善稀疏性问题[3]。
假设目标用户(Target User)的用户模型Pu={(I1,DTU1),(I2,DTU2),…,(In,DTUn)},其中Di为用户对实例Ii(1≤i≤n)的兴趣度。目标用户TU的用户偏好向量可以表示为→VTU=(DTU1,DTU2,…,DTUn),候选邻居CN(Candidate Neighborhood)的用户偏好向量可以表示为→VCN=(DCN1,DCN2,…,DCNn)。
传统方法通过计算目标用户TU和候选邻居CN之间的余弦相似性选择最近邻,然后将最近邻喜欢的项目推荐给目标用户,余弦相似度算法可以表示为:SimCos(TU,CN)

基于语义关联的方法通过加入项目的语义相似度对用户向量的点积加以修正,优化最近邻的形成,修正后的公
通过对比分析得出,基于语义关联的相似度可以通过项目的语义相似度改善用户相似度度量,找出更多的最近邻,改善稀疏性问题。
3.2在检索领域的应用
传统的搜索引擎存在两大问题:一是大都采用基于关键字的相似度匹配方法,由于系统不能理解用户输入的查询信息,导致查全率和查准率不高;二是没有对个性化的查询需求给予重视,不同兴趣的用户使用相同的关键字,查询结果完全相同。
针对问题一,基于本体的方法可以将用户输入关键词映射为本体概念或实例,进行基于概念或实例的语义检索,从而帮助系统理解用户意图,提高检索质量。针对问题二,可以借助语义关联对用户本体模型进行语义扩展,满足用户的个性化需求,提高查准率。
下面从查询词的映射和用户模型的语义关联扩展两个方面,分析语义关联相似度如何通过提高查询词映射的准确率及对用户模型进行语义扩展来提高查询的查准率和查全率。
3.2.1在查询词映射中的应用
基于本体的检索需要将用户输入的关键词映射为本体概念或实例,进行基于概念或实例的语义检索,但在映射过程中,由于不能确定用户意图,可能产生错误的映射。
一般来说,用户在一次查询中输入多个关键词代表用户查询意图,因此这些关键词之间存在较强的关联。将n个查询关键词映射为本体库中的n个实例集后,选择语义相关度高的实例进行组合,该组合代表用户正确查询意图的可能性也较大[14]。文献[5]在选择映射实例时,仅考虑了路径相似度,用实例之间的最短属性序列长度代表语义相似度,忽略了层次相交相似度和属性相交相似度(即在公式(4)中只取α=1,而β=0,γ=0),影响了查全率和查准率。在具体应用中,可以根据应用的需要,对公式4中的各个权重参数加以调整,利用语义关联相似度提高实例映射的准确率,优化用户输入,帮助搜索引擎有效推测用户意图,最终提高检索的查准率。
3.2.2在用户模型语义扩展中的应用
语义关联可以对用户模型进行语义扩展,从而为不同兴趣的用户提供满足其个性化需求的搜索服务。对于用户模型的表示,可以使用浏览历史中包含的实例来表示用户模型,如文献[5]将用户对网页的偏好转化为对本体实例的偏好,形成用户偏好模型。
根据实例之间的语义关联实现用户偏好扩散,可以发现隐含的用户偏好,并利用实例之间的语义相似度更新实例的兴趣度。与基于语义关联的内容推荐相似,假设用户偏好扩散后的网状图中某实例为x,可以根据公式(5)更新实例x的兴趣度,最后对检索结果重新排序。因此,与用户模型相结合,可以满足用户的个性化需求并提高查准率,利用公式(4)的语义关联相似度对用户模型进行语义扩展,可以提高查全率。
4 结 语
本文从属性序列的角度分析了实例之间的路径关联、层次相交关联、属性相交关联对语义相似度的影响,并得出了综合语义相似度的算法。将该相似度算法应用于推荐和检索中,可以对基于内容的推荐中的过于专门化问题、协同过滤推荐中的稀疏性问题以及检索中查全率和查准率不高的问题加以改善。
后续工作将建立领域本体并设计对比实验验证所提出相似度算法的有效性,并使用定量分析验证该算法在推荐和检索质量改善方面的效果。
参考文献
[1]陈沈焰,吴军华.基于本体的概念语义相似度计算及其应用[J].微电子学与计算机,2009,25(12):96-99.
[2]Fernández Y B,Pazos Arias J J,Nores M L,et al.AVATAR:an improved solution for personalized TV based on semantic inference[J]. Consumer Electronics,IEEE Transactions on,2006,52(1):223-231.
[3]Martín-Vicente M I,Gil-Solla A,ramos-Cabrer M,et al.A semantic approach to improve neighborhood formation in collaborative recommender systems[J].Expert Systems with Applications,2014,41(17):7776-7788.
[4]杨美荣,邵洪雨,史建锋,等.改进的领域本体概念相似度计算模型研究[J].情报科学,2014,32(5):72-77.
[5]梅翔,孟祥武,陈俊亮,等.一种基于用户偏好分析的查询优化方法[J].电子与信息学报,2008,30(1):33-37.
[6]Studer R,Benjamins V R,Fensel D.Knowledge Engineering,Principles and Methods[J].Data and Knowledge Engineering,1998,25(1):161-197.
[7]Anyanwu K,Sheth A.Theρoperator:discovering and ranking associations on the semantic web[J].ACM SIGMOD Record,2002,31(4):42-47.
[8]Anyanwu K,Sheth A.ρ-Queries:enabling querying for semantic associations on the semantic web[C]∥Proceedings of the 12th international conference on World Wide Web.ACM,2003:690-699.
[9]Blanco-Fernández Y,Pazos-Arias J J,Gil-Solla A,et al.A flexible semantic inference methodology to reason about user preferences in knowledge-based recommender systems[J].Knowledge-Based Systems,2008,21(4):305-320.
[10]刘宏哲,须德.基于本体的语义相似度和相关度计算研究综述[J].计算机科学,2012,39(2):8-13.
[11]孙海霞,钱庆,成颖.基于本体的语义相似度计算方法研究综述[J].现代图书情报技术,2010,26(1):51-56.
[12]Blanco-Fernández Y,López-Nores M,Gil-Solla A,et al.Exploring synergies between content-based filtering and Spreading Activation techniques in knowledge-based recommender systems[J].Information Sciences,2011,181(21):4823-4846.
[13]徐守坤,孙德超,石林,等.基于语义推理的学习资源推荐[J].计算机工程与设计,2014,35(4):1496-1501.
[14]张克状,刘友华,黄芳,等.一种面向用户兴趣的个性化语义查询扩展方法[J].现代图书情报技术,2008,24(8):48 -52.
(本文责任编辑:郭沫含)
·研究生园地·
Research on Computation Method of Instance Similarity based on Semantic Association and its Application
Liang Shaoxing
(School of Information Management,Wuhan University,Wuhan 430072,China)
〔Abstract〕The effect of information retrieval and recommendation is relative to the similarity computation method.Taking hierarchy relationships and property relationships into account,this paper analyzed the influencing factors of path association similarity,hierarchy join association similarity and property join association similarity according to the characteristics of property sequence in ontology diagram model,and then proposed a similarity computation method between instances.Finally,this paper discussed the applications of this similarity computation method in solving overspecialization problem of content-based recommendation,sparsity problem of collaborative filtering recommendation and recall ratio and precision ratio problems of information retrieval.
〔Key words〕semantic association;similarity computation;ontology;property sequence
作者简介:梁少星(1990-),女,硕士研究生,研究方向;个性化推荐。
收稿日期:2015-05-14
〔中图分类号〕G252.2
〔文献标识码〕A
〔文章编号〕1008-0821(2015)08-0151-06
DOI:10.3969/j.issn.1008-0821.2015.08.030
