基于知识地图的政府诉求文件自动推送模型研究
2015-12-14郑小雪
郑小雪


〔摘要〕当前不少政府部门在其官网上设置了意见反馈栏目,旨在为公众提供申诉和表达意见的渠道。为了表示对公众诉求意见的重视,有关部门必须快速且正确地将诉求文件推送至对口部门进行处理及回应。为解决上述问题,本文提出基于知识地图的政府诉求文件自动推送模型,主要包括通过历史文件的处理构建政府知识地图的模型和机制,并实现知识地图与新进诉求文件的匹配,实现文件到部门的正确推送,有助于减少人工分拣文件的作业,提高政府行政效率。
〔关键词〕知识地图;诉求文件;自动推送
DOI:10.3969/j.issn.1008-0821.2015.08.009
〔中图分类号〕D035〔文献标识码〕B〔文章编号〕1008-0821(2015)08-0043-04
近年来,随着互联网的快速发展,促使了我国网络用户的大幅度增加;同时随着信息科技与产业竞争环境的日新月异,对于客户关系管理(Customer Relationship Management,CRM)来说,建立一套完整的客户信息系统是最为必要的,其目的在于管理和维护客户关系,开发出适合客户个性需求的产品或服务,从而提高客户的满意度同时吸引优质的新客户。对于服务型政府部门而言,公众就是它的客户,同样需要有良好的客户关系管理来提升公众对政府部门的满意度。
借助于客户关系管理理论及相关技术,许多企业利用互联网提供各种网络服务,方便客户在没有时间、地点的限制下接受企业服务,如:网上购物、技术咨询、问题反馈等。同样地,政府部门开通了不少便民服务平台,收集民众关于社会生活的各种诉求问题,通过对问题的回应和处理,完善政府的行政管理机制,为公众提供更便捷有效的政府服务,提高公民对政府的满意度。以福建省福州市“便民呼叫中心12345”为例,该平台叠加了网站、E-mail、短信、传真、QQ等多种方式,自2006年3月由鼓楼区升级到福州市级层面应用以来,截至2012年12月31日,共办理诉求件928 255件次,及时回复率为9874%,群众基本满意率达9333%。然而,纵观我国各种政府便民服务网站,虽然不乏像“福州12345”这样的优秀的公共平台,但是仍然存在诸多问题:首先,现有的便民服务平台的辐射范围有限,仅能维持市一级(及以下)的回应民意服务;其次,由于网络舆情问题越来越受到政府、公众及社会各界人士的关注,现今政府便民平台回应民众的准确率和时效性不高,容易激化舆情矛盾;最后,我国行政组织结构过于庞大,而公众陈情或请求回应的文件过于复杂,常常需要人工分辨后才能指派给相关部门进行处理,政府回应过慢容易导致民怨,而培训专业的分派人员又需要长期训练和熟悉业务,才能准确分配,这些问题无疑严重影响了政府互联网便民服务的效率和效果。本文研究的基于知识地图的政府诉求文件自动推送模型,重点解决“政府知识地图的构建”和“诉求文件自动化分类”两个问题,有利于降低人工处理投资文件的成本,缩短政府回应民意的时间,同时提升政府部门积极服务的形象。
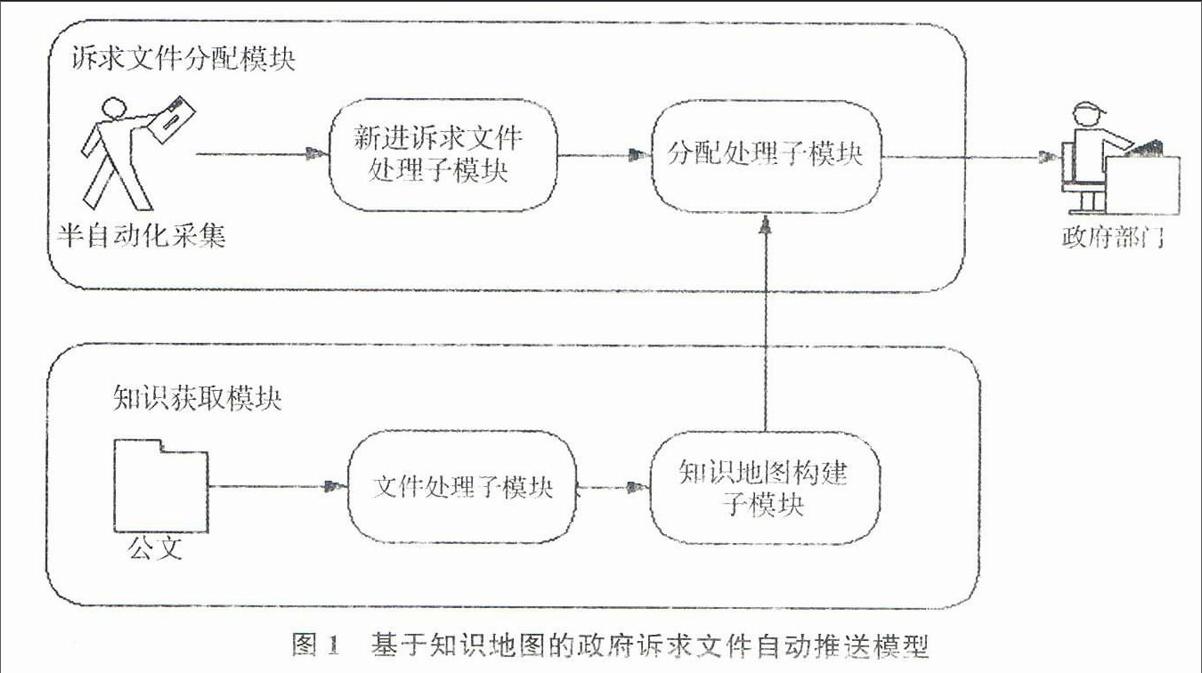
2015年8月第35卷第8期现?代?情?报Journal of Modern InformationAug,2015Vol35No82015年8月第35卷第8期基于知识地图的政府诉求文件自动推送模型研究Aug,2015Vol35No81模型架构
首先以训练文档建立政府知识地图,接着通过对比的方式,为网络舆情事件中的不同政务需求找出所应负责处理的政府部门。模型架构如图1所示,主要分为知识获取和诉求文件分配两个模块,获取知识模块主要是训练样本文档阶段,先利用文件处理子模块找出文件的特征词,再使用知识地图构建模块,利用关联规则技术,找出特征词与政府部门之间的关联,进而建立政府知识地图;而诉求文件分配模块则是针对实际应用阶段,先通过诉求文件处理子模块找出新进诉求文件的特征词,再透过分配处理子模块将文档与知识地图作对比,进而决定诉求文件应由哪些政府部门负责处理。图1基于知识地图的政府诉求文件自动推送模型
2知识获取模块
知识获取模块主要功能是建立政府部门知识地图,作为进行诉求文件分配时文档对比的依据,通过诉求文件与事先建立好的知识地图对比,可预测出该诉求文件所分配的具体政府部门,优化政府决策。该模块的资料来源于政府网站的各种文件和FAQ问答集,主要功能模块包括了文件处理子模块和知识地图构建子模块,各子模块的处理流程描述如下。
21文件处理子模块
该模块是从文件中挖掘出有用的特征词,作为建立特征词表的基础词源;主要包括3个步骤:分别为文件预处理、文件特征词处理及文件特征词表构建,处理流程如图2所示。
211文件预处理
这部分主要包括文件分词处理与特征词提取两个重要
的步骤。文件预处理子模块需要各政府部门提供该部门有代表性的政府职能描述文件,然后,利用分词处理模块对收集来的文件进行分词处理,再通过词性合并的规则挖掘出有意义的特征词。
(1)分词处理
中文与拉丁语系的分词过程大相径庭,一般的英文文件只要以空白间隔将文件分解成一个个词(Word)即可做后续的处理,本文研究的是中文文件为主,没有空白格进行断词。因此,中文分词较英文分词更难处理,现阶段比较流行的中文分词方法大致分为3种类型[3]:基于规则的分词方法、基于理解的分词方法、基于统计的分词方法。本文运用目前最常用的开放中文分词工具CKIP中文断词系统[4],该系统综合运用了上述分词方法,将内容切分成一组组的词汇,并按照不同词性对每组词汇进行标记,例如词类标记Na/Nb/Nc分别是普通名词、专有名词及地方词,且均可统一归类为名词(N)。接着过滤掉各文件中标点符号等不具有语义的符号和不必要的停顿词(Stop Words)。在中文的特征词汇中,名词(Nouns)与动词(Verbs)所代表的意义最为重要,基本能代表文件中的重要概念,因此,本研究近保留名词与动词的单字词,其他词性的字词均可忽略。endprint
(2)特征词提取
“特征词提取”的任务是整理合并经过分词处理后的词汇,使之形成能够代表文件的特征词表。根据CKIP系统所产生的结果,本研究虽然仅保留了名词与动词的词组,但是根据其他学者的研究表明[5],如果不做词性组合,仍然有很多无意义的字词存在。基于本文的运用背景和对象,发现诸多政务类词汇,若不经过词性组合,将大大影响模型效果;例如:当“环保人员”和“市政人员”两个词经过分词处理后,分布得到“环保”、“人员”及“市政”、“人员”,所得到的“人员”对于政府知识地图的构建是没有意义的,因此,必须建立词性合并的规则,具体范例如下:
词性组合范例N+N“禽流感”(N)+“疫苗”(N)=“禽流感疫苗”(N)此外,为能使特征词对于决定未来诉求文件推送至何部门时具有参考性,需先请专家以人工方式判断文件所属的政府部门,并将部门名称加入文件的特征词表中。另外,特征此表中的一些专有名词(如疾病名称、药品名词)因出现的频率低,在建立知识地图模块阶段,可能无法找出有效的关联规则,为了解决此问题,将收集和分析各政府部门官方网站收集来文件及FAQ问答集,依各部门属性建立特定名词的特征词表,以“特定名词”取代出现频率较少的专有名词,例如以流行病代替“H1N1,H7N9”。
212文件特征词处理
并非所有的词汇都是重要的词汇,所以要通过权重筛选的方式,以保留重要的特征词。特征词权重计算主要包括了两个步骤:首先是利用TF-IDF加权模式计算各特征词权重,最后根据特征词出现的位置与事先设定的“特定特征词”作权重加乘。
一般而言,文件词汇的权重计算方法有TF加权和TF-IDF加权等[6]。TF表示词频,即字词在某一个文件中出现的频率,一般而言,TF越高表示该词对这篇文件来说越重要。TF-IDF是一种统计方法,用以评估某个词对于资料库中的其中一份文件的重要程度。计算公式如下:
TF-IDF权重=wij×idf=wij×logNni(1)
wij=1+log10ifij?当tfij>0时
0当ifij=0时(2)
公式(2)中tfij为字词ti在文件j出现的词频,公式(1)中wij为字词ti在文件j出现的对数词频[7],ni为资料库中含有字词ti出现的文件篇数,N为资料库总的文件数。该公式的内涵在于字词的重要性随着它在各文件中出现的次数成正比增加,但同时会随着它在资料库中出现的频率成反比下降。考虑到本文采集的信息来源于各个政府部门官方网站的文件和FAQ问答集,文件长短不一,单用词频来计算权重会受到每篇文件字词多寡的影响,选用TF-IDF来计算权重不仅考虑到了词频还考虑到出现词汇的文件数量。
另一方面,还需要考虑到文件结构对词汇重要性的影响,并修正权重:文件中的特征词出现的位置不同,也将给予不同的权重。一般政府文件或FAQ分为“标题”和“内容”两个部分,“标题”通常代表文件的主旨,位于“标题”的特征词代表文件的可能性更高,因此需要增加位于“标题”的特征词权重;若文件“内容”已经出现了相关政府部门的名称,则文件被推送至这个相关部门的几率越高,因此有必要增加此类政府部门名称特征词的权重。
TF-IDF修正权重=tfij×idfi×(1+s1×02+s2×01+s3×02)(3)
公式(3)中s1,s2和s3为布尔型数值,当词汇出现在文件“标题”时s1为1,否则为0,当词汇出现在文件“内容”时s2为1,否则为0,当词汇为部门名称特征词时s3为1,否则为0。
213建立文件特征词表
特征词的权重可以代表着该特征词在整篇文件中所占的重要性,权重越高越可代表文件概念,从每篇文件中挑选出权重值最高的前10个特征词用于代表该文件。将所有资料库中的文件都整理成以特征词的形式,并建立文件特征词表,以此当作建立知识地图的基础资料,透过编码转换以方便下阶段的关联规则的挖掘。
22知识地图建立模块
文件处理子模块将所有文件都转换成以特征词表示,形成特征词表。利用数据挖掘技术对文件资料库的特征词表进行关联规则的挖掘,透过设定关联规则的最小支持度及置信度门槛值,以挑选出真正有效的关联规则[8];从有效的关联规则中,找出各政府部门与特征词之间的关联。为避免重要的特征词未被选入单位的特征词集合,故设置较低的支持度,例如设定最小支持度为支持个数2,最小置信度07,所产生的关联规则摘要如表1所示。
4讨论
本文提出一个智能型政府知识地图的构建机制,来协助上级政府部门以自动化的形式将公众的诉求意见迅速地分送至对口的政府部门,有利于相关部门
快速回应民意,以提升政府部门的行政绩效,同时节省了处理诉求文件的人力、物力等资源。未来的研究工作包括:首先,本文的研究前提是公众诉求文件内只能描述一个政府部门所负责的政务范围,然而由于公众对政府部门分工的不熟悉,使得文件内往往包含了多类别的意见,如何处理复杂关联的文件将是未来一个重要的研究课题;另外,由于时空环境的变迁,可能会出现不同的流行语或关注点,因此文件的特征词会不断变更,如何设计一个有效率的特征词自动更新模型和机制也是将来一个思考方向。
参考文献
东南网.“12345”:老百姓呼叫政府[EB/OL].http:∥www.fz12345.gov.cn/article.jsp?articleId=1708,2013-05-04.
郑丽珍,赖美慧.结合知识地图之工部门陈述文件自动化分案系统[J].资讯管理学报,2011,18(4):7-11.
[3]Christopher D,Hinrich Schutze.统计自然语言处理基础[M].苑春发,等译.北京:电子工业出版社,2004:1-50.
[4]中文词知识库小组.“CKIP”中文词知识库小组[EB/OL].http:∥rocling.iis.sinica.edu.tw/CKIP/,2013-04-20.
[5]邱登裕,潘雅真.结合资讯检索与分群演算法构建知识地图[J].资讯管理学报,2006,13(8):137-160.
[6]Salton G,Buckley.Term-weighting approaches in automatic text retrieval[J].Information Processing and Management,1988,24(5):513-523.
[7]贝泽耶茨.现代信息检索[M].黄萱菁,张奇,邱锡鹏,译.北京:机械工业出版社,2012:90-155.
[8]Agrawal R,Inielinski T,Swami A.Mining association rules between sets of items in large databases[A].In Proc.1993 ACM-SIGMOD Int.Conf.Management of Data(SIGMOD93)[C].Washington,DC,1993:207-216.
[9]黄国祯,朱蕙君,曾秋蓉,等.具有自我调试功能之线上课程问题自动回复系统[J].电子商务学报,2007,9(3):599-624.
(本文责任编辑:马卓)endprint
