碳排放权市场结构相依特征研究:规则藤方法
2015-07-13胡根华等
胡根华等
摘要
碳排放交易市场的建立,是一个基于经济学理论来解决气候变暖问题的具有价值的途径,其目的是发展低碳经济。在欧盟排放交易体系一级市场上,以欧盟排放配额(European Union Allowances, EUA)作为主要交易标的物的碳排放权交易市场已经成为一个重要的新兴贸易市场。随着碳排放权交易市场的不断发展,该市场的资本化程度逐渐深化,其金融属性也日益显著,并逐步融入到国际资本市场体系之中。与其它资本市场相类似,碳排放权交易市场之间也存在着复杂的非线性相关关系,而Copula函数可以用来捕捉这种相依结构特征。因此,文章选取欧盟排放配额(EUA)期货的日价格时间序列数据,首先假设新息序列服从学生t分布,运用ARMAGARCH模型对经调整的对数收益率序列进行过滤,采用极大似然方法估计模型的参数,并得到残差序列,同时将其标准化而得到标准化残差;然后,将Kendalls tau秩相关系数作为权重,采用最大生成树算法(maximum spanning tree algorithm)的序贯Copula选择方法构建合适的规则藤Copula模型,并运用基于序贯的极大似然方法估计规则藤Copula模型,以描述碳排放权交易市场之间复杂的相依结构特征。研究结果发现:在无条件下,tcopula函数可以较好地捕捉碳排放权市场之间的相依关系,说明市场存在明显的对称尾部;在Dec10EUA、Dec12EUA、Dec13EUA市场相依结构固定下,Dec11EUA与Dec14EUA市场之间的相依结构可以采用Gaussian copula函数来描述,而在Dec10EUA、Dec13EUA市场相依结构确定不变情形下,Dec12EUA与Dec14EUA市场之间的相依结构则适合采用Frank copula函数来捕捉,说明这些市场之间并没有出现尾部特征。进一步地,文章分别选择White信息矩阵等式拟合优度检验和基于概率积分转换(probability integral transform,PIT)与经验Copula过程(empirical copula process,ECP)混合方法的拟合优度检验,并基于Bootstrap方法,以Cramer von Mises(CvM)检验统计量作为度量测度,来对模型进行拟合优度的检验。研究发现,构建的规则藤Copula模型能够较好地捕捉碳排放权市场之间的相依结构。这一研究结果,为准确探讨碳排放权交易市场之间、碳排放权交易市场与其它资本市场之间套期保值策略提供了一定的参考意义,也有利于提高碳排放权市场产品定价的准确度。
关键词碳排放权;相依结构;规则藤;Copula模型
中图分类号X24
文献标识码A
文章编号1002-2104(2015)05-0044-09
在《联合国气候变化框架公约》和《京都议定书》的发展路线下,碳排放权交易市场得到蓬勃发展。目前,碳排放权交易市场已经发展成为主要新兴贸易市场之一。据预测,在未来十年内,国际碳排放权交易市场有可能超过石油市场,成为全球最大的能源交易市场。随着碳排放权市场的发展,其金融属性也日益显现,于是出现了很多碳金融产品及其衍生品。然而,这一新兴市场仍然发展不完善,且经常出现较大的波动,这增加了市场不确定性风险,使得该市场的风险管理研究就显得十分重要,尤其是在发展低碳经济的背景下。因此,针对碳排放权交易市场的相关研究,就具有很重要的实际意义。
1文献综述
作为国际资本市场之一,碳排放权交易市场之间、该市场与其它资本市场之间都存在比较复杂的非线性相关关系,即相依性。为了研究碳排放权交易市场的市场风险,需要准确度量市场之间的相依性,从而进行市场的风险管理。Sklar[1]提出的Copula定理,能够有效地捕捉到这种非线性相依结构。后来,Embrechts[2]和Embrechts等[3]将该理论引入到金融风险管理研究中。目前,构建基于Copula理论的相依性模型,已经成为金融市场波动溢出和风险传染研究的一种重要方法。实证研究表明,金融时间序列之间的相依结构也呈现出时变性和动态性。因此,许多学者构建了动态Copula模型,如Patton [4-5]、Dias and Embrechts [6]、Christoffersen等 [7]、Fei等[8]等。
一般情形下,传统的多维Copula模型能够较好地刻画资本市场之间的相依结构。然而,在高维情况下,这些多维Copula函数并不能准确地捕捉到多资产之间复杂的相依结构。于是,Bedford and Cooke [9-10]提出了基于藤分解结构的Copula方法,以研究高维金融资产之间的相依性,这对于准确研究多种金融资产之间的风险管理问题相当重要,尤其在2007-2009年金融危机期间。更多相关研究,参见Aas等[11]、Horta等[12]、Nikoloulopoulos等[13]、Dimann 等[14]、Allen等[15]、Low 等[16]、Low等[17]、Wei and Supper[18] 、Stber and Czado[19]等。Czado and Aas[20]研究表明,构建的藤Copula结构比其它Copula结构更为灵活,从而更加容易地捕捉高维随机变量之间复杂的相依结构。此外,Beare and Seo[21]构建了一种新的规则藤结构,即针对平稳的多维高阶Markov链建立半参数模型,这种结构被称为M藤。
根据现有的规则藤文献,大多数研究都是基于两种最简单的藤结构,即C藤和D藤,且新息大多假设服从正态分布或者学生t分布,如Kurowicka and Cooke[22]。然而,Aas等[11]将分布函数扩展到其它类型,并采用不同的二元Copula函数来研究相依性,如Gunbel copula和Clayton copula等。在实际应用研究中,D藤结构的Copula模型得到更加广泛的运用,如Nikoloulopoulos等[13] 、Min and Czado[23]。endprint
目前,采用基于更多Copula族模型的规则藤分析框架的应用研究相对较少,而将规则藤应用于国际碳排放权交易市场的文献更加少见。为此,文章通过构建规则藤Copula模型,来研究国际碳排放权市场的相依性结构问题。首先,文章在新息服从学生t分布的假设下,运用ARMAGARCH模型进行过滤,并采用极大似然估计方法来估计模型的参数。其次,文章将Kendalls tau秩相关系数作为权重,使用最大生成树算法(maximum spanning tree algorithm)的序贯Copula选择方法构建合适的规则藤Copula模型,采用极大似然估计方法估计规则藤Copula模型。最后,基于Bootstrap方法,分别选择基于White[24]的信息矩阵等式拟合优度检验和基于概率积分转换(probability integral transform,PIT)与经验Copula过程(empirical copula process,ECP)混合方法的拟合优度检验(称为ECP2检验),以Cramer von Mises(CvM)检验统计量作为度量测度,来对模型进行拟合优度的检验。
文章构建规则藤Copula模型,并应用于碳排放权交易市场相依结构的实证研究,主要工作在于以下两个方面:在理论研究方面,放宽新息服从某一种分布的约束,构建了更具有适用性的规则藤Copula模型,以更好地捕捉高维资产之间复杂的相依结构,也为更好地构建Levy vine Copula分析框架奠定理论基础,从而为投资组合选择和套期保值策略提供一种量化指标的参考;在应用研究方面,首次构建规则藤Copula模型对碳排放权交易市场的相依结构进行实证研究,这拓宽了模型的应用研究领域。
2模型与参数估计
2.1规则藤结构
规则藤结构,是Bedford and Cooke [9-10]提出的一种用来构建多维变量分布之间相依性结构的图形结构。规则藤结构由一系列的“树”状结构组成,而“树”的“边”则被设定为能够描述二元条件分布的Copula函数,且这些Copula函数根据规则藤结构来确定。记d维规则藤为V,其结构由d-1棵“树”组成,依次记为T1,T2,…,Td-1,而结点和边分别记为Ni和Ei(1≤i≤d-1)。根据Bedford and Cooke [9],该规则藤结构必须满足:
(1)树T1的结点和边分别为Ni={1,2,…,d}和Ei;
(2)对于i≥2,树Ti的结点和边分别为Ni=Ei-1和Ei;
(3)如果树Ti+1的两个结点由一个边连接,那么在树Ti上对应的两个边共享一个结点(即近邻条件)。
记随机向量X=(X1,X2,…,Xd),其边缘密度函数为f1,f2,…,fd,XD(e)表示向量X中由集合D(e)确定的子向量,X-j表示向量X剔除第j个变量后的子向量。于是,在规则藤结构的边Ej(1≤i≤d-1)上,给定XD(e)的前提下,Xj(e)与Xk(e)的条件边缘分布函数所对应的二元Copula的密度函数就可以记为cj(e),k(e),D(e),其中j(e)和k(e)均称为被调节集(conditioned set),D(e)称为调节集(conditioning set)。那么,密度函数可表述为
f1,2,…,d(x1,x2,…,xd)=∏di=1fi(xi)·
∏d-1i=1∏e∈Eicj(e),k(e)|D(e)
F(xj(e)|XD(e)),F(xk(e)|XD(e))(1)
其中,边缘密度服从[0,1]均匀分布。
如果记规则藤为V,其对应的二元参数Copula族和参数分别为B和Θ,那么规则藤Copula密度函数就可以记为c(.|V,B,Θ)。由于d维规则藤结构非常灵活,且并没有一个确定的结构种类,文章采用MoralesNapoles [25]、Dimann [26]和Dimann等 [14]的方法,将规则藤结构用为d×d维下三角矩阵M=(mij|i≥j)来表述,其中每一列表示一棵“树”。同理,对应的二元参数Copula族B和参数Θ的表述,可参见Dimann [26]。
2.2规则藤Copula参数估计
规则藤Copula模型的参数估计,通常也是采用极大似然估计方法。研究表明,正则条件下的极大似然估计是一致估计,也是渐进正态的,而渐进协方差矩阵的估计量可以通过标准的方法获得[27]。对于规则藤V,且其对应的二元参数Copula族和参数分别为B和Θ,其密度函数就可以表述为c(.|V,B,Θ),那么似然函数与对数似然函数分别为
4.3规则藤Copula模型构建
由于规则藤分布选择的多样性,规则藤Copula模型具有非常灵活的结构。在构建规则藤Copula模型时,首先要选取合适的规则藤结构,即选择合适的无条件和条件变量对,也即确定构成“树”结构的边的两个市场。此处,文章采用一种基于Kendalls tau相依系数的序贯选择方法,来确定规则藤Copula结构。所谓规则藤Copula模型序贯选择方法,就是首先根据变量之间相依性的强弱程度
来依次确定各“树”。由于选择各“树”是相互独立的,这并不能保证全局最优。当采用极大似然估计时,从模型的拟合优度上看,AIC值不能保证最小。然而,选择这种方法也存在一定的优越性,如在度量两个变量之间的联合尾部相依时,能够最小化舍入误差(rounding error)对第二棵“树”以及以后各“树”的影响。
如图2所示,描述了相依关系散点图(上三角图)以及对应的Kendalls tau系数(下三角图)。由于Kendalls tau系数与Copula函数值具有一一对应的关系,结合序贯选择方法,Dec10EUA与Dec11EUA之间的相依关系最大,肯定作为第一棵“树”的一个“边”。其次,Dec10EUA与Dec12EUA、Dec13EUA与Dec14EUA、Dec11EUA与Dec12EUA之间的相依系数也很大,都应该成为第一棵“树”的一个“边”。然而,藤结构的每一棵“树”不能存在封闭的环状结构。在选择生成树(spanning tree)时,采用最大生成树算法(maximum spanning tree algorithm)的序列Copula选择方法来构建合适的规则藤Copula模型,即最大化Kendalls tau系数的绝对值,也即max∑e={j,k}τ^j,k(1≤j
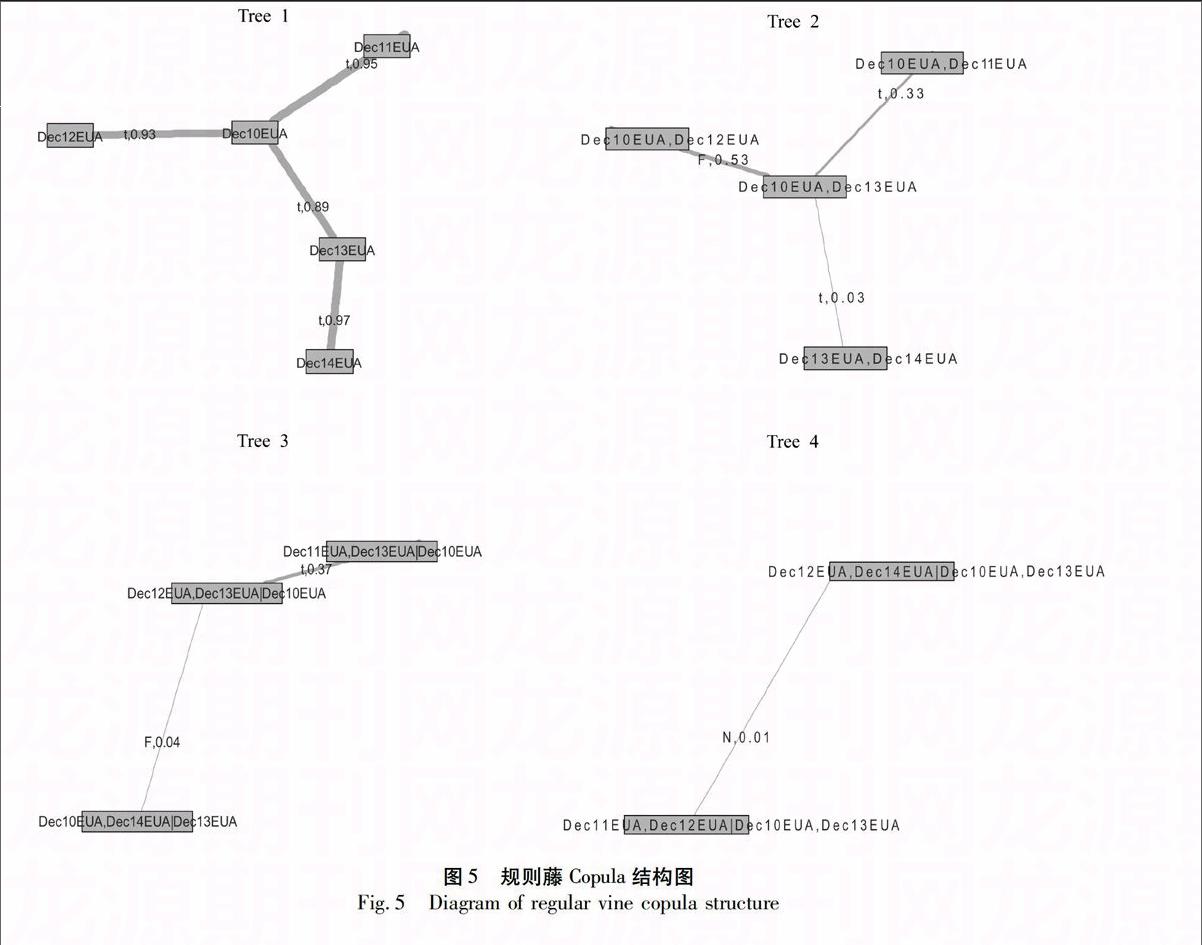
如图3所示,显示了规则藤的结构矩阵,选择方法为基于序贯选择的极大似然估计方法。其中,数字1、2、3、4、5分别表示Dec10EUA、Dec11EUA、Dec12EUA、Dec13EUA和Dec14EUA。根据图3,矩阵第五行显示的是无条件二元Copula函数,也即用来捕捉第一棵“树”中两个变量之间的相依结构;而第二到第四行显示的是有条件二元Copula函数,用来描述其它各“树”中变量之间的相依性。
族函数矩阵,选择标准是基于AIC值,显著性水平为0.05。其中,N、t、F分别表示Gaussian copula、tcopula和Frank copula。根据图4可以看出,在Dec10EUA、Dec12EUA、Dec13EUA市场相依结构固定下,Dec11EUA与Dec14EUA市场之间的相依结构可以采用Gaussian copula函数来描述;而在Dec10EUA、Dec13EUA市场相依结构确定不变情形下,Dec12EUA与Dec14EUA市场之间的相依结构则适合采用Frank copula函数来捕捉(其它市场的相依结构的理解,依此类推,不再赘述)。
4.4规则藤Copula模型参数估计
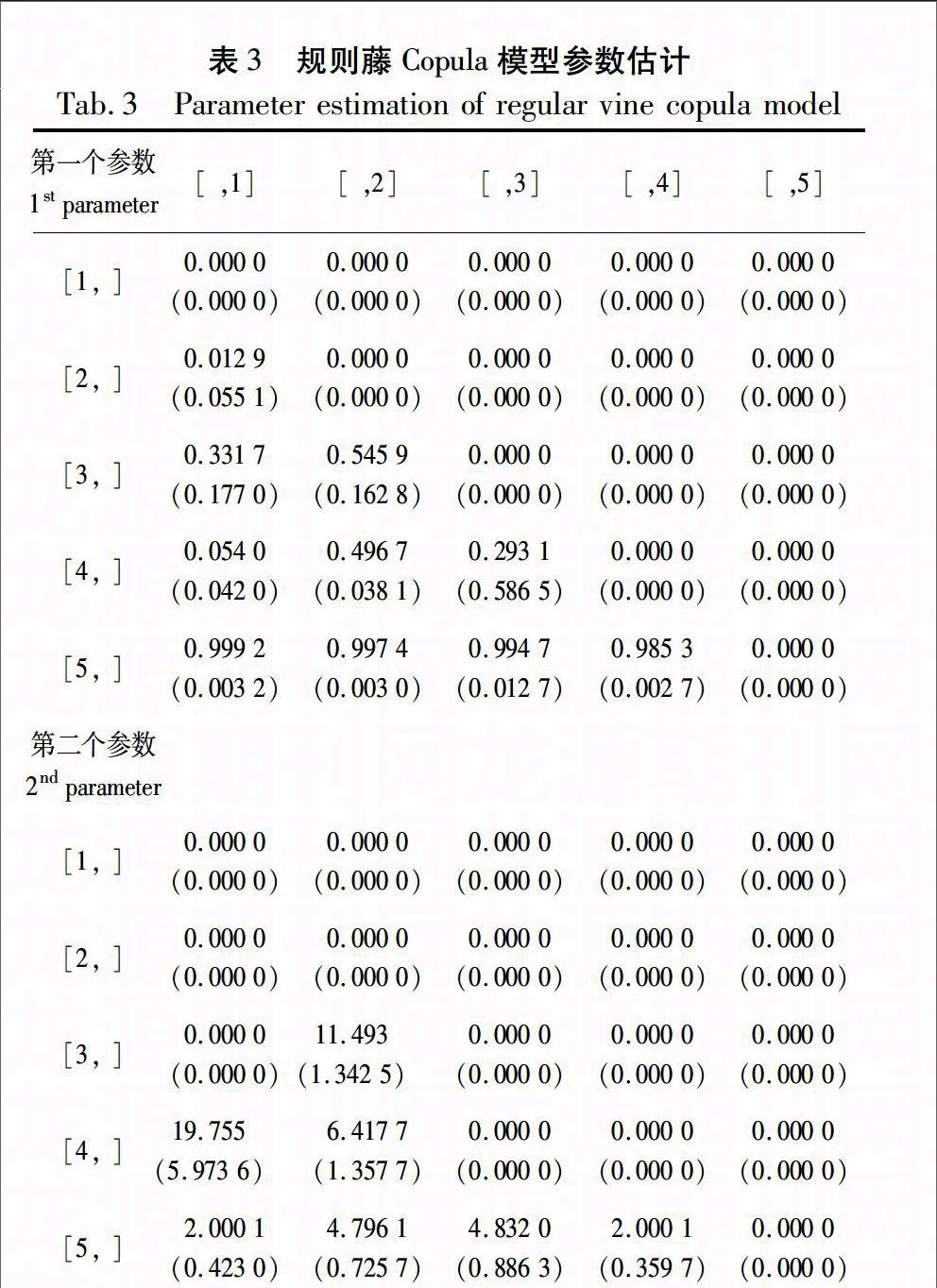
文章以Kendalls tau秩相关系数作为构建各“树”的边的权重,运用基于最大生成树算法(maximum spanning tree algorithm)的序贯选择方法来构建合适的规则藤Copula模型。进一步地,采用极大似然估计方法估计规则藤Copula模型的参数,估计结果如表3所示。根据表3中第一个参数估计的结果,第五行的参数值均最大,一方面显示出变量之间的相依关系大,另一方面检验了采用最大化Kendalls tau系数的绝对值来选择规则藤Copula的有效性。
如图5所示,显示了基于规则藤Copula的国际碳排放权市场相依结构图。其中,第一棵“树”的“边”上,字母表示通过基于序贯选择的极大似然估计方法确定的无条件二元Copula函数,数字表示基于序贯选择的极大似然估计方法估计得到的经验Kendalls tau值,而其它各“树”的“边”上的字母则表示条件二元Copula函数。
4.5模型的拟合优度检验
文章首先采用序贯Copula选择方法构建了合适的规
则藤Copula模型,并采用极大似然估计方法估计了规则
藤Copula模型。此处,文章将基于Bootstrap方法,分别运
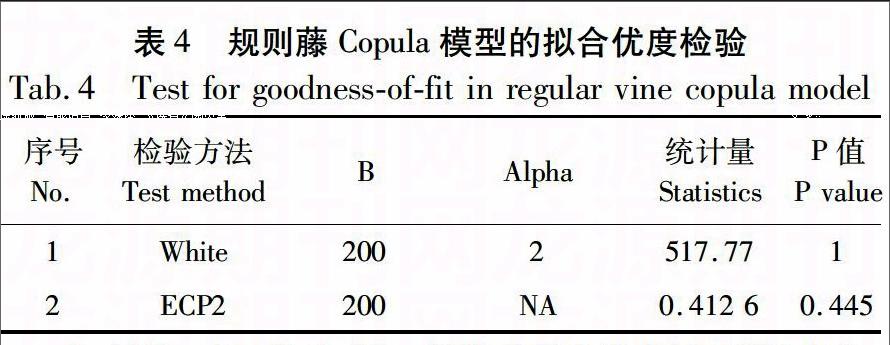
用基于White[24]的信息矩阵等式拟合优度检验和基于概率积分转换(probability integral transform,PIT)与经验Copula过程(empirical copula process,ECP)混合方法的拟合优度检验,且后者以Cramer von Mises(CvM)检验统计量为度量测度,对模型进行拟合优度的检验。如表4,显示了规则藤Copula模型的拟合优度的检验结果。根据P值,原假设不能被拒绝,也即规则藤Copula模型在0.05显著性水平下都不能被拒绝。因此,文章构建的规则藤Copula模型能够较好地捕捉到国际碳排放权市场之间的相依性结构。
5结论与未来研究方向
美国次贷危机的发生,在很大程度上给国际资本市场
造成了冲击。作为国际资本市场之一,国际碳排放权交易市场也可能受到一些冲击,从而使市场价格发生突然的大
B表示bootstrap步长(default B=200)。如果B太大,将会给计算带来负担。Alpha表示基于概率积分转换(probability integral transform,PIT)与单变量数据集合的第二拟合优度检验所设定集合{2,4,6,…}的整数(default Alpha=2),具体可参见Berg and Bakken[32]。原假设H0:多元变量分布之间的相依结构能够被所设定的Copula函数族来描述。显著性水平为0.05。
波动,即跳跃现象。为了研究国际碳排放权交易市场复杂的相依结构特征,且考虑到排除极端事件对市场冲击的不利影响,文章选择了美国次贷危机发生后国际碳排放权交易市场的日价格数据,在新息服从学生t分布的前提假设下,首先运用ARMAGARCH模型对经调整的日收益率数据进行过滤,并采用极大似然方法来估计模型的参数,获得新息序列;然后,选取Kendalls tau秩相关系数作为藤结构中每棵“树”的权重,运用最大生成树算法(maximum spanning tree algorithm)的序贯Copula选择方法来构建合适的规则藤Copula模型,以捕捉不同市场之间的相依结构,并使用基于序贯的极大似然方法估计规则藤Copula模型;最后,选择两种方法对模型进行拟合优度的检验,包括White信息矩阵等式拟合优度检验和基于概率积分转换(probability integral transform,PIT)与经验Copula过程(empirical copula process,ECP)混合方法的拟合优度检验。后一种检验,是基于Bootstrap方法,并以Cramer von Mises (CvM)检验统计量作为度量测度。研究表明,构建的规则藤Copula模型能够较好地捕捉国际碳排放权市场的相依结构。这一研究结论,有利于提高碳排放权市场的风险管理和产品定价的准确度。
然而,在规则藤Copula模型的构建及实证研究中,文章尽管放宽了新息服从某一种分布的约束,但没有引入跳跃特征。实际上,由于不确定因素的影响,市场价格经常出现不同程度的跳跃。因此,在小跳跃发生的情况下,文章构建的规则藤Copula模型能够较好地分析国际碳排放权市场的相依结构,但在较大跳跃发生时,就显得不足。在未来研究中,将引入跳跃过程,构建更具有适用性的规则藤Copula分析框架,来研究国际碳排放权交易市场的有关问题,例如套期保值策略、资产定价等方面。endprint
(编辑:刘呈庆)
参考文献(References)
[1]Sklar A. Fonctions de Repartition an Dimensionset Leurs Marges [J]. Publications de l Institute de Statistiquede l Universite de Paris, 1959, 8:229-231.
[2]Embrechts P. Copulas: A Personal View [J]. Journal of Risk and Insurance, 1999, 76(3):639-650.
[3]Embrechts P, McNeil A, Straumann D. Correlation: Pitfalls and Alternatives [J]. Risk, 1999, 12(5):11-21.
[4]Patton A J. Modelling Asymmetric Exchange Rate Dependence [J]. International Economic Review, 2006, 47(2):527-556.
[5]Patton A J. Estimation of Multivariate Models for Time Series of Possibly Different Lengths [J]. Journal of Applied Econometrics, 2006, 21(2):147-173.
[6]Dias A, Embrechts P. Modeling Exchange Rate Dependence Dynamics at Different Time Horizons [J]. Journal of International Money and Finance, 2010, 29:1687-1705.
[7]Christoffersen P, Errunza V, Jacobs K, et al. Is the Potential for International Diversification Disappearing? A Dynamic Copula Approach [J]. Review of Financial Studies, 2012, 25: 3711-3751.
[8]Fei F, Fuertes A, Kalotychou E. Modeling Dependence in CDS and Equity Markets: Dynamic Copula with Markovswitching [R]. Working Paper, 2013.
[9]Bedford T, Cooke R M. Probability Density Decomposition for Conditionally Dependent Random Variables Modeled by Vines [J]. Annals of Mathematics and Artificial Intelligence, 2001, 32(1-4):245-268.
[10]Bedford T, Cooke R M. Vines: A New Graphical Model for Dependent Random Variables [J]. Annals of Statistics, 2002, 30(4):1031-1068.
[11]Aas K, Czado C, Frigessi A, et al. Paircopula Constructions of Multiple Dependence [J]. Insurance, Mathematics, and Economics, 2009, 44: 182-198.
[12]Horta P, Mendes C, Vieira I. Contagion Effects of the Subprime Crisis in the European NyseEuronext Markets [J]. Portuguese Economic Journal, 2010, 9(2):115-140.
[13]Nikoloulopoulos A K, Joe H, Li H J. Vine Copulas with Asymmetric Tail Dependence and Applications to Financial Return Data [J]. Computational Statistics & Data Analysis, 2012, 56(11):3659-3673.
[14]Dimann J, Brechmann EC, Czado C, et al. Selecting and Estimating Regular Vine Copulae and Application to Financial Returns [J]. Computational Statistics & Data Analysis, 2013, 59(1):52-69.
[15]Allen D E, Ashraf M A, McAleer M, et al. Financial Dependence Analysis: Applications of Vine Copulae [R]. Working Paper, 2013.
[16]Low R K Y, Alcock J, Faff R, et al. Canonical Vine Copulas in the Context of Modern Portfolio Management: Are They Worth It?[J]. Journal of Banking & Finance, 2013, 37(8):3085-3099.endprint
[17]Low R K Y, Faff R, Aas K. Meanvariance Optimization Still Works! A Bayesian Methodology with Vine Copulas [R]. Working Paper, 2013.
[18]Wei G N F, Supper H. Forecasting Liquidityadjusted Intraday Valueatrisk with Vine Copulas [J]. Journal of Banking & Finance, 2013, 37(9):3334-3350.
[19]Stber J, Czado C. Regime Switches in the Dependence Structure of Multidimensional Financial Data [J]. Computational Statistics & Data Analysis, 2014, 76:672-686.
[20]Czado C, Aas K. Paircopula Constructions: Even More Flexible than Copulas [R]. Working Paper, 2013.
[21]Beare B K, Seo J. Vine Copula Specifications for Stationary Multivariate Markov Chains [R]. Working Paper, 2014.
[22]Kurowicka D, Cooke R. Uncertainty Analysis with High Dimensional Dependence Modelling [M] . Chichester: Wiley, 2006.
[23]Min A, Czado C. SCOMDY Models based on Paircopula Constructions with Application to Exchange Rates [J]. Computational Statistics & Data Analysis, 2014, 76:523-535.
[24]White H. Maximum Likelihood Estimation of Misspecified Models [J]. Econometrica, 1982, 50:1-26.
[25]MoralesNapoles O. Bayesian Belief Nets and Vines in Aviation Safety and Other Applications [D]. Technische Universiteit Delft, 2008.
[26]Dimann J. Statistical Inference for Regular Vines and Application [D]. Center of Mathematical Sciences, Munich University of Technology, Garching bei Munchen, 2010.
[27]White H. Estimation, Inference and Specification Analysis [R]. Econometric Society Monographs No. 22, Cambridge University Press, Cambridge, U.K., 1994.
[28]Schepsmeier U. A Goodnessoffit Test for Regular Vine Copula Models [OL]. Http://arxiv.org/abs/1306.0818, 2013.
[29]Genest C, Remillard B. Validity of the Parametric Bootstrap for Goodnessoffit Testing in Semiparametric Models [J]. Annales de lInstitut Henri PoincareProbabilites et Statistiques, 2008, 44:1096-1127.
[30]Akaike H. Information Theory and an Extension of the Likelihood Ratio Principle [C].In: Petrov B N, Eds. Proceedings of the Second International Symposium of Information Theory[A]. Budapest: Akademiai Kiado, 1973: 257-281.
[31]Genest C, Remillard B, Beaudoin D. Goodnessoffit Tests for Copulas: A Review and Power Study [J]. Insurance: Mathematics and Economics, 2009, 44:199-213.
[32]Berg D, Bakken H. A Copula Goodnessoffit Approach Based on the Conditional Probability Integral Transformation [R/OL]. http://www.danielberg.no/publications/Btest.pdf, 2007.endprint
