基于向量空间模型的项目申报书查重系统设计
2015-06-27胡伟伟王婷婷
胡伟伟,孙 逊,王婷婷
(江苏省生产力促进中心 江苏南京210042)
应用技术
基于向量空间模型的项目申报书查重系统设计
胡伟伟,孙 逊,王婷婷
(江苏省生产力促进中心 江苏南京210042)
随着国家及地方科研财政经费的增加,企事业单位对科技项目日益重视,项目申报数量也逐年递增。为避免对类似项目的重复支持,造成科研经费的浪费,项目查重就显得尤为必要。提出了基于向量空间模型的项目申报书查重系统设计方法,并介绍设计流程。
项目查重 向量空间模型 分词
0 引 言
科技是第一生产力。近年来,随着国家对科技创新工作重视程度的提升,各级政府科研经费投入逐年增加,各企事业单位更加积极地申报各类科研项目。但随着科研项目申报数量的增加,科研成果重复申报、多头申报现象日益突出。由于项目分属不同的机构或部门管理,面对数量巨大的申报材料,传统的人工形式审查工作量大,且效果也不理想。为避免对重复或相似科研内容的重复支持,本文将介绍一种基于向量空间模型的文本相似度算法,通过该算法来实现项目研究内容相似度的判断。
1 理论介绍
向量空间模型VSM(Vector Space Model)是20世纪70年代由Salton等人提出的一种简便、高效的文本表示模型。该模型的基本思想是把文档简化为以特征词(关键词)的权重为分量的多维向量表示。通过该方法将对文本内容的处理简化为向量空间中向量的运算。文本向量化后,再利用余弦距离来计算两向量之间的关系,余弦值越大,说明文本相似程度越大。当余弦值为1时,说明文本一致,反之则说明文本匹配度较低。通过向量计算法判别文本的相似性可以使问题的复杂性大为降低。
2 设计流程
项目申报书向量模型化需要经过分词、词权重计算、关键字提取等步骤,大致流程如图1所示。
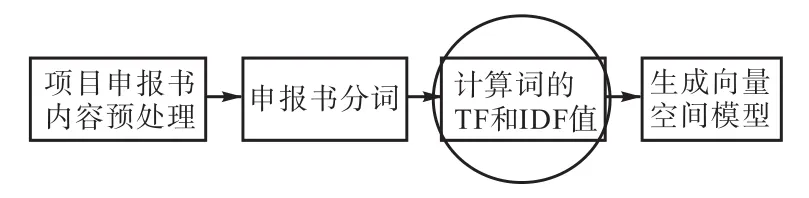
图1 项目申请书向量模型设计流程Fig.1 Design flow of the VSM project application forms
2.1 申报书预处理
为便于将项目申报书内容进行分词,可以通过正则表达式去除申报书中的文本格式化标识符(HMTL标签)、公式、图片等信息,将其纯文本化。
2.2 分词
分词是将文本向量化表示的一个重要步骤,分词的效率和准确度将对文本向量模型的建立和系统速度产生直接影响。
常用的分词算法有基于字典的分词方法、基于知识理解的分词方法、基于词频统计的分词方法等,各种方法各有优缺点。基于字典的分词方法实现相对简单,应用广泛。分词时可以采用中科院计算所研发的ICTCLAS分词系统,兼顾效率和准确率。
2.3 特征词提取和向量模型生成
利用分词算法将经过预处理的文本进行分词,并去除分词后对文本内容识别意义不大但出现频率很高的停用词,如“的”、“是”、“在”等。经过分词处理后,申报书就可以用由若干词组成的集合来表示:
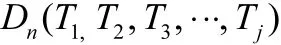
D表示被处理的文档,Tj表示在D中出现的经分词过滤后的词。
如果把所有词都作为特征集,那么特征向量的维数将十分巨大,从而导致计算量太大,耗时较长,这时需要进行特征词提取。特征词提取的主要功能是在不影响文本核心信息的情况下尽量减少关键词的集合大小,以此来降低向量空间的维度,从而降低计算量,提高系统运行效率。
特征词的提取可以结合特征词权重一同进行。
词在文档中的权重可以由多种方式来计算,TF-IDF是一种常见的方法,该方法用于评估一个字词对于一个文件集或者一个语料库中的其中一份文件的重要程度,是一种常用的加权技术。该方法能过滤掉常见的词语,而保留重要的词。TF(Term Frequency)词频,指某个词在文章中出现的频率,体现了该词描述文档的能力。

有些常见非停用词在文档中出现频率较高,它的TF值也相对高些,但是该词对文章或语句的“话语权”不大,对语义的影响较弱,因此考虑到词权重时还需要考虑到词在区分两文档时起到的效果。IDF(Inverse document frequency)指逆向文本频率。

IDF越大,说明该词在文档中出现的概率较小,利用该词能较好地区分文档。TF-IDF算法,是计算TF×IDF的值,体现了某个词对文章的重要性,重要性越高,它的TF-IDF值就越大。因此关键词的提取,可以采用TF-IDF值排在前面的若干词。经特征词提取及权重计算后,项目申报书的向量模型可以表示为:Dn(,……,Tn,Wn)(j>n,其中表示为关键词Tn对应的权重)。
2.4 两申报书相似度计算
通过将拟对比的申报书文本向量化后,计算申报书1和申报书2的相似度就是计算向量空间模型D1、D2的余弦值。
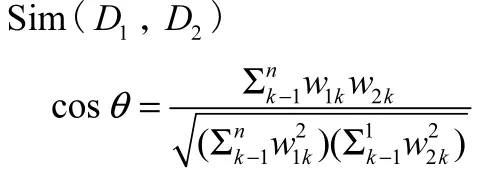
式中D1、D2表示文档的特征集,W1k、W2k分别表示文本D1和D2第K个特征项的权值,1≤j≤N。
3 结 语
通过对项目申报书相似度对比,可以开展有针对性的查重,解决大海捞针式查重和印象查重,大幅提高项目查重的效率和准确率,但项目申报书相似度测算仅是从文本相似程度的角度去测算,对于相似程度较高或较低的较容易判断,介于两者之间的,研究内容是否相似还需要进行人工判断。
[1] 殷耀明,张东站. 基于关系向量模型的句子相似度计算[J]. 计算机工程与应用,2014,50(2):198-203.
[2] 方延风. 科技项目查重中特征词TF-IDF值计算方法的改进[J]. 情报探索,2012(1):1-3.
[3] 陈桂林,王永成. 一种改进的快速分词算法[J]. 计算机研究与发展,2000,37(4):418-423.
Design of VSM-based Duplication Checking System for Project Application Forms
HU Weiwei,SUN Xun,WANG Tingting
(Productivity Centre of Jangsu Province,Nanjing 210042,Jiangsu Province,China)
With the growth of financial expenditures on scientific research from national and local governments,science projects have attracted more attention from enterprises and public institutions and the number of project applications is increasing year by year.To avoid repetitive support of similar projects and prevent the waste of scientific research funds,project duplication checking has become particularly important and necessary.A design method of Vector Space Model(VSM)-based project application form duplication checking system was presented and design procedures were elaborated.
project duplication checking;Vector Space Model(VSM);word segmentation
TP311.1
:A
:1006-8945(2015)08-0033-02
2015-07-03
