智能测评技术在大规模英语口语考试评卷中的探索与实践
2015-06-27吕鸣
吕鸣
智能测评技术在大规模英语口语考试评卷中的探索与实践
吕鸣
本文探讨在大规模英语口语考试中,机器智能评分部分取代人工评卷的可行性。通过对2015年上海市普通高中学业水平考试英语口语考试的考生答卷进行人工和机器评分比较,得出机器评分在稳定性和客观性上的表现明显优于人工评分,可以部分取代人工评卷。本文还对如何进一步提高智能评分的准确度提出建议。
智能测评;机器评分;口语考试
1 引言
英语是我国学生的主要课程之一。英语课程的总体目标是培养学生的语言综合运用能力。听、说、读、写既要作为学习的内容又要作为学习的手段,在重要的终结性评价中应该包括口试、听力考试和笔试,以全面考察学生的语言综合运用能力。2014年9月,上海作为首批高考综合改革的试点城市,对外公布了《上海市深化高等学校考试招生综合改革实施方案》,方案中提到深化外语考试的改革。从2017年开始,外语考试包括笔试和听说测试,听说测试部分采用人机对话的方式,一年举行两次,分别在每年1月和6月。高中生可最多参加两次外语考试,选择其中较好的一次成绩计入高考总分。[1]
在新方案实施前,上海仅在每年1月举行普通高中学业水平考试英语口语考试,近三年参加考试的人数均维持在每年5.5万人左右。每次考试结束后,均需要组织近千名教师对考生语音答卷进行集中网上评阅并采用人工双评模式。
2017年高考改革后,由于推行一年两考,因此每次考试的人数可能大大超过当前。如果在这样大规模的考试中,对所有考生的语音答卷进行集中人工网上评阅,则会存在如下问题:(1)人工评卷工作量大。按照目前人工双评模式,若双评差值超过设定的误差阈值,则需要评卷组长进行仲裁打分以确定最终成绩,因此,每次评卷的总工作量至少是考生数的2.1倍。以评阅完单个考生所有答题需要5~10分钟计算,5万考生的答卷需要千名教师花费2~3天才能完成。(2)人工评卷组织管理困难。上海市英语口语考试共有12套试卷,分别在不同的考试批次中使用,评卷同时在4个评卷点集中进行,因此在评卷前需要根据各批次的考生人数分布情况,划分各评卷点的评阅工作量。若每套试卷按照题型划分成多块评阅,则更增加了管理的复杂度。(3)人工评卷存在较大主观性。人工评卷工作量大且是重复性工作,特别是长时间用耳用眼去判别打分,难以保证评卷质量不受影响。在人工评卷时,不同的评卷教师会按照各自对评卷标准的理解,产生不同的标准,即便是同一个评卷教师在不同时段也会产生标准偏差,这就带来了很多主观差异,考试的信度会受到一定的影响。
为解决上述问题,提高评卷效率和公平性,经过对近三年上海市普通高中学业水平考试英语口语考试考生语音数据的分析研究,构建了具有上海地域特色的智能语音评分模型。通过对比人评和机评的结果,验证智能评测技术在上海英语口语考试评卷中的实际应用效果,稳步推进英语口语考试评卷由人工网上评卷向机器智能评分的转变,为机器评分逐步取代人工评卷打下基础。
2 智能评测技术在英语口语考试评卷中的应用
2.1 智能评测的核心技术
智能评测的核心技术包含语音合成、语音识别和语音评测,其功能和核心技术如表1所示。
智能评分引擎的技术特征包含两方面:(1)自由表述题的自动评分。首先需要引入连续语音识别技术,以使得计算机能够“听懂”考生的表述内容。[2]然后,基于题目要点和专家提供的参考答案,通过语义扩展生成本题定制化语言模型,并使用海量数据训练和通用语言模型插值算法,有效降低未登录词的比例,提升识别性能;同时通过机器翻译对语义进行相似度匹配,实现答案自动扩展,在机器评阅中对答题要点进行准确性比对,从而完成对表述完整度的评价。(2)基于人工辅助的模型自动优化。使用专家对每套试题的转写结果进行语言模型的优化。在通用评测模式下的语言模型如与真实的口语表述有部分不匹配,通过引入题目真实口语表述转写数据和自动扩展生成的训练语料混合进行语言模型训练,以大幅改善语言模型的性能;同时,基于专家打分和转写结果,通过数据驱动的方式训练以自动发现新特征(如某些表述不好,一旦出现则会打低分等),对比专家打分结果和机器预测结果,使机器能学习专家打分的尺度,以进一步提高人机打分结果的一致性。
2.2 智能评测的实施
2.2.1 准备工作
评卷题块划分。在正式评卷时,为了让机器与人工评分相结合,需将每套试卷按评卷模式分为全机评、人机互评和人两评三个题块,如表2所示。这样划分考虑到作答的主观性与客观性差异,使机器评分逐步取代人工双评。客观性最强的题块一全部由机器评分,通过学习专家评分标准,机器可以更稳定、客观地进行评分;主观性最强的题块三则继续维持人两评的模式;处于两者之间的题块二则采用人机互评的模式,人一评可以弥补机器评分在某些方面灵活性不够的缺点。

表1 智能口语评测核心技术

表2 2015年上海市普通高中学业水平考试英语口试评卷分块方式
评卷系统改造。为满足三种评卷模式相互共存,也为今后逐步取消人工双评做好技术准备,需要对原有评卷系统进行技术改造,使各题块可以选择全机评、人机互评和人工双评三种评卷模式中的任何一种,机评可以取代任意一个人工评次,且对已经存在机评的评次不再进行评卷任务分配。
执行效率预估。智能评卷的完成时间在实施中会遇到硬件环境的制约。实施步骤中数据预处理、基础运算和评测运算完成所需要的时间和计算机配置是密切相关的,即评卷效率与线程数、主频性能、可用内存数成正比关系;另外,如果对智能评测引擎进行升级也会带来评测效率的变化。因此,在正式实施前需要进行模拟运算以预估软硬件执行效率,确保整个流程能按计划完成。
人机仲裁率预估。如采用人机互评,仲裁率是否能控制在正常水平将关系到重复劳动的多少。在评卷中如有大量人评与机评结果相差超过误差阈值,将会有相应数量的试卷需要评卷组长仲裁打分,造成人力的浪费。因此,需要在人工定标后的验证环节对人机仲裁率进行预估,确保在正式评卷中不会出现高仲裁率。
2.2.2 实施步骤
根据上海的实际情况,将整个评卷实施步骤划分为五个阶段:数据准备、定标运算、效果论证、评卷和最终论证,每个阶段包含的详细步骤见表3。
2.3 人机评分对比结果
通过对2015年上海市普通高中学业水平考试英语口语考试的答卷进行人工和机器评分,除去机器不评分的部分(如人工定标部分和少部分由于录音质量不达标导致机器无法评分),对最终人机评分结果按题块对比如下。
2.3.1 题块一对比结果
由于题块一是纯朗读题,采用机器评分完全取代人工评卷的方式,因此人机评分结果对比是基于对1 200份验证集数据人工双评和机器评分的对比,如表4所示。
2.3.2 题块二对比结果
题块二是人机互评题型,仅采用人一评,为验证机评的可信度,分别用机评结果、人一评结果与人机最终分进行比较,统计每个分差间距内的人数,如表5所示。为明确仲裁是由哪一方偏差过大造成的,针对题块二的4 377份评卷组长仲裁数据,分别将机评结果和人一评结果对比仲裁分,从分差上可以看出仲裁的责任权重,最终得出“机器分更接近仲裁分”占58.08%,如表6所示。
2.3.3 题块三对比结果
题块三为全人评阅题型,答题的开放性最大,机器评分结果仅作参考,不计入最终成绩。考虑到今后机器评分将逐步取代人一评,为验证机器对开放性较大题型的评分准确度,分别用机评结果、人最终分、人一评结果和人二评结果进行对比,统计每个分差间距内的人数,如表7所示。
2.4 结论
题块一采用机器评分完全取代人工评卷的方式,因此人机评分结果对比是基于对1 200份验证集数据人工双评和机器评分的对比。从分差上来看,机评结果更接近人评最终分,出现的大分差数据最少。
题块二分别用机评结果、人一评结果与人机最终分进行比较,可以看出机器评分在准确率和稳定性上略高于人评;在仲裁权重分析方面,抽取所有被仲裁的4 377份数据,分别将机评结果、人一评结果分别与仲裁分对比,可以看出人评的被仲裁率较高,且在被仲裁数据中,人评偏差所造成的权重较大。
题块三的机器评分虽然目前还停留在试验阶段,但从整体效果上看,机评结果更接近人评最终分,同时比人工双评降低了约2/3的仲裁量。今后在有完备参考答案扩充的前提下,题块三可采用人机互评,以进一步提高效率。
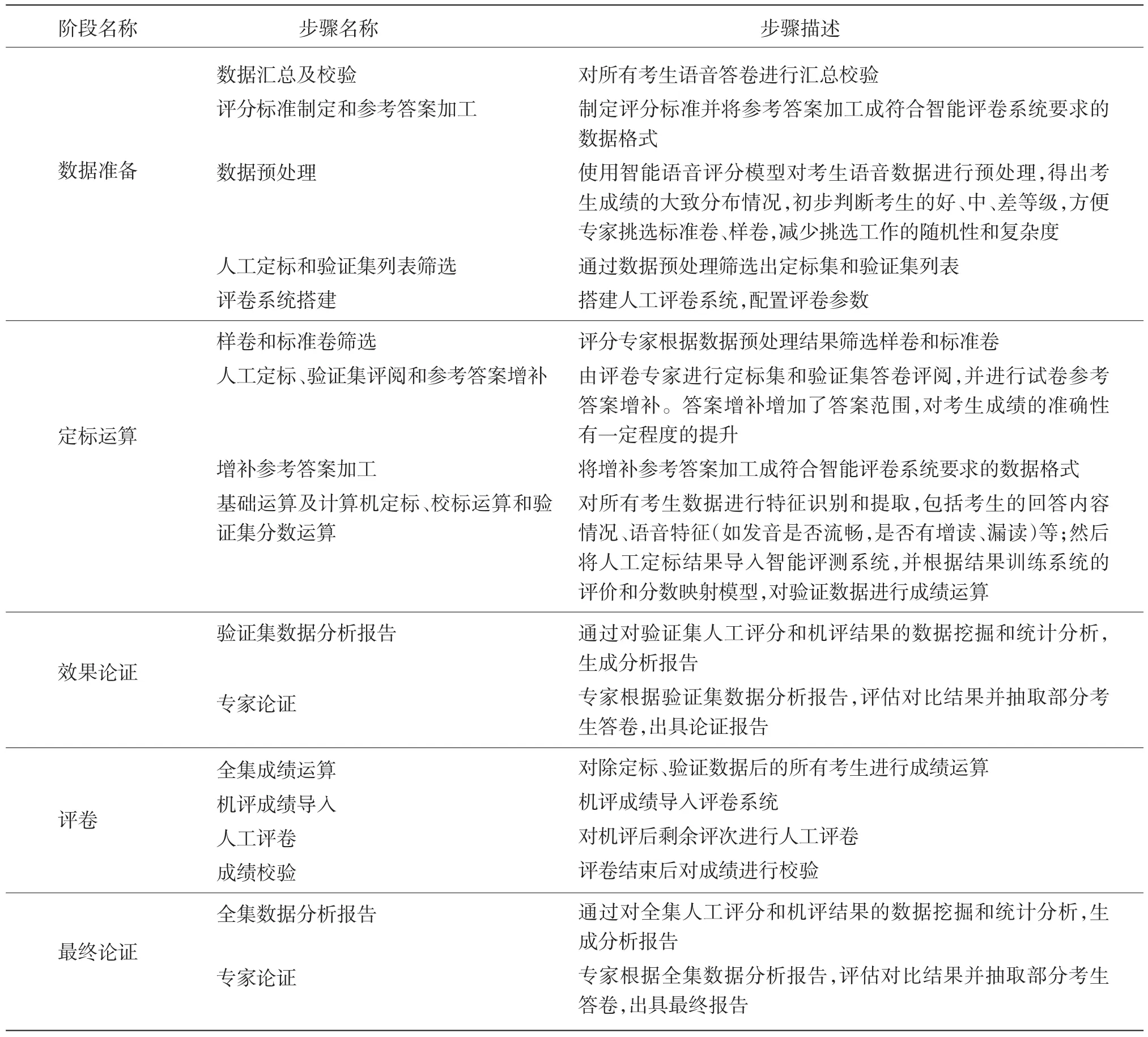
表3 上海市普通高中学业水平考试英语口试评卷实施步骤
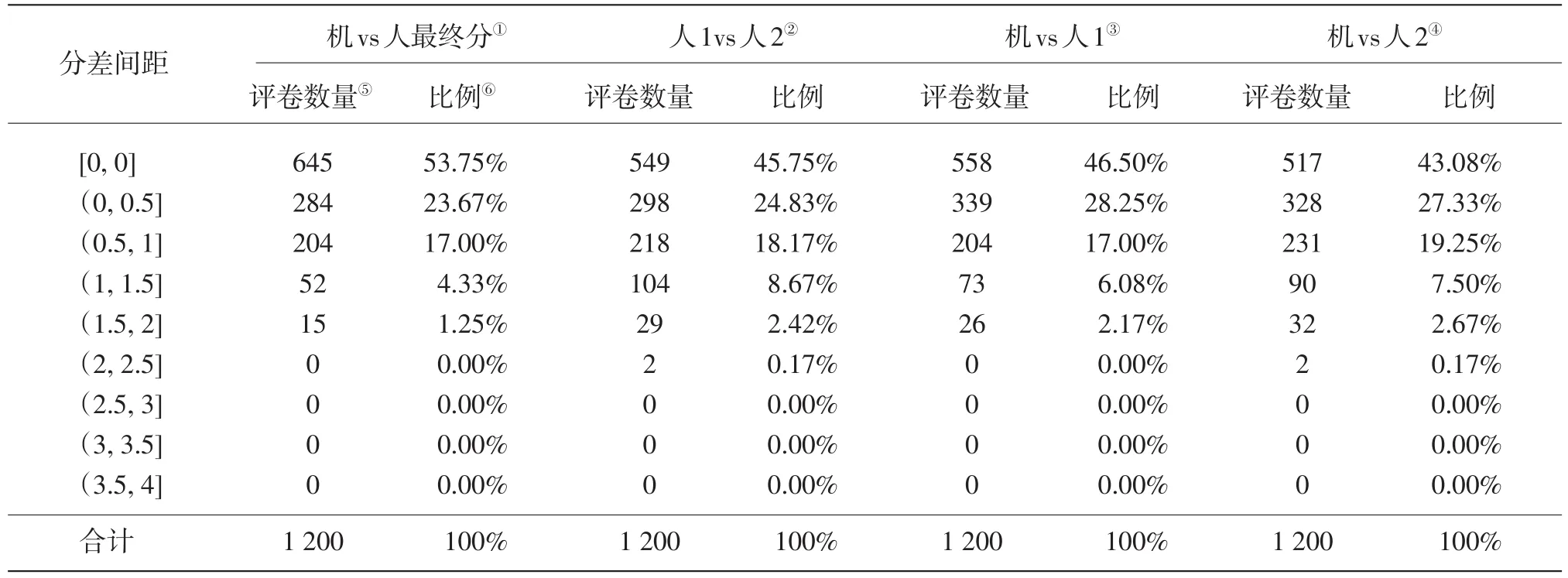
表4 题块一人机分差统计
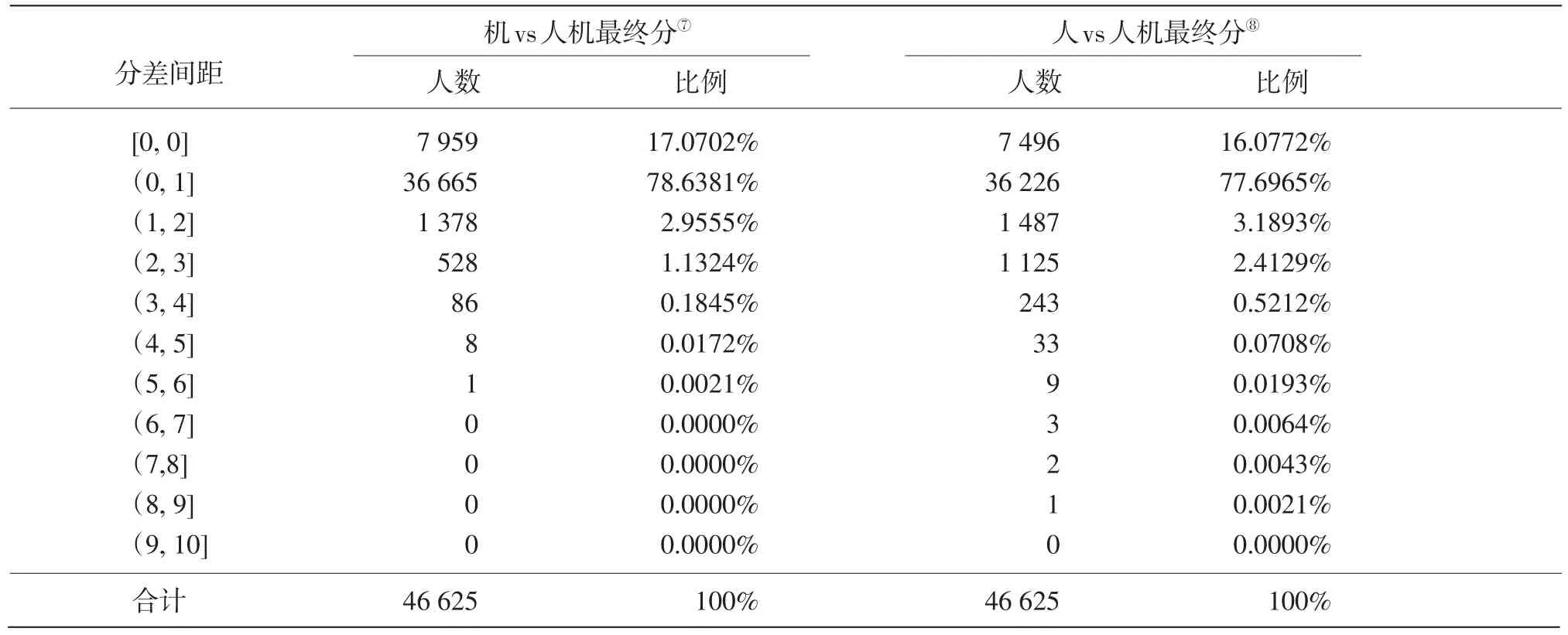
表5 题块二人机分差统计

表6 题块二人机与仲裁分对比统计
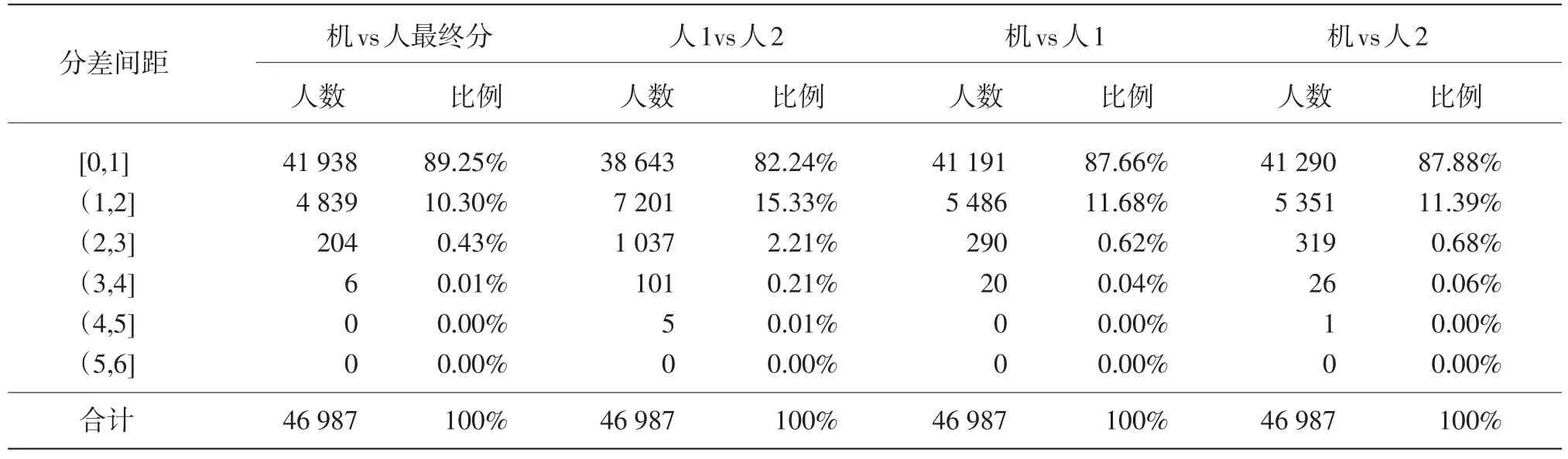
表7 题块三人机分差统计
3 思考与展望
人机对比数据表明,在大规模英语口语考试评卷中,机器完全可以辅助或者部分替代专家进行评卷,不仅可以大幅减少人工评卷的工作量,而且机评的稳定性、客观性等优点也充分的展现出来,但在实际运用中也难免有不足之处。通过对源于机评的误差抽样分析后发现:(1)在朗读题中,考生将一个单词读成另一个单词,机器没有对这类错误扣分。(2)在情景对话环节,考生的作答虽然部分内容与评卷标准中所给的关键词吻合,但整体的回答与情景不符,理应不得分,但机器却给了部分分数。
这些问题说明机器对考生作答的评阅比较机械,不能灵活处理超出标准学习范围的作答。为进一步发挥机器评分的优势,提高评分精准度,还需要完善以下四方面问题:(1)启用口语标准化考场。目前不同口语考场中使用的耳麦质量参差不齐,座位间距也各不相同,可能会因噪声干扰太大导致部分考生答卷不符合机器评分的最低声源要求。因此,需启用标准化考场,以降低噪音干扰,提高机器智能评卷的可识别率。(2)细化评分标准。以往的评分标准较粗略,没有对诸如读错几个单词扣几分等细节进行量化。因此,要使机器进行精准的评分就必须对评分标准细化、量化。(3)重视人工定标环节。人工定标是机器通过学习评卷专家制定的标准来对其他试卷进行评分的过程,如果标准制定有问题,那么之后的机器评分也必然有问题。因此,必须对参与人工定标及评卷教师进行资质认证,其中人工定标的要求应更为严格,认证结果每年动态更新,评卷教师优胜劣汰,确保只有具有资质的评卷教师才能参与评卷。(4)重视专家论证环节。如在高利害性考试中实施机器智能评卷,需要在机器校标和人工评卷后分别进行两次专家论证。在机器校标完成后,专家需要对验证数据的机评准确度进行抽样判定,提早发现可能存在的问题,确保机器对剩余答卷评分的准确性;在人工评卷完成后,专家再根据最终数据分析报告对全集数据进行抽样,验证机评的可靠性。另外,对于高水平考生的答卷,需要专家对机器评分再做修正。
[1]上海市教育委员会.上海市深化高等学校考试招生综合改革实施方案[EB/OL].(2014-09-18)[2015-08-10].http://www.shmec. gov.cn/html/xxgk/201409/420032014012.php.
[2]严可,胡国平,魏思,等.面向大规模英语口语机考的复述题自动评分技术研究[J].清华大学学报(自然科学版),2009,49(S1).
The Exploration and Practice of Computerized Automatic Scoring in Large-scale English Oral Test
LU Ming
This paper discusses the feasibility of computerized automatic scoring replacing human scoring in largescale English oral test.The comparative analysis between computerized automatic scoring and human scoring in different question types of the oral examination for Shanghai Senior High School Achievement Test of 2015 shows that machine scoring is obviously better than human scoring in stability and objectivity.In some cases,machine scoring can take the place of human scoring.Suggestions on how to enhance the accuracy of machine scoring are put forward.
Intelligent Assessment;Computerized Automatic Scoring;Oral Test
G405
A
1005-8427(2015)10-0051-7
吕鸣,男,上海市教育考试院,工程师(上海 200235)
