基于改进BP神经网络的负性情绪语音识别
2015-06-23刘忠锋
刘忠锋,何 亮
(1.中国石油伊拉克公司哈法亚项目,伊拉克阿玛拉 62001;2.南京理工大学自动化学院,江苏南京 210094)
基于改进BP神经网络的负性情绪语音识别
刘忠锋1,何 亮2
(1.中国石油伊拉克公司哈法亚项目,伊拉克阿玛拉 62001;2.南京理工大学自动化学院,江苏南京 210094)
负性情绪对于临床治疗的效果有着巨大影响.语音是人类表达情绪的主要方式之一,通过语音识别患者的情绪状态,可以帮助我们更简便、更快捷地监控病人的情绪,从而可以更快更有效地采取措施降低负面情绪带来的不良影响.对一种改进BP神经网络进行了扩展,拓展了用于情感识别的语音特征向量的冗余度,采取主成分分析方法对语音特征向量进行降维处理,并对语音样本进行去野点处理,从而使得该BP网络同时具备了对于愤怒和悲伤两种负性情绪的良好识别能力.
负性情绪;BP网络;前向选择算法;主成分分析;野点
作为人与人之间进行交流的主要媒介之一,语音不仅包含着语义的信息,还包含着情感的内容,在情感计算中拥有极其重要的地位.语音中情感信息的自动提取与识别可以进一步加强人与计算机之间的交流,创造更为和谐的人机对话环境,从而为我们的生活提供更多的便利.
作为典型的情绪类别,负性情绪(比如愤怒、悲伤、抑郁等)在日常生产生活中所产生的影响不容忽视.研究表明[1],长期负性情绪的影响会导致人的免疫功能下降、认知能力减弱.Evans等人认为[2],缺少积极生活事件的个体更易于患上呼吸道感染.张作记等人的研究表明[3],负性情绪会加速冠心病的发生与发展,并指出通过干预负性情绪可有效降低冠心病冠脉事件发生率.因此,引进计算机自动检测有助于快捷有效地采取相应的措施,降低负性情绪带来的不良影响,因而有着重要的临床意义.
BP神经网络由于其非线性映射能力、较好的泛化能力、良好的对于复杂数据的分类能力以及结构简单等特点,在语音及情感识别中有着广泛的应用①参见: Amir N. Classifying emotions in speech: a comparison of methods [C]. Proc. Eurospeech 2001, Scandinavia..例如Nicholson等人用于情感识别的one-class-in-one模式[5]以及Razak等人提出的all-class-in-one模式②参见: Razak A A, Komiya R, Abidinm I Z. Comparison between fuzzy and NN method for speech emotion recognition [C]. Proc. of the 3rd International Conference on Information Technology and Applications, Washington DC: IEEE Computer Society, 2005: 297-302.等,其采用的基本结构都是BP网络.然而,由于BP网络存在容易陷入局部最优、初始值选取随意性太强等问题,其识别率往往会出现振荡现象,而且网络的训练次数在很大情况下影响了识别效果.针对这些缺点出现了不少改进算法,如动量BP算法(BPM)[6]、可变学习速率的BP算法(VLBP)[7]、Levenberg-Marquardt优化BP算法[8]等,在一定程度上弥补了BP网络的一些缺点.然而,由于情感识别的特殊性,上述改进算法的表现还是不够理想,对此,我们针对一些情感现象进行分析,将生物进化所形成的情感中的“创新”机制引入到BP网络中,并对悲伤情感进行了识别[9].文献[9]中提出的算法与传统BP网络及其改进算法相比,其识别率有了明显的提升,并且受迭代次数即训练次数的影响大大降低,然而,该文献中的实验存在着两个局限性:首先,实验采用的数据均来自女性;其次,仅对悲伤情感进行了分析.
本文采用离散情感模型[4],进一步扩展了文献[9]提出的改进BP网络,并且同时针对愤怒与悲伤两种典型的负性情感进行了特征分析与识别.
1 改进BP神经网络的简单扩展
1.1 改进的BP网络
在之前的工作中,我们对一些情感现象进行了简要的分析,并从中得到启发,提出了一种改进的BP神经网络[9],在BP网络的权值更新阶段加入了“创新”的机制,该机制包含了如下内容:
1)经训练更新后的权值会以一个很小的概率发生改变.
2)改变量不宜过大,并且应该随着迭代次数的增加而减小.
3)对改变后的权值进行识别率的评价,如果此改变使得识别率提高,则它将得以保留.
引入该机制以后,我们发现网络受迭代次数的影响大大减小,有效抑制了“过训练”带来的泛化能力的降低.并且有助于系统从局部最小中逃脱出来,从而达到识别率的提升,经实验验证,使用该改进后的BP网络与使用其他BP改进算法相比,对于悲伤情绪的识别能力获得了很大的提升,并且识别率——迭代次数曲线也相对比较平缓.
1.2 BP神经网络的简单扩展
首先,我们考虑对文献[9]中提出的改进BP神经网络的结构进行简单扩展,使之同时具有对两种典型负性情感——愤怒与悲伤的识别能力.为此,我们采用与文献[9]同样的数据库,将来自同样5位女性的愤怒与悲伤的样本输入神经网络.为了进一步考察网络的分类能力,在输入样本中我们混杂了其他情感的样本作为干扰,然后把网络的输出结点调整为2个.得到的识别结果如表1所示.

表1 BP神经网络扩展后愤怒与悲伤的识别率比较
从表1可以看到,此时系统对于愤怒情感的识别率很低,只有22.35%,可见简单修改文献[9]中提出的BP神经网络的结构并不能达到对愤怒与悲伤两种典型负性情感进行有效识别的目的.进一步的研究和分析表明,简单扩展BP神经网络导致识别率较低的主要原因在于特征向量的选取.文献[9]中选取了短时能量最小值,过零率最小值及均值,基音的最大、最小值及均值,有声部分长度、第一共振峰的最小值和均值等组成9维特征向量,其中大部分特征对于悲伤情感的贡献度较大,但对于区分愤怒和悲伤贡献很小.显而易见,解决此问题的一种途径是增加特征向量的冗余度,为此我们采用了短时能量、过零率、基音频率、前三个共振峰的最大值、最小值和均值,以及有声部分的长度等组成特征向量,将特征向量的维数扩展到了19维.将这个19维的特征向量输入到神经网络,得到识别结果如表2所示.

表2 采用19维特征向量时愤怒与悲伤的识别率比较
显然,增加冗余后,虽然系统对于悲伤情感的识别率略有下降(7.89%),但是对于愤怒情感的识别率却大幅提升了27.75%.
需要注意的是,简单地增加特征向量的冗余度在提高对多种情感的联合识别率的同时,并不能保证提高对于特定情感的识别率,因此扩展到19维特征向量后,系统对于悲伤情感的识别率反而有所下降.原因是不同的语音特征对不同情感识别的贡献差别较大,文献[9]中的9维特征向量主要是针对悲伤情感所选取,对于愤怒情感贡献不够大,造成愤怒情感的识别率较低;扩展的19维特征向量包含了对愤怒情感识别支持较大的语音特征,提高了对愤怒情感的识别率.然而,事物都是一分为二的,扩展的19维特征向量在提高愤怒情感识别率的同时,也因为为悲伤情感引入了更多的非典型特征,实际上降低了原来的9维特征向量对于悲伤情感的代表性,以及相应的对识别率的贡献,因而造成悲伤情感识别率的下降.从这个角度来说,对于语音情感识别而言,特征向量维数不是越高越好,需要研究各种特征对情感识别的贡献程度.
2 带PCA的BP神经网络
显然,在上面的改进BP神经网络扩展中,通过增广特征维数,可以在未明显恶化悲伤情感识别率的前提下有效提升愤怒情感的识别率.然而,高维特征的处理代价较大,并且有可能反而降低了某种情感的识别率.因此,需要研究的问题是:为保证两种负性情绪的有效识别,如此高维的特征是否必要?各种特征对于最终识别的贡献又是如何?
为解答上面的问题,我们对样本中各种特征的分布情况进行分析.图1列出了部分特征(最小过零率、第一共振峰的最小值和均值)在训练样本中的分布状况,其中横轴表示样本,纵轴表示特征的取值.
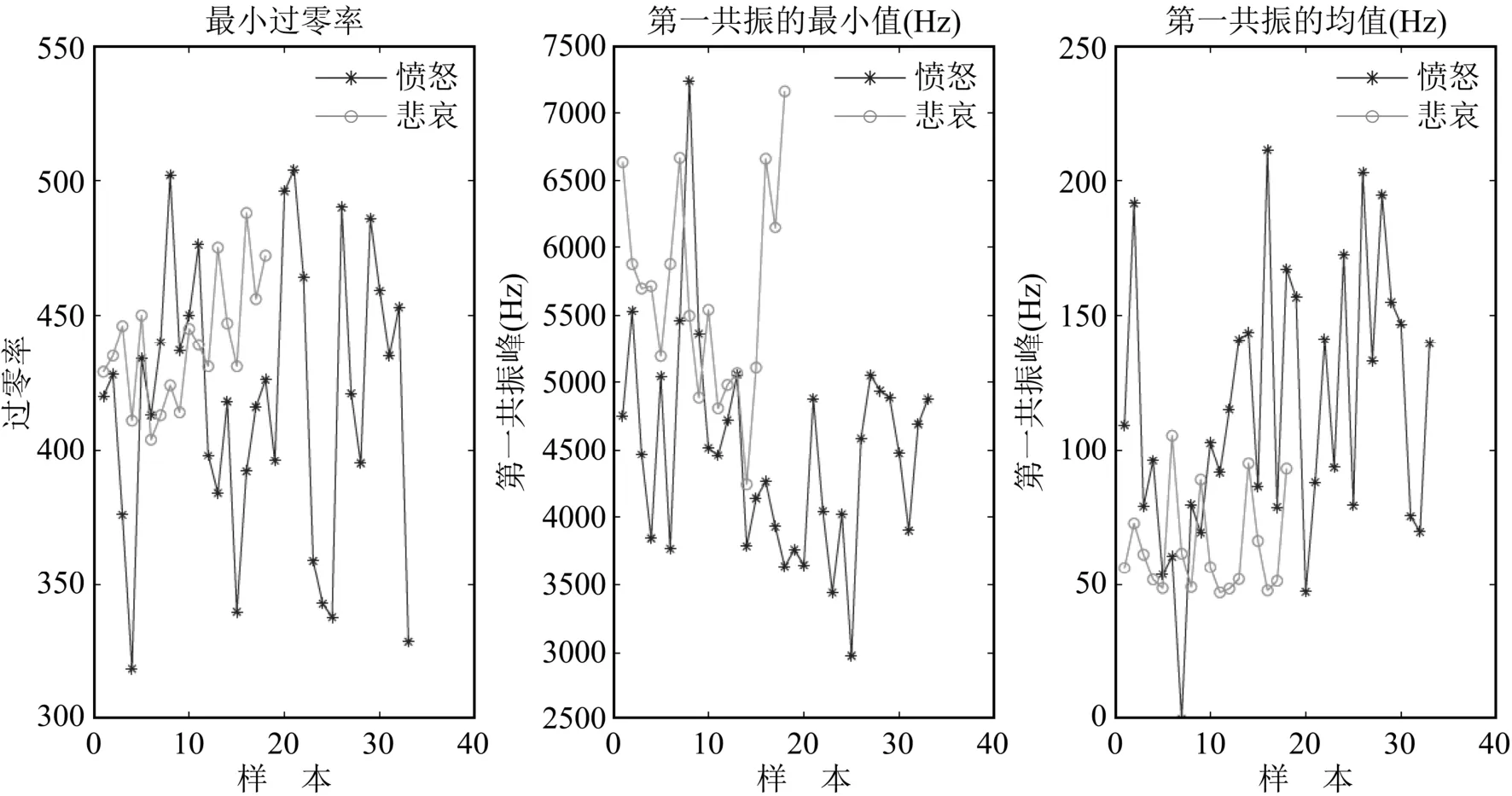
图1 最小过零率、第一共振峰最小值和均值的分布状况
从图1可见,在文献[9]所采用的特征中,部分特征在两种情感样本中的分布密集,以至于很难根据这些特征区分出愤怒与悲伤两种情感.因此,在进行识别之前,我们必须进行“特征降维”,即对拟采用的特征进行筛选,留下对识别贡献较高的特征,剔除对识别过程产生干扰的特征.
目前常用的两种特征降维方法是:前向选择[10]以及主成分分析[11].
2.1 前向选择方法
前向选择(FS)算法是一种应用非常广泛的特征选择算法.首先,FS算法通过一定的判别规则从所有特征中选取一个最佳特征初始化已选特征集,然后从余下的特征中按照同样的原则选取一个特征添加到这个已选特征集中.如果添加了一个特征之后使得系统的识别率上升,则该特征被保留.如此往复,直到达到迭代次数或预设的已选特征个数为止.此时可以得到一组已经筛选的特征,然后采用leave-one-out方法[10],从特征集中一个一个地剔除特征.若某特征被剔除后使得系统的识别率下降,则该特征得以保留.
FS算法是一种精度较高的特征选择算法,它既保持了系统的精度,又保证了特征集的精简.但是它有着明显的缺点,就是操作繁琐,需处理的数据量非常大,且每选择一个特征都需要经过系统精度的验证.这将导致大量的运算.
2.2 主成分分析
主成分分析(PCA)是一种数据分析技术,它通过构造原数据集的协方差矩阵,然后求解使该协方差矩阵成为对角化矩阵的变换,找出原数据集中相关性比较小的一组数据,从而找到原数据中的“主要”成分.在具体操作上,可以通过求解原数据乘方矩阵的特征值与特征向量达到相同的效果.
值得注意的是,PCA的一些前提与假设,比如指数模型假设、大方差向量等具有较大重要性的假设等,使得PCA在应用时存在着一定的局限性,这些局限使得它在处理一些非线性、或者其他不符合其假设的对象时,必然会损失一定的精度.但是,对于情感这一本身界限不太明确的对象,使用PCA仍然有其用武之地.另外,与FS算法相比,PCA更加简单、易操作,并且需处理的数据量远远小于前者.因此,本文在前面简单扩展的基础上,引入PCA算法,以期得到系统识别率的提升.
3 仿真实验
为了验证所提出的引入PCA改进BP神经网络对愤怒和悲伤情感的识别效果,我们采用柏林情感语音库①参见: Berlin Database of Emotional Speech [EB/OL]. http://emodb.bilderbar.info/start.html.设计验证试验.实验分为3个部分,第一个部分的实验数据来自于5名年龄不同的女性演员,10种不同的语句,共137个样本,样本覆盖了愤怒、悲伤、惊奇三种情感的数据.第二个部分的实验数据来自于5名年龄不同的男性演员,10种不同的语句,共121个样本,同样覆盖了愤怒、悲伤、惊奇三种情感的数据.第三个部分的实验数据为前两个部分数据的综合.共258个样本.
每个实验分为以下两个步骤:
1)简单扩展.对于第一部分实验,选取覆盖三种情感的67个样本作为训练集,余下的70个作为测试集;对于第二部分实验,选取覆盖三种情感的60个样本作为训练集,余下的61个作为测试集;对于第三部分实验,选取覆盖三种情感的127个样本作为训练集,余下的131个作为测试集.实验的结果取10次运行后的平均值,采用19维特征向量;
2)带PCA的改进BP算法.首先对特征进行主成分分析,通过考察累积变量解释程度可以得知为了达到目的需要选取多少主成分.图2所示为悲伤情绪的变量解释程度.
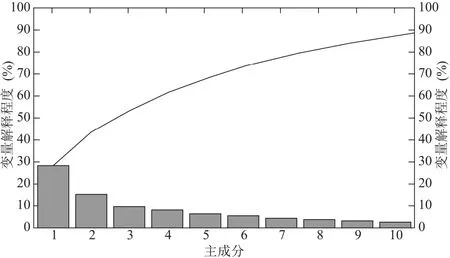
图2 悲伤情绪的变量解释程度
从图中可以看出,选取特征数据的前10个主成分可以表示出原始数据的90%,因此在实验中我们只需取前10个主成分即可.另外,通过观察图1,我们可以看到所采用的样本中存在着一些远远偏离数据主要分布区域的“野点”,在训练与识别的过程中,这些“野点”无疑会对系统的识别与判决造成影响,因此,在进行训练与识别之前,应该将这些“野点”去掉.由于“野点”数量不大,因此可以采用手工方式从数据集中识别野点甚至剔除.但是,对于多种情感的识别而言,手工去野点比较繁复.
野点可以采用基于主成分分析和属性距离和的算法进行检测[13],首先通过主成分分析提取出贡献率满足需要的主成分,同时利用PCA变换矩阵把原始数据集转换到由主成分构成的新的特征空间上,之后对转换后的数据集用属性距离和的方法对野点进行检测.据此,我们对样本做主成分分析及属性距离和判别,去除野点,提取出对识别产生“主要”影响的样本数据.
由此,产生的对于各部分实验数据训练集与测试集的划分如下:
a)第一部分(女性样本):对女性的137个样本进行去野点处理,提取出120个样本,并从中随机挑选60个数据作为训练集,余下的60个数据作为测试集.
b)第二部分(男性样本):对男性的121个样本进行去野点处理,提取出100个样本,并从中随机挑选50个数据作为训练集,余下的50个数据作为测试集.
c)第三部分(混合样本):对男女混合的258个样本进行去野点处理,提取出220个样本,并从中随机挑选110个数据作为训练集,余下的110个数据作为测试集.
三部分实验结果均取10次运行后的平均值,特征向量由前10个主成分组成.其结果及对比如表3所示.
从表3中可以看到,在三种情况下,采用PCA与不采用PCA相比,愤怒情绪的识别率都有了大幅的提升,尤其是对于男性样本和混合样本.使用PCA进行特征降维及去“野点”操作前,识别率不足20%,对于样本只有三种情感类别的情况而言,这样的识别率相当于系统对于愤怒情感毫无识别能力,因为它得到正确结果的概率比“猜”还低,可见采用PCA对于提升愤怒情绪的识别率有着极大的贡献.但是,从表3中我们还可以看到,相对于愤怒情绪识别率的明显提升,在输入男性样本和混合样本的情况下,悲伤情绪的识别率略有下降,其中尤以男性样本下降得最为显著.产生此现象的一个主要原因是样本容量不足.
表4列出了用于实验的各种情感样本在总体中的分布情况.
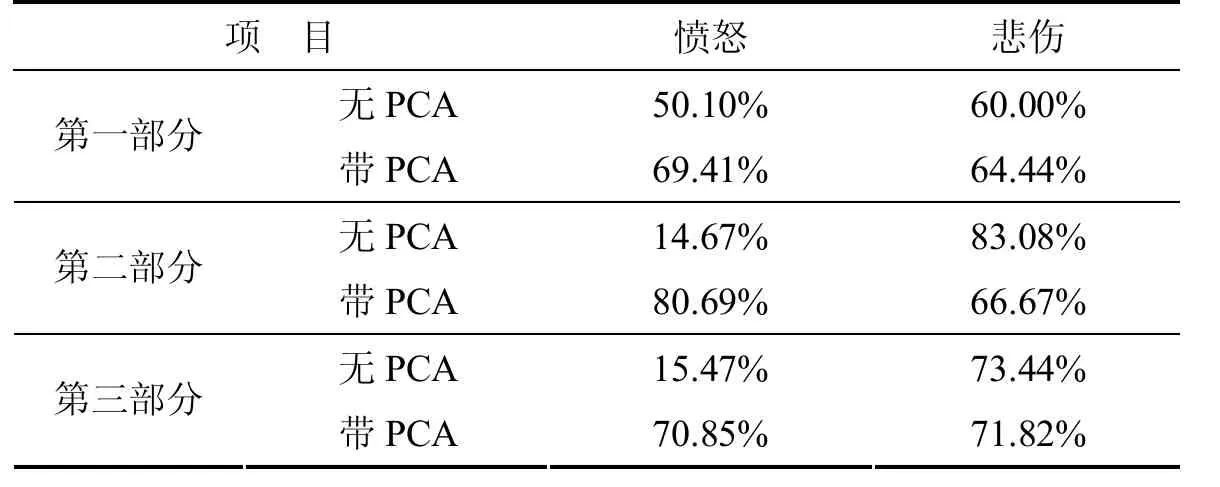
表3 实验结果及比较

表4 各情感样本的分布情况
可见无论在男性样本还是女性样本中,悲伤情绪样本占有的比例都是很低的,在经过了去“野点”处理后,其占有的比例就更少了,这将会导致该情感类别训练不足,从而对于识别率造成极大的影响.
表5中列出了在男性和女性样本中,采用去野点处理与不采用去野点处理时识别率的变化情况.

表5 野点对识别率的影响
由此可见,去野点处理对于样本数较多的愤怒情绪而言,其识别率的提升情况是相当明显的;但是对于样本数很少的悲伤情绪来说,由于训练不足,其识别率略有下降.
传统的PCA算法存在较严重的鲁棒性问题,因此样本需要进行去野点处理,以消除或减弱野点的影响.然而,正如上面所观察到的,去野点处理往往会影响情感的识别率.因此,有必要考虑采用鲁棒PCA算法[14],不对样本进行去野点处理,而是在运行过程中自动地识别样本集中的野点,通过迭代计算加以适当处理来排除对运算精度的影响.我们后续将继续开展这方面的研究.
4 结 语
本文进一步扩展了先导研究中提出的用于负性情绪语音情感识别的改进BP神经网络,提出对网络结构和特征维数进行改变,并对特征向量和样本空间进行主成分分析,使扩展后的网络同时具有对悲伤和愤怒两种负性情感的识别能力.
实验比较结果表明,通过扩展特征向量的维数、提取特征向量的前10个主成分,并将这些数据经去“野点”处理后作为训练集和测试集,可以使改进的BP神经网络大大提升对于愤怒情感的识别率.
然而,由于实验采用的数据库受到客观条件的制约,如情感语音库的采集难度、权威性等,使得样本的容量和质量不尽人意,导致其对于悲伤情绪的识别率不够理想.情感语音库的建立是语音情感识别研究的重点和难点之一[12],除了语音情感识别常用的柏林情感语音库之外,目前缺乏广为采用的其他较成熟的公共情感语音库供研究.
另外,从实验结果也可以看到,采用男性样本与采用女性样本的结果有着较大的区别,因此,提出的改进算法对于不同性别情绪识别的影响,还有待深入研究和进一步扩展.
[1] Dantzer R, Mormede P. Psychoneuroimmunology of stress [M]. Oxford, England: John Wiley & Sons, 1995: 47-67.
[2] Evans P D, Edgerton N. Life-events and mood as predictors of the common cold [J]. British Journal of Medical Psychology, 1991, 64: 35-44.
[3] 张作记, 王长谦, 崔立谦, 等. 负性情绪干预对冠心病心绞痛疗效及冠脉事件发生率的影响[J]. 中国行为医学科学, 1999, 8(3): 187-189.
[4] Murray L R, Arnott J L. Towards the simulation of emotion in synthetic speech: a review of the literature on human vocal emotion [J]. Journal of the Acoustical Society of America, 1993, 93(2): 1097-1108.
[5] Nicholson J, Takahashi K, Nakatsu R. Emotion recognition in speech using neural networks [J]. Neural Computing & Applications, 2000, 9(4): 290-296.
[6] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors [J]. Nature, 1986, 323: 533-536.
[7] Hagan M T, Menhaj M B. Training feedforward networks with the marquardt algorithm [J]. IEEE Transactions on Neural Networks, 1994, 5(6): 989-993.
[8] Saini L M, Soni M K. Artificial neural network based peak load forecasting using levenberg-marquardt and quasi-newton methods [J]. IEE Proceedings-Generation, Transmission and Distribution, 2002, 149(5): 578-584.
[9] He L, Guo L, Li H. Emotion speech recognition under sadness conditions [J]. Advanced Materials Research, 2012, 488-489: 1329-1334.
[10] Lee C M, Narayanan S S. Toward detecting emotions in spoken dialogs [J]. IEEE Transactions on Speech and Audio Processing, 2005, 13(2): 293-303.
[11] 何国辉, 甘俊英. PCA类内平均脸法在人脸识别中的应用研究[J]. 计算机应用研究, 2006, 23(3): 165-169.
[12] Ververidisa D, Kotropoulos C. Emotional speech recognition: resources, features and methods [J]. Speech Communication, 2006, 48(9): 1162-1181.
[13] 张忠平, 宋少英, 宋晓辉. 基于PCA及属性距离和的孤立点检测算法[J]. 计算机工程与应用, 2009, 45(17): 139-141.
[14] 王松, 夏绍玮. 一种鲁棒主成分分析(PCA)算法[J]. 系统工程理论与实践, 1998, 18(1): 9-13.
Speech-oriented Negative Emotion Recognition Based on Improved BP Neural Networks
LIU Zhongfeng1, HE Liang2
(1. Halfaya Program Iraq Company, China National Oil and Gas Exploration and Development Corporation, Amarah, Iraq 62001; 2. School of Automation, Nanjing University of Science and Technology, Nanjing, China 210094)
This paper exposes that negative emotions inflicts deep impact on the effects of clinical care because speech is one of the major patterns for human beings to express emotions. We are helped to monitor the emotional states of patients faster and simplier by automatically detecting negative emotions from speech so as to take effective measures to lower the adverse effect brought by negative emotions. In addition, the paper also introduces and extends an improved back propagation (BP) network. The proposed approach expands the redundancy of the characteristic vector for emotion recognition, applies a Principal Component Analysis (PCA) algorithm to select the most influential voice attributes, and adopts a PCA-based method to reduce the effect of outliers in the sample sets. Simulation study shows that the proposed approach is capable to effectively recognize favorable recognition capability from both anger and sorrow emotions.
Negative Emotions; BP (Back Propagation) Netwoek; Forward Selection Algorithm; Principal Component Analysis (PCA); Outliers
TP183;TP391.42
A
1674-3563(2015)03-0017-08
10.3875/j.issn.1674-3563.2015.03.003 本文的PDF文件可以从xuebao.wzu.edu.cn获得
(编辑:封毅)
2014-10-01
刘忠锋(1972- ),男,北京人,工程师,学士,研究方向:情感计算及其应用
