基于改进对比散度的GRBM语音识别
2015-06-09赵彩光张树群雷兆宜
赵彩光,张树群,雷兆宜
(暨南大学信息科学技术学院,广州510632)
基于改进对比散度的GRBM语音识别
赵彩光,张树群,雷兆宜
(暨南大学信息科学技术学院,广州510632)
对比散度作为训练受限波尔兹曼机模型的主流技术之一,在实验训练中具有较好的测试效果。通过结合指数平均数指标算法和并行回火的思想,提出一种改进对比散度的训练算法,包括模型参数的更新和样本数据的采样,并将改进后的训练算法应用于高斯伯努利受限玻尔兹曼机(GRBM)中训练语音识别模型参数。在TI-Digits数字语音训练和数字测试数据库上的实验结果表明,采用改进的对比散度训练的GRBM明显优于传统的模型训练算法,语音识别率能够达到80%左右,最高提升7%左右,而且应用改进算法训练的其他GRBM对比模型的语音识别率也都有所提高,具有较好的识别性能。
对比散度;高斯伯努利受限玻尔兹曼机;受限玻尔兹曼机;指数平均数指标;并行回火;语音识别;深度神经网络
1 概述
深度神经网络(Deep Neural Network,DNN)模型通常为复杂的分层结构[1],每层训练的样本数据特征值作为其他隐层的输入样本,经过多层训练处理,得到蕴含的抽象信息。DNN的优势在于通过增加隐层数扩展了神经网络建模能力,近年来,深度神经网络在语音识别、图像分类等领域得到了广泛应用[2-3]。
文献[4]提出了一种深度信念网络 (Deep Belief Net,DBN),并给出了一个高效的学习算法——贪婪逐层无监督训练算法[4-6]。DBN可以看成由多层受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[7-8]构成的复杂神经网络,当深信度网络只有一个隐藏层时,就是受限制玻尔兹曼机。
RBM参数训练有多种方法:对比散度(Contrastive Divergence,CD)[9-10]、最大随机似然(Stochastic Max-imum Likelihood,SML)[11]等。其中,对比散度是目前比较流行的一种训练RBM算法,该算法可用于训练不同类型的受限玻尔兹曼机模型。实验表明,对比散度在受限玻尔兹曼机中具有良好的测试效果[12-14]。
传统的基于对比散度训练的受限玻尔兹曼机(RBM)模型参数的算法,仅考虑模型预训练得到的最近一次参数值与当前训练模型参数的叠加。由于神经网络模型在实际应用中无法保证采样的充分性,模型采样的样本数据也可以是连续的,而且在实际训练过程中也不可能满足有足够多的采样训练次数。因此,传统CD训练算法仍会对RBM模型的训练具有一定的误差影响。为了克服这个缺点,进一步保证每次训练所得模型参数的连续性,提高模型的识别效果,本文提出一种改进的对比散度训练算法,在训练过程中,当前所得新的模型参数集都会充分考虑过去所有的训练值,减小模型参数对神经网络模型的影响[15-17]。
2 对比散度基本理论
拟合一个复杂的高维数据分布时,通常会采用联合一些简单的概率模型去描述这个数据分布。最常用的方法就是GMM混合高斯模型,采用估计最大化(Estimation Maximization,EM)迭代方法简便地优化整个模型,但是这种方法在一些较高维的数据中效果并不十分理想。文献[18]在此基础上提出了产品专家(Products of Experts,PoE)模型,较为有效地处理高维数据。
PoE模型通过把n个相关的模型用乘积的形式联合起来,做归一化处理,模型数学等式如下:
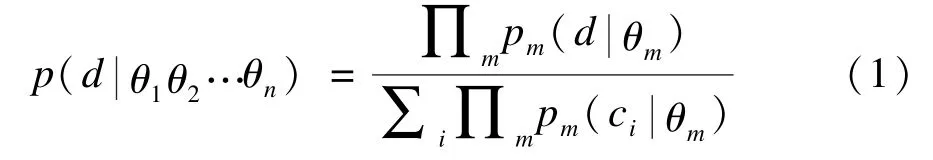
其中,n为模型个数;d为观测数据集;θm为每个模型的参数,分子为归一化项。
通常如果要优化整个模型,会采用log最大似然法去估计模型参数,对θm求偏导:
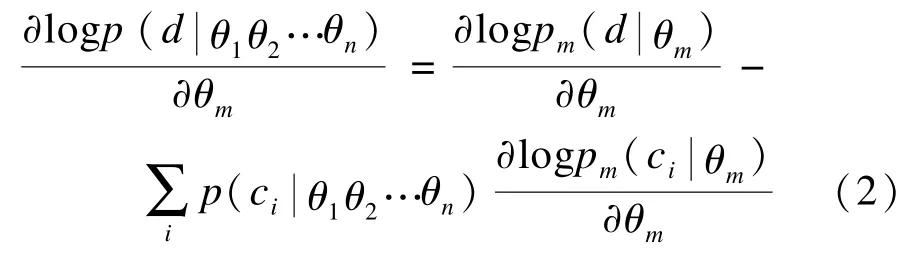
数据分布Q0,而基于观察变量的均衡数据分布表示Q0与Q∞之间的KL距离,即相对熵[9]。所谓的对比散度CD算法,不是去直接优化KL距离,使KL距离达到最小,而是转而去优化Q0之间的距离。Q1是通过一次吉布斯采样[19-20]后重构数据的分布,当两者之间距离为0时,从狭义上来说模型是完美的,因此,CD算法优化两者之间距离,对目标函数求偏导:

而近似的参数更新则为:
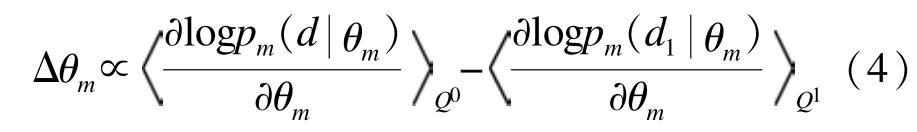
对于式(3)中的第3项可以约去的原因是[9]:在通常情况下,第3项的数值非常小,并且很少会抵消前2项之和。
3 高斯受限玻尔兹曼机
受限玻尔兹曼机(RBM)模型是玻尔兹曼机由可视层v和隐层h组成,同层节点间没有连接,传统的RBM模型采用二元神经元节点,即节点取值为{0,1}两值的神经元构建RBM。高斯伯努利受限玻尔兹曼机(GRBM)与基本受限玻尔兹曼机的区别在于: GRBM将二进制可视节点值替换为具有高斯分布的连续实数,隐层仍采用服从伯努利分布的二值神经元节点,高斯伯努利受限玻尔兹曼机的能量函数为:

N(μ,σ2)表示均值为μ,方差为σ2的高斯分布, GRBM的可视节点和隐层节点激活的条件概率如下:
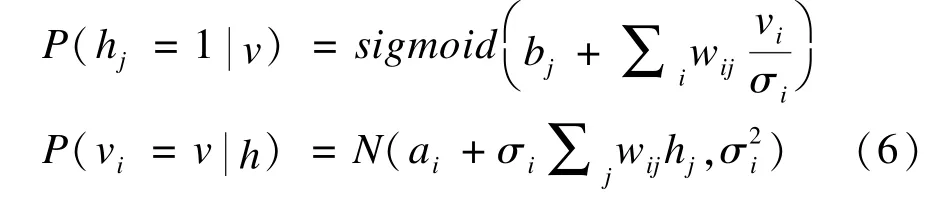
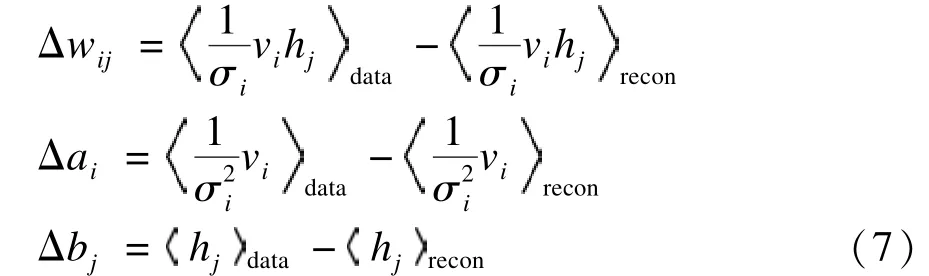
因此,GRBM模型参数θGRBM更新方法如式(8)所示,ε表示学习率:
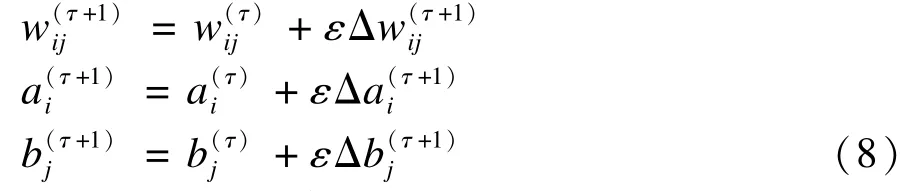
其中,i,j表示模型参数下标;上标τ表示模型训练的次数;表示第 τ+1次采用对比散度算法训练所得模型参数值θGRBM。
4 改进的对比散度训练算法
4.1 对比散度改进算法
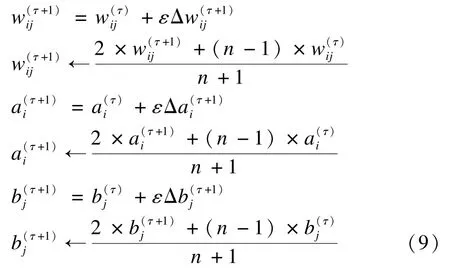
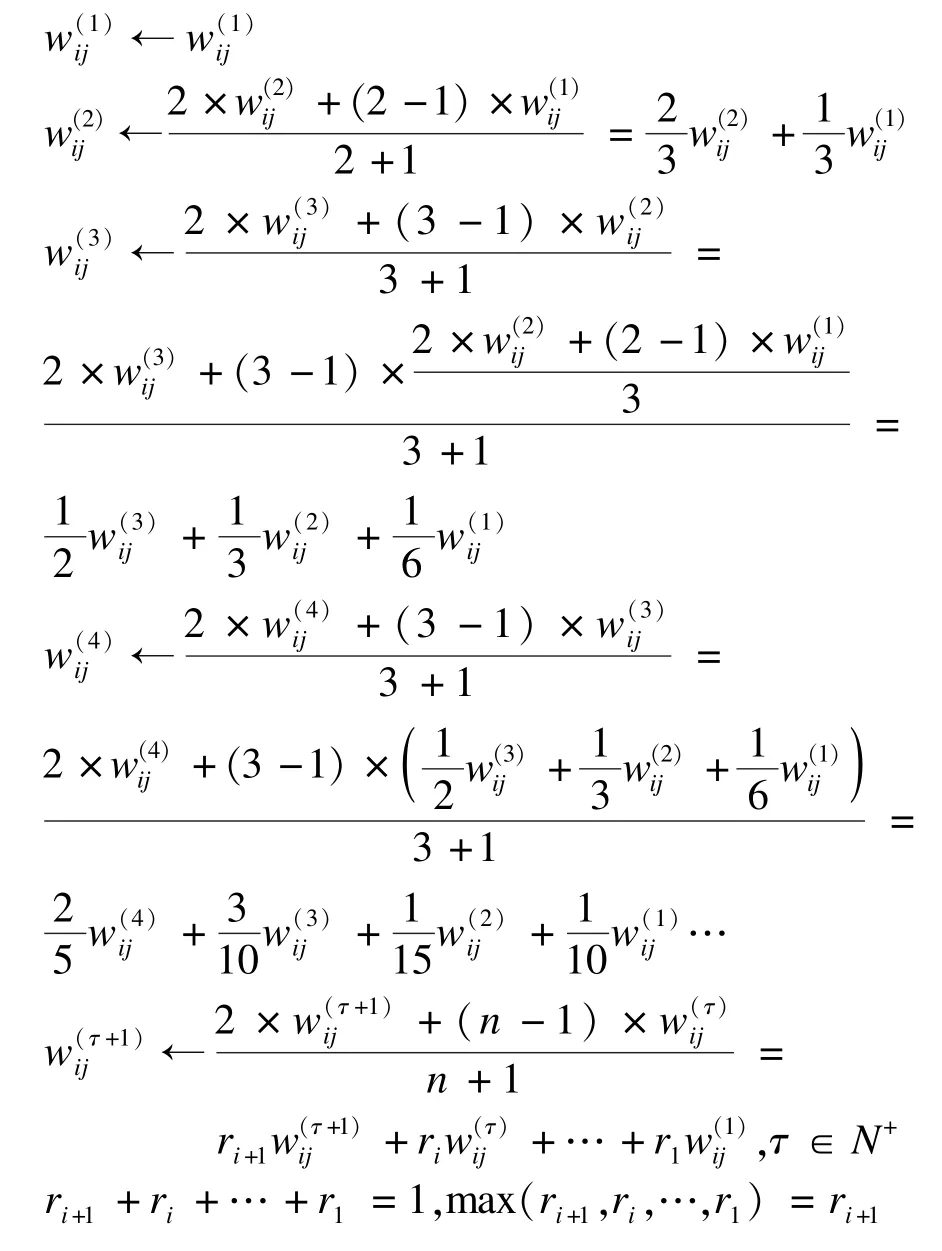
同理,偏置向量a和b:
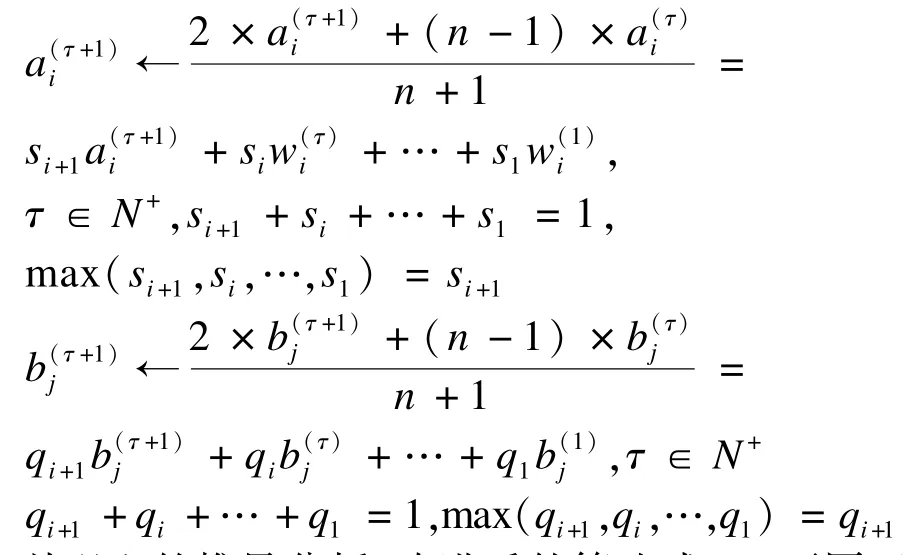
从以上的推导分析,改进后的算法式(9)不同于传统的对比散度训练模型参数,式(8)只是考虑了最近一次的相关模型参数。可以看到,基于指数平均数指标改进的对比散度训练算法,每次参数的更新不仅会对上一次的相关参数值加强权重比(最大权重比),而且在训练的过程中也会加权过去已知的模型训练值,反映近期模型参数的波动情况,过去各个阶段的参数所占权重比不同。改进的CD算法对模型参数进行加权平均,分析可知,给予当前得到的新模型参数的权重,给予过去的参数值共的权重。
4.2 并行回火
并行回火(Parallel Tempering,PT)[21-23]采样对RBM训练是一种很有效率的方法[24]。RBM-PT在训练过程中,M个不同温度对应M条吉布斯链使用并行回火的方法采样,每条吉布斯链对应一个不同的温度ti,ti满足1=t1<t2<…<ti<…<tM-1<tM,不同温度链之间根据一定的条件决定是否交换采样值。通过分析基本并行回火RBM模型,对GRBM在并行回火的每个温度下进行一次或多次吉布斯采样,采用并行回火改进 GRBM 模型的参数为,具体公式如下:
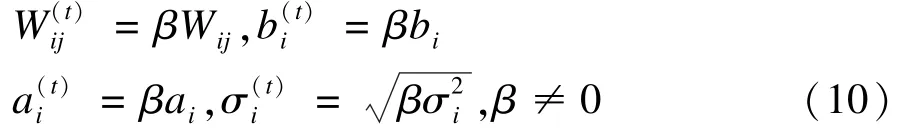
计算温度集内的2个相邻的温度(tr和tr-1)下的显隐层节点(vr,hr)与(vr-1,hr-1)是否满足交换的条件,并行回火GRBM模型的交换条件如式(11)所示:

E(vr,hr)即不同模型下的能量函数,如式(5)所示。如果满足该条件式(11),就把相邻的温度链下的采样点交换,否则不交换。经过多次循环采样、交换,最终将t1=1温度下的采样值用于GRBM预训练模型参数θ,采用并行回火获取的目标采样值可使GRBM训练获得较好的应用效果。
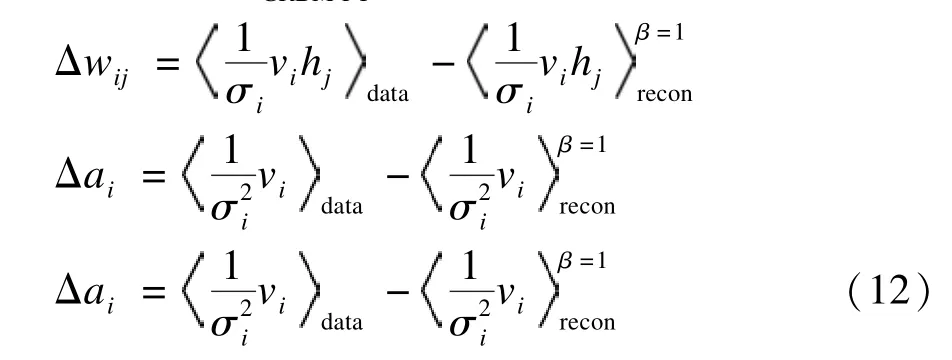
4.3 算法描述
综上所述,本文改进的对比散度算法训练GRBM模型如下:
输入 训练样本xi,隐层单元个数m,学习率ε,最大训练周期N,GRBM模型参数θGRBM-PT={βW,βa,,其中,0<β1<…<βi<…<βM-1<βM=1
输出 连接权值矩阵w,可见层的偏置向量a,隐层的偏置向量b

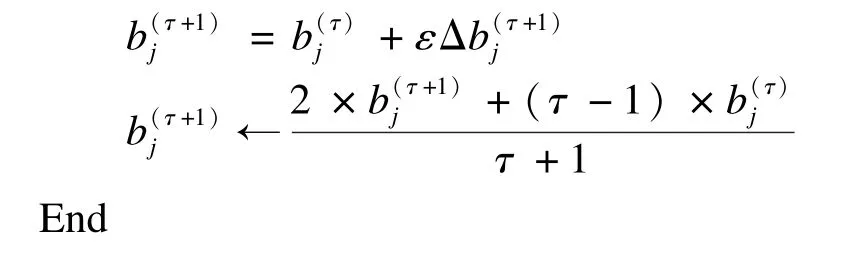
5 实验配置与结果分析
5.1 实验配置
本文实验在TI-Digits数据集上进行,分为训练集和测试集2类,训练集和测试集各自包含男声和女声发音,分别为英文数字0~9,训练集包含38组男声和57组女声,共2 072段语音,每个训练数据对应一个类别的标签作为分类的依据,类别标签共2 072个,测试集包含56组男声和57组女声,共2 260段语音,类别标签为2 260个,语音识别内容的具体数量如表1所示。原始语音信号使用Hanning窗进行处理,帧长32 ms,帧移16 ms。虽然RBM也能提取声学特征参数,但是,由文献[26]中的实验表明,MFCC在实际应用中具有较好的实验效果,因此,本文实验全部采用声学特征Mel频率倒谱系数(Mel frequency Cepstral Coefficient,MFCC)作为模型底层的输入数据,实验中采用42维的特征向量。
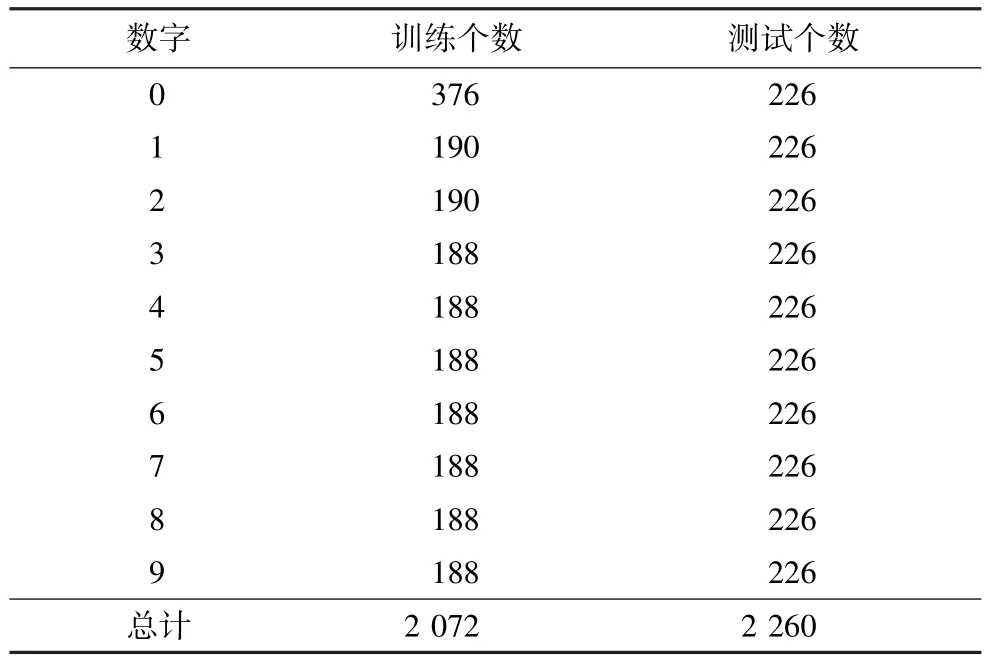
表1 语音训练和测试数据具体个数
GRBM模型采用2层模型进行语音识别实验:第1层是采用改进的对比散度算法训练GRBM模型,包括并行回火采样;第2层采用支持向量机(Support Vector Machine,SVM)[27]对训练后的模型得到的识别结果进行分类。显层节点数为42,因为隐层节点的数目不同会对识别效果产生不同影响,因此这里不固定。权值W初始为满足[-1.0,1.0]均匀分布的随机数,偏置a和b初始为0,预训练中的学习速率为0.001,参数循环次数为100。并行回火的温度个数M=10,β∈{0.1,0.2,…,1},[t1= 0.1,tM=1]满足β∈0.1,1]内的均匀分布。实验采用一步吉布斯采样改进的对比散度(CD1)方法,由于语音识别采用的训练和识别数据是连续的,因此本文选用3种不同的GRBM模型用于实验测试,建立3个不同的高斯受限玻尔兹曼模型进行实验对比,采用改进的CD训练算法与未改进的CD训练算法的数字语音识别率。模型分为:(1)基本GRBM模型;(2)文献[24]提出的GBRBM模型;(3)GRBM-PT模型(本文改进算法模型)。实验平台采用的是Matlab 2010b。
5.2 实验结果及分析
表2分别列出各种不同高斯受限玻尔兹曼机下的语音识别率,不同GRBM模型下的语音识别率不同,在同等训练条件下,使用原始对比散度算法训练的GRBM-PT模型的语音识别率最高,能够达到73.23%,比未使用并行回火采样的GRBM的语音识别率有较大的提高。
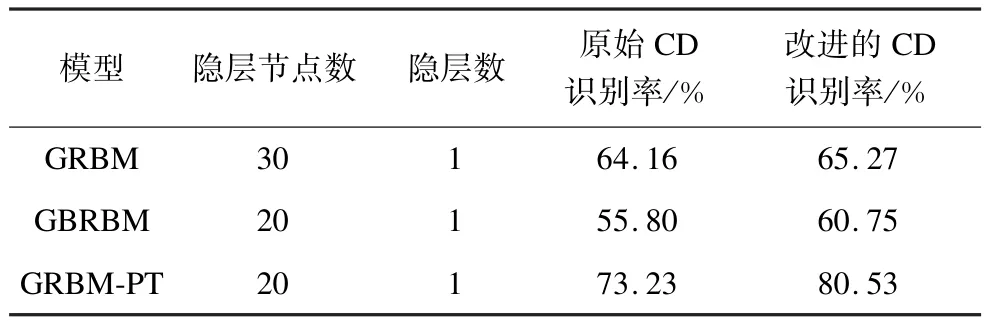
表2 数字语音识别率比较
另外,由表2可以看出,对于同一个模型,采用改进的CD算法明显优于传统的CD训练算法,同一个模型下的语音识别率都有相应的提高。各个模型间对比说明,使用改进的CD算法训练的GRBM的识别效果仍是最好的。改进的对比散度训练算法在采样过程中使用本文提出的并行回火采样算法(GRBM-PT),语音识别率可以达到80%左右,在保证基本识别效果的前提下,语音识别率进一步提高了7%左右,模型具有良好的识别性能。
图1~图4中的黑色实线表示采用本文改进的CD训练算法,虚线表示原始CD训练算法,图4用“∗”线表示原始CD训练算法。由图1~图3可以看出,改进的CD算法,因为模型参数的每次训练都与过去所有已知值相关,充分考虑过去已知参数值,算法能及时反映近期参数值的波动情况,更加稳定,改进的CD算法训练的模型参数值相比于未改进的CD算法训练的模型参数值的绝对值要小。实线较虚线走向更加平滑,曲线连续性好。由图4可以看出,改进算法得到的重构误差曲线快速收敛,在曲线下降即第0~500次训练阶段,改进的CD算法实线曲线走向收敛的速度明显快于原始“∗”线。
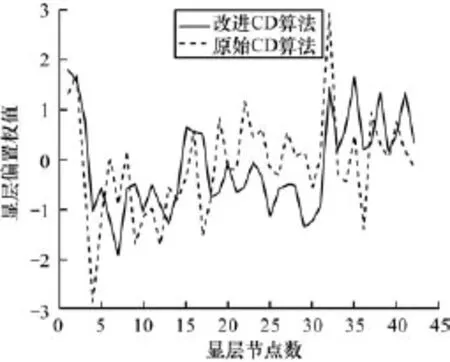
图1 显层偏置权值对比曲线
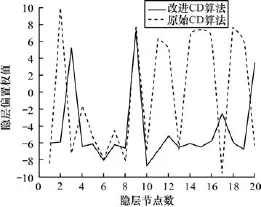
图2 隐层偏置权值对比曲线
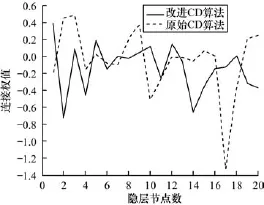
图3 显层和隐层连接权值对比曲线
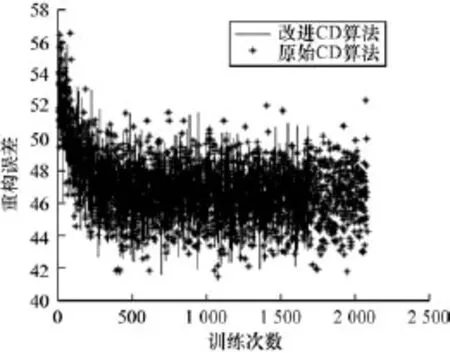
图4 模型重构误差对比曲线
图1 ~图3模型参数实线曲线变化平滑,波动幅度较小,而原始CD训练算法所得模型参数值幅度跳动较大,不易稳定;并且由图4重构误差曲线可以看出,图4的∗线曲线轮廓稍大于实线曲线轮廓,实线曲线波动范围主要集中在44~48左右,而∗线则集中在43~50左右间波动,采用改进后的CD算法,模型误差的波动幅度范围进一步降低。除此之外,改进的CD训练算法实线曲线大约训练1 600次左右就收敛停止训练,而原始CD算法在2 200次左右,改进后的训练算法模型更容易收敛,训练循环次数降低。
6 结束语
本文主要研究分析了对比散度的算法原理,利用指数平均数指标算法改进传统的对比散度算法训练高斯受限玻尔兹曼机模型参数,并且实现了并行回火下GRBM神经网络模型在TI-Digits数据集上进行的语音识别。实验结果表明,改进后的对比散度算法训练的神经网络模型在识别效率和训练速度上明显提高,为进一步将该方法应用于多层深度学习的语音识别奠定了基础。
[1]Bengio Y.Learning Deep Architectures for AI[J]. Foundations and Trends in Machine Learning,2009, 2(1):1-127.
[2]Dahl G E,Ranzato M,Mohamed A,etal.Phonerecognition with the Mean-covariance Restricted Boltzmann Machine[C]//Proceedings of the 24th Annual Conference on Neural Information Processing Systems.Berlin, Germany:Springer,2010:469-477.
[3]Mohamed A,Dahl G E,Hinton G,et al.Acoustic Modeling UsingDeepBeliefNetworks[J].IEEE Transactions on Audio, Speech and Language Processing,2012,20(1):14-22.
[4]Salakhutdinov R,Hinton G.An EfficientLearning Procedure for Deep Boltzmann Machines[J].Neural Computation,2012,24(8):1967-2006.
[5]Hinton G E,Osindero S,Teh Y W.A Fast Learning Algorithm for Deep Belief Nets[J]. Neural Computation,2006,18(7):1527-1554.
[6]张 震,赵庆卫,颜永红.基于语音识别与特征的无监督语音模式提取[J].计算机工程,2014,40(5): 262-265.
[7]Fischer A,Igel C.An Introduction to Restricted Boltzmann Machines[C]//Proceedings of Progress in Pattern Recognition,Image Analysis,Computer Vision,and Applications.Berlin,Germany:Springer,2012:14-36.
[8]Mohamed A,Dahl G,Hinton G.Deep Belief Networks for Phone Recognition[C]//Proceedings of Workshop on Deep Learning for Speech Recognition and Related Applications.Berlin,Germany:Springer,2009.
[9]Hinon G E.Training Products of Experts by Minimizing Contrastive Divergence[J].Neural Computation,2002, 14(8):1771-1800.
[10]Tóth L,Grósz T.A Comparison of Deep Neural Network Training Methods for Large Vocabulary Speech Recognition[C]//Proceedings of the 16th International Conference on Text,Speech,and Dialogue.Berlin, Germany:Springer,2013:36-43.
[11]Tieleman T.Training Restricted Boltzmann Machines Using Approximations to the Likelihood Gradient[C]// Proceedings of the 25th International Conference on Machine Learning.New York,USA:ACM Press,2008: 1064-1071.
[12]Dahl G E,Yu Dong,Li Deng,et al.Context-dependent Pre-trained Deep Neural Networks for Large-vocabulary Speech Recognition[J].IEEE Transactions on Audio, Speech,and Language Processing,2012,20(1):30-42.
[13]Seide F,Li Gang,Dong Yu.Conversational Speech Transcription Using Context-dependentDeep Neural Networks[C]//Proceedings of the 12th Annual Conference of the International Speech Communication Association.Washington D.C.,USA:IEEE Press,2011: 437-440.
[14]薛少飞,宋 彦,戴礼荣.基于多GPU的深层神经网络快速训练方法[J].清华大学学报,2013,53(6): 745-748.
[15]Krizhevsky A,Hinton G.Learning Multiple Layers of Features from Tiny Images[D].Toronto,Canada: University of Toronto,2009.
[16]Tang Yichuan,Mohamed A R.Multiresolution Deep Belief Networks[C]//Proceedings of International Conference on Artificial Intelligence and Statistics. New York,USA:ACM Press,2012:1203-1211.
[17]陈丽萍,王尔玉,戴礼荣.基于深层置信网络的说话人信息提取方法[J].模式识别与人工识别,2013, 26(12):1089-1095.
[18]Hinton G E.Products of Experts[C]//Proceedings of the 9th International Conference on Artificial Neural Networks.New York,USA:ACM Press,1999:1-6.
[19]Resnik P,Hardisty E. Gibbs Sampling for the Uninitiated[D].Washington D.C.,USA:University of Maryland,2010.
[20]Walsh B.Markov Chain Monte Carlo and Gibbs Sampling[D].Tucson,USA:University of Arizona,2004.
[21]Gront D,Kolinski A.Efficient Scheme for Optimization of Parallel Tempering Monte Carlo Method[J].Journal of Physics:Condensed Matter,2007,19(3).
[22]Trebst S,Troyer M,Hansmann U H E.Optimized Parallel Tempering Simulations of Proteins[J].The Journal of Chemical Physics,2006,124(17).
[23]Desjardins G,Courville A,Bengio Y,et al.Parallel Tempering for Training of Restricted Boltzmann Machines[C]//Proceedings of the 13th International Conference on ArtificialIntelligence and Statistics. Berlin,Germany:Springer,2010:145-152.
[24]Cho K H,Raiko T,Ilin A.ParallelTempering is Efficient for Learning Restricted Boltzmann Machines[C]//Proceedings of International Joint Conference on Neural Networks.New York,USA:ACM Press,2010:1-8.
[25]Cho K H,Ilin A,Raiko T.Improved Learning of Gaussian-Bernoulli Restricted Boltzmann Machines[C]//Proceedings of the 21st International Conference on Artificial Neural Networks.Berlin,Germany:Springer,2011:10-17.
[26]Mus D.Audio Feature Extraction with Restricted Boltzmann Machines[EB/OL].(2014-02-28).http:// www.liacs.nl/~dmus/paper.pdf.
[27]徐 晨,曹 辉,赵 晓.基于SVM的说话人识别参数选择方法[J].计算机工程,2012,38(21):175-177.
编辑 顾逸斐
Speech Recognition of Gaussian-Bernoulli Restricted Boltzmann Machine Based on Improved Contrastive Divergence
ZHAO Caiguang,ZHANG Shuqun,LEI Zhaoyi
(College of Information Science and Technology,Jinan University,Guangzhou 510632,China)
Contrastive divergence has a good result for training restricted Boltzmann machine model as one of the mainstream training algorithm in the experiments.An improved contrastive divergence based on Exponential Moving Average(EMA)is proposed by combining with the exponential moving average learning algorithm and Parallel Tempering(PT),which includes updating the model parameters and samples.The improved algorithm is applied to train speech recognition model parameters in Gaussian-Bernoulli Restricted Boltzmann Machine(GRBM),and experimental results of digit speech recognition on the core test of TI-Digits show that the proposed algorithm works better than traditional training algorithms in GRBM,the accuracy can be as high as 80.53%and increase by about 7%.Recognition accuracy of some other GRBM models also increase apparently based on the proposed algorithm.And its performance keeps well.
Contrastive Divergence(CD);Gaussian-Bernoulli Restricted Boltzmann Machine(GRBM);Restricted Boltzmann Machine(RBM);Exponential Moving Average(EMA);Parallel Tempering(PT);speech recognition;Deep Neural Network(DNN)
1000-3428(2015)05-0213-06
A
TP391.4
10.3969/j.issn.1000-3428.2015.05.039
赵彩光(1989-),男,硕士研究生,主研方向:神经网络,语音识别;张树群,副教授;雷兆宜,高级实验师。
2014-06-16
2014-07-09E-mail:gwongc@126.com
中文引用格式:赵彩光,张树群,雷兆宜.基于改进对比散度的GRBM语音识别[J].计算机工程,2015,41(5):213-218.
英文引用格式:Zhao Caiguang,Zhang Shuqun,Lei Zhaoyi.Speech Recognition of Gaussian-Bernoulli Restricted Boltzmann Machine Based on Improved Contrastive Divergence[J].Computer Engineering,2015,41(5):213-218.
